Python笔记完整版
常用pip源
(1)阿里云
http://mirrors.aliyun.com/pypi/simple/
(2)豆瓣
http://pypi.douban.com/simple/
(3)清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
(4)中国科学技术大学
http://pypi.mirrors.ustc.edu.cn/simple/
(5)华中科技大学
http://pypi.hustunique.com/
第一讲 基础知识
# ctrl+/ 添加注释
# ctrl+alt+l 三键实现格式规范
# \+特定字符 产生一个新的含义,就是转义字符(# \\ \t)
#\\ 表示一个反斜杠
#\n 是换行符
变量
# 变量
# 1.严格区分大小写
# 2.由数字,字母,下划线组成,数字不能开头
# 3.不能使用关键字
name = '张三'
print(name)
# input()表示输入,在括号里面加入''可加入提示\
input('请输入您的密码')
输入输出
# 格式化输出
age=18
name="zxy"
print("我的姓名是%s,年龄是%d"%(name,age))print(666)
print('我爱编程')
# sep=','指定,为分隔变量的符号
print('唐三', '小舞', '张三', sep=',')
print('唐三', '小舞', sep=' ')# end='\n'指定换行结尾
print('唐三', '小舞', end='*')
print('唐三', '小舞', end='\n') #这个是输出换行,其实py默认有
print('唐三', '小舞', end=' ') #输出不换行
input()函数接收的用户输入始终是字符串类型(str)
遵循命名规范:大驼峰命名法和小驼峰命名法

第二讲 数据类型
- 基本数据类型:
# 整型 int
age=19# 浮点型 float
money=15.1# 布尔型 boolean
sex=True #男
gender =False #女# String 字符串
a='A'
s="我爱python"
# '''中间可以放几段话'''
name = '''
啦啦啦
啦啦啦
啦啦啦
'''
print(name)
定义字符串不要单引号和双引号混用,显得你不专业
- 复合数据类型
# list 列表
name_list['周总','王哥']
# tuple 元组
tuple=(1,2,3,4,5)
# dict 字典 {key:value,key1:value1}
person={'name':'小张','age':18}
- 用法:
# type函数,查看变量的类型
name = '漩涡鸣人'
print(type(name)) #<class 'str'>
# 运算注意优先级以及从左向右计算
转义字符:
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\n</font>**:换行**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\t</font>**:制表符**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\\</font>**:反斜杠本身**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\'</font>**或**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">\"</font>**:单引号/双引号
- 类型转换
# 字符不能和整数类型相加,但可以变换
name = '张三'
age = 48
print(name + str(age))
同理整型和浮点类型也可以相互转换,但有非数字的字符不能转换为整数,也不能是浮点类型结构
| 函数 | 说明 |
|---|---|
| int(x) | 把x转换为一个整数 |
| float(x) | 把x转换为一个浮点数 |
| str(x) | 把x转换为一个字符串 |
| bool(x) | 把x转换为一个布尔值 |
转换为整型
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">int()</font>** 只能转换 整数字符串(如 **<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">"123"</font>**)或 浮点数(如 **<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">123.456</font>**)
print(int("123")) #123将字符串转换成为整款
print(int(123.78)) #123将浮点数转换成为整数
print(int(true)) #布尔值true转换成为整数是1
print(int(false)) #布尔值false转换成为整数是
#以下两种情况将会转换失败
123.456和12ab是字符串,一个是浮点数一个含字母,不能被转换成为整数,会报措
print(int("123.456"))
print(int("12ab"))
转换为浮点数
f1=float("12.34")
print(f1) #12.34
print(type(f1)) #f1oat将字符串的"12.34"转换成为浮点数12.34
f2=float(23)
print(f2) #23.0
print(type(f2)) #float将整数转换成为了浮点数
转换为字符串
str1=str(45)
str2=str(34.56)
str3=str(True)
print(type(str1),type(str2),type(str3))
转换为布尔类型(应用:常用于条件判断,检查变量是否为空或有效)
print(bool('')) # False(空字符串)
print(bool("")) # False(空字符串)
print(bool(0)) # False(整数 0)
print(bool({})) # False(空字典)
print(bool([])) # False(空列表)
print(bool(())) # False(空元组)
对于非0的整数进行布尔类型的转换,都是True
第三讲 运算符
- 算数运算符
-
-
- / 加减乘除
-
% 取余
// 取整除
** 指数
优先级 *高于/%//高于±
number = input('请输入数字')
number = int(number) # 输入的是字符类型,用int转换为整数类型进行运算
result = number % 2
print(result)# //表示整除运算
bounty = 5000
print(bounty/280) # 结果是17.86
print(bounty//280) # 结果是17print(2**3) #输出8# += *= /= -= 运算符
# 关系运算符返回值类型是布尔类型# ord()函数可以查看字符对应的整数数值
print(ord('a'))
- 赋值运算符
a,b,c=1,2,3
多变量赋值用逗号分隔
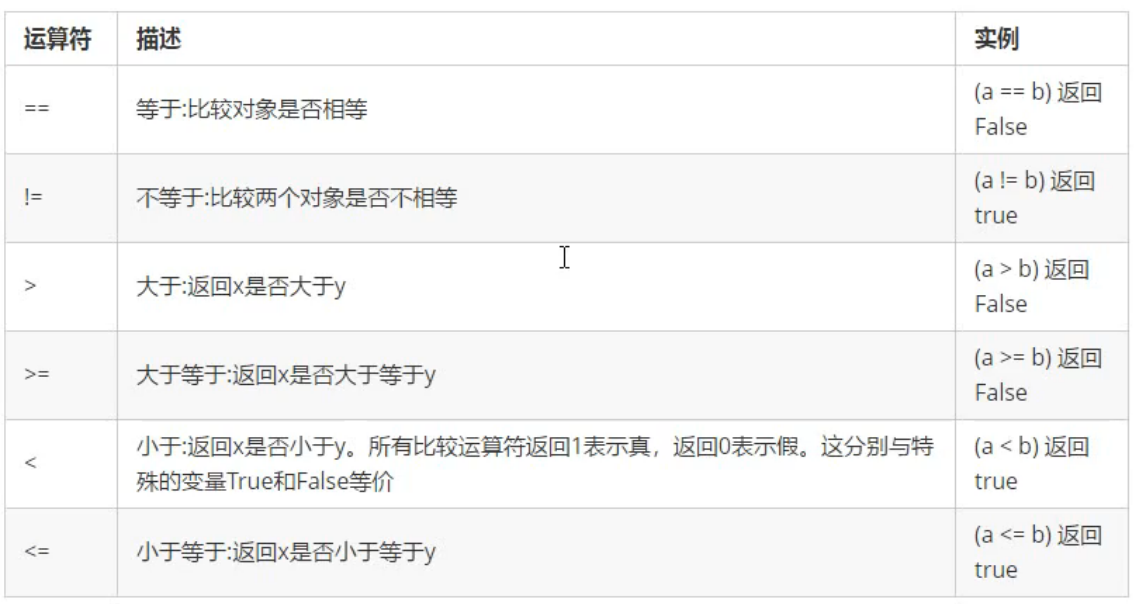
- 比较运算符
- 逻辑运算符

and的性能优化:当and前面的结果是fa1se的情况下 那么后面的代码就不再执行了
or:只要有一方为true 那么结果就是true
第四讲 条件语句
- if语句的使用
- if…else语句的使用
- 多重if语句的使用
- if嵌套
# if 要判断的条件: (标准结构)
# 条件成立时要做的事情
# else:
# 条件成立时要做的事情
money = input('请输入您的钱数')
money = int(money) # 注意转换
things1 = '盲盒'
if money>35:print('拿下{}'.format(things1))
# 用{}进行占位,用.format()函数填充占位
else:print('买不起')
# elif语句
# if 条件1:
# 事情1
# elif 条件2:
# 事情2
# else:
# 事情3
choice1 = input('请输入你要选的品牌')
choice2 = input('请输入你要选的衣服类型')
money = input('请输入你手中有多少钱')
money = int(money)
if choice1 == '安踏' and choice2 == '短袖' and money > 60 :print('您购买了{}品牌的{}'.format(choice1,choice2), '您还有{}元钱'.format(money-60) , sep = '\n')
elif choice1 == '李宁' and choice2 == '短袖' and money > 60 :print('您购买了{}品牌的{}'.format(choice1,choice2), '您还有{}元钱'.format(money-60) , sep = '\n')
elif choice1 == '耐克' and choice2 == '短袖' and money > 60:print('您购买了{}品牌的{}'.format(choice1, choice2), '您还有{}元钱'.format(money - 60), sep='\n')
else:print('您要的我们没有或者您的钱不足以支付请重试')# if下语句可继续嵌套if
第五讲 循环语句
- while的使用
- for的使用
- break和continue的使用
- while或者for与else结合使用
循环的核心在于减少重复代码,条件要尽量通用化
# while 循环条件:(当循环条件不成立时结束)
# 循环执行的代码
# break,整个循环会立即终止,不再执行后续的循环体代码,直接跳出循环
# continue 跳过本次循环,后面语句不执行,继续执行下一次循环
i = input('请输入数字')
i = int(i)
while i <= 5:i += 1print(i)
# 需求:限制登陆次数
i = 3
while i >= 1:username = input('请输入用户名')password = input('请输入密码')if username == 'admin' and password == '123456' :print('登录成功')break # 作用在于登录成功后退出循环else:print('登录失败')i -= 1print('还有{}次机会' .format(i))continue # 继续循环
# for 变量 in 序列:
# 循环体
# 变量:自定义变量名,要求和单独定义时候一样
# 序列:容器型数据类型的数据,比如字符串,布尔,列表,元组,集合
# 循环体:需要重复执行的代码
for x in range(1,11):print('今天你直播下单{}次'.format(x))# range()函数作用是产生一个序列,从0开始# range(1,11)则表示从1开始11结束但是不包括11# range(1,6,2)表示135的序列,即2为步长(可以是负数)
# 需求:限制登陆次数
for i in range(3):username = input('请输入用户名')password = input('请输入密码')if username == 'admin' and password == '123456' :print('登录成功')break # 作用在于登录成功后退出循环else:print('登录失败')print('还有{}次机会' .format(2-i))continue # 继续循环# 需求:打印1-12数字,除了8不打印
# 方法一
for i in range(1,13):if i == 8:continueelse:print(i)
# 方法二
i = 1
while i <12:i += 1if i == 8 :continueprint(i)
# else可以和while,for进行配合
# 案例一
i = 13
while i <12:print('验证失败')
else:print('验证成功')
# 案例二
for i in range(8):print(i , end=' ')
else:print('\n')print('结束')
第六讲 数据类型列表
列表类似数组,字典类似结构体
列表的使用
# 以前介绍的int bool str float都只能存放一个值,需要列表存放一堆值
# 变量名字 = [元素,元素,元素]
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
print(type(heros))
输出结果是<class ‘list’>,即构成了一种新的数据类型列表
列表索引
# 编号从0开始,相关方式类比数组
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
print(heros[1])
即可获取张四,同理可以获取其他元素
若要同时获取多个元素,则要使用列表切片的办法

# 1:3表示索引的一个左闭右开区间,只包含左边不包含右边
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
print(heros[0:6])
# [3:]若省去终止位置,则表示从标明的初始位置一直索引到终止位置
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
print(heros[0:])
这样就可以把上述元素全部输出出来了(俩个方法结果一样)
但是显然不可能所有的取法步长都为一也不可能都是顺序取元素
# 完整格式 print(列表名(初始位置:终止位置:步长)) 默认步长为+1
#输出从第一个元素开始的所有奇数项元素
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
print(heros[0::2])
我们在长数据超大数据时,往往不方便一次看出到底有多少个元素
# len()函数可以获取列表的长度
print(len(heros))
我们往往需要增删改查,实现列表元素动态管理
增:
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
# append可以实现列表元素增加
heros.append('张九')# insert方法定向插入元素,原来在此位置以及之后的元素全体后移
heros.insert(3, '张六plus')# extend合并两个列表
num_list=[1,2,3]
num1_list=[4,5,6]
num_list.extend(num1_list)
print(num_list)
删:
# del根据下标进行删除
fruits = ['apple', 'banana', 'orange', 'pear']
# 删除索引为1的元素('banana')
del fruits[1]
print(fruits) # 输出: ['apple', 'orange', 'pear']# pop删除最后一个元素
last_fruit = fruits.pop()
print(last_fruit) # 输出: 'pear'
print(fruits) # 输出: ['apple', 'banana', 'orange']# remove根据元素的值删除元素
# 删除第一个匹配到的'banana'
fruits.remove('banana')print(fruits) # 输出: ['apple', 'orange', 'banana']# 如果要删除的元素不存在会报错
# fruits.remove('peach') # 会引发 ValueError
改:
改
heros[0] = '张三plus' # 实现修改定向位置的元素
查:
# index函数可以实现查找某一元素具体位置,并通过变量存储,在案例实现的时候有奇效
number1 = heros.index('张三')
print(number1)# 可以利用 in 来判断元素在不在列表内
# 格式 查找的元素 in 列表名 返回值是布尔类型,可以用int转换后用变量储存下来
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
number3 = int('张2' in heros)
print(number3) #输出1或0
index 和 in 可以相互补充相互协调,index返回具体位置,in判断在不在,还可以配合后面的count来判断在不在
计数:
# 列表名.count(要查询的元素) 返回值为元素个数
heros = ['张三', '张四', '张五', '张六', '张七', '张八']
heros.append('张三')
heros.append('张三')
heros.append('张三')
heros.append('张三')
number2 = heros.count('张三')
print(number2)
字典的使用
# 基础格式: 变量名字 = {key1:value1,key2:value2}
hero = {'姓名': '孙悟空','性别': '男', '定位':'战士' }
print(hero)
print(type(hero))
得到的结果是<class ‘dict’>即构成了一种新的数据类型列表
字典还可以和列表搭配使用
hero = {'姓名': '孙悟空', '性别': '男', '定位': '战士', '最佳搭档': ['八戒', '沙僧', '唐僧']}
print(hero)
print(type(hero))
# 那如何获取里面中的东西呢
print(hero['性别'])
# 如何判断字典里面是否有我们查找的键呢
# print(字典名.get(查找的键,如果找不到返回的东西))
hero = {'姓名': '孙悟空', '性别': '男', '定位': '战士', '最佳搭档': ['八戒', '沙僧', '唐僧']}
print(hero.get('定位', '未知'))
# 我们用get的时候,如果键存在则返回键的值,如果键不存在则返回设定的返回值,如果我们没有设定返回值,则返回NONE
字典同样支持增删改查操作,实现动态管理
增:
hero = {'姓名': '孙悟空', '性别': '男', '定位': '战士', '最佳搭档': ['八戒', '沙僧', '唐僧']}
hero['血量'] = 4399 # 对于一个原来没有的键进行操作会添加
删:
# 1.del - 直接删除键值对
my_dict = {'a': 1, 'b': 2, 'c': 3}
del my_dict['b'] # 删除键'b'对应的键值对
print(my_dict) # 输出: {'a': 1, 'c': 3}
# 注意:键不存在会引发KeyError
# del my_dict['x'] # 会报错 KeyError: 'x'特点:
- 最简单直接的删除方式
- 不返回被删除的值
- 键不存在时会引发错误# 2. pop() - 删除并返回值
my_dict = {'a': 1, 'b': 2, 'c': 3}
value = my_dict.pop('b') # 删除并返回'b'对应的值
print(value) # 输出: 2
print(my_dict) # 输出: {'a': 1, 'c': 3}特点:
- 删除指定键并返回对应的值
- 可以设置默认值避免KeyError
- 需要知道确切的键名# 3. clear() - 清空字典
my_dict = {'a': 1, 'b': 2, 'c': 3}
my_dict.clear() # 清空字典
print(my_dict) # 输出: {}- 字典对象仍然存在,只是变为空字典
改:
hero['性别'] = '未知' # 对于一个原来有的键进行操作会修改
print(hero)
查:
# 可以利用 in 来判断元素在不在字典内
# 格式 查找的键 in 字典 返回值是布尔类型,可以用int转换后用变量储存下来
hero = {'姓名': '孙悟空', '性别': '男', '定位': '战士', '最佳搭档': ['八戒', '沙僧', '唐僧']}
number4 = int('姓名' in hero)
print(number4)# value函数可以输出字典的所有值
hero = {'姓名': '孙悟空', '性别': '男', '定位': '战士', '最佳搭档': ['八戒', '沙僧', '唐僧']}
print(hero.values())
# 结果为: dict_values(['孙悟空', '男', '战士', ['八戒', '沙僧', '唐僧']])
# value的作用不光只是显示,还可以配合in进行逻辑判断
hero = {'姓名': '孙悟空', '性别': '男', '定位': '战士', '最佳搭档': ['八戒', '沙僧', '唐僧']}
print(int('孙尚香' in hero.values())) # 返回值为布尔类型
遍历:
person={'name':'zxy','age':18,'sex':'男'}
#(1) 遍历字典的key
# 方法1:直接遍历字典(默认遍历键)
for key in person:print(key) # 依次输出:name → age → sex# 方法2:使用keys()方法(更明确)
for key in person.keys():print(key)#(2) 遍历字典的value
for value in person.values():print(value)#(3) 遍历字典的key和value
for key, value in person.items():print(f"{key}: {value}") #name: zxy#(4) 遍历字典的项/元素
# 方法1:直接遍历字典项(实际就是遍历键值对)
for item in person.items():print(f"字典项: {item}") #字典项: ('name', 'zxy')
字符串的使用
# 单引号,双引号,三引号三种声明方式,三引号的优点在于可以原样输出,空格空行都会被保留
hero1 = 'hello'
hero2 = "hi"
hero3 = '''hellohi'''
print(hero1, hero2, hero3)
字符串和列表一样,也有切片和索引的访问形式
把字符串当成字符的列表

函数怎么用:
text = "Hello World"
print(len(text)) # 输出: 11text = "Hello World"
print(text.find("World")) # 输出: 6 (找到的位置)
print(text.find("Python")) # 输出: -1 (未找到)filename = "document.txt"
print(filename.startswith("doc")) # 输出: True
print(filename.endswith(".txt")) # 输出: Truetext = "I like apples"
new_text = text.replace("apples", "bananas")
print(new_text) # 输出: "I like bananas"data = "apple,banana,orange"
fruits = data.split(",")
print(fruits) # 输出: ['apple', 'banana', 'orange']text = "Python"
print(text.upper()) # 输出: "PYTHON"
print(text.lower()) # 输出: "python"text = " hello "
print(text.strip()) # 输出: "hello"words = ["Hello", "World", "Python"]
sentence = " ".join(words)
print(sentence) # 输出: "Hello World Python"
message = '王者荣耀'
print(message[0])
print(message[:2]) # 从初始位置到2这个位置
# 案例 在任意一个输入字符串中,查找是否有英雄这个子串
string = input('请输入一个字符串')
lenstr = int(len(string))
for x in range(0, lenstr):if string.find('英雄') >= 0:# find函数可以查找,如果找到显示第一个字符的位置,如果没找到会返回-1print('有英雄这个子串')breakelse:if x == lenstr - 1 :print('没有英雄这个子串')else:continue
print(string.startswith('王者'))
print(string.endswith('王者'))
# startswitch函数可以判断是否以某某字符或字符串开头,返回值为布尔类型
# endswitch函数可以判断是否以某某字符或字符串结尾,返回值为布尔类型
字符串与列表相互转换方法
一、字符串转换为列表
- 使用
split()方法按分隔符拆分
text = "apple,banana,orange"
fruit_list = text.split(",") # 按逗号分隔
print(fruit_list) # 输出: ['apple', 'banana', 'orange']
- 直接使用
list()函数将字符串转为字符列表
text = "hello"
char_list = list(text)
print(char_list) # 输出: ['h', 'e', 'l', 'l', 'o']
- 使用列表推导式处理复杂字符串
text = "1,2,3,4,5"
num_list = [int(x) for x in text.split(",")]
print(num_list) # 输出: [1, 2, 3, 4, 5]
二、列表转换为字符串
- 使用
join()方法连接列表元素
word_list = ['Hello', 'World', 'Python']
sentence = " ".join(word_list) # 用空格连接
print(sentence) # 输出: "Hello World Python"
- 使用
str()和字符串方法处理
num_list = [1, 2, 3, 4]
num_str = str(num_list) # 直接转为字符串表示
print(num_str) # 输出: "[1, 2, 3, 4]"
- 使用
map()和join()处理非字符串列表
num_list = [1, 2, 3, 4]
num_str = ",".join(map(str, num_list))
print(num_str) # 输出: "1,2,3,4"
元组
元组的元素不可修改
访问元组
tuple=(1,2,3,4)
print(tuple[1])
定义只有一个元素的元组,必须在元素后面加个逗号
a=(11,)
第七讲 函数
- 函数的作用与定义
# 函数格式(定义)
def sum(num):
# def关键字表示定义一个函数 sum是函数名 num是形参可以有多个result = 0for x in range(1, num+1):result += xprint(result)
# 要注意缩进,以及分号的使用
# 函数调用
# 调用格式: 函数名(参数)这里参数是实参
def sum(num):result = 0for x in range(1, num+1):result += xprint(result)
number = 1
sum(number) #函数名调用
案例
定义一个函数来实现用户的登录
def login():username = input('输入用户名')password = input('输入密码')if username == 'admin' and password == '123456':print('登录成功')else:print('登录失败')login()
定义时小括号中的参数,用来接收参数用的,称为"形参"
调用时小括号中的参数,用来传递给函数用的,称为"实参"
- 函数的参数
# 有参传参,无参空着,顺序一致
def milk_tea(n,kind='波霸奶茶'): # n表示奶茶数量,kind表示奶茶种类# 默认参数一定要在普通参数后,默认参数可以不传参使用默认值# 可以有很多默认参数但一定要在所有普通参数结束后再写默认参数for i in range(n):print('正在制作第{}杯奶茶'.format(i+1))print('放入{}的原材料'.format(kind))print('调制奶茶')print('倒入奶茶')print('封口')
milk_tea(5)
milk_tea(1, '珍珠奶茶')
milk_tea(4, '椰果奶茶')
milk_tea(5, '黑糖珍珠奶绿')
关键字参数
def milk_tea(n, kind='波霸奶茶',price=15): # n表示奶茶数量,kind表示奶茶种类print('顾客您需要的{},每杯{}元,应收{}元'.format(kind,price,n*price))for i in range(n):print('正在制作第{}杯奶茶'.format(i+1))print('放入{}的原材料'.format(kind))print('调制奶茶')print('倒入奶茶')print('封口')
milk_tea(1)
milk_tea(2, '原味奶茶')
milk_tea(n=4, kind='原味奶茶',price=18) # 关键字参数可以自定义传输
- 返回值
# 计算从1到num的和
def ger_sum(num):total = 0for i in range(1, num + 1): # 直接从1开始遍历total += ireturn total
num=5
num1 = int(num)
result = ger_sum(num1)
print('result = {}'.format(result))
关键字是return,存在函数中
- 局部变量和全局变量
局部变量:在函数内部定义的变量,称为局部变量,只能在函数内部使用
全局变量:函数外部定义的
第八讲 面向对象基础
知识讲解
一类人或一类车等的定义方法用列表太过复杂,所以抽象出类这一概念
面向过程编程(把大象放进冰箱需要几步)
- 把冰箱门打开
- 把大象装进去
- 把冰箱门关上
面向对象编程(大象,冰箱的种类,具象化目标具象化实现)
- 类的定义
# class 类名:
# 属性
# 方法
要求
-
类的首字母必须大写
-
类名后面必须有冒号
-
类体有缩进
-
类的方法:类中定义的函数称为方法
类中的方法定义与函数定义基本相同,区别有:
-
方法中的第一个参数必须是self,而且不能省略
-
方法的调用实例化类,并以“实例名.方法名”形式调用
-
整体进行一个单位的缩进,表示其属于类中的内容
-
面向对象三大特征:
- 多态:同一个方法调用由于对象不同会产生不同的方法
- 封装:隐藏对象的属性和实现细节,只对外提供必要的方法。通过私有属性,私有方法的方式,实现封装
- 继承:继承可以让子类具有父类的特性,提高代码的重用性
代码示例:
- 类的定义
class Phone:pass
# 在python中 pass是空语句,是为了保持程序结构的完整性。pass不做任何事情,一般用于占位有语句,支撑结构
class Phone:brand = '华为'color = '黑色'type = 'Mate30 pro'price = 9999
# 定义行为和函数相似,只是必须带上一个参数selfdef call(self):print('打电话')def send_message(self):print('可以发信息')
class Saiya:name = '悟空'hair = '固定'has_tail = Trueappetite = '大'def fight(self):print('我们赛亚人就是喜欢战争')
- 类的使用类的定义主要用途是把一个类的所有特征抽象出来,而用到具体对象时则需要讲抽象的特征一一赋值一一对应
# 对象名 = 类名(参数),其中参数是可选参数,可有可无
phone1 = Phone()
phone2 = Phone()
phone3 = Phone()
print(phone1)
print(phone2)
print(phone3)
# 访问方式 对象名.属性名 or 对象名.方法名
print(phone1.price)
- 属性添加的方式
# __init__魔术构造方法也就是构造函数,会在开始时自动调用
class Person:country = '中国'def __init__(self,name):
# self表示对象本身,self.name = name表示在当前对象中增加一个属性并且赋值(在这里也就是Person)print('我是一个__init__方法')self.name =namedef eat(self):print('我是一个吃货')
p1 = Person('龟龟')
p2 = Person(name = '兔兔')
p1.eat()
p2.eat()
1. 通过外层的对象动态添加
2. 使用构造函数添加
- 类的方法的定义与调用
class Person:name = '悟空'def __init__(self,name):self.name =namedef eat(self):print('我是一个吃货')def sprot(self, time):if time < 6:print(self.name + '你怎么这么勤快,这么早就起床了')else:print(self.name + '怎么这么爱睡懒觉!')self.eat()
p1 = Person(name = '龟龟')
p2 = Person(name = '兔兔')
p1.sprot(time=3)
p2.sprot(time=7)
- 类的封装
#前面加双下划线"__"使其变成私有
class Dog:#设置私有属性__legs=4
# 内部设置方法def print_legs_count(self):print(f'狗有{self.__legs}条腿')# 实例化小狗
my_dog=Dog()
my_dog.print_legs_count()
用get/set方法
class Dog:__legs=4def get_legs(self):return self.__legsdef set_legs(self,legs):self.__legs=legsmy_dog=Dog()
print(my_dog.get_legs())
my_dog.set_legs(2)
print(my_dog.get_legs())
- 类的继承
class Person:def __init__(self, name):self.name = namedef eat(self):print(self.name + '我是一个吃货')class Saiya(Person): # Saiya 继承 Persondef sport(self, time):if time < 6:print(self.name + '你怎么这么勤快,这么早就起床了')else:print(self.name + '怎么这么爱睡懒觉!')self.eat() # 调用父类的 eat() 方法# 实例化 Saiya 并测试方法
saiya1 = Saiya("悟空") # 创建对象,自动调用 __init__
saiya1.eat() # 调用继承自 Person 的方法
saiya1.sport(4) # 调用 Saiya 新增的方法(早睡情况)
saiya1.sport(8) # 调用 Saiya 新增的方法(懒睡情况)
super()实现
class Person:def __init__(self, name):self.name = namedef eat(self):print(self.name + '我是一个吃货')class Saiya(Person):def __init__(self, name):super().__init__(name) # 调用父类的 __init__def sport(self, time):if time < 6:print(self.name + '你怎么这么勤快,这么早就起床了')else:print(self.name + '怎么这么爱睡懒觉!')super().eat() # 显式调用父类的 eat()# 测试
saiya1 = Saiya("悟空")
saiya1.eat() # 输出: 悟空我是一个吃货
saiya1.sport(4) # 输出: 悟空你怎么这么勤快... \n 悟空我是一个吃货
saiya1.sport(8) # 输出: 悟空怎么这么爱睡懒觉! \n 悟空我是一个吃货
多继承语法格式
class A:pass
class B:pass
class C(A,B):pass
class Dog:def __init__(self,name):self.name=namedef show_info(self):print(f'狗的名字叫做{self.name}')def run(self):print('狗跑的很快')
class Husky:def __init__(self,name):self.name=namedef show_info(self):print(f'哈市其的名字叫:{self.name}')def run(self):print("哈士奇跑得快")def sofa(self):print("哈士奇咬沙发")class MyDog(Dog,Husky):def __init__(self,name,age):super().__init__(name)self.age=agedef show_info(self):print(f'MyDog的名字叫:{self.name}')my_dog=MyDog('小嘎',4)
my_dog.run() #输出狗跑的很快
my_dog.sofa() #输出哈士奇咬沙发
my_dog.show_info() #输出:MyDog的名字叫:小嘎
第九讲 模块
- 模块简介与导入
#创建一个文件test_module_1.py
#创建一个自定义模块
#自定义模块
test_name='自定义模块test_module_1的变量'
def test_function():print("自定义模块test_module_1的函数")
编写主程序
import test_module_1
print(test_module_1.test_name)
test_module_1.test_function()
当导入多个模块的时候,并且模块内有同名的功能,这时候调用同名功能用的是后导入的功能查看模块位置
import sys
print(sys.path)
输出:
['E:\\python', 'E:\\python', 'D:\\Program Files\\JetBrains\\PyCharm 2023.3.7\\plugins\\python\\helpers\\pycharm_display', 'D:\\Program Files\\Python312\\python312.zip', 'D:\\Program Files\\Python312\\DLLs', 'D:\\Program Files\\Python312\\Lib', 'D:\\Program Files\\Python312', 'C:\\Users\\ASUS\\AppData\\Roaming\\Python\\Python312\\site-packages', 'D:\\Program Files\\Python312\\Lib\\site-packages', 'D:\\Program Files\\JetBrains\\PyCharm 2023.3.7\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
- 自定义包包就是一个文件夹其中必须包含一个__init__.py 的文件。这个可以是一个空文件,仅表示该目录是个包。包可以嵌套,即把子包放在某个包中包可以看作同一目录中的模块在Python中首先需要先使用目录名,然后使用模块名导入需要的模块举个例子:建包:my_package建完自动生成__init__.py空文件
#在包下创立文件package_module_1.py
def print_info():print("my_package中的模块1的函数")
#在包下创立文件package_module_2.py
def print_info():print("my_package中的模块2的函数")
在demo.py调用这两个模块:
from my_package import package_module_1,package_module_2
package_module_1.print_info()
package_module_2.print_info()
- 系统内置模块
- time模块
- random模块
- os模块
# 可以获取当前的时间戳
import time
t1 = time.time()
print(time.ctime(t1))
# 利用sleep函数进行每隔一秒循环进行一次
import time
for i in range(5):print(i)time.sleep(1)
# datetime
# datetime中封装了date,time,datetime,timedelta其中timedelta是值时间差
from datetime import *
print(datetime.now())
dt = datetime.now()
dt1 = dt + timedelta(days=-1) # 表示日期-1
print(dt, dt1, sep='\n')
import random
print(random.random()) # 表示从0到1的随机小书
print(random.randint(1, 10))
# 表示从1到10的随机整数(包括1和10)
print(random.randrange(1, 10))
# 表示从1到10的随机整数(不包括10)
print(random.choice(range(10)))
# random.choice(列表或数据集),表示从列表或数据集中随机获取一个元素,起到定范围而又随机的作用
import os
# 查看当前工作目录
result1 = os.getcwd()
print(result1)
# 在当前文件夹中创建一个文件夹
# os.mkdir()只能创建一级目录。而os.makedirs()可以创建多级目录。
os.mkdir('images')
# 获取当前环境变量
print(os.environ)
# 获取绝对路径
result = os.path.abspath('harry.py')
print(result)
# os.listdir('package')查看文件列表
# os.remove('package/text.py')删除某个模块
注意以下操作只能针对同级或下级文件,如harry.py中使用下面代码则会报错,一定要在与package同级的.py文件中操作才有用
result = os.listdir('package')
print(result)
os.remove('package/text.py')
# 查看文件大小
path = './package/harry.py' # .表示当前目录下
result = os.path.getsize(path)
print(result)
# 查看是否为文件
result1 = os.path.isfile('path')
print(result1)
# 查看是否为文件夹
result1 = os.path.isdir('path')
print(result1)
第十讲 文件操作和异常处理
文件操作
文件的打开与关闭
打开文件/创建文件
open(文件路径,访问模式)
f=open('test.txt','w')

访问模式:w 可写 r 可读

fp=open('test.txt','w')
fp.write('hello world
fp.close()
文件的读写
文件的序列化和反序列化
文件的异常处理
# 格式
try:可能会有异常的代码
except:发生异常的时候要执行的代码
finally:无论是否有异常都要执行的代码
# 方法1
content = None
try:stream = open('records.txt', mode='r', encoding='utf-8')content = stream.read()
except:print('文件找不到')
finally:print(content)# 这段代码逻辑就是,设置变量为空,如果文件可以找到并打开,将改空代码重新赋值并且输出,如果文件无法找到并打开,则会输出except的提示语句,并且输出空。这样就可以避免了报错导致程序异常终止
输出:
文件找不到
None
# with关键字的使用
with 表达式 as 变量:语句
with open('records.txt',mode='r',encoding='utf-8') as stream: content = stream.read() print(content)
第十一讲 多任务的介绍
想要实现多个函数同时执行就要使用多任务,充分利用CPU资源
多任务就是电脑同一时间内执行多个任务
两种表现形式:并发和并行
进程的介绍
进程是资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位
说白了:一个正在运行的程序就是进程
def func_a():print("任务A")
def func_b():print("任务B")
func_a()
func_b()
是否可以让func_a和func_b同时运行呢?用多进程就可以
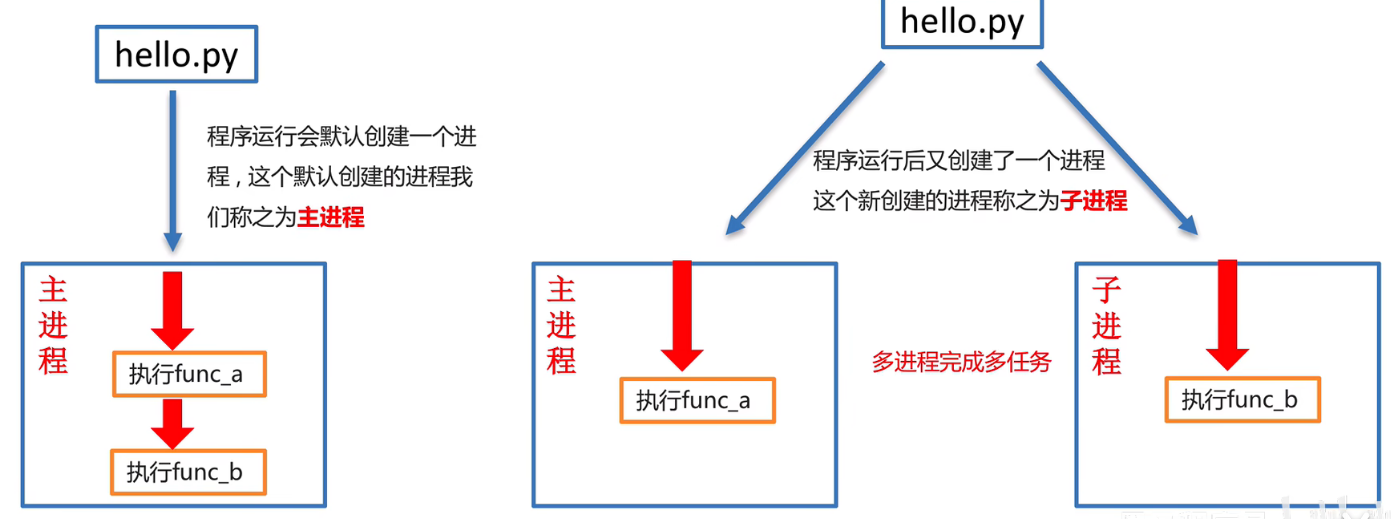
多进程是python实现多任务的一种方式
多进程完成多任务
进程创建步骤
- 导入进程包。import multiprocessing
- 通过进程类创建进程对象。 进程对象=multiprocessing.Process(target=任务名)
- 启动进程执行任务。 进程对象.start()
注意第二步,括号里面歧视有很多参数
| 参数 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 进程名,一般不用设置 |
| group | 进程组,目前只能用None |
# 创建子进程
coding_process=multiprocessing.Process(target=coding)
# 创建子进程
music_process=multiprocessing.Process(target=music)
#启动进程
coding_process.start()
music_process.start()
举个例子:
单任务
import time
def coding():for i in range(3):print("coding...")time.sleep(0.2)
#听音乐
def music():for i in range(3):print("music...")time.sleep(0.2)if __name__=='__main__':coding()music()改进成多任务:
import time
import multiprocessingdef coding():for i in range(3):print("coding...")time.sleep(0.2)
#听音乐
def music():for i in range(3):print("music...")time.sleep(0.2)if __name__=='__main__':# 创建子进程coding_process = multiprocessing.Process(target=coding)# 创建子进程music_process = multiprocessing.Process(target=music)# 启动进程coding_process.start()music_process.start()
程序运行起来就默认创建一个主进程,两个子进程是主进程创建的,两个子进程是2个主进程启动的
进程执行带参数的任务
| 参数名 | 说明 |
|---|---|
| args | 以元组的方式给执行任务传参,一i的那个要和参数的顺序保持一致 |
| kwargs | 以字典的方式给执行任务传参,传参字典中的key一定要与参数名保持一致 |
args参数的使用
coding_process = multiprocessing.Process(target=coding,args=(3,))
coding_process.start()
kwargs参数的使用
#kwargs:表示以字典的方式给函数传参
coding_process = multiprocessing.Process(target=coding,kwargs={"num":3})
coding_process.start()
举个例子:
import time
import multiprocessingdef coding(num,name):for i in range(num):print("coding...")print(name)time.sleep(0.2)
#听音乐
def music(count):for i in range(count):print("music...")time.sleep(0.2)if __name__=='__main__':# 创建子进程coding_process = multiprocessing.Process(target=coding,args=(3,"zxy"))# 创建子进程music_process = multiprocessing.Process(target=music,kwargs={"count":2})# 启动进程coding_process.start()music_process.start()获取进程编号
当程序中的进程越来越多,就无法区分主进程和子进程和不同的子进程。实际上为了方便管理,每个进程都是有自己的编号的,通过获取编号就可以快速区分不同的进程
- 获取当前进程编号 getpid()方法
- os.getpid()的使用
import os
def work():#获取当前进程的编号print("work进程编号:",os.getpid())
- 获取当前父进程编号 gerppid()方法
- os.getppid()的使用
if __name__=='__main__':#获取主进程print("主进程>>>%d"%os.getppid())# 创建子进程coding_process = multiprocessing.Process(target=coding)# 创建子进程music_process = multiprocessing.Process(target=music)# 启动进程coding_process.start()music_process.start()
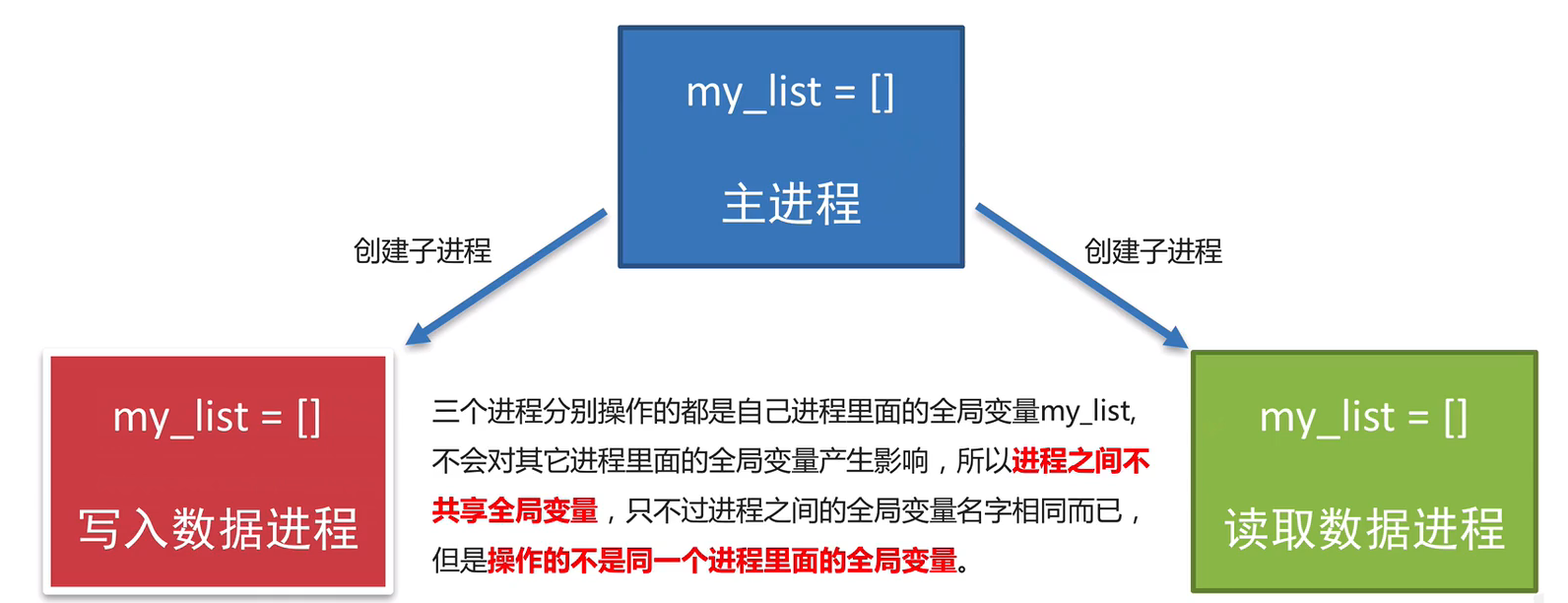
进程间不共享全局变量
进程间是不共享全局变量的
实际上创建一个子进程就是把主进程的资源进行拷贝产生了一个新的进程,这里主进程和子进程是相互独立的
也就是说操作的不是一个进程里面的全局变量,只不过是不同进程里面的全局变量名字相同而已
验证:
#定义全局变量
import multiprocessingmy_list=[]#写入数据函数
def write_data():for i in range(3):my_list.append(i)print("add:",i)print(my_list)#读取数据函数
def read_data():print(my_list)if __name__=='__main__':# 创建写入数据的进程write_process=multiprocessing.Process(target=write_data)#创建读取数据进程read_process = multiprocessing.Process(target=read_data)write_process.start()read_process.start()
运行结果:
add: 0
add: 1
add: 2
[0, 1, 2]
[]
主进程和子进程的结束顺序
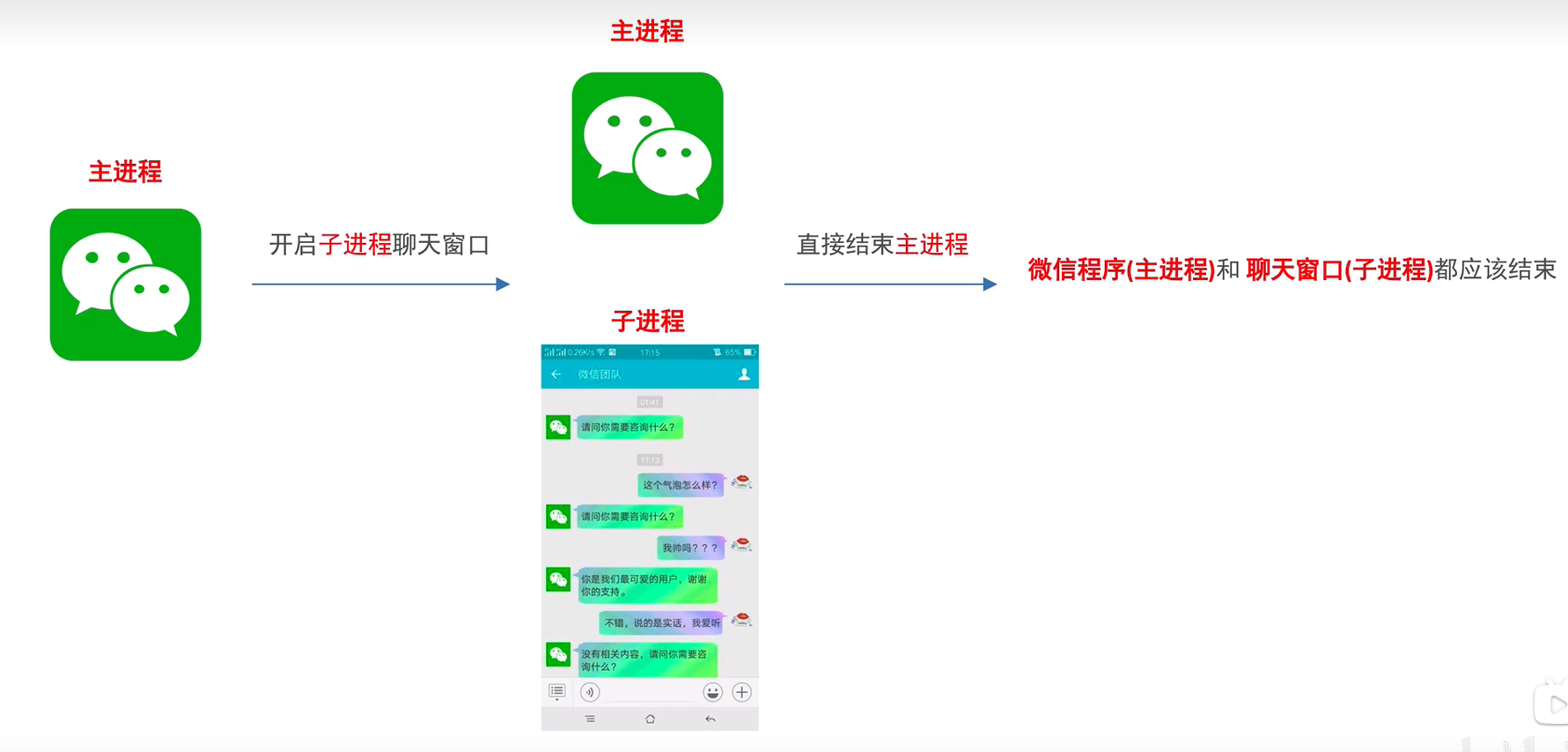
主进程会等待所有的子进程执行结束再结束
import multiprocessing
import time
#工作函数
def work():for i in range(10):print("工作中。。。")time.sleep(0.2)if __name__=='__main__':#创建子进程work_process=multiprocessing.Process(target=work)#启动子进程work_process.start()#延时一秒time.sleep(1)print("主程序执行完毕")
结果:
工作中。。。
工作中。。。
工作中。。。
工作中。。。
工作中。。。
主程序执行完毕
工作中。。。
工作中。。。
工作中。。。
工作中。。。
工作中。。。
如何保证主进程销毁之后子进程也直接销毁?
设置守护主进程 : 主进程.daemon=True
import multiprocessing
import time
#工作函数
def work():for i in range(10):print("工作中。。。")time.sleep(0.2)if __name__=='__main__':#创建子进程work_process=multiprocessing.Process(target=work)#设置守护主进程,主进程退出后子进程直接销毁,不再执行子进程中的代码work_process.daemon=True#启动子进程work_process.start()#延时一秒time.sleep(1)print("主程序执行完毕")
输出:
工作中。。。
工作中。。。
工作中。。。
工作中。。。
工作中。。。
主程序执行完毕
另外一种方式:手动销毁子进程 子进程.terminate()
import multiprocessing
import time
#工作函数
def work():for i in range(10):print("工作中。。。")time.sleep(0.2)if __name__=='__main__':#创建子进程work_process=multiprocessing.Process(target=work)#启动子进程work_process.start()#延时一秒time.sleep(1)#让子进程直接销毁,表示终止运行,主进程退出之前,把所有的子进程直接销毁就可以了work_process.terminate()print("主程序执行完毕")
第十二讲 网络
网络是将具有独立功能的多台计算机通过通信线路和通信设备连接起来,在网络管理软件及网络通信协议下,实现资源共享和信息传递的虚拟平台
学习网络的目的是编写基于网络通信的软件或程序,通常来说就是网络编程
IP地址介绍
IP地址是分配给网络设备上网使用的数字标签,它能够标识网络中唯一的一台设备
IP地址分为两类:IPv4(目前使用的)和IPv6
ifconfig和ping命令
ifconfig:查看网卡信息
127.0.0.1代表本机(也称localhost)
ping:检查网络是否正常
ping 本机通了说明本机网络没问题
端口和端口号
每个运行的程序都有一个端口,想要给对应程序发送数据,找到对应的端口即可
端口就是传输数据的通道,想要找到端口找到端口号即可
端口号就是一个数字
端口号有65536个
用IP地址找到对应的设备,通过端口号找到对应的端口,然后通过端口把数据给应用程序
端口号可分为:知名端口号(0到1023,这些端口号通常分配给一些固定的任务,比如21端口分配给FTP服务,25端口分配给SMTP服务,80端口分配给HTTP服务)和动态端口号(1024到65536,开发过程若为指定则操作系统在这个范围内随机生成一个给开发的应用程序使用)
socket分类
socket(套接字)是程序之间网络通信的一个工具,好比知道对方的电话号码才能给对方打电话,程序之间想要进行通信需要基于这个socket
程序之间网络数据的传输可以通过socket来完成
TCP
数据不能乱发送,发送之前要选择网络传输方式(传输协议),保证程序之间按照指定的传输规则进行数据的通信
TCP简称传输控制协议,面向连接的,可靠的,基于字节流的传输层通信协议
通信步骤:创建连接,传输数据,关闭连接。


python3编码转换
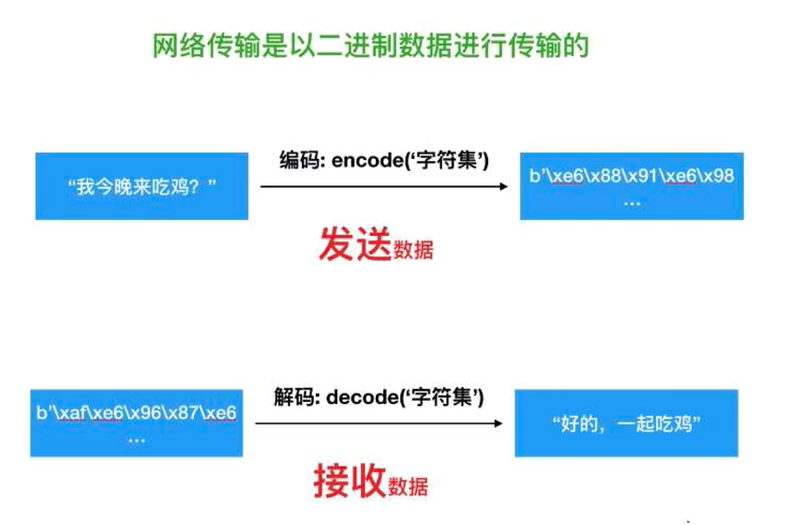
数据转化用到了:
| 函数名 | 说明 |
|---|---|
| encode | 编码 将字符串转换为字节码 |
| decode | 解码 将字节码转化为字符串 |
encode()和decode()函数可以接受参数,encoding是指在编解码过程中使用的编码方案
bytes.decode(encoding=“utf-8”)
str.encode(encoding=“utf-8”)
TCP客户端程序开发
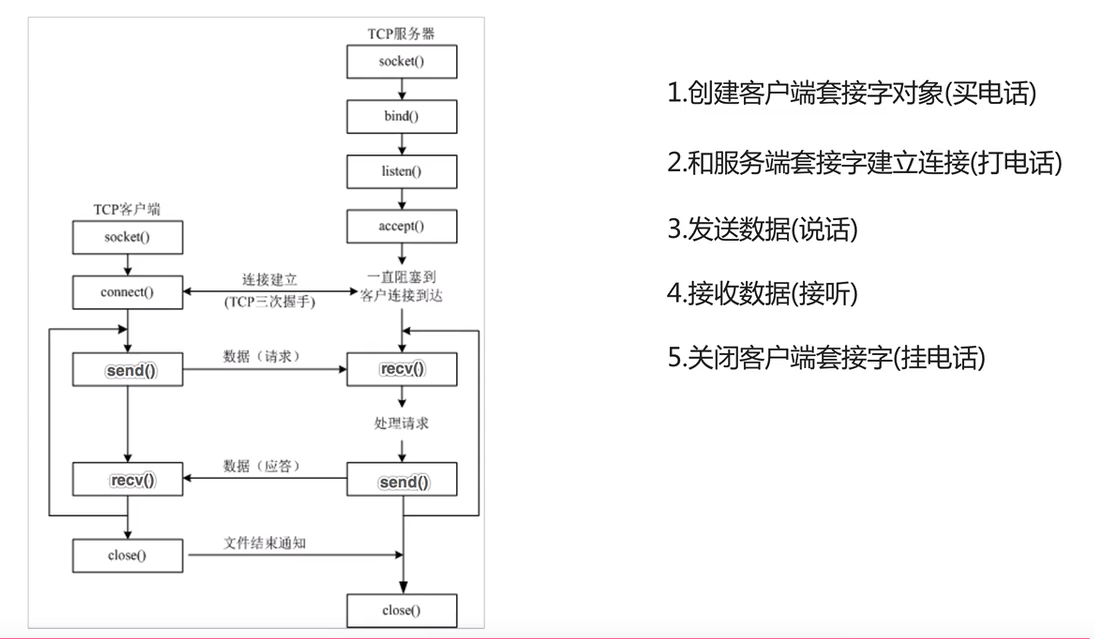
主动发起建立连接请求的是客户端程序
等待接受连接请求的是服务端程序
客户端socket类的参数和方法说明:
| 参数名 | 说明 |
|---|---|
| AddressFamily | IP地址类型,分为IPv4(AF_INET)和IPv6 |
| Type | 传输协议类型(SOCK_STREAM) |
要用到的函数
| 方法名 | 说明 |
|---|---|
| connect | 和服务端套接字建立连接 |
| send | 发送数据 |
| recv | 接收数据 |
| close | 关闭连接 |
# 模板
# 导入socket模块
import socket
#创建客户端socket对象使用socket类
socket.socket(AddressFamily,Type)
举个例子:
客户端:client.py
import socketif __name__ == '__main__':try:# 1. 创建 sockettcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 2. 连接 Node.js 服务器tcp_client_socket.connect(("127.0.0.1", 8080)) # 确保端口一致# 3. 发送数据tcp_client_socket.send("Hello Node.js Server!".encode("utf-8"))# 4. 接收服务器回复,,rece阻塞等待数据的到来recv_data = tcp_client_socket.recv(1024)print("服务器回复:", recv_data.decode("utf-8"))# 5. 关闭连接tcp_client_socket.close()except Exception as e:print("发生错误:", e)
服务端 server.js
const net = require('net');// 创建 TCP 服务器
const server = net.createServer((socket) => {console.log(`客户端已连接: ${socket.remoteAddress}:${socket.remotePort}`);// 接收客户端数据socket.on('data', (data) => {console.log(`收到客户端消息: ${data.toString()}`);socket.write("你好,我是Node.js服务器!"); // 回复客户端});// 客户端断开连接socket.on('end', () => {console.log('客户端已断开连接');});
});// 监听 8080 端口
server.listen(8080, '0.0.0.0', () => {console.log('服务器已启动,等待客户端连接...');
});
先运行服务端再运行客户端
TCP服务端程序开发
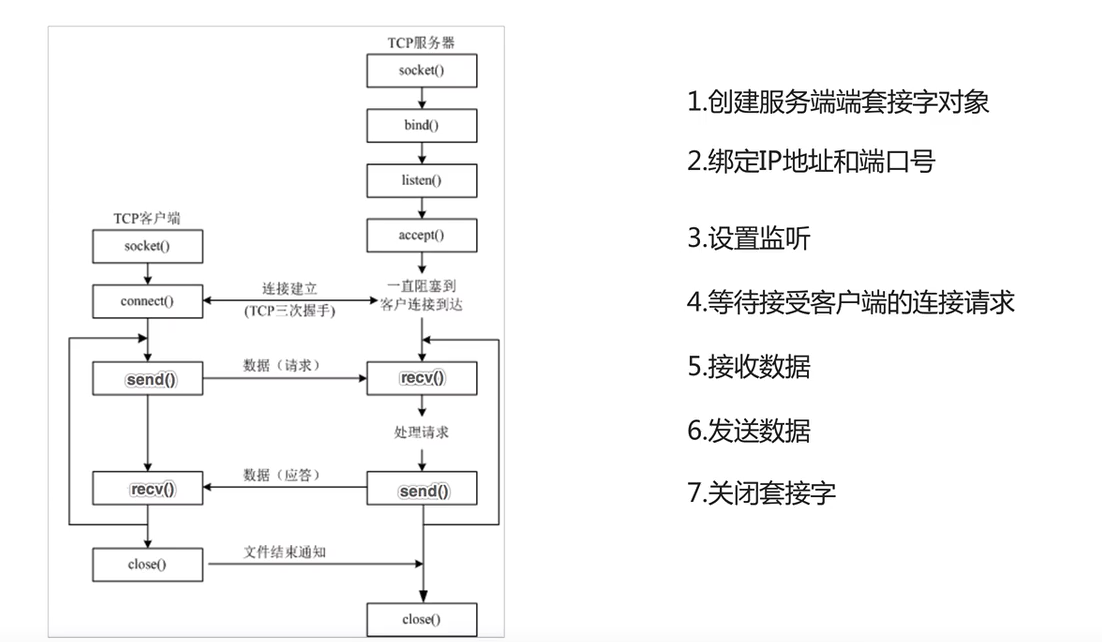
TCP服务端程序开发相关函数:
| 方法名 | 说明 |
|---|---|
| bind | 绑定IP地址和端口号,参数1:元组,如:(’ ',端口号),元组里面第一个元素是IP地址,一般不需要设置。第二个元素是启动程序后使用的端口号 |
| listen | 设置监听,参数1:最大等待连接数 |
| accept | 等待接收客户端的连接请求 |
| send | 发送数据,参数1:要发送的二进制数据,注意:字符串要用encode()方法进行编码 |
| recv | 接收数据,参数1:表示每次接收数据的大小,单位是字节,注意:解码成字符串使用decode()方法 |
举个例子:
服务端 server.py
import socket
if __name__=='__main__':# 创建服务端套接字对象。tcp_server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)# 绑定IP地址和端口号#如果bind中的第一个参数IP地址元素设置为"",默认为本机IP地址tcp_server_socket.bind(("",8080))# 设置监听128:代表服务端等待连接排队的最大数量tcp_server_socket.listen(128)# 等待接受客户端的连接请求 accept阻塞等待conn_socket,ip_port=tcp_server_socket.accept()print("客户端地址:",ip_port)# 接收数据recv_data=conn_socket.recv(1024)print("接收到的数据是:",recv_data.decode())# 发送数据conn_socket.send("客户端你的数据我收到了".encode())# 关闭套接字conn_socket.close()tcp_server_socket.close()# 输出:
# 客户端地址: ('127.0.0.1', 57402)
# 接收到的数据是: 你好,服务端!
客户端 client.py
import socketif __name__ == '__main__':try:# 1. 创建客户端套接字(IPv4, TCP)tcp_client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)# 2. 连接服务端(假设服务端运行在本机 8080 端口)server_ip = "127.0.0.1" # 本机回环地址server_port = 8080tcp_client_socket.connect((server_ip, server_port))print("已连接到服务端...")# 3. 发送数据到服务端send_data = "你好,服务端!".encode("utf-8") # 编码为字节流tcp_client_socket.send(send_data)print(f"已发送数据: {send_data.decode('utf-8')}")# 4. 接收服务端的回复recv_data = tcp_client_socket.recv(1024) # 最大接收 1024 字节print(f"服务端回复: {recv_data.decode('utf-8')}")except ConnectionRefusedError:print("连接被拒绝,请检查服务端是否启动!")except Exception as e:print(f"发生错误: {e}")finally:# 5. 关闭套接字tcp_client_socket.close()print("客户端已关闭")# 输出:
# 已连接到服务端...
# 已发送数据: 你好,服务端!
# 服务端回复: 客户端你的数据我收到了
# 客户端已关闭
注意的点:

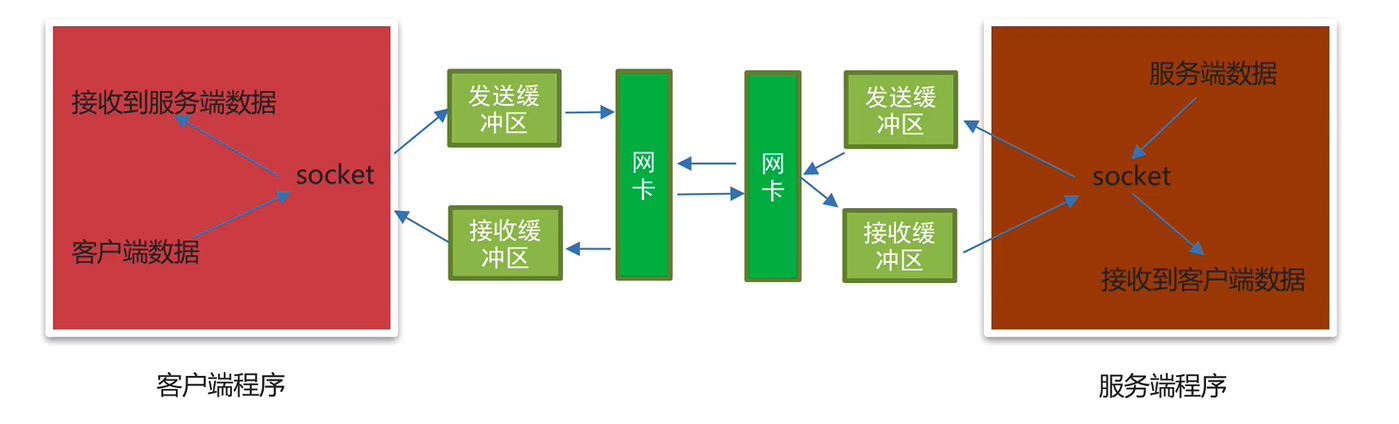
socket之send和recv原理剖析
当创建一个TCP socket对象的时候会有一个发送缓冲区和接收缓冲区,这个发送和接收缓冲区指的就是内存中的一片空间
send原理剖析:
send想发送数据,必须得通过网卡发送数据,应用程序是无法直接通过网卡发送数据的,它需要调用操作系统接口,也就是说,应用程序把发送的数据先写入到发送缓冲区(内存中的一片空间),再由操作系统控制网卡把发送缓冲区的数据发送给服务端网卡
rece原理剖析:
应用程序是无法直接通过网卡接收数据的,它需要调用操作系统接口,由操作系统通过网卡接收数据,把接收的数据写入到接收缓冲区(内存中的一片空间),应用程序再从接收缓冲区获取客户端发送的数据