【Semi笔记】Semisupervised Change Detection With Feature-Prediction Alignment
目录
- 引言
- 概要
- 一:类感知特征对齐(FA)class-aware feature alignment
- 挑战:
- 解决:
- 1数据增强
- 弱增强预测图指导强增强特征图
- PA
- 二:
- 挑战:
- 解决:
- 实验结果
- 小结
- 论文地址
- 代码地址
引言
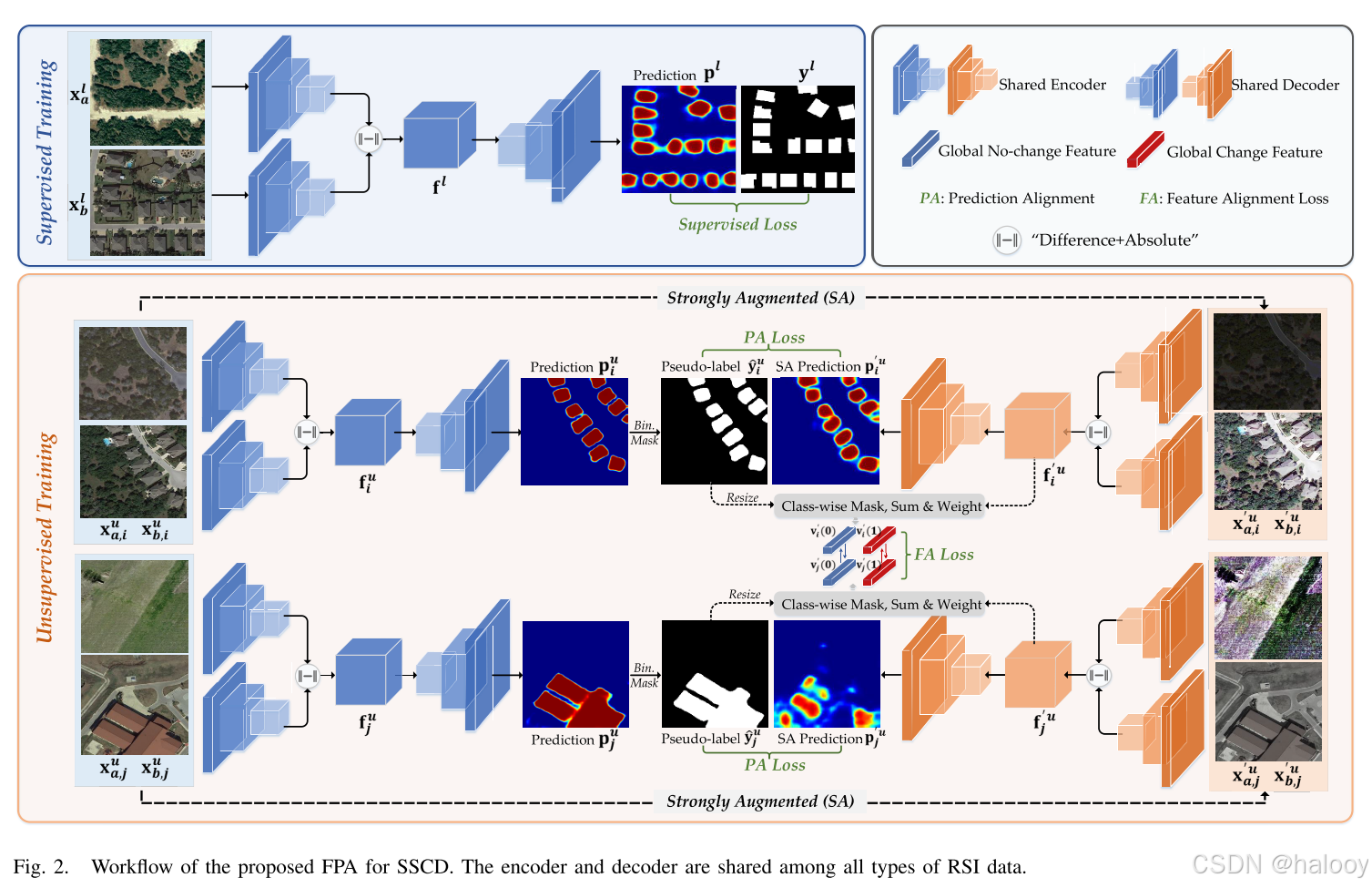
目前主流的变化检测方法主要基于全监督的深度学习模型,特别是卷积神经网络(CNN)[7],[8],[9],[10],[11],这些方法严重依赖于大量手动注释的数据。然而,在真实的世界中获取大量的标记数据通常是耗时的,甚至是困难的。因此,实际的CD应用受到限制,特别是在一些很少拍摄的场景中。在这种情况下,半监督CD(SSCD),它可以利用少量的标记RSI对和占主导地位的未标记RSI对进行模型训练,将是一个很有前途的解决方案。近年来,一些SSCD作品被探索,他们可以大致分为两类。1)基于对抗性学习的方法[12]:这种类型的算法利用替代优化策略来促进模型学习未标记RSI对的预测图和标记RSI对的地面真值之间的不可区分的表示。2)基于一致性学习的方法[13],[14]:这种类型的方法专注于促进模型学习未标记RSI对的扰动不变变化特征表示,通过使扰动数据的变化预测与非扰动数据一致。尽管这些SSCD方法显著提高了未标记RSI对变化预测的准确性,但它们仍然存在一些固有的问题。例如,基于对抗学习的方法由于其不稳定的黑盒优化策略而具有对未标记数据的不可控变化检测。基于一致性学习的方法的性能在很大程度上取决于各种扰动,例如特征噪声和特征丢弃[15];然而,这些扰动没有明确的物理意义,无法为SSCD社区提供明确的模型优化见解。为此,我们提出了一个具有物理意义的渐进式半监督学习(SSL)框架,在本文中称为SSCD的特征预测对齐(FPA),如图1所示。我们的FPA基于CD广泛使用的Siamese编码器-解码器架构[13],[16],[17],其中编码器模块从RSI对中提取双时间变化特征图,解码器模块进一步生成变化置信度的像素级预测图。基于提取的特征图和预测图,我们的FPA可以充分利用未标记的RSI对进行训练。
概要
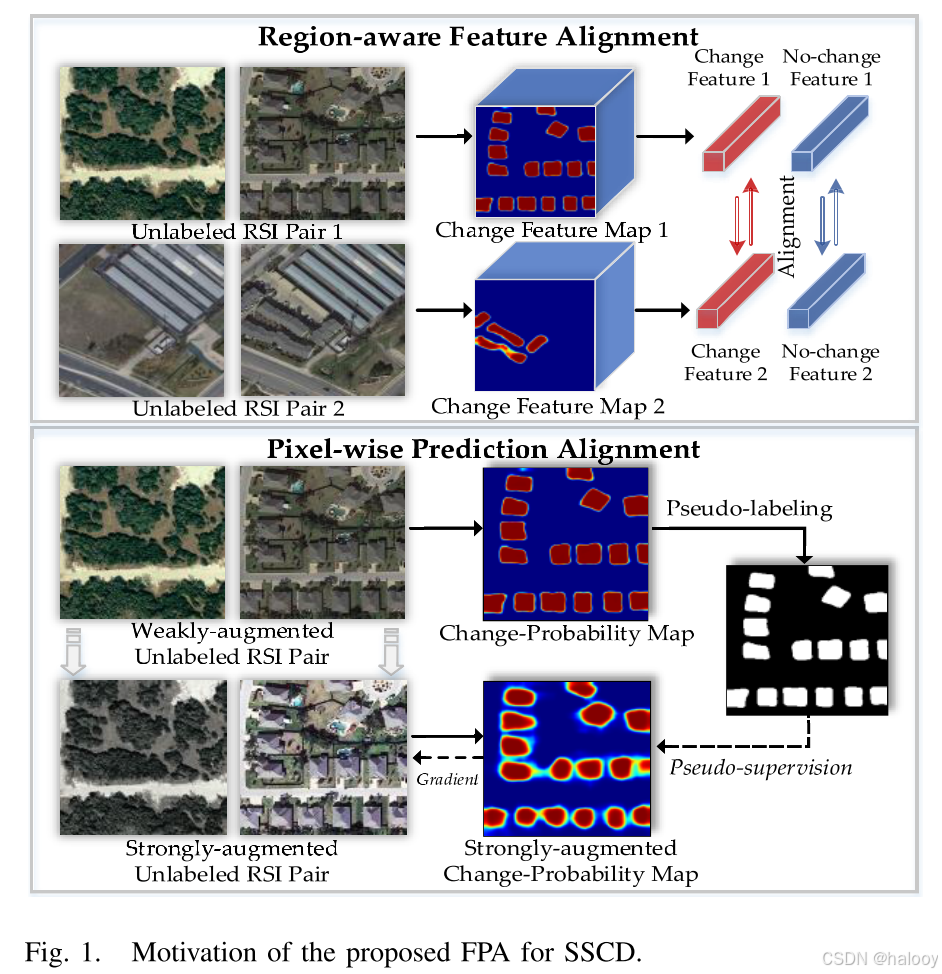
该文提出了一种新的渐进式SSCD框架,称为特征预测对齐(FPA)。FPA通过两种比对策略有效地利用未标记的RSI对进行训练.首先,设计了一种类感知特征对齐(FA)策略,用于对齐从不同的未标记RSI对中提取的区域级变化/无变化特征,跨区域),其目标是减少相同类别内的特征差异以降低预测不确定性。其次,提出了一种像素级预测对齐算法(pixel-wise prediction alignment,PA),将强增广的未标记RSI对的像素级变化预测与弱增广的RSI对计算得到的伪标记进行对齐,以降低各种具有物理意义的RSI变换的预测不确定性。
一:类感知特征对齐(FA)class-aware feature alignment
挑战:
基于对抗性学习的方法通常受制于其不稳定的对抗性优化策略。此外,他们对标记的训练数据的比例有相对严格的要求。
解决:
类感知FA:FA的目标是在训练阶段在一个小批次内实现不同未标记RSI对之间的类内全局特征对齐。
1数据增强
首先,通过一些弱增广运算从原始未标记RSI对获得未标记RSI对{xa u,x B u},并进一步获得其对应的强增广RSI对{x′ a u,x′ B u},如下所示:

其中RandAugment表示从预定义的增强列表中随机采样的两个级联强增强操作。其使用九种增强技术来扩展RSI对的图像表示,包括Identity,Contrast,Autocontrast,Brightness,Color,Sharpness,Sharpness,Posterize和Solarize。这些增强技术的可视化如图6所示。在这里,值得一提的是,Identity意味着无增广操作。

弱增强预测图指导强增强特征图

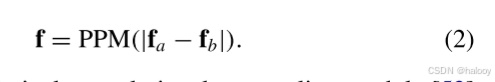
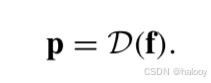
通过(1)和(2),将分别从{xa u,x B u}和{x′ a u,x′ B u}提取特征图fu和强增广特征图f′u。对于鲁棒模型训练,使用从fu中提取的弱增强预测图pu作为参考,以指导FA在强增强特征图f′u上操作。其中,弱增强预测图pu生成一个基于置信度的掩码图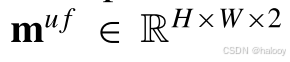 (“2”表示变化和无变化两类),其中,如果位置(i,j)处类别k的概率大于阈值t,则其值为1,维泽,其值为0。阈值t是用于过滤低置信度伪标签的超参数。在低Ⅳ节中使用值分析进行了它的调整实验。在生成掩码图之后,将muf进一步下采样到
(“2”表示变化和无变化两类),其中,如果位置(i,j)处类别k的概率大于阈值t,则其值为1,维泽,其值为0。阈值t是用于过滤低置信度伪标签的超参数。在低Ⅳ节中使用值分析进行了它的调整实验。在生成掩码图之后,将muf进一步下采样到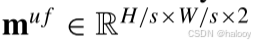 ,以适应强增强特征图f‘u的空间大小。
,以适应强增强特征图f‘u的空间大小。
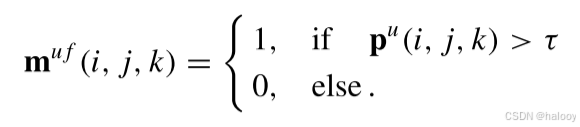
接下来,需要获得一个类权重向量 表示双时态特征图f的类像素数。公式为:
表示双时态特征图f的类像素数。公式为: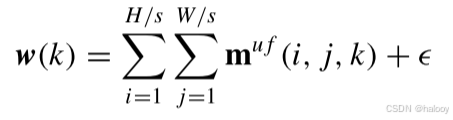 其中,k = 1 e-8是一个微小的余量,以避免每个类可能的零权重。
其中,k = 1 e-8是一个微小的余量,以避免每个类可能的零权重。
基于掩码映射mu f和加权向量w,可以从强增广特征映射f′u中提取类全局特征向量v′ ∈ R2×C.它可以表示为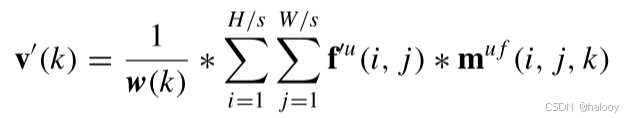
其中,*表示逐像素点积运算。结果,只有概率大于阈值τ的高质量特征向量才能被选择用于全局变化/不变特征向量的计算。值得一提的是,当不存在类别k的高质量像素时,该类别的全局特征向量,即,v′u(k)是零向量。到这一步为止,我们可以为每个强增广的未标记RSI对获得全局变化/不变特征向量v′ ∈ R2×C。这里,2表示包括“改变”和“无改变”的两个类别,并且C是特征通道的数量。
为了实现跨区域类内FA,通过增加它们的余弦相似性,将小批量内的所有类全局特征向量彼此对齐
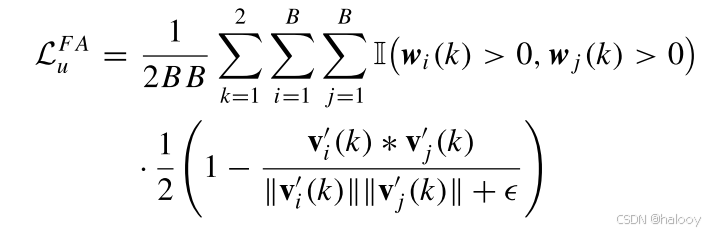
其中v′ i(k)和v′ j(k)分别表示当前小批量内第i个和第j个未标记RSI对的k类全局特征向量(B是小批量大小)。此外,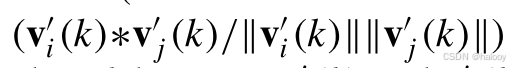
是指v′ i(k)和v′ j(k)之间k类的余弦相似度,其取值范围为[-1,1]。为了更好地适应损失优化,我们将其值范围重新投影到[0,1]。I是一个指标函数。只有当v′ i(k)和v′ j(k)都是非零向量时,它的值才为1(即,wi(k)> 0且wj(k)> 0);否则,其值为0。项= 1 e −8是一个微小的余量,以避免分母可能的零。
PA
PA旨在通过使强增强RSI对的输出与非增强RSI对的输出保持一致,使模型获得鲁棒的特征提取能力。为此,我们在本研究中将FixMatch [35]的置信度一致性学习策略从半监督图像分类任务引入到SSCD的像素级任务。如(1)-(3)所示,将未标记的RSI对{xu a,xu B}嵌入到整个模型中,输出像素级变化概率图pu。对于强增广RSI对的以下伪监督,伪标签映射y u ∈ RH×W由下式生成:
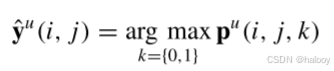
其中,位置(i,j)处的y元素表示最大预测类别索引,即在这个位置的伪标签。
为了减少噪声伪标签的干扰,为PA生成基于置信度的掩蔽映射mup ∈ RH×W,
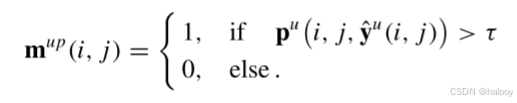
这里,如(10)中所述,y = u(i,j)是位置(i,j)处的伪标签,并且pu(i,j,k)表示位置(i,j)处的类别k的概率。对于mup在位置(i,j)处的元素,如果伪标记类在该位置处的概率,即,Pu(i,j,Pu(i,j))大于阈值τ;否则,其值为0。因此,第k个RSI对的逐像素PA损失(表示为具有小批量的LPA u(k))可以公式化为:
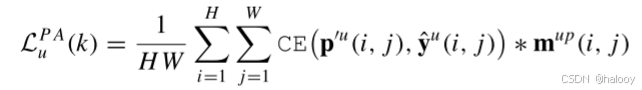
其中,MUP可以滤除Yu的低置信度伪标记像素,并因此减少它们的干扰。值得一提的是,为了提高编码器-解码器模型的输入多样性,使用p′u来对齐y u,而不是朴素的pu。这里,p′u是可以经由(1)-(3)从强增强的未标记RSI对{x′ a u,x′ B u}获取的强增强的变化概率图。
小批次的PA损失是LPA u(k)的平均值
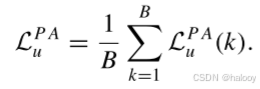
总损失是监督损失Ll、FA损失LFA u和PA损失LPA u的组合
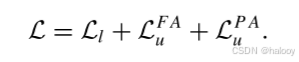
二:
挑战:
另一方面,基于一致性学习的方法主要集中在提高分类器的决策边界的区分度,这对于提取有效的跨时变化特征不是很重要。与它们相比,建议FPA是能够学习的区域和增强不变的特征表示的无监督RSI对两个对齐策略的FA和PA的基础上的物理特定的增强技术。
解决:
它可以促进模型学习增强不变的变化特征表示,通过监督强增强RSI对的像素级变化预测与伪弱增广RSI对的标签;各种具有物理意义的增广策略被尝试以增加图像表示能力。
实验结果
小结
论文地址
pdf地址
代码地址
https://github.com