深入解析预训练语言模型在文本生成中的革命性应用:技术全景与未来挑战
本文精读最新综述《Pretrained Language Models for Text Generation: A Survey》,揭秘PLM如何重塑文本生成技术格局!
一、引言:文本生成的范式革命
文本生成(NLG)作为NLP核心任务之一,旨在根据输入数据生成符合人类语言习惯的文本。传统方法受限于数据稀疏性和模型泛化能力,而预训练语言模型(PLM)的出现彻底改变了这一局面。通过“预训练+微调”范式,PLM将海量语言学知识和世界知识编码到参数中,显著提升了生成文本的质量和多样性。
核心优势:
-
知识富集:在大规模语料上预训练,捕获深层语言规律
-
迁移高效:通过微调快速适应下游任务,解决数据稀缺问题
-
架构统一:Transformer架构提供强大的序列建模能力
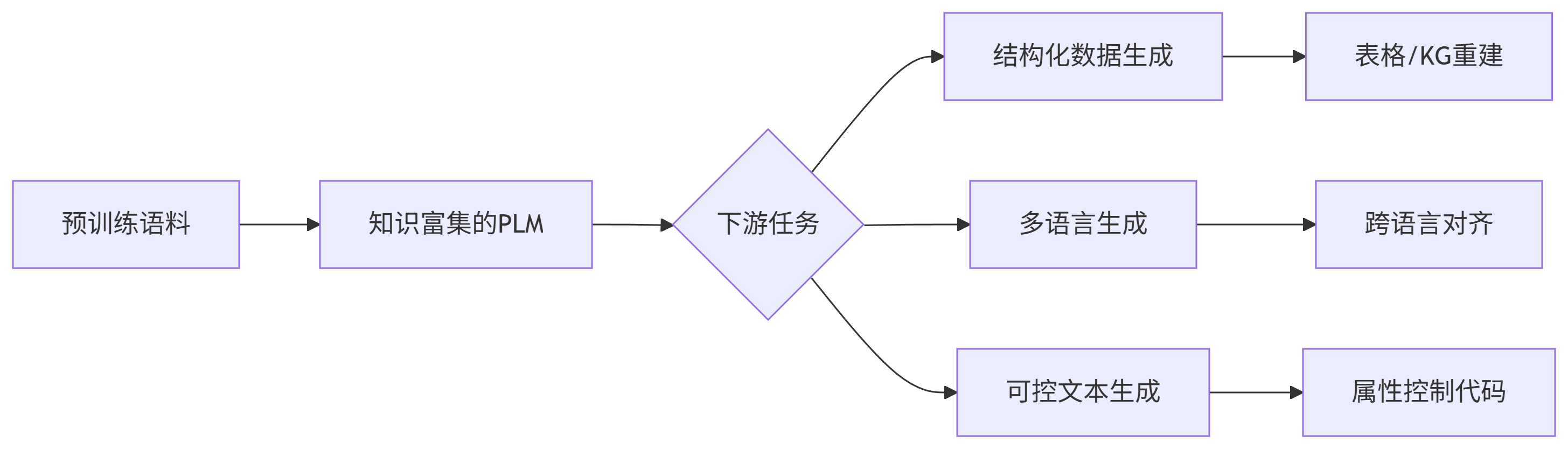
二、文本生成任务全景图
根据输入类型,文本生成任务可分为五大类:
| 输入类型 | 典型任务 | 代表方法 |
|---|---|---|
| 无输入/噪声 | 无条件生成 | GPT系列 |
| 离散属性 | 主题生成/属性控制 | CTRL |
| 结构化数据 | 数据到文本生成 | TableGPT, KG-to-text |
| 多媒体 | 图像描述/语音识别 | VideoBERT, XGPT |
| 文本序列 | 机器翻译/摘要/对话 | BART, T5 |
三、核心技术突破
1. 多模态输入建模
结构化数据处理挑战:知识图谱/表格等非序列数据与PLM的序列结构不匹配
创新解决方案:
-
线性化:将KG三元组转为序列(如
(主体, 关系, 客体)) -
图编码器增强:使用GNN编码结构信息后与PLM融合
-
重建辅助任务:通过解码器重建原始结构(如Gong等提出的内容匹配损失)
# 伪代码:表格线性化示例
def serialize_table(table):return " | ".join([f"{col} is {val}" for col, val in table.items()])
# 输入: {"name": "Jack", "age": 30}
# 输出: "name is Jack | age is 30"2. 输出文本关键特性控制
| 特性 | 定义 | 实现技术 |
|---|---|---|
| 相关性(Relevance) | 输出与输入主题一致性 | 条件注意力路由(Zeng & Nie) |
| 忠实性(Faithfulness) | 输出不违背输入事实 | 指针生成器+知识检索(Kryscinski) |
| 顺序保持(Order-preservation) | 跨语言短语顺序一致性 | 多语言对齐(mRASP) |
案例:在摘要任务中,Rothe等实验证明,用BERT初始化编码器可使模型更关注文档事实,减少幻觉生成。
四、微调策略精要
1. 数据视角
-
Few-shot学习:XLM利用高资源语言知识迁移到低资源翻译
-
领域迁移:基于TF-IDF的掩码策略强化领域关键词学习
2. 任务视角
-
增强连贯性:
-
下一句预测(NSP):判断句子连续性
-
去噪自编码(DAE):重构受损文本(如TED模型)
-
-
保持保真度:多任务学习同步优化内容匹配损失
3. 模型视角
-
知识蒸馏:BERT作教师模型指导轻量学生模型(Chen等)
-
课程学习:从简单样本逐步过渡到复杂样本(Zhao等)
五、未来挑战与方向
-
模型扩展
-
解决预训练(如
[MASK])与微调任务的不一致性 -
探索知识注入式预训练(如ERNIE)
-
-
可控生成
-
实现细粒度控制(情感/主题/风格)
-
动态控制码替代预设标签
-
-
模型压缩
-
蒸馏/量化PLM(如DistilGPT2)
-
参数量化技术应用于生成任务
-
-
伦理治理
-
消除性别/种族偏见
-
构建内容安全过滤机制
-
六、结语
PLM已成为文本生成的基础设施级技术,其核心价值在于:
-
统一架构解决多种生成任务
-
知识迁移突破数据瓶颈
-
生成质量实现跨越式提升
未来研究需在可控性、效率和安全性三个维度持续突破。正如论文所预言:“设计更贴合生成任务的预训练范式,将是解锁PLM全部潜力的关键”。
参考文献
[1] Brown T B, et al. Language Models are Few-shot Learners. NeurIPS 2020.
[2] Gong H, et al. TableGPT: Few-shot Table-to-text Generation. COLING 2020.
[3] Zhou L, et al. Unified Vision-Language Pre-training. AAAI 2020.
本文首次发布于CSDN,转载请注明出处。关注AI技术前沿,欢迎评论区交流讨论!