Java-78 深入浅出 RPC Dubbo 负载均衡全解析:策略、配置与自定义实现实战
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月21日更新到:
Java-77 深入浅出 RPC Dubbo 负载均衡全解析:策略、配置与自定义实现实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

异步调用
Dubbo 不仅提供了传统的同步阻塞调用方式,还支持高效的异步调用模式。这种异步调用机制特别适用于以下场景:
- 服务提供者接口响应时间较长(如复杂计算、IO密集型操作)
- 消费者端需要并行处理多个服务调用
- 需要提高系统吞吐量和资源利用率
异步调用实现方式
服务定义
我们定义一个模拟耗时服务的接口,通过 timeToWait 参数控制服务端处理时长:
public interface GreetingService {/*** 模拟耗时服务* @param name 用户名* @param timeToWait 模拟处理耗时(毫秒)* @return 问候语*/String sayHello(String name, int timeToWait);
}
服务实现
服务提供者实现中加入线程休眠来模拟处理耗时:
public class GreetingServiceImpl implements GreetingService {@Overridepublic String sayHello(String name, int timeToWait) {try {// 模拟业务处理耗时Thread.sleep(timeToWait);} catch (InterruptedException e) {Thread.currentThread().interrupt();}return "Hello, " + name;}
}
消费者配置
XML配置方式
在消费者端通过XML配置启用异步调用:
<dubbo:reference id="greetingService" interface="com.example.GreetingService"><dubbo:method name="sayHello" async="true" />
</dubbo:reference>
消费者调用示例
消费者端异步调用及结果获取:
// 发起异步调用
greetingService.sayHello("world", 1000);// 立即返回null,实际调用在后台执行
System.out.println("调用立即返回,继续执行其他操作...");// 从RpcContext获取Future对象
Future<String> future = RpcContext.getContext().getFuture();// 其他业务逻辑处理...try {// 等待并获取结果(设置超时时间1500ms)String result = future.get(1500, TimeUnit.MILLISECONDS);System.out.println("收到结果: " + result);
} catch (Exception e) {// 处理超时或异常情况System.err.println("获取结果异常: " + e.getMessage());
}
注意事项
- 超时控制:Dubbo默认异步调用超时为1000ms,可通过
timeout参数调整<dubbo:method name="sayHello" async="true" timeout="2000"/> - Future获取:必须在发起调用的同一线程中获取Future对象
- 异常处理:异步调用需要通过Future检查执行状态和异常
- 资源释放:长时间不获取结果可能导致资源泄露,建议总是设置合理的超时时间
这种异步模式特别适合服务调用链较长或需要并行调用的场景,能显著提升系统吞吐量。例如在电商系统中,可以异步获取商品详情、库存、评价等信息,最后统一处理结果。
特殊说明
需要特别说明的是,该方式的使用必须确保在 2.5.4 及以后的版本中使用,在此之前的版本会存在异步状态传递异常的问题。这个问题主要体现在服务调用链中的异步状态错误传递。
具体来说,假设我们有一个服务调用链 A→B→C:
- 当服务A向服务B发起异步调用时
- 在底层实现中,系统会通过RPCContext的attachment属性添加一个特殊的异步标志(如"async=true")
- 这个标志用于标识当前请求需要异步等待结果
然而在2.5.4之前的版本中存在以下缺陷:
- 这个异步标志会随着调用链被错误传递
- 当B服务接收到A的请求后继续调用C服务时
- 错误的版本会将A→B的异步标志也传递给B→C的调用
- 导致C服务误判需要异步处理,从而返回空结果
问题产生的根本原因是:
- RPCContext的attachment属性在服务间传递时存在值传递问题
- 异步状态标志没有被正确清除
- 下游服务无法区分是本级调用还是上级调用的异步状态
解决方案:
- 升级到2.5.4及以上版本
- 新版本修复了异步状态传递机制
- 确保每个服务调用都有独立的异步状态管理
- 防止异步标志在调用链中错误传播
线程池
已有线程池实现
Dubbo在提供服务时,会使用真实的业务线程池来处理请求。目前框架内置了两种线程池模型,分别对应Java中的标准线程池实现:
-
固定大小线程池(fix)
- 这是Dubbo默认采用的线程池实现方式
- 默认创建200个工作线程,没有等待队列
- 特点:
- 线程数量固定,不会动态增减
- 当所有线程都在处理任务时,新任务会被拒绝
- 典型问题场景:
- 突发流量时,线程全部被占用会导致新请求被拒绝
- 某些耗时操作阻塞线程时,会影响整体吞吐量
- 示例配置:
<dubbo:protocol name="dubbo" threadpool="fixed" threads="200"/>
-
缓存线程池(cache)
- 线程数量不固定,会根据需求动态创建
- 特点:
- 空闲线程会被回收(默认60秒后)
- 理论上可以无限扩展线程数量
- 潜在风险:
- 高并发时可能创建大量线程
- 如果线程执行速度跟不上请求速度,会导致:
- 系统资源被耗尽
- CPU负载过高
- 出现"执行越多反而越慢"的恶性循环
- 适用场景:
- 请求量波动较大但持续时间较短
- 任务执行时间较短且可预测
自定义线程池方案
在实际生产环境中,使用固定线程池(fix模式)可能会遇到以下典型问题:
-
线程资源不足
- 某些业务场景突发流量时,线程池中的线程数量不足
- 导致请求被拒绝,业务功能不可用
- 常见于:
- 促销活动期间
- 定时任务集中执行时段
- 系统间批量数据交互
-
问题发现滞后
- 大部分业务开发人员对线程池容量无感知
- 通常只有在出现以下情况时才会发现问题:
- 监控系统发出告警
- 客户反馈功能异常
- 系统出现大量错误日志
-
解决方案
- 线程池监控:
- 实现线程池使用率实时监控
- 设置合理的阈值告警机制
- 动态调整:
- 根据监控数据动态扩容机器
- 在流量高峰前预先扩容
- 自定义实现:
- 扩展Dubbo线程池接口
- 增加监控和动态调整能力
- 示例实现:
public class MonitorThreadPool implements ThreadPool {// 实现线程池接口// 添加监控指标采集// 支持动态参数调整 }
- 线程池监控:
-
最佳实践
- 为不同业务设置独立的线程池
- 根据业务特点选择合适的线程池类型
- 建立完善的监控告警体系
- 定期进行压力测试评估线程池容量
线程池的实现,主要是对 FixedThreadPool 的实现进行扩展出线程监控的部分:
package icu.wzk.pool;import org.apache.dubbo.common.URL;
import org.apache.dubbo.common.threadpool.support.fixed.FixedThreadPool;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.util.ConcurrentModificationException;
import java.util.Map;
import java.util.concurrent.*;public class WzkWatchingThreadPool extends FixedThreadPool implements Runnable {private static final Logger LOGGER =LoggerFactory.getLogger(WzkWatchingThreadPool.class);private static final double ALARM_PERCENT = 0.9;private final Map<URL, ThreadPoolExecutor> THREADS_POOLS = new ConcurrentHashMap<>();public WzkWatchingThreadPool() {Executors.newSingleThreadScheduledExecutor().scheduleWithFixedDelay(this, 1, 3, TimeUnit.SECONDS);}@Overridepublic Executor getExecutor(URL url) {final Executor executor = super.getExecutor(url);if (executor instanceof ThreadPoolExecutor) {THREADS_POOLS.put(url, (ThreadPoolExecutor) executor);}return executor;}@Overridepublic void run() {for (Map.Entry<URL, ThreadPoolExecutor> entry : THREADS_POOLS.entrySet()) {final URL url = entry.getKey();final ThreadPoolExecutor executor = entry.getValue();final int activeCount = executor.getActiveCount();final int poolSize = executor.getPoolSize();double used = (double) activeCount / poolSize;final int usedNum = (int) (used * 100);LOGGER.info("线程池情况: {}, {}, {}", activeCount, poolSize, usedNum);if (used >= ALARM_PERCENT) {LOGGER.warn("线程池预警: {}, {}, {}", url.getIp(), usedNum, url);}}}
}SPI 声明,创建文件 META-INF/dubbo/org.apache.dubbo.common.threadpool.ThreadPool
wzkWatching=包名.线程池名
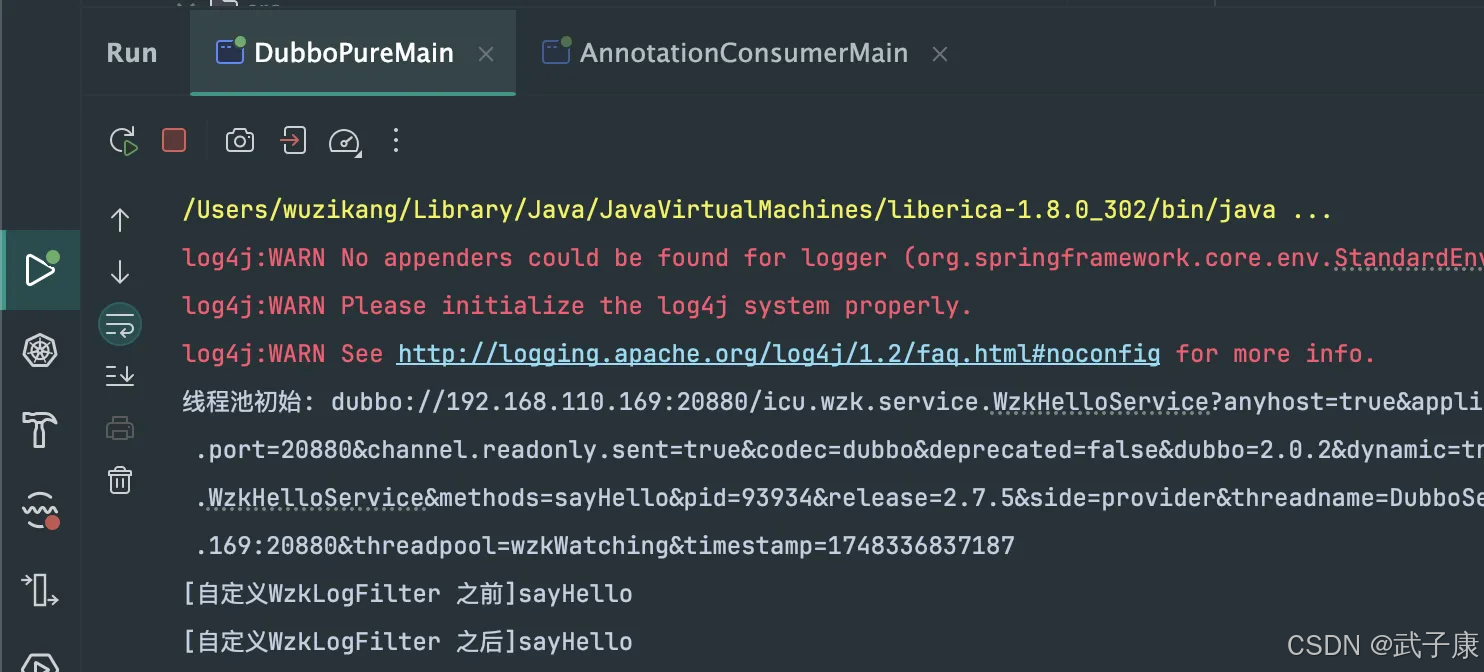
我们新建之后,文件内容是这样的:
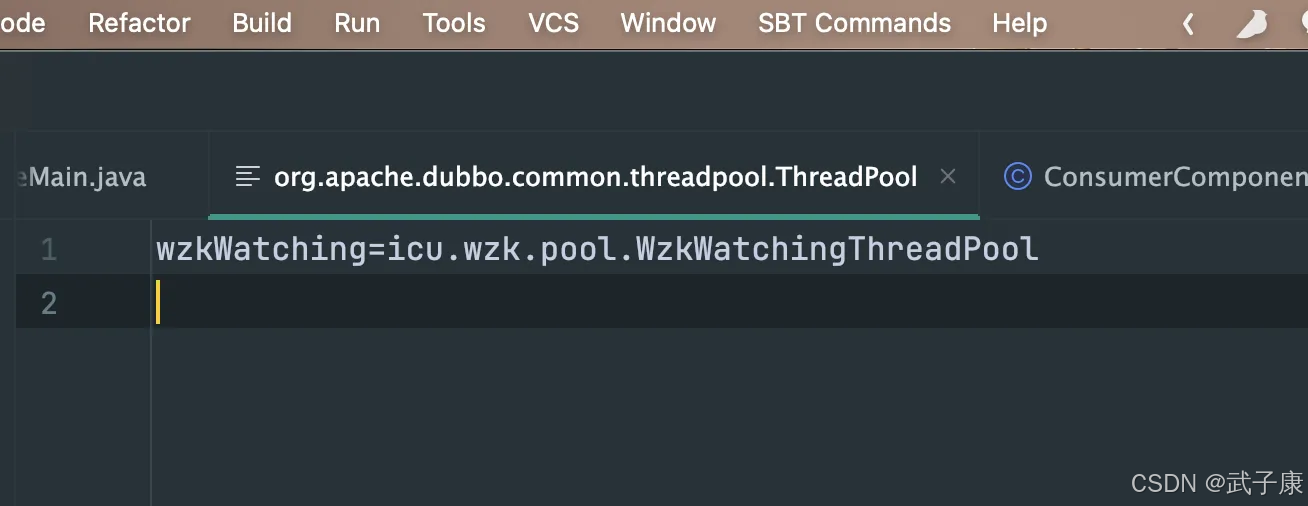
我们写入的内容是:
wzkWatching=icu.wzk.pool.WzkWatchingThreadPool
对应的内容如下所示:
在服务提供方引入该依赖,在服务提供方项目中设置使用该线程池生成器:
dubbo.provider.threadpool=wzkWatching
接下来需要做的就是模拟整个流程,因为该线程当前是每一秒调用一次,所以我们需要对该方法的提供者超过1秒的事件(比如这里用休眠Thread.sleep),消费者则需要启动多个线程来并行执行,来模拟整个并发的情况。
在调用方则尝试简单通过for循环启动多个线程来执行,查看服务提供方的监控情况。
测试使用
我们启动服务后,可以看到已经生效了: