【AI学习从零至壹】Transformer
Transformer
- Positional Encoding
- Self Attention
- multi-head
- scaled dot-product attention
- Add & Norm
- Decoder的两层multi-head attention
- Transformer构建Seq2Seq模型
transformer论文
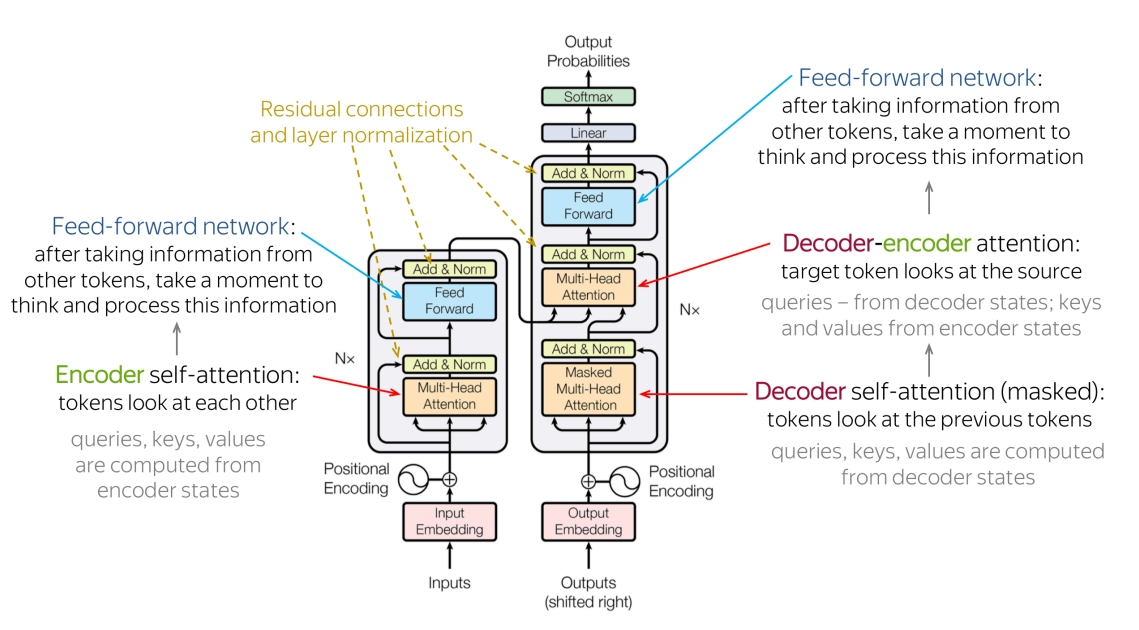
Transformer架构已经成为许多应⽤中的主导架构,它堆叠了许多层“self-attentionˮ模块。同⼀层中对每个模块使⽤标量积来计算其查询向量与该层中其他模块的关键向量之间的匹配。匹配被归⼀化为总和1,然后使⽤产⽣的标量系数来形成前⼀层中其他模块产⽣的值向量的凸组合。结果向量形成下⼀计算阶段的模块的输⼊。
Positional Encoding
常⻅的NLP模型都会使⽤TextCNN或RNN来进⾏位置相关信息的训练和提取,但Transformer中并没有这样的结构。所以作者是想要通过Positional Encoding的来解决这样的问题。
具体操作是位置编码和Input Embedding的维度相同,相加后作为模型的输⼊。
# 位置编码矩阵
class PositionalEncoding(nn.Module):def __init__(self, emb_size, dropout, maxlen=5000):super().__init__()# 行缩放指数值den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)# 位置编码索引 (5000,1)pos = torch.arange(0, maxlen).reshape(maxlen, 1)# 编码矩阵 (5000, emb_size)pos_embdding = torch.zeros((maxlen, emb_size))pos_embdding[:, 0::2] = torch.sin(pos * den)pos_embdding[:, 1::2] = torch.cos(pos * den)# 添加和batch对应维度 (1, 5000, emb_size)pos_embdding = pos_embdding.unsqueeze(-2)# dropoutself.dropout = nn.Dropout(dropout)# 注册当前矩阵不参与参数更新self.register_buffer('pos_embedding', pos_embdding)
Self Attention
transformer 的 self-attention 结构可以理解为: multi-head scaled dot-product attention
multi-head
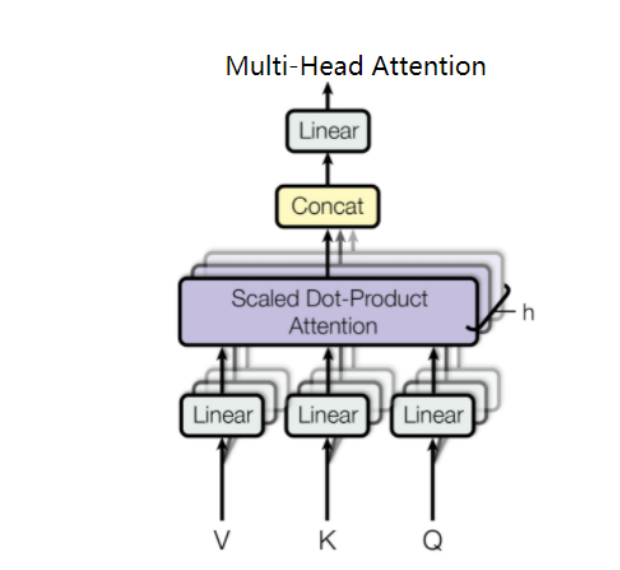
multi-head就是将⼀组向量拆分为多组,并⾏计算。这样做的好处可以理解为:模型在不同的表⽰⼦空间⾥学习到相关的信息。
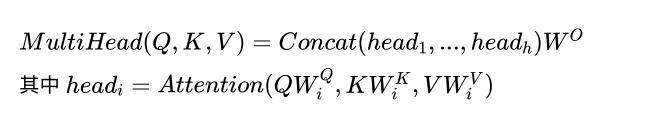
多头的本质就是 拆分后进⾏ 运算,之后再合并的过程。
torch.nn.MultiheadAttention源码链接
torch.nn.functional.multi_head_attention_forward()源码链接
scaled dot-product attention
⼀组query(Q) 和⼀组key-value(K-V)之间的映射,这⾥的 Q, K , V 都是原始输⼊经过线性变换得到的向量。
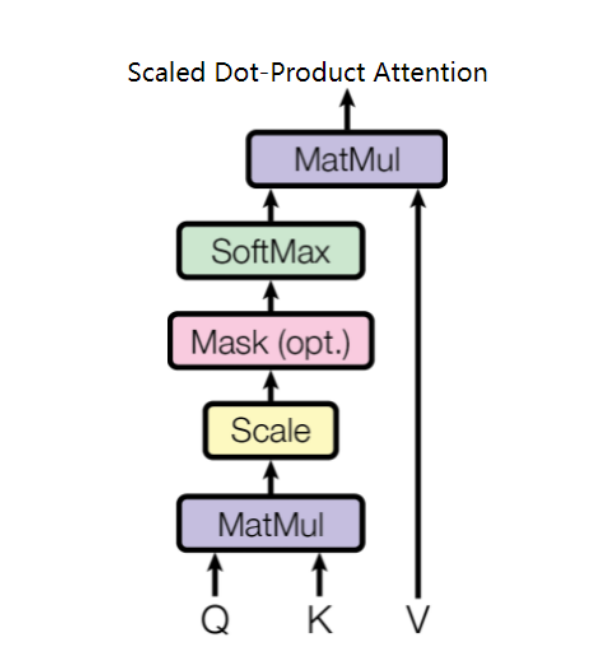

torch.nn.functional._scaled_dot_product_attention()源码链接
关于mask,有两个地⽅需要注意:
第1个是模型中的mask参数,通过将模型中不需要计算的值转换为很⼤的负数,在通过softmax后结果变为了0。
第2个是只有在decoder中才会设置mask。通过倒三⻆形的mask。⽬的是不让模型在训练时看到后⾯的信息,这也是decoder和encoder训练的不同点之⼀。
Scaled ⼀词在公式中的表⽰就是 表达式要除以 ,这么做的原因是当 增⼤时, 的值增⻓幅度会⼤幅加⼤,导致softmax后的梯度很⼩,模型效果变差。
假设 query 和 key 向量中的元素都是相互独⽴的均值为 0,⽅差为 1 的随机变量,那么这两个向量的内积 假设 query 和 key 向量中的元素都是相互独⽴的均值为 0,⽅差为 1 的随机变量,那么这两个向量的内积 的均值为0,⽅差为 。当除以 后,⽅差从 变为1,从⽽softmax反向运算的梯度不趋向于0。
Add & Norm
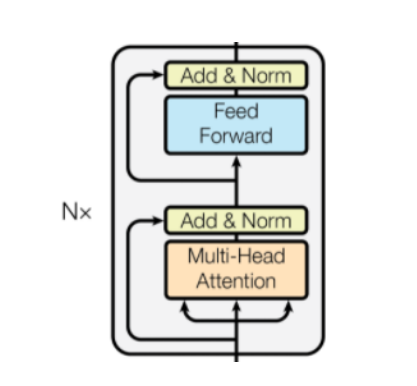
Add就是残差连接,把输⼊层和multi-head attention输出进⾏拼接
torch.nn.TransformerEncoderLayer源码链接
关于Batch Normalization和Layer Normalization有⼀个通俗化的解释:Batch Normalization 的处理对象是对⼀批样本, Layer Normalization 的处理对象是单个样本。Batch Normalization 是
对这批样本的同⼀维度特征做归⼀化, Layer Normalization 是对这单个样本的所有维度特征做归⼀化。
在CNN⽹络中,图像通过卷积层提取的信息,属于同⼀卷积核批次的feature map。所以通常会使⽤Batch Normalization。
在RNN和attention⽹络中,我们提取的语料维度信息都是同⼀语句批次的特征。所以使⽤Layer Normalization做归⼀化是有效的 。
Decoder的两层multi-head attention
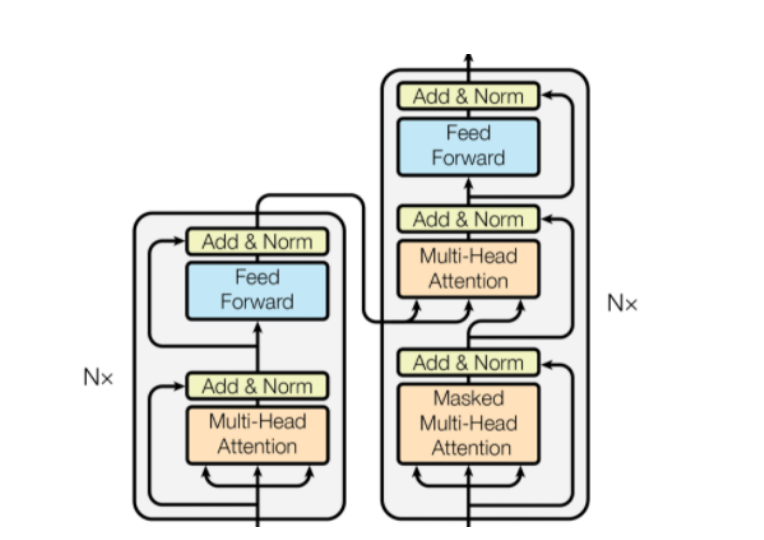
第⼀层是Masked Multi-Head Attention,通过Mask掩码来遮挡⼀部分的信息。
第⼆层是把Decoder的上⼀层输出作为Q,Encoder的输出导⼊作为K和V。
Transformer构建Seq2Seq模型
利⽤Pytorch中的Transformer模型来实现Seq2Seq,只依赖其内部的Transformer类还不够。我们还需要为其添加输⼊和输出端结构,才能实现完整的模型功能。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import math# 位置编码矩阵
class PositionalEncoding(nn.Module):def __init__(self, emb_size, dropout, maxlen=5000):super().__init__()# 行缩放指数值den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)# 位置编码索引 (5000,1)pos = torch.arange(0, maxlen).reshape(maxlen, 1)# 编码矩阵 (5000, emb_size)pos_embdding = torch.zeros((maxlen, emb_size))pos_embdding[:, 0::2] = torch.sin(pos * den)pos_embdding[:, 1::2] = torch.cos(pos * den)# 添加和batch对应维度 (1, 5000, emb_size)pos_embdding = pos_embdding.unsqueeze(-2)# dropoutself.dropout = nn.Dropout(dropout)# 注册当前矩阵不参与参数更新self.register_buffer('pos_embedding', pos_embdding)def forward(self, token_embdding):token_len = token_embdding.size(1) # token长度# (1, token_len, emb_size)add_emb = self.pos_embedding[:token_len, :] + token_embddingreturn self.dropout(add_emb)class Seq2SeqTransformer(nn.Module):def __init__(self, d_model, nhead, num_enc_layers, num_dec_layers, dim_forward, dropout, enc_voc_size, dec_voc_size):super().__init__()# transformerself.transformer = nn.Transformer(d_model=d_model,nhead=nhead,num_encoder_layers=num_enc_layers,num_decoder_layers=num_dec_layers,dim_feedforward=dim_forward,dropout=dropout,batch_first=True)# encoder input embeddingself.enc_emb = nn.Embedding(enc_voc_size, d_model)# decoder input embeddingself.dec_emb = nn.Embedding(dec_voc_size, d_model)# predict generate linearself.predict = nn.Linear(d_model, dec_voc_size) # token预测基于解码器词典# positional encodingself.pos_encoding = PositionalEncoding(d_model, dropout)def forward(self, enc_inp, dec_inp, tgt_mask, enc_pad_mask, dec_pad_mask):# multi head attention之前基于位置编码embedding生成enc_emb = self.pos_encoding(self.enc_emb(enc_inp))dec_emb = self.pos_encoding(self.dec_emb(dec_inp))# 调用transformer计算outs = self.transformer(src=enc_emb, tgt=dec_emb, tgt_mask=tgt_mask,src_key_padding_mask=enc_pad_mask, tgt_key_padding_mask=dec_pad_mask)# 推理return self.predict(outs)# 推理环节使用方法def encode(self, enc_inp):enc_emb = self.pos_encoding(self.enc_emb(enc_inp))return self.transformer.encoder(enc_emb)def decode(self, dec_inp, memory, dec_mask):dec_emb = self.pos_encoding(self.dec_emb(dec_inp))return self.transformer.decoder(dec_emb, memory, dec_mask)if __name__ == '__main__':# 模型数据# 一批语料: encoder:decoder# <s></s><pad>corpus= "人生得意须尽欢,莫使金樽空对月"chs = list(corpus)enc_tokens, dec_tokens = [],[]for i in range(1,len(chs)):enc = chs[:i]dec = ['<s>'] + chs[i:] + ['</s>']enc_tokens.append(enc)dec_tokens.append(dec)# 构建encoder和docoder的词典# 模型训练数据: X:([enc_token_matrix], [dec_token_matrix] shifted right),# y [dec_token_matrix] shifted# 1. 通过词典把token转换为token_index# 2. 通过Dataloader把encoder,decoder封装为带有batch的训练数据# 3. Dataloader的collate_fn调用自定义转换方法,填充模型训练数据# 3.1 encoder矩阵使用pad_sequence填充# 3.2 decoder前面部分训练输入 dec_token_matrix[:,:-1,:]# 3.3 decoder后面部分训练目标 dec_token_matrix[:,1:,:]# 4. 创建mask# 4.1 dec_mask 上三角填充-inf的mask# 4.2 enc_pad_mask: (enc矩阵 == 0)# 4.3 dec_pad_mask: (dec矩阵 == 0)# 5. 创建模型(根据GPU内存大小设计编码和解码器参数和层数)、优化器、损失# 6. 训练模型并保存