LFU算法及优化
继上一篇的LRU算法的实现和讲解,这一篇来讲述LFU
最近使用频率高的数据很大概率将会再次被使用,而最近使用频率低的数据,将来大概率不会再使用。
做法:把使用频率最小的数据置换出去。这种算法更多是从使用频率的角度(但是当缓存满时,如果最低访问频次的缓存数据有多个,就需要考虑哪个元素最近最久未被访问)去考虑的。
基本算法描述
- LRU 是根据时间维度来选择将要淘汰的元素,即删除掉最长时间没被访问的元素。
- LFU 是根据频数和时间维度来选择将要淘汰的元素,即首选删除访问频数最低的元素。如果两个元素的访问频数相同,则淘汰最久没被访问的元素。
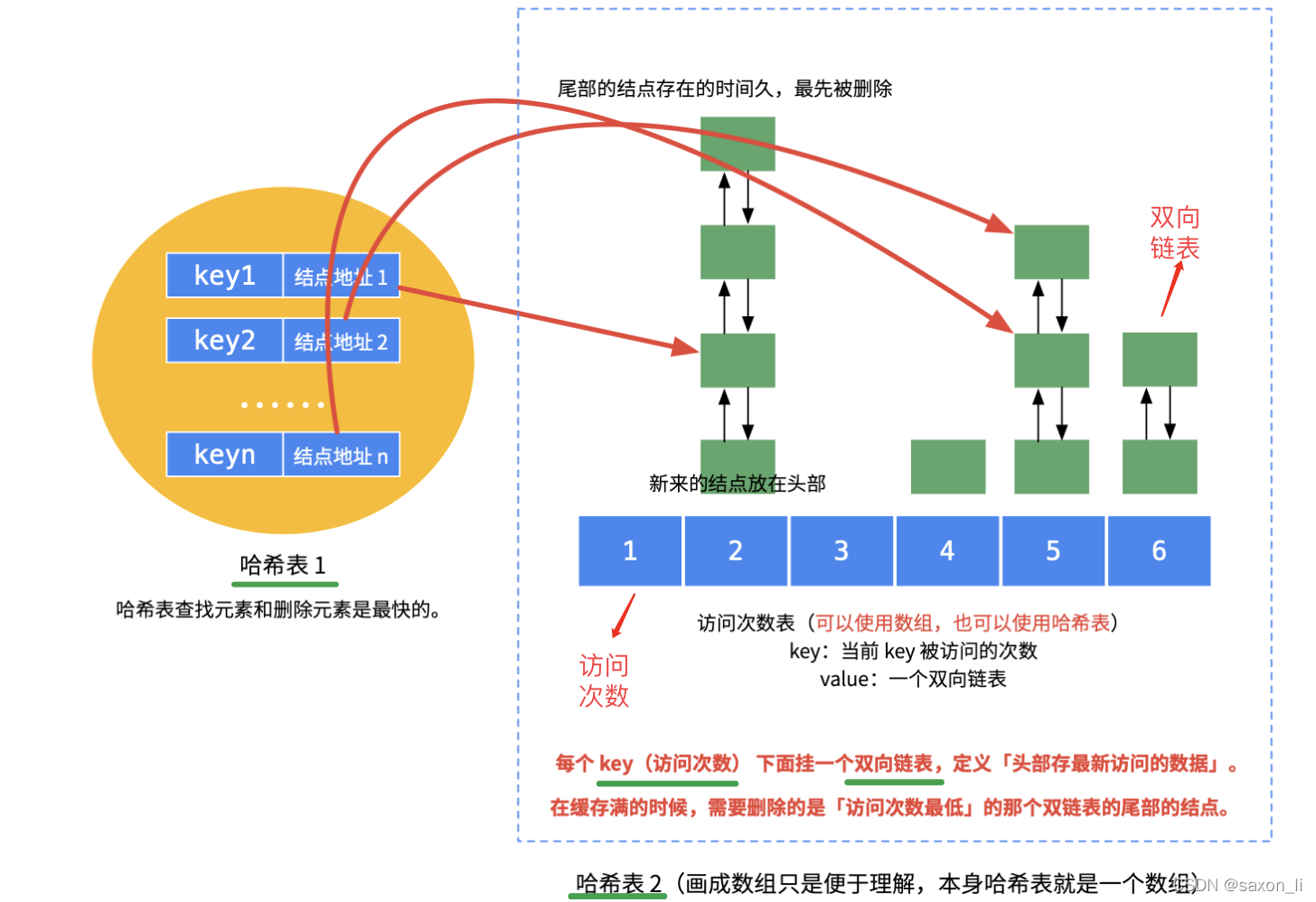
就是说LFU淘汰的时候会选择两个维度,先比较频数,选择访问频率最小的元素;如果频率相同,则按时间维度淘汰掉最久远的那个元素。LRU的实现是 1 个哈希表加上 1 个双链表,与LRU类似,想要完成上述条件,LFU 仍需要结合哈希表和双向链表这两个结构进行操作,不过需要用 2 个哈希表再加上 N 个双链表才能实现先按照频数再按照时间两个纬度的淘汰策略,具体 LFU 数据结构参考下图。
算法实现
基础版
unordered_map<int,Node *> hashNode;unordered_map<int,FreqList *> hashFreq;- 哈希表 1:hashNode,节点哈希表,用于快速获取数据中 key 对应的节点信息
- 哈希表 2:hashFreq,频数双向链表哈希表,为每个访问频数 freq 构造一个双向链表 freqList,并且用哈希表联系二者关系以快速定位
#include <unordered_map>
using namespace std;/*** LFU (Least Frequently Used) 缓存实现* 核心思想:当缓存满时,优先淘汰访问频率最低的数据;* 若存在多个频率相同的数据,则淘汰其中最久未使用的数据*/
class LFUCache {
private:// 双向链表节点结构struct Node{int key; // 键值int value; // 存储的值int freq; // 访问频率:记录该节点被访问的次数Node *pre; // 前驱指针:指向链表中的前一个节点Node *next; // 后继指针:指向链表中的后一个节点// 节点构造函数Node(int key,int value,int freq){this->key = key;this->value = value;this->freq = freq;pre = nullptr; // 初始化为空指针next = nullptr; // 初始化为空指针}};// 频率链表结构:每个频率对应一个双向链表,管理该频率下的所有节点struct FreqList{int freq; // 该链表中所有节点的共同访问频率Node *L; // 头哨兵节点:简化链表操作,不存储实际数据Node *R; // 尾哨兵节点:简化链表操作,不存储实际数据// 频率链表构造函数FreqList(int freq){this->freq = freq;L = new Node(-1, -1, 1); // 创建头哨兵R = new Node(-1, -1, 1); // 创建尾哨兵L->next = R; // 头哨兵的后继指向尾哨兵R->pre = L; // 尾哨兵的前驱指向头哨兵}};int n; // 缓存的最大容量int minFreq; // 当前缓存中最小的访问频率,用于快速定位需要淘汰的节点/*** 节点哈希表:key -> Node** 作用:通过key快速定位对应的节点,实现O(1)时间复杂度的访问*/unordered_map<int, Node*> hashNode;/*** 频率链表哈希表:freq -> FreqList** 作用:通过频率快速定位对应的链表,实现O(1)时间复杂度的链表操作*/unordered_map<int, FreqList*> hashFreq;/*** 从链表中删除指定节点* @param node 要删除的节点*/void deleteFromList(Node *node){Node *pre = node->pre; // 获取前驱节点Node *next = node->next; // 获取后继节点pre->next = next; // 前驱节点的后继指向后继节点next->pre = pre; // 后继节点的前驱指向前驱节点}/*** 将节点添加到对应频率的链表尾部(尾部表示最近使用)* @param node 要添加的节点*/void append(Node *node){int freq = node->freq; // 获取节点当前的频率// 如果该频率对应的链表不存在,则创建新的频率链表if(hashFreq.find(freq) == hashFreq.end())hashFreq[freq] = new FreqList(freq);FreqList *curList = hashFreq[freq]; // 获取当前频率对应的链表// 将节点插入到尾哨兵的前面(即链表的尾部)Node *pre = curList->R->pre; // 尾哨兵的前驱节点Node *next = curList->R; // 尾哨兵节点pre->next = node; // 前驱节点的后继指向当前节点node->next = next; // 当前节点的后继指向尾哨兵next->pre = node; // 尾哨兵的前驱指向当前节点node->pre = pre; // 当前节点的前驱指向前驱节点}public:/*** LFU缓存构造函数* @param capacity 缓存的最大容量*/LFUCache(int capacity) {n = capacity; // 初始化缓存容量minFreq = 0; // 初始化最小访问频率为0}/*** 从缓存中获取指定key的值* @param key 要访问的键* @return key对应的value,如果key不存在则返回-1*/int get(int key) {// 缓存中存在该keyif(hashNode.find(key) != hashNode.end()){Node *node = hashNode[key]; // 通过哈希表快速定位节点// 从原频率链表中删除该节点(因为频率即将增加)deleteFromList(node);// 访问频率加1node->freq++;/*** 检查是否需要更新最小频率:* 如果原来的最小频率链表在删除节点后变为空链表,* 说明当前节点是该频率下的最后一个节点,最小频率需要加1*/if(hashFreq[minFreq]->L->next == hashFreq[minFreq]->R) minFreq++;// 将节点添加到新频率对应的链表中append(node);return node->value; // 返回key对应的value}else return -1; // 缓存中不存在该key,返回-1}/*** 向缓存中插入或更新键值对* @param key 要插入或更新的键* @param value 要插入或更新的值*/void put(int key, int value) {if(n == 0) return; // 缓存容量为0,无法存储任何数据// 缓存中已存在该key,复用get操作更新频率,再更新valueif(get(key) != -1)hashNode[key]->value = value;else // 缓存中不存在该key,需要插入新节点{// 缓存空间已满,需要淘汰节点if(hashNode.size() == n){// 找到最小频率对应的链表中最久未使用的节点(头哨兵的下一个节点)Node *node = hashFreq[minFreq]->L->next;deleteFromList(node); // 从链表中删除该节点hashNode.erase(node->key); // 从哈希表中删除该节点}// 创建新节点,初始频率为1Node *node = new Node(key, value, 1);hashNode[key] = node; // 将新节点加入哈希表minFreq = 1; // 新节点频率为1,当前最小频率更新为1append(node); // 将新节点添加到频率为1的链表中}}
};
我们不难发现以上设计存在诸多问题:
- 频率爆炸问题:对于长期驻留在缓存中的热数据,频率计数可能会无限增长,占用额外的存储空间或导致计数溢出。
- 过时热点数据占用缓存:一些数据可能已经不再是热点数据,但因访问频率过高,难以被替换。
- 冷启动问题:刚加入缓存的项可能因为频率为1而很快被淘汰,即便这些项是近期访问的热门数据。
- 不适合短期热点:LFU对长期热点数据表现较好,但对短期热点数据响应较慢,可能导致短期热点数据无法及时缓存。
- 缺乏动态适应性:固定的LFU策略难以适应不同的应用场景或工作负载。
- 锁的粒度大,多线程高并发访问下锁的同步等待时间过长。
针对上述问题,进行了以下几点优化:
- 加上最大平均访问次数限制
- HashLFUCache
最大平均访问次数限制
在LFU算法之上,引入访问次数平均值概念,当平均值大于最大平均值限制时将所有结点的访问次数减去最大平均值限制的一半或者一个固定值。相当于热点数据“老化”了,这样可以避免频次计数溢出,也可以缓解缓存污染。
template <typename Key, typename Value>
class LfuCache {
private:// 1. 缓存基础属性int capacity_; // 缓存最大容量(核心参数,决定何时触发淘汰)int minFreq_; // 当前缓存中最小的访问频率(LFU核心,用于快速定位淘汰目标)// 2. 平均频率控制(扩展功能,区别于标准LFU)int maxAverageNum_; // 允许的最大平均访问频率(防止频率无限增长)int curAverageNum_; // 当前平均访问频率(总访问次数 / 节点数)int curTotalNum_; // 所有节点的总访问次数(用于计算平均频率)// 3. 线程安全std::mutex mutex_; // 互斥锁,保证多线程环境下put/get操作的原子性// 4. 核心映射表(数据结构核心)NodeMap nodeMap_; // key -> 节点指针(O(1)定位节点)std::unordered_map<int, FreqList<Key, Value>*> freqToFreqList_; // 频率 -> 频率链表(O(1)定位同频率节点的链表)
};capacity_:缓存容量上限,决定何时触发淘汰逻辑。minFreq_:LFU 的 “锚点”,直接指向最不常访问的频率,避免遍历所有频率找淘汰目标。- 两个哈希表:
nodeMap_解决 “找节点” 的效率问题,freqToFreqList_解决 “找同频率链表” 的效率问题,共同支撑 O (1) 操作。 - 平均频率相关变量:解决标准 LFU 中 “频率无限增长导致哈希表膨胀” 的问题,是该实现的核心扩展点。
1. getInternal(访问时更新频率的核心逻辑)
/*** 【核心】处理缓存命中时的频率更新(LFU核心逻辑)* 作用:将节点从原频率链表迁移到新频率链表,更新最小频率和平均访问次数*/
void getInternal(NodePtr node, Value& value) {value = node->value; // 返回节点值removeFromFreqList(node); // 从当前频率链表中移除节点node->freq++; // 访问频率+1(核心:LFU的“频率递增”特性)addToFreqList(node); // 加入新频率对应的链表// 若原频率是最小频率且链表已空,更新最小频率(保证minFreq_有效性)if (node->freq - 1 == minFreq_ && freqToFreqList_[node->freq - 1]->isEmpty()) {minFreq_++;}addFreqNum(); // 更新总访问次数和平均频率(扩展功能)
}2. putInternal(插入新节点的核心逻辑)
/*** 【核心】处理新节点插入(含缓存满时的淘汰逻辑)* 作用:新增节点时,若缓存满则淘汰最不常使用节点,否则直接插入*/
void putInternal(Key key, Value value) {if (nodeMap_.size() == capacity_) { // 缓存满,触发淘汰kickOut(); // 淘汰最不常使用的节点(LFU核心淘汰逻辑)}// 插入新节点(初始频率为1)NodePtr node = std::make_shared<Node>(key, value);nodeMap_[key] = node; // 加入节点哈希表addToFreqList(node); // 加入频率=1的链表addFreqNum(); // 更新总访问次数和平均频率minFreq_ = std::min(minFreq_, 1); // 新节点频率为1,更新最小频率
}3. kickOut(淘汰节点的核心逻辑)
/*** 【核心】淘汰最不常使用的节点(LFU核心策略)* 逻辑:淘汰最小频率链表中最久未使用的节点(链表头部节点)*/
void kickOut() {// 找到最小频率对应的链表中最久未使用的节点(头节点的下一个,即链表第一个有效节点)NodePtr node = freqToFreqList_[minFreq_]->getFirstNode();removeFromFreqList(node); // 从频率链表中移除nodeMap_.erase(node->key); // 从节点哈希表中移除decreaseFreqNum(node->freq); // 更新总访问次数和平均频率
}4. handleOverMaxAverageNum(扩展功能核心)
/*** 【扩展核心】处理平均频率超上限的情况(解决频率无限增长问题)* 逻辑:当平均访问频率过高时,降低所有节点的频率,控制频率范围*/
void handleOverMaxAverageNum() {if (nodeMap_.empty()) return;// 遍历所有节点,降低频率(核心:批量调整频率,防止频率无限增大)for (auto& it : nodeMap_) {NodePtr node = it.second;removeFromFreqList(node); // 从原频率链表移除node->freq -= maxAverageNum_ / 2; // 频率降低(至少保留1)if (node->freq < 1) node->freq = 1;addToFreqList(node); // 加入新频率链表}updateMinFreq(); // 重新计算最小频率
}设置最大平均访问次数的值解决了什么问题?
- 防止某一个缓存的访问频次无限增加,而导致的计数溢出。
- 旧的热点缓存,也就是该数据之前的访问频次很高,但是现在不再被访问了,也能够保证他在每次访问缓存平均访问次数大于最大平均访问次数的时候减去一个固定的值,使这个过去的热点缓存的访问频次逐步降到最低,然后从内存中淘汰出去
- 一定程度上是对新加入进来的缓存,也就是访问频次为1的数据缓存进行了保护,因为长时间没被访问的旧的数据不再会长期占据缓存空间,访问频率会逐步被降为小于1最终淘汰。
HashLfuCache
思路与HashLruCachea类似,参照上篇对应的内容
采用分片思想
template<typename Key, typename Value>
class HashLfuCache {
private:size_t capacity_; // 缓存总容量(所有分片容量之和)int sliceNum_; // 分片数量(核心参数,决定并发性能和分片大小)// 存储所有LFU分片的容器(每个分片都是独立的KLfuCache实例)std::vector<std::unique_ptr<KLfuCache<Key, Value>>> lfuSliceCaches_;
};