【系统全面】linux基础以及命令——基础知识介绍
Linux基础命令
在终端执行“ls -al”命令显示当前目录下的所有文件及文件夹的详细信息。
**pwd:**打印当前所在路径
**cd /home/:**改变路径、切换路径
**cd -:**进入上次目录
**cd ~:**进入home目录
**mkdir:**创建目录
**rmdir:**删除目录
**ls:**列出目录内容
复制目录时,常用如下命令: $ cp -rfd dir_a dir_b
⚫ r:recursive,递归地,即复制所有文件
⚫ f:force,强制覆盖
⚫ d:如果源文件为链接文件,也只是把它作为链接文件复制过去,而不是复制实际文件
删除目录时,常用如下命令: $ rm -rf dir_a
⚫ r:recursive,递归地,即删除所有文件
⚫ f:force,强制删除
**cat:**串联文件的内容并打印出来
**touch:**修改文件的时间,如果文件不存在则创建空文件
**chgrp:**改变文件所属用户组 -R:进行递归的持续更改,也连同子目录下的所有文件、目录都更新成为这个 用户组之意。常常用在更改某一目录内所有文件的情况。
**chown:**改变文件所有者 chown [-R] 账号名 文件或目录 chown [-R] 账号名:组名 文件或目录 ⚫ -R:也是递归子目录。
**chmod:**改变文件的权限 文件权限有两种设置方法:数字类型改变权限和符号改变权限。 首先说明各个权限对应的数字: ⚫ r: 4或0 ⚫ w: 2或0 ⚫ x: 1或0 这3种权限的取值相加后,就是权限的数字表示。例如:文件a的权限为“ rwxrwx—”,它的数值表示为: ⚫ owner = rwx = 4+2+1 = 7 ⚫ group = rwx = 4+2+1 = 7 ⚫ others = — = 0+0 +0 = 0 所以在设置权限时,该文件的权限数字就是770。 数字类型改变权限 使用数值改变文件权限的命令如下: chmod [-R] xyz 文件或目录 ⚫ xyz:代表权限的数值,如770。 ⚫ -R:以递归方式进行修改,比如修改某个目录下所有文件的属性。
或者使用u、g、o三个字母代表user、group、others 3中身份。此外a代表 all,即所有身份。 范例: chmod u=rwx,go=rx .bashrc 也可以增加或去除某种权限,“+”表示添加权限,“-”表示去除权限: chmod a+w .bashrc chmod a-x .bashrc
find 目录名 选项 查找条件 :$ find /home/book/dira/ -name " test1.txt "
$ find /home/book -mtime -2 //查找/home目录下两天内有变动的文件。
grep [选项] [查找模式] [文件名]:查找文件中符合条件的字符串
grep -rn “字符串” 文件名 r(recursive):递归查找 n(number)显示目标位置的行号
$ grep “ABC” * -nR | grep “.h” :搜索包含有ABC的头文件
gzip : gzip 的常用选项: ⚫ -l(list) ⚫ -k(keep) 列出压缩文件的内容。 在压缩或解压时,保留输入文件。 ⚫ -d(decompress) 将压缩文件进行解压缩。
bzip2 bzip2 的常用选项: ⚫ -k(keep) 在压缩或解压时,保留输入文件; ⚫ -d(decompress) 将压缩文件进行解压缩;
**tar :**tar 常用选项: ⚫ -c(create):表示创建用来生成文件包 。 ⚫ -x:表示提取,从文件包中提取文件。 ⚫ -t:可以查看压缩的文件。 ⚫ -z:使用 gzip 方式进行处理,它与”c“结合就表示压缩,与”x“结合就表示解压缩。 ⚫ -j:使用bzip2方式进行处理,它与”c“结合就表示压缩,与”x“结合就表示解压缩。 ⚫ -v(verbose):详细报告tar处理的信息。 ⚫ -f(file):表示文件,后面接着一个文件名。 -C <指定目录> 解压到指定目录。
ping www.baidu.com:访问百度
**ifconfig :**查看网络、设置IP。ifconfig常用选项: ⚫ -a :显示所有网卡接口 ⚫ up:激活网卡接口 ⚫ down:关闭网卡接口 ⚫ address:xxx.xxx.xxx.xxx,IP 地址
Vi编辑器:
$ vi 文件名 :wq 保存并退出文件
file 文件名:查看文件类型
$ which pwd //定位到/bin/pwd
$ which gcc //定位到/usr/bin/gcc
$ whereis pwd //可得到可执行程序的位置和手册页的位置
gedit: 是一个窗口式的编辑器,只能在Ubuntu桌面环境下使用。在终端里,可以直接运行gedit命令打开编辑器,也可以运行“gedit 文 件名”打开指定文件。
解决Ubantu不能上网
先:sudo dhclient ens33;;;;ip a
后:看看route和DNS
如果执行以下命令不成功,表示路由没设置好:
$ ping 8.8.8.8 connect: Network is unreachable
如果“ping 8.8.8.8”成功,但是“ping www.baidu.com”不成功,则是DNS 没设置好:
$ ping www.baidu.com ping: unknown host www.baidu.com
DNS的设置比较简单,8.8.8.8是好记好用的DNS服务器,修改Ubuntu中的 /etc/resolv.conf文件,内容如下: nameserver 8.8.8.8 路由信息使用route命令查看,其输出信息可以参考链接: https://akaedu.github.io/book/ch36s05.html
什么是gcc
gcc的全称是GNU Compiler Collection,它是一个能够编译多种语言的编译器。
最开始gcc是作为C语言的编译器(GNU C Compiler),现在除了c语言,还支持C++、java、Pascal等语言。
GCC 的主要作用是将源代码编译成机器语言
glibc 是Linux 系统上最常用的C标准库实现之一,它实现了C标准规定的所有标准库函数以及 POSIX(可移植操作系统接口)的扩展。
总的来说,GCC是编译器,负责将源代码转换为可执行代码;glibc是运行时库,提 供程序运行所需的标准函数和操作系统服务的接口;而GNU C则定义了GCC支持的C语言 的标准和扩展。
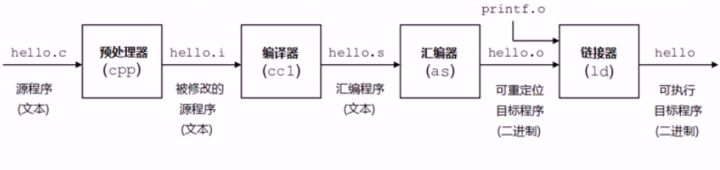
gcc工作流程
-
预处理(–E)
- 宏替换
- 头文件展开
- 去掉注释
- .c文件变成了.i文件(本质上还是.c文件,只不过#include中的程序给链接进去)
-
编译(–S)
- gcc调用不同语言的编译器
- .i文件编程.s(汇编文件)
- 生成汇编文件
-
汇编(-c)
- .s文件转化成.o文件
- 翻译成机器语言指令
- 二进制文件
-
链接
- .o文件变成可执行文件,一般不加后缀
预处理实际上是将头文件、宏进行展开。
编译阶段gcc调用不同语言的编译器。gcc实际上是个工具链,在编译程序的过程中调用不同的工具。
汇编阶段gcc调用汇编器进行汇编。汇编语言是一种低级语言,在不同的设备中对应着不同的机器语言指令,一种汇编语言专用于某种计算机体系结构,可移植性比较差。通过相应的汇编程序可以将汇编语言转换成可执行的机器代码这一过程叫做汇编过程。汇编器生成的是可重定位的目标文件,在源程序中地址是从0开始的,这是一个相对地址,而程序真正在内存中运行时的地址肯定不是从0开始的,而且在编写源代码的时候也不能知道程序的绝对地址,所以重定位能够将源代码的代码、变量等定位为内存具体地址。
链接过程会将程序所需要的目标文件进行链接成可执行文件。
gcc常用参数
- -v/–version:查看gcc的版本
- -I:编译的时候指定头文件路径,不然头文件找不到
- -c:将汇编文件转换成二进制文件,得到.o文件
- -g:gdb调试的时候需要加
- -D:编译的时候指定一个宏(调试代码的时候需要使用例如printf函数,但是这种函数太多了对程序性能有影响,因此如果没有宏,则#ifdefine的内容不起作用)
- -wall:添加警告信息
- -On:-O是优化代码,n是优化级别:1,2,3
静态库和动态库
![clip_image002[4]](https://i-blog.csdnimg.cn/img_convert/ab945692f7a7e7c1c1bb83c8d78edac2.png)
-
什么是库?
-
库是写好的现有的,成熟的,可以复用的代码。
-
现实中每个程序都要依赖很多基础的底层库,不可能每个人的代码都从零开始,因此库的存在意义非同寻常。
-
库是二进制文件,.o文件
-
将源代码变成二进制的源代码
-
主要起到加密的作用,为了防止泄露
-
-
静态库的制作
-
原材料:源代码(.c或.cpp文件)
-
将.c文件生成.o文件(ex:g++ a.c -c)
-
将.o文件打包
- ar rcs 静态库名称 原材料(ex: ar rcs libtest.a a.0)
-
静态库的使用

-
-
动态库的制作(so代表动态库)
- 命名规则:libxxx.so
- 制作步骤
- 将源文件生产.o文件(gcc a.c -c -fpic)
- 打包(gcc -shared a.o -o libxxx.so)
- 动态库的使用
- 跟静态库一样
- 动态库无法加载的问题
- 使用环境变量(临时设置和全局设置)
gdb相关问题
- gdb 不能显示代码(No symbol table is loaded. Use the “file” command)
- 要使用-g 比如: g++ map_test.cpp -g -o mao
makefile
使用keil, mdk,avr等工具开发程序时点击鼠标就可以编译了,它的内部机制是什么?它怎么组织管理程序?怎么决定编译哪一个文件?
答:实际上windows工具管理程序的内部机制,也是Makefile,我们在linux下来开发裸板程序的时候,使用Makefile组织管理这些程序,Makefile要做什么事情呢?组织管理程序,组织管理文件。
当某程序运行时,第一次编译 a.c 得到 xxx.o 文件,这是很合乎情理的, 执行完第一次之后,如果修改 a.c 又再次执行:gcc -o test a.c b.c,对于 a.c 应该重新生成 xxx.o,但是对于 b.c 又会重新编译一次,这完全没有必要,b.c 根本没有修改,直接使用第一次生成的 yyy.o 文件就可以了。
缺点:对所有的文件都会再处理一次,即使 b.c 没有经过修改,b.c 也会重新编译一次,当文件比较少时,这没有没有什么问题,当文件非常多的时候,就会带来非常多的效率问题如果文件非常多的时候,我们,只是修改了一个文件,所用的文件就会重新处理一次,编译的时候就会等待很长时间。
对于这些源文件,我们应该分别处理,执行:预处理 编译 汇编,先分别编译它们,最后再把它们链接在一次,比如:
编译:
gcc -o a.o a.c
gcc -o b.o b.c
链接:
gcc -o test a.o b.o
比如:上面的例子,当我们修改a.c之后,a.c会重现编译然后再把它们链接在一起就可以了。b.c
就不需要重新编译。
那么问题又来了,怎么知道哪些文件被更新了/被修改了?
比较时间:比较 a.o 和 a.c 的时间,如果a.c的时间比 a.o 的时间更加新的话,就表明 a.c 被修改了,同理b.o和b.c也会进行同样的比较。比较test和 a.o,b.o 的时间,如果a.o或者b.o的时间比test更加新的话,就表明应该重新生成test。Makefile
makefie最基本的语法是规则,规则:
目标 : 依赖1 依赖2 ...
[TAB]命令
当“依赖”比“目标”新,执行它们下面的命令。我们要把上面三个命令写成makefile规则,如下:
test :a.o b.o //test是目标,它依赖于a.o b.o文件,一旦a.o或者b.o比test新的时候,
就需要执行下面的命令,重新生成test可执行程序。
gcc -o test a.o b.o
a.o : a.c //a.o依赖于a.c,当a.c更加新的话,执行下面的命令来生成a.o
gcc -c -o a.o a.c
b.o : b.c //b.o依赖于b.c,当b.c更加新的话,执行下面的命令,来生成b.o
gcc -c -o b.o b.c
执行make命令的时候,就会在当前目录下面找到名字为:Makefile的文件,根据里面的内容来执行里面的判断/命令。
Makefile的语法
官方文档: http://www.gnu.org/software/make/manual/
a. 通配符
若某目标文件所依赖的依赖文件很多,那样岂不是我们要写很多规则,这显然是不合乎常理的,我们可以使用通配符,来解决这些问题。
我们对上节程序进行修改代码如下:
test: a.o b.o gcc -o test $^%.o : %.cgcc -c -o $@ $<
%.o:表示所有的.o文件
%.c:表示所有的.c文件
$@:表示目标
$<:表示第1个依赖文件
$^:表示所有依赖文件
我们来在该目录下增加一个 c.c 文件,代码如下:了
#include <stdio.h>void func_c()
{printf("This is C\n");
}
然后在main函数中调用修改Makefile,修改后的代码如下:
test: a.o b.o c.ogcc -o test $^%.o : %.cgcc -c -o $@ $<
执行:
make
结果:
gcc -c -o a.o a.c
gcc -c -o b.o b.c
gcc -c -o c.o c.c
gcc -o test a.o b.o c.o
运行:
./test
结果:
This is B
This is C
b. 假想目标: .PHONY
1.我们想清除文件,我们在Makefile的结尾添加如下代码就可以了:
clean:rm *.o test
*1)执行 make :生成第一个可执行文件。
*2)执行 make clean : 清除所有文件,即执行: rm *.o test。
make后面可以带上目标名,也可以不带,如果不带目标名的话它就想生成第一个规则里面的第一个目标。
2.使用Makefile
执行:make [目标] 也可以不跟目标名,若无目标默认第一个目标。我们直接执行make的时候,会在makefile里面找到第一个目标然后执行下面的指令生成第一个目标。当我们执行 make clean 的时候,就会在 Makefile 里面找到 clean 这个目标,然后执行里面的命令,这个写法有些问题,原因是我们的目录里面没有 clean 这个文件,这个规则执行的条件成立,他就会执行下面的命令来删除文件。
如果:该目录下面有名为clean文件怎么办呢?
我们在该目录下创建一个名为 “clean” 的文件,然后重新执行:make然后make
clean,结果(会有下面的提示:):
make: \`clean' is up to date.
它根本没有执行我们的删除操作,这是为什么呢?
我们之前说,一个规则能过执行的条件:
*1)目标文件不存在
*2)依赖文件比目标新
现在我们的目录里面有名为“clean”的文件,目标文件是有的,并且没有依赖文件,没有办法判断依赖文件的时间。这种写法会导致:有同名的"clean"文件时,就没有办法执行make clean操作。解决办法:我们需要把目标定义为假象目标,用关键子PHONY
.PHONY: clean //把clean定义为假象目标。他就不会判断名为“clean”的文件是否存在,
然后在Makfile结尾添加.PHONY: clean语句,重新执行:make clean,就会执行删除操作。
C. 变量
在makefile中有两种变量:
1), 简单变量(即使变量):
A := xxx # A的值即刻确定,在定义时即确定
对于即使变量使用 “:=” 表示,它的值在定义的时候已经被确定了
2)延时变量
B = xxx # B的值使用到时才确定
对于延时变量使用“=”表示。它只有在使用到的时候才确定,在定义/等于时并没有确定下来。
想使用变量的时候使用“$”来引用,如果不想看到命令是,可以在命令的前面加上"@"符号,就不会显示命令本身。当我们执行make命令的时候,make这个指令本身,会把整个Makefile读进去,进行全部分析,然后解析里面的变量。常用的变量的定义如下:
:= # 即时变量
= # 延时变量
?= # 延时变量, 如果是第1次定义才起效, 如果在前面该变量已定义则忽略这句
\+= # 附加, 它是即时变量还是延时变量取决于前面的定义
?=: 如果这个变量在前面已经被定义了,这句话就会不会起效果,
实例:
A := $(C)
B = $(C)
C = abc#D = 100ask
D ?= weidongshanall:@echo A = $(A)@echo B = $(B)@echo D = $(D)C += 123
执行:
make
结果:
A =
B = abc 123
D = weidongshan
分析:
- A := $©:
A为即使变量,在定义时即确定,由于刚开始C的值为空,所以A的值也为空。
-
B = $©:
B为延时变量,只有使用到时它的值才确定,当执行make时,会解析Makefile里面的所用变量,所以先解析C= abc,然后解析C += 123,此时,C = abc 123,当执行:@echo B = $(B) B的值为 abc 123。 -
D ?= weidongshan:
D变量在前面没有定义,所以D的值为weidongshan,如果在前面添加D = 100ask,最后D的值为100ask。
我们还可以通过命令行存入变量的值 例如:
执行:make D=123456 里面的 D ?= weidongshan 这句话就不起作用了。
结果:
A =
B = abc 123
D = 123456
Makefile函数
makefile里面可以包含很多函数,这些函数都是make本身实现的,下面我们来几个常用的函数。引用一个函数用“$”。
函数foreach
函数foreach语法如下:
$(foreach var,list,text)
前两个参数,‘var’和‘list’,将首先扩展,注意最后一个参数 ‘text’ 此时不扩展;接着,对每一个 ‘list’ 扩展产生的字,将用来为 ‘var’ 扩展后命名的变量赋值;然后 ‘text’ 引用该变量扩展;因此它每次扩展都不相同。结果是由空格隔开的 ‘text’。在 ‘list’ 中多次扩展的字组成的新的 ‘list’。‘text’ 多次扩展的字串联起来,字与字之间由空格隔开,如此就产生了函数 foreach 的返回值。
实例:
A = a b c
B = $(foreach f, &(A), $(f).o)all:@echo B = $(B)
结果:
B = a.o b.o c.o
函数filter/filter-out
函数filter/filter-out语法如下:
$(filter pattern...,text) # 在text中取出符合patten格式的值
$(filter-out pattern...,text) # 在text中取出不符合patten格式的值
实例:
C = a b c d/D = $(filter %/, $(C))
E = $(filter-out %/, $(C))all:@echo D = $(D)@echo E = $(E)
结果:
D = d/
E = a b c
Wildcard
函数Wildcard语法如下:
$(wildcard pattern) # pattern定义了文件名的格式, wildcard取出其中存在的文件。
这个函数 wildcard 会以 pattern 这个格式,去寻找存在的文件,返回存在文件的名字。
实例:
在该目录下创建三个文件:a.c b.c c.c
files = $(wildcard *.c)all:@echo files = $(files)
结果:
files = a.c b.c c.c
我们也可以用wildcard函数来判断,真实存在的文件
实例:
files2 = a.c b.c c.c d.c e.c abc
files3 = $(wildcard $(files2))all:@echo files3 = $(files3)
结果:
files3 = a.c b.c c.c
patsubst函数

任意取一行,如:drwxr-xr-x 2 root root 4096 2009-01-14 17:34 bin
用序列表示为:0123456789
-
第一列
- d:代表目录
- -:代表文件
- l:代表链接,如同windows的快捷方式
-
第一到九列
- r:可读
- w:可写
- x:可执行文件
- 0:代表文件类型
- 123:表示文件所有者的权限
- 456:表示同组用户的权限
- 789:表示其他用户的权限
-
权限的数字表示
- 读取的权限等于4,用r表示
- 写入的权限等于2,用w表示
- 执行的权限等于1,用x表示
-
改变文件权限命令
chmod 权限数字(如777) filename
-
改变目录下所有的文件的权限命令
chmod -R 权限数字(如777) 目录(如/home)
系统调用知识点
用户态和内核态
l链接
系统调用过程
用户空间的程序无法直接执行内核代码,它们不能直接调用内核空间中的函数,因为内核驻留在受保护的地址空间上。如果进程可以直接在内核的地址空间上读写的话,系统安全就会失去控制。所以,应用程序应该以某种方式通知系统,告诉内核自己需要执行一个系统调用,希望系统切换到内核态,这样内核就可以代表应用程序来执行该系统调用了。
通知内核的机制是靠软件中断实现的。首先,用户程序为系统调用设置参数。其中一个参数是系统调用编号。参数设置完成后,程序执行“系统调用”指令。这个指令会导致一个异常:产生一个事件,这个事件会致使处理器切换到内核态并跳转到一个新的地址,并开始执行那里的异常处理程序。此时的异常处理程序实际上就是系统调用处理程序。它与硬件体系结构紧密相关。
**系统调用的过程:**首先将API函数参数压到栈上,然后将函数内调用系统调用的代码放入寄存器,通过陷入中断,进入内核将控制权交给操作系统,操作系统获得控制后,将系统调用代码拿出来,跟操作系统一直维护的一张系统调用表做比较,已找到该系统调用程序体的内存地址,接着访问该地址,执行系统调用。执行完毕后,返回用户程序
系统调用和函数调用区别
库函数调用
函数调用主要通过压栈出栈的操作,面向应用开发。库函数顾名思义是把函数放到库里。是把一些常用到的函数编完放到一个文件里,供别人用。别人用的时候把它所在的文件名用#include<>加到里面就可以了。一般是指编译器提供的可在c源程序中调用的函数。可分为两类,一类是c语言标准规定的库函数,一类是编译器特定的库函数。(由于版权原因,库函数的源代码一般是不可见的,但在头文件中你可以看到它对外的接口)
系统调用
系统调用就是用户在程序中调用操作系统所提供的一个子功能,也就是系统API,系统调用可以被看做特殊的公共子程序。通俗的讲是操作系统提供给用户程序调用的一组“特殊”接口。用户程序可以通过这组“特殊”接口来获得操作系统内核提供的服务,比如用户可以通过文件系统相关的调用请求系统打开文件、关闭文件或读写文件,可以通过时钟相关的系统调用获得系统时间或设置定时器等。系统中的各种共享资源都由操作系统统一掌管,因此在用户程序中,凡是与资源有关的操作(如存储分配、进行I/O传输及管理文件等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
dup和fdtable:dup函数通过复制一个文件描述符来创建一个新的文件描述符。新文件描述符会与原文件描述符共享同一个file结构,从而实现多个文件描述符指向同一个文件。
文件I/O
文件(不带缓存的)I/O和标准(带缓存的)I/O
首先要明确一个问题:有无缓存是相对于用户层面来说的,而不是系统内核层面。在系统内核层面,一直都存在有“内核高速缓存”
-
不带缓存的概念
所谓不带缓存,并不是指内核不提供缓存,而是在用户进程层次没有提供缓存。不带缓存的I/O只存在系统调用(write和read函数),不是函数库的调用。系统内核对磁盘的读写都会提供一个块缓冲(在有些地方也被称为内核高速缓存),当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓存进行排队,当块缓存达到一定的量时,才会把数据写入磁盘。因此所谓的不带缓存的I/O是指用户进程层面不提供缓存功能(但内核还是提供缓冲的)。
文件I/O以文件标识符(整型)作为文件唯一性的判断依据。这种操作与系统有关,移植有一定的问题。
-
带缓存的概念
与之相对的就是带缓存I/O。而带缓存的是在不带缓存的基础之上封装了一层,在用户进程层次维护了一个输入输出缓冲区,使之能跨OS,成为ASCI标准,称为标准IO库。其实就是在用户层再建立一个缓存区,这个缓存区的分配和优化长度等细节都是标准IO库代你处理好了,不用去操心。第一次调用带缓存的文件操作函数时标准库会自动分配内存并且读出一段固定大小的内容存储在缓存中。所以以后每次的读写操作并不是针对硬盘上的文件直接进行的,而是针对内存中的缓存的。
不带缓存的文件操作通常都是系统提供的系统调用, 更加低级,直接从硬盘中读取和写入文件,由于IO瓶颈的原因,速度并不如意,而且原子操作需要程序员自己保证,但使用得当的话效率并不差。另外标准库中的带缓存文件IO 是调用系统提供的不带缓存IO实现的。
-
因此,标准I/O函数有两个优点:
1. 具有良好的移植性
2. 利用用户层提供的缓存区(流缓冲)提高性能
-
标准I/O函数缺点
- 不容易进行双向通信
- 有时可能频繁调用fflush函数
- 需要以FILE结构体指针的形式返回文件描述符
-
-
在Linux上操作文件时,有两套函数:标准IO、系统调用IO。标准IO的相关函数是:fopen/fread/fwrite/fseek/fflush/fclose 等 。 系 统 调 用 IO 的 相 关 函 数 是 : open/read/write/lseek/fsync/close。
这2种IO函数的差别如下图所示:
标准IO的内部,会分配一个用户空间的buffer,读写操作先经过这个buffer。在有必 要时,才会调用底下的系统调用IO向内核发起操作。 所以:标准IO效率更高;但是要访问驱动程序时就不能使用标准IO,而是使用系统调 用IO。
-
举例说明
**带缓冲的I/O在往磁盘写入相同的数据量时,会比不带缓冲的I/O调用系统调用的次数要少。**比如内核缓冲存储器长度为100字节,在进行写操作时每次写入10个字节,则你需要调用10次write函数才能把内核缓冲区写满。但是要注意此时数据还在缓冲区,不在磁盘中,缓冲区满时才进行实际的I/O操作,把数据写入到磁盘,这样调用了太多次系统调用,显得效率很低。但是若调用标准I/O函数,假设用户层缓冲区为50字节(称为流缓存),则用fwrite将数据写入到流缓存,等到流缓存区存满之后再进入内核缓存区,在调用write函数将数据写入到内核缓冲区中,若内核缓冲区满或执行fflush操作,那么内核缓冲区的数据会写入到磁盘中
- 无缓存IO操作数据流向路径:数据——内核缓存区——磁盘
- 标准IO操作数据流向路径:数据——流缓存区——内核缓存区——磁盘
-
apue三种io的总结
在apue中有三种io类型,如下:
- 文件I/O(不带缓冲的I/O):open、read、write、lseek、close
- 标准I/O(带缓冲的I/O):标准I/O库由ISO C标准说明
- 高级I/O:非阻塞I/O、I/O多路转接、异步I/O、readv和writev
函数原型
open、read、write
### 实例打开文件```#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>/** ./open 1.txt* argc = 2* argv[0] = "./open"* argv[1] = "1.txt"*/int main(int argc, char **argv)
{int fd;if (argc != 2){printf("Usage: %s <file>\n", argv[0]);return -1;}fd = open(argv[1], O_RDWR);if (fd < 0){printf("can not open file %s\n", argv[1]);printf("errno = %d\n", errno);printf("err: %s\n", strerror(errno));perror("open");}else{printf("fd = %d\n", fd);}while (1){sleep(10);}close(fd);return 0;}
#创建文件
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>/** ./create 1.txt* argc = 2* argv[0] = "./open"* argv[1] = "1.txt"*/int main(int argc, char **argv)
{int fd;if (argc != 2){printf("Usage: %s <file>\n", argv[0]);return -1;}fd = open(argv[1], O_RDWR | O_CREAT | O_TRUNC, 0777);if (fd < 0){printf("can not open file %s\n", argv[1]);printf("errno = %d\n", errno);printf("err: %s\n", strerror(errno));perror("open");}else{printf("fd = %d\n", fd);}while (1){sleep(10);}close(fd);return 0;
}
#在某位置写文件
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>/** ./write 1.txt str1 str2* argc = 2* argv[0] = "./open"* argv[1] = "1.txt"*/int main(int argc, char **argv)
{int fd;int i;int len;if (argc != 2){printf("Usage: %s <file>\n", argv[0]);return -1;}fd = open(argv[1], O_RDWR | O_CREAT, 0644);if (fd < 0){printf("can not open file %s\n", argv[1]);printf("errno = %d\n", errno);printf("err: %s\n", strerror(errno));perror("open");}else{printf("fd = %d\n", fd);}printf("lseek to offset 3 from file head\n");lseek(fd, 3, SEEK_SET);write(fd, "123", 3);close(fd);return 0;
}
#在某位置读
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>/** ./read 1.txt* argc = 2* argv[0] = "./read"* argv[1] = "1.txt"*/int main(int argc, char **argv)
{int fd;int i;int len;unsigned char buf[100];if (argc != 2){printf("Usage: %s <file>\n", argv[0]);return -1;}fd = open(argv[1], O_RDONLY);if (fd < 0){printf("can not open file %s\n", argv[1]);printf("errno = %d\n", errno);printf("err: %s\n", strerror(errno));perror("open");}else{printf("fd = %d\n", fd);}/* 读文件/打印 */while (1){len = read(fd, buf, sizeof(buf)-1);if (len < 0){perror("read");close(fd);return -1;}else if (len == 0){break;}else{/* buf[0], buf[1], ..., buf[len-1] 含有读出的数据* buf[len] = '\0'*/buf[len] = '\0';printf("%s", buf);}}close(fd);return 0;
}
一个实用:处理Excel
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h>
#include <string.h>
#include <unistd.h>/* 返回值: n表示读到了一行数据的数据个数(n >= 0)* -1(读到文件尾部或者出错)*/static int read_line(int fd, unsigned char *buf){/* 循环读入一个字符 *//* 如何判断已经读完一行? 读到0x0d, 0x0a */unsigned char c;int len;int i = 0;int err = 0;while (1){len = read(fd, &c, 1);if (len <= 0){err = -1;break;}else{if (c != '\n' && c != '\r'){buf[i] = c;i++;}else{/* 碰到回车换行 */err = 0;break;}}}buf[i] = '\0';if (err && (i == 0)){/* 读到文件尾部了并且一个数据都没有读进来 */return -1;}else{return i;}}void process_data(unsigned char *data_buf, unsigned char *result_buf)
{/* 示例1: data_buf = ",语文,数学,英语,总分,评价" * result_buf = ",语文,数学,英语,总分,评价" * 示例2: data_buf = "张三,90,91,92,," * result_buf = "张三,90,91,92,273,A+" **/char name[100];int scores[3];int sum;char *levels[] = {"A+", "A", "B"};int level;if (data_buf[0] == 0xef) /* 对于UTF-8编码的文件,它的前3个字符是0xef 0xbb 0xbf */{strcpy(result_buf, data_buf);}else{sscanf(data_buf, "%[^,],%d,%d,%d,", name, &scores[0], &scores[1], &scores[2]);//printf("result: %s,%d,%d,%d\n\r", name, scores[0], scores[1], scores[2]);//printf("result: %s --->get name---> %s\n\r", data_buf, name);sum = scores[0] + scores[1] + scores[2];if (sum >= 270)level = 0;else if (sum >= 240)level = 1;elselevel = 2;sprintf(result_buf, "%s,%d,%d,%d,%d,%s", name, scores[0], scores[1], scores[2], sum, levels[level]);//printf("result: %s", result_buf);}}/** ./process_excel data.csv result.csv* argc = 3* argv[0] = "./process_excel"* argv[1] = "data.csv"* argv[2] = "result.csv"*/int main(int argc, char **argv)
{int fd_data, fd_result;int i;int len;unsigned char data_buf[1000];unsigned char result_buf[1000];if (argc != 3){printf("Usage: %s <data csv file> <result csv file>\n", argv[0]);return -1;}fd_data = open(argv[1], O_RDONLY);if (fd_data < 0){printf("can not open file %s\n", argv[1]);perror("open");return -1;}else{printf("data file fd = %d\n", fd_data);}fd_result = open(argv[2], O_RDWR | O_CREAT | O_TRUNC, 0644);if (fd_result < 0){printf("can not create file %s\n", argv[2]);perror("create");return -1;}else{printf("resultfile fd = %d\n", fd_result);}while (1){/* 从数据文件里读取1行 */len = read_line(fd_data, data_buf);if (len == -1){break;}//if (len != 0)// printf("line: %s\n\r", data_buf);if (len != 0){/* 处理数据 */process_data(data_buf, result_buf);/* 写入结果文件 *///write_data(fd_result, result_buf);write(fd_result, result_buf, strlen(result_buf));write(fd_result, "\r\n", 2);}}close(fd_data);close(fd_result);return 0;}