(DINO)Emerging Properties in Self-Supervised Vision Transformers论文精读(逐段解析)
Emerging Properties in Self-Supervised Vision Transformers论文精读(逐段解析)
自监督视觉Transformer中的新兴特性
论文地址:https://arxiv.org/abs/2104.14294
1 Facebook AI Research
2 Inria∗
3 Sorbonne University
ICCV 2021
【论文总结】DINO (Self-Distillation with No Labels) 是一种创新的自监督学习框架,其核心思想是将自监督学习重新概念化为无标签的知识蒸馏过程。
- 无标签自蒸馏机制:DINO通过学生网络学习预测教师网络的输出,而教师网络则是学生网络参数的指数移动平均版本,形成了一个自我强化的学习循环。
- 多尺度视图策略:采用多裁剪策略生成全局视图(224×224)和局部视图(96×96),学生网络处理所有视图,教师网络只处理全局视图,建立"局部到全局"的对应关系。
- 动量编码器设计:教师网络参数通过指数移动平均更新:θt ← λθt + (1-λ)θs,其中λ采用余弦调度从0.996到1,提供稳定的学习目标。
- 简洁的防坍塌机制:仅通过中心化和锐化操作避免模型坍塌,无需复杂的预测器网络或对比损失函数。
Figure 1: Self-attention from a Vision Transformer with 8×88\times88×8 patches trained with no supervision. We look at the self-attention of the [CLS] token on the heads of the last layer. This token is not attached to any label nor supervision. These maps show that the model automatically learns class-specific features leading to unsupervised object segmentations.

【翻译】来自使用8×88\times88×8块训练且无监督的视觉Transformer的自注意力。我们观察最后一层各个头部中[CLS]标记的自注意力。该标记未附加任何标签或监督。这些图显示模型自动学习了特定类别的特征,从而实现了无监督的目标分割。
【解析】在Vision Transformer中,输入图像被切分成8×88\times88×8大小的小块(patches),每个小块都会被处理成一个token。除了这些图像块token之外,还有一个特殊的[CLS]token,它不对应图像的任何具体部分,而是用来汇总整个图像的信息。在传统的有监督学习中,这个[CLS]token会被训练来预测图像的类别标签。但在这个无监督的情况下,[CLS]token没有接受任何标签信息的指导。通过分析最后一层Transformer中[CLS]token对其他token的注意力权重,作者发现它能够自动识别和关注图像中的重要目标区域。这种注意力模式形成了类似语义分割的效果,也就是说模型能够区分前景目标和背景,甚至能够准确地勾勒出目标的轮廓。这说明自监督学习使得Vision Transformer具备了一种内在的场景理解能力,能够在没有任何人工标注的情况下学会识别和定位图像中的关键物体。
Abstract
In this paper, we question if self-supervised learning provides new properties to Vision Transformer (ViT) [16] that stand out compared to convolutional networks (convnets). Beyond the fact that adapting self-supervised methods to this architecture works particularly well, we make the following observations: first, self-supervised ViT features contain explicit information about the semantic segmentation of an image, which does not emerge as clearly with supervised ViTs, nor with convnets. Second, these features are also excellent kkk -NN classifiers, reaching 78.3%78.3\%78.3% top-1 on ImageNet with a small ViT. Our study also underlines the importance of momentum encoder [26], multi-crop training [9], and the use of small patches with ViTs. We implement our findings into a simple self-supervised method, called DINO, which we interpret as a form of self-distillation with no labels. We show the synergy between DINO and ViTs by achieving 80.1%80.1\%80.1% top-1 on ImageNet in linear evaluation with ViT-Base.
【翻译】在本文中,我们质疑自监督学习是否为视觉Transformer (ViT) [16]提供了相比卷积网络(convnets)更突出的新特性。除了将自监督方法适应到这种架构上效果特别好这一事实之外,我们有以下观察:首先,自监督ViT特征包含关于图像语义分割的明确信息,这在有监督的ViT或卷积网络中都没有如此清晰地出现。其次,这些特征也是优秀的kkk-NN分类器,使用小型ViT在ImageNet上达到了78.3%78.3\%78.3%的top-1准确率。我们的研究还强调了动量编码器[26]、多裁剪训练[9]以及在ViT中使用小块的重要性。我们将我们的发现实现为一种简单的自监督方法,称为DINO,我们将其解释为一种无标签的自蒸馏形式。我们通过使用ViT-Base在ImageNet线性评估中达到80.1%80.1\%80.1%的top-1准确率,展示了DINO与ViT之间的协同效应。
【解析】作者提出问题:自监督学习能否让Vision Transformer展现出卷积神经网络所不具备的独特优势。传统上,Vision Transformer在有监督学习中的表现虽然不错,但并没有展现出明显超越卷积网络的特性。作者通过自监督学习的角度重新审视了这个问题,发现了两个重要的新兴特性。第一个特性是语义分割能力的自然涌现。在自监督训练的Vision Transformer中,模型能够自动学会识别图像中的目标边界和语义区域,这种能力在有监督的ViT或传统卷积网络中都不够明显。这说明自监督学习能够让模型学到更丰富的空间结构信息。第二个特性是优秀的kkk-NN分类性能。kkk-NN分类器是最简单的分类方法之一,它通过比较特征相似度来进行分类,不需要额外的参数训练。自监督ViT特征在这种简单分类器上就能达到78.3%78.3\%78.3%的ImageNet准确率,说明学到的特征具有很强的判别性和泛化能力。作者还指出了几个关键技术组件:动量编码器通过指数移动平均更新参数来稳定训练过程;多裁剪训练通过对同一图像生成多个不同尺度的视图来增强数据;使用小块能够让模型获得更细粒度的图像信息。基于这些发现,作者提出了DINO方法,将其概念化为一种无标签的知识蒸馏或自蒸馏过程,其中模型同时充当教师和学生角色,通过自我一致性学习来获得良好的表征。最终在ViT-Base上达到的80.1%80.1\%80.1%准确率证明了这种方法的有效性。
1. Introduction
Transformers [57] have recently emerged as an alternative to convolutional neural networks (convnets) for visual recognition [16, 56, 68]. Their adoption has been coupled with a training strategy inspired by natural language processing (NLP), that is, pretraining on large quantities of data and finetuning on the target dataset [15, 45]. The resulting Vision Transformers (ViT) [16] are competitive with convnets but, they have not yet delivered clear benefits over them: they are computationally more demanding, require more training data, and their features do not exhibit unique properties.
【翻译】Transformers [57]最近已经成为卷积神经网络(convnets)在视觉识别方面的替代方案[16, 56, 68]。它们的采用伴随着受自然语言处理(NLP)启发的训练策略,即在大量数据上预训练然后在目标数据集上微调[15, 45]。由此产生的视觉Transformers (ViT) [16]与卷积网络相比具有竞争力,但它们尚未展现出明显的优势:它们在计算上更加苛刻,需要更多的训练数据,并且它们的特征没有表现出独特的性质。
【解析】关于ViT可以参考: Vision Transformer论文精读(逐段解析)
【解析】ViT:将图像分割成固定大小的块,然后将每个块当作序列中的一个token来处理,利用自注意力机制来建模不同位置之间的关系。虽然ViT在性能上能够与卷积网络相媲美,但在实际应用中面临挑战。首先是计算复杂度高,自注意力机制的计算量随着序列长度呈平方增长;其次是对数据量的要求更高,需要大规模的预训练数据才能发挥出优势;最重要的是,ViT的特征表示并没有展现出相比卷积网络的独特优势,这限制了其进一步的发展和应用。
In this paper, we question whether the muted success of Transformers in vision can be explained by the use of supervision in their pretraining. Our motivation is that one of the main ingredients for the success of Transformers in NLP was the use of self-supervised pretraining, in the form of close procedure in BERT [15] or language modeling in GPT [45]. These self-supervised pretraining objectives use the words in a sentence to create pretext tasks that provide a richer learning signal than the supervised objective of predicting a single label per sentence. Similarly, in images, imagelevel supervision often reduces the rich visual information contained in an image to a single concept selected from a predefined set of a few thousand categories of objects [49].
【翻译】在本文中,我们质疑Transformers在视觉领域的有限成功是否可以通过它们预训练中使用监督学习来解释。我们的动机是Transformers在NLP中成功的主要因素之一是使用自监督预训练,例如BERT [15]中的掩码过程或GPT [45]中的语言建模。这些自监督预训练目标使用句子中的单词来创建代理任务,这些任务提供了比预测每个句子单一标签的监督目标更丰富的学习信号。同样,在图像中,图像级监督往往将图像中包含的丰富视觉信息简化为从预定义的数千个对象类别集合中选择的单一概念[49]。
【解析】作者在这里提出假设:Transformer在视觉领域表现平平可能是因为训练方式的问题,而不是架构本身的局限性。在自然语言处理中,Transformer的成功很大程度上归功于自监督学习策略。以BERT为例,它通过掩码语言模型的方式进行预训练,即随机遮盖句子中的某些词,然后让模型预测被遮盖的词,这种方式能够让模型学习到词汇之间的复杂关系和语言的内在结构。类似地,GPT通过自回归的语言建模任务,让模型学会根据前文内容预测下一个词。这些自监督任务相比于简单的分类任务能够提供更丰富的监督信号,因为它们要求模型理解文本的细粒度结构和语义关系。而在计算机视觉领域,传统的监督学习通常采用图像分类的方式,即为每张图像分配一个类别标签。这种方式存在明显的信息损失:一张复杂的图像可能包含多个物体、丰富的空间关系、纹理细节等信息,但最终只被简化为一个类别标签。这种粗粒度的监督信号可能无法充分挖掘Vision Transformer的潜力。
While the self-supervised pretext tasks used in NLP are text specific, many existing self-supervised methods have shown their potential on images with convnets [9, 11, 23, 26]. They typically share a similar structure but with different components designed to avoid trivial solutions (collapse) or to improve performance [14]. In this work, inspired from these methods, we study the impact of self-supervised pretraining on ViT features. Of particular interest, we have identified several interesting properties that do not emerge with supervised ViTs, nor with convnets:
【翻译】虽然NLP中使用的自监督代理任务是文本特定的,但许多现有的自监督方法已经在图像上与卷积网络一起展现了它们的潜力[9, 11, 23, 26]。它们通常共享相似的结构,但具有不同的组件,这些组件旨在避免平凡解(坍塌)或提高性能[14]。在这项工作中,受这些方法的启发,我们研究了自监督预训练对ViT特征的影响。特别令人感兴趣的是,我们识别出了几个有趣的性质,这些性质在有监督的ViT或卷积网络中都没有出现:
【解析】视觉自监督方法通常遵循相似的框架设计:通过数据增强生成同一图像的不同视图,然后设计适当的学习目标来让模型学习这些视图之间的一致性。但是,这些方法面临的一个关键挑战是如何避免模型学习到平凡解,即所谓的"坍塌"问题。坍塌指的是模型为所有输入都产生相同或极其相似的表示,这样虽然满足了一致性要求,但没有学到有用的特征。因此,不同的自监督方法会采用不同的技术组件来防止这种坍塌,比如负样本采样、动量更新、特征归一化等。基于这些成功的经验,作者决定系统性地研究自监督学习对Vision Transformer的影响,希望能够发现ViT在自监督学习下的独特优势。
• Self-supervised ViT features explicitly contain the scene layout and, in particular, object boundaries, as shown in Figure 1. This information is directly accessible in the self-attention modules of the last block.
• Self-supervised ViT features perform particularly well with a basic nearest neighbors classifier kkk -NN) without any finetuning, linear classifier nor data augmentation, achieving 78.3%78.3\%78.3% top-1 accuracy on ImageNet.
【翻译】• 自监督ViT特征明确包含场景布局,特别是物体边界,如图1所示。这些信息可以在最后一个块的自注意力模块中直接获取。
• 自监督ViT特征在基本的最近邻分类器kkk-NN上表现特别好,无需任何微调、线性分类器或数据增强,在ImageNet上达到了78.3%78.3\%78.3%的top-1准确率。
【解析】第一个发现揭示了自监督Vision Transformer的一个重要特性:它能够自动学习到图像的结构化表示。在传统的有监督学习中,模型通常只关注与分类任务相关的高级语义特征,而忽略了空间结构信息。但在自监督学习中,由于没有外部标签的指导,模型必须依靠图像内在的结构规律来学习表示。Vision Transformer的自注意力机制在这种学习过程中发挥了关键作用,它能够计算图像中不同位置之间的相关性。最后一层的自注意力权重实际上反映了模型对图像中不同区域重要性的判断,这些权重自然地形成了对物体边界和场景布局的编码。这种现象说明自监督学习能够让Vision Transformer发现图像的本质结构,而无需人工标注的语义分割数据。第二个发现突出了学习到特征的质量。kkk-NN分类器是最简单的分类方法,它仅仅通过计算测试样本与训练样本特征之间的距离来进行分类决策,不涉及任何参数学习或优化过程。如果一个特征表示能够在这种简单分类器上取得良好性能,说明该特征具有很强的内在判别性和语义一致性。在ImageNet这样包含1000个类别的大规模数据集上达到78.3%78.3\%78.3%的准确率,证明了自监督ViT学习到的特征已经具备了丰富的语义信息,不同类别的样本在特征空间中形成了清晰的聚类结构。
The emergence of segmentation masks seems to be a property shared across self-supervised methods. However, the good performance with kkk -NN only emerge when combining certain components such as momentum encoder [26] and multi-crop augmentation [9]. Another finding from our study is the importance of using smaller patches with ViTs to improve the quality of the resulting features.
【翻译】分割掩码的出现似乎是自监督方法共有的特性。然而,kkk-NN的良好性能只有在结合某些组件(如动量编码器[26]和多裁剪增强[9])时才会出现。我们研究的另一个发现是在ViT中使用更小块对改善结果特征质量的重要性。
【解析】作者进一步分析了这些优异特性的技术根源。分割掩码的自然涌现确实是多种自监督方法的共同现象,这反映了自监督学习的一个基本原理:当模型缺乏外部监督信号时,它会寻找图像内部的结构化模式作为学习目标,而物体边界和区域分割正是图像结构的重要体现。然而,kkk-NN分类的优异性能并不是自动出现的,而是需要特定技术组件的支持。动量编码器通过指数移动平均的方式更新教师网络参数,这种策略能够提供更稳定和一致的训练目标,避免训练过程中的剧烈震荡。多裁剪增强策略通过生成同一图像的多个不同尺度和位置的视图,强迫模型学习尺度不变和位置不变的特征表示。这两个组件的结合创造了更加稳定和丰富的自监督学习环境。较小的块能够提供更细粒度的图像信息,让模型能够捕捉到更精细的空间结构和纹理细节。
Overall, our findings about the importance of these components lead us to design a simple self-supervised approach that can be interpreted as a form of knowledge distillation [28] with no labels. The resulting framework, DINO, simplifies self-supervised training by directly predicting the output of a teacher network—built with a momentum encoder—by using a standard cross-entropy loss. Interestingly, our method can work with only a centering and sharpening of the teacher output to avoid collapse, while other popular components such as predictor [23], advanced normalization [9] or contrastive loss [26] add little benefits in terms of stability or performance. Of particular importance, our framework is flexible and works on both convnets and ViTs without the need to modify the architecture, nor adapt internal normalizations [47].
【翻译】总的来说,我们关于这些组件重要性的发现引导我们设计了一种简单的自监督方法,可以解释为一种无标签的知识蒸馏[28]形式。所得到的框架DINO通过使用标准交叉熵损失直接预测教师网络(用动量编码器构建)的输出来简化自监督训练。有趣的是,我们的方法只需要对教师输出进行中心化和锐化就可以避免坍塌,而其他流行组件如预测器[23]、高级归一化[9]或对比损失[26]在稳定性或性能方面几乎没有带来好处。特别重要的是,我们的框架是灵活的,可以在卷积网络和ViT上工作,无需修改架构,也无需调整内部归一化[47]。
【解析】基于前述发现,作者提出了DINO方法,其核心思想是将自监督学习重新概念化为知识蒸馏过程。传统的知识蒸馏需要一个预训练的教师模型来指导学生模型的学习,但DINO创新性地实现了无标签的知识蒸馏,其中教师网络是通过动量更新机制从学生网络动态构建的。这种设计巧妙地解决了自监督学习中的目标制定问题:学生网络学习预测教师网络的输出,而教师网络又是学生网络的滞后版本,形成了一个自我强化的学习循环(传统的方法是让学生独自摸索,但DINO的巧妙之处在于让学生创造出一个"虚拟老师"来指导自己。这个虚拟老师实际上就是学生自己,但是一个稍微"过时"的版本。具体来说,学生网络在学习过程中不断更新自己的参数,而教师网络则是学生网络参数的一个缓慢移动的平均值。就像学生今天学到的知识会成为明天指导自己的经验一样。这种动量更新机制确保了教师网络总是比学生网络"稳定"一些,提供了相对一致的学习目标。学生网络试图预测教师网络对同一图像不同视角的理解,而教师网络又基于学生网络的历史学习经验。这样形成了一个闭环的自我学习系统,不需要任何外部标签,却能让模型逐步学会理解图像的深层结构和语义信息。)。DINO方法的简洁性体现在其损失函数的直接性:使用标准的交叉熵损失来度量学生网络输出与教师网络输出之间的差异。为了防止模型坍塌到平凡解,DINO采用了两个关键的正则化技术:中心化(centering)和锐化(sharpening)。中心化通过减去批次均值来防止某个维度的激活值过度主导,而锐化通过降低温度参数来增强输出分布的置信度。与其他复杂的自监督方法相比,DINO避免了对预测器网络、复杂归一化或对比损失函数的依赖,既简洁又有效。
We further validate the synergy between DINO and ViT by outperforming previous self-supervised features on the ImageNet linear classification benchmark with 80.1%80.1\%80.1% top-1 accuracy with a ViT-Base with small patches. We also confirm that DINO works with convnets by matching the state of the art with a ResNet-50 architecture. Finally, we discuss different scenarios to use DINO with ViTs in case of limited computation and memory capacity. In particular, training DINO with ViT takes just two 8-GPU servers over 3 days to achieve 76.1%76.1\%76.1% on ImageNet linear benchmark, which outperforms self-supervised systems based on convnets of comparable sizes with significantly reduced compute requirements [9, 23].
【翻译】我们通过使用带有小块的ViT-Base在ImageNet线性分类基准测试上达到80.1%80.1\%80.1%的top-1准确率,超越了之前的自监督特征,进一步验证了DINO与ViT之间的协同效应。我们还通过使用ResNet-50架构达到最先进水平,确认了DINO在卷积网络上的有效性。最后,我们讨论了在计算和内存容量有限情况下使用DINO与ViT的不同场景。特别是,使用ViT训练DINO只需要两台8-GPU服务器用3天时间就能在ImageNet线性基准测试上达到76.1%76.1\%76.1%的准确率,这超越了基于相似规模卷积网络的自监督系统,并且显著减少了计算需求[9, 23]。
Figure 2: Self-distillation with no labels. We illustrate DINO in the case of one single pair of views (x1,x2)(x_{1},x_{2})(x1,x2) for simplicity. The model passes two different random transformations of an input image to the student and teacher networks. Both networks have the same architecture but different parameters. The output of the teacher network is centered with a mean computed over the batch. Each networks outputs a KKK dimensional feature that is normalized with a temperature softmax over the feature dimension. Their similarity is then measured with a cross-entropy loss. We apply a stop-gradient (sg) operator on the teacher to propagate gradients only through the student. The teacher parameters are updated with an exponential moving average (ema) of the student parameters.
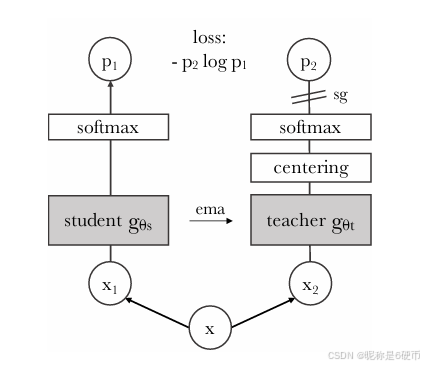
【翻译】图2:无标签的自蒸馏。为了简单起见,我们以一对视图(x1,x2)(x_{1},x_{2})(x1,x2)的情况来说明DINO。模型将输入图像的两个不同随机变换传递给学生网络和教师网络。两个网络具有相同的架构但参数不同。教师网络的输出通过批次上计算的均值进行中心化。每个网络输出一个KKK维特征,该特征通过特征维度上的温度softmax进行归一化。然后通过交叉熵损失来测量它们的相似性。我们在教师网络上应用停止梯度(sg)算子,使梯度只通过学生网络传播。教师参数通过学生参数的指数移动平均(ema)进行更新。
【解析】整个框架基于教师-学生的知识蒸馏模式,实现了自监督学习。数据流程从输入图像开始,通过数据增强生成两个不同的视图,这些视图作为同一图像的不同表现形式,为模型提供了丰富的训练信号。学生网络和教师网络虽然共享相同的架构设计,但它们的参数是不同的,两个网络能够提供不同的视角来观察相同的输入。教师网络输出的中心化操作是防止模型坍塌的关键技术之一,通过减去批次均值,确保输出分布不会过度集中在某个特定值上。温度softmax的应用控制了输出分布的尖锐程度,较高的温度会产生更平滑的分布,而较低的温度会产生更尖锐的分布,这种调节机制有助于稳定训练过程。交叉熵损失的使用将知识蒸馏的概念引入到自监督学习中,通过最小化学生网络和教师网络输出分布之间的差异来驱动学习过程。停止梯度操作确保了梯度只在学生网络中反向传播,而不会影响教师网络的参数。指数移动平均更新策略使得教师网络的参数变化更加平滑和稳定,避免了训练过程中的剧烈震荡,同时保持了教师网络作为一个相对稳定的学习目标的作用。
2. Related work
Self-supervised learning. Alarge body of work on self-supervised learning focuses on discriminative approaches coined instance classification [11, 17, 26, 60], which considers each image a different class and trains the model by discriminating them up to data augmentations. However, explicitly learning a classifier to discriminate between all images [17]does not scale well with the number of images. Wu et al.[60]propose to use a noise contrastive estimator (NCE) [25]to compare instances instead of classifying them. A caveat of this approach is that it requires comparing features from a large number of images simultaneously. In practice, this requires large batches [11]or memory banks [26, 60]. Several variants allow automatic grouping of instances in the form of clustering [2, 7, 8, 21, 29, 35, 61, 65, 69].
【翻译】自监督学习。大量关于自监督学习的工作专注于被称为实例分类的判别性方法[11, 17, 26, 60],该方法将每张图像视为不同的类别,并通过在数据增强范围内区分它们来训练模型。然而,明确学习一个分类器来区分所有图像[17]在图像数量增加时扩展性不佳。Wu等人[60]提出使用噪声对比估计器(NCE)[25]来比较实例而不是对它们进行分类。这种方法的一个缺陷是它需要同时比较来自大量图像的特征。在实践中,这需要大批次[11]或记忆库[26, 60]。几种变体允许以聚类的形式自动分组实例[2, 7, 8, 21, 29, 35, 61, 65, 69]。
【解析】自监督学习的核心挑战在于如何在没有人工标注的情况下构造有效的学习目标。实例分类方法通过将每张图像都当作一个独立的类别来解决这个问题,模型的任务是学会区分不同的图像实例。这种方法的基本假设是:经过不同数据增强的同一张图像应该被认为是同一类,而不同的原始图像应该被区分开来。这样,模型就能在没有外部标签的情况下学习到有意义的特征表示。然而,随着数据集规模的增长,这种方法面临严重的计算复杂度问题。如果数据集包含百万张图像,那么分类器就需要输出百万个类别的概率分布,这在计算和存储上都是不现实的。为了解决这个扩展性问题,研究者们提出了对比学习的思路,其中NCE是一个关键的技术突破。NCE不再要求模型对所有可能的类别进行建模,而是通过对比正样本对和负样本对来学习特征表示。具体来说,对于一个查询样本,模型需要学会将其与正样本(同一图像的增强版本)的相似度最大化,同时与负样本(其他图像)的相似度最小化。这种对比学习范式极大地简化了优化目标,但也带来了新的挑战:为了获得有效的梯度信号,模型需要同时看到足够多的负样本,这就要求使用大批次训练或者维护一个包含历史特征的记忆库。大批次训练虽然直接,但对硬件资源要求极高;记忆库方法虽然节省内存,但增加了实现复杂度和特征一致性的维护难度。
Recent works have shown that we can learn unsupervised features without discriminating between images. Of particular interest, Grill et al.[23]propose a metric-learning formulation called BYOL, where features are trained by matching them to representations obtained with a momentum encoder. It has been shown that methods like BYOL work even without a momentum encoder, at the cost of a drop of performance [14, 23]. Several other works echo this direction, showing that one can train features matching them to a uniform distribution on the l2 hypersphere [5]or by using whitening [19, 66]. Our approach takes its inspiration from BYOL but operates with a different similarity matching loss and uses the exact same architecture for the student and the teacher. That way, our work completes the interpretation initiated in BYOL of self-supervised learning as a form of Mean Teacher self-distillation [52]with no labels.
【翻译】最近的工作表明,我们可以在不区分图像的情况下学习无监督特征。特别令人感兴趣的是,Grill等人[23]提出了一种称为BYOL的度量学习公式,其中特征通过匹配动量编码器获得的表示来训练。已经表明,像BYOL这样的方法即使没有动量编码器也能工作,但性能会有所下降[14, 23]。其他几项工作呼应了这个方向,表明可以通过将特征匹配到l2超球面上的均匀分布[5]或使用白化[19, 66]来训练特征。我们的方法从BYOL中获得灵感,但使用不同的相似性匹配损失,并且学生和教师使用完全相同的架构。这样,我们的工作完成了BYOL开始的解释,即自监督学习是一种无标签的Mean Teacher自蒸馏[52]形式。
【解析】自监督学习范式的转变:从基于对比的方法转向基于一致性的方法。BYOL方法的核心洞察是:我们不一定需要通过对比负样本来学习好的特征表示,相反,我们可以通过让模型学习预测自己的不同版本来实现这个目标。这种方法避免了对比学习中对大量负样本的依赖,从而解决了之前提到的计算和存储问题。BYOL的技术核心是动量编码器机制,它维护一个目标网络,该网络的参数是在线网络参数的指数移动平均。这种设计提供了一个相对稳定的学习目标,避免了训练过程中的崩溃问题。值得注意的是,即使移除动量编码器,这类方法仍然可以工作,这表明其成功的关键可能不在于特定的技术组件,而在于其基本的学习原理。一些研究进一步简化了这种思路,直接让特征匹配到某种预定义的分布(如超球面上的均匀分布)或通过统计技术(如白化)来避免特征坍塌。DINO方法在BYOL的基础上进一步创新,它完全统一了学生网络和教师网络的架构,消除了它们之间的任何结构差异。这种设计选择不仅简化了方法,还强化了自监督学习作为自蒸馏过程的理论解释。Mean Teacher是半监督学习中的一个经典方法,它通过维护教师模型来为学生模型提供更稳定的监督信号。DINO将这一思想推广到完全无监督的场景,创造了一种新的自监督学习范式。
Self-training and knowledge distillation. Self-training aims at improving the quality of features by propagating asmall initial set of annotations to a large set of unlabeled instances. This propagation can either be done with hard assignments of labels [34, 63, 64]or with a soft assignment [62]. When using soft labels, the approach is often referred to as knowledge distillation [6, 28]and has been primarily designed to train a small network to mimic the output of a larger network to compress models. Xie et al.[62]have recently shown that distillation could be used to propagate soft pseudo-labels to unlabelled data in a self-training pipeline, drawing an essential connection between self-training and knowledge distillation. Our work builds on this relation and extends knowledge distillation to the case where no labels are available. Previous works have also combined self-supervised learning and knowledge distillation, enabling self-supervised model compression [20]and performance gains [12, 38]. However, these works rely on a pretrained fixed teacher while our teacher is dynamically built during training. This way, knowledge distillation, instead of being used as a post-processing step, becomes an integral part of the learning process.
【翻译】自训练和知识蒸馏。自训练旨在通过将少量初始标注传播到大量无标签实例来改善特征质量。这种传播可以通过标签的硬分配[34, 63, 64]或软分配[62]来完成。当使用软标签时,该方法通常被称为知识蒸馏[6, 28],主要设计用于训练小网络来模仿大网络的输出以压缩模型。Xie等人[62]最近表明,蒸馏可以用于在自训练流水线中传播软伪标签到无标签数据,建立了自训练和知识蒸馏之间的重要联系。我们的工作建立在这种关系之上,并将知识蒸馏扩展到没有标签可用的情况。之前的工作也结合了自监督学习和知识蒸馏,实现了自监督模型压缩[20]和性能提升[12, 38]。然而,这些工作依赖于预训练的固定教师,而我们的教师是在训练过程中动态构建的。这样,知识蒸馏不再作为后处理步骤使用,而是成为学习过程的一个组成部分。
【解析】自训练和知识蒸馏都试图从有限的监督信号中最大化学习效果。自训练的基本思想是利用模型在少量标注数据上学到的知识来为大量无标签数据生成伪标签,然后用这些伪标签来进一步训练模型。这个过程可以迭代进行,逐步扩大标注数据的规模。在实施过程中,标签分配策略是关键:硬分配直接将最高概率的类别作为伪标签,这种方法简单但可能丢失不确定性信息;软分配则保留完整的概率分布作为软标签,这样能够传递更丰富的信息但计算复杂度更高。知识蒸馏最初是为了模型压缩而设计的,它的核心思想是让一个小的学生网络学习模仿一个大的教师网络的行为。教师网络的软输出(经过温度缩放的概率分布)比硬标签包含更多的信息,比如类别之间的相似性关系。这种软监督信号帮助学生网络学到更好的特征表示。Xie等人的贡献在于发现了自训练和知识蒸馏的本质联系:当我们用软伪标签进行自训练时,实际上就是在进行一种形式的知识蒸馏。DINO方法的创新之处在于它将知识蒸馏推广到了完全无监督的场景。传统的知识蒸馏依赖于一个预训练好的固定教师模型,而DINO的教师模型是在训练过程中动态演化的。这种动态性使得知识蒸馏从一个后处理技术转变为学习过程的核心组件,创造了一种全新的自监督学习范式。
3. Approach
3.1. SSL with Knowledge Distillation
The framework used for this work, DINO, shares the same overall structure as recent self-supervised approaches [9, 14, 11, 23, 26]. However, our method shares also similarities with knowledge distillation [28] and we present it under this angle. We illustrate DINO in Figure 2 and propose a pseudo-code implementation in Algorithm 1.
【翻译】本工作使用的框架DINO与最近的自监督方法[9, 14, 11, 23, 26]具有相同的整体结构。然而,我们的方法与知识蒸馏[28]也有相似之处,我们从这个角度来介绍它。我们在图2中说明了DINO,并在算法1中提出了伪代码实现。
Knowledge distillation is a learning paradigm where we train a student network gθsg_{\theta_{s}}gθs to match the output of a given teacher network gθtg_{\theta_{t}}gθt , parameterized by θs\theta_{s}θs and θt\theta_{t}θt respectively. Given an input image xxx , both networks output probability distributions over KKK dimensions denoted by PsP_{s}Ps and PtP_{t}Pt . The probability PPP is obtained by normalizing the output of the network ggg with a softmax function. More precisely,
Ps(x)(i)=exp(gθs(x)(i)/τs)∑k=1Kexp(gθs(x)(k)/τs),P_{s}(x)^{(i)}=\frac{\exp(g_{\theta_{s}}(x)^{(i)}/\tau_{s})}{\sum_{k=1}^{K}\exp(g_{\theta_{s}}(x)^{(k)}/\tau_{s})}, Ps(x)(i)=∑k=1Kexp(gθs(x)(k)/τs)exp(gθs(x)(i)/τs),
with τs>0\tau_{s}~>~0τs > 0 a temperature parameter that controls the sharpness of the output distribution, and a similar formula holds for PtP_{t}Pt with temperature τt\tau_{t}τt . Given a fixed teacher network gθtg_{\theta_{t}}gθt , we learn to match these distributions by minimizing the cross-entropy loss w.r.t. the parameters of the student network θs\theta_{s}θs :
minθsH(Pt(x),Ps(x)),\operatorname*{min}_{\theta_{s}}H(P_{t}(x),P_{s}(x)), θsminH(Pt(x),Ps(x)),
where H(a,b)=−alogbH(a,b)=-a\log bH(a,b)=−alogb .
【翻译】知识蒸馏是一种学习范式,我们训练学生网络gθsg_{\theta_{s}}gθs来匹配给定教师网络gθtg_{\theta_{t}}gθt的输出,它们分别由θs\theta_{s}θs和θt\theta_{t}θt参数化。给定输入图像xxx,两个网络都输出KKK维的概率分布,分别记为PsP_{s}Ps和PtP_{t}Pt。概率PPP通过使用softmax函数对网络ggg的输出进行归一化得到。更精确地说,其中τs>0\tau_{s}~>~0τs > 0是控制输出分布尖锐度的温度参数,对于PtP_{t}Pt也有类似的公式,温度为τt\tau_{t}τt。给定固定的教师网络gθtg_{\theta_{t}}gθt,我们通过最小化关于学生网络参数θs\theta_{s}θs的交叉熵损失来学习匹配这些分布:其中H(a,b)=−alogbH(a,b)=-a\log bH(a,b)=−alogb。

【解析】DINO框架中,学生网络gθsg_{\theta_{s}}gθs和教师网络gθtg_{\theta_{t}}gθt都将输入图像映射到KKK维的特征空间,然后通过softmax函数转换为概率分布。温度参数τ\tauτ在这个过程中起到关键调节作用:当温度较高时,softmax输出更加平滑,不同维度的概率差异较小;当温度较低时,输出分布更加尖锐,模型的预测更加确定。温度调节机制允许控制知识转移的粒度:较高的温度有助于传递更多的细节信息,而较低的温度则突出最重要的特征。交叉熵损失函数H(Pt(x),Ps(x))H(P_{t}(x),P_{s}(x))H(Pt(x),Ps(x))衡量了两个概率分布之间的差异,其优化目标是让学生网络的输出分布尽可能接近教师网络的输出分布。在传统的知识蒸馏中,教师网络通常是一个预训练好的大模型,具有固定的参数,而学生网络通过梯度下降不断调整参数来逼近教师的行为。这种学习方式的优势在于学生网络不仅能学到教师网络的最终预测结果,还能学到其决策过程中的中间信息,从而获得更丰富的知识表示。
In the following, we detail how we adapt the problem in Eq. (2) to self-supervised learning. First, we construct different distorted views, or crops, of an image with multicrop strategy [9]. More precisely, from a given image, we generate a set VVV of different views. This set contains two global views, x1gx_{1}^{g}x1g and x2gx_{2}^{g}x2g and several local views of smaller resolution. All crops are passed through the student while only the global views are passed through the teacher, therefore encouraging “local-to-global” correspondences. We minimize the loss:
minθs∑x∈{x1g,x2g}∑x′∈Vx′≠xH(Pt(x),Ps(x′)).\operatorname*{min}_{\theta_{s}}\sum_{x\in\{x_{1}^{g},x_{2}^{g}\}}\quad\sum_{x^{'}\in V\atop x^{'}\ne x}\quad H(P_{t}(x),P_{s}(x^{\prime})). θsminx∈{x1g,x2g}∑x′=xx′∈V∑H(Pt(x),Ps(x′)).
This loss is general and can be used on any number of views, even only 2. However, we follow the standard setting for multi-crop by using 2 global views at resolution 2242224^{2}2242 covering a large (for example greater than 50%50\%50% ) area of the original image, and several local views of resolution 96296^{2}962 covering only small areas (for example less than 50%50\%50% ) of the original image. We refer to this setting as the basic parametrization of DINO, unless mentioned otherwise.
Both networks share the same architecture ggg with different sets of parameters θs\theta_{s}θs and θt\theta_{t}θt . We learn the parameters θs\theta_{s}θs by minimizing Eq. (3) with stochastic gradient descent.
【翻译】在下文中,我们详细说明如何将公式(2)中的问题适应到自监督学习。首先,我们使用多裁剪策略[9]构造图像的不同扭曲视图或裁剪。更精确地说,从给定图像中,我们生成一个包含不同视图的集合VVV。该集合包含两个全局视图x1gx_{1}^{g}x1g和x2gx_{2}^{g}x2g以及几个较小分辨率的局部视图。所有裁剪都通过学生网络传递,而只有全局视图通过教师网络传递,因此鼓励"局部到全局"的对应关系。我们最小化损失:这个损失是通用的,可以用于任意数量的视图,甚至只有2个。然而,我们遵循多裁剪的标准设置,使用2个分辨率为2242224^{2}2242的全局视图覆盖原始图像的大面积(例如大于50%50\%50%),以及几个分辨率为96296^{2}962的局部视图仅覆盖原始图像的小面积(例如小于50%50\%50%)。除非另有说明,我们将此设置称为DINO的基本参数化。两个网络共享相同的架构ggg,具有不同的参数集θs\theta_{s}θs和θt\theta_{t}θt。我们通过使用随机梯度下降最小化公式(3)来学习参数θs\theta_{s}θs。
【解析】DINO的核心创新在于其多尺度视图策略和不对称的视图处理策略。多裁剪策略从单一原始图像生成多个不同的视图,这些视图在空间覆盖范围和分辨率上都有所差异。全局视图x1gx_{1}^{g}x1g和x2gx_{2}^{g}x2g具有较高的分辨率(2242224^{2}2242)并覆盖原图的大部分区域,它们能够捕获图像的全局语义信息和整体结构特征。而局部视图则具有较低的分辨率(96296^{2}962)但专注于图像的小区域,它们主要关注局部细节和纹理特征。这种多尺度设计使得模型能够同时学习不同层次的视觉表示。更重要的是,DINO采用了不对称的处理策略:所有的视图(包括全局和局部)都会输入到学生网络中进行处理,而教师网络只处理全局视图。这样设计是为了让学生网络从局部细节中学习如何预测全局的语义表示,从而建立"局部到全局"的对应关系。而这种对应关系对于理解视觉场景至关重要,因为它要求模型能够从部分信息推断出整体特征。损失函数的设计也体现了这一思想:对于每个全局视图xxx,我们计算它与所有其他视图x′x'x′之间的交叉熵损失,其中教师网络的输出Pt(x)P_{t}(x)Pt(x)作为监督信号,学生网络的输出Ps(x′)P_{s}(x')Ps(x′)作为学习目标。这种损失设计确保了学生网络能够从不同尺度的视图中学习一致的特征表示。多裁剪策略不仅增加了训练数据的多样性,还通过强制模型在不同视图之间建立一致性来提高学习的鲁棒性。此外,由于局部视图的计算成本较低,这种策略在保持性能的同时提高了训练效率。网络架构的共享设计简化了模型结构,同时通过不同的参数集θs\theta_{s}θs和θt\theta_{t}θt来实现学生和教师网络的功能分工。
Table 1: Networks configuration. “Blocks” is the number of Transformer blocks, “dim” is channel dimension and “heads” is the number of heads in multi-head attention. “# tokens” is the length of the token sequence when considering 2242224^{2}2242 resolution inputs, “# params” is the total number of parameters (without counting the projection head) and “m/s” is the inference time on a NVIDIA V100 GPU with 128 samples per forward.
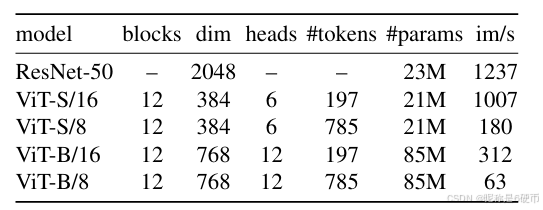
【翻译】表1:网络配置。"Blocks"是Transformer块的数量,“dim"是通道维度,“heads"是多头注意力中头的数量。”# tokens"是考虑2242224^{2}2242分辨率输入时令牌序列的长度,”# params"是参数总数(不包括投影头),"m/s"是在NVIDIA V100 GPU上每次前向传播128个样本的推理时间。
【解析】Transformer块数量决定了模型的深度,更多的块通常表示更强的表征能力但也带来更高的计算复杂度。通道维度dim控制了每个位置的特征表示的丰富程度,更高的维度可以捕获更复杂的模式但增加内存使用。多头注意力中的头数量影响模型并行处理不同类型注意力模式的能力,多个头允许模型同时关注不同的空间位置和特征类型。
Teacher network. Unlike knowledge distillation, we do not have a teacher gθtg_{\theta_{t}}gθt given a priori and hence, we build it from past iterations of the student network. We study different update rules for the teacher in Appendix and show that freezing the teacher network over an epoch works surprisingly well in our framework, while copying the student weight for the teacher fails to converge. Of particular interest, using an exponential moving average (EMA) on the student weights, i.e., a momentum encoder [26], is particularly well suited for our framework. The update rule is θt←λθt+(1−λ)θs\theta_{t}\leftarrow\lambda\theta_{t}+(1-\lambda)\theta_{s}θt←λθt+(1−λ)θs , with λ\lambdaλ following a cosine schedule from 0.996 to 1 during training [23]. Originally the momentum encoder has been introduced as a substitute for a queue in contrastive learning [26]. However, in our framework, its role differs since we do not have a queue nor a contrastive loss, and may be closer to the role of the mean teacher used in self-training [52]. Indeed, we observe that this teacher performs a form of model ensembling similar to Polyak-Ruppert averaging with an exponential decay [41, 48]. Using PolyakRuppert averaging for model ensembling is a standard practice to improve the performance of a model [31]. We observe that this teacher has better performance than the student throughout the training, and hence, guides the training of the student by providing target features of higher quality. This dynamic was not observed in previous works [23, 47].
【翻译】教师网络。与知识蒸馏不同,我们没有先验给定的教师网络gθtg_{\theta_{t}}gθt,因此我们从学生网络的过去迭代中构建它。我们在附录中研究了教师网络的不同更新规则,并表明在我们的框架中冻结教师网络一个epoch的效果出人意料地好,而将学生权重复制给教师网络则无法收敛。特别值得关注的是,对学生权重使用指数移动平均(EMA),即动量编码器[26],特别适合我们的框架。更新规则是θt←λθt+(1−λ)θs\theta_{t}\leftarrow\lambda\theta_{t}+(1-\lambda)\theta_{s}θt←λθt+(1−λ)θs,其中λ\lambdaλ在训练过程中遵循从0.996到1的余弦调度[23]。最初,动量编码器是作为对比学习中队列的替代品而引入的[26]。然而,在我们的框架中,它的作用有所不同,因为我们没有队列也没有对比损失,可能更接近自训练中使用的平均教师的作用[52]。实际上,我们观察到这个教师执行了一种类似于带指数衰减的Polyak-Ruppert平均的模型集成形式[41, 48]。使用Polyak-Ruppert平均进行模型集成是提高模型性能的标准做法[31]。我们观察到这个教师在整个训练过程中的性能都优于学生,因此通过提供更高质量的目标特征来指导学生的训练。这种动态在以前的工作中没有观察到[23, 47]。
【解析】DINO框架动态地从学生网络的历史状态构建教师网络,避免了对外部预训练模型的依赖。冻结教师网络一个epoch实际上为模型提供了稳定的学习目标,防止了学生和教师之间的不稳定耦合。指数移动平均(EMA)机制的引入,更新规则θt←λθt+(1−λ)θs\theta_{t}\leftarrow\lambda\theta_{t}+(1-\lambda)\theta_{s}θt←λθt+(1−λ)θs中的动量系数λ\lambdaλ采用余弦调度从0.996逐渐增加到1,这种设计使得教师网络在训练初期能够快速吸收学生网络的学习成果,而在训练后期则变得更加稳定,避免了过度频繁的参数更新。这种动量机制本质上实现了一种时间维度上的模型集成,类似于Polyak-Ruppert平均,它将多个时间步的模型参数进行加权平均,从而获得比单一模型更稳定和更优的性能。DINO框架中的动量编码器与对比学习中的应用有本质区别:在对比学习中,动量编码器主要用于维护一个稳定的负样本队列,而在DINO中,它的作用是创建一个持续优化的教师模型。这种设计使得教师网络能够始终保持比学生网络更好的性能,为学生网络提供高质量的学习目标。教师网络性能持续优于学生网络,说明:通过时间平滑得到的模型往往比瞬时模型具有更好的泛化能力。
Network architecture. The neural network ggg is composed of a backbone fff (ViT [16] or ResNet [27]), and of a projection head hhh : g=h∘fg=h\circ fg=h∘f . The features used in downstream tasks are the backbone fff output. The projection head consists of a 3-layer multi-layer perceptron (MLP) with hidden dimension 2048 followed by ℓ2\ell_{2}ℓ2 normalization and a weight normalized fully connected layer [50] with KKK dimensions, which is similar to the design from SwAV [9]. We have tested other projection heads and this particular design appears to work best for DINO (see Appendix). We do not use a predictor [23, 14], resulting in the exact same architecture in both student and teacher networks. Of particular interest, we note that unlike standard convnets, ViT architectures do not use batch normalizations (BN) by default. Therefore, when applying DINO to ViT we do not use any BN also in the projection heads, making the system entirely BN-free.
【翻译】网络架构。神经网络ggg由主干网络fff(ViT [16]或ResNet [27])和投影头hhh组成:g=h∘fg=h\circ fg=h∘f。下游任务中使用的特征是主干网络fff的输出。投影头由一个3层多层感知机(MLP)组成,隐藏维度为2048,然后是ℓ2\ell_{2}ℓ2归一化和一个具有KKK维的权重归一化全连接层[50],这与SwAV [9]的设计相似。我们测试了其他投影头,这种特定设计对DINO效果最佳(见附录)。我们不使用预测器[23, 14],因此学生和教师网络具有完全相同的架构。特别值得注意的是,与标准卷积网络不同,ViT架构默认不使用批归一化(BN)。因此,当将DINO应用于ViT时,我们在投影头中也不使用任何BN,使整个系统完全无BN。
【解析】DINO整个网络ggg采用了经典的两阶段设计:特征提取主干fff负责从输入图像中提取高级语义特征,而投影头hhh则将这些特征映射到适合自监督学习的表示空间。主干网络支持ViT和ResNet两种主流架构,投影头的设计借鉴了SwAV的成功经验,采用3层MLP结构能够提供足够的非线性变换能力,而2048的隐藏维度为特征学习提供了充足的表示空间。ℓ2\ell_{2}ℓ2归一化的使用确保了特征向量的模长一致性,以方便后续的相似性计算。权重归一化全连接层的引入进一步稳定了训练过程,避免了梯度爆炸或消失的问题。
Avoiding collapse. Several self-supervised methods differ by the operation used to avoid collapse, either through contrastive loss [60], clustering constraints [7, 9], predictor [23] or batch normalizations [23, 47]. While our framework can be stabilized with multiple normalizations [9], it can also work with only a centering and sharpening of the momentum teacher outputs to avoid model collapse. As shown experimentally in Appendix, centering prevents one dimension to dominate but encourages collapse to the uniform distribution, while the sharpening has the opposite effect. Applying both operations balances their effects which is sufficient to avoid collapse in presence of a momentum teacher. Choosing this method to avoid collapse trades stability for less dependence over the batch: the centering operation only depends on firstorder batch statistics and can be interpreted as adding a bias term ccc to the teacher: gt(x)←gt(x)+cg_{t}(x)\gets g_{t}(x)+cgt(x)←gt(x)+c . The center ccc is updated with an exponential moving average, which allows the approach to work well across different batch sizes as shown in Appendix.
c←mc+(1−m)1B∑i=1Bgθt(xi),c\leftarrow m c+(1-m)\frac{1}{B}\sum_{i=1}^{B}g_{\theta_{t}}(x_{i}), c←mc+(1−m)B1i=1∑Bgθt(xi),
where m>0m>0m>0 is a rate parameter and BBB is the batch size. Output sharpening is obtained by using a low value for the temperature τt\tau_{t}τt in the teacher softmax normalization.
【翻译】避免崩塌。几种自监督方法在避免崩塌的操作上有所不同,要么通过对比损失[60]、聚类约束[7, 9]、预测器[23]或批归一化[23, 47]。虽然我们的框架可以通过多种归一化[9]来稳定,但它也可以仅通过对动量教师输出进行中心化和锐化来避免模型崩塌。如附录实验所示,中心化防止一个维度占主导地位,但鼓励向均匀分布崩塌,而锐化具有相反的效果。应用这两种操作平衡了它们的效果,在存在动量教师的情况下足以避免崩塌。选择这种避免崩塌的方法以稳定性换取对批次的较少依赖:中心化操作只依赖于一阶批次统计量,可以解释为向教师添加偏置项ccc:gt(x)←gt(x)+cg_{t}(x)\gets g_{t}(x)+cgt(x)←gt(x)+c。中心ccc通过指数移动平均更新,这使得该方法在不同批次大小下都能很好地工作,如附录所示。其中m>0m>0m>0是速率参数,BBB是批次大小。输出锐化通过在教师softmax归一化中使用较低的温度τt\tau_{t}τt值来获得。
【解析】DINO通过双重策略来解决崩塌问题:中心化和锐化操作的组合。中心化操作通过减去均值来防止某个特征维度过度激活而占据主导地位,但这种操作本身可能导致特征分布趋向于均匀分布,从而失去有用的结构信息。锐化操作则通过降低温度参数τt\tau_{t}τt来增强预测的确定性,使模型输出更加尖锐,避免向均匀分布的退化。这两种操作的组合创造了一种平衡:中心化确保了特征的多样性,而锐化保持了预测的置信度。中心化操作的实现通过指数移动平均c←mc+(1−m)1B∑i=1Bgθt(xi)c\leftarrow m c+(1-m)\frac{1}{B}\sum_{i=1}^{B}g_{\theta_{t}}(x_{i})c←mc+(1−m)B1∑i=1Bgθt(xi)来更新中心ccc,其中mmm是动量参数,BBB是批次大小。这种设计使得中心化操作只依赖于一阶统计量,减少了对特定批次大小的依赖,提高了算法的泛化能力。相比于传统的批归一化等方法,这种崩塌避免机制在保持模型稳定性的同时减少了对批次统计的敏感性,使得DINO能够在不同的批次大小下都保持良好的性能。
【指数移动平均的详细解析】:指数移动平均(Exponential Moving Average, EMA)是一种时间序列平滑技术,其核心思想是对历史数据赋予指数递减的权重,即越近期的数据权重越大,越远期的数据权重越小。在DINO框架中,EMA被应用于两个关键场景:教师网络参数的更新和中心化操作中的中心点计算。对于教师网络参数更新,公式θt←λθt+(1−λ)θs\theta_{t}\leftarrow\lambda\theta_{t}+(1-\lambda)\theta_{s}θt←λθt+(1−λ)θs中的λ\lambdaλ通常接近1(如0.996-1),这意味着教师网络主要保持其当前状态,只是轻微地融入学生网络的最新参数。这种设计有几个重要优势:首先,它提供了参数更新的平滑性,避免了教师网络的剧烈变化,从而为学生网络提供稳定的学习目标;其次,它实现了一种隐式的模型集成,教师网络实际上是学生网络在多个时间步上的加权平均,这通常比单一时刻的模型具有更好的泛化性能;第三,它缓解了学生-教师网络之间的相互依赖关系,防止了训练过程中的不稳定性。对于中心化操作中的EMA应用,公式c←mc+(1−m)1B∑i=1Bgθt(xi)c\leftarrow m c+(1-m)\frac{1}{B}\sum_{i=1}^{B}g_{\theta_{t}}(x_{i})c←mc+(1−m)B1∑i=1Bgθt(xi)中的mmm参数控制了历史中心值和当前批次平均值的融合程度。较大的mmm值使得中心更新更加保守,有助于在训练过程中保持稳定的中心化基准;较小的mmm值则使得中心能够更快地适应当前数据分布的变化。EMA的数学本质可以从递归展开的角度理解:θt=λθt−1+(1−λ)θs,t=λ[λθt−2+(1−λ)θs,t−1]+(1−λ)θs,t=∑i=0t(1−λ)λiθs,t−i\theta_t = \lambda\theta_{t-1} + (1-\lambda)\theta_{s,t} = \lambda[\lambda\theta_{t-2} + (1-\lambda)\theta_{s,t-1}] + (1-\lambda)\theta_{s,t} = \sum_{i=0}^{t}(1-\lambda)\lambda^i\theta_{s,t-i}θt=λθt−1+(1−λ)θs,t=λ[λθt−2+(1−λ)θs,t−1]+(1−λ)θs,t=∑i=0t(1−λ)λiθs,t−i,这表明教师网络的参数实际上是所有历史学生参数的指数加权和,权重系数随时间指数衰减,因此,它不需要存储完整的历史记录,只需要维护一个累积的状态变量,就能够捕获整个训练历史的信息。从信号处理的角度看,EMA相当于一个低通滤波器,它能够滤除学生网络参数更新中的高频噪声,保留低频的趋势信息,从而提高教师网络的稳定性和可靠性。此外,EMA计算效率高、内存占用少,因为它只需要保存前一时刻的状态,而不需要存储完整的历史序列。举个简单的例子就是:指数移动平均就像是一个有记忆但会遗忘的智能助手,例如学习一门新技能时,这个助手会记住你之前所有的练习成果,但是越久远的记忆越模糊,最近的学习成果记得最清楚。在DINO中,教师网络就是这样一个助手,它主要保持之前学到的知识(占96.6%),然后轻微地吸收学生网络最新的学习成果(占3.4%)。这样做的好处是教师网络不会因为学生网络某一次的"坏表现"而大幅改变,同时又能持续地从学生的进步中学习。简单来说,就是"稳中求进"——既保持稳定性,又能持续改进,这样教师网络总是比学生网络表现得更好,能够为学生提供高质量的指导。
3.2. 实现和评估协议
In this section, we provide the implementation details to train with DINO and present the evaluation protocols used in our experiments.
【翻译】在本节中,我们提供了使用DINO进行训练的实现细节,并介绍了实验中使用的评估协议。
Vision Transformer. We briefly describe the mechanism of the Vision Transformer (ViT) [16, 57] and refer to Vaswani et al. [57] for details about Transformers and to Dosovitskiy et al. [16] for its adaptation to images. We follow the implementation used in DeiT [56]. We summarize the configuration of the different networks used in this paper in Table 1. The ViT architecture takes as input a grid of non-overlapping contiguous image patches of resolution N×NN\times NN×N . In this paper we typically use N=16N=16N=16 (“/16”) or N=8N=8N=8 (“/8”). The patches are then passed through a linear layer to form a set of embeddings. We add an extra learnable token to the sequence [15, 16]. The role of this token is to aggregate information from the entire sequence and we attach the projection head hhh at its output. We refer to this token as the class token [CLS] for consistency with previous works[15, 16, 56], even though it is not attached to any label nor supervision in our case. The set of patch tokens and [CLS] token are fed to a standard Transformer network with a “pre-norm” layer normalization [10, 32]. The Transformer is a sequence of self-attention and feed-forward layers, paralleled with skip connections. The self-attention layers update the token representations by looking at the other token representations with an attention mechanism [3].
【翻译】视觉Transformer。我们简要描述了视觉Transformer (ViT) [16, 57]的机制,关于Transformer的详细信息请参见Vaswani等人[57],关于其在图像上的适应请参见Dosovitskiy等人[16]。我们遵循DeiT [56]中使用的实现。我们在表1中总结了本文使用的不同网络的配置。ViT架构以分辨率为N×NN\times NN×N的非重叠连续图像补丁网格作为输入。在本文中,我们通常使用N=16N=16N=16(“/16”)或N=8N=8N=8(“/8”)。然后将补丁通过线性层形成一组嵌入。我们向序列中添加一个额外的可学习令牌[15, 16]。该令牌的作用是聚合整个序列的信息,我们在其输出处附加投影头hhh。为了与之前的工作[15, 16, 56]保持一致,我们将此令牌称为类令牌[CLS],尽管在我们的情况下它没有附加任何标签或监督。补丁令牌和[CLS]令牌的集合被输入到带有"pre-norm"层归一化[10, 32]的标准Transformer网络中。Transformer是自注意力层和前馈层的序列,与跳跃连接并行。自注意力层通过注意力机制[3]查看其他令牌表示来更新令牌表示。
Implementation details. We pretrain the models on the ImageNet dataset [49] without labels. We train with the adamw optimizer [37] and a batch size of 1024, distributed over 16 GPUs when using ViT-S/16. The learning rate is linearly ramped up during the first 10 epochs to its base value determined with the following linear scaling rule [22]: lr=0.0005* batchsize/256. After this warmup, we decay the learning rate with a cosine schedule [36]. The weight decay also follows a cosine schedule from 0.04 to 0.4. The temperature τs\tau_{s}τs is set to 0.1 while we use a linear warm-up for τt\tau_{t}τt from 0.04 to 0.07 during the first 30 epochs. We follow the data augmentations of BYOL [23] (color jittering, Gaussian blur and solarization) and multi-crop [9] with a bicubic interpolation to adapt the position embeddings to the scales [16, 56]. The code and models to reproduce our results is publicly available at https://github.com/ facebookresearch/dino.
【翻译】实现细节。我们在ImageNet数据集[49]上预训练模型而不使用标签。我们使用adamw优化器[37]和1024的批量大小,在使用ViT-S/16时分布在16个GPU上。学习率在前10个epochs内线性上升到其基准值,该基准值由以下线性缩放规则[22]确定:lr=0.0005* batchsize/256。在这个预热之后,我们使用余弦调度[36]衰减学习率。权重衰减也遵循从0.04到0.4的余弦调度。温度τs\tau_{s}τs设置为0.1,而我们对τt\tau_{t}τt在前30个epochs使用从0.04到0.07的线性预热。我们遵循BYOL [23]的数据增强(颜色抖动、高斯模糊和太阳化)和多裁剪[9],使用双三次插值来适应位置嵌入的尺度[16, 56]。复现我们结果的代码和模型可在https://github.com/ facebookresearch/dino公开获得。
Evaluation protocols. Standard protocols for selfsupervised learning are to either learn a linear classifier on frozen features [67, 26] or to finetune the features on downstream tasks. For linear evaluations, we apply random resize crops and horizontal flips augmentation during training, and report accuracy on a central crop. For finetuning evaluations, we initialize networks with the pretrained weights and adapt them during training. However, both evaluations are sensitive to hyperparameters, and we observe a large variance in accuracy between runs when varying the learning rate for example. We thus also evaluate the quality of features with a simple weighted nearest neighbor classifier ( kkk -NN) as in [60]. We freeze the pretrain model to compute and store the features of the training data of the downstream task. The nearest neighbor classifier then matches the feature of an image to the kkk nearest stored features that votes for the label. We sweep over different number of nearest neighbors and find that 20 NN is consistently working the best for most of our runs. This evaluation protocol does not require any other hyperparameter tuning, nor data augmentation and can be run with only one pass over the downstream dataset, greatly simplifying the feature evaluation.
【翻译】评估协议。自监督学习的标准协议是在冻结特征上学习线性分类器[67, 26]或在下游任务上微调特征。对于线性评估,我们在训练期间应用随机调整大小裁剪和水平翻转增强,并报告中心裁剪的准确性。对于微调评估,我们用预训练权重初始化网络并在训练期间调整它们。然而,两种评估都对超参数敏感,我们观察到当改变学习率时运行之间的准确性有很大差异。因此,我们还用简单的加权最近邻分类器(kkk-NN)评估特征质量,如[60]所示。我们冻结预训练模型来计算和存储下游任务训练数据的特征。然后最近邻分类器将图像的特征与kkk个最近的存储特征匹配,这些特征为标签投票。我们扫过不同数量的最近邻,发现20个NN对我们的大多数运行都是一致的最佳选择。这种评估协议不需要任何其他超参数调整,也不需要数据增强,可以只对下游数据集运行一次,大大简化了特征评估。
Table 2: Linear and kkk -NN classification on ImageNet. We report top-1 accuracy for linear and kkk -NN evaluations on the validation set of ImageNet for different self-supervised methods. We focus on ResNet-50 and ViT-small architectures, but also report the best results obtained across architectures. ∗ are run by us. We run the kkk -NN evaluation for models with official released weights. The throughput (im/s)(\mathrm{im}/\mathrm{s})(im/s) is calculated on a NVIDIA V100 GPU with 128 samples per forward. Parameters (M) are of the feature extractor.
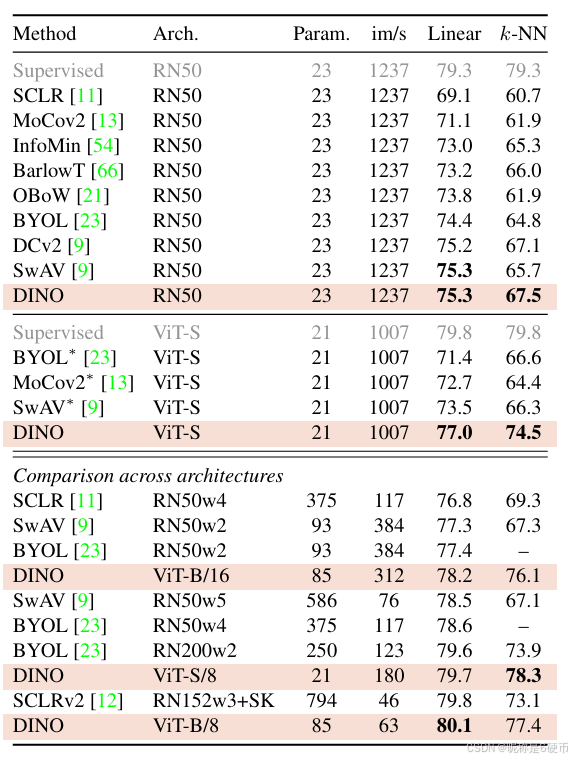
【翻译】表2:ImageNet上的线性分类和kkk-NN分类。我们报告了不同自监督方法在ImageNet验证集上线性评估和kkk-NN评估的top-1准确率。我们专注于ResNet-50和ViT-small架构,但也报告了跨架构获得的最佳结果。∗表示由我们运行的结果。我们对具有官方发布权重的模型运行kkk-NN评估。吞吐量(im/s)(\mathrm{im}/\mathrm{s})(im/s)是在NVIDIA V100 GPU上以每次前向传播128个样本计算的。参数(M)是特征提取器的参数数量。
4. Main Results
We first validate the DINO framework used in this study with the standard self-supervised benchmark on ImageNet. We then study the properties of the resulting features for retrieval, object discovery and transfer-learning.
【翻译】我们首先在ImageNet的标准自监督基准上验证本研究中使用的DINO框架。然后我们研究所得特征在检索、目标发现和迁移学习方面的特性。
4.1. 在ImageNet上与SSL框架的比较
We consider two different settings: comparison with the same architecture and across architectures.
Comparing with the same architecture. In top panel of Table 2, we compare DINO with other self-supervised methods with the same architecture, either a ResNet-50 [27] or a ViT-small (ViT-S) [56]. The choice of ViT-S is motivated by its similarity with ResNet-50 along several axes: number of parameters (21M vs 23M), throughput (1237/sec VS 1007im/sec)1007{\mathrm{~im/sec}})1007 im/sec) and supervised performance on ImageNet with the training procedure of [56] ( 79.3%79.3\%79.3% VS 79.8%79.8\%79.8% ). We explore variants of ViT-S in Appendix. First, we observe that DINO performs on par with the state of the art on ResNet-50, validating that DINO works in the standard setting. When we switch to a ViT architecture, DINO outperforms BYOL, MoCov2 and SwAV by +3.5%+3.5\%+3.5% with linear classification and by +7.9%+7.9\%+7.9% with kkk -NN evaluation. More surprisingly, the performance with a simple kkk -NN classifier is almost on par with a linear classifier 74.5%74.5\%74.5% versus 77.0%77.0\%77.0% ). This property emerges only when using DINO with ViT architectures, and does not appear with other existing self-supervised methods nor with a ResNet-50.
【翻译】我们考虑两种不同的设置:相同架构的比较和跨架构的比较。
相同架构的比较。在表2的上半部分,我们将DINO与其他具有相同架构的自监督方法进行比较,要么是ResNet-50 [27],要么是ViT-small (ViT-S) [56]。选择ViT-S的动机是它与ResNet-50在几个方面的相似性:参数数量(21M vs 23M)、吞吐量(1237/sec VS 1007im/sec1007{\mathrm{~im/sec}}1007 im/sec)以及在ImageNet上使用[56]的训练程序的监督性能(79.3%79.3\%79.3% VS 79.8%79.8\%79.8%)。我们在附录中探索了ViT-S的变体。首先,我们观察到DINO在ResNet-50上的表现与最先进的方法相当,验证了DINO在标准设置下的有效性。当我们切换到ViT架构时,DINO在线性分类上比BYOL、MoCov2和SwAV高出+3.5%+3.5\%+3.5%,在kkk-NN评估上高出+7.9%+7.9\%+7.9%。更令人惊讶的是,简单的kkk-NN分类器的性能几乎与线性分类器相当(74.5%74.5\%74.5% versus 77.0%77.0\%77.0%)。这种特性只有在使用DINO与ViT架构时才会出现,在其他现有的自监督方法或ResNet-50中都不会出现。
Table 3: Image retrieval. We compare the performance in retrieval of off-the-shelf features pretrained with supervision or with DINO on ImageNet and Google Landmarks v2 (GLDv2) dataset. We report mAP on revisited Oxford and Paris. Pretraining with DINO on a landmark dataset performs particularly well. For reference, we also report the best retrieval method with off-the-shelf features [46].
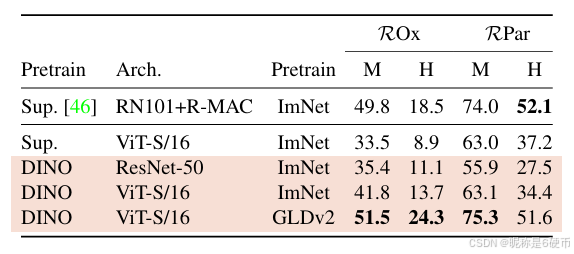
表3:图像检索。我们比较了在ImageNet和Google Landmarks v2 (GLDv2)数据集上用监督或DINO预训练的现成特征在检索中的性能。我们报告了在重新访问的Oxford和Paris上的mAP。在地标数据集上使用DINO预训练表现特别好。作为参考,我们还报告了使用现成特征的最佳检索方法[46]。
Comparing across architectures. On the bottom panel of Table 2, we compare the best performance obtained across architectures. The interest of this setting is not to compare methods directly, but to evaluate the limits of a ViT trained with DINO when moving to larger architectures. While training a larger ViT with DINO improves the performance, reducing the size of the patches (“/8” variants) has a bigger impact on the performance. While reducing the patch size do not add parameters, it still leads to a significant reduction of running time, and larger memory usage. Nonetheless, a base ViT with 8×88\times88×8 patches trained with DINO achieves 80.1%80.1\%80.1% top-1 in linear classification and 77.4%77.4\%77.4% with a kkk -NN classifier with 10×10\times10× less parameters and 1.4×1.4\times1.4× faster run time than previous state of the art [12].
跨架构的比较。在表2的下半部分,我们比较了跨架构获得的最佳性能。这种设置的意义不是直接比较方法,而是评估当转向更大架构时用DINO训练的ViT的极限。虽然用DINO训练更大的ViT可以提高性能,但减少补丁的大小("/8"变体)对性能的影响更大。虽然减少补丁大小不会增加参数,但仍然导致运行时间的显著减少和更大的内存使用。尽管如此,用DINO训练的具有8×88\times88×8补丁的基础ViT在线性分类中达到80.1%80.1\%80.1%的top-1,在kkk-NN分类器中达到77.4%77.4\%77.4%,参数比之前的最先进方法[12]少10×10\times10×,运行时间快1.4×1.4\times1.4×。
4.2. 使用SSL训练的ViT的特性
We evaluate properties of the DINO features in terms of nearest neighbor search, retaining information about object location and transferability to downstream tasks.
【翻译】我们从最近邻搜索、保留目标位置信息和可迁移性到下游任务等方面评估DINO特征的特性。
Table 4: Copy detection. We report the mAP performance in copy detection on Copydays “strong” subset [18]. For reference, we also report the performance of the multigrain model [4], trained specifically for particular object retrieval.
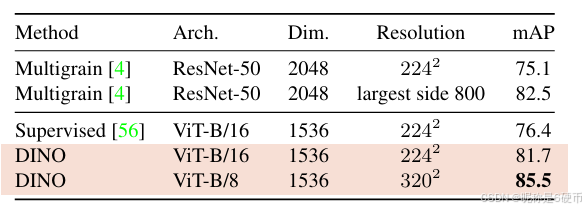
【翻译】表4:复制检测。我们报告了在Copydays "strong"子集[18]上复制检测的mAP性能。作为参考,我们还报告了专门为特定目标检索训练的multigrain模型[4]的性能。
4.2.1 Nearest neighbor retrieval with DINO ViT
The results on ImageNet classification have exposed the potential of our features for tasks relying on nearest neighbor retrieval. In this set of experiments, we further consolidate this finding on landmark retrieval and copy detection tasks.
【翻译】ImageNet分类的结果揭示了我们的特征在依赖最近邻检索的任务中的潜力。在这组实验中,我们进一步在地标检索和复制检测任务上巩固了这一发现。
Image Retrieval. We consider the revisited [43] Oxford and Paris image retrieval datasets [40]. They contain 3 different splits of gradual difficulty with query/database pairs. We report the Mean Average Precision (mAP) for the Medium (M) and Hard (H) splits. In Table 3, we compare the performance of different off-the-shelf features obtained with either supervised or DINO training. We freeze the features and directly apply kkk -NN for retrieval. We observe that DINO features outperform those trained on ImageNet with labels.
【翻译】图像检索。我们考虑重新访问的[43] Oxford和Paris图像检索数据集[40]。它们包含3个不同的难度递增的分割,具有查询/数据库对。我们报告中等(M)和困难(H)分割的平均精度均值(mAP)。在表3中,我们比较了通过监督或DINO训练获得的不同现成特征的性能。我们冻结特征并直接应用kkk-NN进行检索。我们观察到DINO特征优于在ImageNet上使用标签训练的特征。
An advantage of SSL approaches is that they can be trained on any dataset, without requiring any form of annotations. We train DINO on the 1.2M clean set from Google Landmarks v2 (GLDv2) [59], a dataset of landmarks designed for retrieval purposes. DINO ViT features trained on GLDv2 are remarkably good, outperforming previously published methods based on off-the-shelf descriptors [55, 46].
【翻译】SSL方法的一个优势是它们可以在任何数据集上训练,而不需要任何形式的注释。我们在Google Landmarks v2 (GLDv2) [59]的1.2M清洁集上训练DINO,这是一个专为检索目的设计的地标数据集。在GLDv2上训练的DINO ViT特征表现极佳,优于之前基于现成描述符发布的方法[55, 46]。
Copy detection. We also evaluate the performance of ViTs trained with DINO on a copy detection task. We report the mean average precision on the “strong” subset of the INRIA Copydays dataset [18]. The task is to recognize images that have been distorted by blur, insertions, print and scan, etc. Following prior work [4], we add 10k distractor images randomly sampled from the YFCC100M dataset [53]. We perform copy detection directly with cosine similarity on the features obtained from our pretrained network. The features are obtained as the concatenation of the output [CLS] token and of the GeM pooled [44] output patch tokens. This results in a 1536d descriptor for ViT-B. Following [4], we apply whitening on the features. We learn this transformation on an extra 20K random images from YFCC100M, distincts from the distractors. Table 4 shows that ViT trained with DINO is very competitive on copy detection.
【翻译】复制检测。我们还评估了用DINO训练的ViT在复制检测任务上的性能。我们报告了INRIA Copydays数据集[18]"strong"子集上的平均精度均值。任务是识别经过模糊、插入、打印和扫描等扭曲的图像。遵循之前的工作[4],我们添加了从YFCC100M数据集[53]随机抽样的10k干扰图像。我们直接使用预训练网络获得的特征的余弦相似度进行复制检测。特征是通过连接输出[CLS]标记和GeM池化[44]输出补丁标记获得的。这为ViT-B产生了1536维描述符。遵循[4],我们对特征应用白化。我们在YFCC100M的额外20K随机图像上学习这种变换,与干扰图像不同。表4显示,用DINO训练的ViT在复制检测上非常有竞争力。
Table 5: DAVIS 2017 Video object segmentation. We evaluate the quality of frozen features on video instance tracking. We report mean region similarity Im\mathcal{I}_{m}Im and mean contour-based accuracy Fm{\mathcal{F}}_{m}Fm . We compare with existing self-supervised methods and a supervised ViT-S/8 trained on ImageNet. Image resolution is 480p480\mathrm{p}480p .
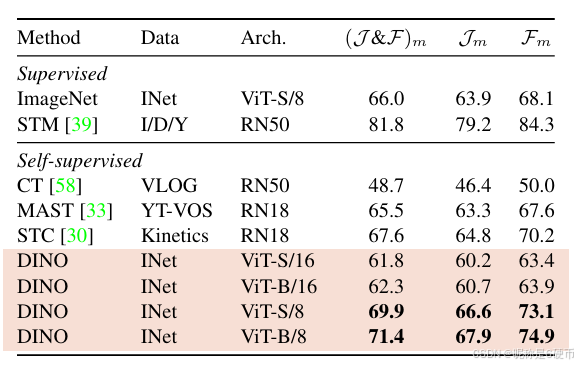
【翻译】表5:DAVIS 2017视频目标分割。我们评估冻结特征在视频实例跟踪上的质量。我们报告平均区域相似度Im\mathcal{I}_{m}Im和平均基于轮廓的准确度Fm{\mathcal{F}}_{m}Fm。我们与现有的自监督方法和在ImageNet上训练的监督ViT-S/8进行比较。图像分辨率为480p480\mathrm{p}480p。
Figure 3: Attention maps from multiple heads. We consider the heads from the last layer of a ViT-S/8 trained with DINO and display the self-attention for [CLS] token query. Different heads, materialized by different colors, focus on different locations that represents different objects or parts (more examples in Appendix).

【翻译】图3:来自多个注意力头的注意力图。我们考虑用DINO训练的ViT-S/8最后一层的注意力头,并显示[CLS]标记查询的自注意力。不同的注意力头,用不同的颜色表示,关注代表不同目标或部分的不同位置(附录中有更多示例)。
4.2.2 发现场景的语义布局
As shown qualitatively in Figure 1, our self-attention maps contain information about the segmentation of an image. In this study, we measure this property on a standard benchmark as well as by directly probing the quality of masks generated from these attention maps.
【翻译】如图1定性所示,我们的自注意力图包含有关图像分割的信息。在这项研究中,我们在标准基准测试上测量这一特性,并直接探测从这些注意力图生成的掩码的质量。
Video instance segmentation. In Tab. 5, we evaluate the output patch tokens on the DAVIS-2017 video instance segmentation benchmark [42]. We follow the experimental protocol in Jabri et al. [30] and segment scenes with a nearestneighbor between consecutive frames; we thus do not train any model on top of the features, nor finetune any weights for the task. We observe in Tab. 5 that even though our training objective nor our architecture are designed for dense tasks, the performance is competitive on this benchmark. Since the network is not finetuned, the output of the model must have retained some spatial information. Finally, for this dense recognition task, the variants with small patches (“/8”) perform much better (+9.1%(I&F)m(+9.1\%(\mathcal{I}\&\mathcal{F})_{m}(+9.1%(I&F)m for ViT-B).
【翻译】视频实例分割。在表5中,我们在DAVIS-2017视频实例分割基准测试[42]上评估输出补丁标记。我们遵循Jabri等人[30]的实验协议,使用连续帧之间的最近邻来分割场景;因此我们不在特征之上训练任何模型,也不为该任务微调任何权重。我们在表5中观察到,尽管我们的训练目标和架构都不是为密集任务设计的,但在这个基准测试上的性能是有竞争力的。由于网络没有经过微调,模型的输出必须保留了一些空间信息。最后,对于这种密集识别任务,具有小补丁的变体(“/8”)表现要好得多(ViT-B的(I&F)m(\mathcal{I}\&\mathcal{F})_{m}(I&F)m提高了+9.1%+9.1\%+9.1%)。
Figure 4: Segmentations from supervised versus DINO. We visualize masks obtained by thresholding the self-attention maps to keep 60%60\%60% of the mass. On top, we show the resulting masks for a ViT-S/8 trained with supervision and DINO. We show the best head for both models. The table at the bottom compares the Jaccard similarity between the ground truth and these masks on the validation images of PASCAL VOC12 dataset.
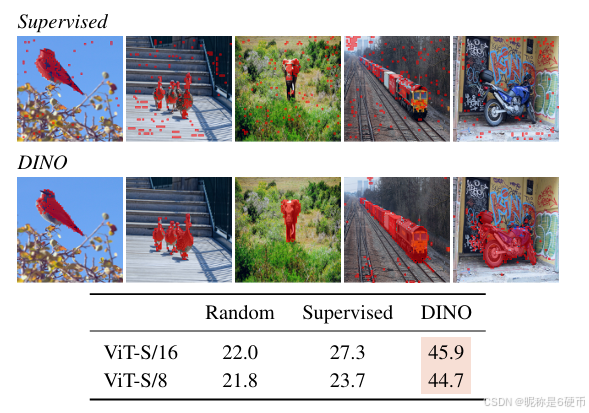
【翻译】图4:监督与DINO的分割比较。我们可视化通过对自注意力图进行阈值处理以保留60%60\%60%质量而获得的掩码。在顶部,我们显示了用监督和DINO训练的ViT-S/8的结果掩码。我们展示了两个模型的最佳头。底部的表格比较了PASCAL VOC12数据集验证图像上真实标签与这些掩码之间的Jaccard相似度。
Probing the self-attention map. In Fig. 3, we show that different heads can attend to different semantic regions of an image, even when they are occluded (the bushes on the third row) or small (the flag on the second row). Visualizations are obtained with 480p images, resulting in sequences of 3601 tokens for ViT-S/8. In Fig. 4, we show that a supervised ViT does not attend well to objects in presence of clutter both qualitatively and quantitatively. We report the Jaccard similarity between the ground truth and segmentation masks obtained by thresholding the self-attention map to keep 60%60\%60% of the mass. Note that the self-attention maps are smooth and not optimized to produce a mask. Nonetheless, we see a clear difference between the supervised or DINO models with a significant gap in terms of Jaccard similarities. Note that self-supervised convnets also contain information about segmentations but it requires dedicated methods to extract it from their weights [24].
【翻译】探测自注意力图。在图3中,我们显示不同的头可以关注图像的不同语义区域,即使当它们被遮挡(第三行的灌木丛)或很小(第二行的旗帜)时也是如此。可视化是通过480p图像获得的,对于ViT-S/8产生3601个标记的序列。在图4中,我们显示监督的ViT在存在杂乱的情况下无法很好地关注目标,无论是定性还是定量。我们报告了通过对自注意力图进行阈值处理以保留60%60\%60%质量而获得的真实标签与分割掩码之间的Jaccard相似度。注意自注意力图是平滑的,并没有优化来产生掩码。尽管如此,我们看到监督或DINO模型之间存在明显差异,在Jaccard相似度方面有显著差距。注意自监督卷积网络也包含关于分割的信息,但需要专门的方法从其权重中提取[24]。
Table 6: Transfer learning by finetuning pretrained models on different datasets. We report top-1 accuracy. Self-supervised pretraining with DINO transfers better than supervised pretraining.
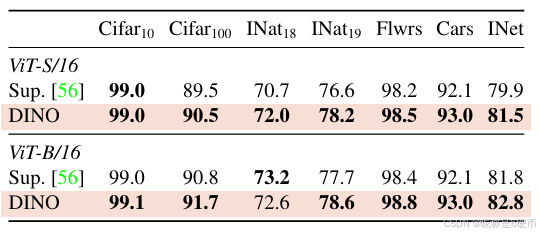
【翻译】表6:通过在不同数据集上微调预训练模型的迁移学习。我们报告top-1准确率。使用DINO的自监督预训练比监督预训练转移效果更好。
4.2.3 下游任务的迁移学习
In Tab. 6, we evaluate the quality of the features pretrained with DINO on different downstream tasks. We compare with features from the same architectures trained with supervision on ImageNet. We follow the protocol used in Touvron et al. [56] and finetune the features on each downstream task. We observe that for ViT architectures, self-supervised pretraining transfers better than features trained with supervision, which is consistent with observations made on convolutional networks [9, 26, 51]. Finally, self-supervised pretraining greatly improves results on ImageNet (+1−2%)(+1-2\%)(+1−2%) .
【翻译】在表6中,我们评估了用DINO在不同下游任务上预训练的特征质量。我们与在ImageNet上进行监督训练的相同架构的特征进行比较。我们遵循Touvron等人[56]使用的协议,并在每个下游任务上微调特征。我们观察到,对于ViT架构,自监督预训练比监督训练的特征转移效果更好,这与在卷积网络上的观察一致[9, 26, 51]。最后,自监督预训练大大改善了ImageNet上的结果(+1−2%+1-2\%+1−2%)。
5. DINO的消融研究
In this section, we empirically study DINO applied to ViT. The model considered for this entire study is ViT-S. We also refer the reader to Appendix for additional studies.
【翻译】在本节中,我们实证研究了应用于ViT的DINO。整个研究考虑的模型是ViT-S。我们还请读者参考附录以获得额外的研究。
Importance of the Different Components We show the impact of adding different components from self-supervised learning on ViT trained with our framework.
【翻译】不同组件的重要性 我们展示了在使用我们框架训练的ViT上添加来自自监督学习的不同组件的影响。
In Table 7, we report different model variants as we add or remove components. First, we observe that in the absence of momentum, our framework does not work (row 2) and more advanced operations, SK for example, are required to avoid collapse (row 9). However, with momentum, using SK has little impact (row 3). In addtition, comparing rows 3 and 9 highlights the importance of the momentum encoder for performance. Second, in rows 4 and 5, we observe that multi-crop training and the cross-entropy loss in DINO are important components to obtain good features. We also observe that adding a predictor to the student network has little impact (row 6) while it is critical in BYOL to prevent collapse [14, 23]. For completeness, we propose in Appendix an extended version of this ablation study.
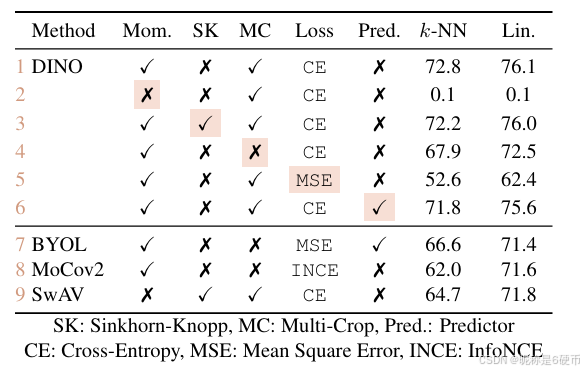
【翻译】在表7中,我们报告了在添加或移除组件时的不同模型变体。首先,我们观察到在没有动量的情况下,我们的框架不起作用(第2行),需要更高级的操作(例如SK)来避免崩塌(第9行)。然而,有了动量,使用SK的影响很小(第3行)。此外,比较第3行和第9行突出了动量编码器对性能的重要性。其次,在第4行和第5行中,我们观察到多裁剪训练和DINO中的交叉熵损失是获得良好特征的重要组件。我们还观察到向学生网络添加预测器的影响很小(第6行),而这在BYOL中对防止崩塌至关重要[14, 23]。为了完整性,我们在附录中提出了这种消融研究的扩展版本。
Importance of the patch size. In Fig. 5, we compare the kkk -NN classification performance of ViT-S models trained with different patch sizes, 16×1616\times1616×16 , 8×88\times88×8 and 5×55\times55×5 . We also compare to ViT-B with 16×1616\times1616×16 and 8×88\times88×8 patches. All the models are trained for 300 epochs. We observe that the performance greatly improves as we decrease the size of the patch. It is interesting to see that performance can be greatly improved without adding additional parameters. However, the performance gain from using smaller patches comes at the expense of throughput: when using 5×55\times55×5 patches, the throughput falls to 44 im/s, vs 180 im/s for 8×88\times88×8 patches.
【翻译】补丁大小的重要性。在图5中,我们比较了使用不同补丁大小(16×1616\times1616×16、8×88\times88×8和5×55\times55×5)训练的ViT-S模型的kkk-NN分类性能。我们还与使用16×1616\times1616×16和8×88\times88×8补丁的ViT-B进行比较。所有模型都训练了300个epoch。我们观察到随着补丁大小的减少,性能大大改善。有趣的是,在不添加额外参数的情况下,性能可以大大改善。然而,使用较小补丁的性能提升是以吞吐量为代价的:当使用5×55\times55×5补丁时,吞吐量降至44 im/s,而8×88\times88×8补丁为180 im/s。
Table 7: Important component for self-supervised ViT pretraining. Models are trained for 300 epochs with ViT-S/16. We study the different components that matter for the kkk -NN and linear (“Lin.”) evaluations. For the different variants, we highlight the differences from the default DINO setting. The best combination is the momentum encoder with the multicrop augmentation and the cross-entropy loss. We also report results with BYOL [23], MoCo-v2 [13] and SwAV [9].
【翻译】表7:自监督ViT预训练的重要组件。模型使用ViT-S/16训练300个epoch。我们研究了对kkk-NN和线性(“Lin.”)评估重要的不同组件。对于不同的变体,我们突出了与默认DINO设置的差异。最佳组合是动量编码器与多裁剪增强和交叉熵损失。我们还报告了BYOL [23]、MoCo-v2 [13]和SwAV [9]的结果。
Figure 5: Effect of Patch Size. kkk -NN evaluation as a function of the throughputs for different input patch sizes with ViT-B and ViT-S. Models are trained for 300 epochs.
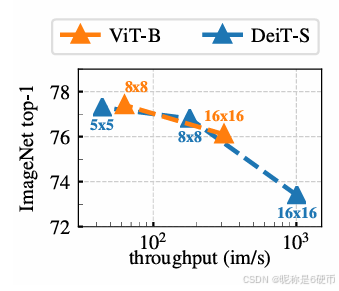
【翻译】图5:补丁大小的影响。不同输入补丁大小下ViT-B和ViT-S的kkk-NN评估作为吞吐量的函数。模型训练了300个epoch。
6. Conclusion
We have shown the potential of self-supervised pretraining a standard ViT model, achieving performance that are comparable with the best convnets specifically designed for this setting. We have also seen emerged two properties that can be leveraged in future applications: the quality of the features in kkk -NN classification has a potential for image retrieval. The presence of information about the scene layout in the features can also benefit weakly supervised image segmentation.
【翻译】我们已经展示了自监督预训练标准ViT模型的潜力,实现了与专门为此设置设计的最佳卷积网络相当的性能。我们还看到了两个可以在未来应用中利用的新兴属性:kkk-NN分类中特征的质量具有图像检索的潜力。特征中场景布局信息的存在也可以有益于弱监督图像分割。