机器学习入门
一:什么是机器学习
人类通过记忆和归纳这两种方式进行学习,通过记忆可以积累单个事实,使用归纳可以从旧的事实推导出新的事实。机器学习是赋予机器从数据中学习知识的能力,这个过程并不需要人类的帮助(给出明确的规则),也就是说机器学习关注的是从数据中学习一种模式(pattern),即便数据本身存在问题(噪声),这也是机器学习算法和传统算法最根本的区别。传统的算法需要计算机被告知如何从复杂系统中找到答案,算法利用计算机的运算能力去寻找最佳结果。传统算法最大的缺点就是人类必须首先知道最佳的解决方案是什么,而机器学习算法并不需要人类告诉模型最佳解决方案,取而代之的是,我们提供和问题相关的示例数据。
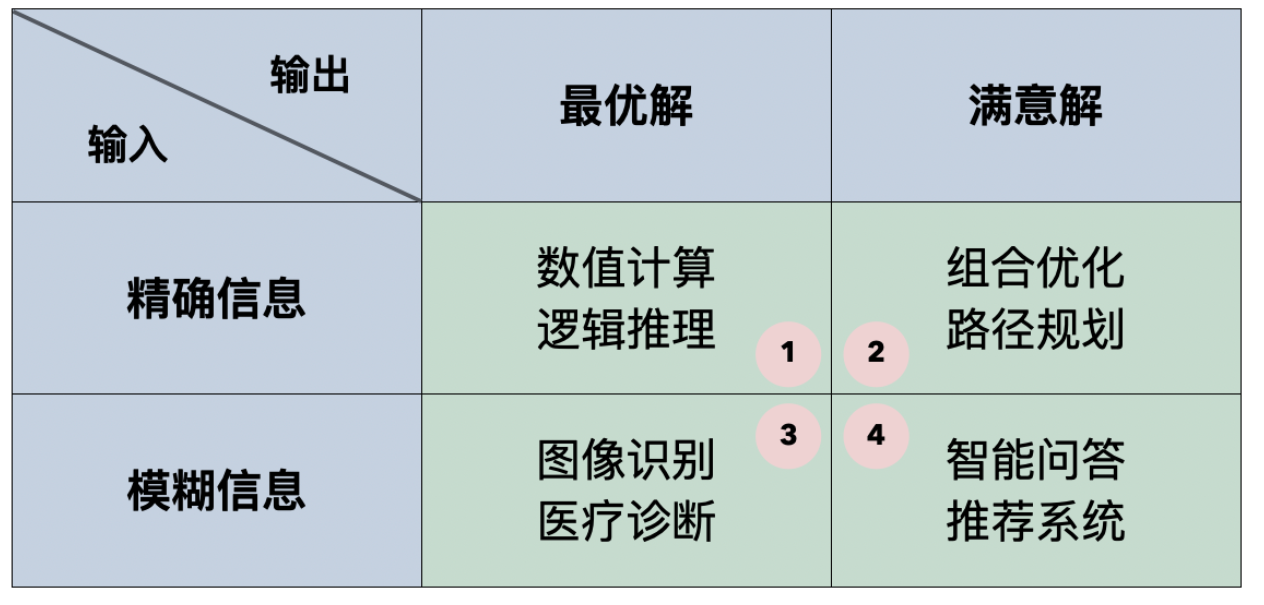
我们可以把需要计算机解决的问题分为四类,分类的依据一方面是输入是精确的还是模糊的,另一方面是输出是最优的还是满意的,我们可以制作出如下所示的表格。可以看出,传统算法擅长解决的只有第一类问题,而机器学习比较擅长解决第三类和第四类问题;第二类问题基本属于 NP 问题(非确定性多项式时间问题),包括旅行经销商问题、图着色问题、集合覆盖问题等,我们通常会采用启发式算法(如模拟退火算法、遗传算法等)或近似算法来解决这类问题,当然机器学习算法也可以为这类问题提供满意解。
当然,机器学习算法并非完美到无懈可击。在通过数据训练模型时,我们需要使用预处理和清洗后的数据,如果数据本身质量非常糟糕,我们也很难训练出一个好的模型,这也是我们经常说到的 GIGO(Garbage In Garbage Out)。如果要使用机器学习,我们还得确定变量之间是否存在某种关系,机器学习无法处理不存在任何关系的数据。大多数时候,机器学习模型输出的是一系列的数字和指标,需要人类解读这些数字和指标并做出决策,判定模型的好坏并决定模型如何在实际的业务场景中落地。通常,我们用来训练模型的数据会存在噪声数据(noisy data),很多机器学习模型对噪声都非常敏感,如果不能处理好这些噪声数据,我们就不太容易得到好的模型。
二:目前常见应用领域
即使对于机器学习这个概念不那么熟悉,但是机器学习的成果已经广泛渗透到了生产生活的各个领域,下面的这些场景对于你来说一定不陌生。
场景1:搜索引擎会根据搜索和使用习惯,优化下一次搜索的结果。
场景2:电商网站会根据你的访问历史自动推荐你可能感兴趣的商品。
场景3:金融类产品会通过你最近的金融活动信息综合评定你的贷款申请。
场景4:视频和直播平台会自动识别图片和视频中有没有不和谐的内容。
场景5:智能家电和智能汽车会根据你的语音指令做出相应的动作。
简单的总结一下,机器学习可以应用到但不限于以下领域:
2.1 图像识别与计算机视觉
计算机视觉(Computer Vision)是机器学习的一个重要应用领域,涉及到使机器能够理解和处理图像和视频数据。
- 人脸识别:通过深度学习模型识别图片中的人脸,如安全监控、手机解锁等。
- 自动驾驶:自动驾驶汽车使用计算机视觉来识别道路标志、行人、其他车辆、交通信号灯等,从而实现自主导航。
- 医疗影像分析:机器学习应用于X光片、MRI扫描和CT图像的分析,帮助医生发现疾病(如癌症、脑卒中等)。
- 图像分类与标注:自动为图像打标签,比如在社交媒体平台上自动识别图片中的物品和场景。
2.2 自然语言处理(NLP)
自然语言处理是机器学习在文本和语音数据上的应用,目的是让计算机能够理解和生成自然语言。
- 语音识别:如智能助手(Siri、Google Assistant)通过语音识别技术将语音转换为文本。
- 机器翻译:Google翻译、百度翻译等应用,使用机器学习技术进行语言之间的自动翻译。
- 情感分析:分析社交媒体帖子、评论等文本数据的情感倾向(积极、消极、中立)。
- 文本生成:自动生成文章或新闻(如GPT系列),为用户提供文章自动写作、智能客服等功能。
- 聊天机器人:例如客服机器人,通过自然语言处理技术与用户进行对话。
2.3 推荐系统
推荐系统利用用户行为数据来预测用户可能感兴趣的物品或服务。
- 电子商务:如亚马逊、淘宝等平台根据用户的浏览和购买记录推荐商品。
- 影视推荐:如Netflix、YouTube等根据用户观看历史推荐电影、视频和节目。
- 社交网络推荐:例如,Facebook和Twitter根据用户的兴趣推荐朋友、帖子或广告。
2.4 预测相关
机器学习在金融领域的应用主要体现在风险管理、预测和自动化交易等方面。
- 信用评分:银行和金融机构利用机器学习模型评估借款人的信用风险。
- 欺诈检测:通过分析交易模式,机器学习模型能够检测到潜在的欺诈行为(如信用卡欺诈、洗钱行为)。
- 算法交易:利用机器学习算法进行股票和其他金融资产的自动化交易,实时根据市场数据进行决策。
机器学习在医疗行业中被广泛应用,尤其是在疾病预测、个性化治疗和医疗图像分析等方面。
- 疾病预测:使用机器学习算法预测疾病的发生概率,例如糖尿病、心脏病等。
- 个性化医疗:基于患者的历史健康数据、基因数据等,机器学习可以帮助提供个性化的治疗方案。
- 药物发现:通过大数据分析,机器学习能够加速新药的发现过程,例如通过预测化合物的药效来筛选潜在药物。
- 健康监测:利用可穿戴设备(如智能手表、健康追踪器)收集的数据,机器学习可以监测健康状况并预测疾病风险。
机器学习也在体育领域得到应用,特别是在数据分析和比赛策略优化方面。
- 运动员表现分析:通过分析运动员的训练数据、比赛数据等,机器学习可以帮助教练制定个性化的训练计划。
- 比赛结果预测:通过历史数据和实时数据,机器学习可以预测比赛的结果、球队表现等。
- 虚拟体育教练:利用机器学习技术为运动员提供数据驱动的训练建议和反馈。
2.5 智能辅助驾驶
自动驾驶技术和智能交通系统都依赖于机器学习技术。
- 自动驾驶汽车:自动驾驶依赖于机器学习来识别周围环境(如行人、交通信号、其他车辆等),并作出决策。
- 交通预测:根据交通流量、天气、节假日等因素,机器学习可以预测路况、交通拥堵情况,优化路线规划。
- 车联网(V2X):车与车、车与基础设施之间的通信系统,利用机器学习进行数据分析和决策。
三:机器学习分类
3.1 按照学习方式分类
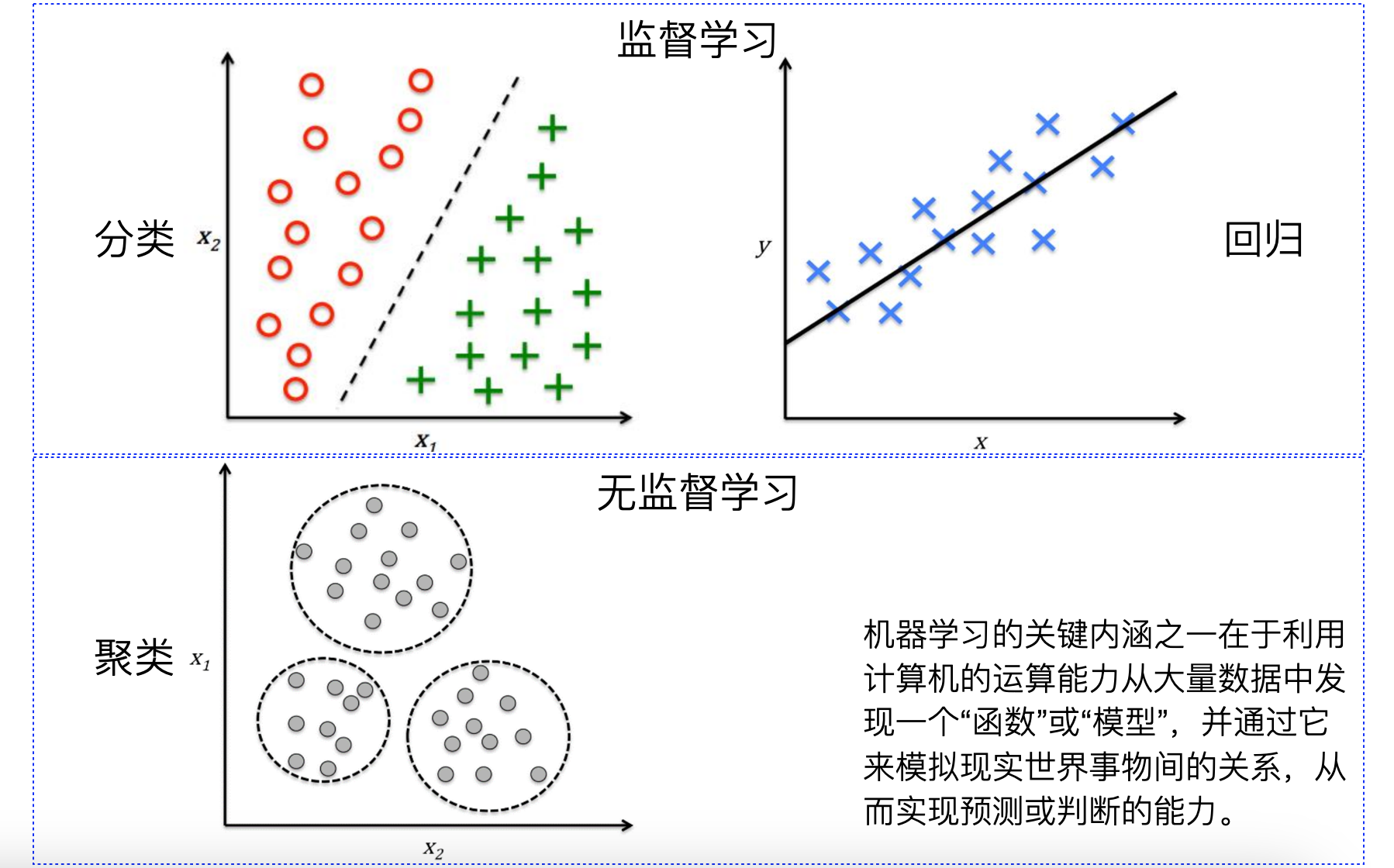
监督学习(Supervised Learning)
- 回归(Regression):用于预测连续值的模型,例如线性回归、Ridge 回归、Lasso 回归等。
- 分类(Classification):用于预测离散类别的模型,例如逻辑回归、支持向量机、决策树、随机森林、k近邻、朴素贝叶斯等。
无监督学习(Unsupervised Learning)
- 聚类(Clustering):用于将数据分组的模型,例如K均值聚类、层次聚类、DBSCAN 等。
- 降维(Dimensionality Reduction):用于减少特征数量的模型,例如主成分分析(PCA)、线性判别分析(LDA)、t分布随机近邻嵌入(t-SNE)等。
- 关联规则学习(Association Rule Learning):用于发现数据集中项之间关系的模型,例如 Apriori 算法、Eclat 算法等。
半监督学习(Semi-Supervised Learning)
- 结合了监督学习和无监督学习的方法,使用大量未标记的数据和少量标记的数据来构建模型。
强化学习(Reinforcement Learning)
- 基于奖励机制的学习方法,例如Q-Learning、深度Q网络(DQN)、策略梯度方法等。
3.2 按照模型的复杂度分类
- 线性模型(Linear Models):如线性回归、逻辑回归。
- 非线性模型(Non-linear Models):如带核函数的支持向量机(SVM with Kernel)、神经网络。
3.3 按照模型的结构分类
- 生成模型(Generative Models):可以生成新的数据点,如朴素贝叶斯、隐马尔可夫模型(HMM)。
- 判别模型(Discriminative Models):仅用于分类或回归,如逻辑回归、支持向量机。
四:机器学习的步骤
机器学习的实施步骤通常分为多个阶段,从问题定义、数据准备到模型部署和维护,每个步骤都非常重要,具体如下所示。
定义问题。首先我们需要做业务理解,明确问题的性质和类型,这个会直接影响到后续的数据收集、特征工程、选择算法以及评估指标的确定。
数据收集。机器学习模型的训练需要大量的数据,这些数据可能包含结构化数据(数据库、Excel 电子表格等)、非结构化数据(文本、图像、音频、视频等)、其他类型的数据集。
数据清洗。数据清洗要确保数据质量高且适合模型训练,具体包括:缺失值和异常值处理、数据标准化和归一化、特殊编码、特征工程等。
数据划分。为了评估机器学习模型的泛化能力,需要将数据划分为训练集和测试集。除此以外,还可能使用交叉验证的方式将数据分成多个子集,每个子集轮流作为验证集,从而对模型的超参数进行调整。
模型选择。针对分类问题、回归问题、聚类问题、深度学习,我们选择的机器学习算法或模型是不一样的。
模型训练。使用训练集对模型进行训练,使模型能够学习到输入特征与目标之间的关系。此外,每个机器学习算法都有超参数,这些参数需要根据数据和任务来调优。
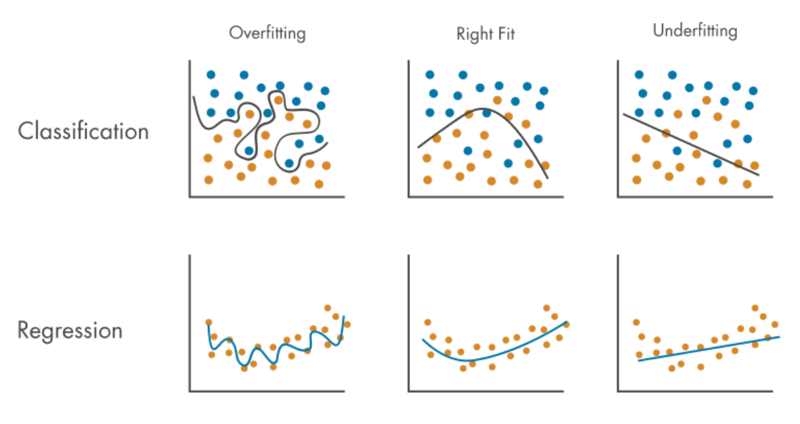
模型评估。模型评估主要的目标是确定模型在新数据(测试集)上的表现,确保模型没有出现过拟合(overfitting)或欠拟合(underfitting),如下图所示。欠拟合会导致模型的预测效果糟糕,而过拟合会导致模型缺乏泛化能力,即在测试集和新数据上表现欠佳。当然,为了提高模型的性能或适应性,可能还要通过正则化、集成学习、算法调整等方式进行调优。
机器学习的实施步骤通常分为多个阶段,从问题定义、数据准备到模型部署和维护,每个步骤都非常重要,具体如下所示。
定义问题。首先我们需要做业务理解,明确问题的性质和类型,这个会直接影响到后续的数据收集、特征工程、选择算法以及评估指标的确定。
数据收集。机器学习模型的训练需要大量的数据,这些数据可能包含结构化数据(数据库、Excel 电子表格等)、非结构化数据(文本、图像、音频、视频等)、其他类型的数据集。
数据清洗。数据清洗要确保数据质量高且适合模型训练,具体包括:缺失值和异常值处理、数据标准化和归一化、特殊编码、特征工程等。
数据划分。为了评估机器学习模型的泛化能力,需要将数据划分为训练集和测试集。除此以外,还可能使用交叉验证的方式将数据分成多个子集,每个子集轮流作为验证集,从而对模型的超参数进行调整。
模型选择。针对分类问题、回归问题、聚类问题、深度学习,我们选择的机器学习算法或模型是不一样的。
模型训练。使用训练集对模型进行训练,使模型能够学习到输入特征与目标之间的关系。此外,每个机器学习算法都有超参数,这些参数需要根据数据和任务来调优。
模型评估。模型评估主要的目标是确定模型在新数据(测试集)上的表现,确保模型没有出现过拟合(overfitting)或欠拟合(underfitting),如下图所示。欠拟合会导致模型的预测效果糟糕,而过拟合会导致模型缺乏泛化能力,即在测试集和新数据上表现欠佳。当然,为了提高模型的性能或适应性,可能还要通过正则化、集成学习、算法调整等方式进行调优
模型部署。当你对模型的性能感到满意时,可以将模型部署到生产环境中,进行实时预测或批量预测。我们通过监控模型在实际应用中的表现,确保其持续保持较好的预测效果。如果模型性能下降,可能需要重新训练或调整。
模型维护。机器学习模型不是一成不变的,随着时间的推移,模型可能需要通过重新训练、增量学习等方式来维持其性能。
五:机器学习初练
为了研究某城市某类消费者每月收入和每月网购支出的关系,我们收集到了50条样本数据(后面我们统称为历史数据),分别保存在两个列表中,如下所示。
# 每月收入
x = [9558, 8835, 9313, 14990, 5564, 11227, 11806, 10242, 11999, 11630,6906, 13850, 7483, 8090, 9465, 9938, 11414, 3200, 10731, 19880,15500, 10343, 11100, 10020, 7587, 6120, 5386, 12038, 13360, 10885,17010, 9247, 13050, 6691, 7890, 9070, 16899, 8975, 8650, 9100,10990, 9184, 4811, 14890, 11313, 12547, 8300, 12400, 9853, 12890]
# 每月网购支出
y = [3171, 2183, 3091, 5928, 182, 4373, 5297, 3788, 5282, 4166,1674, 5045, 1617, 1707, 3096, 3407, 4674, 361, 3599, 6584,6356, 3859, 4519, 3352, 1634, 1032, 1106, 4951, 5309, 3800,5672, 2901, 5439, 1478, 1424, 2777, 5682, 2554, 2117, 2845,3867, 2962, 882, 5435, 4174, 4948, 2376, 4987, 3329, 5002]我们假设月收入和月网购支出都来自于正态总体,接下来我们可以通过计算皮尔逊相关系数来判定两组数据是否存在相关性,代码如下所示。
import numpy as npnp.corrcoef(x, y)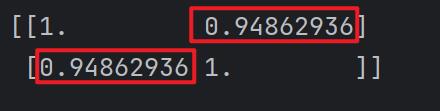
可以看出该城市该类人群的月收入和月网购支出之间存在强正相关性(相关系数为0.94862936)。
上面,我们已经确认了月收入和月网购支出之间存在强相关性,那么一个很自然的想法就是通过某人的月收入来预测他的月网购支出,反过来当然也是可以的。为了做到这一点,可以充分利用我们收集到的历史数据,让计算机通过对数据的“学习”获得相应的知识,从而实现对未知状况的预测。我们可以将上述数据中的 x 称为自变量或特征(feature),将y称为因变量或目标值(target),机器学习的关键就是要通过历史数据掌握如何实现从特征到目标值的映射。
5.1 KNN算法
要通过月收入预测月网购支出,一个最朴素的想法就是将历史数据做成一个字典,月收入作为字典中的键,月网购支出作为对应的值,这样就可以通过查字典的方式通过收入查到支出。
sample_data = {key: value for key, value in zip(x, y)}但是,输入的月收入未必在字典中对应的键,没有键就无法获取对应的值,这个时候我们可以找到跟输入的月收入最为接近的 k 个键,对这 k 个键对应的值求平均,用这个平均值作为对月网购支出的预测。这里的方法就是机器学习中最为简单的 k 最近邻算法(kNN),它是一种用于分类和回归的非参数统计方法。
下面我们用原生 Python 代码来实现 kNN 算法,暂时不使用 NumPy、SciPy、Scikit-Learn 这样的三方库,主要帮助大家理解算法的原理。
import heapq
import statisticsdef predict_by_knn(history_data, param_in, k=5):"""用kNN算法做预测:param history_data: 历史数据:param param_in: 模型的输入:param k: 邻居数量(默认值为5):return: 模型的输出(预测值)"""neighbors = heapq.nsmallest(k, history_data, key=lambda x: (x - param_in) ** 2)return statistics.mean([history_data[neighbor] for neighbor in neighbors])上面的代码中,我们用 Python 中heapq模块的nsmallest来找到历史数据中最小的 k 个元素,通过该函数的key参数,我们界定了最小指的是跟输入的参数param_in误差最小,由于误差有正数和负数,所以通常都需要求平方或者取绝对值。对于算术平均值的计算,我们使用了 Python 中statistics模块的mean函数。接下来,我们用上面的函数来预测月网购支出,代码如下所示。
incomes = [1800, 3500, 5200, 6600, 13400, 17800, 20000, 30000]
for income in incomes:print(f'月收入: {income:>5d}元, 月网购支出: {predict_by_knn(sample_data, income):>6.1f}元')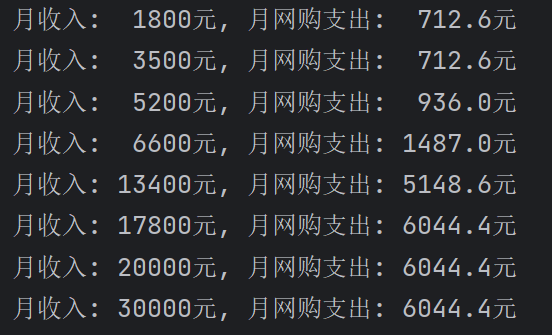
通过上面的输出,我们可以看出 kNN 算法的一个弊端,样本数据的缺失或者不均衡情况会导致预测结果非常糟糕。上面月收入17800元、20000元、30000元的网购支出预测值都是6044.4元,那是因为历史数据中月收入的最大值是19880,所以跟它们最近的 k 个邻居是完全相同的,所以从历史数据预测出的网购支出也是相同的;同理,月收入1800元跟月收入3500元的网购支出预测值也是相同的,因为跟1800元最近的 k 个邻居和跟3500元最近的 k 个邻居也是完全相同的。当然,上面我们给出的 kNN 算法实现还有其他的问题,大家应该不难发现predict_by_knn函数中,我们每次找寻最近的 k 个邻居时,都要将整个历史数据遍历一次,如果数据集体量非常大,那么这个地方就会产生很大的开销。
5.2 回归模型
我们换一种思路来预测网购支出,我们将月收入和月网购支出分别作为横纵坐标来绘制散点图。既然网购支出跟月收入之间存在强正相关,这就意味着可以找一条直线来拟合这些历史数据点,我们把这条直线的方程 y=ax+b 称为回归方程或回归模型,如下图所示。
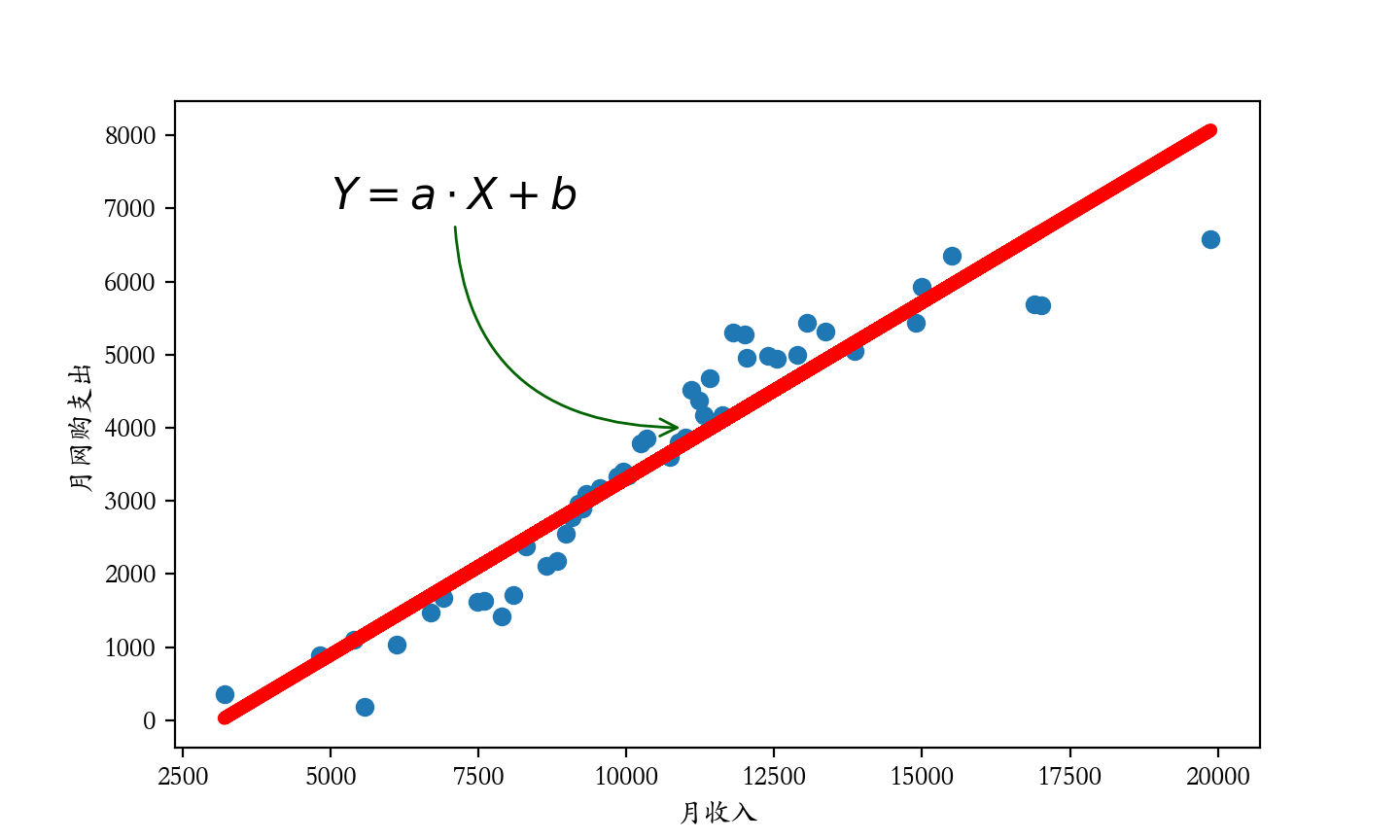
现在,我们的问题就变成了如何利用收集到的历史数据计算出回归模型的斜率 a 和截距 b 。
为了评价回归模型的好坏,也就是我们计算出的斜率和截距是否理想,我们可以先定义评判标准,一个简单且直观的评判标准就是我们将月收入 x 带入回归模型,计算出月网购支出的预测值 y^ ,预测值 y^ 和真实值 y 之间的误差越小,说明我们的回归模型越理想。
之前我们提到过,计算误差的地方通常都需要取绝对值或者求平方,我们可以用误差平方的均值来作为评判标准,通常称之为均方误差(MSE),如下所示。
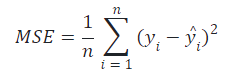
根据上面的公式,我们可以写出计算均方误差的函数,通常称之为损失函数。
import statisticsdef get_loss(X_, y_, a_, b_):"""损失函数:param X_: 回归模型的自变量:param y_: 回归模型的因变量:param a_: 回归模型的斜率:param b_: 回归模型的截距:return: MSE(均方误差)"""y_hat = [a_ * x + b_ for x in X_]return statistics.mean([(v1 - v2) ** 2 for v1, v2 in zip(y_, y_hat)])能让 MSE 达到最小的 a 和 b ,我们称之为回归方程的最小二乘解,接下来的工作就是要找到这个最小二乘解。
简单的说,我们要将可能的 a 和 b 带入损失函数,看看什么样的 a 和 b 能让损失函数取到最小值。如果对 a 和 b 的取值一无所知,我们可以通过不断产生随机数的方式来寻找 a 和 b ,这种方法称为蒙特卡洛模拟,通俗点说就是随机瞎蒙,代码如下所示。
import random# 先将最小损失定义为一个很大的值
min_loss, a, b = 1e12, 0, 0for _ in range(100000):# 通过产生随机数的方式获得斜率和截距_a, _b = random.random(), random.random() * 4000 - 2000# 带入损失函数计算回归模型的MSEcurr_loss = get_loss(x, y, _a, _b)if curr_loss < min_loss:# 找到更小的MSE就记为最小损失min_loss = curr_loss# 记录下当前最小损失对应的a和ba, b = _a, _bprint(f'MSE = {min_loss}')
print('a={},b={}'.format(_a,_b))上面的代码进行了100000次的模拟, a 和 b 的值在 [−2000,2000) 范围随机选择的,下面是在我的电脑上跑出来的结果。大家可以把自己蒙特卡罗模拟的结果分享到评论区,看看谁的运气更好,找到了让误差更小的 a 和 b 。

对于数学知识比较丰富的小伙伴,我们可以将回归模型带入损失函数x 和 y 是已知的历史数据,那么损失函数其实是一个关于 a 和 b 的二元函数,如下所示。 其实就是将上面MSE公式中预测值 y^变成现在我们预测的带有a,b的函数了。
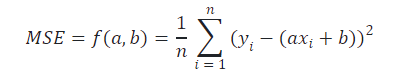
根据微积分的极值定理,我们可以对f(a,b) 求偏导数,并令其等于0,这样我们就可以计算让 f(a,b) 取到最小值的 a 和 b 分别是多少,即:
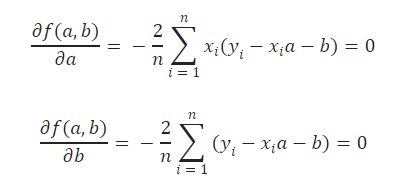
求解上面的方程组可以得到:
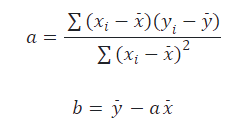
需要说明的是,如果回归模型本身比较复杂,不像线性模型 y=ax+b 这么简单,可能没有办法像上面那样直接求解方程,而是要通过其他的方式来找寻极值点,这个我们会在后续的内容中会为大家讲解。回到刚才的问题,我们可以通过上面的公式计算出 a 和 b 的值,为了运算方便,下面直接使用了 NumPy 中的函数,因为 NumPy 中的运算都是矢量化的,通常不需要我们自己写循环结构。
import numpy as npx_bar, y_bar = np.mean(x), np.mean(y)
a = np.dot((x - x_bar), (y - y_bar)) / np.sum((x - x_bar) ** 2)
b = y_bar - a * x_bar
print('a={},b={}'.format(a,b))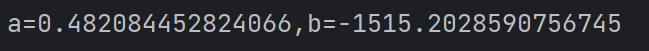
事实上,NumPy 库中还有封装好的函数可以帮我们完成参数拟合,你可以使用linalg模块的lstsq函数来计算最小二乘解
a, b = np.polyfit(x, y, deg=1)
print('a={}, b={}'.format(a,b))![]()
结果当然也是相同的。