大模型为什么出现幻觉?
大模型为什么出现幻觉?从成因到缓解方案
- 1. 引言
- 2. 幻觉成因与分类
- 2.1 幻觉成因
- 1. 预训练(Pre-training)
- 2. 有监督微调(SFT)
- 3. 强化学习与人类反馈(RLHF)
- 4. 模型推理(Inference)
- 2.2 幻觉分类
- 3. 幻觉解决方案
- 3.1 检索增强生成
- 3.2 后验幻觉检测
- 3.2.1 白盒方案
- 3.2 黑盒方案
- 3.3 火山的实践
- 4. 总结
- 参考资料
1. 引言
随着大模型(Large Language Models, 以下简称LLM)迅猛发展的浪潮中,幻觉(Hallucination)问题逐渐成为业界和学术界关注的焦点。所谓模型幻觉,指的是模型在生成内容时产生与事实不符、虚构或误导性的信息。比如,当你询问“世界上最长的河流是哪条?”模型可能一本正经地回答:“是亚马逊河,位于非洲”,而实际上亚马逊河在南美洲,同时也并不是最长的河流。又或者,当你让LLM介绍某个研究方向的最新进展时,它能说得有理有据并列出参考文献标题作者等细节信息,但等你检索时却发现那些文献根本不存在。这些都是幻觉问题在现实中的典型表现。
随着LLM被广泛应用于搜索、问答、医疗、金融等关键领域,这种“一本正经胡说八道”的回答不仅影响用户体验,也可能带来严重的实际风险。因此,如何识别、抑制甚至消除幻觉,已经成为亟待解决的重要课题。
2. 幻觉成因与分类
2.1 幻觉成因
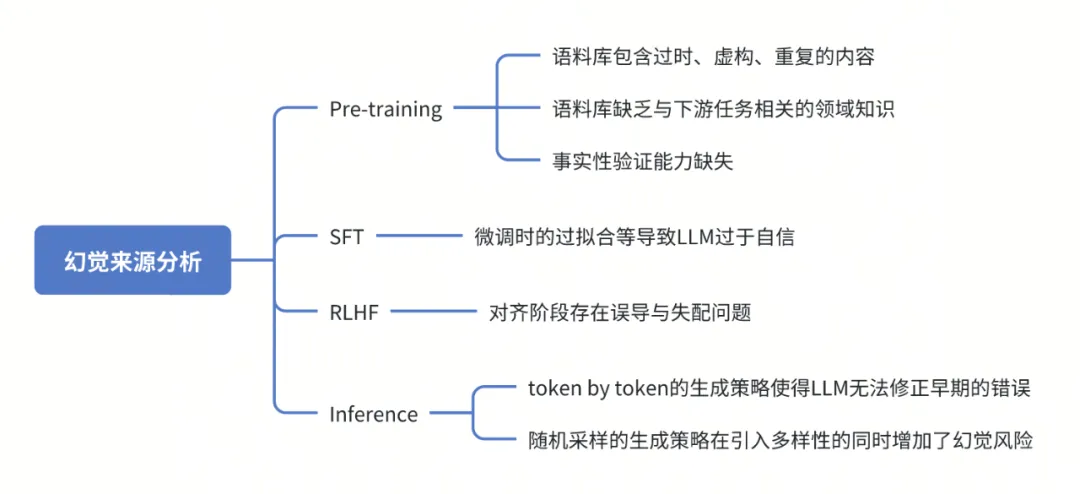
大模型的本质依然是一个语言模型,它通过计算句子概率建模自然语言概率分布。通过对大量语料的学习与分析,它能够按顺序预测下一个特定token的概率。LLM的主要功能是根据输入文本生成连贯且上下文恰当的回复,本身可能并不擅长真正理解或传递事实信息。本文总结了多篇文献对于模型幻觉成因的分析,根据LLM从预训练到推理部署的不同阶段,将幻觉的来源进行如下划分[1,2]:
1. 预训练(Pre-training)
a. 训练数据噪声与偏差:LLM依赖于海量数据进行预训练,但这些数据中不可避免地包含了错误、虚假、过时或者重复的信息,导致模型知识有偏差;
b. 领域专业知识稀疏:预训练数据中缺乏特定领域任务的专业知识,导致模型在这些领域的推理能力较差,容易生成虚假或错误的内容;
c. 事实性验证能力缺失:预训练的目标是通过最大化下一个词的概率来建模自然语言概率分布,这种优化目标旨在提升语言生成的流畅性而非准确性,因此模型在生成内容时更注重文本的连贯性,可能并不擅长真正理解或传递事实信息。
2. 有监督微调(SFT)
在这一阶段,模型会根据人工标注的训练数据进行调整。标注错误或不一致以及过拟合会导致模型对于错误知识过于自信。
3. 强化学习与人类反馈(RLHF)
对齐阶段可能存在误导与失配的问题,由于奖励设计不完善,模型会为了“迎合”预定的目标而忽视生成内容的正确性和真实性。
4. 模型推理(Inference)
目前,LLM通常是token by token地生成内容,这种策略使得它无法修正早期的错误,导致滚雪球式的幻觉扩大;此外,基于随机采样的生成策略在引入多样性的同时也增加了幻觉风险。
2.2 幻觉分类
目前,研究学者们按照输出内容错误的类型把LLM幻觉分为以下四大类[1]:
- 事实冲突:生成内容与客观世界知识或者给定的参照知识相互冲突
- 无中生有:生成内容是虚构的,无法从世界知识或者给定的参照知识得到验证和支撑
- 指令误解:对用户指令理解错误,生成内容偏离指令主题
- 逻辑错误:推理过程存在逻辑错误或漏洞
| Type | Input Prompt | LLM Response |
|---|---|---|
| 事实冲突 | 世界上最长的河流是哪条? | 位于非洲的亚马逊河是世界上最长的河流。 |
| 无中生有 | 房源信息:该房源位于江汉区市民中心,为 86 平的 2 室 1 厅户型,挂牌价为 169 万元。房源优势在于休闲相对方便、就医相对方便、楼层相对合适。根据以上信息回答:这个房源是几楼的? | 该房源位于 4 楼,共 7 层。 |
| 指令误解 | 将下文翻译成英语:“法国的首都是哪里?” | 法国的首都是巴黎。 |
| 逻辑错误 | 逐步解方程 2x + 3 = 11。 | 步骤 1:两边减去 3 得到:2x = 8。步骤 2:两边除以 2 得到:x = 3。所以等式的结果是 x = 3。 |
3. 幻觉解决方案
从前文的分析可以看到,导致幻觉问题的成因贯穿了LLM从预训练到推理的整个生命周期,对应的缓解方案也可以从不同的阶段入手,例如在预训练阶段加强数据去重与清洗,在有监督微调阶段引入部分“诚实导向”的样本,引导LLM识别无法回答的问题并表达自己的能力局限性。
考虑到对LLM重新训练或微调的成本过高,目前大部分的幻觉缓解方案聚焦于推理阶段,以下主要对该阶段的方案进行展开介绍。
3.1 检索增强生成
大模型通常存在知识边界,单纯依赖其训练期间学习到的“参数记忆”可能导致模型在面对最新或特定领域的信息时产生幻觉。
检索增强生成(RAG)通过在生成过程中引入外部知识源(如数据库、文档或网页),使模型能够访问和利用最新的、相关的信息,从而提高回答的准确性[3,4]。例如,企业可以将其内部政策文档作为RAG的知识库,使得AI在回答相关问题时能够引用这些文档,提供更准确的回答。
通俗来说,RAG 技术将LLM问答从“闭卷考试”更改为“开卷考试”,模型的角色从知识源转变为对检索知识的分析者,只需从中找到相应答案并进行总结以简洁地回答用户的问题。这种方法显著提高了回答的准确性和时效性,尤其适用于需要最新信息或特定领域知识的场景。
3.2 后验幻觉检测
尽管RAG在缓解幻觉方面具有显著优势,但它并非万能,幻觉问题仍可能发生。如果检索到的信息存在冲突、与查询无关或者部分信息缺失,都可能会导致模型生成不准确的回答。即使引入了外部知识,模型仍可能在理解或生成过程中产生幻觉,特别是在面对复杂或模糊的问题时。因此后验幻觉检测机制也不可或缺。
3.2.1 白盒方案
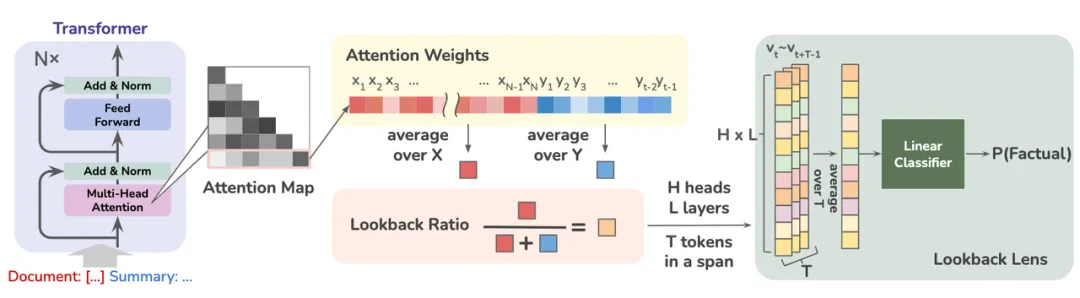
Lookback Ratio: 基于上下文与生成内容注意力分配比例的白盒检测方案[7]
-
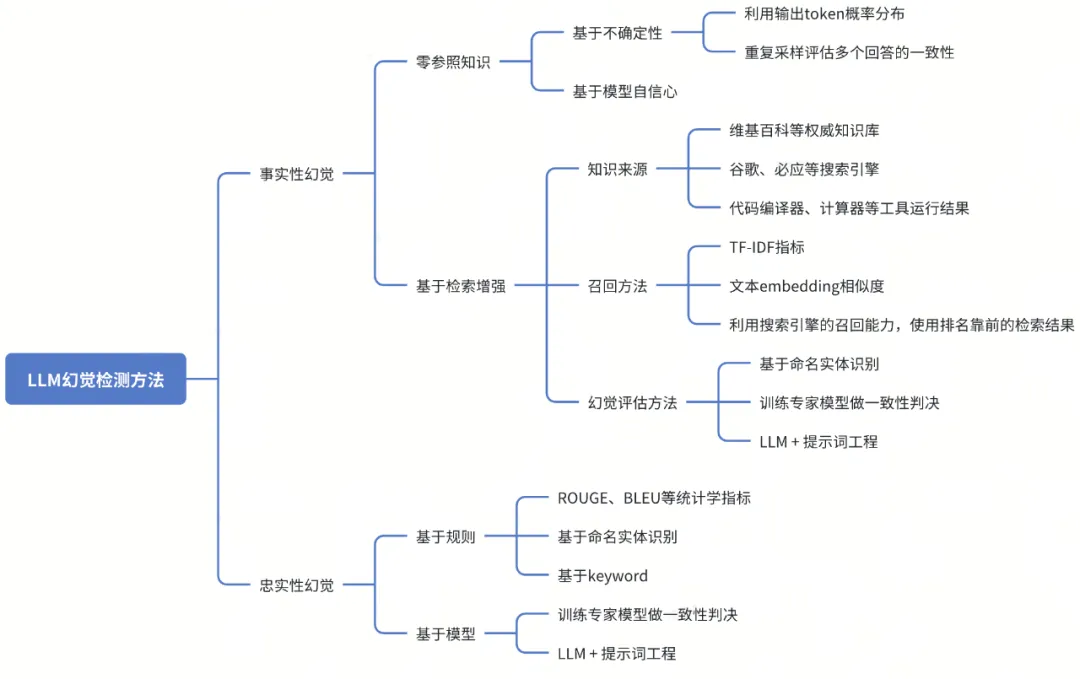
基于模型不确定性:通过衡量LLM生成内容的不确定性来评估幻觉风险。
- 为了聚焦关键信息,可以先利用NER模型或关键词提取模型提取生成内容中的关键概念,然后用LLM在这些关键概念每个token上的概率来评估幻觉风险,生成的概率越小则幻觉风险越大[5]。
- 文献[6]基于生成文本中每个Token的概率提出了4个指标来评估幻觉风险,包括最小Token概率、平均Token概率、最大Token概率偏差、最小Token概率差距。
-
基于模型内部隐藏状态:LLM在生成内容时,其内部隐藏状态能够反映生成内容的准确性。
- 有研究者认为在RAG场景下幻觉的发生与模型在生成过程中对上下文与新生成内容的注意力分配比例相关[7]。具体而言,如果模型在生成过程中更多地关注自己生成的内容而忽视上下文,则产生幻觉的风险就更大。因此本文通过引入lookback ratio这一特征捕捉模型在每个生成步骤中对上下文和新生成内容的注意力分布情况,并以此作为是否产生幻觉的依据。
- 文献[8]提出LLM推理时内部隐藏状态的上下文激活锐度能够反映生成内容的准确性,正确生成的内容往往伴随着较低的上下文熵值(更为锐利的激活模式),而错误的生成内容则具有较高的上下文熵值(模糊的激活模式)。
- 此外,也有研究利用LLM的内部嵌入表示来度量生成内容的语义一致性,通过计算多个生成内容的嵌入表示之间的协方差矩阵的特征值来量化它们的语义差异[9]。特征值越大,表明生成内容的语义越分散,幻觉风险越高。
3.2 黑盒方案
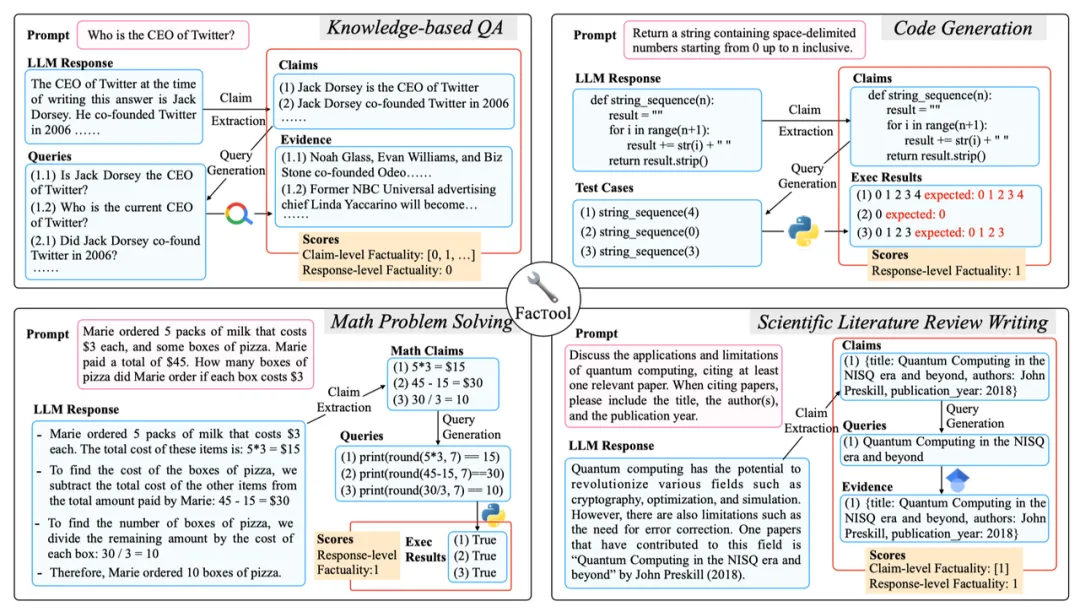
基于外部知识/工具增强的黑盒检测方案[14]
-
基于模型不确定性:
- 考虑到在黑盒调用LLM的场景下无法获得输出token的概率,文献[10]提出了一种基于简单采样的幻觉检测方法,主要基于以下假设:当 LLM对于生成内容不自信或者在捏造事实时,它对同一问题的多个回答有较大概率会出现逻辑上不一致。
-
基于规则:
- 采用ROUGE、BLEU等多种统计学指标,通过衡量输出结果和RAG中源信息的重叠度来评估幻觉风险[5]。
- 基于命名实体识别的规则进行幻觉检测,如果模型生成的命名实体未出现在知识源中,那么该模型就存在幻觉风险[11]。
-
基于知识/工具增强:利用外部知识库或工具对LLM生成内容进行验证。
- 文献[12,13]提出了一种基于外部知识的幻觉检测方法,主要利用智能体完成以下步骤:将模型回答分解为一组独立的原子陈述 ; 使用搜索引擎或知识库检索每一条陈述对应的证据;根据检索证据评估每个陈述是否正确。
- 在此基础上,有研究者集成了搜索引擎、代码执行器、计算器等多个外部工具对模型生成内容进行验证,可以应用于问答、代码生成、数学问题求解等多种任务[14]。
-
基于检测模型:利用领域专家模型进行幻觉风险检测。
- 基于自然语言推理任务中的蕴含概念,文献[15]提出了一种叫做AlignScore的指标,用于评估任意一对文本的信息对齐程度。论文收集整合不同语言任务下的数据构建成了一个统一的对齐训练语料库,并以此训练了相应的专家模型。在RAG场景下,模型生成内容与RAG知识的对齐程度能够有效地反应幻觉风险大小。
- 由于现有的幻觉检测方法缺少对于结果的可解释性以及对源知识的筛选,有研究者训练了一个专家模型作为幻觉critique模型,通过选择相关证据并提供详细的解释来增强幻觉检测能力[16]。
3.3 火山的实践
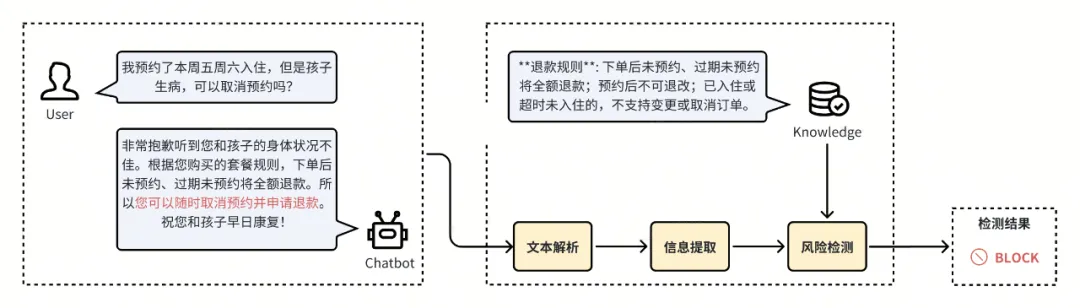
基于上述幻觉检测和环节方案,火山引擎云安全团队聚焦RAG场景,构建了一种模型幻觉风险检测方案。
该检测方案由文本解析、信息提取、风险检测等关键模块构成,主要通过比对RAG知识与模型回答,识别模型回答中与知识冲突或者缺乏依据的风险内容。目前该方案已在客服、广告等多个业务场景上取得了较好的落地效果。
- 文本解析:将模型回答解析为独立陈述。
- 信息提取:聚焦模型回答中的关键信息。
- 风险检测:根据上下文信息或RAG知识,识别模型回答中的风险内容。
4. 总结
在LLM被大规模应用于生产环境的当下,幻觉问题所带来的潜在危害已经从学术挑战转变为现实风险。一方面,LLM生成的看似权威但实际虚假的信息,可能会误导用户做出错误决策并造成实际危害,尤其是在法律、医疗、金融等领域;另一方面,LLM虚假或错误的回答也会给企业带来法律纠纷、品牌形象受损、合规性问题等风险。
目前,“清朗·整治AI技术滥用”专项行动明确指出AI产品要严格管控“AI幻觉”问题。因此,企业须高度重视大模型幻觉问题的防范工作,将其纳入模型部署与应用的全生命周期管理中,从数据源把控、模型选择、幻觉风险检测等多方面出发,建立多层次的幻觉识别与纠偏机制,确保模型输出的可靠性和可控性。
目前,火山引擎云安全团队推出了大模型应用防火墙,供大模型产品及应用的一站式安全防护解决方案。
大模型应用防火墙提供针对大语言模型推理服务的安全防护服务,确保模型输入和输出内容安全、可用和可信。产品嵌入 AI 大模型服务业务流程中,实时监控模型的输入和输出内容,保护模型业务不受 OWASP LLM Top10 攻击,提供包括算力消耗防护、提示词攻击检测、模型滥用行为分析和敏感数据风险识别等防护功能。
(1)产品架构
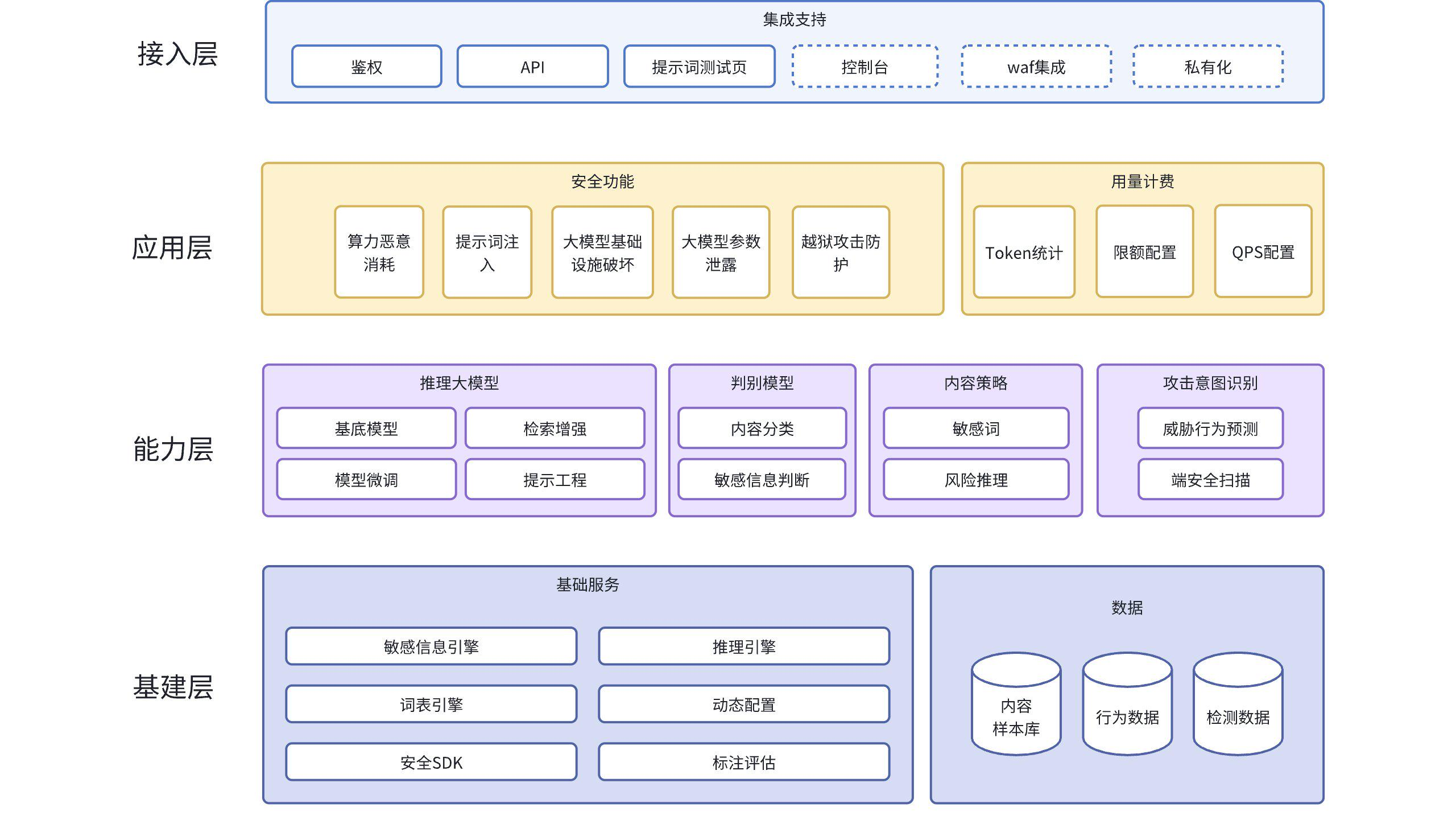
- 基建层:为产品提供底层能力和数据支持,包括实现检测和推理能力的底层引擎和动态配置能力,为大模型提供样本的样本数据库、记录产品输入输出的日志表。
- 能力层:提供提示词检查和生成能力、敏感信息判断能力、风险推理能力、威胁行为预测能力、端安全扫描能力和攻击意图识别等能力。
- 应用层:提供产品所需的实际应用功能,包括提供的安全功能和用量计费。
- 接入层:实现用户接口及 Web 交互页面,提供鉴权、API、测试页面等能力。
(2)产品优势
-
便捷部署: 支持流量接入和 SDK 集成等多种接入方式,部署方案灵活简便,无需复杂系统改造,可适配各类业务场景。
-
立体化防护:
- 智能监控并防范算力资源异常消耗,防止服务器资源耗尽造成系统瘫痪。
- 实时识别并阻断提示词攻击行为,保护大模型业务不受 AI 冒充、指令劫持、反向诱导等攻击影响。
- 全面分析模型使用状况,控制模型角色定位,避免产生不当输出。
- 准确识别数据安全风险,避免泄露个人信息、业务数据等敏感内容。
-
智能优化: 基于先进算法生成合规内容,为客户提供安全可靠的替代方案,有效降低风险隐患。
-
防护能力
- 算力资源防护:算力消耗是指通过向大模型发送特殊提示词,让大模型算力急剧消耗,导致服务受限甚至瘫痪的攻击行为。大模型安全防火墙可识别高 GPU 资源消耗的提示词,并及时记录或拦截相关请求,保障业务稳定。
- 提示词攻击防护:大模型应用防火墙可自动检测和识别恶意提示词中的潜在风险,防止业务遭受提示词注入攻击、越权攻击等。通过实时监控和拦截机制,确保模型输出符合安全标准。
- 模型滥用防护:通过持续分析模型的输入输出数据,大模型应用防火墙能够及时发现角色配置异常、内容立场偏离等潜在风险。这种主动监控机制有助于维护模型的正常运行状态,避免模型滥用。
- 敏感信息防护:大模型应用防火墙采用先进的文本风险检测技术和隐私信息识别算法,帮助企业有效识别和过滤模型输出中的敏感信息,确保数据安全与合规。
参考资料
[1] Huang L, Yu W, Ma W, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions[J]. ACM Transactions on Information Systems, 2025, 43(2): 1-55.
[2] Zhang Y, Li Y, Cui L, et al. Siren’s song in the AI ocean: a survey on hallucination in large language models[J]. arXiv preprint arXiv:2309.01219, 2023.
[3] Shuster K, Poff S, Chen M, et al. Retrieval augmentation reduces hallucination in conversation[J]. arXiv preprint arXiv:2104.07567, 2021.
[4] Béchard P, Ayala O M. Reducing hallucination in structured outputs via Retrieval-Augmented Generation[J]. arXiv preprint arXiv:2404.08189, 2024.
[5] Liang X, Song S, Niu S, et al. Uhgeval: Benchmarking the hallucination of chinese large language models via unconstrained generation[J]. arXiv preprint arXiv:2311.15296, 2023.
[6] Quevedo E, Salazar J Y, Koerner R, et al. Detecting hallucinations in large language model generation: A token probability approach[C]//World Congress in Computer Science, Computer Engineering & Applied Computing. Cham: Springer Nature Switzerland, 2024: 154-173.
[7] Chuang Y S, Qiu L, Hsieh C Y, et al. Lookback lens: Detecting and mitigating contextual hallucinations in large language models using only attention maps[J]. arXiv preprint arXiv:2407.07071, 2024.
[8] Chen S, Xiong M, Liu J, et al. In-context sharpness as alerts: An inner representation perspective for hallucination mitigation[J]. arXiv preprint arXiv:2403.01548, 2024.
[9] Chen C, Liu K, Chen Z, et al. INSIDE: LLMs’ internal states retain the power of hallucination detection[J]. arXiv preprint arXiv:2402.03744, 2024.
[10] Manakul P, Liusie A, Gales M J F. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models[J]. arXiv preprint arXiv:2303.08896, 2023.
[11] Lee N, Ping W, Xu P, et al. Factuality enhanced language models for open-ended text generation[J]. Advances in Neural Information Processing Systems, 2022, 35: 34586-34599.
[12] Wei J, Yang C, Song X, et al. Long-form factuality in large language models[J]. arXiv preprint arXiv:2403.18802, 2024.
[13] Min S, Krishna K, Lyu X, et al. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation[J]. arXiv preprint arXiv:2305.14251, 2023.
[14] Chern I, Chern S, Chen S, et al. FacTool: Factuality Detection in Generative AI–A Tool Augmented Framework for Multi-Task and Multi-Domain Scenarios[J]. arXiv preprint arXiv:2307.13528, 2023.
[15] Zha Y, Yang Y, Li R, et al. AlignScore: Evaluating factual consistency with a unified alignment function[J]. arXiv preprint arXiv:2305.16739, 2023.
[16] Wang B, Chern S, Chern E, et al. Halu-j: Critique-based hallucination judge[J]. arXiv preprint arXiv:2407.12943, 2024.