【Ansible】Ansible 管理 Elasticsearch 集群启停
一、集群节点信息
通过 Ansible inventory 定义的集群节点分组如下:
-
[es](Elasticsearch 节点)
- 192.168.100.150
- 192.168.100.151
- 192.168.100.152
-
[logstash](Logstash 节点)
- 192.168.100.151
-
[kibana](Kibana 节点)
- 192.168.100.150
二、集群启动脚本(es_start.sh)
1. 脚本功能
通过 Ansible 批量启动集群组件,遵循依赖顺序启动原则,确保组件间协作正常。
2. 启动顺序及说明
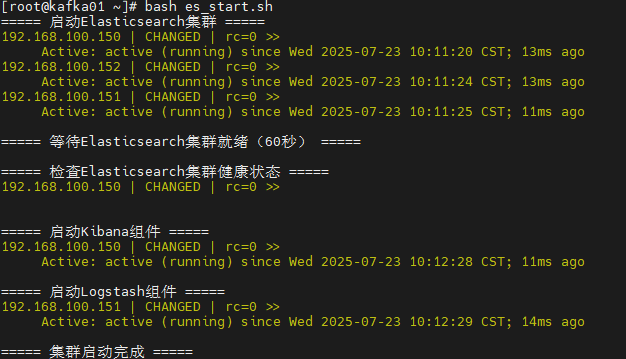
#!/bin/bash# 1. 先启动Elasticsearch(核心存储组件,需等待集群就绪)
echo "===== 启动Elasticsearch集群 ====="
ansible es -m shell -a "systemctl start elasticsearch && systemctl status elasticsearch | grep 'Active:'"# 等待Elasticsearch集群初始化(根据集群规模调整等待时间)
echo -e "\n===== 等待Elasticsearch集群就绪(60秒) ====="
sleep 60# 检查Elasticsearch集群健康状态
echo -e "\n===== 检查Elasticsearch集群健康状态 ====="
ansible es[0] -m shell -a "curl -s -u elastic:your_elastic_password 'http://192.168.100.150:9200/_cluster/health' | jq .status"# 2. 启动Kibana(依赖Elasticsearch)
echo -e "\n===== 启动Kibana组件 ====="
ansible kibana -m shell -a "systemctl start kibana && systemctl status kibana | grep 'Active:'"# 3. 最后启动Logstash(数据采集组件,依赖Elasticsearch接收数据)
echo -e "\n===== 启动Logstash组件 ====="
ansible logstash -m shell -a "systemctl start logstash && systemctl status logstash | grep 'Active:'"echo -e "\n===== 集群启动完成 ====="
3. 启动逻辑说明
- 优先启动 Elasticsearch:作为核心存储组件,需先确保集群就绪(通过 60 秒等待和健康状态检查)。
- 其次启动 Kibana:Kibana 依赖 Elasticsearch 提供数据,需在 ES 就绪后启动。
- 最后启动 Logstash:Logstash 负责数据采集,需在 ES 可用后启动以避免数据丢失。
三、集群停止脚本(es_stop.sh)
1. 脚本功能
通过 Ansible 批量停止集群组件,遵循反向依赖顺序,确保数据安全。
2. 停止顺序及说明
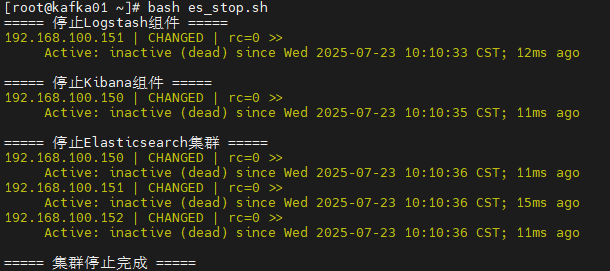
#!/bin/bash# 1. 先停止Logstash(数据采集组件,避免新数据写入)
echo "===== 停止Logstash组件 ====="
ansible logstash -m shell -a "systemctl stop logstash && systemctl status logstash | grep 'Active:'"# 2. 停止Kibana(可视化组件,不影响数据存储)
echo -e "\n===== 停止Kibana组件 ====="
ansible kibana -m shell -a "systemctl stop kibana && systemctl status kibana | grep 'Active:'"# 3. 最后停止Elasticsearch(核心存储组件,确保数据写入完成)
echo -e "\n===== 停止Elasticsearch集群 ====="
ansible es -m shell -a "systemctl stop elasticsearch && systemctl status elasticsearch | grep 'Active:'"echo -e "\n===== 集群停止完成 ====="
3. 停止逻辑说明
- 先停止 Logstash:避免新数据持续写入,确保现有数据已处理完毕。
- 再停止 Kibana:Kibana 仅用于可视化,停止后不影响数据存储。
- 最后停止 Elasticsearch:确保所有数据已落盘,避免强制停止导致数据损坏。
四、脚本使用说明
- 权限设置:确保脚本可执行
chmod +x es_start.sh es_stop.sh - 启动集群:
./es_start.sh - 停止集群:
./es_stop.sh - 注意事项:
- 替换脚本中的
your_elastic_password为实际 Elasticsearch 密码。 - 可根据集群规模调整
sleep 60的等待时间(节点越多,可能需要更长时间)。 - 脚本通过
grep 'Active:'实时输出组件状态,便于确认操作结果。
- 替换脚本中的