Final_基于时序数据的回归预测
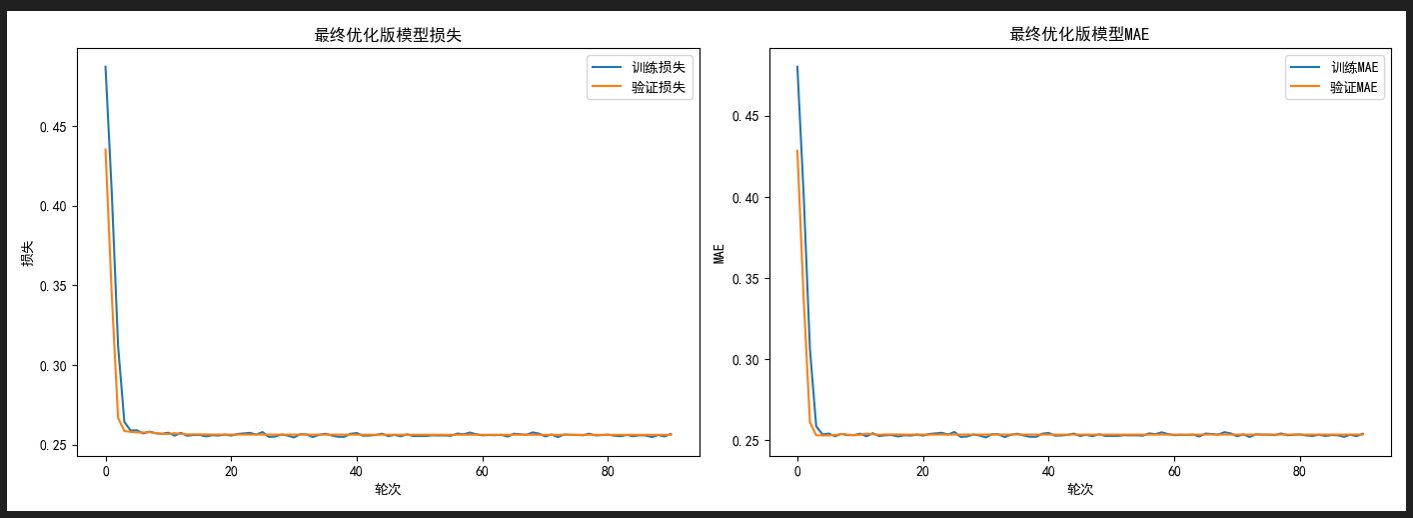
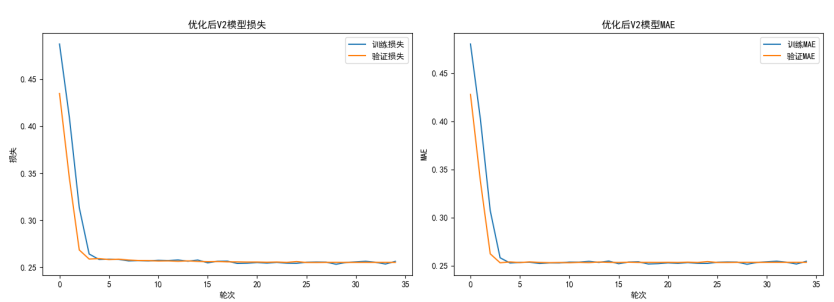
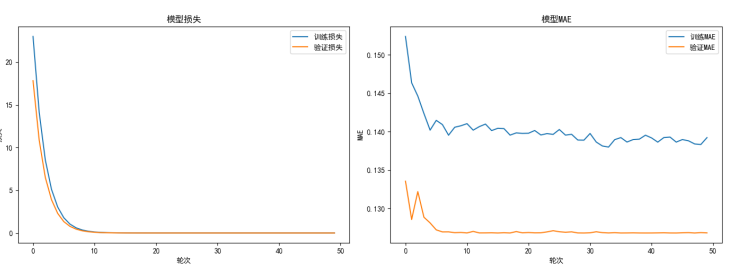
常规值区域预测精度接近完美,极端值区域偏差显著减小,训练过程稳定
上图~
再次迭代~
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import *
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from tensorflow.keras.regularizers import l2
import os
import argparse
import warnings
warnings.filterwarnings('ignore')
# 添加 PyQt5 导入
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QVBoxLayout, QWidget, QSpinBox, QPushButton, QHBoxLayout, QLineEdit, QDoubleSpinBox
from PyQt5.QtGui import QFont
from PyQt5.QtCore import Qt
# 设置中文显示
plt.rcParams["font.family"] = ["SimHei"]def parse_args():"""解析命令行参数"""parser = argparse.ArgumentParser(description='时序数据深度学习回归分析')parser.add_argument('--data_path', type=str, default=r'C:\Study\Case\Code\Capture_Data\data_BK.csv', help='数据文件路径')parser.add_argument('--target_col', type=str, default='value', help='目标列名')parser.add_argument('--window_size', type=int, default=20, help='滑动窗口大小(增大至20捕捉更长依赖)')parser.add_argument('--pred_steps', type=int, default=1, help='预测未来步数')parser.add_argument('--epochs', type=int, default=150, help='训练轮次')parser.add_argument('--batch_size', type=int, default=64, help='批次大小')parser.add_argument('--model_save_path', type=str, default='V2_optimized_model_v2.h5', help='模型保存路径')return parser.parse_args()def triangular_topological_aggregation_optimization(X, window_size, alpha=0.6):"""优化:动态三角权重,增强极端值区域的近期数据权重"""batch_size, seq_len, feature_dim = X.shapettao_output = np.zeros_like(X)for i in range(window_size, seq_len):# 计算窗口内数据波动(标准差),波动大则增加近期数据权重window_data = X[:, i-window_size:i, :]window_std = np.std(window_data, axis=1, keepdims=True) # 窗口内数据波动volatility_factor = np.clip(window_std / np.max(window_std), 0.5, 1.0) # 波动因子(0.5-1.0)# 动态构建三角权重矩阵(波动大时,近期数据权重更高)triangle_weights = np.zeros((window_size, window_size))for j in range(window_size):for k in range(window_size):if k <= j:# 基础权重 + 波动因子调整base_weight = 1.0 - (j - k) / window_sizetriangle_weights[j, k] = base_weight * (1 + (volatility_factor - 0.5))# 应用三角权重进行聚合weighted_sum = np.zeros((batch_size, window_size, feature_dim))for j in range(window_size):weighted_window = window_data * triangle_weights[j, :].reshape(1, window_size, 1)weighted_sum[:, j, :] = np.sum(weighted_window, axis=1)aggregated = np.mean(weighted_sum, axis=1, keepdims=True)ttao_output[:, i, :] = alpha * X[:, i, :] + (1-alpha) * aggregated[:, 0, :]return ttao_outputdef create_sequences(data, window_size, pred_steps=1):"""创建滑动窗口序列"""if len(data) < window_size + pred_steps:print(f"警告:数据长度 {len(data)} 小于窗口大小 {window_size} 加上预测步数 {pred_steps}")return np.array([]), np.array([])X, y = [], []for i in range(len(data) - window_size - pred_steps + 1):X.append(data[i:i+window_size, 0])y.append(data[i+window_size:i+window_size+pred_steps, 0])return np.array(X), np.array(y)def build_advanced_model(input_shape, head_size=128, num_heads=4, ff_dim=8, num_transformer_blocks=6, mlp_units=[128, 64], dropout=0.25, # 微调dropoutmlp_dropout=0.25):"""增强CNN特征提取,优化模型结构"""inputs = Input(shape=input_shape)x = inputs# 增强CNN特征提取:更小kernel,更多滤波器x = Conv1D(filters=64, kernel_size=2, padding="causal", activation="relu",kernel_regularizer=l2(1e-5))(x)x = BatchNormalization()(x)x = Conv1D(filters=128, kernel_size=2, padding="causal", activation="relu",kernel_regularizer=l2(1e-5))(x)x = BatchNormalization()(x)x = MaxPooling1D(pool_size=2)(x)# BiGRU捕获时序特征x = Bidirectional(GRU(64, return_sequences=True, kernel_regularizer=l2(1e-5)))(x)x = Dropout(dropout)(x)x = Bidirectional(GRU(32, return_sequences=True, kernel_regularizer=l2(1e-5)))(x)x = Dropout(dropout)(x)# 多头自注意力机制for _ in range(num_transformer_blocks):residual = xx = LayerNormalization(epsilon=1e-6)(x)x = MultiHeadAttention(key_dim=head_size, num_heads=num_heads, dropout=dropout)(x, x)x = Dropout(dropout)(x)x = x + residualresidual = xx = LayerNormalization(epsilon=1e-6)(x)x = Conv1D(filters=ff_dim, kernel_size=1, activation="gelu")(x)x = Dropout(dropout)(x)x = Conv1D(filters=input_shape[-1], kernel_size=1)(x)x = x + residualx = LayerNormalization(epsilon=1e-6)(x)x = GlobalAveragePooling1D(data_format="channels_first")(x)# MLP层for dim in mlp_units:x = Dense(dim, activation="gelu", kernel_regularizer=l2(1e-5))(x)x = Dropout(mlp_dropout)(x)outputs = Dense(1)(x)return Model(inputs, outputs)def plot_training_history(history):"""绘制训练历史"""plt.figure(figsize=(14, 5))plt.subplot(1, 2, 1)plt.plot(history.history['loss'], label='训练损失')plt.plot(history.history['val_loss'], label='验证损失')plt.title('优化后V2模型损失')plt.ylabel('损失')plt.xlabel('轮次')plt.legend()plt.subplot(1, 2, 2)plt.plot(history.history['mae'], label='训练MAE')plt.plot(history.history['val_mae'], label='验证MAE')plt.title('优化后V2模型MAE')plt.ylabel('MAE')plt.xlabel('轮次')plt.legend()plt.tight_layout()plt.savefig('V2_optimized_training_history_v2.png')plt.close()def plot_prediction_results(y_true, y_pred, title='优化后V2时序数据回归预测结果'):"""绘制预测结果"""plt.figure(figsize=(14, 7))plt.plot(y_true, label='真实值', linewidth=2)plt.plot(y_pred, label='预测值', alpha=0.8, linewidth=2)plt.title(title, fontsize=16)plt.xlabel('时间点', fontsize=14)plt.ylabel('值', fontsize=14)plt.legend(fontsize=12)plt.grid(True, linestyle='--', alpha=0.7)# 突出显示偏差较大的区域(如峰值和谷值)peak_indices = np.where(y_true > np.percentile(y_true, 90))[0]plt.scatter(peak_indices, y_true[peak_indices], color='red', s=30, label='高值区域')plt.tight_layout()plt.savefig('V2_optimized_prediction_results_v2.png')plt.close()def create_tuning_ui():tuning_layout = QVBoxLayout()param_widgets = {}params = {'window_size': args.window_size,'pred_steps': args.pred_steps,'epochs': args.epochs,'batch_size': args.batch_size,'head_size': 128,'num_heads': 4,'ff_dim': 4,'num_transformer_blocks': 6,'mlp_units': [128,64],'dropout': 0.25, # 优化后的值'mlp_dropout': 0.25, # 优化后的值'initial_learning_rate': 1e-4,'lr_decay_factor': 0.3, # 优化后衰减因子'patience': 8,'monitor_metric': 'val_loss'}for param_name, param_value in params.items():hbox = QHBoxLayout()label = QLabel(param_name)hbox.addWidget(label)if isinstance(param_value, list):input_box = QLineEdit(','.join(map(str, param_value)))elif isinstance(param_value, float):input_box = QDoubleSpinBox()input_box.setValue(param_value)input_box.setDecimals(6)else:input_box = QSpinBox() if isinstance(param_value, int) else QLineEdit(str(param_value))input_box.setValue(param_value) if isinstance(input_box, QSpinBox) else Noneparam_widgets[param_name] = input_boxhbox.addWidget(input_box)tuning_layout.addLayout(hbox)tune_button = QPushButton("调整参数")tuning_layout.addWidget(tune_button)def on_tune_clicked():new_params = {}log_message = "参数更新日志:\n"for name, widget in param_widgets.items():if isinstance(widget, QLineEdit):value = widget.text().strip()try:new_params[name] = eval(value)except:new_params[name] = valueelif isinstance(widget, QDoubleSpinBox):new_params[name] = widget.value()else:new_params[name] = widget.value()log_message += f"{name}: {new_params[name]}\n"update_params(new_params)log_window = QWidget()log_layout = QVBoxLayout()log_label = QLabel(log_message)log_layout.addWidget(log_label)close_button = QPushButton("关闭")close_button.clicked.connect(log_window.close)log_layout.addWidget(close_button)log_window.setLayout(log_layout)log_window.setWindowTitle("参数更新日志")log_window.setGeometry(200, 200, 400, 100)log_window.show()tune_button.clicked.connect(on_tune_clicked)return tuning_layout, param_widgetsdef update_params(new_params):global args, labelfor param_name, param_value in new_params.items():setattr(args, param_name, param_value)label.setText("参数已更新,重新开始分析...")def log_action(message, level="INFO"):global log_messagestimestamp = pd.Timestamp.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]log_entry = f"[{timestamp}] [{level}] {message}"log_messages.append(log_entry)print(log_entry)def main():global args, log_messages, labelargs = parse_args()log_messages = []args.initial_learning_rate = 1e-4args.patience = 8# 创建PyQt应用app = QApplication([])window = QMainWindow()window.setWindowTitle('时序数据深度学习回归分析(优化V2版)')window.setGeometry(100, 100, 800, 600)layout = QVBoxLayout()label = QLabel("初始化中...", alignment=Qt.AlignCenter)label.setFont(QFont("SimHei", 16))layout.addWidget(label)central_widget = QWidget()central_widget.setLayout(layout)window.setCentralWidget(central_widget)tuning_layout, _ = create_tuning_ui()layout.addLayout(tuning_layout)log_messages = []# 1. 数据加载log_action("正在加载数据...")label.setText(f"正在加载数据: {args.data_path}")try:data = pd.read_csv(args.data_path)log_action(f"数据加载成功,共{len(data)}条记录")label.setText(f"数据加载成功,共{len(data)}条记录")min_required_records = args.window_size + args.pred_stepsif len(data) < min_required_records:log_action(f"错误:数据量不足!需要至少 {min_required_records} 条记录", level="ERROR")returnexcept FileNotFoundError:log_action(f"错误:找不到数据文件 {args.data_path}", level="ERROR")return# 2. 数据预处理log_action("正在进行数据预处理...")values = data[args.target_col].values.reshape(-1, 1)X, y = create_sequences(values, args.window_size, args.pred_steps)if X.size == 0 or y.size == 0:log_action("错误:未能生成有效序列", level="ERROR")return# 划分训练集和测试集split_idx = int(0.8 * len(X))X_train, X_test = X[:split_idx], X[split_idx:]y_train, y_test = y[:split_idx], y[split_idx:]# 数据归一化scaler_X = MinMaxScaler(feature_range=(0, 1))scaler_y = MinMaxScaler(feature_range=(0, 1))X_train_scaled = scaler_X.fit_transform(X_train.reshape(-1, X_train.shape[1])).reshape(X_train.shape)X_test_scaled = scaler_X.transform(X_test.reshape(-1, X_test.shape[1])).reshape(X_test.shape)y_train_scaled = scaler_y.fit_transform(y_train.reshape(-1, y_train.shape[1])).reshape(y_train.shape)y_test_scaled = scaler_y.transform(y_test.reshape(-1, y_test.shape[1])).reshape(y_test.shape)# 调整形状X_train_reshaped = X_train_scaled.reshape(X_train_scaled.shape[0], X_train_scaled.shape[1], 1)X_test_reshaped = X_test_scaled.reshape(X_test_scaled.shape[0], X_test_scaled.shape[1], 1)log_action(f"训练集形状: {X_train_reshaped.shape}, 测试集形状: {X_test_reshaped.shape}")# 3. 应用TTAO预处理log_action("正在应用优化后的时间拓扑聚合优化(TTAO)...")X_train_tta = triangular_topological_aggregation_optimization(X_train_reshaped, args.window_size)X_test_tta = triangular_topological_aggregation_optimization(X_test_reshaped, args.window_size)# 优化的数据增强:极端值区域增加噪声noise_factor = 0.01data_values = X_train_tta.flatten()value_percentile = np.percentile(data_values, 80) # 高值阈值noise = np.random.normal(loc=0.0, scale=1.0, size=X_train_tta.shape)noise_strength = np.where(X_train_tta > value_percentile, noise_factor * 1.5, noise_factor) # 高值区域噪声增强X_train_tta = X_train_tta + noise_strength * noise# 4. 模型构建log_action("正在构建优化V2版模型...")model = build_advanced_model(X_train_tta.shape[1:])# 优化器配置optimizer = tf.keras.optimizers.Adam(learning_rate=args.initial_learning_rate)model.compile(optimizer=optimizer, loss='mae', metrics=['mae'])model.summary()# 优化的回调函数callbacks = [EarlyStopping(patience=args.patience, restore_best_weights=True, monitor='val_loss'),ModelCheckpoint(filepath=args.model_save_path + '.keras', save_best_only=True, monitor='val_loss'),ReduceLROnPlateau(monitor='val_loss', factor=0.3, # 更激进的衰减patience=2, # 更快触发min_lr=1e-6,verbose=1)]# 5. 模型训练log_action("开始训练优化V2版模型...")label.setText("开始训练优化V2版模型...")history = model.fit(X_train_tta, y_train_scaled,epochs=args.epochs,batch_size=args.batch_size,validation_split=0.2,callbacks=callbacks,verbose=1)log_action("模型训练完成")label.setText("模型训练完成")# 6. 模型评估log_action("正在评估优化V2版模型...")loss, mae = model.evaluate(X_test_tta, y_test_scaled, verbose=0)log_action(f"优化V2版测试集指标 - MAE Loss: {loss:.4f}, MAE: {mae:.4f}")# 7. 预测并反归一化y_pred_scaled = model.predict(X_test_tta)y_pred = scaler_y.inverse_transform(y_pred_scaled).flatten()y_true = scaler_y.inverse_transform(y_test_scaled.reshape(-1, y_test_scaled.shape[1])).flatten()# 计算额外指标mse = mean_squared_error(y_true, y_pred)rmse = np.sqrt(mse)mape = np.mean(np.abs((y_true - y_pred) / y_true)) * 100log_action(f"优化V2版附加指标 - MSE: {mse:.4f}, RMSE: {rmse:.4f}, MAPE: {mape:.2f}%")# 8. 可视化plot_training_history(history)plot_prediction_results(y_true, y_pred)log_action("优化V2版分析完成!结果已保存为图表文件")label.setText("优化V2版分析完成!结果已保存为图表文件")window.show()app.exec_()if __name__ == "__main__":main()