7.20 树hash |字典树模板❗
字典树模板2.0

struct Node {
Node* son[26]{};
bool end = false;
};
class Trie {
Node* root = new Node();
int find(string word)
{
Node* cur = root;
for (char c : word)
{
c -= 'a';
if (cur->son[c] == nullptr)
{ // 道不同,不相为谋
return 0;
}
cur = cur->son[c];
}
// 走过同样的路(2=完全匹配,1=前缀匹配)
return cur->end ? 2 : 1;
}
void destroy(Node* node) {
if (node == nullptr) {
return;
}
for (Node* son : node->son) {
destroy(son);
}
delete node;
}
public:
~Trie() {
destroy(root);
}
void insert(string word)
{
Node* cur = root;
for (char c : word)
{
c -= 'a';
if (cur->son[c] == nullptr)
{ // 无路可走?
cur->son[c] = new Node();
// new 出来!
}
cur = cur->son[c];
}
cur->end = true;
}
bool search(string word) {
return find(word) == 2;
}
bool startsWith(string prefix) {
return find(prefix) != 0;
}
};
旋转矩阵
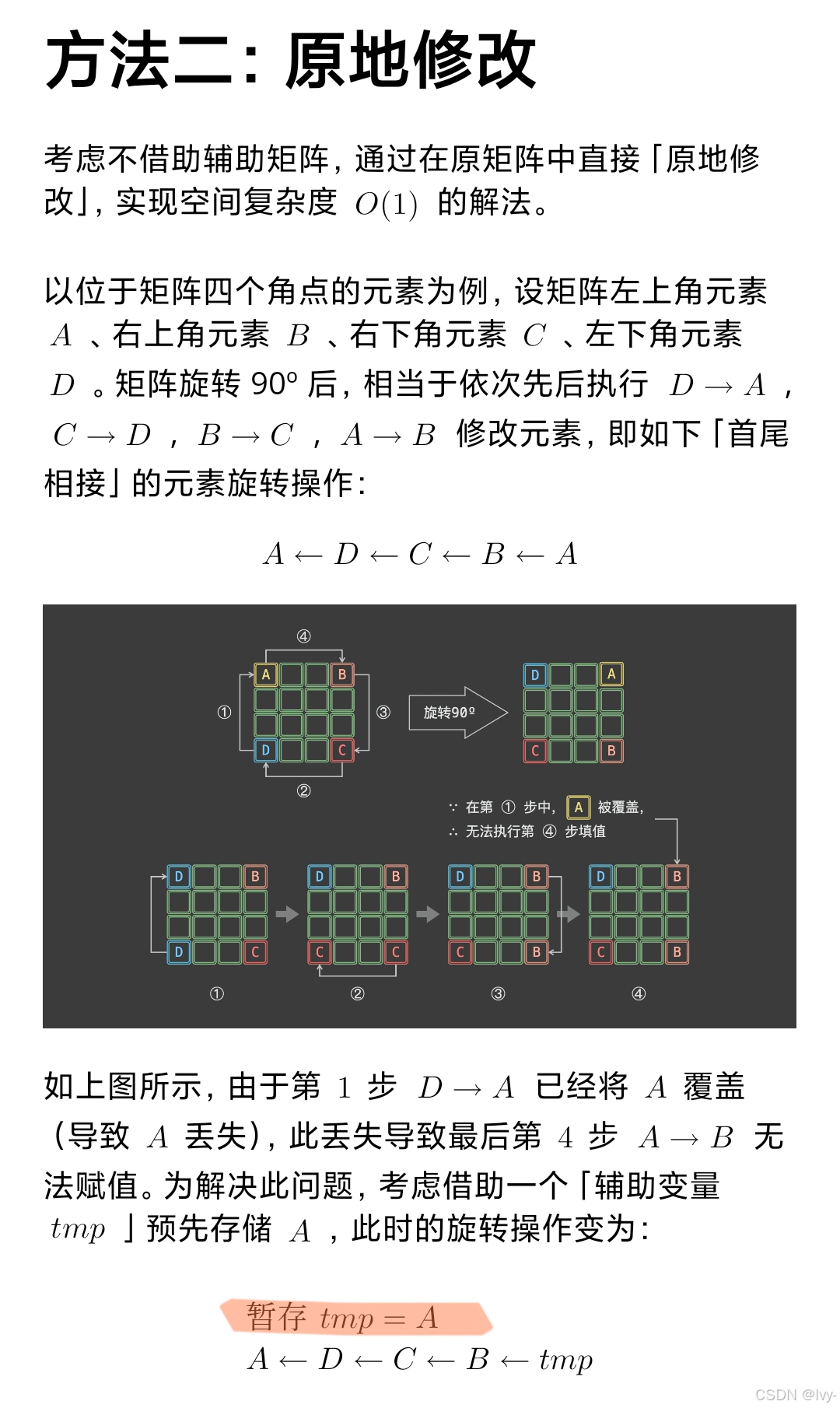
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for (int i = 0; i < n / 2; i++)
{
for (int j = 0; j < (n + 1) / 2; j++)
{
int tmp = matrix[i][j];
matrix[i][j] = matrix[n - 1 - j][i];
matrix[n - 1 - j][i] = matrix[n - 1 - i][n - 1 - j];
matrix[n - 1 - i][n - 1 - j] = matrix[j][n - 1 - i];
matrix[j][n - 1 - i] = tmp;
}
}
}
};
字典树
// 字典树节点结构体
struct TrieNode {
unordered_map<char, TrieNode*> children;
bool is_end_of_word;
TrieNode() : is_end_of_word(false) {}
};
// 字典树类
class Trie {
private:
TrieNode* root;
// 辅助函数,用于查找前缀对应的节点
TrieNode* searchPrefix(const string& prefix) {
TrieNode* node = root;
for (char c : prefix)
{
if (node->children.find(c) == node->children.end())
{
return nullptr;
}
node = node->children[c];
}
return node;
}
public:
// 构造函数,初始化根节点
Trie() {
root = new TrieNode();
}
// 插入单词到字典树
void insert(const string& word) {
TrieNode* node = root;
for (char c : word)
{
if (node->children.find(c) == node->children.end())
{
node->children[c] = new TrieNode();
}
node = node->children[c];
}
node->is_end_of_word = true;
}
// 查找单词是否在字典树中(完整存在)
bool search(const string& word)
{
TrieNode* node = searchPrefix(word);
return node != nullptr && node->is_end_of_word;
}
// 查找是否有单词以给定前缀开头
bool startsWith(const string& prefix)
{
return searchPrefix(prefix) != nullptr;
}
};
lc1948.树hash
#define ull unsigned long long
class Solution
{
const int base = 31;
struct Node
{
string name;
Node(string name) {
this->name = name;
}
};
public:
vector<vector<string>> deleteDuplicateFolder(vector<vector<string>>& paths)
{
vector<vector<string>> ans;
unordered_map<Node*, map<string, Node*>> mp;
unordered_map<Node*, Node*> fa;
Node* root = new Node("");
for (const auto& v: paths)
{
Node* last = root;
for (const auto& s: v)
{
if (mp[last].count(s) == 0)
{
Node* tmp = new Node(s);
mp[last][s] = tmp;
fa[tmp] = last;
last = tmp;
}
else last = mp[last][s];
}
}
map<ull, vector<Node*>> del;
function<ull(Node*)> dfs = [&](Node* node) {
// 如果没有子节点,直接返回哈希值
if (mp.count(node) == 0 || mp[node].size() == 0) {
ull H = 0;
for (const auto& c: node->name) {
H *= base;
H += c;
}
return H;
}
ull H = 0;
// 遍历所有子节点,计算哈希值,加在一起
for (const auto& ss: mp[node]) {
H += 71 * dfs(ss.second);
}
// 存储子树的哈希值
del[H].push_back(node);
// 加上自己的节点哈希值,返回
for (const auto& c: node->name) {
H += c;
}
return H;
};
dfs(root);
for (const auto& p: del) {
if (p.second.size() > 1) {
for (const auto& ss: p.second) {
mp[fa[ss]].erase(ss->name);
}
}
}
function<void(Node*, vector<string>&)> cal = [&](Node* node, vector<string>& rec) {
for (const auto& ss: mp[node]) {
rec.push_back(ss.first);
ans.push_back(rec);
cal(ss.second, rec);
rec.pop_back();
}
};
vector<string> rr;
cal(root, rr);
return ans;
}
};
删除文件夹路径中的重复子文件夹,通俗来说就是:如果两个文件夹的子结构完全相同(包含的子文件夹和文件结构一样),就把它们都删掉,最后返回剩下的有效路径。
具体实现思路可以分3步:
1. 构建文件夹结构树
- 把输入的所有路径(比如 ["a","b"] 、 ["a","c"] )转换成一棵“文件夹树”
- 每个节点代表一个文件夹,节点之间的父子关系对应路径中的层级(比如 a 是 b 的父节点)
2. 找出重复的子文件夹
- 用哈希值表示每个文件夹的“子结构”:
- 空文件夹(没有子文件夹):哈希值只由自身名字计算
- 有子文件夹的:哈希值由所有子文件夹的哈希值组合而成(相当于给整个子结构“签名”)
- 哈希值相同的文件夹,说明它们的子结构完全重复,标记这些文件夹要删除
3. 删除重复文件夹并输出结果
- 把标记为重复的文件夹从树上删掉(连带它们的子文件夹一起删)
- 遍历剩下的树,收集所有完整路径,就是最终结果
举个例子:
如果输入路径有 ["a","x"] 和 ["b","x"] ,这两个 x 文件夹都是空的(子结构相同),会被判定为重复并删除,最终结果就是空;
如果输入 ["a","b"] 和 ["a","c"] ,两个子文件夹结构不同,就都会保留。