使用Kiro开发项目
景说明:
Amazon推出AI代码编辑器Kiro!全新规范驱动开发,支持Claude 4,这个很厉害,重点是免费,今天示范使用 Kiro 开发一个有趣的项目:
创建一个使用DeepSeek大语言模型出题并评测其他8B以下模型的系统。这个项目将包括题目生成、模型测试和自动评分功能。来评测语言模型的智力。
下载资源在文章最后面有哦!
1. 可以使用中文与Kiro对话
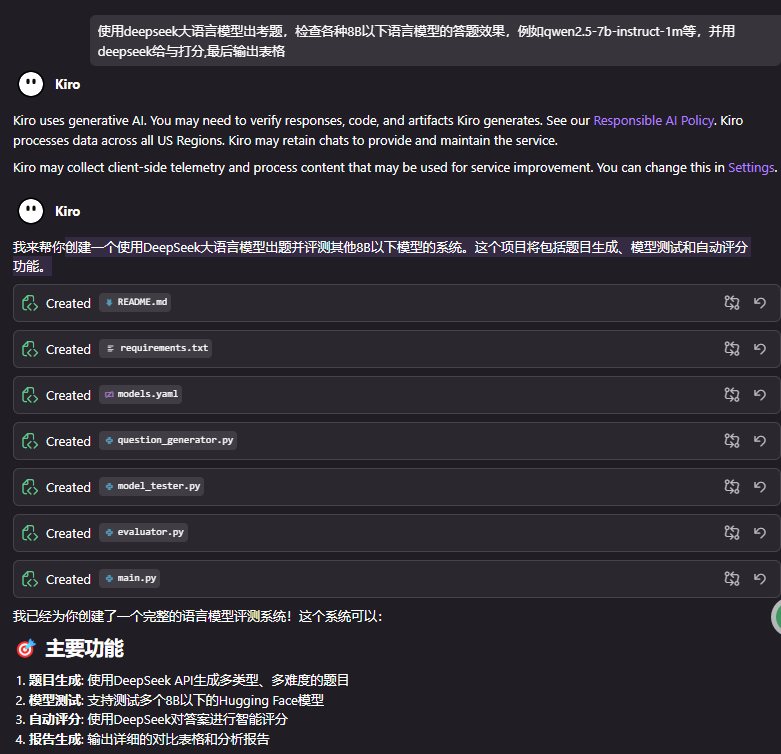
很快的 Kiro就啪啦啪啦的写完代码了:
🎯 主要功能
题目生成: 使用DeepSeek API生成多类型、多难度的题目
模型测试: 支持测试多个8B以下的Hugging Face模型
自动评分: 使用DeepSeek对答案进行智能评分
报告生成: 输出详细的对比表格和分析报告
📁 项目结构
src/question_generator.py: 使用DeepSeek生成考题
src/model_tester.py: 加载并测试各种模型
src/evaluator.py: 使用DeepSeek评分并生成报告
src/main.py: 主程序,协调整个流程
config/models.yaml: 配置文件,包含API密钥和模型设置
🚀 使用步骤
安装依赖:
pip install -r requirements.txt
配置API密钥: 编辑 config/models.yaml,填入你的DeepSeek API密钥运行完整评测:
python src/main.py --questions 30
分步运行 (可选):
# 只生成题目
python src/main.py --skip-testing --skip-evaluation# 只测试模型
python src/main.py --skip-generation --skip-evaluation# 只评估结果
python src/main.py --skip-generation --skip-testing
📊 输出结果
系统会生成:
总体排名表: 按准确率排序的模型对比
各题型表现: 不同类型题目的准确率对比
详细分析: 每个模型的具体表现和反馈
⚙️ 自定义配置
你可以在 config/models.yaml 中:
添加更多测试模型
调整题目类型和难度
修改模型参数
第一次运行结果
Kiro 误会了 从 huggingface.co 下载模型,这个是我没有说清楚
PS C:\AI\AI-learn\HW1> & c:/ProgramData/anaconda3/envs/agi-learn/python.exe c:/AI/AI-learn/HW1/src/main.py
🚀 语言模型评测系统启动
==================================================📝 步骤1: 使用通义千问生成题目
已保存 20 道题目到 data/questions.json
✅ 成功生成 20 道题目🧪 步骤2: 测试各个模型
使用设备: cpu开始测试模型: qwen2.5-7b-instruct
测试模型 qwen2.5-7b-instruct 时出错: We couldn't connect to 'https://huggingface.co' to load the files, and couldn't find them in the cached files.
Check your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.开始测试模型: llama2-7b-chat
测试模型 llama2-7b-chat 时出错: We couldn't connect to 'https://huggingface.co' to load the files, and couldn't find them in the cached files.
Check your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.开始测试模型: chatglm3-6b
测试模型 chatglm3-6b 时出错: We couldn't connect to 'https://huggingface.co' to load the files, and couldn't find them in the cached files.
Check your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
测试结果已保存到 data/results.json
✅ 模型测试完成📊 步骤3: 使用通义千问评估结果
正在评估模型: qwen2.5-7b-instruct
评分中: 0it [00:00, ?it/s]正在评估模型: llama2-7b-chat
评分中: 0it [00:00, ?it/s]正在评估模型: chatglm3-6b
评分中: 0it [00:00, ?it/s]
Traceback (most recent call last):
File "c:\AI\AI-learn\HW1\src\main.py", line 66, in <module>
main()
~~~~^^
File "c:\AI\AI-learn\HW1\src\main.py", line 53, in main
evaluator.save_evaluation(evaluated_results)
~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
File "c:\AI\AI-learn\HW1\src\evaluator.py", line 224, in save_evaluation
report = self.generate_report(evaluated_results)
File "c:\AI\AI-learn\HW1\src\evaluator.py", line 161, in generate_report
"平均分": f"{stats['average_score']:.2f}",
~~~~~^^^^^^^^^^^^^^^^^
KeyError: 'average_score'
但是 考题还是出出来了挺棒的!把得分点都提示了!
"question_id": 19,
"type": "语言理解",
"difficulty": "困难",
"question": "以下句子中存在多重隐含意义和复杂语义结构:'如果昨天我没有忘记带伞,今天就不会因为淋雨而生病了。'请分析并回答:说话者今天是否生病了?并解释句子表达的核心因果关系。",
"standard_answer": "是的,说话者今天生病了。核心因果关系是:因为昨天忘记带伞,导致今天淋雨,最终引发了生病。",
"scoring_criteria": "满分10分。回答说话者今天生病了得4分;正确解释因果关系中'忘记带伞'导致'淋雨'得3分;进一步说明'淋雨'导致'生病'得3分。回答不完整或逻辑混乱酌情扣分。",
"max_score": 10
},
{
"question_id": 20,
"type": "逻辑推理",
"difficulty": "简单",
"question": "小明、小红和小亮三个人中,只有一个人说了真话,其他两人都说了假话。小明说:‘小红说的是真的。’ 小红说:‘小亮说的是假的。’ 小亮说:‘我才是说实话的人。’ 请问:谁说了真话?",
"standard_answer": "小亮",
"scoring_criteria": "正确回答‘小亮’得10分;回答错误或未能作答得0分。",
"max_score": 10
要求 Kiro 进行修正:
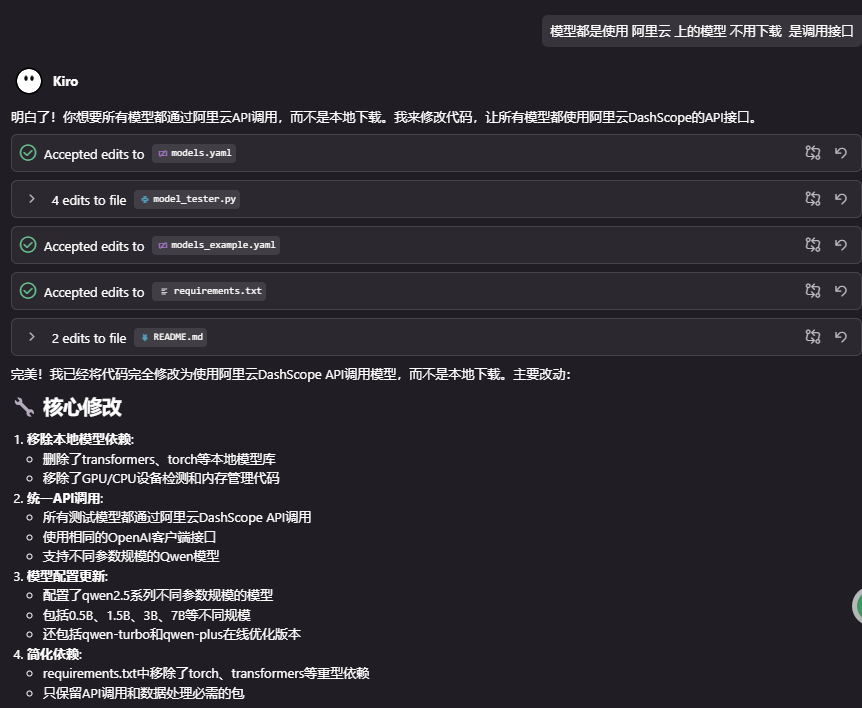
第二次 完美输出
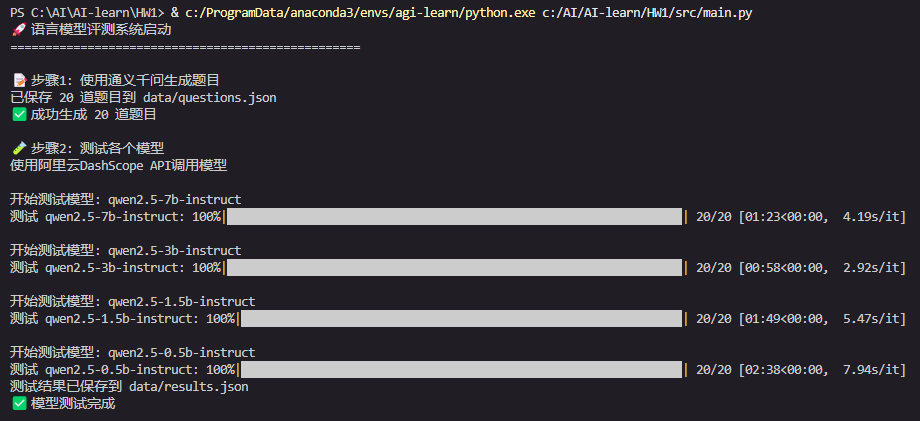
答题最快的是 qwen2.5-3b-instruct 2.92s 答一题
我们来看看评分的结果
# 语言模型评测报告
## 总体排名
| 模型名称 | 平均分 | 准确率 | 总题数 | |--------------------------|-------:|-------:|-------:| | qwen2.5-7b-instruct | 8.6 | 86.0% | 20 | | qwen2.5-3b-instruct | 8.35 | 83.5% | 20 | | qwen2.5-0.5b-instruct | 7.75 | 77.5% | 20 | | qwen2.5-1.5b-instruct | 7.15 | 71.5% | 20 |
## 各题型表现对比
| 模型 | 代码编程|常识问答 |数学计算|文本总结 |语言理解 |
|:----------------------|:-------|:-------|:-------|:-------|:-------|
| qwen2.5-7b-instruct | 90.0% | 83.3% | 60.0% | 97.5% | 100.0% |
| qwen2.5-3b-instruct | 90.0% | 100.0% | 70.0% | 85.0% | 83.3% |
| qwen2.5-1.5b-instruct | 15.0% | 83.3% | 72.0% | 77.5% | 80.0% |
| qwen2.5-0.5b-instruct | 60.0% | 46.7% | 72.0% | 82.5% | 100.0% |
✅ 结果评估完成
🎉 评测系统运行完成!
📁 结果文件:
- data/questions.json: 生成的题目
- data/results.json: 模型答题结果
- data/evaluation_results.json: 详细评估结果
- data/evaluation_report.md: 评测报告
llm中使用的 prompt
1. 出题专家
prompt = f"""
请生成一道{difficulty}难度的{q_type}题目。要求:
1. 题目要有明确的标准答案
2. 适合测试语言模型的能力
3. 题目描述清晰,不产生歧义
4. 提供详细的标准答案和评分标准请按以下JSON格式返回:
{{"question_id": {question_id},"type": "{q_type}","difficulty": "{difficulty}","question": "题目内容","standard_answer": "标准答案","scoring_criteria": "评分标准说明","max_score": 10
}}
"""try:response = self.client.chat.completions.create(model=self.config['dashscope']['model'],messages=[{"role": "system", "content": "你是一个专业的出题专家,擅长生成各种类型的测试题目。"},{"role": "user", "content": prompt}],temperature=0.8)2.答题人
messages=[{"role": "system", "content": "你是一个智能助手,请准确回答用户的问题。"},{"role": "user", "content": prompt}3.评分专家
prompt = f"""
请作为专业评委,对以下答题进行评分:题目类型:{question_type}
题目:{question}标准答案:{standard_answer}学生答案:{model_answer}评分要求:
1. 满分10分
2. 考虑答案的准确性、完整性和逻辑性
3. 给出具体的评分理由
4. 如果答案完全正确给满分,部分正确给部分分数,完全错误给0分请按以下JSON格式返回评分结果:
{{"score": 评分(0-10),"max_score": 10,"feedback": "详细的评分理由和建议"
}}
"""try:response = self.client.chat.completions.create(model=self.config['dashscope']['model'],messages=[{"role": "system", "content": "你是一个专业的评分专家,能够客观公正地评估答案质量。"},{"role": "user", "content": prompt}],temperature=0.3)我看到评分的内容,真的赞叹LLM 点赞:

相关资源
1. Kiro 下载
https://download.csdn.net/download/chenchihwen/91444400?spm=1001.2014.3001.5501![]() http://kiro安装包 现代开发的革命性AI IDE 2. 代码包
http://kiro安装包 现代开发的革命性AI IDE 2. 代码包
创建一个使用DeepSeek大语言模型出题并评测其他8B以下模型的系统 这个项目将包括题目生成、模型测试和自动评分功能 来评测语... ![]() https://download.csdn.net/download/chenchihwen/91446521
https://download.csdn.net/download/chenchihwen/91446521