学习笔记-关于中华心法问答系统的环境配置和源代码理解
1. 简介
由于上周电脑故障的问题,没有进行环境配置。所以本周的主要任务就是进行环境配置和阅读理解基本代码。
2. 环境配置
首先需要需要下载python。这里注意最好下载python3.11版本。因为Python 3.12 不兼容旧版 jieba 和 setuptools;NumPy 2.2.3 尚未支持 Python 3.13。
安装python的时候记得勾选自动配置环境变量,如果忘记勾选,需要自己添加环境变量。验证python可以使用后进行下面的虚拟环境配置。
(1)创建和激活虚拟环境
# 创建虚拟环境
python -m venv venv# 激活虚拟环境
venv\Scripts\activate(2)下载需要的功能包
# 安装 Flask
pip install flask# 安装 jieba
pip install jieba# 安装 numpy
pip install numpy# 安装PyTorch (torch) 库
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu# 安装 transformers
pip install transformers(3)运行代码
python xinfa_QA.py(4)登录网页:http://127.0.0.1:5000
即可出现以下页面
关掉终端后,仅需激活虚拟环境,再运行代码就可以了。
3. 代码理解
3.1 代码流程图
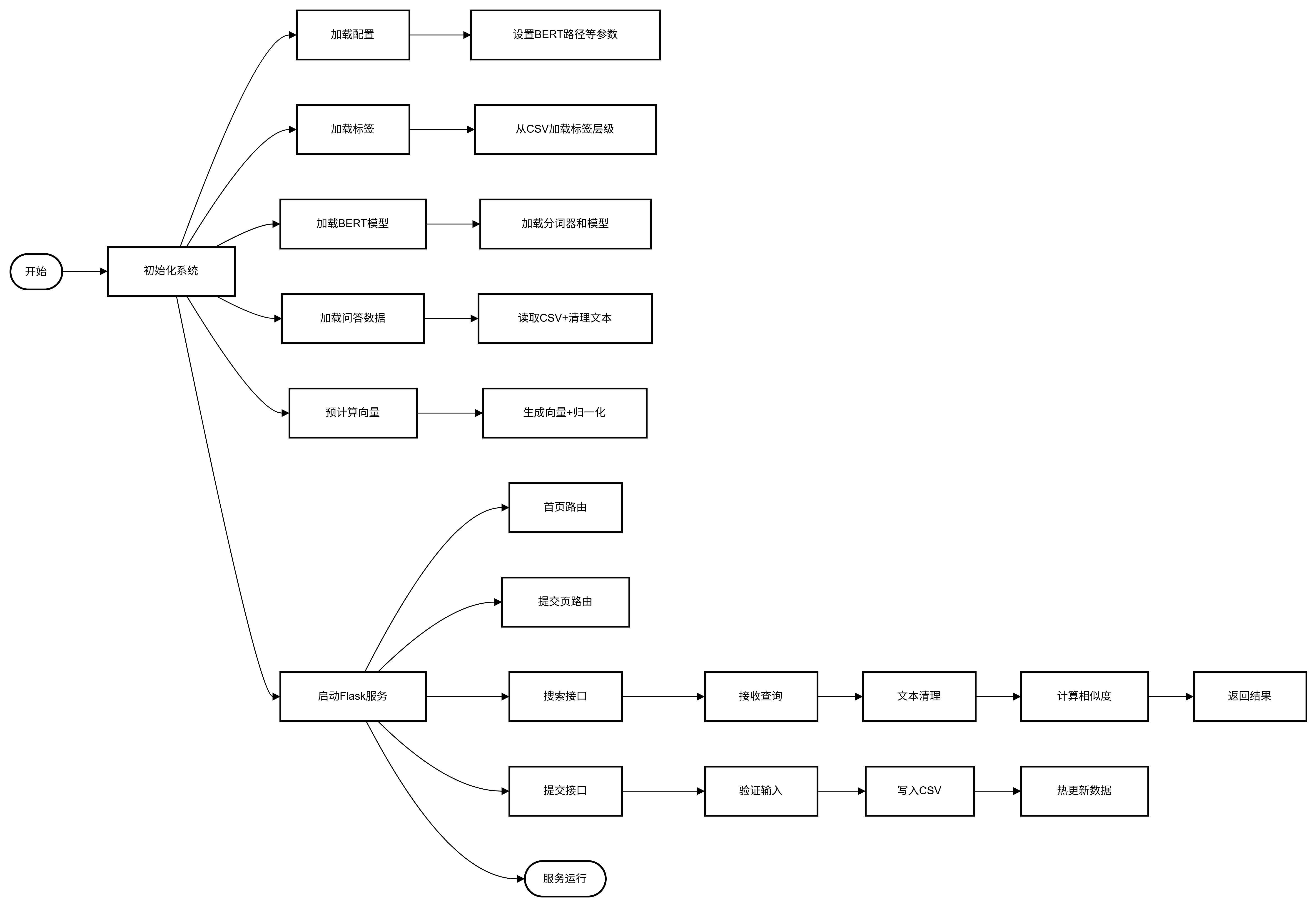
3.2 主要模块
3.2.1 全局变量和配置类
(1)全局变量:
# app 是 Flask 应用实例。
app = Flask(__name__)# system 是全局变量,用于存储问答系统实例。
system = None(2)配置类:
①TagConfig 类:管理问答系统中的标签层级结构(一级标签和二级标签)。
a.工作方式:从CSV文件中加载标签配置,存储一级标签和二级标签的层级关系,提供标签的验证功能。
b.主要功能:
- 初始化方法
# 接收一个CSV文件路径作为参数
def __init__(self, csv_path):# 初始化两个数据结构:# LEVEL1: 存储所有一级标签的集合self.LEVEL1 = set()# LEVEL2: 使用defaultdict(set)存储每个一级标签对应的二级标签集合self.LEVEL2 = defaultdict(set)- CSV文件处理
-
使用
csv.DictReader读取CSV文件 -
遍历每一行数据:
-
如果存在非空的"一级标签",将其添加到
LEVEL1集合中 -
如果该行还有非空的"二级标签",会将其按"/"分割,去除空白后添加到对应一级标签的二级标签集合中
-
-
with open(csv_path, 'r', encoding='utf-8') as f:reader = csv.DictReader(f)for row in reader:if '一级标签' in row and row['一级标签']:l1 = row['一级标签'].strip()self.LEVEL1.add(l1)if '二级标签' in row and row['二级标签']:l2_list = [t.strip() for t in row['二级标签'].split('/') if t.strip()]for l2 in l2_list:self.LEVEL2[l1].add(l2)- 数据整理
-
最后将
LEVEL1集合转换为排序后的列表 -
将
LEVEL2中的每个集合也转换为排序后的列表
-
self.LEVEL1 = sorted(self.LEVEL1)
self.LEVEL2 = {k: sorted(v) for k, v in self.LEVEL2.items()② Config 类:存储系统配置参数。
a.功能:用于集中管理项目中使用的各种配置参数和常量。
class Config:# 指定BERT模型的存储路径# 默认值为当前目录下的"BERT"文件夹BERT_PATH = "./BERT"# 指定问答数据文件的名称# 文件格式应为CSV,包含问题和答案数据QA_FILE = "心法问答.csv"# 指定停用词文件的名称# 停用词文件包含需要过滤的无意义词汇STOPWORDS_FILE = "stopwords.txt"# 设置检索或返回结果的最大数量# 值为1000表示最多返回1000个结果TOP_K = 1000# 设置相似度的最低阈值# 值为0.6表示只保留相似度大于等于60%的结果MIN_SIMILARITY = 0.6# 自动检测并设置计算设备# 优先使用CUDA(GPU)加速,不可用时回退到CPUDEVICE = "cuda" if torch.cuda.is_available() else "cpu"# 设置BERT模型各层的权重分配# 列表中的4个值分别对应BERT的4个隐藏层# 权重总和应为1.0LAYER_WEIGHTS = [0.15, 0.25, 0.35, 0.25]3.2.2 Flask路由
每个函数基本流程:接收请求→验证数据→处理业务→返回响应
(1)首页路由(/)
a.功能:处理根路径请求,返回首页
@app.route('/')
def home():# 使用 render_template 渲染并返回 index.html 模板# 这是应用的入口页面return render_template('index.html')(2)提交页面路由(/submit)
a.功能:返回问题提交页面
@app.route('/submit')
def submit_page():# 渲染 submit.html 模板# 用于展示问题提交表单return render_template('submit.html')(3)搜索接口(/search)
a.功能:处理问题搜索请求
# 只接受 POST 请求
@app.route('/search', methods=['POST'])
def search():# 从请求 JSON 中获取 question(搜索问题)和 tags(筛选标签)data = request.jsonquery = data.get('question', '')selected_tags = data.get('tags', {})# 调用 system.search_with_tags 进行带标签的搜索results = system.search_with_tags(query, selected_tags)# 返回包含问题、答案、相似度和标签的 JSON 数组return jsonify([{'question': r['question'],'answer': r['answer'],'similarity': r['similarity'],'tags': r['tags']#使用列表推导式格式化返回结果} for r in results])(4)问题提交接口(/submit_question)
a.功能:处理新问题的提交
b.细节
-
数据获取与清理:从请求中获取问题、答案、标签等数据并去除空白
try:# 获取并清理数据data = request.jsonquestion = data.get('question', '').strip()answer = data.get('answer', '').strip()level1 = data.get('level1', '').strip()level2 = data.get('level2', [])-
验证逻辑:
-
检查必填字段是否为空
-
验证一级标签是否有效
-
验证二级标签是否属于对应的一级标签
-
# 验证必填字段
if not question or not answer or not level1:return jsonify({'status': 400, 'msg': '问题、答案和一级标签不能为空'})# 验证一级标签有效性
if level1 not in system.tag_config.LEVEL1:return jsonify({'status': 400, 'msg': '无效的一级标签'})# 验证二级标签有效性
for tag in level2:if tag not in system.tag_config.LEVEL2.get(level1, []):return jsonify({'status': 400, 'msg': '无效的二级标签组合'})-
重复检查:清理问题文本后检查是否已存在
# 清理问题文本并检查是否已存在
clean_q = clean_text(question)
existing = [q['cleaned_question'] for q in system.qa_pairs]
if clean_q in existing:return jsonify({'status': 400, 'msg': '该问题已存在'})-
数据持久化:
-
将新问题追加到 CSV 文件中
-
更新内存中的问答对列表
-
计算并更新问题的向量表示
-
# 以追加模式打开QA文件
with open(system.config.QA_FILE, 'a', newline='', encoding='utf-8') as f:# 创建CSV写入器writer = csv.writer(f)# 写入新行:问题、答案、一级标签、用斜杠连接的二级标签writer.writerow([question, answer, level1, '/'.join(level2)])# 创建内存中的新条目字典new_entry = {"original_question": question, # 原始问题"cleaned_question": clean_q, # 清洗后问题"answer": answer, # 答案"tags": {'level1': level1, # 一级标签'level2': level2 # 二级标签列表}}# 将新条目添加到内存列表system.qa_pairs.append(new_entry)# 获取新问题的嵌入向量并调整形状new_vec = system._get_embedding(clean_q).reshape(1, -1)# 将新向量垂直堆叠到现有向量矩阵system.question_vectors = np.vstack([system.question_vectors, new_vec])# 返回成功响应return jsonify({'status': 200, 'msg': '提交成功'})
-
错误处理:捕获异常并返回 500 错误
# 捕获所有异常
except Exception as e:# 返回500服务器错误及异常信息return jsonify({'status': 500, 'msg': f'服务器错误: {str(e)}'})3.2.3 文本清理函数
a.功能:用于清理输入的文本,去除非中文字符和停用词,并保留指定词性的词语。
b.细节:
-
移除特殊字符(保留中文和标点)
-
使用jieba进行分词和词性标注
-
过滤停用词(保留某些否定词和程度词)
-
只保留特定词性(名词(n)、动词(v)、形容词(a)、人名(nr)、地名(ns))
-
返回用空格连接的关键词串
def clean_text(text: str) -> str:# 使用正则表达式移除所有非中文字符、非汉字字符(保留中文标点??!!)text = re.sub(r"[^\w\u4e00-\u9fa5??!!]", "", text)# 去除文本首尾空白字符text = text.strip()# 使用jieba分词器进行词性标注分词(pseg.cut)# 返回生成器,产生(词, 词性)元组words = pseg.cut(text)# 初始化停用词集合stopwords = set()# 打开停用词文件(使用Config中定义的路径)with open(Config.STOPWORDS_FILE, "r", encoding='utf-8') as f:for line in f:# 去除每行首尾空白word = line.strip()# 保留有意义的否定词和程度词,添加到停用词集合if word not in ["不", "没", "非常", "极其"]:stopwords.add(word)# 定义需要保留的词性集合:# n-名词, v-动词, a-形容词, nr-人名, ns-地名keep_pos = {'n', 'v', 'a', 'nr', 'ns'}# 使用列表推导式过滤词语:# 1. 词性标记的首字母在保留集合中# 2. 词语不在停用词集合中filtered_words = [word for word, flag in wordsif flag[0] in keep_pos and word not in stopwords]# 用空格连接过滤后的词语,返回处理后的字符串return " ".join(filtered_words)c. 例子
原始输入: "Python是一种非常流行的编程语言!"
处理流程:
1. 移除"!" → "Python是一种非常流行的编程语言"
2. 分词+词性标注: [('Python','n'), ('是','v'), ('一种','m'), ('非常','d'), ('流行','v'), ('的','uj'), ('编程','v'), ('语言','n')]
3. 过滤后: ['Python', '流行', '编程', '语言']
4. 返回结果: "Python 流行 编程 语言"3.2.4 问答系统类
a.功能:问答系统的核心实现。
b.主要方法
- 类初始化
__init__-
接收配置对象
-
初始化标签管理系统
-
按顺序执行:模型加载 → 数据加载 → 向量计算 → 向量验证
-
def __init__(self, config: Config):self.config = config # 存储配置对象self.tag_config = TagConfig(config.QA_FILE) # 初始化标签配置self.qa_pairs = [] # 存储问答对self._load_model() # 加载BERT模型self._load_data() # 加载问答数据self._prepare_vectors() # 预计算问题向量self._validate_vectors() # 验证向量质量-
模型加载
_load_model-
加载预训练的BERT模型和分词器
-
设置模型为评估模式
-
指定设备(CPU/GPU)
-
def _load_model(self):# 加载BERT分词器和模型self.tokenizer = BertTokenizer.from_pretrained(self.config.BERT_PATH)self.model = BertModel.from_pretrained(self.config.BERT_PATH,output_hidden_states=True # 获取所有隐藏层输出).to(self.config.DEVICE) # 自动选择GPU/CPUself.model.eval() # 设置为评估模式- 数据加载
_load_data-
从CSV文件加载问答对数据
-
对每个问题:
-
清理文本
-
验证标签
-
存储原始问题、清理后的问题、答案和标签
-
-
数据处理流程:原始数据 → 标签解析 → 严格验证 → 文本清洗 → 内存存储
-
def _load_data(self):# 仅支持CSV格式with open(self.config.QA_FILE, 'r', encoding='utf-8') as f:reader = csv.DictReader(f)for row in reader:# 标签处理与验证tags = {'level1': row.get('一级标签', '').strip(),'level2': [t.strip() for t in row.get('二级标签', '').split('/') if t.strip()]}# 严格验证标签有效性if not tags['level1'] or tags['level1'] not in self.tag_config.LEVEL1:raise ValueError(f"无效的一级标签")# 存储处理后的数据self.qa_pairs.append({"original_question": row['问题'],"cleaned_question": clean_text(row['问题']), # 文本清洗"answer": row['答案'],"tags": tags})-
向量准备_prepare_vectors-
为所有问题预计算BERT嵌入向量
-
使用与
_get_embedding相同的融合策略 -
存储归一化后的向量矩阵
-
def _prepare_vectors(self):# 批量处理所有问题inputs = self.tokenizer([q["cleaned_question"] for q in self.qa_pairs],padding=True, truncation=True,max_length=512,return_tensors="pt").to(self.config.DEVICE)# 获取BERT各层输出with torch.no_grad():outputs = self.model(**inputs)# 融合最后4层隐藏状态(加权平均)hidden_states = outputs.hidden_states[-4:]weights = torch.tensor(self.config.LAYER_WEIGHTS).to(self.config.DEVICE)weights /= weights.sum()# 生成标准化向量self.question_vectors = np.array([torch.sum(torch.stack([hs[i][0] for hs in hidden_states]) * weights,dim=0).cpu().numpy()for i in range(len(self.qa_pairs))])# L2归一化self.question_vectors /= np.linalg.norm(self.question_vectors, axis=1, keepdims=True)-
搜索功能search-
搜索流程:
-
查询文本清洗和向量化
-
计算余弦相似度 + 非线性校准
-
结合关键词匹配权重
-
多维度结果过滤:
-
相似度阈值
-
内容去重
-
高相似结果去重
-
-
-
def search(self, query: str) -> List[Dict]:# 1. 查询预处理cleaned_query = clean_text(query)query_emb = self._get_embedding(cleaned_query)# 2. 计算相似度(带校准)raw_sim = np.dot(self.question_vectors, query_emb)calibrated = 1 / (1 + np.exp(-25*(raw_sim-0.88))) # Sigmoid校准similarities = 0.2*raw_sim + 0.8*calibrated# 3. 关键词增强query_keywords = set(jieba.lcut(cleaned_query))keyword_weights = np.array([len(set(jieba.lcut(q["cleaned_question"])) & query_keywords)/ max(len(query_keywords), 1)for q in self.qa_pairs])similarities = 0.7*similarities + 0.3*keyword_weights# 4. 结果过滤与排序results = []seen_hashes = set()for idx in np.argsort(-similarities):# 多种过滤条件...results.append({"question": self.qa_pairs[idx]["original_question"],"answer": self.qa_pairs[idx]["answer"],"similarity": float(similarities[idx]),"tags": self.qa_pairs[idx]["tags"]})return sorted(results, key=lambda x: -x['similarity'])[:self.config.TOP_K]-
带标签过滤的搜索方法
search_with_tags-
标签过滤采用"或空即通过"逻辑:如果未指定某级标签,则视为通过
-
当前实现中标签匹配不改变相似度(+0),但保留了权重调整接口
-
二级标签采用部分匹配策略(any)
-
def search_with_tags(self, query: str, selected_tags: Dict) -> List[Dict]:# 先获取基础搜索结果(不带标签过滤)base_results = self.search(query)filtered = []# 遍历所有结果进行标签过滤for item in base_results:# 检查一级标签匹配(如果selected_tags中有level1要求)l1_match = not selected_tags.get('level1') or \item['tags']['level1'] in selected_tags['level1']# 检查二级标签匹配(如果selected_tags中有level2要求)l2_match = not selected_tags.get('level2') or \any(tag in item['tags']['level2'] for tag in selected_tags['level2'])# 同时满足两级标签条件if l1_match and l2_match:# 理论上可以增加匹配标签的权重(当前实现为+0,保持原相似度)item['similarity'] = min(item['similarity'] + 0 * len(set(item['tags']['level2']) & set(selected_tags.get('level2', []))), 1.0)filtered.append(item)# 按相似度降序返回,限制结果数量return sorted(filtered, key=lambda x: -x['similarity'])[:self.config.TOP_K]-
文本向量化方法
_get_embedding-
使用BERT的[CLS]token作为文本表示
-
多层融合策略:最后4层加权求和(权重来自配置)
-
强制设备转移确保GPU/CPU一致性
-
最终向量进行L2归一化,方便余弦相似度计算
-
def _get_embedding(self, text: str) -> np.ndarray:# 使用BERT tokenizer处理文本inputs = self.tokenizer(text,return_tensors="pt", # 返回PyTorch张量padding=True, # 自动填充truncation=True, # 自动截断max_length=512 # 最大长度限制).to(self.config.DEVICE) # 发送到指定设备# 不计算梯度(推理模式)with torch.no_grad():outputs = self.model(**inputs)# 获取最后4层隐藏状态hidden_states = outputs.hidden_states[-4:]# 加载层级权重并归一化weights = torch.tensor(self.config.LAYER_WEIGHTS).to(self.config.DEVICE)weights /= weights.sum()# 提取每层的[CLS]向量(首向量)并堆叠cls_vectors = torch.stack([layer[:, 0, :] for layer in hidden_states])# 加权融合各层向量fused_vector = torch.sum(cls_vectors * weights.view(-1, 1, 1), dim=0)# 转为numpy数组并去除多余维度fused_vector = fused_vector.cpu().numpy().squeeze()# L2归一化后返回return fused_vector / np.linalg.norm(fused_vector)-
向量质量验证方法
_validate_vectors-
验证逻辑:
-
重复检测:确保相同文本生成的向量几乎相同(相似度≈1)
-
空间分析:计算所有向量两两之间的平均相似度,评估:
-
值过高 → 向量区分度不足
-
值过低 → 可能编码异常
-
-
典型健康值:0.2-0.5
-
-
def _validate_vectors(self):# 检查所有问题对for i in range(len(self.qa_pairs)):for j in range(i+1, len(self.qa_pairs)):# 发现文本完全重复的问题if self.qa_pairs[i]["cleaned_question"] == self.qa_pairs[j]["cleaned_question"]:# 计算向量相似度sim = np.dot(self.question_vectors[i], self.question_vectors[j])# 理论上相同文本的向量相似度应为1if abs(sim - 1.0) > 1e-6:print(f"警告:重复问题向量差异过大 [{i}] vs [{j}]: {sim:.4f}")# 计算整个向量空间的平均相似度avg_sim = np.mean(np.dot(self.question_vectors, self.question_vectors.T))print(f"向量空间平均相似度: {avg_sim:.2f}")3.2.5 主函数
-
初始化jieba分词
-
创建QASystem实例
-
启动Flask应用
def main():global systemjieba.initialize()system = QASystem(Config())app.run(host='0.0.0.0', port=5000, debug=False)if __name__ == "__main__":main()4. 总结
本周主要是进行环境配置,以及代码的阅读理解。通过本周的学习任务,我理解了一些爱问答系统的实现细节。核心即是采用BERT+标签体系的双通道架构,在文本处理方面采用保留关键否定词/程度词、基于词性的内容过滤、文本重复检测的哈希值对比机制等技术来实现。在向量化方面,掌握了BERT[CLS]向量的提取方法和多层表达融合技巧等。