数组去重性能优化:为什么Set和Object哈希表的效率最高
目录
数组去重性能优化:为什么Set和Object哈希表的效率最高
一、数组去重的基本概念
二、常见的数组去重方法
三、Set和Object哈希表综合复杂度为O(n)的秘密
1、数据结构区别
2、Set去重的底层原理
3、Set去重的鲁棒性
4、Set去重的局限性
四、总结
作者:watermelo37
CSDN万粉博主、华为云云享专家、阿里云专家博主、腾讯云、支付宝合作作者,全平台博客昵称watermelo37。
一个假装是giser的coder,做不只专注于业务逻辑的前端工程师,Java、Docker、Python、LLM均有涉猎。
---------------------------------------------------------------------
温柔地对待温柔的人,包容的三观就是最大的温柔。
---------------------------------------------------------------------

数组去重性能优化:为什么Set和Object哈希表的效率最高

一、数组去重的基本概念
数组去重是指从一个数组中移除重复的元素,保留唯一值的过程。例如,给定数组 [1, 2, 2, 3, 4, 4],去重后的结果为 [1, 2, 3, 4]。
在日常开发中,数组去重是一个常见的需求。无论是处理用户输入、分析数据集,还是实现某些特定算法,数组去重都能显著提升代码的效率和可读性。然而,随着数据规模的增长,不同的去重方法在性能上的差异也会愈发明显。本文将深入探讨数组去重的各种方法及其性能表现,并重点分析如何利用 Set 和哈希表实现高效的去重操作。
二、常见的数组去重方法
这篇博客主要讨论数组去重的性能,数组去重方法不细谈,有需求您可以移步到我写的数组去重方法合集,其中讨论了:数值类去重、引用类去重:去除完全重复的对象元素、引用类去重:去除部分重复的对象元素、特殊情况:对象的键值对顺序不同但其内容相同、混合数组去重五大类数组去重情景的各种去重方法,适用于任何场景:
全网最全情景,深入浅出解析JavaScript数组去重:数值与引用类型的全面攻略-CSDN博客文章浏览阅读3.3k次,点赞171次,收藏97次。在日常开发中,数组去重是一个不可避免的话题。不管是简单的数值数组去重,还是复杂的引用类型数组去重,掌握多种方法可以帮助开发者高效、优雅地解决实际问题。在这篇博客中,我们将从基础到进阶,结合大量代码案例,系统介绍数组去重的各种技巧。_f (!txt.includes(num)) { txt.push(num) 什么意思https://opengms-watermelo.blog.csdn.net/article/details/143950308
常见数组去重方法有:
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Set | 基础类型数组去重 | 简洁高效 | 无法处理引用类型 |
| 遍历 + includes | 基础类型数组去重 | 易理解 | 性能较低 |
| filter() + indexOf() | 基础类型数组去重 | 通用 | 性能较低 |
| reduce() | 复杂逻辑处理或混合类型数组去重 | 灵活,可扩展逻辑 | 写法稍复杂 |
| JSON.stringify+set | 引用类型数组去重 | 简洁 | 无法处理嵌套或无序字段的对象 |
| Map | 引用类型数组去重 | 性能较优,适合复杂数据结构 | 写法稍繁琐 |
有人做过一个测试:在处理一百万个数字的数组(有30%元素重复),使用常规方法去重,执行时间均超过30s,但是使用Set和Object哈希表用时在100ms左右。存在巨大的性能差距。
这里分享一下生成大量元素数组且重复元素比例可控的方法,这是我在别的资料里面找到的,感觉很有意思。
function generateTestArray(size) {const array = []; // 初始化一个空数组for (let i = 0; i < size; i++) {// 每次循环决定是否生成重复元素if (Math.random() > 0.7) {// 生成重复元素(30% 概率)array.push(array[Math.floor(Math.random() * array.length)] || 0);} else {// 生成新的随机数(70% 概率)array.push(Math.floor(Math.random() * size * 10));}}return array;
}拓展:该方法的系统误差
生成数的范围是0-10size。比如传入5,那就生成0-50之间的整数,传入1000,就生成0-10000之间的整数,其中有300个是确定重复的。 可是在0-10000之间的剩下的700个整数也有可能重复,重复的期望是多少呢?
首先,700个整数相对于10000来说很小,所以有3个整数相同的概率极低,故忽略,那么第i个生成的整数已经存在的概率为:
m为总范围,即10000,然后线性期望相加得到重复的数字数量为:
n是生成的数字总数,计算结果约为24.465个,即随机生成的重复率为:24.465/700,约为3.5%,即该方法生成数字的实际重复率约为:33.5%。
当然,其实真正的存在概率是:
综合期望是:
但是结果和近似估算几乎没差距,就不展开了。如果想降低这个系统误差,直接扩大size后面的乘数即可。
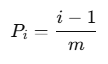
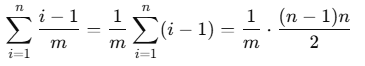
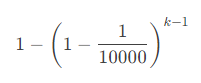
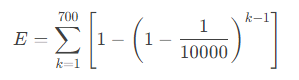
拓展:排序后去重
这种去重方法的时间复杂度为O(nlogn),额外开销主要由排序操作决定。但是这种方法只能用来进行基础数据类型的去重。同时会改变原始数组的顺序,在部分场景的使用受限。
为什么呢?
首先我们知道,遍历 + includes、filter() + indexOf()、reduce()只有写法上存在优雅与否,但是本质都是双循环,均为O(n²)复杂度,关键就在于Set和Object哈希表去重特别高效,接下来我们来探究一下Set和Object哈希表去重高效的原因。
三、Set和Object哈希表综合复杂度为O(n)的秘密
1、数据结构区别
Set 是 ES6 引入的一种集合数据结构,专门用于存储唯一值。它的底层实现基于哈希表,因此插入和查找的时间复杂度接近 O(1)。
Object哈希表就不用说了,本质就是利用Object键的映射创建了一个哈希表,只是没有哈希函数,且无法兼容引用类型(可以通过JSON.stringify()处理后兼容)。V8引擎中,Set使用哈希表和红黑树的组合实现,据测试Set的效率要略优于Object哈希表。
2、Set去重的底层原理
Set 的高效性源于其底层的哈希表实现。以下是关键步骤:
- 计算哈希值 :通过哈希函数将每个值映射到一个整数索引。
- 定位存储位置 :根据哈希值找到对应的存储位置。
- 检查冲突 :如果发生哈希冲突,则采用链地址法或开放地址法解决。
- 插入或跳过 :如果该位置已有相同值,则跳过;否则插入。
这种机制使得 Set 能够快速判断某个值是否已经存在,从而实现高效的去重。
3、Set去重的鲁棒性
我们来看一个特殊的例子:
function deduplicateWeirdValues(array) {return [...new Set(array)];
}const weirdArray = [0, -0, NaN, NaN, undefined, null, false, 0, "0"];
console.log(deduplicateWeirdValues(weirdArray));
// 输出: [0, NaN, undefined, null, false, "0"]在这样一个去重案例中,NaN !== NaN, 同时 0 == "0",但是Set只保留了一个NaN,同时又区分开了 0 与 "0" ,这是常规方法所做不到的:要么会保留所有的NaN,要么无法区分 0 和 "0"。
4、Set去重的局限性
仅限于基础数据类型的数组去重,如果涉及到引用类型的数组去重,一般需要结合JSON.stringify()函数(有局限性)或者设计对比函数来实现。详情可以参考这篇文章:
全网最全情景,深入浅出解析JavaScript数组去重:数值与引用类型的全面攻略
四、总结
数组去重过程中,本质可以简化为遍历原数组,然后通过去重算法判断是否重复,重复就去除,不重复就添加,所以综合复杂度一定是O(n)*x,x是去重算法的时间复杂度。Set和Object哈希表去重的时间复杂度正好是O(1),如果还要进一步优化,就需要再在去重算法上下功夫了。
只有锻炼思维才能可持续地解决问题,只有思维才是真正值得学习和分享的核心要素。如果这篇博客能给您带来一点帮助,麻烦您点个赞支持一下,还可以收藏起来以备不时之需,有疑问和错误欢迎在评论区指出~
其他热门文章,请关注:
极致的灵活度满足工程美学:用Vue Flow绘制一个完美流程图
你真的会使用Vue3的onMounted钩子函数吗?Vue3中onMounted的用法详解
DeepSeek:全栈开发者视角下的AI革命者
通过array.filter()实现数组的数据筛选、数据清洗和链式调用
通过Array.sort() 实现多字段排序、排序稳定性、随机排序洗牌算法、优化排序性能
TreeSize:免费的磁盘清理与管理神器,解决C盘爆满的燃眉之急
通过MongoDB Atlas 实现语义搜索与 RAG——迈向AI的搜索机制
深入理解 JavaScript 中的 Array.find() 方法:原理、性能优势与实用案例详解
el-table实现动态数据的实时排序,一篇文章讲清楚elementui的表格排序功能
MutationObserver详解+案例——深入理解 JavaScript 中的 MutationObserver
JavaScript中通过array.map()实现数据转换、创建派生数组、异步数据流处理、DOM操作等
前端实战:基于Vue3与免费满血版DeepSeek实现无限滚动+懒加载+瀑布流模块及优化策略
高效工作流:用Mermaid绘制你的专属流程图;如何在Vue3中导入mermaid绘制流程图
干货含源码!如何用Java后端操作Docker(命令行篇)
在线编程实现!如何在Java后端通过DockerClient操作Docker生成python环境
Dockerfile全面指南:从基础到进阶,掌握容器化构建的核心工具