深度学习-全连接神经网络2
六、反向传播算法
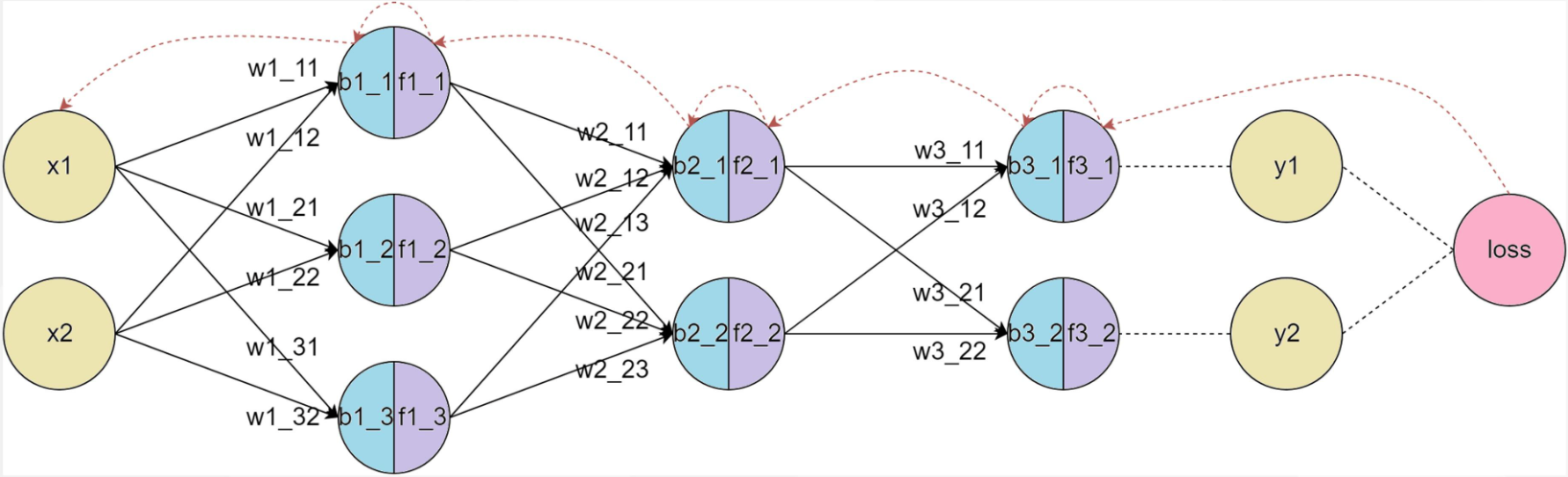
反向传播(Back Propagation,简称BP)算法是用于训练神经网络的核心算法之一,它通过计算损失函数(如均方误差或交叉熵)相对于每个权重参数的梯度,来优化神经网络的权重。
1、前向传播
前向传播(Forward Propagation)把输入数据经过各层神经元的运算并逐层向前传输,一直到输出层为止。
1.1数学表达
下面是一个简单的三层神经网络(输入层、隐藏层、输出层)前向传播的基本步骤分析。
-
输入层到隐藏层
给定输入 x 和权重矩阵 W1 及偏置向量 b1,隐藏层的输出(激活值)计算如下:
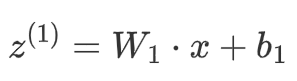
将z^(1) 通过激活函数 σ进行激活:
![]()
- 隐藏层到输出层
隐藏层的输出 a^(1) 通过输出层的权重矩阵 W2和偏置 b2 生成最终的输出:
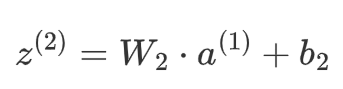
输出层的激活值 a^(2) 是最终的预测结果:
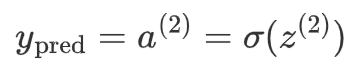
1.2作用
前向传播的主要作用是:
-
计算神经网络的输出结果,用于预测或计算损失。
-
在反向传播中使用,通过计算损失函数相对于每个参数的梯度来优化网络。
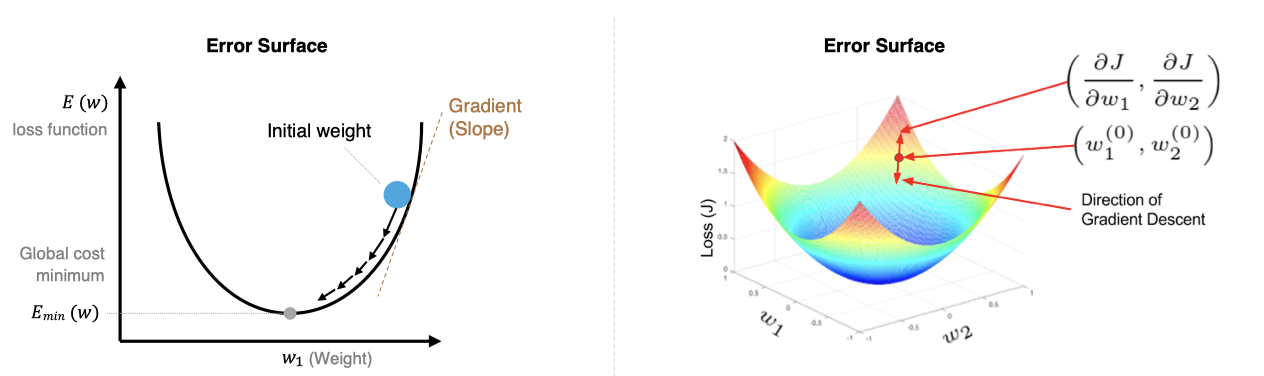
2、BP基础之梯度下降算法
梯度下降算法的目标是找到使损失函数 L(θ) 最小的参数θ,其核心是沿着损失函数梯度的负方向更新参数,以逐步逼近局部或全局最优解,从而使模型更好地拟合训练数据。
2.1数学描述
数学公式: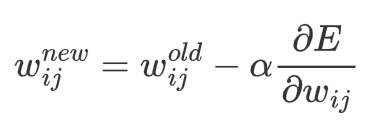
其中,α是学习率:
-
学习率太小,每次训练之后的效果太小,增加时间和算力成本。
-
学习率太大,大概率会跳过最优解,进入无限的训练和震荡中。
-
解决的方法就是,学习率也需要随着训练的进行而变化。
过程:
-
初始化参数:随机初始化模型的参数 θ ,如权重 W和偏置 b。
-
计算梯度:损失函数 L(θ)对参数 θ 的梯度 ∇_θL(θ),表示损失函数在参数空间的变化率。
-
更新参数:按照梯度下降公式更新参数:θ := θ - α ∇_θ L(θ),其中,α 是学习率,用于控制更新步长。
-
迭代更新:重复【计算梯度和更新参数】步骤,直到某个终止条件(如梯度接近0、不再收敛、完成迭代次数等)。
2.2传统下降方式
根据计算梯度时数据量不同,常见的方式有:
2.2.1批量梯度下降
Batch Gradient Descent BGD
-
特点:
-
每次更新参数时,使用整个训练集来计算梯度。
-
-
优点:
-
收敛稳定,能准确地沿着损失函数的真实梯度方向下降。
-
适用于小型数据集。
-
-
缺点:
-
对于大型数据集,计算量巨大,更新速度慢。
-
需要大量内存来存储整个数据集。
-
例如,在训练集中有100个样本,迭代50轮。
那么在每一轮迭代中,都会一起使用这100个样本,计算整个训练集的梯度,并对模型更新。
所以总共会更新50次梯度。
因为每次迭代都会使用整个训练集计算梯度,所以这种方法可以得到准确的梯度方向。
但如果数据集非常大,那么就导致每次迭代都很慢,计算成本就会很高。
2.2.2随机梯度下降
Stochastic Gradient Descent, SGD
-
特点:
-
每次更新参数时,仅使用一个样本来计算梯度。
-
-
优点:
-
更新频率高,计算快,适合大规模数据集。
-
能够跳出局部最小值,有助于找到全局最优解。
-
-
缺点:
-
收敛不稳定,容易震荡,因为每个样本的梯度可能都不完全代表整体方向。
-
需要较小的学习率来缓解震荡。
-
例如,如果训练集有100个样本,迭代50轮,那么每一轮迭代,会遍历这100个样本,每次会计算某一个样本的梯度,然后更新模型参数。
换句话说,100个样本,迭代50轮,那么就会更新100*50=5000次梯度。
因为每次只用一个样本训练,所以迭代速度会非常快。
但更新的方向会不稳定,这也导致随机梯度下降,可能永远都不会收敛。
不过也因为这种震荡属性,使得随机梯度下降,可以跳出局部最优解。
这在某些情况下,是非常有用的。
2.2.3小批量梯度下降
Mini-batch Gradient Descent MGBD
-
特点:
-
每次更新参数时,使用一小部分训练集(小批量)来计算梯度。
-
-
优点:
-
在计算效率和收敛稳定性之间取得平衡。
-
能够利用向量化加速计算,适合现代硬件(如GPU)。
-
-
缺点:
-
选择适当的批量大小比较困难;批量太小则接近SGD,批量太大则接近批量梯度下降。
-
通常会根据硬件算力设置为32\64\128\256等2的次方。
-
例如,如果训练集中有100个样本,迭代50轮。
如果设置小批量的数量是20,那么在每一轮迭代中,会有5次小批量迭代。
换句话说,就是将100个样本分成5个小批量,每个小批量20个数据,每次迭代用一个小批量。
因此,按照这样的方式,会对梯度,进行50轮*5个小批量=250次更新。
2.3存在的问题
-
收敛速度慢:BGD和MBGD使用固定学习率,太大会导致震荡,太小又收敛缓慢。
-
局部最小值和鞍点问题:SGD在遇到局部最小值或鞍点时容易停滞,导致模型难以达到全局最优。
-
训练不稳定:SGD中的噪声容易导致训练过程中不稳定,使得训练陷入震荡或不收敛。
2.4优化下降方式
通过对标准的梯度下降进行改进,来提高收敛速度或稳定性。
2.4.1指数加权平均
我们平时说的平均指的是将所有数加起来除以数的个数,很单纯的数学。再一个是移动平均数,指的是计算最近邻的N个数来获得平均数,感觉比纯粹的直接全部求均值高级一点。
指数加权平均:Exponential Moving Average,简称EMA,是一种平滑时间序列数据的技术,它通过对过去的值赋予不同的权重来计算平均值。与简单移动平均不同,EMA赋予最近的数据更高的权重,较远的数据则权重较低,这样可以更敏感地反映最新的变化趋势。
2.4.2 Momentum
动量(Momentum)是对梯度下降的优化方法,可以更好地应对梯度变化和梯度消失问题,从而提高训练模型的效率和稳定性。它通过引入 指数加权平均 来积累历史梯度信息,从而在更新参数时形成“动量”,帮助优化算法更快地越过局部最优或鞍点。

特点:
-
惯性效应: 该方法加入前面梯度的累积,这种惯性使得算法沿着当前的方向继续更新。如遇到鞍点,也不会因梯度逼近零而停滞。
-
减少震荡: 该方法平滑了梯度更新,减少在鞍点附近的震荡,帮助优化过程稳定向前推进。
-
加速收敛: 该方法在优化过程中持续沿着某个方向前进,能够更快地穿越鞍点区域,避免在鞍点附近长时间停留。
总结:
-
动量项更新:利用当前梯度和历史动量来计算新的动量项。
-
权重参数更新:利用更新后的动量项来调整权重参数。
-
梯度计算:在每个时间步计算当前的梯度,用于更新动量项和权重参数。
Momentum 算法是对梯度值的平滑调整,但是并没有对梯度下降中的学习率进行优化。
2.4.3 AdaGrad
AdaGrad(Adaptive Gradient Algorithm)为每个参数引入独立的学习率,它根据历史梯度的平方和来调整这些学习率。具体来说,对于频繁更新的参数,其学习率会逐渐减小;而对于更新频率较低的参数,学习率会相对较大。AdaGrad避免了统一学习率的不足,更多用于处理稀疏数据和梯度变化较大的问题。
AdaGrad流程:
- 初始化
- 梯度计算
- 累积梯度的平方
- 参数更新
优点:
-
自适应学习率:由于每个参数的学习率是基于其梯度的累积平方和 G_{t,i} 来动态调整的,这意味着学习率会随着时间步的增加而减少,对梯度较大且变化频繁的方向非常有用,防止了梯度过大导致的震荡。
-
适合稀疏数据:AdaGrad 在处理稀疏数据时表现很好,因为它能够自适应地为那些较少更新的参数保持较大的学习率。
缺点:
-
学习率过度衰减:随着时间的推移,累积的时间步梯度平方值越来越大,导致学习率逐渐接近零,模型会停止学习。
-
不适合非稀疏数据:在非稀疏数据的情况下,学习率过快衰减可能导致优化过程早期停滞。
AdaGrad是一种有效的自适应学习率算法,然而由于学习率衰减问题,我们会使用改 RMSProp 或 Adam 来替代。
2.4.4 RMSProp
虽然 AdaGrad 能够自适应地调整学习率,但随着训练进行,累积梯度平方 G_t会不断增大,导致学习率逐渐减小,最终可能变得过小,导致训练停滞。
RMSProp(Root Mean Square Propagation)是一种自适应学习率的优化算法,在时间步中,不是简单地累积所有梯度平方和,而是使用指数加权平均来逐步衰减过时的梯度信息。旨在解决 AdaGrad 学习率单调递减的问题。它通过引入 指数加权平均 来累积历史梯度的平方,从而动态调整学习率。
优点
-
适应性强:RMSProp自适应调整每个参数的学习率,对于梯度变化较大的情况非常有效,使得优化过程更加平稳。
-
适合非稀疏数据:相比于AdaGrad,RMSProp更加适合处理非稀疏数据,因为它不会让学习率减小到几乎为零。
-
解决过度衰减问题:通过引入指数加权平均,RMSProp避免了AdaGrad中学习率过快衰减的问题,保持了学习率的稳定性
缺点
依赖于超参数的选择:RMSProp的效果对衰减率 \gamma 和学习率 \eta 的选择比较敏感,需要一些调参工作。
2.4.5 Adam
Adam(Adaptive Moment Estimation)算法将动量法和RMSProp的优点结合在一起:
-
动量法:通过一阶动量(即梯度的指数加权平均)来加速收敛,尤其是在有噪声或梯度稀疏的情况下。
-
RMSProp:通过二阶动量(即梯度平方的指数加权平均)来调整学习率,使得每个参数的学习率适应其梯度的变化。
Adam过程
-
初始化
-
梯度计算
-
一阶动量估计(梯度的指数加权平均)
-
二阶动量估计(梯度平方的指数加权平均)
-
偏差校正
优点
-
高效稳健:Adam结合了动量法和RMSProp的优势,在处理非静态、稀疏梯度和噪声数据时表现出色,能够快速稳定地收敛。
-
自适应学习率:Adam通过一阶和二阶动量的估计,自适应调整每个参数的学习率,避免了全局学习率设定不合适的问题。
-
适用大多数问题:Adam几乎可以在不调整超参数的情况下应用于各种深度学习模型,表现良好。
缺点
-
超参数敏感:尽管Adam通常能很好地工作,但它对初始超参数(如β1、β2 和 η)仍然较为敏感,有时需要仔细调参。
-
过拟合风险:由于Adam会在初始阶段快速收敛,可能导致模型陷入局部最优甚至过拟合。因此,有时会结合其他优化算法(如SGD)使用。
2.5总结
梯度下降算法通过不断更新参数来最小化损失函数,是反向传播算法中计算权重调整的基础。在实际应用中,根据数据的规模和计算资源的情况,选择合适的梯度下降方式(批量、随机、小批量)及其变种(如动量法、Adam等)可以显著提高模型训练的效率和效果。
Adam是目前最为流行的优化算法之一,因其稳定性和高效性,广泛应用于各种深度学习模型的训练中。Adam结合了动量法和RMSProp的优点,能够在不同情况下自适应调整学习率,并提供快速且稳定的收敛表现。
import torch
from sympy.abc import alpha
from torch.utils.data import TensorDataset,DataLoader
from torch import nn,optimdef test01():model = nn.Linear(10,5)x = torch.randn(10000,10)y = torch.randn(10000,5)criterion = nn.MSELoss()# momentum:动量,根据历史梯度增加惯性# 参数值:动量系数,一般取0.9opt = optim.SGD(model.parameters(),lr=0.01,momentum=0.9)dataset = TensorDataset(x,y)# 批量梯度下降# dataloader = DataLoader(# dataset=dataset,# batch_size=len( dataset),# shuffle= True# )# 随机梯度下降,随机选择一条样本进行梯度更新# dataloader = DataLoader(# dataset=dataset,# batch_size=1,# shuffle= True# )# 小批量梯度下降dataloader = DataLoader(dataset=dataset,batch_size=64,shuffle= True)epochs = 200for epoch in range(epochs):for tx,ty in dataloader:y_pred = model(tx)loss = criterion(y_pred,ty)opt.zero_grad()loss.backward()opt.step()print(f'epoch:{epoch},loss:{loss.item()}')def test02():model = nn.Linear(10,5)x = torch.randn(1000,10)y = torch.randn(1000,5)criterion = nn.MSELoss()# Adagrad:自适应学习率优化器# 原理:历史梯度平方和作为学习率的分母,动态调整学习率# 优点:自适应动态调整学习率# 缺点:随着训练时间增加,历史梯度平方和越来越大,导致学习率越来越小,可能会停止参数更新# eps:避免学习率的分母为0,是一个非常小的数字# opt = optim.Adagrad(model.parameters(),lr=0.1,eps=1e-08)# RMSProp:自适应学习率优化器# 原理:使用指数加权平均对历史梯度平方求和,将平方和作为分母调整学习率# 优点:缓解历史梯度平方和快速变大,使学习率衰减更加平稳# 缺点:需要调整alpha参数,找到最优值# opt = optim.RMSprop(model.parameters(),lr=0.1,alpha=0.9,eps=1e-08)# Adam:自适应优化器# 结合了动量和RMSprop,既优化了梯度,又能动态调整学习率# 缺点是对参数设置比较敏感,需要根据实际情况进行调整# betas参数:是一个元组,第一个元素是一阶动量的系数0.9,第二个元素是二阶动量的系数0.999,两个系数是经验值opt = optim.Adam(model.parameters(),lr=0.1,betas=(0.9,0.999),eps=1e-08)for epoch in range(50):y_pred = model(x)loss = criterion(y_pred,y)opt.zero_grad()loss.backward()opt.step()print(f'loss:{loss.item()}')if __name__ == '__main__':# test01()test02()七、过拟合和欠拟合
在训练深层神经网络时,由于模型参数较多,在数据量不足时很容易过拟合。而正则化技术主要就是用于防止过拟合,提升模型的泛化能力(对新数据表现良好)和鲁棒性(对异常数据表现良好)。
1、概念
1.1过拟合
过拟合是指模型对训练数据拟合能力很强并表现很好,但在测试数据上表现较差。
过拟合常见原因有:
-
数据量不足:当训练数据较少时,模型可能会过度学习数据中的噪声和细节。
-
模型太复杂:如果模型很复杂,也会过度学习训练数据中的细节和噪声。
-
正则化强度不足:如果正则化强度不足,可能会导致模型过度学习训练数据中的细节和噪声。
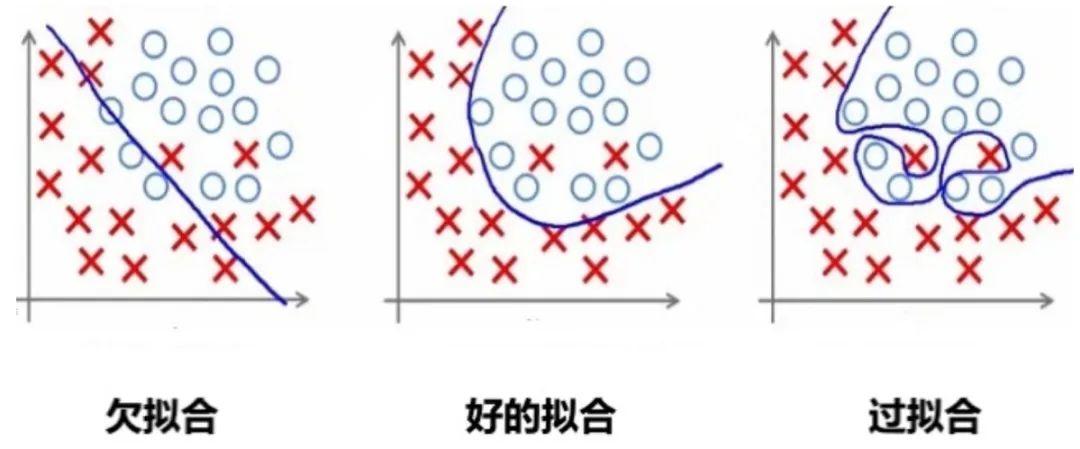
1.2欠拟合
欠拟合是由于模型学习能力不足,无法充分捕捉数据中的复杂关系。
1.3如何判断
那如何判断一个错误的结果是过拟合还是欠拟合呢?
过拟合
训练误差低,但验证时误差高。模型在训练数据上表现很好,但在验证数据上表现不佳,说明模型可能过度拟合了训练数据中的噪声或特定模式。
欠拟合
训练误差和测试误差都高。模型在训练数据和测试数据上的表现都不好,说明模型可能太简单,无法捕捉到数据中的复杂模式。
2、解决欠拟合
欠拟合的解决思路比较直接:
-
增加模型复杂度:引入更多的参数、增加神经网络的层数或节点数量,使模型能够捕捉到数据中的复杂模式。
-
增加特征:通过特征工程添加更多有意义的特征,使模型能够更好地理解数据。
-
减少正则化强度:适当减小 L1、L2 正则化强度,允许模型有更多自由度来拟合数据。
-
训练更长时间:如果是因为训练不足导致的欠拟合,可以增加训练的轮数或时间.
3、解决过拟合
避免模型参数过大是防止过拟合的关键步骤之一。
模型的复杂度主要由权重w决定,而不是偏置b。偏置只是对模型输出的平移,不会导致模型过度拟合数据。
怎么控制权重w,使w在比较小的范围内?
考虑损失函数,损失函数的目的是使预测值与真实值无限接近,如果在原来的损失函数上添加一个非0的变量
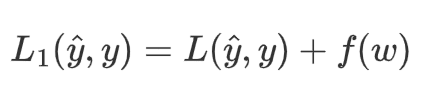
其中f(w)是关于权重w的函数,f(w)>0
要使L1变小,就要使L变小的同时,也要使f(w)变小。从而控制权重w在较小的范围内。
3.1 L2正则化
数学表达
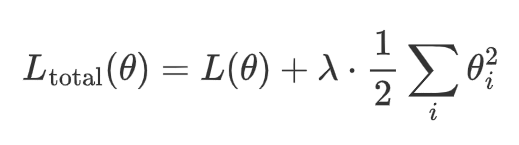
其中:
-
L(θ) 是原始损失函数(比如均方误差、交叉熵等)。
-
\lambda 是正则化强度,控制正则化的力度。
-
θi 是模型的第 i 个权重参数。
-
1/2Σ_{i} θi^2 是所有权重参数的平方和,称为 L2 正则化项。
梯度更新
在 L2 正则化下,梯度更新时,不仅要考虑原始损失函数的梯度,还要考虑正则化项的影响。更新规则为:

作用
-
防止过拟合:当模型过于复杂、参数较多时,模型会倾向于记住训练数据中的噪声,导致过拟合。L2 正则化通过抑制参数的过大值,使得模型更加平滑,降低模型对训练数据噪声的敏感性。
-
限制模型复杂度:L2 正则化项强制权重参数尽量接近 0,避免模型中某些参数过大,从而限制模型的复杂度。通过引入平方和项,L2 正则化鼓励模型的权重均匀分布,避免单个权重的值过大。
-
提高模型的泛化能力:正则化项的存在使得模型在测试集上的表现更加稳健,避免在训练集上取得极高精度但在测试集上表现不佳。
-
平滑权重分布:L2 正则化不会将权重直接变为 0,而是将权重值缩小。这样模型就更加平滑的拟合数据,同时保留足够的表达能力。
3.2 L1正则化
数学表达

梯度更新

作用
-
稀疏性:L1 正则化的一个显著特性是它会促使许多权重参数变为 零。这是因为 L1 正则化倾向于将权重绝对值缩小到零,使得模型只保留对结果最重要的特征,而将其他不相关的特征权重设为零,从而实现 特征选择 的功能。
-
防止过拟合:通过限制权重的绝对值,L1 正则化减少了模型的复杂度,使其不容易过拟合训练数据。相比于 L2 正则化,L1 正则化更倾向于将某些权重完全移除,而不是减小它们的值。
-
简化模型:由于 L1 正则化会将一些权重变为零,因此模型最终会变得更加简单,仅依赖于少数重要特征。这对于高维度数据特别有用,尤其是在特征数量远多于样本数量的情况下。
-
特征选择:因为 L1 正则化会将部分权重置零,因此它天然具有特征选择的能力,有助于自动筛选出对模型预测最重要的特征。
L1与L2对比
-
L1 正则化 更适合用于产生稀疏模型,会让部分权重完全为零,适合做特征选择。
-
L2 正则化 更适合平滑模型的参数,避免过大参数,但不会使权重变为零,适合处理高维特征较为密集的场景。
3.3 Dropout
Dropout 的工作流程如下:
-
在每次训练迭代中,随机选择一部分神经元(通常以概率 p丢弃,比如 p=0.5)。
-
被选中的神经元在当前迭代中不参与前向传播和反向传播。
-
在测试阶段,所有神经元都参与计算,但需要对权重进行缩放(通常乘以 1−p),以保持输出的期望值一致。
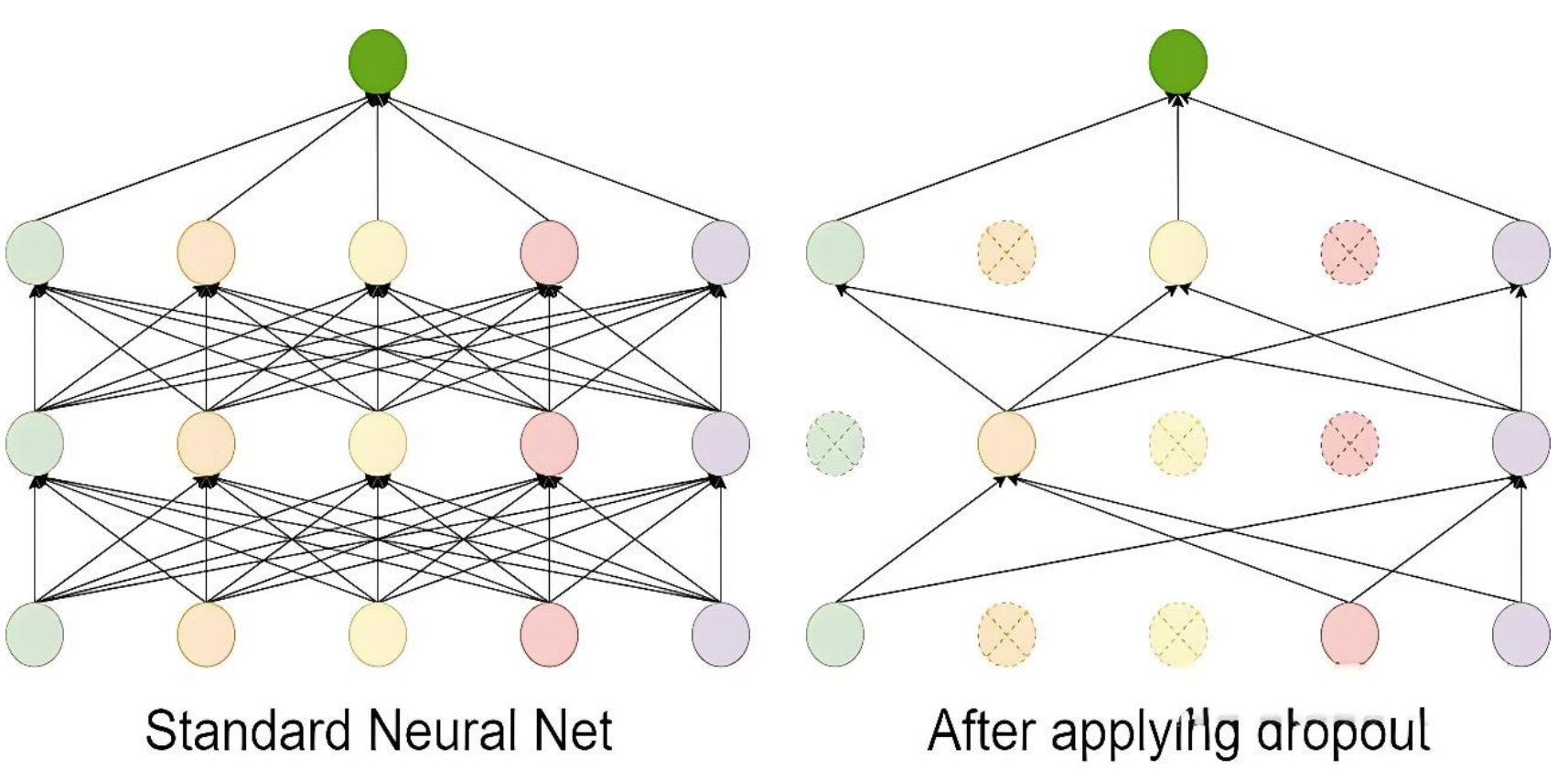
Dropout 是一种在训练过程中随机丢弃部分神经元的技术。它通过减少神经元之间的依赖来防止模型过于复杂,从而避免过拟合。
import torch
from torch import nn
from torch.onnx.symbolic_opset9 import dropoutdef test01():x = torch.randint(0,10,(5,6),dtype=torch.float)dropout = nn.Dropout(p=0.5)print(x)print(dropout(x))if __name__ == '__main__':test01()3.4数据增强
样本数量不足(即训练数据过少)是导致过拟合(Overfitting)的常见原因之一,可以从以下角度理解:
-
当训练数据过少时,模型容易“记住”有限的样本(包括噪声和无关细节),而非学习通用的规律。
-
简单模型更可能捕捉真实规律,但数据不足时,复杂模型会倾向于拟合训练集中的偶然性模式(噪声)。
-
样本不足时,训练集的分布可能与真实分布偏差较大,导致模型学到错误的规律。
-
小数据集中,个别样本的噪声(如标注错误、异常值)会被放大,模型可能将噪声误认为规律。
数据增强(Data Augmentation)是一种通过人工生成或修改训练数据来增加数据集多样性的技术,常用于解决过拟合问题。数据增强通过“模拟”更多训练数据,迫使模型学习泛化性更强的规律,而非训练集中的偶然性模式。其本质是一种低成本的正则化手段,尤其在数据稀缺时效果显著。
在了解计算机如何处理图像之前,需要先了解图像的构成元素。
图像是由像素点组成的,每个像素点的值范围为: [0, 255], 像素值越大意味着较亮。比如一张 200x200 的图像, 则是由 40000 个像素点组成, 如果每个像素点都是 0 的话, 意味着这是一张全黑的图像。
我们看到的彩色图一般都是多通道的图像, 所谓多通道可以理解为图像由多个不同的图像层叠加而成, 例如我们看到的彩色图像一般都是由 RGB 三个通道组成的,还有一些图像具有 RGBA 四个通道,最后一个通道为透明通道,该值越小,则图像越透明。
数据增强是提高模型泛化能力(鲁棒性)的一种有效方法,尤其在图像分类、目标检测等任务中。数据增强可以模拟更多的训练样本,从而减少过拟合风险。数据增强通过torchvision.transforms模块来实现。
数据增强的好处
大幅度降低数据采集和标注成本;
模型过拟合风险降低,提高模型泛化能力;
官方地址:
transforms:Transforming and augmenting images — Torchvision 0.22 documentation
transforms:
常用变换类
-
transforms.Compose:将多个变换操作组合成一个流水线。
-
transforms.ToTensor:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,将图像数据从 uint8 类型 (0-255) 转换为 float32 类型 (0.0-1.0)。
-
transforms.Normalize:对张量进行标准化。
-
transforms.Resize:调整图像大小。
-
transforms.CenterCrop:从图像中心裁剪指定大小的区域。
-
transforms.RandomCrop:随机裁剪图像。
-
transforms.RandomHorizontalFlip:随机水平翻转图像。
-
transforms.RandomVerticalFlip:随机垂直翻转图像。
-
transforms.RandomRotation:随机旋转图像。
-
transforms.ColorJitter:随机调整图像的亮度、对比度、饱和度和色调。
-
transforms.RandomGrayscale:随机将图像转换为灰度图像。
-
transforms.RandomResizedCrop:随机裁剪图像并调整大小。
3.4.1图片缩放
def test01():path = 'datasets/images/100.jpg'img = Image.open(path)print( img.size)transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()])t_img = transform(img)print(t_img.shape)t_img = torch.permute(t_img, (1,2,0))plt.imshow(t_img)plt.show()3.4.2随机裁剪
def test02():path = 'datasets/images/100.jpg'img = Image.open(path)print(img.size)transform = transforms.Compose([# 随机裁剪transforms.RandomCrop(size=(224,224)),transforms.ToTensor()])t_img = transform(img)print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.4.3随机水平翻转
RandomHorizontalFlip(p):随机水平翻转图像,参数p表示翻转概率(0 ≤ p ≤ 1),p=1 表示必定翻转,p=0 表示不翻转
def test03():path = 'datasets/images/100.jpg'img = Image.open(path)print(img.size)transform = transforms.Compose([# 随机水平翻转transforms.RandomHorizontalFlip(p=0.5),transforms.ToTensor()])t_img = transform(img)print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.4.4调整图片颜色
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
brightness:
-
亮度调整的范围。
-
可以
float或(min, max)元组:-
如果是
float(如brightness=0.2),则亮度在[max(0, 1 - 0.2), 1 + 0.2] = [0.8, 1.2]范围内随机缩放。 -
如果是
(min, max)(如brightness=(0.5, 1.5)),则亮度在[0.5, 1.5]范围内随机缩放。
-
contrast:
-
对比度调整的范围。
-
格式与 brightness 相同。
saturation:
-
饱和度调整的范围。
-
格式与 brightness 相同。
hue:
-
色调调整的范围。
-
可以是一个浮点数(表示相对范围)或一个元组 (min, max)。
-
取值范围必须为
[-0.5, 0.5](因为色相在 HSV 色彩空间中是循环的,超出范围会导致颜色异常)。
3.4.5随机旋转
RandomRotation用于对图像进行随机旋转。
transforms.RandomRotation(
degrees,
interpolation=InterpolationMode.NEAREST,
expand=False,
center=None,
fill=0
)
degrees:
-
旋转角度的范围,可以是一个浮点数或元组 (min_degree, max_degree)。
-
例如,degrees=30 表示旋转角度在 [-30, 30] 之间随机选择。
-
例如,degrees=(30, 60) 表示旋转角度在 [30, 60] 之间随机选择。
interpolation:
-
插值方法,用于旋转图像。
-
默认是 InterpolationMode.NEAREST(最近邻插值)。
-
其他选项包括 InterpolationMode.BILINEAR(双线性插值)、InterpolationMode.BICUBIC(双三次插值)等。
expand:
-
是否扩展图像大小以适应旋转后的图像。如:当需要保留完整旋转后的图像时(如医学影像、文档扫描)
-
如果为 True,旋转后的图像可能会比原始图像大。
-
如果为 False,旋转后的图像大小与原始图像相同。
center:
-
旋转中心点的坐标,默认为图像中心。
-
可以是一个元组 (x, y),表示旋转中心的坐标。
fill:
-
旋转后图像边缘的填充值。
-
可以是一个浮点数(用于灰度图像)或一个元组(用于 RGB 图像)。默认填充0(黑色)
def test04():path = 'datasets/images/100.jpg'img = Image.open(path)print(img.size)transform = transforms.Compose([# 随机旋转# degress参数:degress=30,表示在(-30,30)范围内随机旋转,degree=(30,60),表示在该范围内随机旋转transforms.RandomRotation(degrees=45),transforms.ToTensor()])t_img = transform(img)print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.4.6图片转Tensor
import torch
from PIL import Image
from torchvision import transforms
import osdef test001():dir_path = os.path.dirname(__file__)file_path = os.path.join(dir_path,'img', '1.jpg')file_path = os.path.relpath(file_path)print(file_path)# 1. 读取图片img = Image.open(file_path)# transforms.ToTensor()用于将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,并自动进行数值归一化和维度调整# 将像素值从 [0, 255] 缩放到 [0.0, 1.0](浮点数)# 自动将图像格式从 (H, W, C)(高度、宽度、通道)转换为 PyTorch 标准的 (C, H, W)transform = transforms.ToTensor()img_tensor = transform(img)print(img_tensor)if __name__ == "__main__":test001()3.4.7 Tensor转图片
def test05():t = torch.randn(3, 224, 224)transform = transforms.Compose([# 张量转PIL图片transforms.ToPILImage()])img = transform(t)print(img.size)img.show()3.4.8归一化
-
标准化:将图像的像素值从原始范围(如 [0, 255] 或 [0, 1])转换为均值为 0、标准差为 1 的分布。
-
加速训练:标准化后的数据分布更均匀,有助于加速模型训练。
-
提高模型性能:标准化可以使模型更容易学习到数据的特征,提高模型的收敛性和稳定性。
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])]
均值(Mean):数据集中所有图像在每个通道上的像素值的平均值。
标准差(Std):数据集中所有图像在每个通道上的像素值的标准差。
RGB 三个通道的均值和标准差 不是随便定义的,而是需要根据具体的数据集进行统计计算。这些值是 ImageNet 数据集的统计结果,已成为计算机视觉任务的默认标准。
def test06():path = 'datasets/images/100.jpg'img = Image.open(path)print(img.size)transform = transforms.Compose([transforms.ToTensor(),# Normalize:标准化# mean:均值# std:标准差# 如果数据集是官方数据集,需要查看官方提供的mean和std值# 如果是自定义的数据集,可以将mean和std设置为[0.5, 0.5, 0.5],是一个经验值# Normalize要在ToTensor()之后执行,否则会报错transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])t_img = transform(img)print(t_img.shape)t_img = torch.permute(t_img, (1, 2, 0))plt.imshow(t_img)plt.show()3.4.9数据增强整合
使用transforms.Compose()把要增强的操作整合到一起:
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
from torchvision import transforms, datasets, utilsdef test01():# 定义数据增强和归一化transform = transforms.Compose([transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.RandomRotation(10), # 随机旋转 ±10 度transforms.RandomResizedCrop(32, scale=(0.8, 1.0)), # 随机裁剪到 32x32,缩放比例在0.8到1.0之间transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 随机调整亮度、对比度、饱和度、色调transforms.ToTensor(), # 转换为 Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化,这是一种常见的经验设置,适用于数据范围 [0, 1],使其映射到 [-1, 1]])# 加载 CIFAR-10 数据集,并应用数据增强trainset = datasets.CIFAR10(root="./cifar10_data", train=True, download=True, transform=transform)dataloader = DataLoader(trainset, batch_size=4, shuffle=False)# 获取一个批次的数据images, labels = next(iter(dataloader))# 还原图片并显示plt.figure(figsize=(10, 5))for i in range(4):# 反归一化:将像素值从 [-1, 1] 还原到 [0, 1]img = images[i] / 2 + 0.5# 转换为 PIL 图像img_pil = transforms.ToPILImage()(img)# 显示图片plt.subplot(1, 4, i + 1)plt.imshow(img_pil)plt.axis('off')plt.title(f'Label: {labels[i]}')plt.show()if __name__ == "__main__":test01()八、批量标准化
1、训练阶段的批量标准化
- 计算均值和方差
- 标准化
- 缩放和平移
- 更新全局统计量
2、测试阶段的批量标准化
在测试阶段,由于没有 mini-batch 数据,无法直接计算当前 batch 的均值和方差。因此,使用训练阶段通过 EMA 计算的全局统计量(均值和方差)来进行标准化。
在测试阶段,使用全局统计量对输入数据进行标准化:
然后对标准化后的数据进行缩放和平移:
为什么使用全局统计量?
一致性:
-
在测试阶段,输入数据通常是单个样本或少量样本,无法准确计算均值和方差。
-
使用全局统计量可以确保测试阶段的行为与训练阶段一致。
稳定性:
-
全局统计量是通过训练阶段的大量 mini-batch 数据计算得到的,能够更好地反映数据的整体分布。
-
使用全局统计量可以减少测试阶段的随机性,使模型的输出更加稳定。
效率:
-
在测试阶段,使用预先计算的全局统计量可以避免重复计算,提高效率。
3、作用
批量标准化(Batch Normalization, BN)通过以下几个方面来提高神经网络的训练稳定性、加速训练过程并减少过拟合:
3.1 缓解梯度问题
标准化处理可以防止激活值过大或过小,避免了激活函数(如 Sigmoid 或 Tanh)饱和的问题,从而缓解梯度消失或爆炸的问题。
3.2 加速训练
由于 BN 使得每层的输入数据分布更为稳定,因此模型可以使用更高的学习率进行训练。这可以加快收敛速度,并减少训练所需的时间。
3.3 减少过拟合
-
类似于正则化:虽然 BN 不是一种传统的正则化方法,但它通过对每个批次的数据进行标准化,可以起到一定的正则化作用。它通过在训练过程中引入了噪声(由于批量均值和方差的估计不完全准确),这有助于提高模型的泛化能力。
-
避免对单一数据点的过度拟合:BN 强制模型在每个批次上进行标准化处理,减少了模型对单个训练样本的依赖。这有助于模型更好地学习到数据的整体特征,而不是对特定样本的噪声进行过度拟合。
4、函数
torch.nn.BatchNorm1d 是 PyTorch 中用于一维数据的批量标准化(Batch Normalization)模块。
torch.nn.BatchNorm1d(
num_features, # 输入数据的特征维度
eps=1e-05, # 用于数值稳定性的小常数
momentum=0.1, # 用于计算全局统计量的动量
affine=True, # 是否启用可学习的缩放和平移参数
track_running_stats=True, # 是否跟踪全局统计量
device=None, # 设备类型(如 CPU 或 GPU)
dtype=None # 数据类型
)
参数说明:
eps:用于数值稳定性的小常数,添加到方差的分母中,防止除零错误。默认值:1e-05
momentum:用于计算全局统计量(均值和方差)的动量。默认值:0.1,参考本节1.4
affine:是否启用可学习的缩放和平移参数(γ和 β)。如果 affine=True,则模块会学习两个参数;如果 affine=False,则不学习参数,直接输出标准化后的值 \hat x_i。默认值:True
track_running_stats:是否跟踪全局统计量(均值和方差)。如果 track_running_stats=True,则在训练过程中计算并更新全局统计量,并在测试阶段使用这些统计量。如果 track_running_stats=False,则不跟踪全局统计量,每次标准化都使用当前 mini-batch 的统计量。默认值:True
import torch
from torch import nn,optim
from sklearn.datasets import make_circles
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as pltdef build_data():x , y = make_circles(n_samples=2000,factor=0.4,noise=0.1,random_state=42)print(x[0])print(y[0:5])x = torch.tensor(x,dtype=torch.float)y = torch.tensor(y,dtype=torch.long)# plt.scatter(x[:,0],x[:,1],c=y)# plt.show()x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=42)return x_train,x_test,y_train,y_test# 构建网络模型,带批量标准化
class NetWithBN(nn.Module):def __init__(self,in_features,out_features):super().__init__()self.fc1 = nn.Linear(in_features,128)self.bn1 = nn.BatchNorm1d(128)self.relu1 = nn.ReLU()self.fc2 = nn.Linear(128,64)self.bn2 = nn.BatchNorm1d(64)self.relu2 = nn.ReLU()self.fn3 = nn.Linear(64,out_features)def forward(self,x):x = self.relu1(self.bn1(self.fc1(x)))x = self.relu2(self.bn2(self.fc2(x)))x = self.fn3(x)return x# 创建网络模型,不使用批量标准化
class NetWithoutBN(nn.Module):def __init__(self,in_features,out_features):super().__init__()self.fc1 = nn.Linear(in_features,128)self.relu1 = nn.ReLU()self.fc2 = nn.Linear(128,64)self.relu2 = nn.ReLU()self.fn3 = nn.Linear(64,out_features)def forward(self,x):x = self.relu1(self.fc1(x))x = self.relu2(self.fc2(x))x = self.fn3(x)return xdef train(model,x_train,y_train,epochs):# 如果网络模型中使用了dropout或批量标准化,train()默认启动dropout或批量标准化的功能model.train()criterion = nn.CrossEntropyLoss()opt = optim.SGD(model.parameters(),lr=0.1)loss_list = []for epoch in range(epochs):y_pred = model(x_train)print(y_pred[0])print(y_train.shape)loss = criterion(y_pred,y_train)opt.zero_grad()loss.backward()opt.step()loss_list.append(loss.item())return loss_listdef eval(model,x_test,y_test,epochs):# 验证阶段会自动关闭dropout或批量标准化的参数更新model.eval()acc_list = []for epoch in range(epochs):with torch.no_grad():y_gred = model(x_test)_, pred = torch.max(y_gred,dim=1)correct = (pred == y_test).sum().item()acc = correct / len(y_test)acc_list.append((acc))return acc_listdef plot(bn_loss_list,no_bn_loss_list,bn_acc_list,no_bn_acc_list):fig = plt.figure(figsize=(12, 5))ax1 = fig.add_subplot(1, 2, 1)ax1.plot(bn_loss_list, 'b', label='BN')ax1.plot(no_bn_loss_list, 'r', label='NoBN')ax1.legend()ax2 = fig.add_subplot(1, 2, 2)ax2.plot(bn_acc_list, 'b', label='BN')ax2.plot(no_bn_acc_list, 'r', label='NoBN')ax2.legend()plt.show()if __name__ == '__main__':x_train,x_test,y_train,y_test =build_data()bn_model = NetWithBN(2,2)nobn_model = NetWithoutBN(2,2)bn_loss_list = train(bn_model,x_train,y_train,100)no_bn_loss_list = train(nobn_model,x_train,y_train,100)bn_acc_list = eval(bn_model,x_test,y_test,100)no_bn_acc_list = eval(nobn_model,x_test,y_test,100)plot(bn_loss_list,no_bn_loss_list,bn_acc_list,no_bn_acc_list)九、模型的保存和加载
训练一个模型通常需要大量的数据、时间和计算资源。通过保存训练好的模型,可以满足后续的模型部署、模型更新、迁移学习、训练恢复等各种业务需要求。
1、标准网络模型构建
class MyModle(nn.Module):def __init__(self, input_size, output_size):super(MyModle, self).__init__()# 创建一个全连接网络(full connected layer)self.fc1 = nn.Linear(input_size, 128)self.fc2 = nn.Linear(128, 64)self.fc3 = nn.Linear(64, output_size)def forward(self, x):x = self.fc1(x)x = self.fc2(x)output = self.fc3(x)return output# 创建模型实例
model = MyModel(input_size=10, output_size=2)
# 输入数据
x = torch.randn(5, 10)
# 调用模型
output = model(x)forward 方法是 PyTorch 中 nn.Module 类的必须实现的方法。它是定义神经网络前向传播逻辑的地方,决定了数据如何通过网络层传递并生成输出。同时forward 方法定义了计算图,PyTorch 会根据这个计算图自动计算梯度并更新参数。
2、序列化模型对象
模型序列化对象的保存和加载:
模型保存:
torch.save(obj, f, pickle_module=pickle, pickle_protocol=DEFAULT_PROTOCOL, _use_new_zipfile_serialization=True)
参数说明:
-
obj:要保存的对象,可以是模型、张量、字典等。
-
f:保存文件的路径或文件对象。可以是字符串(文件路径)或文件描述符。
-
pickle_module:用于序列化的模块,默认是 Python 的 pickle 模块。
-
pickle_protocol:pickle 模块的协议版本,默认是 DEFAULT_PROTOCOL(通常是最高版本)。
模型加载:
torch.load(f, map_location=None, pickle_module=pickle, **pickle_load_args)
参数说明:
-
f:文件路径或文件对象。可以是字符串(文件路径)或文件描述符。
-
map_location:指定加载对象的设备位置(如 CPU 或 GPU)。默认是 None,表示保持原始设备位置。例如:map_location=torch.device('cpu') 将对象加载到 CPU。
-
pickle_module:用于反序列化的模块,默认是 Python 的 pickle 模块。
-
pickle_load_args:传递给 pickle_module.load() 的额外参数。
3、保存模型参数
这种形式更常用,只需要保存权重、偏置、准确率等相关参数,都可以在加载后打印观察!
import torch
from torch import nnclass MyNet(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(10,64)self.fc2 = nn.Linear(64,5)def forward(self,x):x = self.fc1(x)x = self.fc2(x)return x# 保存模型
def test01():model = MyNet()print( model)torch.save(model,'./model/fcnn_model.pt')# 加载模型
# 完整的模型
def test02():model = torch.load('./model/fcnn_model.pt')print( model)# 保存模型参数
def test03():model = MyNet()state_dict = model.state_dict()torch.save(state_dict,'./model/fcnn_state.pt')# 加载模型参数
# 如果保存的是模型参数,加载的是字典,内容是模型参数,并不是完整的模型
# 需要事先初始化模型,然后把模型参数导入到模型中
def test04():model = MyNet()state_dict = torch.load('./model/fcnn_state.pt')model.load_state_dict(state_dict)if __name__ == '__main__':# test01()test02()十、项目实战
1.使用全连接网络训练和验证MNIST数据集
# 使用全连接网络训练和预测MINIST数据集
# 1.数据准备:通过数据加载器加载官方MINIST数据集
# 2.构建网络结构
# 3.实现训练方法:使用交叉熵损失函数、Adam优化器
# 4.实现验证方法
# 5.通过测试图片进行预测import torch
from torch import nn,optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
from PIL import Imagedef build_data():transform = transforms.Compose([transforms.Resize((28, 28)), # 正确写法:调整为28x28transforms.ToTensor(),])# 训练数据集train_dataset = datasets.MNIST(root = './datasets',train = True,download=True,transform=transform,)# 验证数据集eval_dataset = datasets.MNIST(root = './datasets',train = False,download=True,transform=transform,)# 训练数据加载器train_dataloader = DataLoader(dataset=train_dataset,batch_size=64,shuffle=True,)# 验证数据加载器eval_dataloader = DataLoader(dataset=eval_dataset,batch_size=64,shuffle=True,)return train_dataloader,eval_dataloader# 构建网络架构
class MNISTNet(nn.Module):def __init__(self,in_fearures,out_featuers):super().__init__()self.fc1 = nn.Linear(in_fearures,128)self.bn1 = nn.BatchNorm1d(128)self.relu1 = nn.ReLU()self.fc2 = nn.Linear(128,64)self.bn2 = nn.BatchNorm1d(64)self.relu2 = nn.ReLU()self.fn3 = nn.Linear(64,out_featuers)def forward(self,x):x = x.view(-1,1*28*28)x = self.relu1(self.bn1(self.fc1(x)))x = self.relu2(self.bn2(self.fc2(x)))x = self.fn3(x)return xdef train(model,train_dataloader,lr,epochs):model.train()criterion = nn.CrossEntropyLoss()opt = optim.Adam(model.parameters(),lr=lr,betas=(0.9,0.999),eps=1e-08,weight_decay=0.001)for epoch in range(epochs):correct = 0for tx,ty in train_dataloader:y_pred = model(tx)loss = criterion(y_pred,ty)opt.zero_grad()loss.backward()opt.step()_,pred = torch.max(y_pred.data,dim=1)correct += (pred==ty).sum().item()acc = correct / len(train_dataloader.dataset)print(f'epoch:{epoch},loss:{loss.item():.4f},acc:{acc:.4f}')def eval(model,eval_dataloader):model.eval()criterion = nn.CrossEntropyLoss()correct = 0for vx,vy in eval_dataloader:with torch.no_grad():y_pred = model(vx)loss = criterion(y_pred,vy)_,pred = torch.max(y_pred.data,dim=1)correct += (pred==vy).sum().item()acc = correct / len(eval_dataloader.dataset)print(f'loss:{loss.item()},acc:{acc}')def save_model(model,path):torch.save(model.state_dict(),path)def load_model(path):model = MNISTNet(1 * 28 * 28,10)model.load_state_dict(torch.load(path))return modeldef predict(test_path,model_path):transform = transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor(),])img = Image.open(test_path).convert('L')t_img = transform(img).unsqueeze(0)model = load_model(model_path)model.eval()with torch.no_grad():y_pred = model(t_img)_,pred = torch.max(y_pred.data,dim=1)print(f'预测分类:{pred.item()}')if __name__ == '__main__':# train_dataloader,val_dataloader = build_data()# model = MNISTNet(1 * 28 * 28,10)# train(model,train_dataloader,lr=0.01,epochs=20)# eval(model,val_dataloader)# save_model(model,'./model/mnist_model.pt')predict('./datasets/images/8.png', './model/mnist_model.pt')2.使用全连接网络训练和验证CIFAR10数据集
import torch
from torch import nn,optim
from torchvision import datasets,transforms
from torch.utils.data import DataLoaderdef build_data():# 数据转换transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])# 数据准备# 训练数据集train_dataset = datasets.CIFAR10(root='./datasets',train=True,transform=transform,download=True)# 验证数据集eval_dataset = datasets.CIFAR10(root='./datasets',train=False,transform=transform,download=True)# 训练集数据加载器train_loader = DataLoader(dataset=train_dataset,batch_size=128,shuffle=True)# 验证集数据加载器eval_loader = DataLoader(dataset=eval_dataset,batch_size=256,shuffle=False)return train_loader,eval_loader# 定义网络结构
class CIFAR10Net(nn.Module):def __init__(self,in_features,out_features):super().__init__()self.fc1 = nn.Linear(in_features,2048)self.bn1 = nn.BatchNorm1d(2048)self.dropout1 = nn.Dropout(0.3)self.fc2 = nn.Linear(2048,1024)self.bn2 = nn.BatchNorm1d(1024)self.dropout2 = nn.Dropout(0.3)self.fc3 = nn.Linear(1024,512)self.bn3 = nn.BatchNorm1d(512)self.fc4 = nn.Linear(512,256)self.bn4 = nn.BatchNorm1d(256)self.fc5 = nn.Linear(256,out_features)self.relu = nn.ReLU()def forward(self,x):x = x.view(-1,32*32*3)x = self.dropout1(self.bn1(self.fc1(x)))x = self.relu(x)x = self.dropout2(self.bn2(self.fc2(x)))x = self.relu(x)x = self.bn3(self.fc3(x))x = self.relu(x)x = self.relu(self.bn4(self.fc4(x)))x = self.fc5(x)return xdef train(model,train_loader,lr,epochs):model.train()criterion = nn.CrossEntropyLoss()opt = optim.AdamW(model.parameters(),lr=lr,weight_decay=0.01)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)for epoch in range(epochs):correct = 0for tx,ty in train_loader:tx,ty = tx.to(device),ty.to(device)y_pred = model(tx)loss = criterion(y_pred,ty)opt.zero_grad()loss.backward()opt.step()_,pred = torch.max(y_pred.data,dim=1)correct += (pred==ty).sum().item()acc = correct / len(train_loader.dataset)print(f'epoch:{epoch},loss:{loss.item():.4f},acc:{acc:.4f}')def eval(model,eval_loader):model.eval()criterion = nn.CrossEntropyLoss()device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)eval_loss = 0correct = 0with torch.no_grad():for vx,vy in eval_loader:vx,vy = vx.to(device),vy.to(device)y_pred = model(vx)eval_loss += criterion(y_pred,vy)_,pred = torch.max(y_pred.data,dim=1)correct += (pred==vy).sum().item()eval_loss /= len(eval_loader.dataset)acc = 100*correct / len(eval_loader.dataset)print(f'loss:{eval_loss.item()},acc:{acc}')if __name__ == '__main__':train_loader,val_loader = build_data()model = CIFAR10Net(32*32*3,10)train(model,train_loader,lr=0.001,epochs=60)eval(model,val_loader)