拼写纠错模型Noisy Channel(下)
关键词:Noisy Channel
说明
在文中,我们将介绍检测和纠正拼写错误的问题。修正拼写错误是现代写作的重要组成部分,无论是通过手机短信、发送电子邮件、撰写较长文档,还是在网络上查找信息。现代拼写检查器并不完美(事实上,自动更正出错是网络上一个流行的娱乐来源),但它们几乎存在于任何依赖键盘输入的软件中。
本文接上文:https://blog.csdn.net/gongdiwudu/article/details/149297802?spm=1001.2014.3001.5501
四、实际拼写错误
噪声信道方法也可以应用于检测和纠正实际单词中的拼写错误,这些错误导致了英语中的一个实际单词。这可能由于打字错误(插入、删除、转位)意外地产生了一个实际单词(例如,将“three”错打成“there”),或者因为作者使用了同音词或近似同音词的错误拼写(例如,将“dessert”错写成“desert”,或将“piece”错写成“peace”)。一些研究表明,大约有25%到40%的拼写错误是有效的英语单词,如下列例子所示(Kukich, 1992):
This used to belong to thew queen. They are leaving in about fifteen minuets to go to her house.
The design an construction of the system will take more than a year.
Can they lave him my messages?
The study was conducted mainly be John Black.
【这曾经属于女王。他们大约十五分钟后要去她的房子。
该系统的设计和建设将超过一年时间。
他们能带我的消息给他吗?
这项研究主要是由约翰·布莱克进行的。】
噪声信道可以处理真实世界中的错误。让我们从Mays等人(1991年)首次提出的噪声信道模型开始,以应对这些真实世界的拼写错误。他们的算法接受输入句子X={x1,x2,…,xk,…,xn},生成一组候选纠正句子C(X),然后选择语言模型概率最高的句子。
为了生成候选纠正句子,我们首先为每个输入单词xi生成一组候选词。候选词C(xi)包括与xi编辑距离较小的所有英文单词。对于编辑距离为1(Mays等人,1991年的常见选择),对于罕见单词“thew”(意为‘肌肉力量’)的候选集可能是C(thew)={the, thaw, threw, them, thwe}。然后我们简化假设每个句子只有一个错误。因此,对于句子X=Only two of thew apples,候选句子集C(X)将是:
only two of thew apples
oily two of thew apples
only too of thew apples
only to of thew apples
only tao of the apples
only two on thew apples
only two off thew apples
only two of the apples
only two of threw apples
only two of thew applies
only two of thew dapples
每个句子都由噪声信道评分。
W^=argmaxw∈CP(X∣W)P(W)\hat W = \underset{w∈C}{argmax} P(X|W)P(W)W^=w∈CargmaxP(X∣W)P(W)
B7
对于P(W),我们可以使用句子的三元语法概率。那么信道模型呢?由于这些是真实单词,我们需要考虑输入单词不是错误的可能性。假设正确书写一个单词的信道概率P(w|w)为α;我们可以对不同任务中α的具体值做出不同的假设;也许在某些任务中α为0.95,假设人们每写20个单词就错一个,或者在其他任务中可能是0.99。Mays等人(1991)提出了一种简单的模型:给定一个打字词x,当x=w时,信道模型P(x|w)为α,然后将1-α均匀分配给所有其他候选修正C(x)。
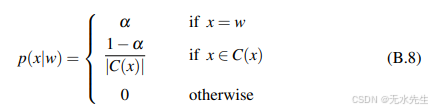
现在我们可以用公式B.6中更复杂的信道模型的编辑概率来替换公式B.8中的等量分配(1−α);我们将使分布与该更复杂信道模型的编辑概率成比例。让我们来看一个将这种集成噪声信道模型应用于实际单词的例子。假设我们看到字符串“two of thew”。作者可能本意是要输入真实单词“thew”(意为“肌肉力量”)。但在这里,“thew”也可能是一个拼写错误,可能是“the”或其他某个单词的错字。为了这个例子的目的,我们考虑编辑距离为1,并且只考虑以下五个候选词:“the”,“thaw”,“threw”和“thwe”(一个罕见的名字),以及所输入的字符串“thew”。我们从Norvig在2009年对该例子的分析中获取了编辑概率。对于语言模型概率,我们使用了一个基于Google n-grams训练的愚蠢退避模型(第??节)。
P(the∣twoof)=0.476012P(the|two of) = 0.476012P(the∣twoof)=0.476012
P(thew∣twoof)=9.95051×10−8P(thew|two of) = 9.95051 ×10^{−8}P(thew∣twoof)=9.95051×10−8
P(thaw∣twoof)=2.09267×10−7P(thaw|two of) = 2.09267 ×10^{−7}P(thaw∣twoof)=2.09267×10−7
P(threw∣twoof)=8.9064×10−7P(threw|two of) = 8.9064 ×10^{−7}P(threw∣twoof)=8.9064×10−7
P(them∣twoof)=0.00144488P(them|two of) = 0.00144488P(them∣twoof)=0.00144488
P(thwe∣twoof)=5.18681×10−9P(thwe|two of) = 5.18681 ×10^{−9}P(thwe∣twoof)=5.18681×10−9
在这里,我们刚刚计算了短语“two of thew”的概率,但模型适用于整个句子;因此,如果上下文中的例子是“two of thew people”,我们还需要乘以P(people|of the)、P(people|of thew)、P(people|of threw)等的概率。根据Norvig(2009)的假设,在这个任务中单词是拼写错误的概率为0.05,这意味着α=P(w|w)为0.95。图B.6显示了计算过程。
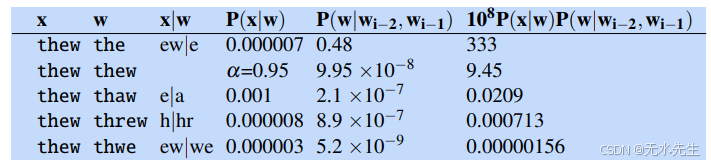
图B.6 在5个可能的thew候选者上的噪声信道模型,使用从Google n-gram语料库计算出的愚蠢三元语法语言模型和错误模型。
在诺维格(2009年)的研究中,对于错误短语“two of thew”,模型正确地选择了“the”作为纠正。但请注意,较低的错误率可能会改变情况;在一个任务中,如果错误的概率足够低(α值很高),模型可能会决定“thew”是作者想要的单词。
五 噪声信道模型:最新进展
当前最先进的噪声信道拼写纠错实现对上述简单模型进行了多项扩展。首先,现代系统不是假设输入句子只有一个错误,而是逐词处理输入,使用噪声信道为每个单词做出决策。但是,如果我们只是在每个单词上运行上述基本的噪声信道系统,它容易过度纠正,将正确的但罕见的单词(例如人名)替换为更常见的单词(Whitelaw等,2009;Wilcox-O’Hearn,2014)。因此,现代算法需要增强噪声信道,以检测是否应该真正纠正某个单词。例如,像Google这样的先进系统(Whitelaw等,2009)使用黑名单,禁止更改某些标记(如数字、标点符号和单字母单词)。这些系统在决定是否信任候选纠正时也更加谨慎。它们不仅选择一个候选纠正,如果它的概率P(w|x)高于单词本身,而是只有当概率差异足够大时才建议进行纠正w而不是保留非纠正x。最佳纠正w仅在以下情况下被选择:
logP(w∣x)−logP(x∣x)>θlogP(w|x)−logP(x|x) > θlogP(w∣x)−logP(x∣x)>θ
根据具体应用,拼写检查器可能会自动更正(自动将拼写更改为假设的修正)或仅仅标记错误并提供建议。这个决定通常由另一个分类器做出,该分类器使用诸如候选词之间的对数概率差异等特征来判断最佳候选词是否足够好(我们将在下一章介绍分类算法)。
在他们的网络查询语料库中,73%的词汇类型缺失了像pics、multiplayer、google、xbox、clipart和mallorca这样的词。因此,现代系统通常使用从非常大的一元词表(如Google n-gram语料库)自动派生出的更大字典。例如,Whitelaw等人(2009年)使用了大量网页样本中最常出现的前一千万个词汇类型。由于这个列表会包含许多拼写错误,他们的系统需要更复杂的错误模型。单词通常比其拼写错误更常见,这一事实可以用于候选建议,通过构建具有相似上下文的单词及其拼写变体集合,按频率排序,将最频繁的变体视为来源,并从差异中学习错误模型,无论是来自网络文本(Whitelaw等人,2009年)还是查询日志(Cucerzan和Brill,2004年)。当用户拒绝一个修正时,单词也可以自动添加到字典中,运行在手机上的系统可以从用户的联系人或日历中自动添加单词。
我们也可以通过改变先验和似然的组合方式来改进噪声信道模型。在标准模型中,它们只是相乘。但通常这些概率并不可比;语言模型或信道模型可能有不同的范围。或者对于某些任务或数据集,我们可能有理由更信任其中一个模型。因此,我们使用加权组合,将其中一个因子提升到幂 λ:
w^=argmaxw∈CP(x∣w)P(w)λ\hat w = \underset{w∈C}{argmax}P(x|w)P(w)^λw^=w∈CargmaxP(x∣w)P(w)λ
B9
在对数空间中
w^=argmaxw∈ClogP(x∣w)+λlogP(w)\hat w = \underset{w∈C}{argmax} logP(x|w)+ λlog P(w) w^=w∈CargmaxlogP(x∣w)+λlogP(w)
B10
然后我们在开发测试集上调整参数λ。最后,如果我们的目标是仅对特定混淆词组(如peace/piece,affect/effect,weather/whether)或语法纠错示例(如among/between)进行实际拼写纠正,我们可以训练监督分类器利用上下文的许多特征,在两个候选词之间做出选择。这些分类器可以对这些特定词组实现非常高的准确率,尤其是在利用大规模网络统计数据时(Golding和Roth 1999,Lapata和Keller 2004,Bergsma等2009,Bergsma等2010)。
六、 改进的编辑模型:分区和发音
最近的其他研究主要集中在改进信道模型P(t|c)。一个重要的扩展是能够计算多字母转换的概率。例如,Brill和Moore(2000)提出了一种信道模型,该模型(非正式地)将错误视为由打字员首先选择一个单词,然后选择该单词字母的分割,最后逐个输入每个分割,可能有错误。例如,想象一个人选择了单词physical,然后选择了分割ph y s i c al。她会生成每个分割,可能有错误。例如,生成字符串fisikle与分割f i s i k le的概率为p(f|ph) * p(i|y) * p(s|s) * p(i|i) * p(k|k) * p(le|al)。与Damerau-Levenshtein编辑距离不同,Brill-Moore信道模型可以因此建模编辑概率如P(f|ph)或P(le|al),或 P(错误字符串x)的高可能性。此外,每次编辑都取决于它在单词中的位置(开头、中间、结尾),因此模型实际上估计的是P(f|ph, 开头)而不是P(f|ph)。更正式地说,设R为将错误字符串x划分为相邻(可能为空)子字符串的分区,T为候选字符串的分区。Brill和Moore(2000年)则通过单个最佳分区的概率来近似总可能性P(x|w)(例如,P(fisikle|physical)):
P(x∣w)≈maxR,Ts.t.∣T∣=∣R∣∑i=1∣R∣P(Ti,∣Ri,position)P(x|w) ≈ \underset {R,T s.t.|T|=|R|}{max}\sum_{i=1}^{|R|}P(T_i,|R_i,position)P(x∣w)≈R,Ts.t.∣T∣=∣R∣max∑i=1∣R∣P(Ti,∣Ri,position)
(B.11)
每个变换的概率P(Ti|Ri)可以从一个训练集中学到,该训练集由错误、正确的字符串以及它出现的次数组成。例如,给定一个训练对akgsual/actual,使用标准最小编辑距离来生成对齐:
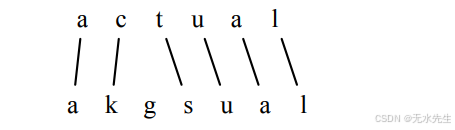
这种对齐对应于编辑操作的序列: 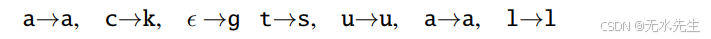
每个不匹配的替换然后扩展以包含多达N个额外的编辑;对于N=2,我们会将c→k扩展为:
ac→ak
c→cg
ac→akg
ct→kgs
每个这些多次编辑都获得一个分数计数,然后从训练语料库中的三元组中估计每个编辑 α → β 的概率为 count(α→β) / count(α)
在信道模型的另一个研究方向中,除了拼写之外,还使用发音。发音是某些非噪声信道拼写纠正算法(如GNU aspell算法,Atkinson, 2011)的重要特征,这些算法利用了单词的元音表示发音(Philips, 1990)。元音是一系列将单词映射到其发音规范化表示的规则。一些示例规则:
删除重复的相邻字母,但C除外。
如果单词以‘KN’、‘GN’、‘PN’、‘AE’、‘WR’开头,则删除第一个字母。
如果B在M之后且位于单词末尾,则删除B。
Aspell与噪声信道模型中的通道组件类似,找到字典中所有发音字符串与拼写错误之间编辑距离(1或2个发音字母)较短的单词,然后通过结合两个编辑距离的度量标准对这些候选词进行评分:一个是发音编辑距离,另一个是加权字母编辑距离。
发音也可以直接融入噪声信道模型。例如,Toutanova和Moore(2002)的模型,像aspell一样,插值两个信道。

(图B.7 Soundex算法)
上面模型,一个基于拼写,另一个基于发音。发音字母到音素模型是通过使用字母到音素模型来翻译每个输入单词,并将字典中的每个单词转换为表示该单词发音的音素序列。例如,actress和aktress都会映射到音素字符串ae k t r ix s。参见第16章关于字母到音素或图谱到音素的任务。
一些额外的字符串距离函数被提出用于专门处理名字。这些主要用于去重任务(决定人口普查列表或其他名单中的两个名字是否相同),而不是拼写检查。Soundex算法(Knuth 1973,Odell和Russell 1918/1922)是一种较老的方法,最初用于人口普查记录以表示人们的名字。它的优点是稍微拼错的名字版本仍然会有与正确拼写的名称相同的表示(例如,Jurafsky,Jarofsky,Jarovsky和Jarovski都映射到J612)。该算法显示在图B.7中。
Jaro-Winkler 相比于Soundex,最近的工作使用了Jaro-Winkler距离,这是一种编辑距离算法,设计用于名字,允许字符在较长的名字中移动更长的距离,并且对初始字符相同的字符串给予更高的相似度(Winkler,2006)。
七、 后记
以上是一篇论文整理的一部分,并不是我的原创,我的唯一贡献是将该论文整理编辑,先放在这里,然后慢慢研读,成为自己的东西。