使用pytorch创建模型时,nn.BatchNorm1d(128)的作用是什么?
在PyTorch中,nn.BatchNorm1d(128) 的作用是对 一维输入数据(如全连接层的输出或时间序列数据)进行批标准化(Batch Normalization),具体功能与实现原理如下:
1. 核心作用
- 标准话数据分布
对每个批次的输入数据进行归一化,使其均值接近0、方差接近1,公式如下:
x^=x−μbatchσbatch2+e\hat{\mathbf{x}}=\frac{\mathbf{x}-\mathbf{\mu}_{batch}}{\sqrt{\sigma^{2}_{batch}+e}}x^=σbatch2+ex−μbatch
其中:- μbatch\mu_{batch}μbatch:当前批次的均值
- σbatch\sigma_{batch}σbatch:当前批次的方差
- eee: 防止除零的小常数(默认1e-5)
- 可学习的缩放与偏移:
通过参数γ\gammaγ (缩放)和 β\betaβ(偏移)保留模型的表达能力:
y=γx^+β y = \gamma \hat{\mathbf{x}}+\beta y=γx^+β
2. 参数解释

3. 全连接网络应用场景
import torch.nn as nnmodel = nn.Sequential(nn.Linear(64, 128),nn.BatchNorm1d(128), # 对128维特征归一化nn.ReLU(),nn.Linear(128, 10)
)
数学效果:
若输入特征x∈Rm×128\mathbf{x}\in \mathbb{R}^{m\times128}x∈Rm×128,输出yyy满足:
E[y:j]≈0,Var(y:,j)≈1
\mathbb{E}[y_{:j}]\approx0, Var(y_{:,j})\approx1
E[y:j]≈0,Var(y:,j)≈1
4. 与其他归一化层的对比
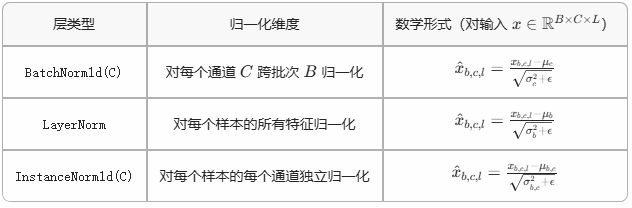
5. 训练与推理的差异
- 训练阶段
使用当前批次的统计量μbatch\mu_{batch}μbatch和σbatch2\sigma_{batch}^2σbatch2,并更新全局统计量:
μrunnning←μrunning×(1−momentum)+μbatch×momentum\mu_{runnning} \leftarrow \mu_{running}\times(1-momentum) + \mu_{batch}\times momentumμrunnning←μrunning×(1−momentum)+μbatch×momentum - 推理阶段(测试阶段)
固定使用训练积累的全局统计量μbatch\mu_{batch}μbatch和σbatch2\sigma_{batch}^2σbatch2
KaTeX parse error: Undefined control sequence: \sigmma at position 54: …unning}}{\sqrt{\̲s̲i̲g̲m̲m̲a̲^{2}_{running}+…
6. 代码战争数学性质
import torch# 模拟输入(batch_size=4, 128维特征)
x = torch.randn(4, 128) * 2 + 1 # 均值1,方差4bn = nn.BatchNorm1d(128, affine=False) # 禁用γ和β
output = bn(x)print("输入均值:", x.mean(dim=0).mean().item()) # ≈1
print("输出均值:", output.mean(dim=0).mean().item()) # ≈0
print("输入方差:", x.var(dim=0).mean().item()) # ≈4
print("输出方差:", output.var(dim=0).mean().item()) # ≈1