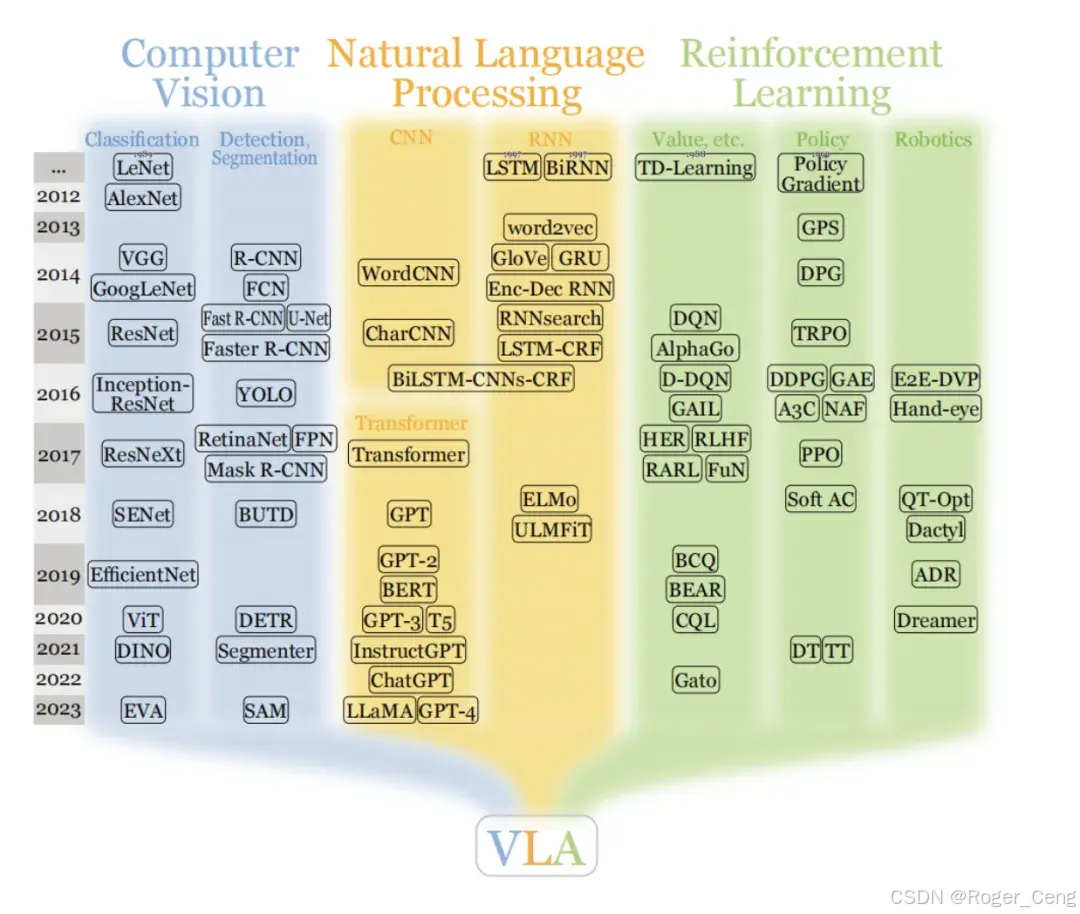
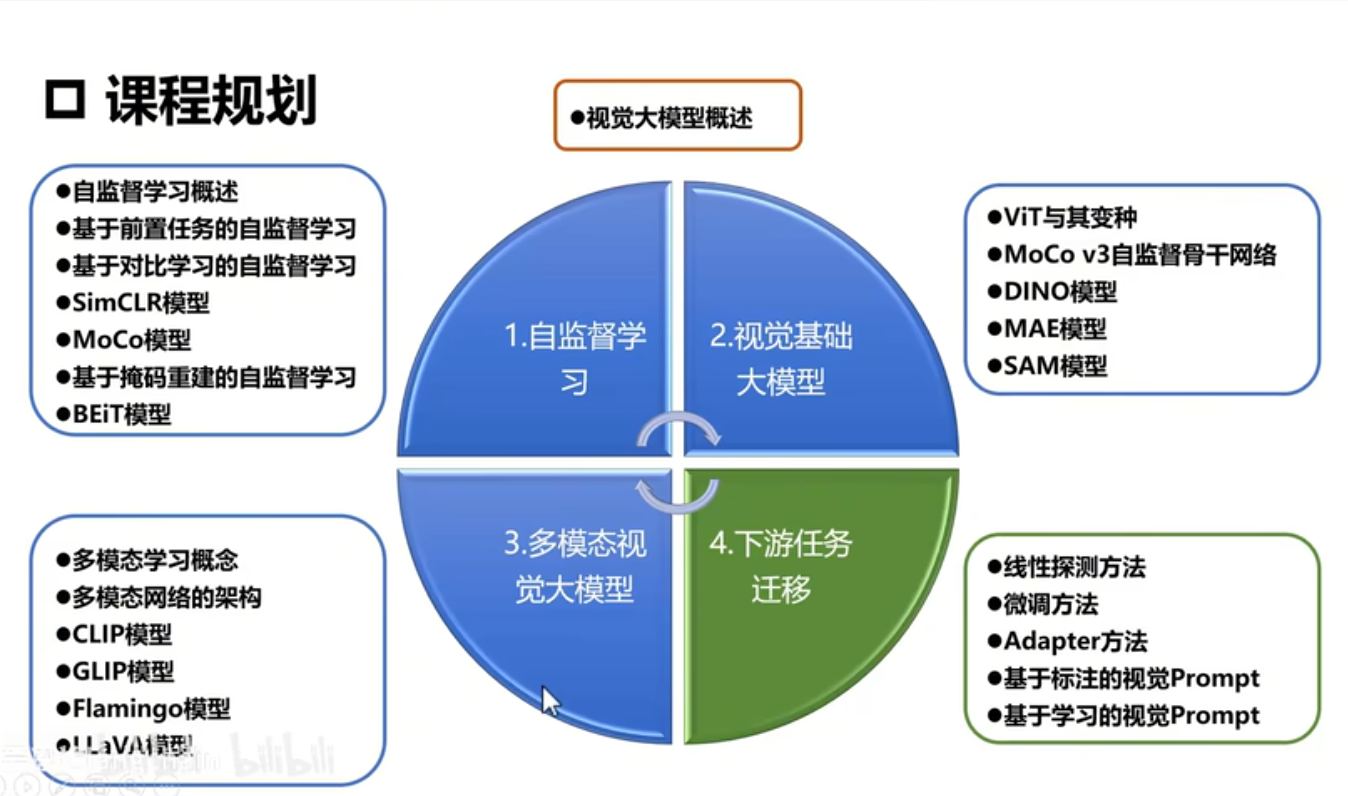
视觉大模型
技术路线
智能交互-语音识别,认知推理-大语言模型LLM
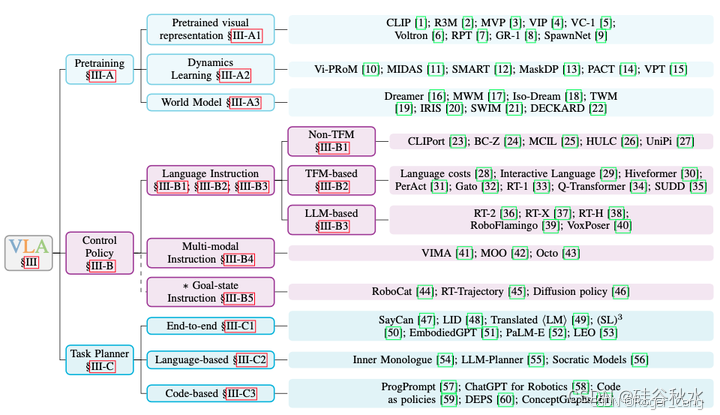
大模型浪潮爆发后,机器人领域经历了两个阶段:从利用基础模型进行机器人研究(leveraging foundation models in robotics)到为机器人预训练基础模型(pretraining foundation models for robotics)
第一阶段:利用基础模型进行机器人研究 ,机器人传统三板块:Planning+Perception+Actuation(规划+感知+执行)
第一步,用LLM(Large Language Model,大语言模型)替代Planning
第二步,用VLM(Vision-Language Models,视觉语言模型)替代Perception
第三步,想把Actuation进一步自动化,用Code LM(专门用于代码相关任务的大型语言模型)来替代Actuation
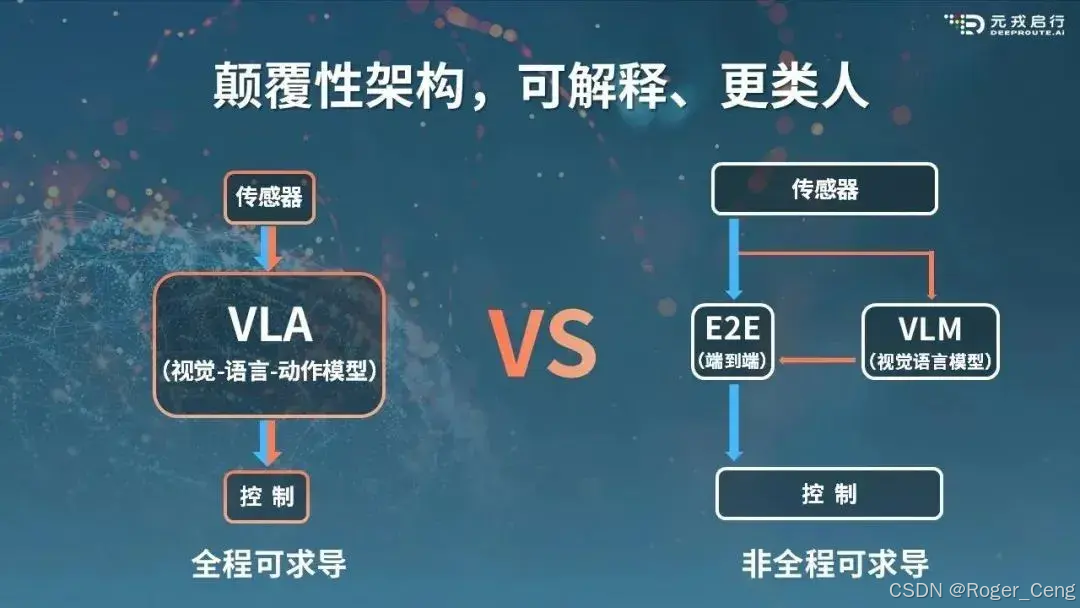
第二阶段:为机器人预训练基础模型 38:36 VLA端到端模型(Vision-Language-Action Model,视觉语言动作模型)——“人是很智能的VLA Agent”
NLP大模型特别大,需要很大算力,CV领域还可以
智能涌现
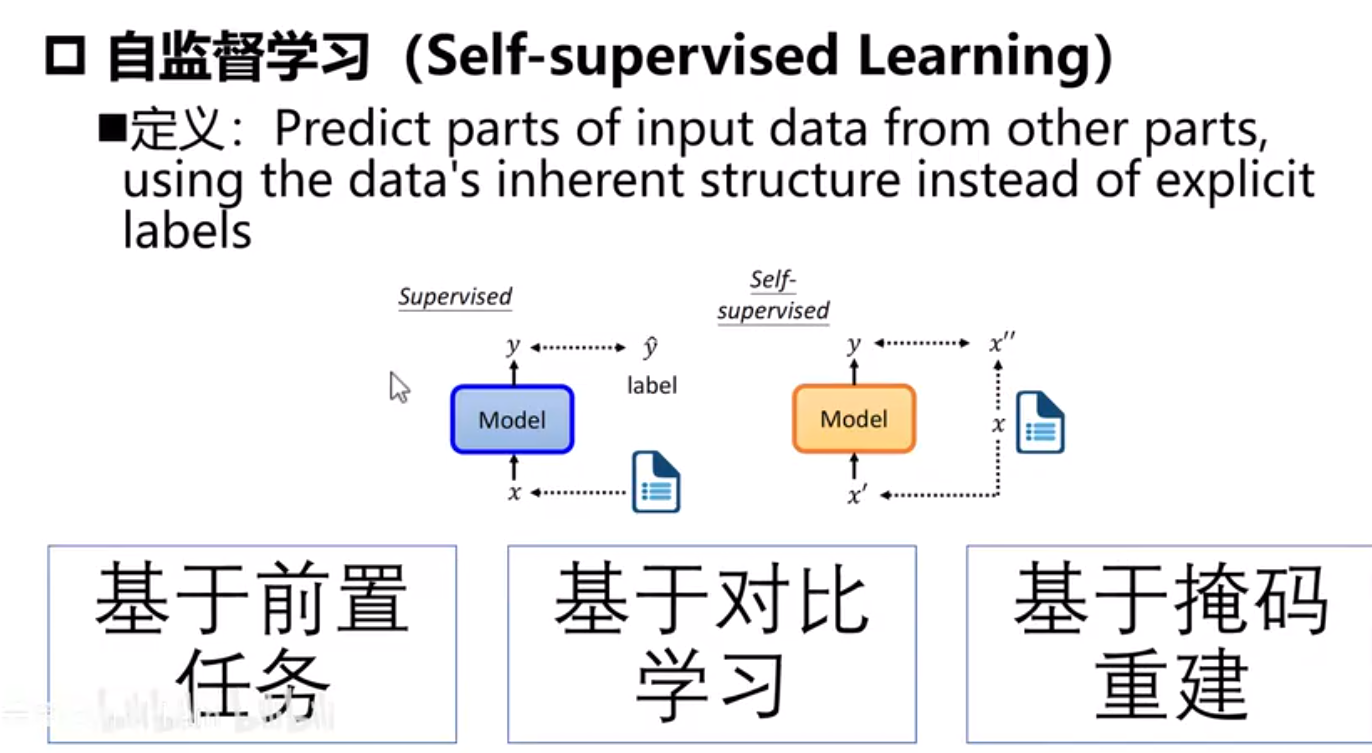
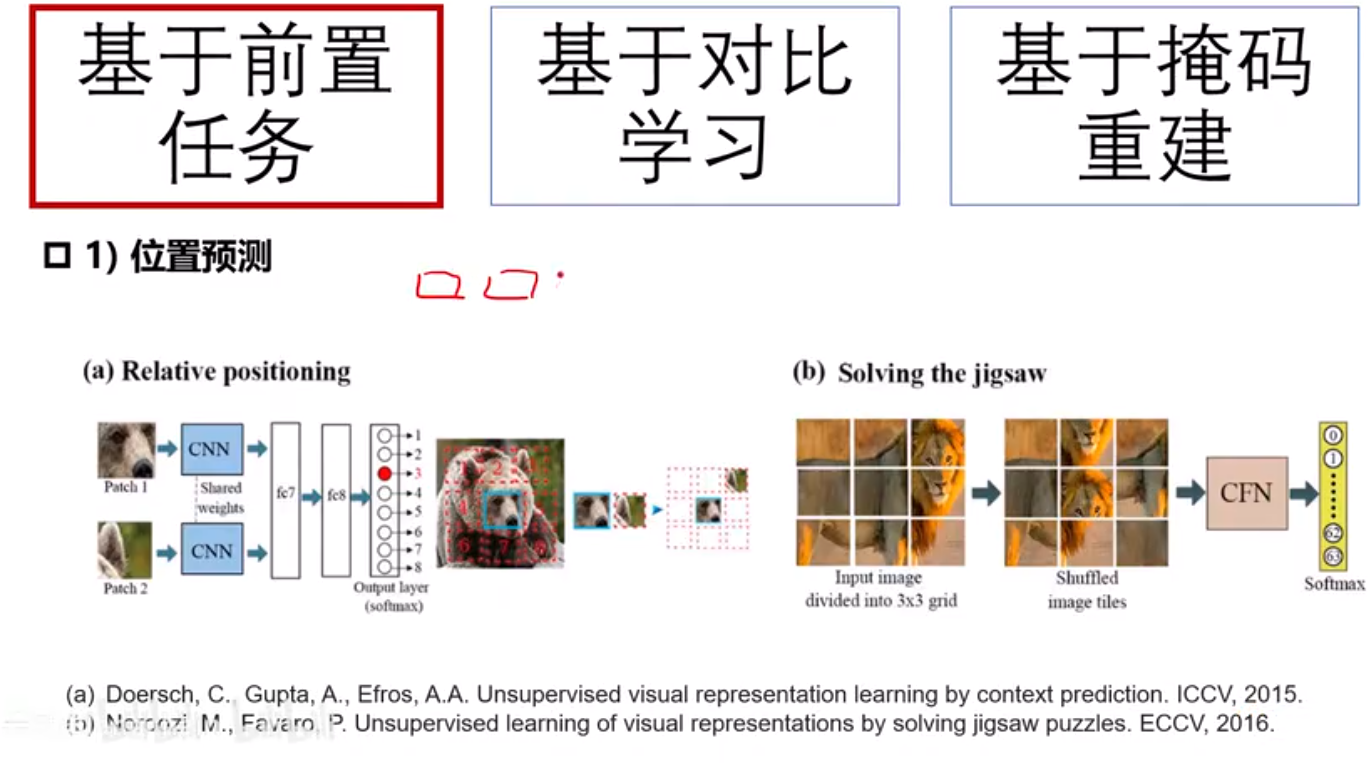
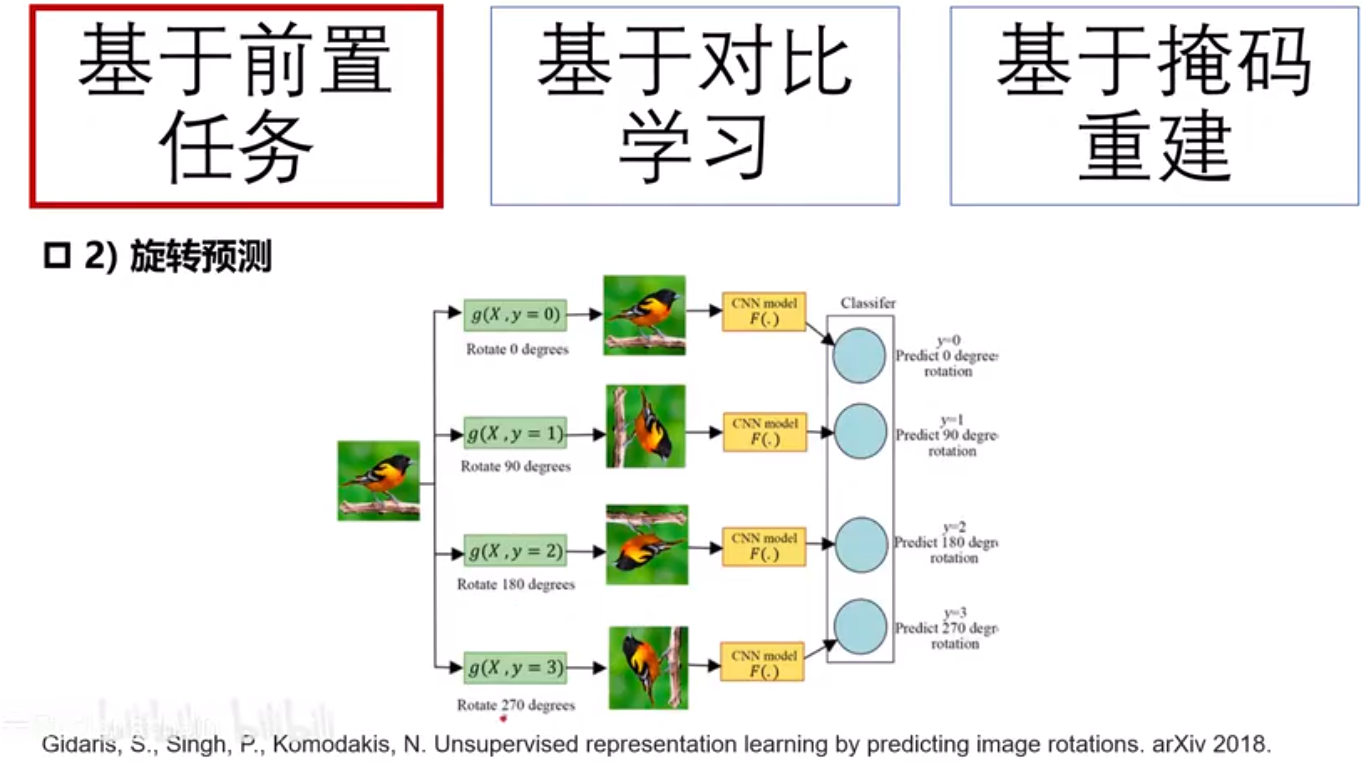
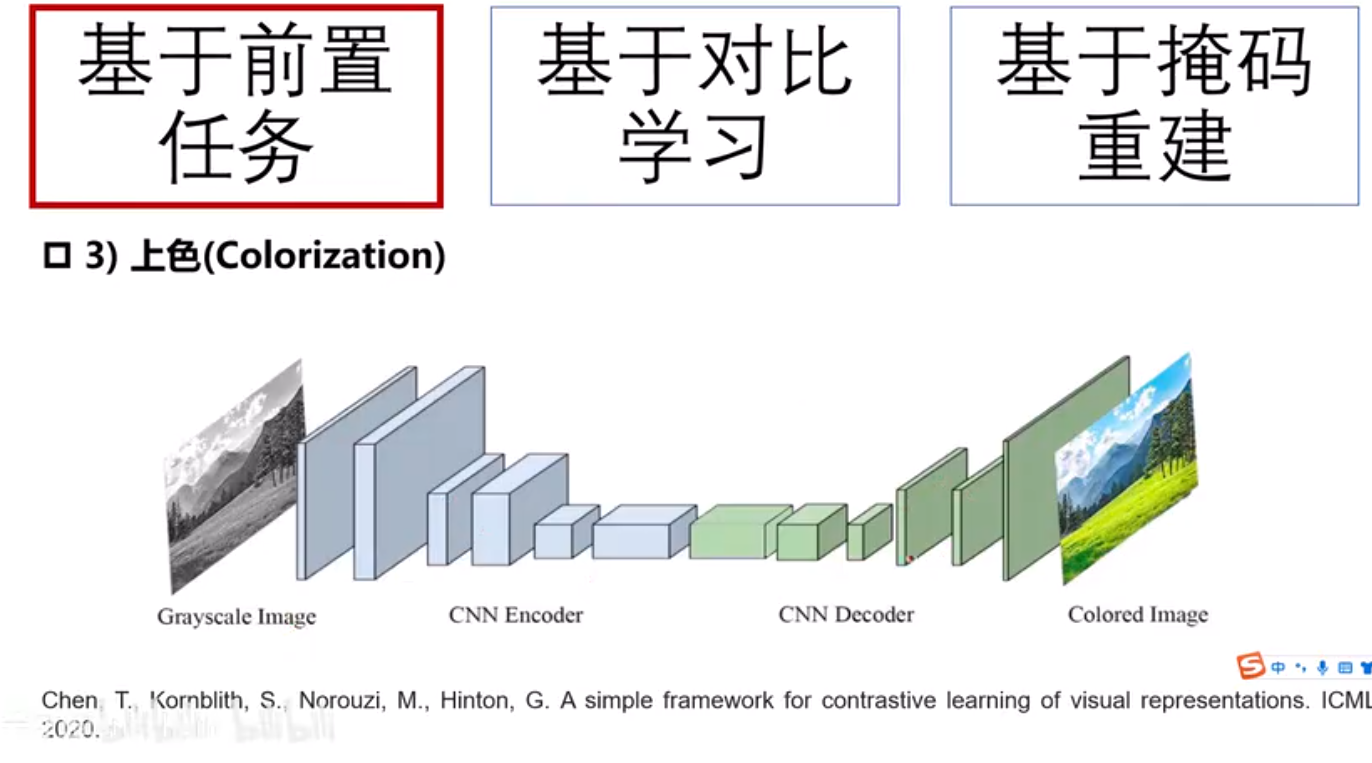
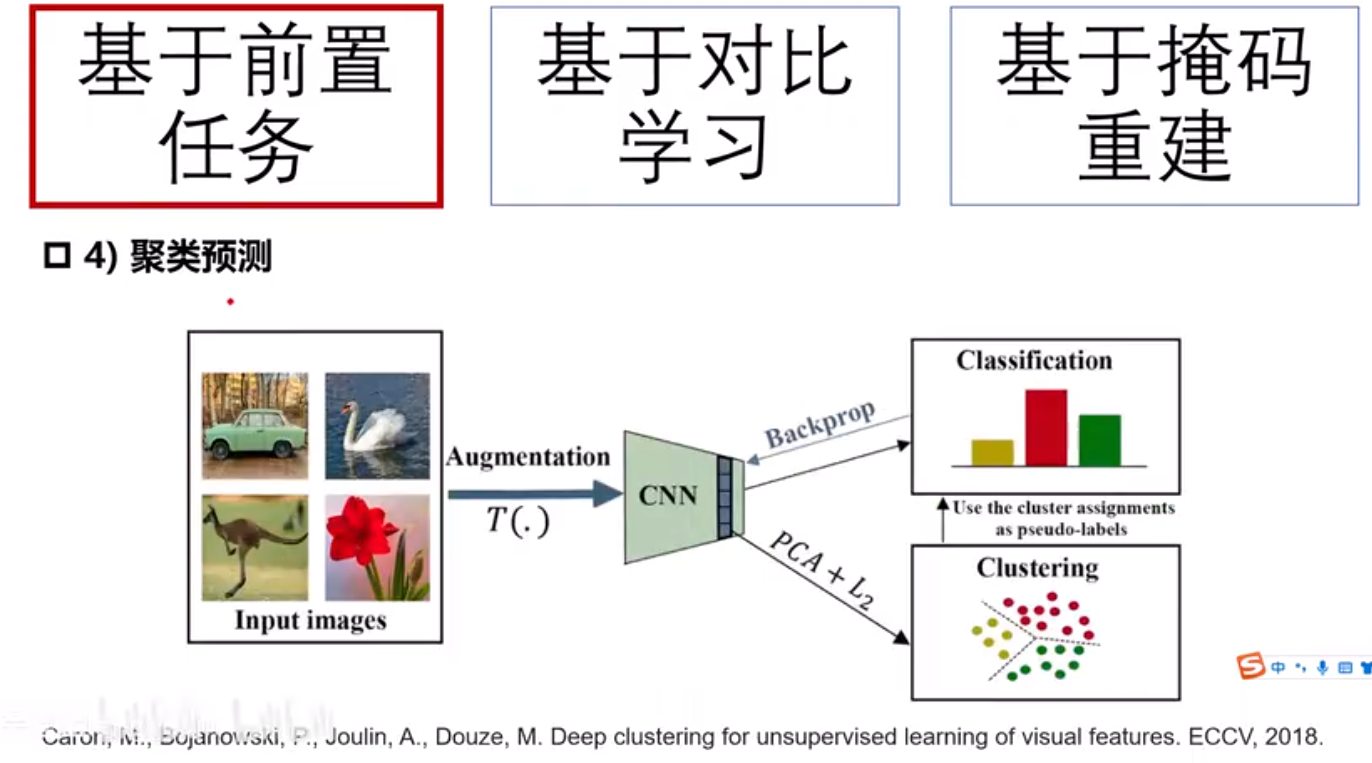
自监督学习
https://www.bilibili.com/video/BV1hwLEzZEnS?spm_id_from=333.788.player.switch&vd_source=d31e5014a01dd0e66e50092730d3cc5c&p=2
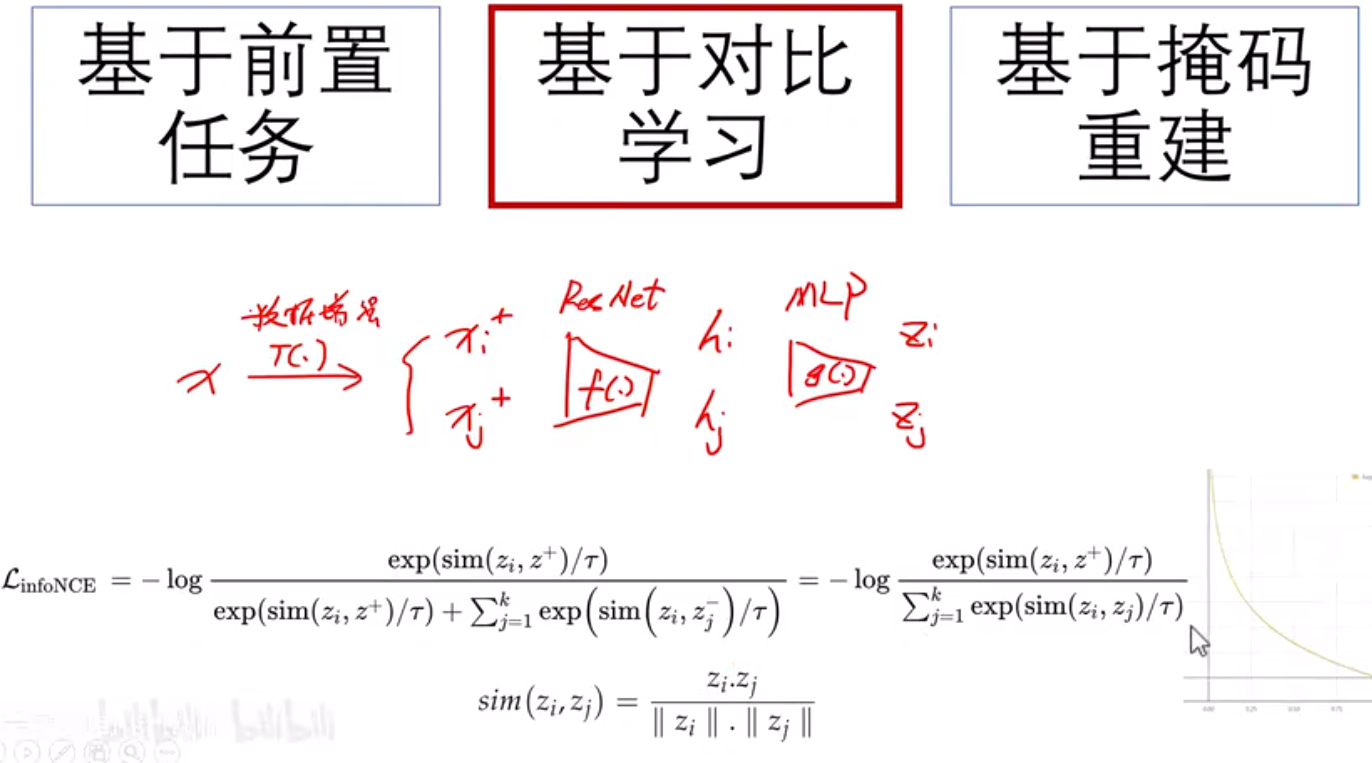
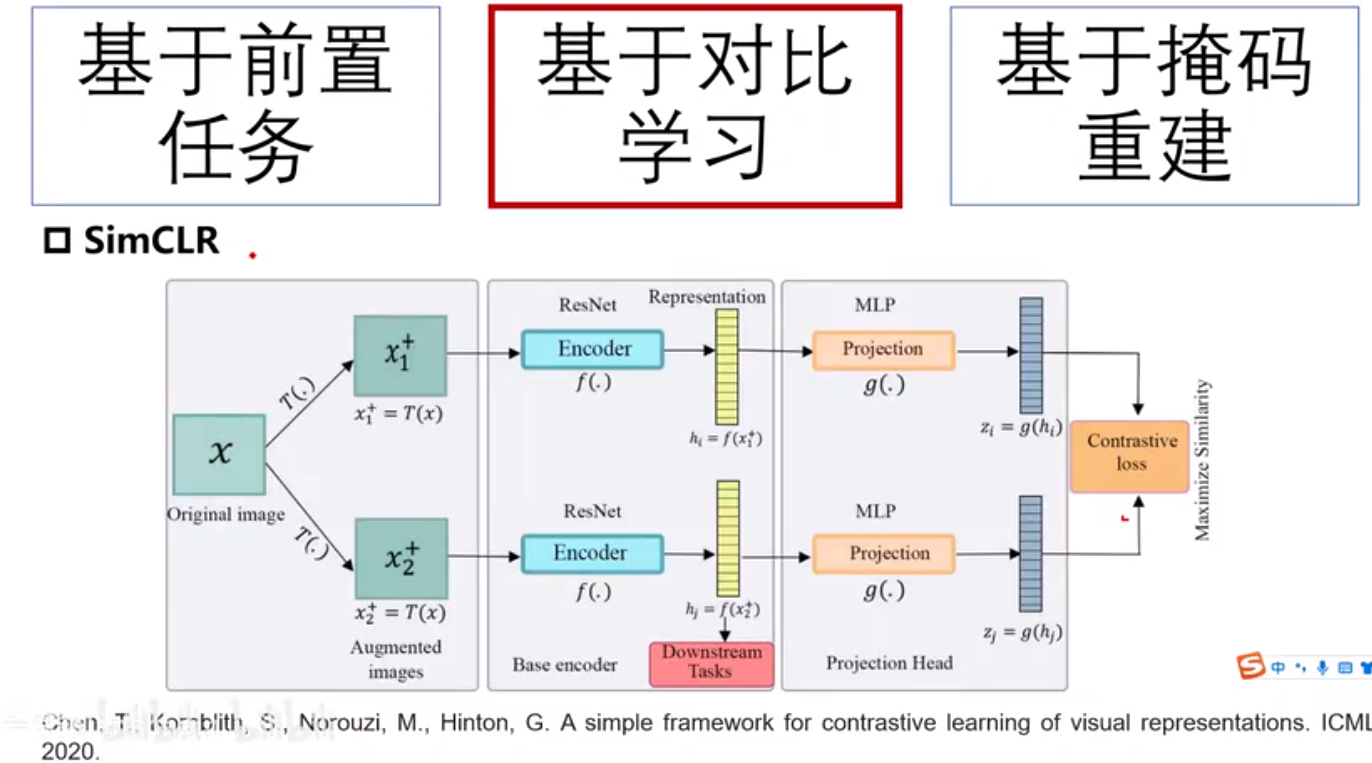
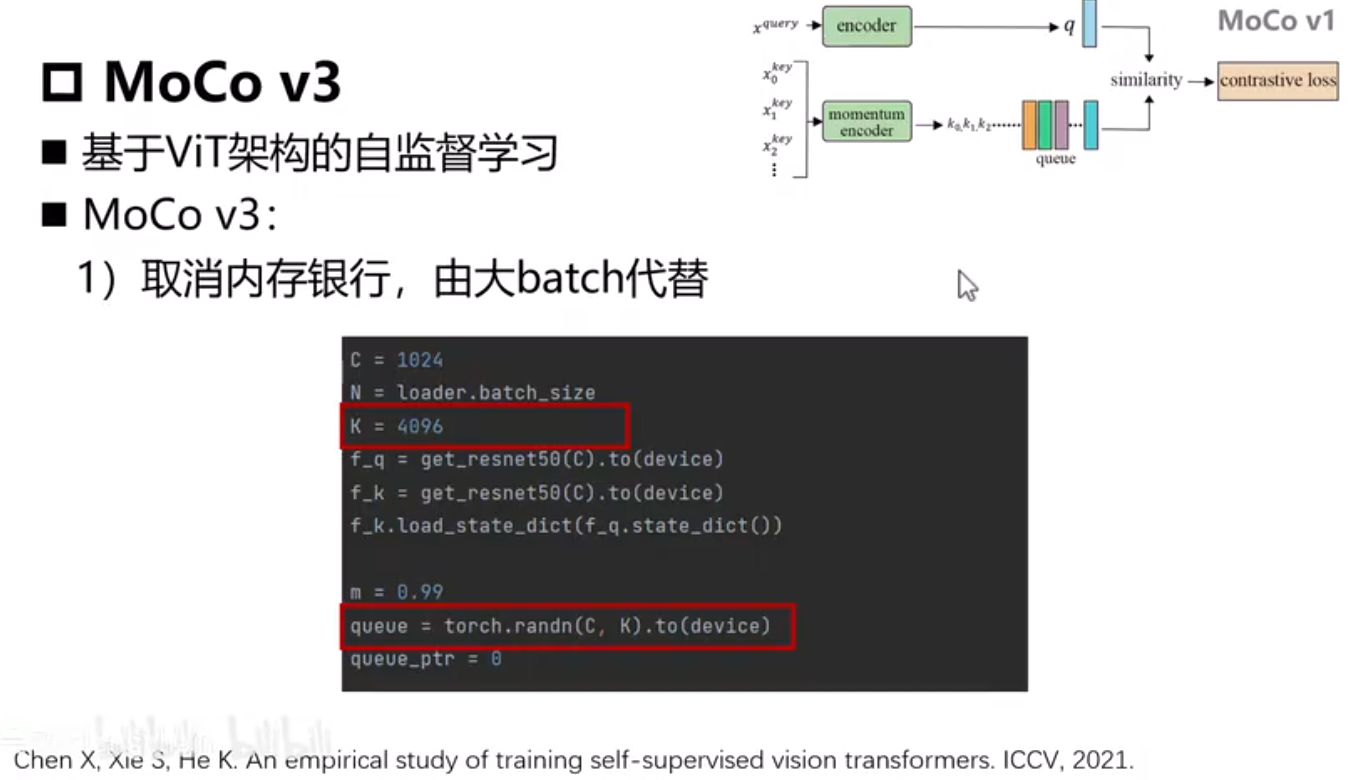
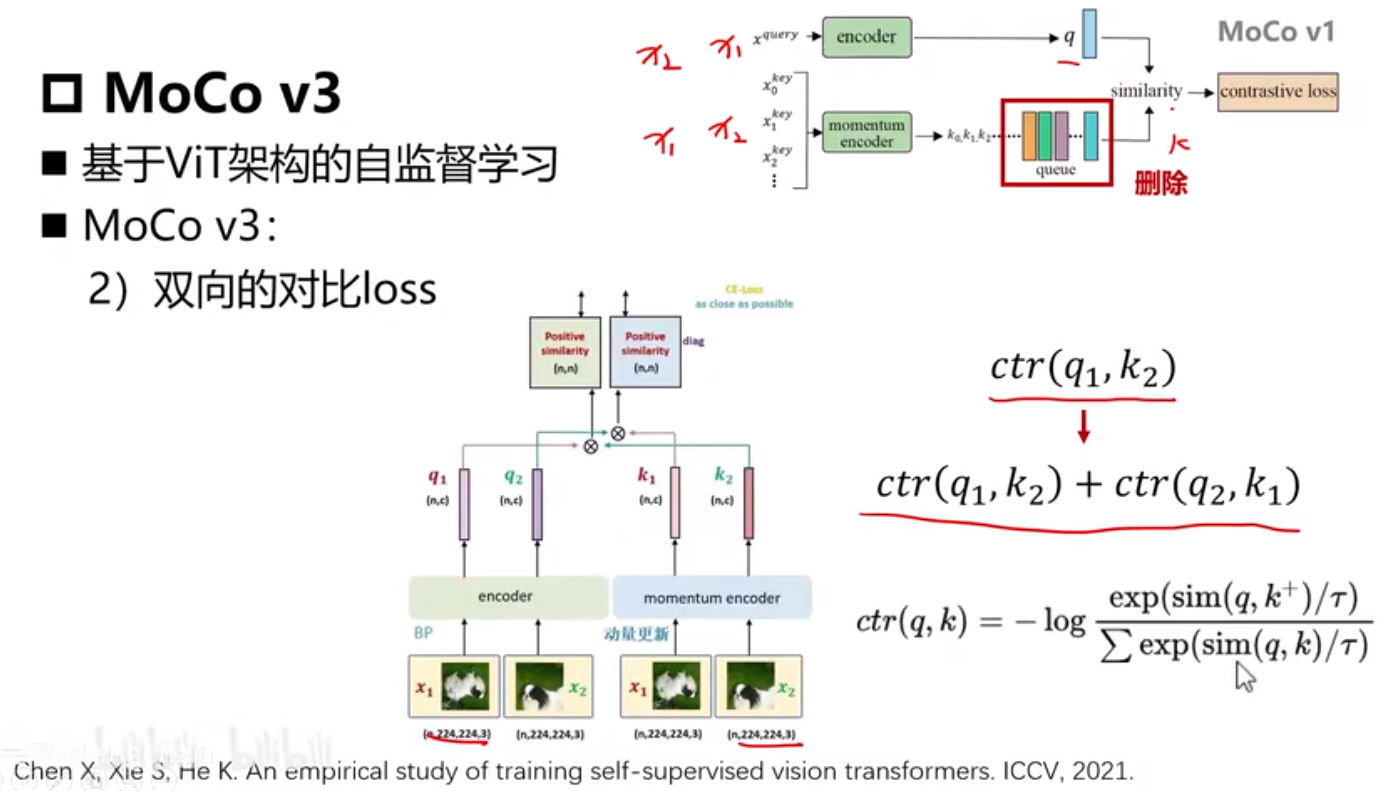
C=1024 维度大小
N=batchsize
K=4096 最多可以存储负样本数量
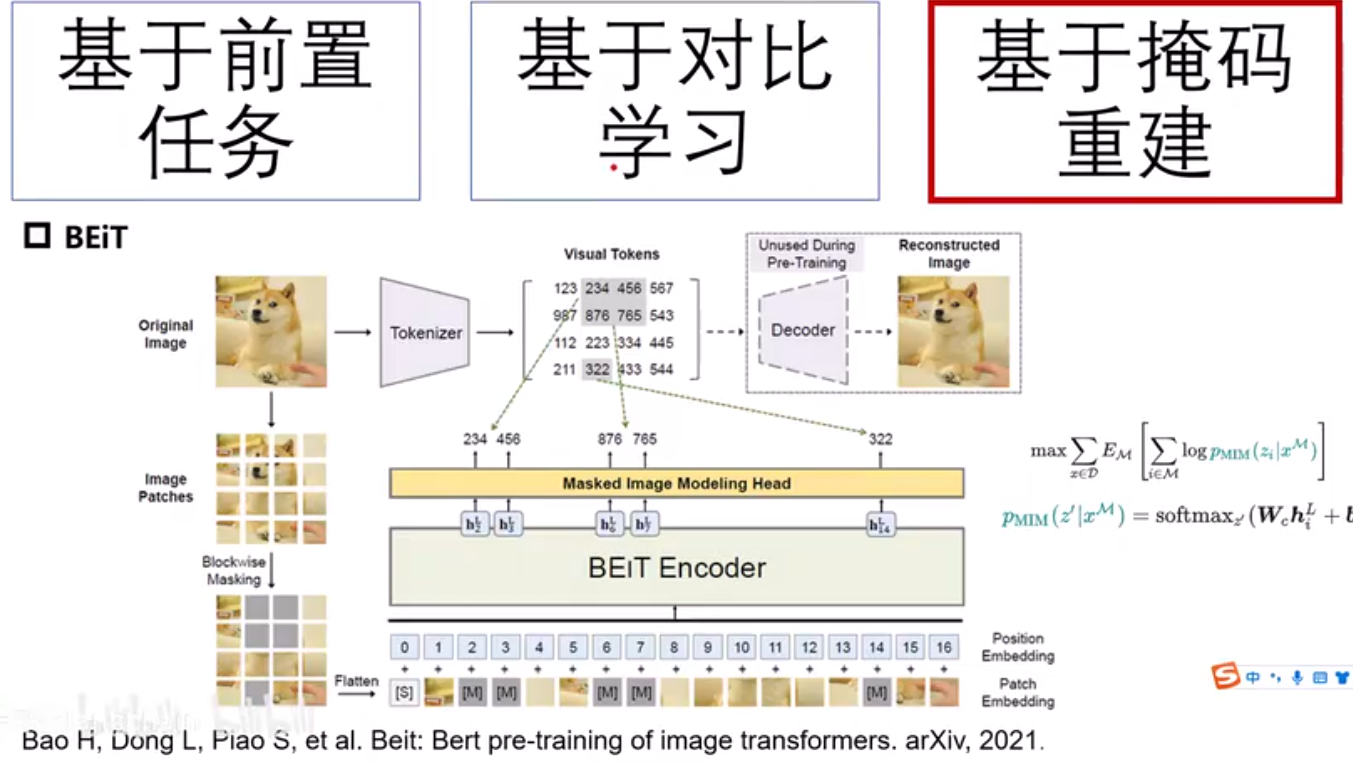
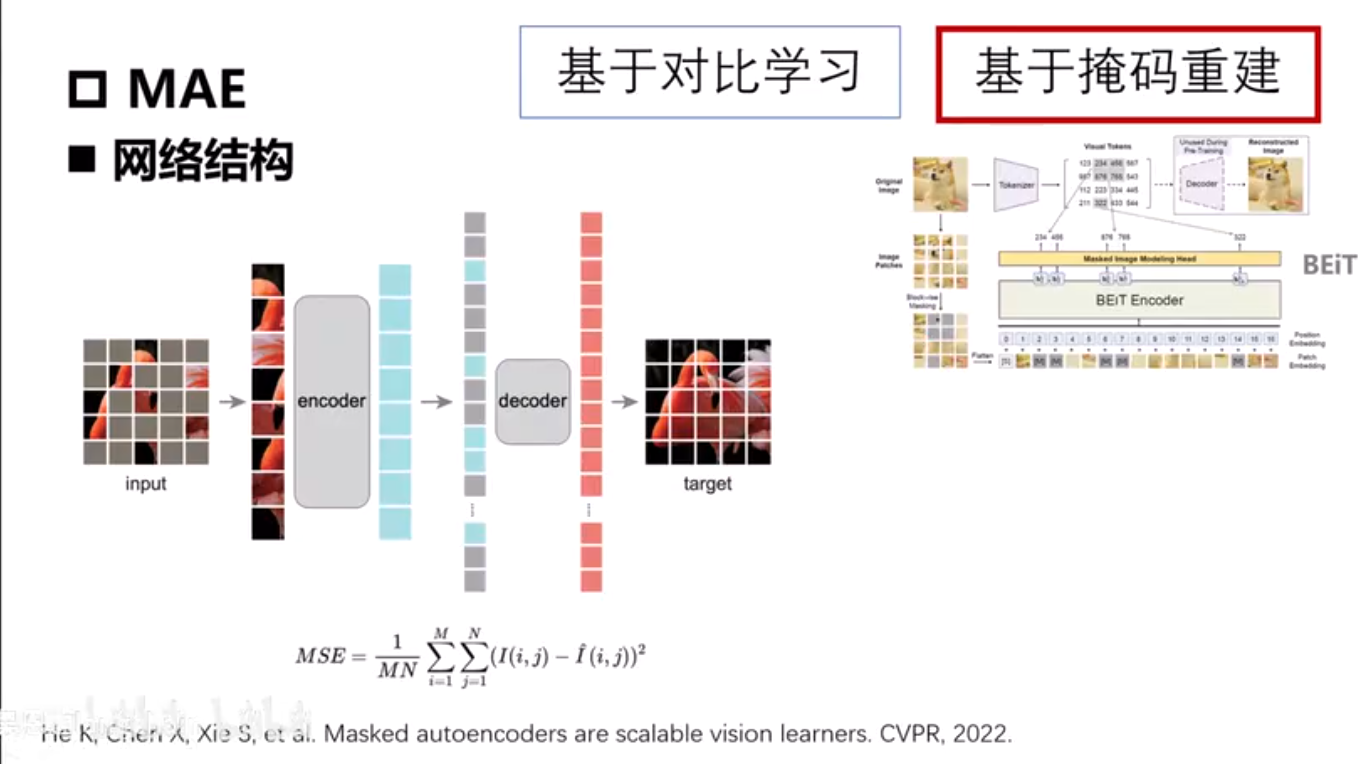
Masked Image Modeling
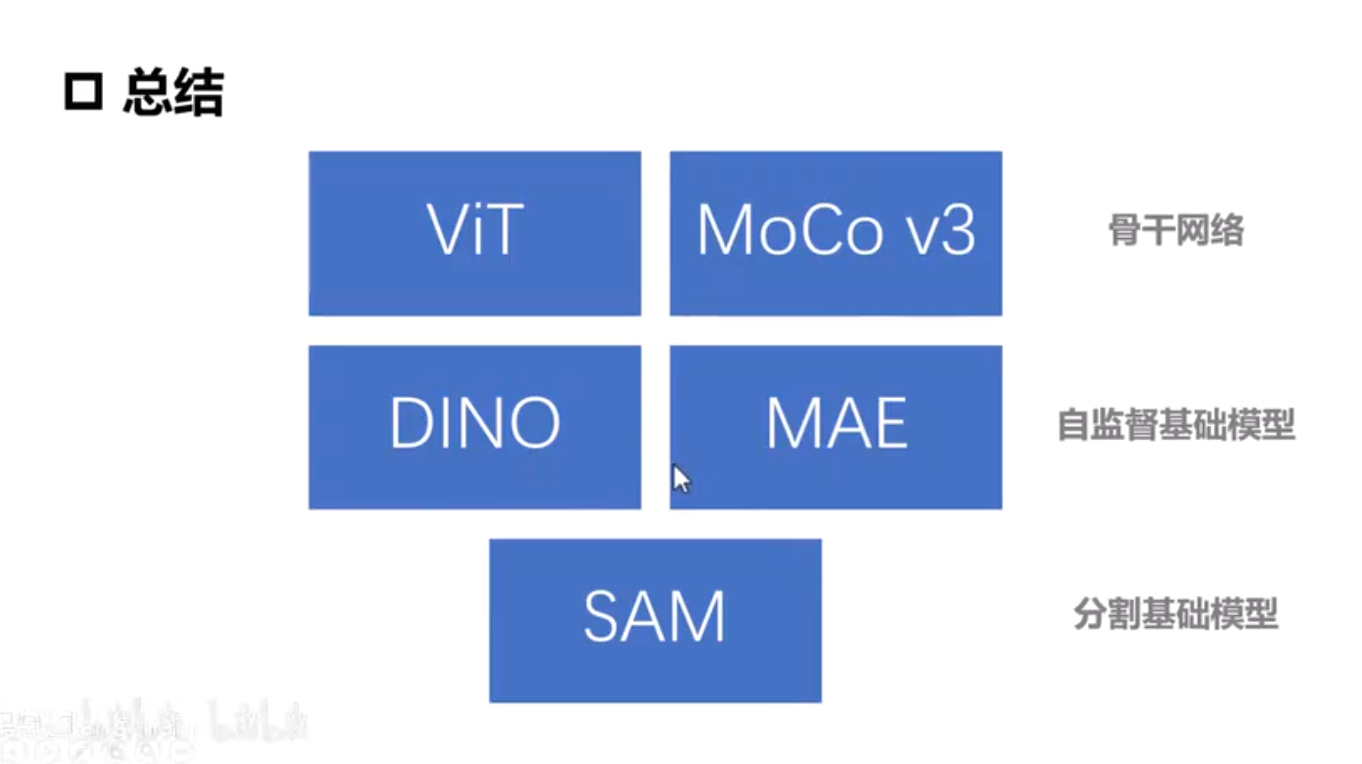
视觉大模型
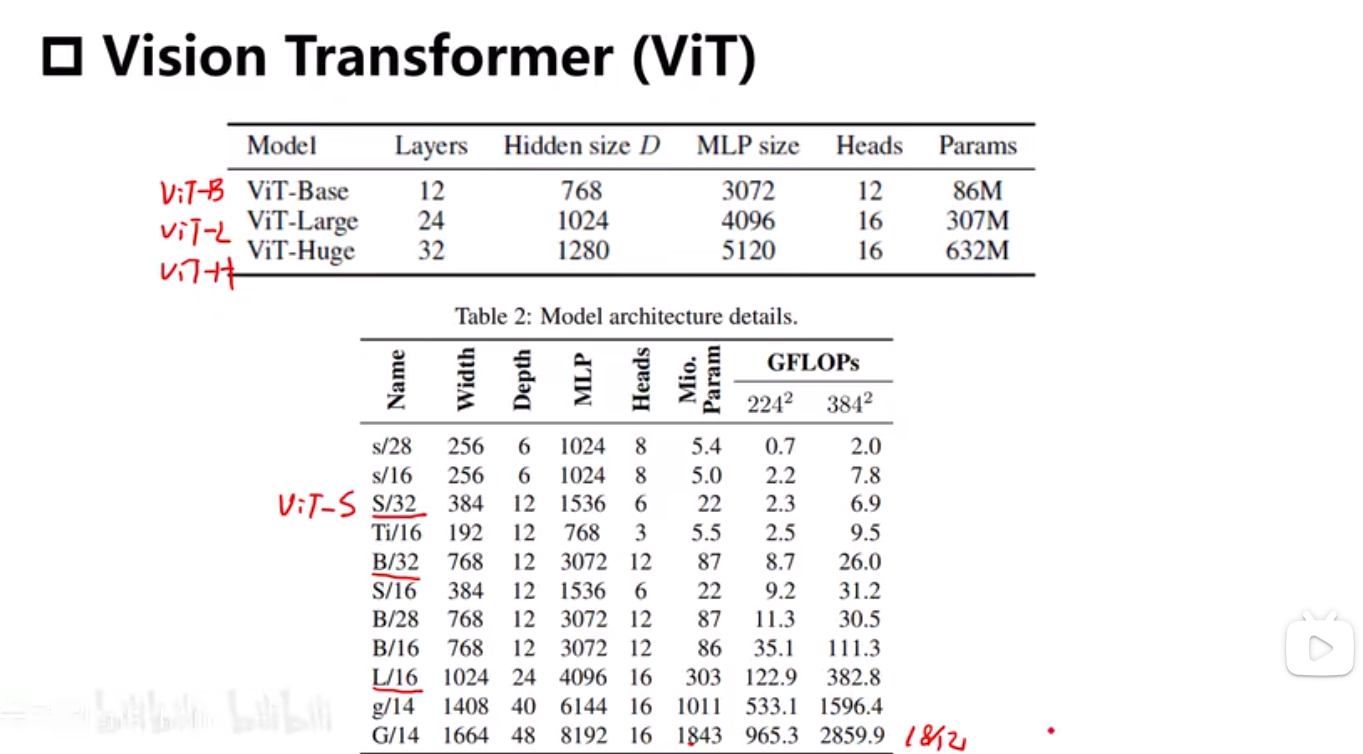
VIT
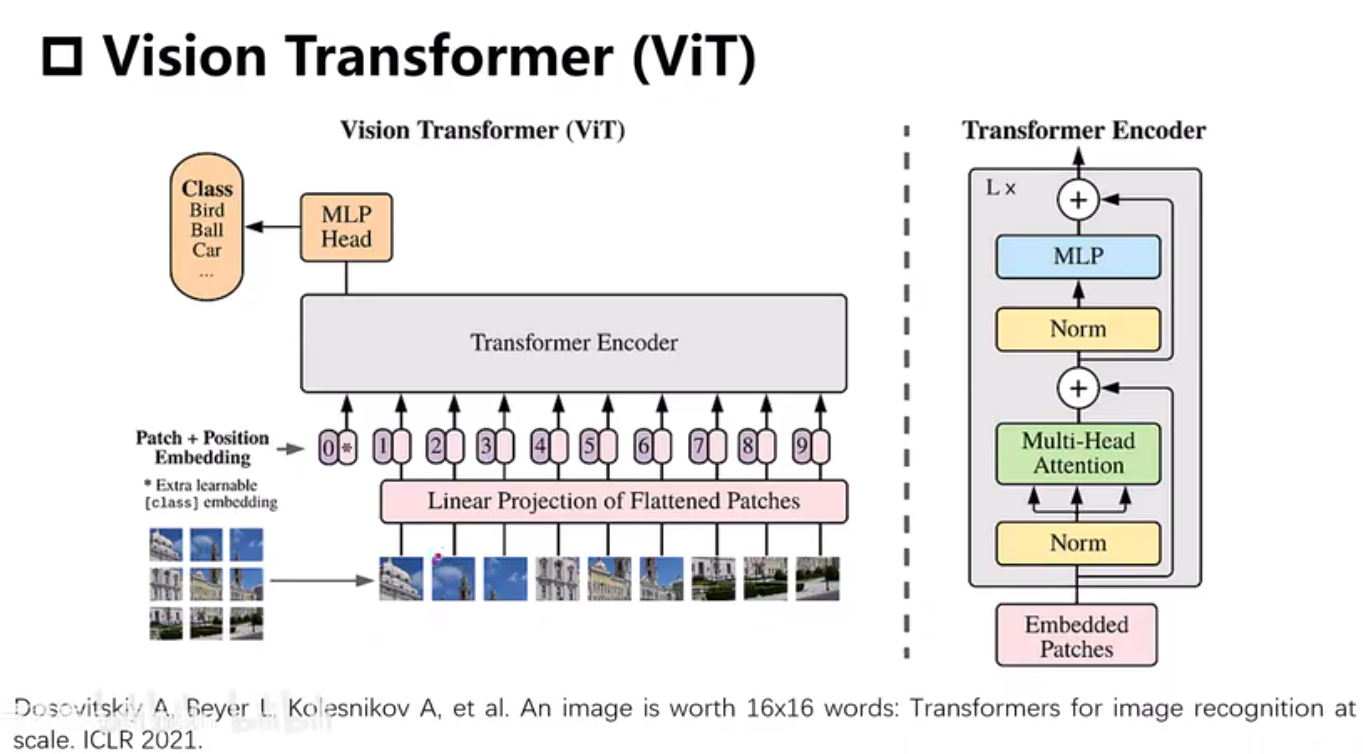
切割patch
q k v 权重
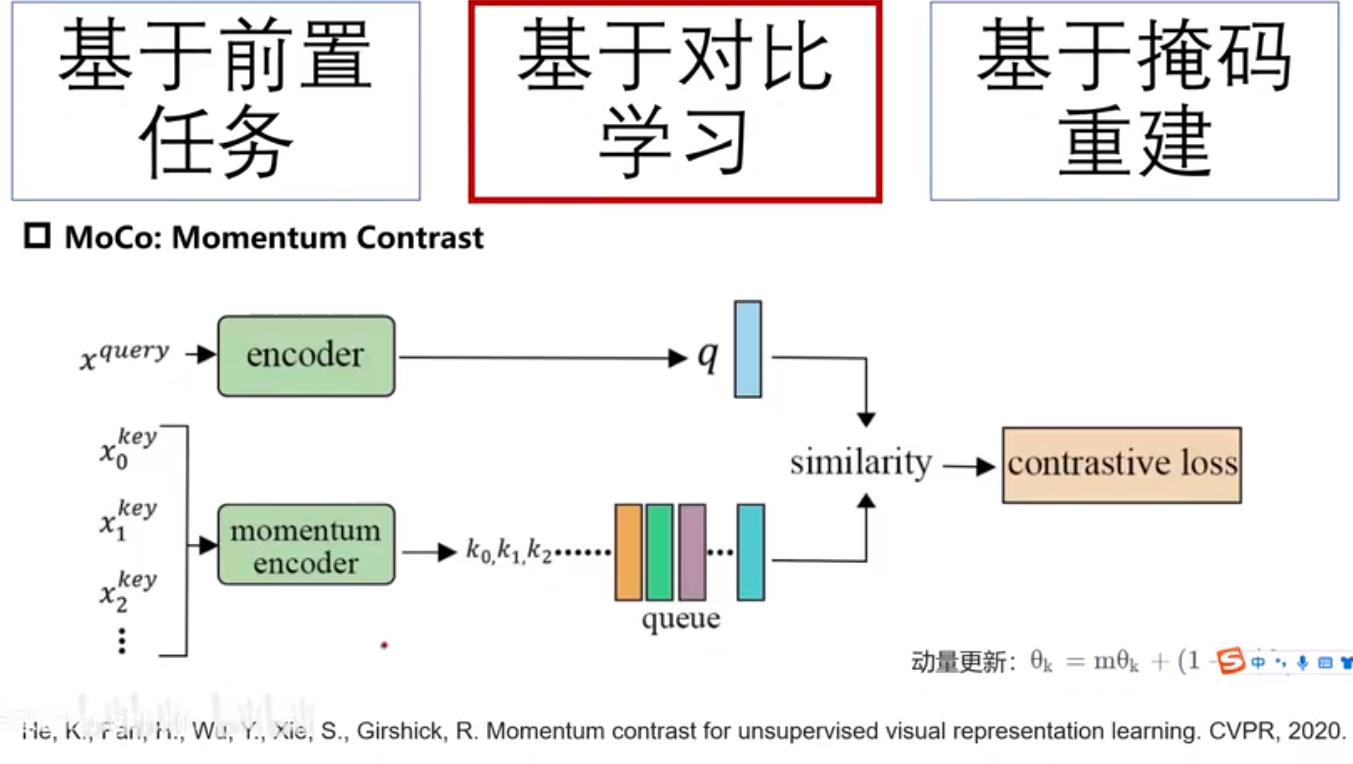
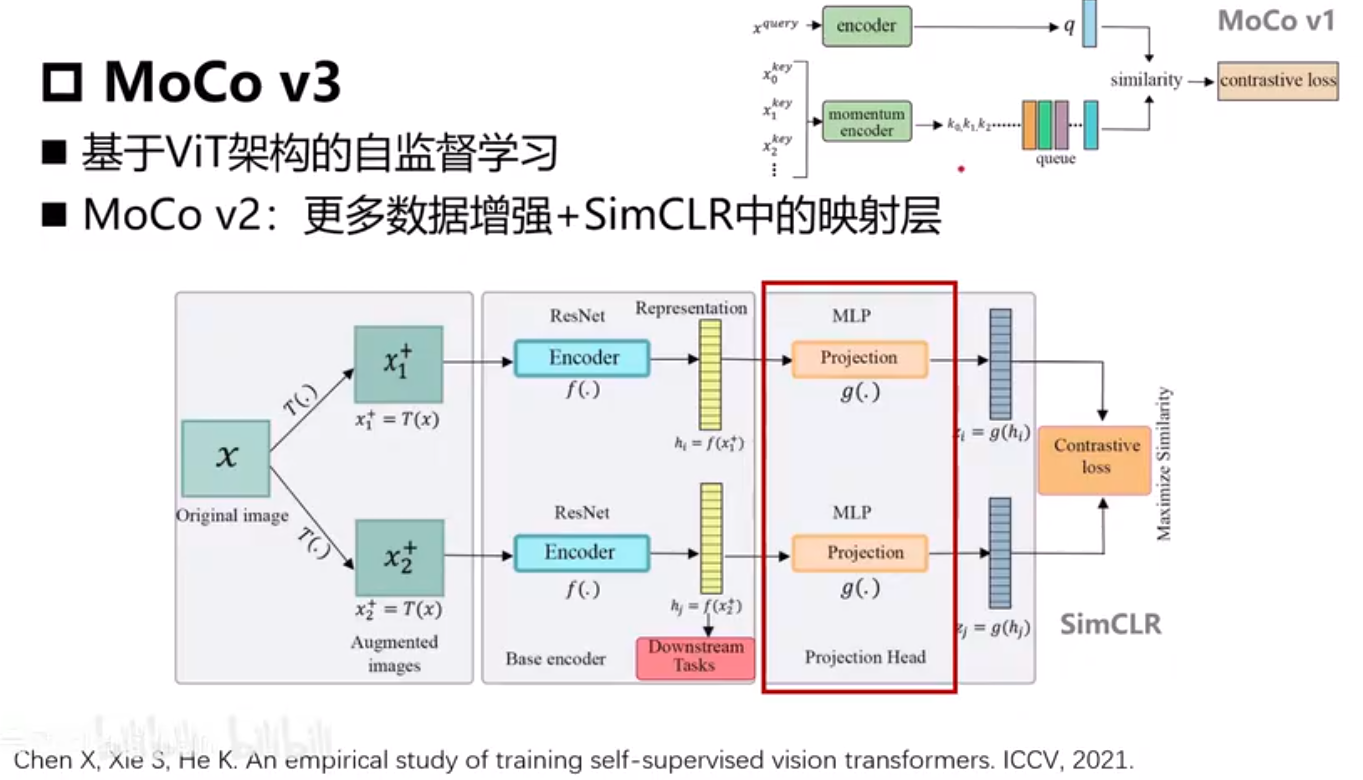
MoCo V3
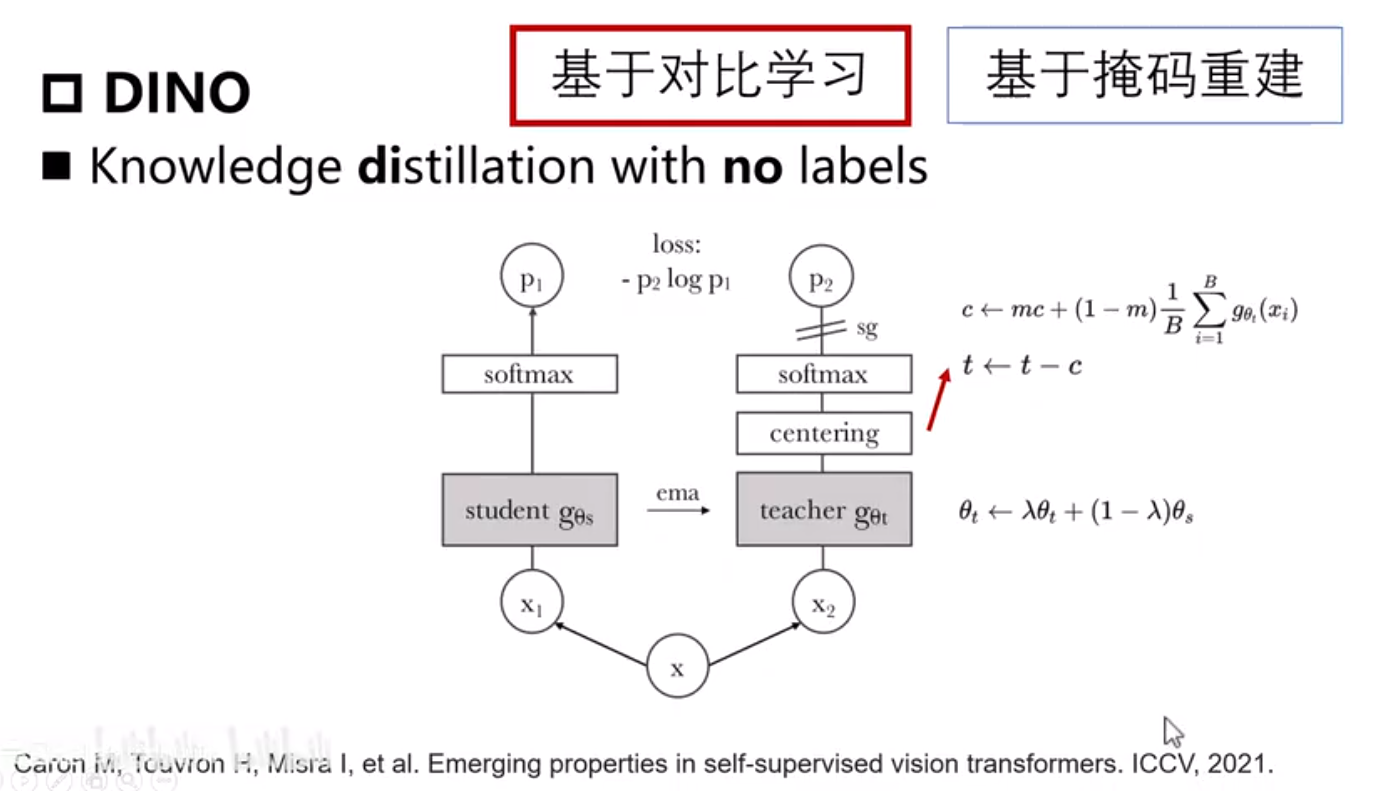
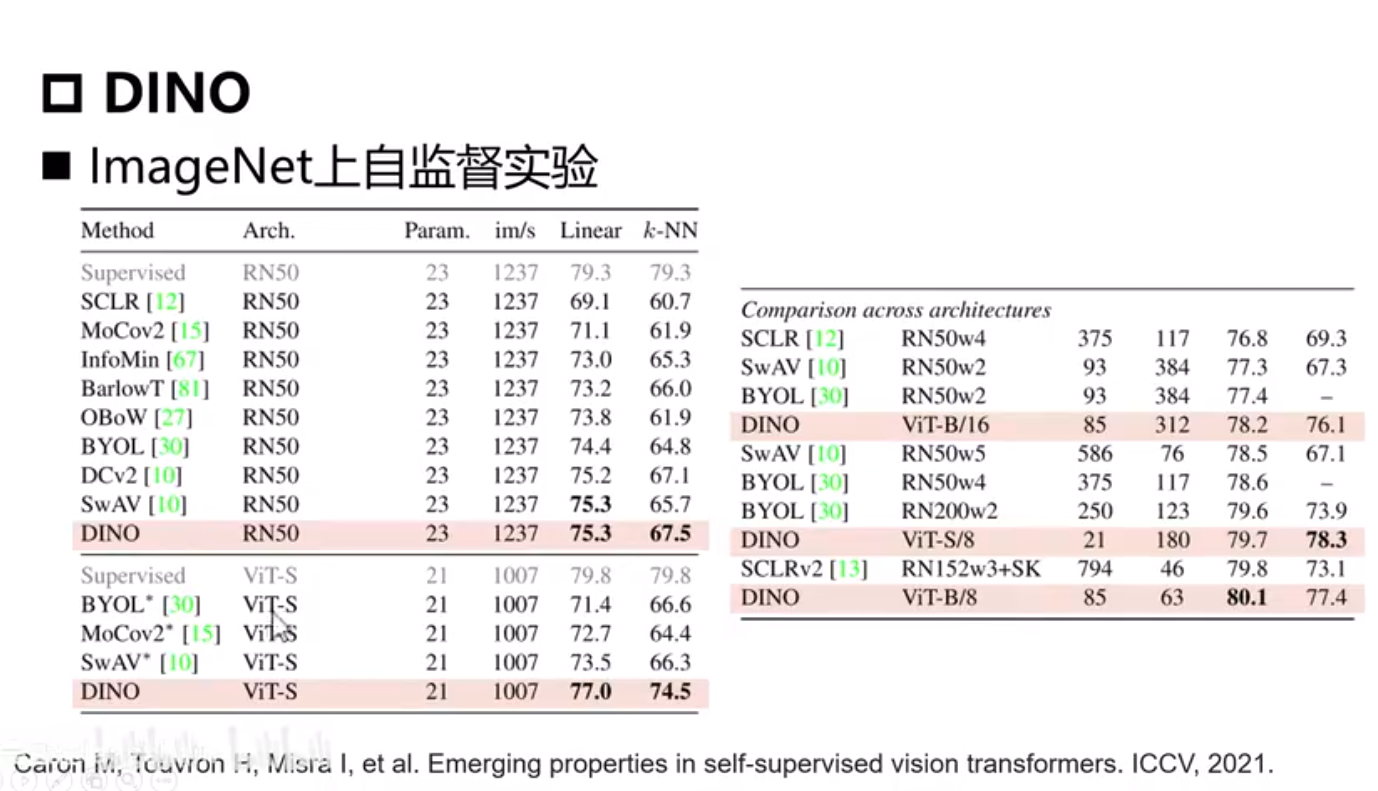
DINO
self distillation
为啥用ema?如果直接将学生网络的参数拷贝到教师网络作为参数,训练过程中很难收敛
直接使用交叉熵损失,未考虑负样本,只需将学生网络学习到的特征接近教师网络。
centering让学习到的特征更有泛华性

最后一层特征层可视化,class token
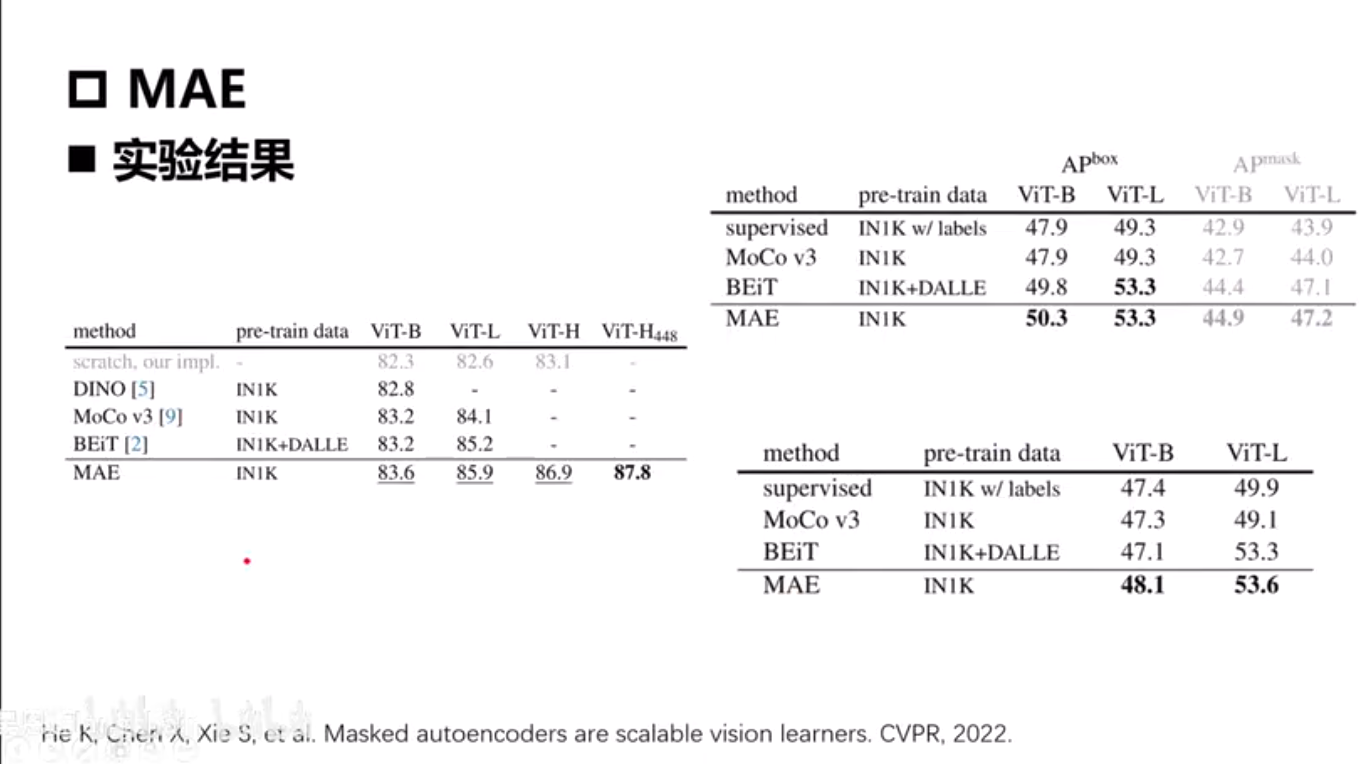
MAE
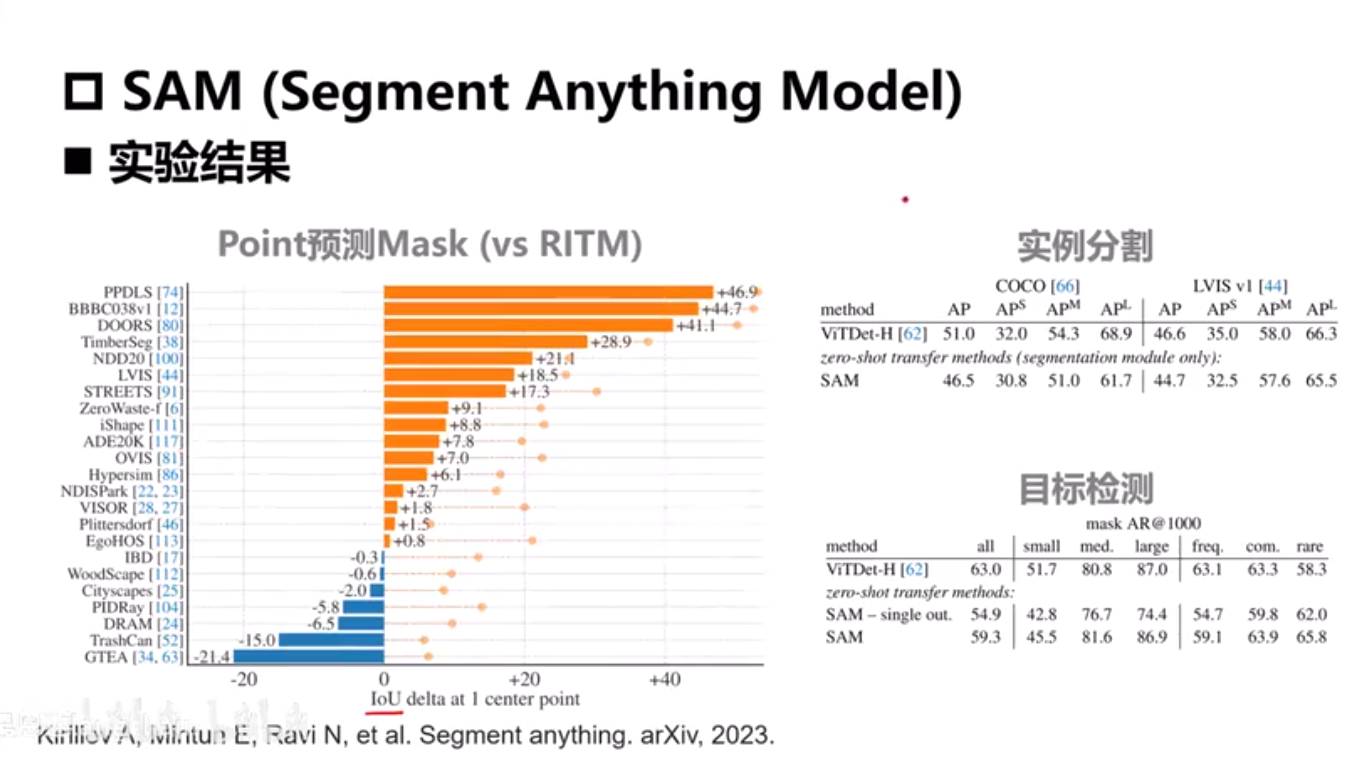
SAM
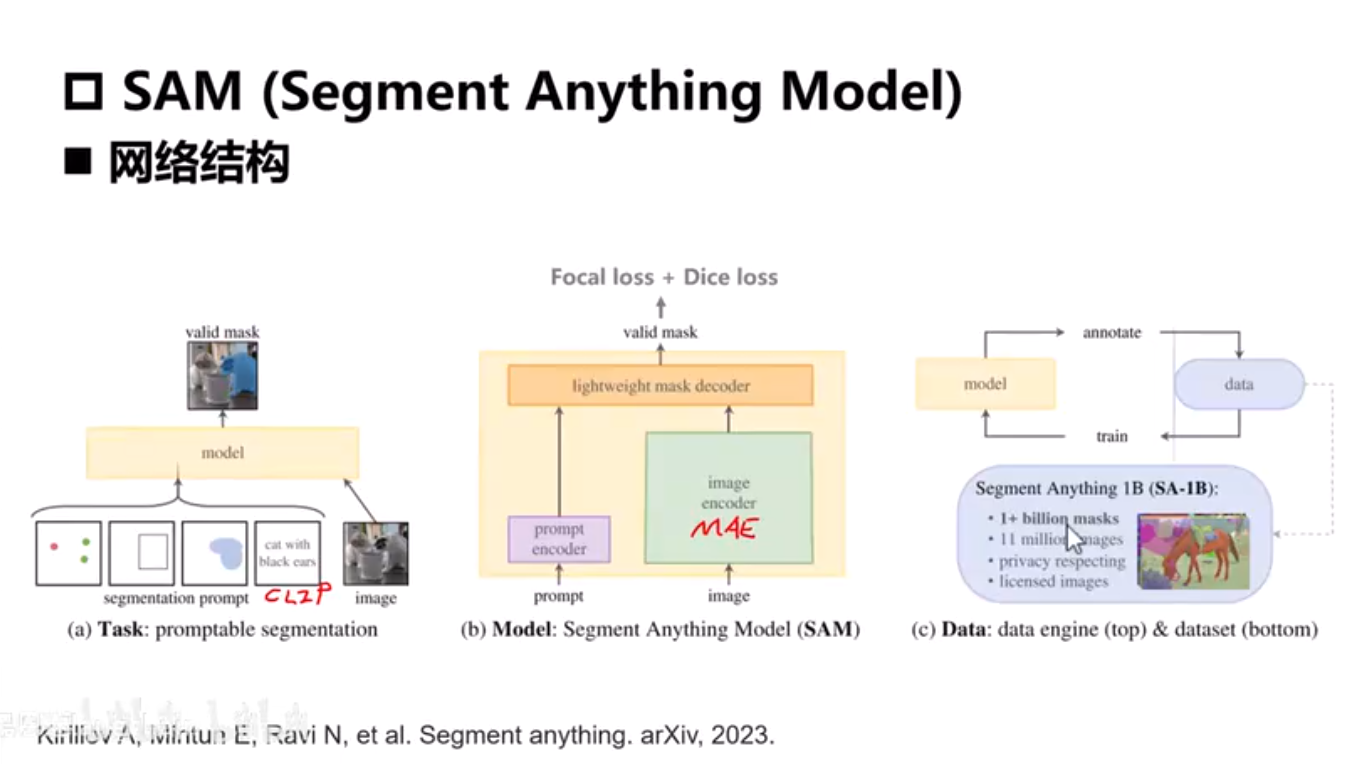
point bbox使用坐标表示,mask使用一个小网络编码,文本-预训练模型CLIP
image encoder - MAE
decoder - MAE 轻量化
多模态视觉

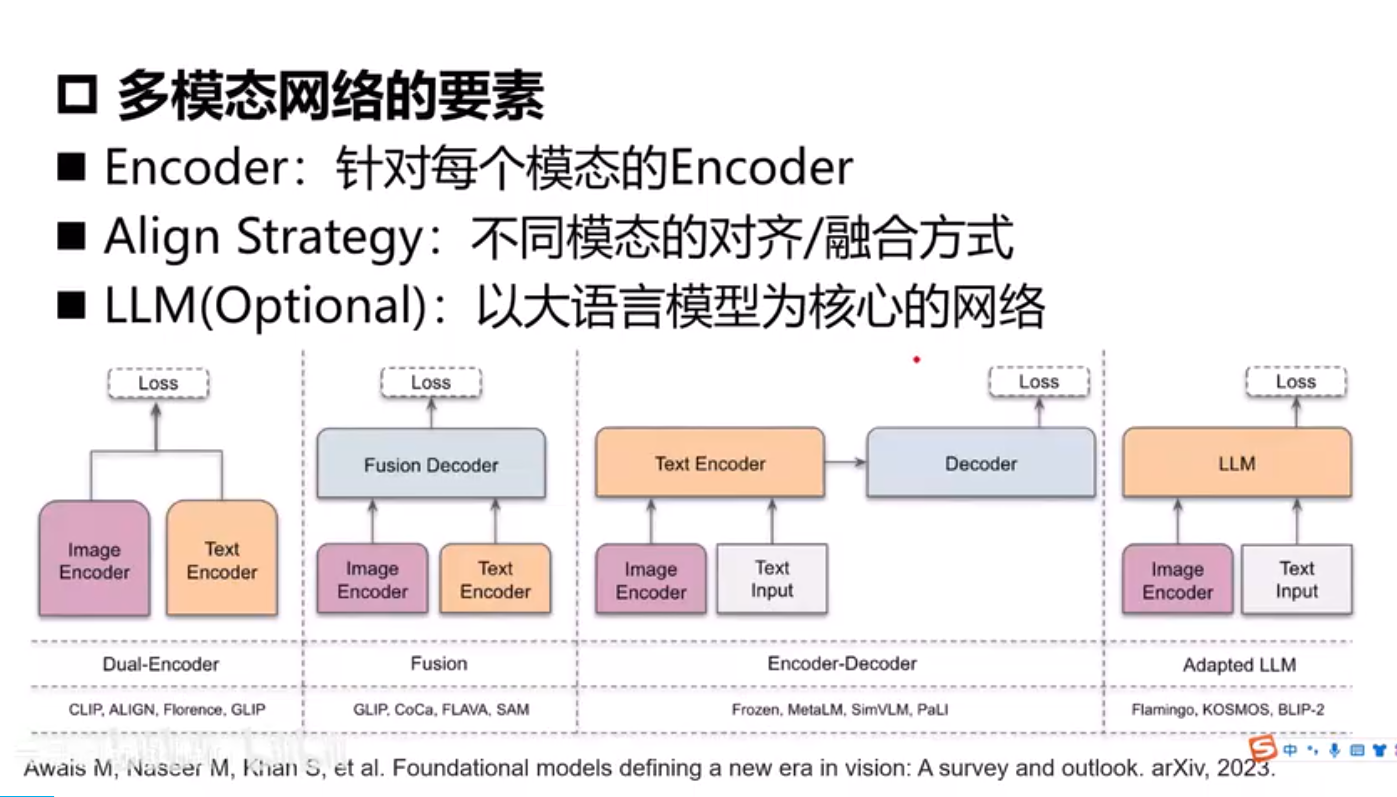
CLIP-分类
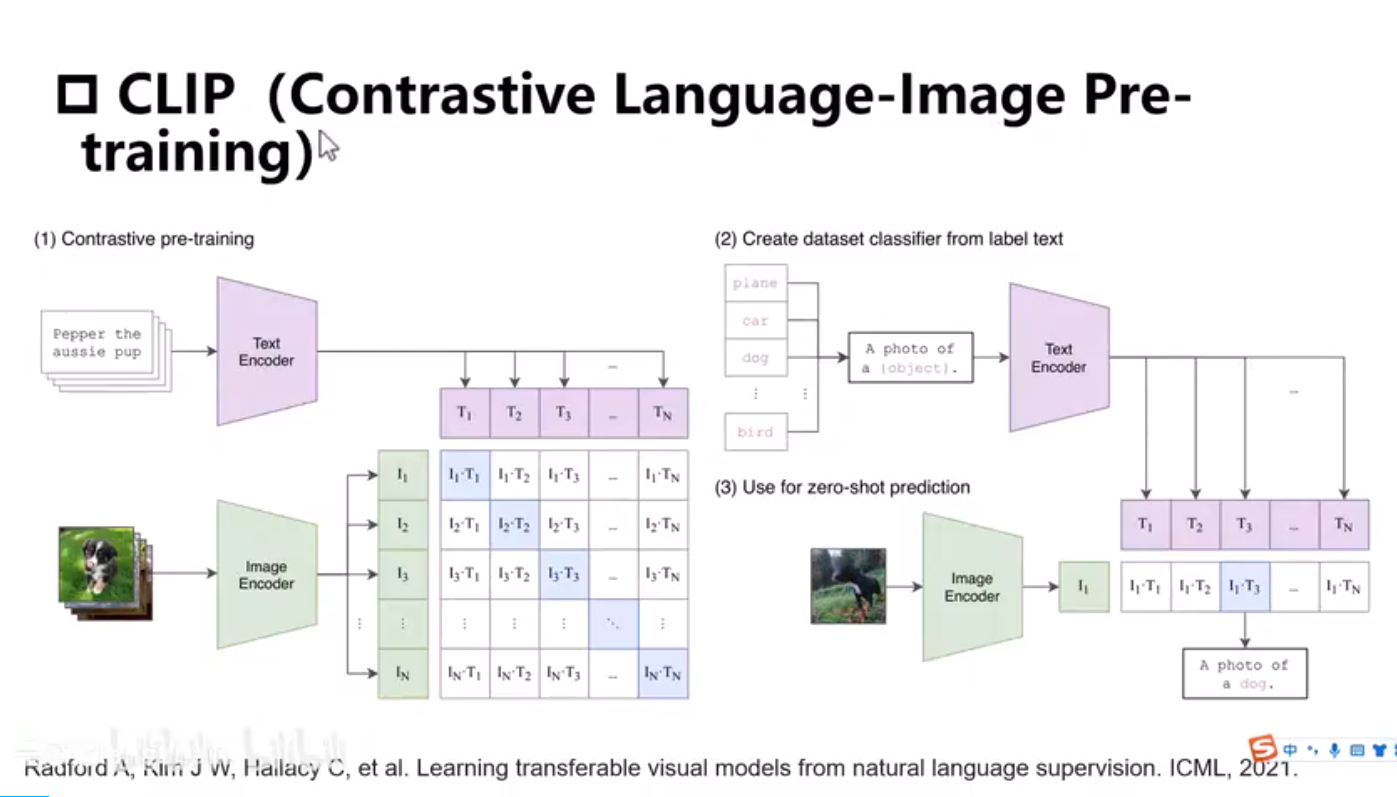
GLIP-目标检测-有监督bbox label
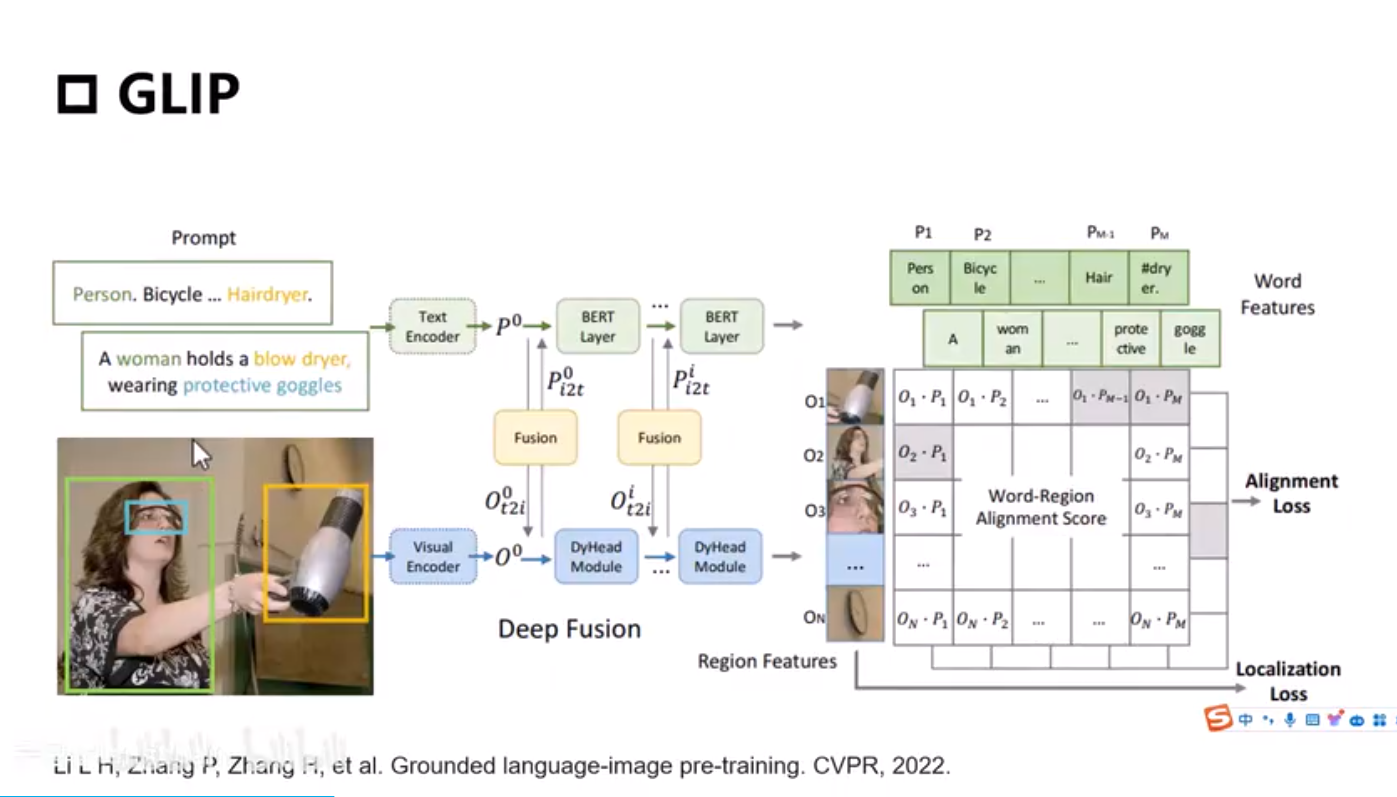
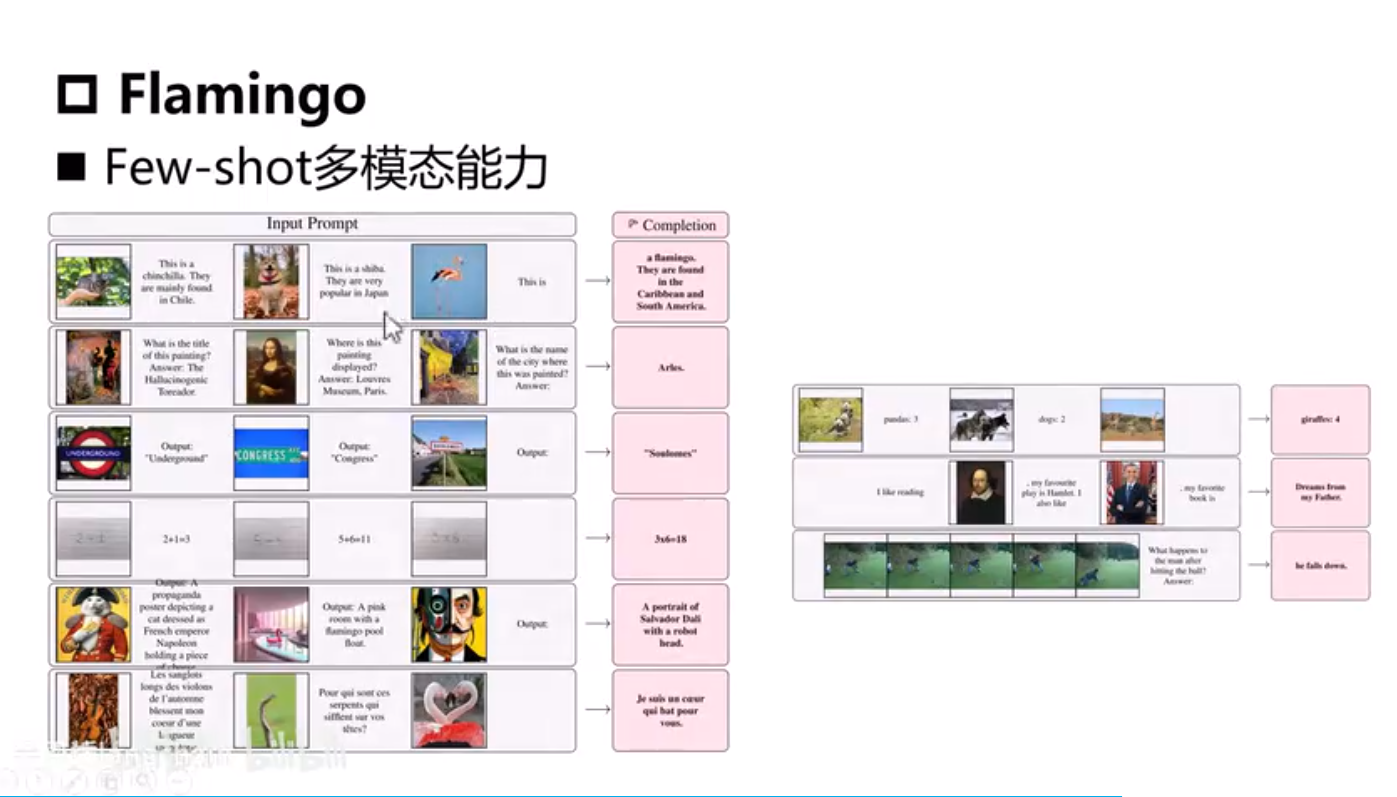
Flamingo
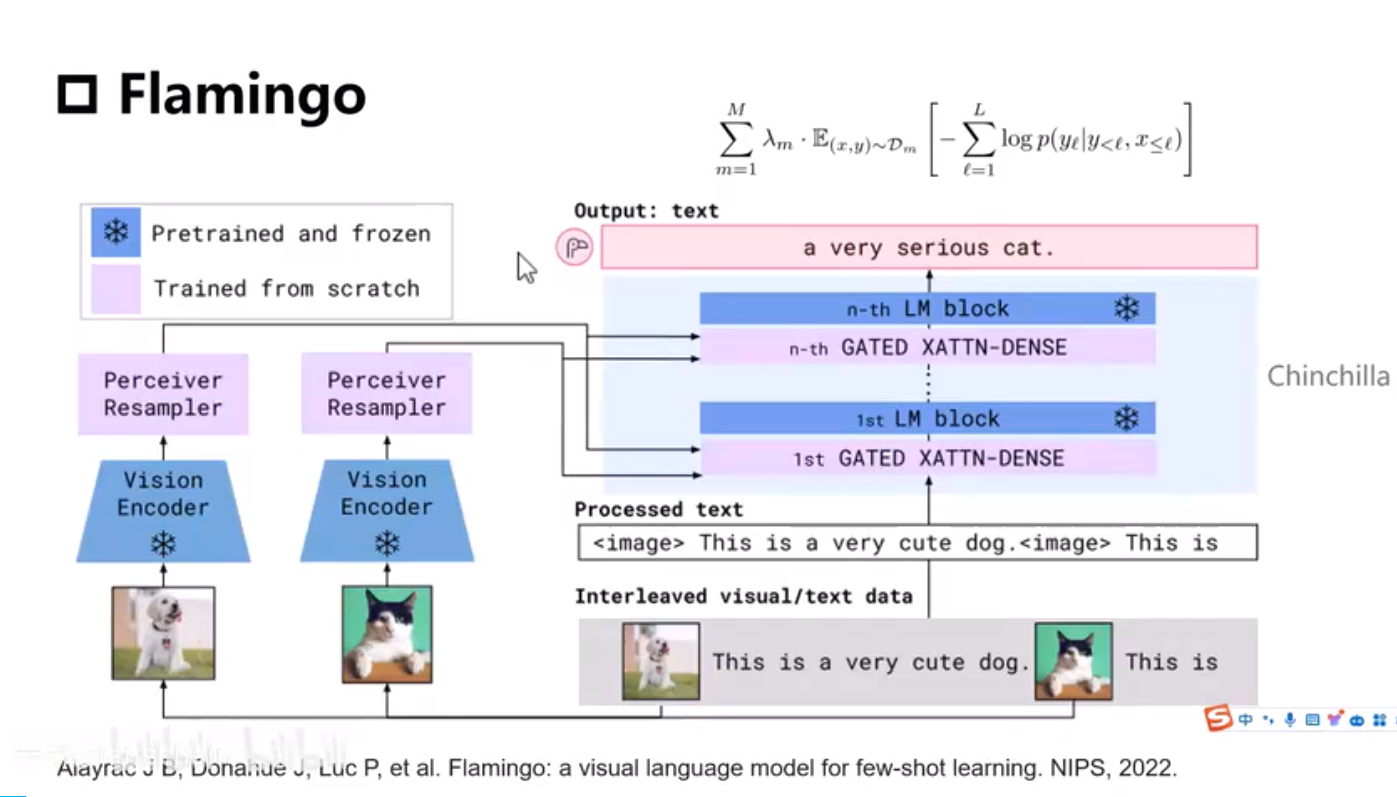
image embedding k and v, text embeddig q
image 10 Billion param, text 70 Billion param

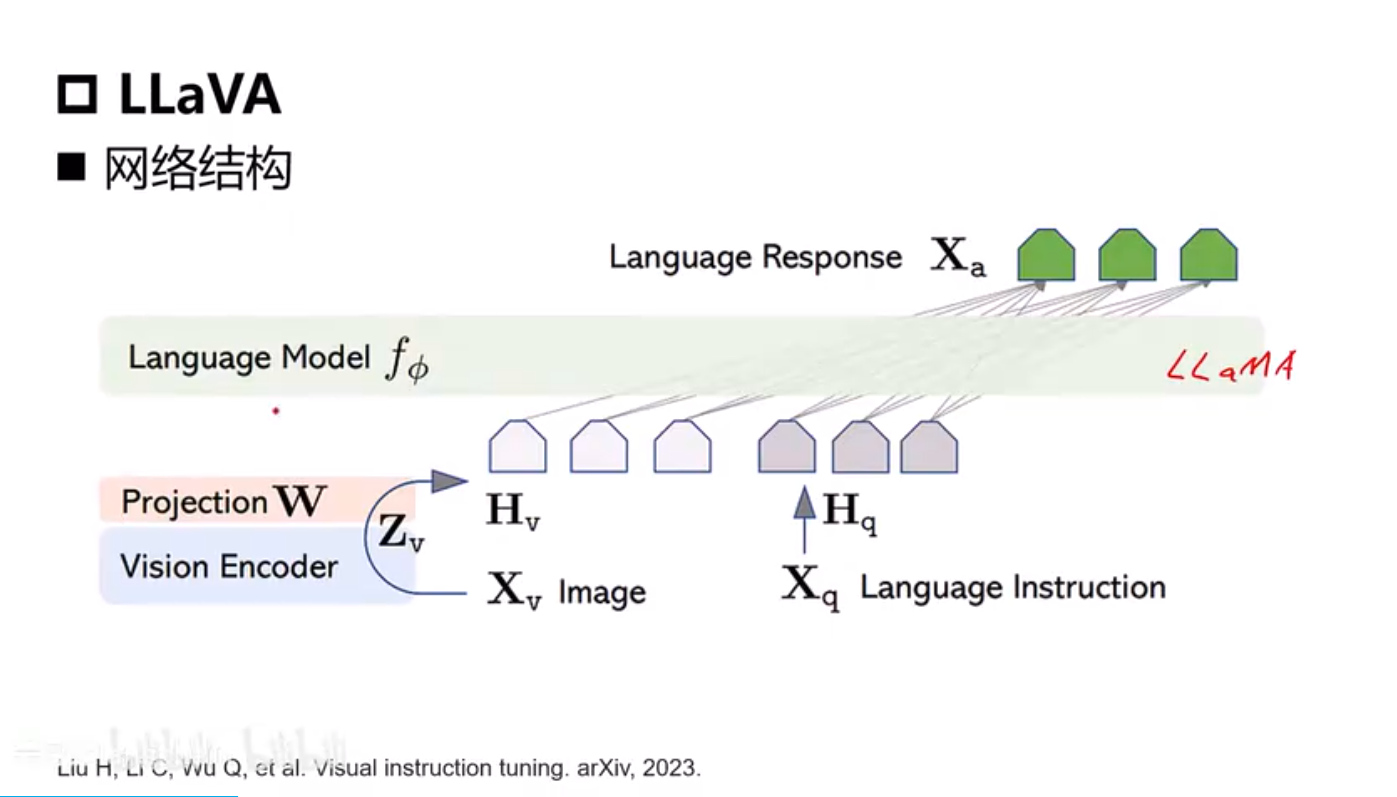
LLaVA
LLaMA
从GPT4语言模型拿多模态数据训练自己的模型

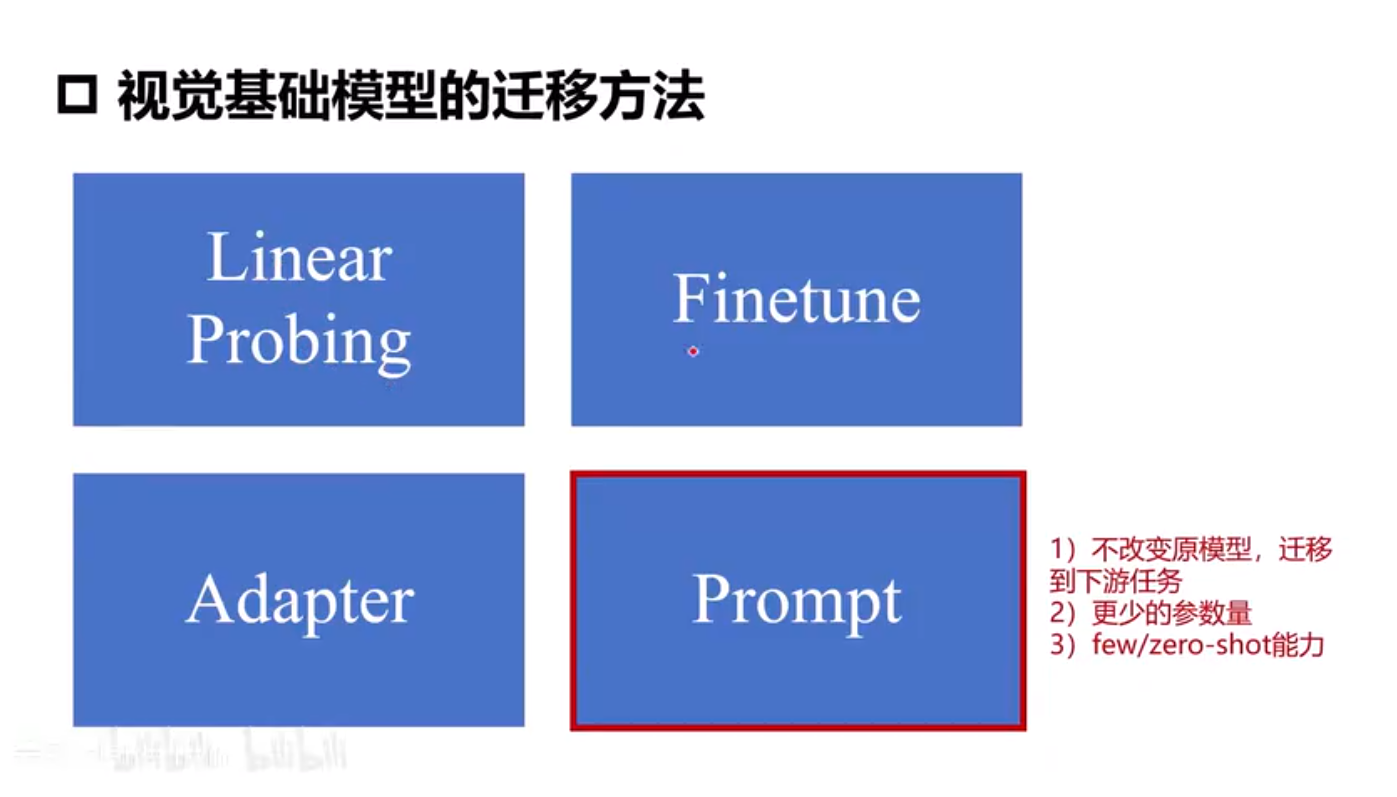
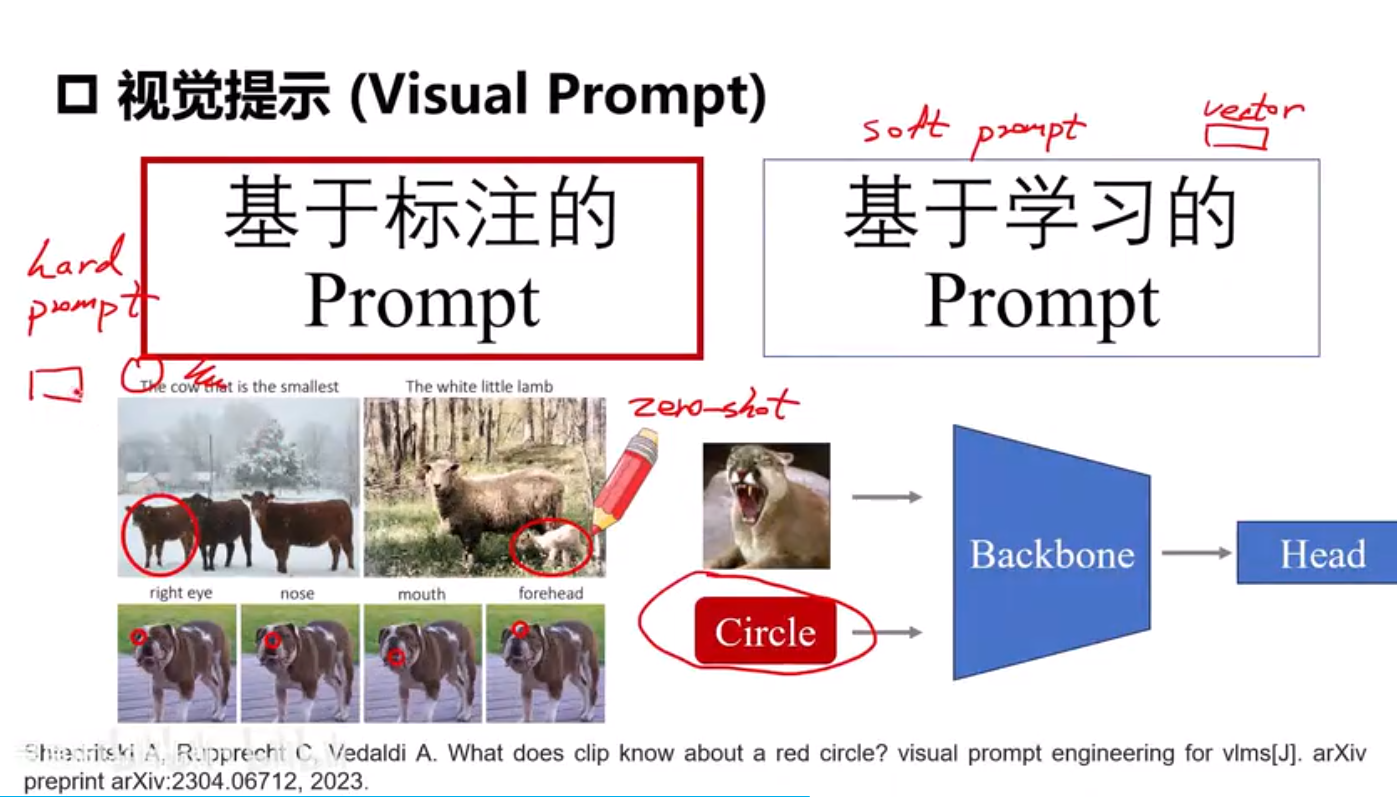
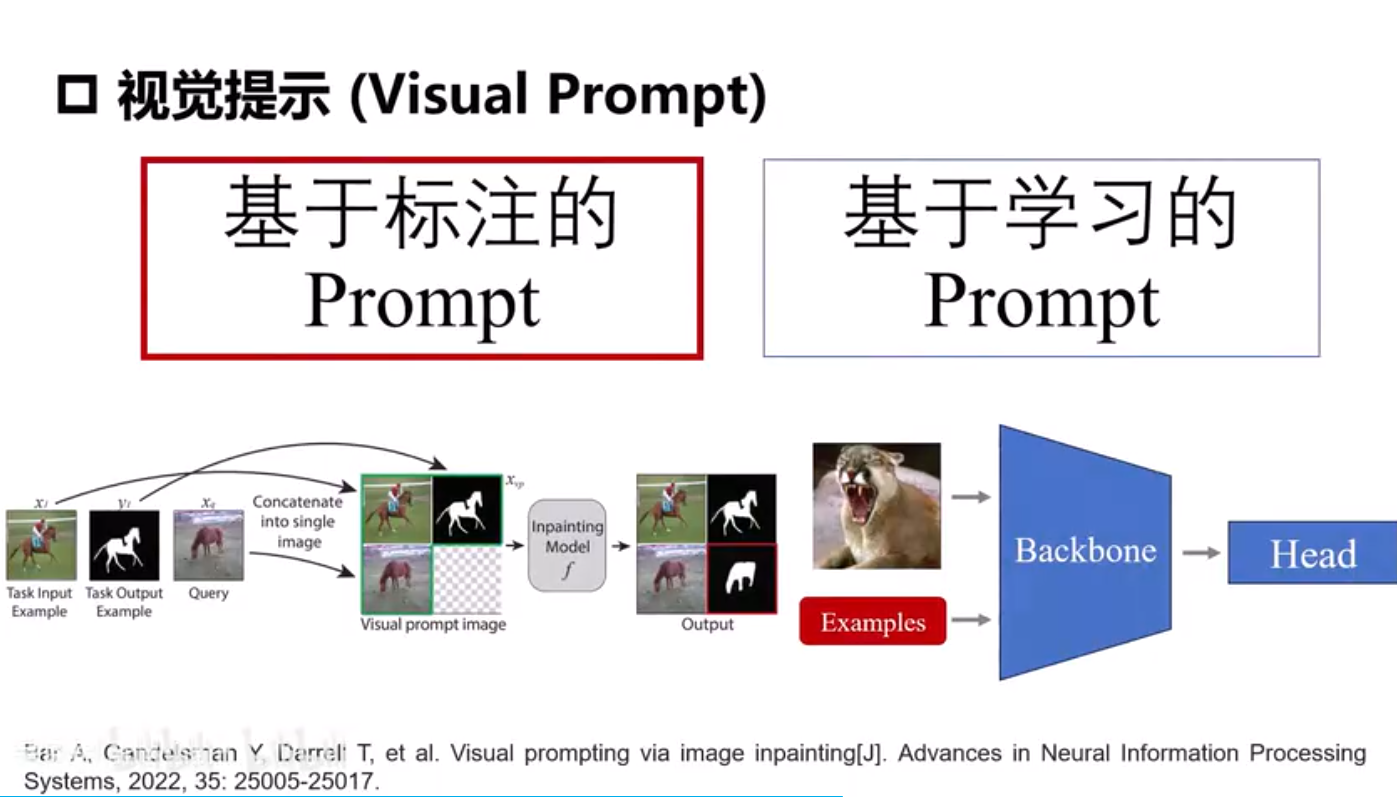
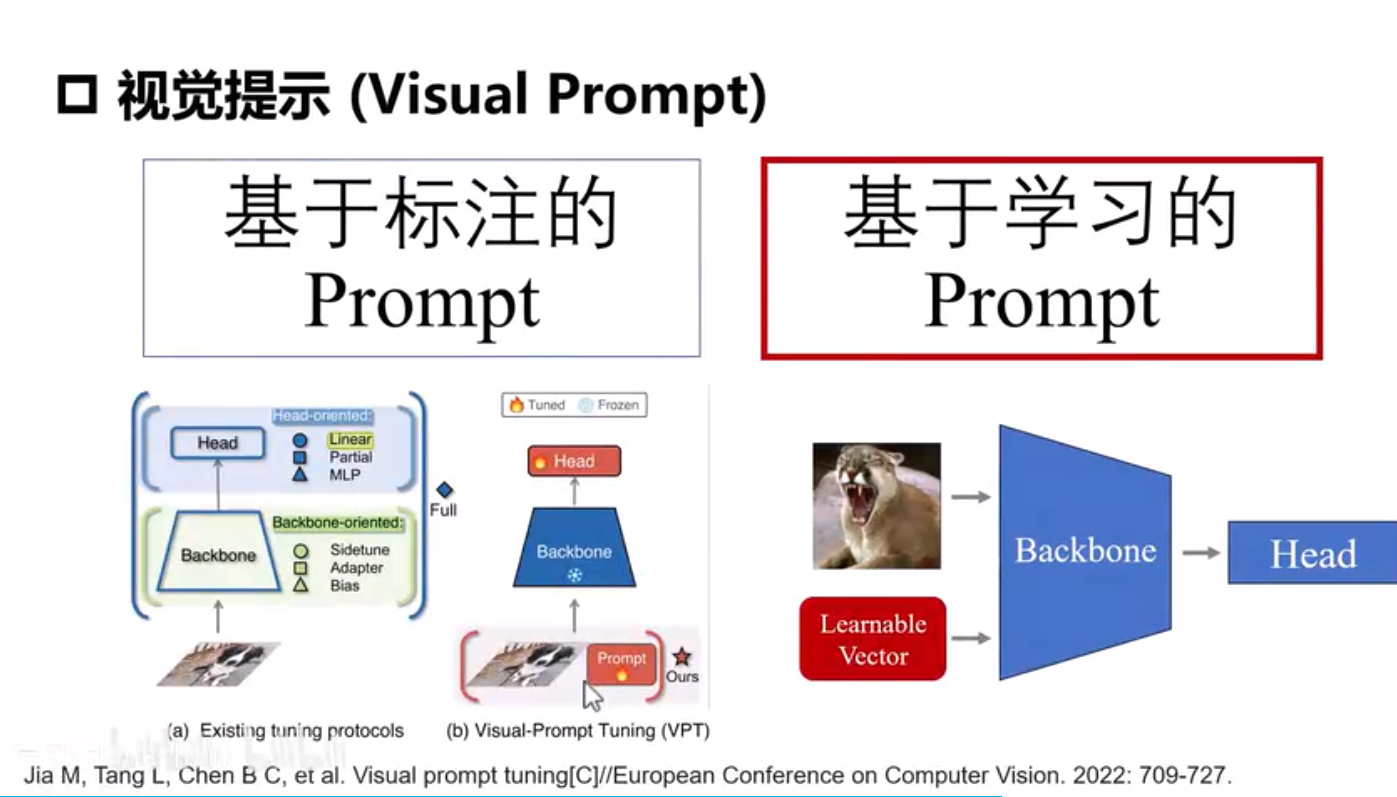
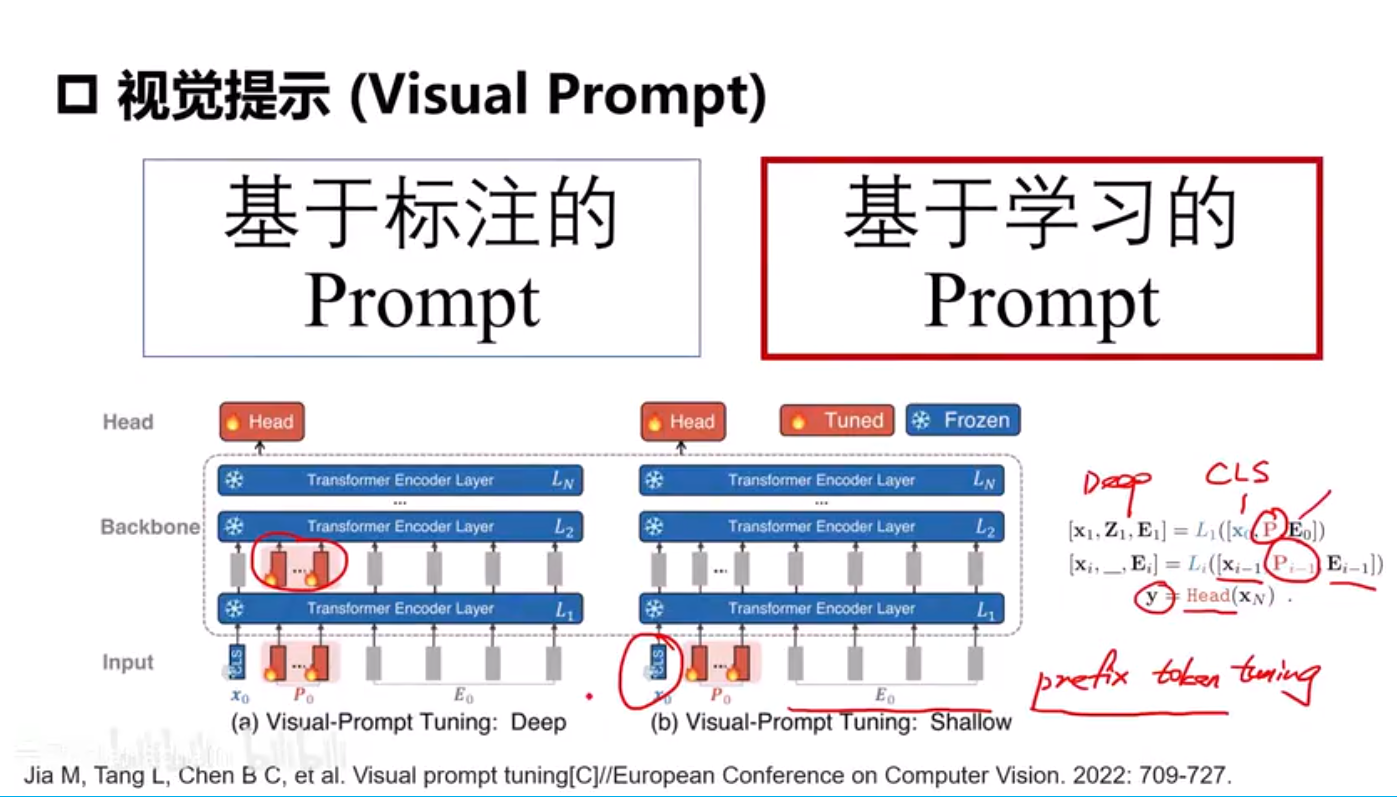
下游任务迁移和视觉提示
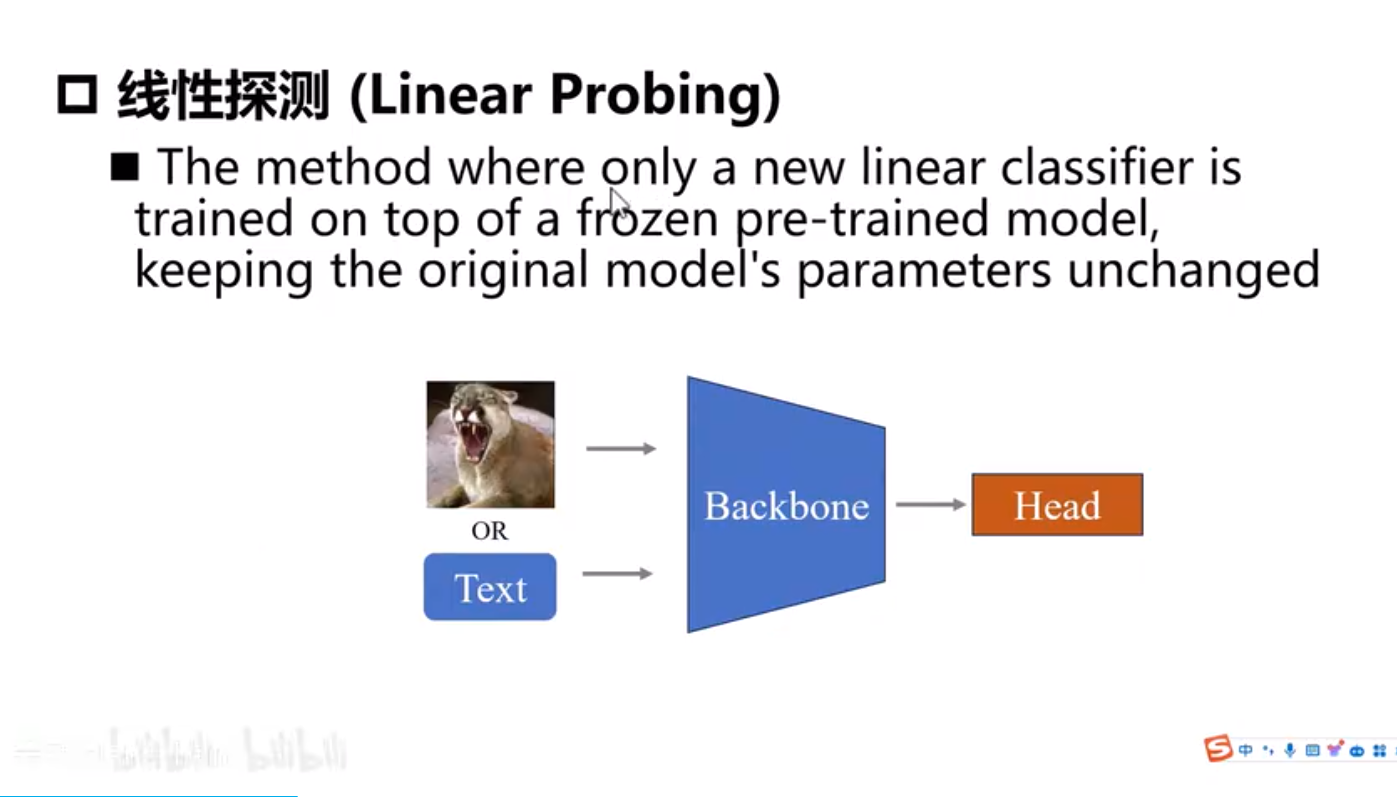
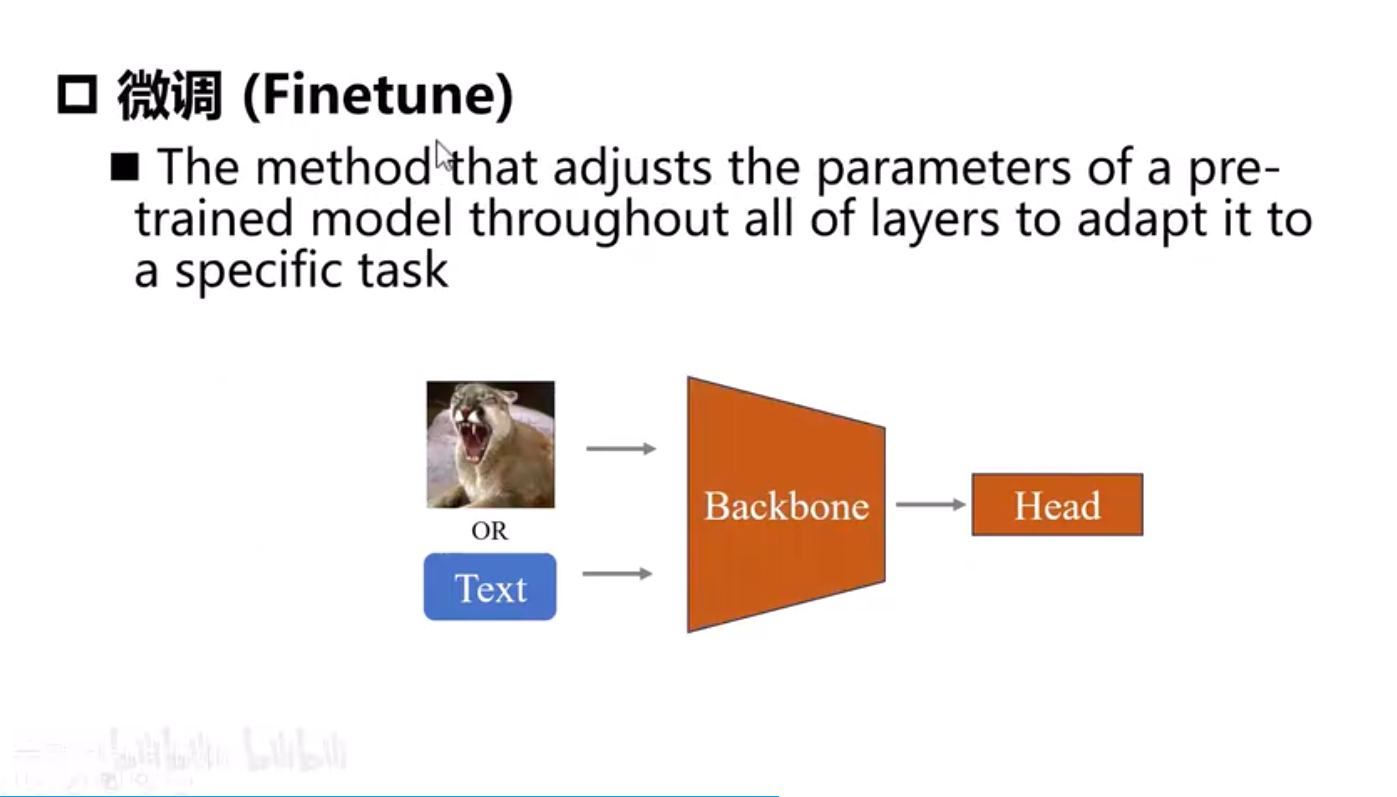
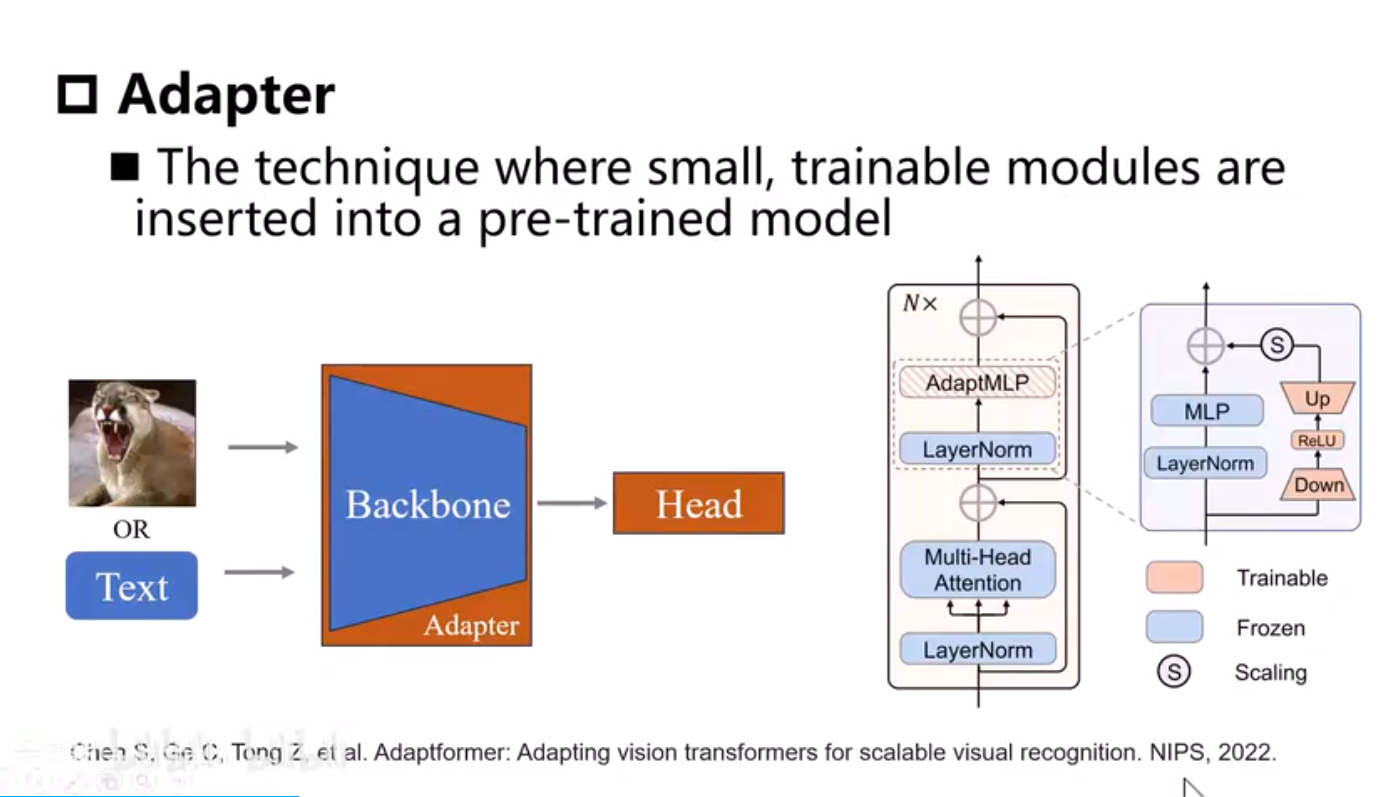
Adapter需要引入新的模块,而且需要训练。



实战迁移PandaGPT
输入图像、文本、音频、视频。
LLaMA --> Vicuna
LoRA
Hugging Face 模型存放
8*A100(40G)batchsize=64,可以将batchsize=4,micro_batchsize=2变小,在单张RTX3090上训练
参考
2.1自监督学习与前置任务_哔哩哔哩_bilibili2.1自监督学习与前置任务是AI视觉大模型教程(LLM+多模态+SAM+视觉Prompt+CV+学习路线图)从入门到实战简直配享太庙!的第2集视频,该合集共计40集,视频收藏或关注UP主,及时了解更多相关视频内容。![]() https://www.bilibili.com/video/BV1hwLEzZEnS?spm_id_from=333.788.player.switch&vd_source=d31e5014a01dd0e66e50092730d3cc5c&p=2
https://www.bilibili.com/video/BV1hwLEzZEnS?spm_id_from=333.788.player.switch&vd_source=d31e5014a01dd0e66e50092730d3cc5c&p=2
myCobot 320 机械臂 教育
基于3D视觉的水果分拣_哔哩哔哩_bilibili 遨博机械臂应用案例
copilot 自动补全
服务器上运行demo结果URL,在本地上看,端口映射
![]()

大象机器人mycobot 280 pi 6轴 吸泵 摄像头 8000元 上位机主控板树莓派4B ubuntu20.04
AppBuilder-SDK语音识别 输入麦克风录制好的wav音频文件输出文字,然后把文字输入给Agent智能体(大语言模型,文心一言、kimi、chat、cloud3)paddlespeech-tts语音合成算法
大语言模型API调用
抓取物体:机械变成俯视姿态,拍摄一张图,俯视姿态用nvidia机器人仿真软件lsaac sim试出来的,发送给多模态大模型
视觉语言多模态大模型 零一万物 通义千问