反向传播及优化器
反向传播(Backpropagation)
反向传播是计算梯度的算法,核心作用是高效求解 “损失函数对模型所有参数的偏导数”(即梯度)。没有反向传播,深度学习的大规模训练几乎不可能实现。

整个过程像 “从终点回溯到起点”,因此称为 “反向传播”。
# 测试损失函数
loss=nn.CrossEntropyLoss()
for data in dataloader:imgs, targets = dataoutput = module(imgs)result_loss=loss(output,targets)# print(result_loss)# 反向传播result_loss.backward()优化器(Optimizer)
优化器的作用是根据反向传播计算的梯度,更新模型参数,最终目的是减小损失。它是 “梯度→参数更新” 的执行者。
1. 核心目标
根据梯度调整参数,使损失函数尽可能小。基本逻辑是: \(参数_{新} = 参数_{旧} - 学习率 \times 梯度\) (“减梯度” 是因为梯度方向是损失增大的方向,反向才能减小损失)
2. 常见优化器及特点
不同优化器通过改进 “梯度使用方式” 提升效果,以下是主流优化器对比:
优化器 | 核心特点 | 适用场景 |
|---|---|---|
SGD | 基础版:直接用当前梯度更新(\(W = W - lr \cdot \nabla Loss\)) | 简单模型、需要稳定收敛 |
SGD + 动量 | 模拟物理动量:保留部分历史梯度,减少震荡(适合非凸损失函数) | 复杂模型(如 CNN)、避免局部最优 |
Adam | 结合动量和自适应学习率(对不同参数用不同学习率),收敛快且稳定 | 大部分场景(推荐新手首选) |
RMSprop | 自适应学习率:对频繁变化的参数用小学习率,稀疏参数用大学习率 | 处理非平稳目标(如 RNN) |
无论哪种优化器,都需要指定两个基础参数:
| 参数 | 含义 | 作用 |
|---|---|---|
params | 模型需要更新的参数(如 model.parameters()) | 告诉优化器 “要调整哪些参数”(必须指定,否则无法定位更新对象) |
lr(learning rate) | 学习率(核心超参数,通常取值 1e-3、1e-4 等) | 控制参数更新的 “步长”: - 过大:可能跳过最优解(不收敛); - 过小:收敛太慢或陷入局部最优 |
其他参数 依据各个优化器算法的不同而不同
代码案例:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("../torchvision_dataset", train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1)class MyModule(nn.Module):def __init__(self):super().__init__()self.model1 = Sequential(Conv2d(3, 32, 5, stride=1, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, stride=1, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, stride=1, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10),)def forward(self, x):x = self.model1(x)return xmodule = MyModule()
loss=nn.CrossEntropyLoss()
# 随机梯度下降(SGD)优化器
optim=torch.optim.SGD(module.parameters(),lr=0.001)
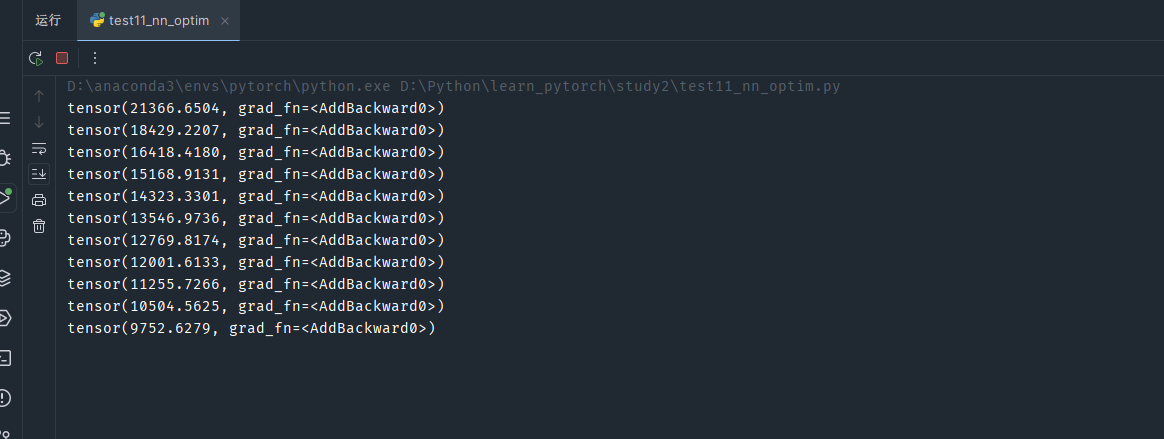
for epo in range(20):running_loss=0for data in dataloader:# 每次训练前,先把各个梯度设为0optim.zero_grad()imgs, targets = dataoutput = module(imgs)result_loss=loss(output,targets)# 反向传播,依据链式法则计算各个梯度result_loss.backward()optim.step()running_loss=result_loss+running_lossprint(running_loss)
看几轮训练结果的损失函数值变化