假如只给物品编号和物品名称,怎么拆分为树形结构(拆出父级id和祖籍列表),用于存储具有层级关系的数据。
一、需求分析
需求:只给编号和物品名称,怎么拆分为树形结构,用于存储具有层级关系的数据。
例如下面这样:
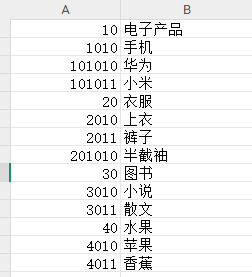
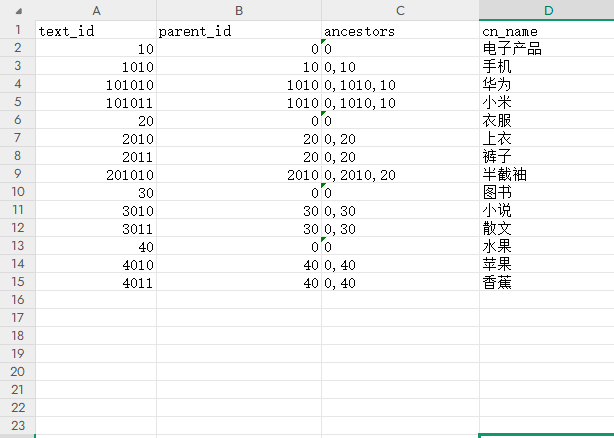
最终的到结果:
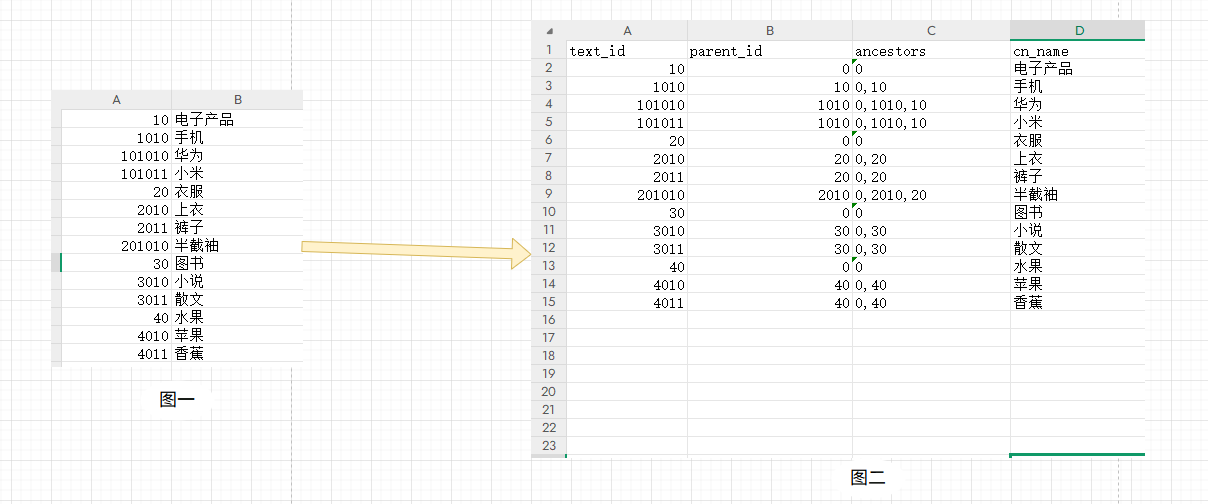
如果在项目·中,前端可能会这样展示:
- 电子产品- 手机- 华为- 小米- 衣服- 上衣- 半截袖- 裤子- 图书- 小说- 散文- 水果- 苹果- 香蕉
这种结构在数据库中被称为嵌套集合模型(Nested Set Model)或邻接表模型(Adjacency List Model)。
字段含义:
- text_id:当前节点的唯一标识(主键)。
- parent_id:当前节点的父节点 ID。
- ancestors:当前节点的所有祖先节点
- ID(用逗号分隔)。
- cn_name:节点名称。
层级关系:
- 根节点的parent_id为0,ancestors为0。
- 子节点的parent_id指向父节点的text_id。
- ancestors字段存储从根节点到当前节点的路径(如10,0,10表示路径为根节点 -> 10 -> 当前节点)。
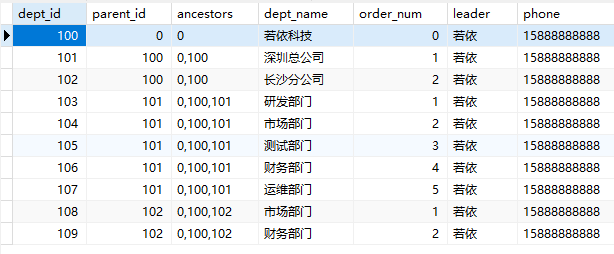
例如,若依框架中的部门表(sys_dept),也是这样的存储结构:
二、主要方法实现
2.1 main方法
main方法是程序的执行入口,负责协调各个数据处理步骤。它首先调用readDataFromExcel方法读取本地Excel文件的数据,然后创建一个新的Excel工作簿,并在其中创建一个名为“文本数据”的工作表。接着,为工作表创建表头,并对读取到的每一项数据进行处理,计算parent_id和ancestors,将处理后的数据写入工作表的相应行。最后,自动调整列宽并保存生成的Excel文件。
public static void main(String[] args) {// 读取本地 Excel 文件String[][] dataFromFigure2 = readDataFromExcel("E:\\idea_workspace\\maven_project\\input_data.xlsx");try (Workbook workbook = new XSSFWorkbook()) {Sheet sheet = workbook.createSheet("文本数据");// 创建表头行Row headerRow = sheet.createRow(0);String[] headers = {"text_id", "parent_id", "ancestors", "cn_name", "english_name"};for (int i = 0; i < headers.length; i++) {Cell cell = headerRow.createCell(i);cell.setCellValue(headers[i]);}// 处理每个数据项int rowNum = 1;for (String[] item : dataFromFigure2) {String code = item[0];String name = item[1];long id = Long.parseLong(code);// 计算parent_id和ancestorsString parentCode = getParentCode(code);long parentId = parentCode != null? Long.parseLong(parentCode) : 0;String ancestors = calculateAncestors(parentCode);// 创建数据行Row row = sheet.createRow(rowNum++);row.createCell(0).setCellValue(id);row.createCell(1).setCellValue(parentId);row.createCell(2).setCellValue(ancestors);row.createCell(3).setCellValue(name);row.createCell(4).setCellValue(""); // 留空,后续根据需求填写}// 自动调整列宽for (int i = 0; i < headers.length; i++) {sheet.autoSizeColumn(i);}// 保存Excel文件try (FileOutputStream fileOut = new FileOutputStream("text_data.xlsx")) {workbook.write(fileOut);}System.out.println("Excel文件已生成:text_data.xlsx");} catch (IOException e) {e.printStackTrace();}
}
2.2 readDataFromExcel方法
该方法负责从指定路径的Excel文件中读取数据。它使用FileInputStream读取文件,并通过WorkbookFactory.create方法创建Workbook对象。然后遍历工作表的每一行,跳过表头行,根据单元格类型获取code和name值,并将其存储在List中,最后将List转换为二维数组返回。
private static String[][] readDataFromExcel(String filePath) {List<String[]> dataList = new ArrayList<>();try (FileInputStream fis = new FileInputStream(filePath);Workbook workbook = WorkbookFactory.create(fis)) {Sheet sheet = workbook.getSheetAt(0);for (Row row : sheet) {if (row.getRowNum() == 0) continue; // 跳过表头Cell codeCell = row.getCell(0);Cell nameCell = row.getCell(1);if (codeCell != null && nameCell != null) {// 根据单元格类型获取 code 值String code = getCellValueAsString(codeCell);// 根据单元格类型获取 name 值String name = getCellValueAsString(nameCell);dataList.add(new String[]{code, name});}}} catch (IOException e) {e.printStackTrace();}return dataList.toArray(new String[0][]);
}
2.3 getCellValueAsString方法
此方法根据单元格的类型获取其字符串值。对于STRING类型,直接返回字符串值;对于NUMERIC类型,将其转换为长整型后再转换为字符串;对于BOOLEAN类型,返回布尔值的字符串表示;对于FORMULA类型,返回单元格的公式;其他类型则返回空字符串。
private static String getCellValueAsString(Cell cell) {CellType cellType = cell.getCellType();switch (cellType) {case STRING:return cell.getStringCellValue();case NUMERIC:// 处理数值类型,将其转换为字符串return String.valueOf((long) cell.getNumericCellValue());case BOOLEAN:return String.valueOf(cell.getBooleanCellValue());case FORMULA:return cell.getCellFormula();default:return "";}
}
在 Apache POI 库中,FORMULA 是 CellType 枚举里的一个值,代表 Excel 单元格使用了公式。在 Excel 里,用户可以在单元格输入公式,像 =SUM(A1:A10)、=AVERAGE(B1:B5) 这类,让单元格依据公式自动计算并显示结果。
2.4 getParentCode方法
该方法用于计算给定编码的父编码。
- 若 code 的长度小于等于 2,认为该节点是根节点,没有父节点,返回 null。
- 若 code 的长度大于 2,截取 code 的前 length - 2 个字符作为父节点的 code。
private static String getParentCode(String code) {if (code.length() <= 2) return null;return code.substring(0, code.length() - 2);
}
2.5 calculateAncestors方法
此方法用于计算给定父编码的所有祖先编码。它从父编码开始,通过递归调用getParentCode方法获取每一级的父编码,并将其添加到StringBuilder中,最终返回以逗号分隔的祖先编码字符串,开头加上0。
- 若 parentCode 为 null,表示该节点是根节点,祖籍路径为 “0”。
- 初始化 StringBuilder 对象ancestors,初始值为 “0”。
- 使用 while 循环,不断调用 getParentCode 方法获取当前节点的父节点 code,并将其追加到 ancestors 中,直到父节点 code 为 null。
- 最后将 StringBuilder对象转换为字符串并返回。
private static String calculateAncestors(String parentCode) {if (parentCode == null) return "0";StringBuilder ancestors = new StringBuilder("0");String currentCode = parentCode;while (currentCode != null) {ancestors.append(",").append(currentCode);currentCode = getParentCode(currentCode);}return ancestors.toString();
}
完整代码
package com.example.utils;import org.apache.poi.ss.usermodel.*;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;public class ExcelReportUtils {public static void main(String[] args) {// 读取本地 Excel 文件String[][] dataFromFigure2 = readDataFromExcel("E:\\idea_workspace\\maven_project\\input_data.xlsx");try (Workbook workbook = new XSSFWorkbook()) {Sheet sheet = workbook.createSheet("文本数据");// 创建表头行Row headerRow = sheet.createRow(0);String[] headers = {"text_id", "parent_id", "ancestors", "cn_name", "english_name"};for (int i = 0; i < headers.length; i++) {Cell cell = headerRow.createCell(i);cell.setCellValue(headers[i]);}// 处理每个数据项int rowNum = 1;for (String[] item : dataFromFigure2) {String code = item[0];String name = item[1];long id = Long.parseLong(code);// 计算parent_id和ancestorsString parentCode = getParentCode(code);long parentId = parentCode != null ? Long.parseLong(parentCode) : 0;String ancestors = calculateAncestors(parentCode);// 创建数据行Row row = sheet.createRow(rowNum++);row.createCell(0).setCellValue(id);row.createCell(1).setCellValue(parentId);row.createCell(2).setCellValue(ancestors);row.createCell(3).setCellValue(name);row.createCell(4).setCellValue(""); // 留空,后续根据需求填写}// 自动调整列宽for (int i = 0; i < headers.length; i++) {sheet.autoSizeColumn(i);}// 保存Excel文件try (FileOutputStream fileOut = new FileOutputStream("text_data.xlsx")) {workbook.write(fileOut);}System.out.println("Excel文件已生成:text_data.xlsx");} catch (IOException e) {e.printStackTrace();}}// 读取本地 Excel 文件private static String[][] readDataFromExcel(String filePath) {List<String[]> dataList = new ArrayList<>();try (FileInputStream fis = new FileInputStream(filePath);Workbook workbook = WorkbookFactory.create(fis)) {Sheet sheet = workbook.getSheetAt(0);for (Row row : sheet) {if (row.getRowNum() == 0) continue; // 跳过表头Cell codeCell = row.getCell(0);Cell nameCell = row.getCell(1);if (codeCell != null && nameCell != null) {// 根据单元格类型获取 code 值String code = getCellValueAsString(codeCell);// 根据单元格类型获取 name 值String name = getCellValueAsString(nameCell);dataList.add(new String[]{code, name});}}} catch (IOException e) {e.printStackTrace();}return dataList.toArray(new String[0][]);}// 根据单元格类型获取字符串值private static String getCellValueAsString(Cell cell) {CellType cellType = cell.getCellType();switch (cellType) {case STRING:return cell.getStringCellValue();case NUMERIC:// 处理数值类型,将其转换为字符串return String.valueOf((long) cell.getNumericCellValue());case BOOLEAN:return String.valueOf(cell.getBooleanCellValue());case FORMULA:return cell.getCellFormula();default:return "";}}// 计算父编码private static String getParentCode(String code) {if (code.length() <= 2) return null;return code.substring(0, code.length() - 2);}// 计算ancestorsprivate static String calculateAncestors(String parentCode) {if (parentCode == null) return "0";StringBuilder ancestors = new StringBuilder("0");String currentCode = parentCode;while (currentCode != null) {ancestors.append(",").append(currentCode);currentCode = getParentCode(currentCode);}return ancestors.toString();}
}依赖管理
<dependencies><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId><version>1.15</version> </dependency><!-- FastJSON 依赖 --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.44</version></dependency><!-- SLF4J 日志实现(这里使用 Logback) --><dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>1.2.3</version></dependency><!-- Spring Web 依赖,包含所需的 Spring 相关类 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.7.17</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.14.0</version></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.8.2</version><scope>test</scope></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-engine</artifactId><version>5.8.2</version><scope>test</scope></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>5.3.29</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.3</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency><!-- 处理 .doc 格式文件的依赖 --><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>5.2.3</version></dependency><!-- docx4j 核心依赖 --><dependency><groupId>org.docx4j</groupId><artifactId>docx4j-JAXB-Internal</artifactId><version>8.3.10</version></dependency><!-- 用于将 XHTML 导入到 Word 文档的依赖 --><dependency><groupId>org.docx4j</groupId><artifactId>docx4j-ImportXHTML</artifactId><version>8.3.10</version></dependency><!-- 处理 XML 的依赖 --><dependency><groupId>org.jvnet.jaxb2_commons</groupId><artifactId>jaxb2-basics</artifactId><version>1.11.1</version></dependency><!-- 日志相关依赖 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.36</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.36</version></dependency><!-- flexmark-java 用于解析 Markdown --><dependency><groupId>com.vladsch.flexmark</groupId><artifactId>flexmark</artifactId><version>0.60.2</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.16.1</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.3</version></dependency></dependencies>