LRU算法及优化
LRU算法全称是最近最少使用算法(Least Recently Use),广泛的应用于缓存机制中。当缓存使用的空间达到上限后,就需要从已有的数据中淘汰一部分以维持缓存的可用性,而淘汰数据的选择就是通过LRU算法完成的。
潜在问题:淘汰热点数据,如果有个数据在1个小时的前59分钟访问了1万次(可见这是个热点数据),再后一分钟没有访问这个数据,但是有其他的数据访问,就导致了我们这个热点数据被淘汰。
基本算法描述
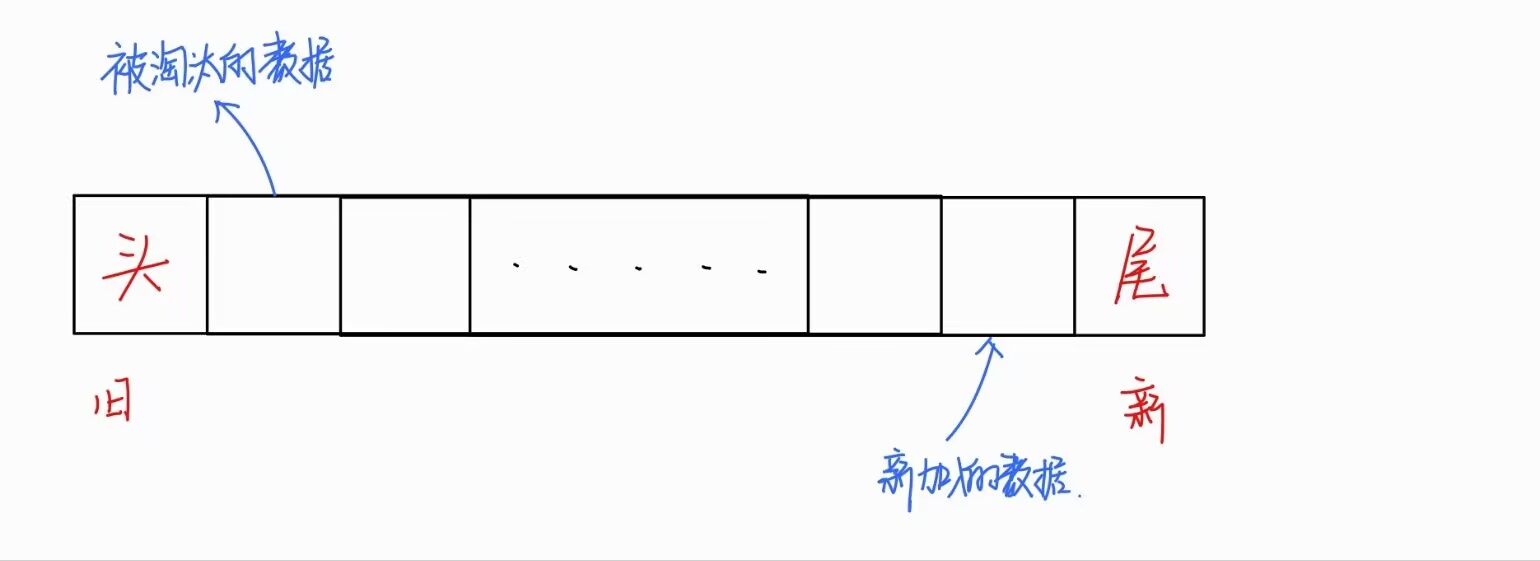
- 初始设置容量为capacity_的缓存空间,缓存中的数据为 (key,value) 结构;
- 设置哨兵节点头和尾
- 当有新加入数据操作时,先判断该 key 值是否已经在缓存空间中,如果在的话更新 key 对应的 value 值,并把该数据加入到缓存空间的最右边;
- 如果新加入数据的 key 值不在缓存空间中,则判断缓存空间是否已满,若缓存空间未满,则构造新的节点加入到缓存空间的最右边,否则把该数据加入到缓存空间的右边并淘汰掉队列最左边的数据(缓存中最久未被使用的数据);
LRU算法实现
基础版
基于双向链表+哈希表实现
哈希表可以快速定位与查找,但是不能够满足时序这个条件;双向链表可以满足时序条件,并且可以同时操作最近使用和最久未使用的两个边界元素,但是不能在 O(1) 时间复杂度内完成定位工作。故结合一下二者,采用双向链表及哈希表结合的方式来实现即可,
template <typename Key, typename Value>class LruCache;template <typename Key, typename Value>class LruNode{private:Key key_;Value value_;std::weak_ptr<LruNode<Key, Value>> prev_;std::shared_ptr<LruNode<Key, Value>> next_;public:LruNode(Key key, Value value) : key_(key), value_(value), count_(1) {}Key getKey() const { return key_; }Value getValue() const { return value_; }void setValue(Value &value) { value_ = value; }friend class LruCache<Key, Value>;};template <typename Key, typename Value>class LruCache : public Common{public:using LruNodeType = LruNode<Key, Value>;using LruNodePtr = std::shared_ptr<LruNodeType>;using NodeMap = std::unordered_map<Key, LruNodePtr>;LruCache(int capacity) : capacity_(capacity) { inital(); }~LruCache() override = default;private:int capacity_;NodeMap nodeMap_;LruNodePtr head_; // 虚拟头节点LruNodePtr tail_;std::mutex mtx_;void inital(){head_ = std::make_shared<LruNodeType>(Key(), Value());tail_ = std::make_shared<LruNodeType>(Key(), Value());head_->next_ = tail_;tail_->prev_ = head_;}// 尾插void insertNode(LruNodePtr node){node->next_ = tail_;node->prev_ = tail_->prev_;tail_->prev_.lock()->next_ = node;tail_->prev_ = node;}// 删除节点void removeNode(LruNodePtr node){if (!node->prev_.expired() && !node->next_.expired()){auto prev = node->prev_.lock();prev->next_ = node->next_;node->next_->prev_ = prev;node->next_ = nullptr;}}// 驱逐最近最少访问void evict(){LruNodePtr node = head_->next_;removeNode(node);nodeMap_.erase(node->getKey());}// 移动节点到最新位置void moveToMostRecent(LruNodePtr node){removeNode(node);insertNode(node);}void update(LruNodePtr node, const Value &value){node->setValue(value);moveToMostRecent(node);}void addNewNode(const Key &key, const Value &value){if (nodeMap_.size() >= capacity_){evict();}NodePtr newNode = std::make_shared<LruNodeType>(key, value);insertNode(newNode);nodeMap_[key] = newNode;}public:void put(const Key &key, const Value &value) override{if (capacity_ <= 0)return;std::lock_guard<std::mutex> lock(mtx_);auto it = nodeMap_.find(key);if (it != nodeMap_.end()){update(it->second, value);return;}addNewNode(key, value);}bool get(Key key, Value &value) override{std::lock_guard<std::mutex> lock(mtx_);auto it = nodeMap_.find(key);if (it != nodeMap_.end()){value = it->second->getValue();moveToMostRecent(it->second);return true;}return false;}Value get(Key key) override{Value value;get(key, value);return value;}void remove(Key key) override{std::lock_guard<std::mutex> lock(mtx_);auto it = nodeMap_.find(key);if (it != nodeMap_.end()){removeNode(it->second);nodeMap_.erase(it);}}};
朴素的LRU算法已经能够满足缓存的要求了,但是还是有一些不足。当热点数据较多时,有较高的命中率,但是如果有偶发性的批量操作,会使得热点数据被非热点数据挤出容器,使得缓存受到了“污染”。所以为了消除这种影响,又衍生出了下面这些优化方法。
LRU-K
LRU-k算法是对LRU算法的改进,基础的LRU算法被访问数据进入缓存队列只需要访问(put、get)一次就行,但是现在需要被访问k(大小自定义)次才能被放入缓存中,基础的LRU算法可以看成是LRU-1。
LRU-k算法有两个队列一个是缓存队列,一个是数据访问历史队列。当访问一个数据时,首先将其添加进入访问历史队列并进行累加访问次数,当该数据的访问次数超过k次后,才将数据缓存到缓存队列,从而避免缓存队列被冷数据所污染。同时访问历史队列中的数据也不是一直保留的,也是需要按照LRU的规则进行淘汰的。LRU-k执行过程如图:
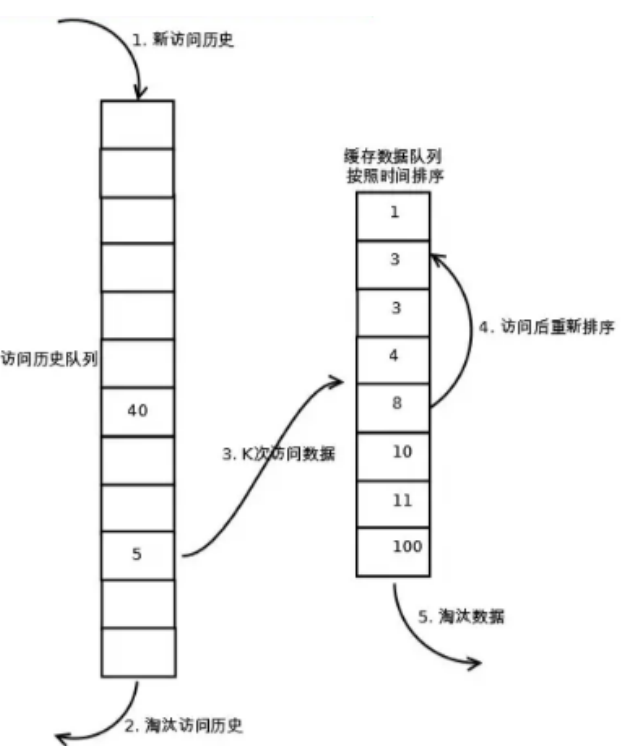
一般情况下,当k的值越大,缓存的命中率越高,但也使得缓存难以淘汰。综合来说,k = 2 时性能最优。
// LRU优化:Lru-k版本。 通过继承的方式进行再优化template <typename Key, typename Value>class LruKCache : public LruCache<Key, Value>{private:int k_; // 进入缓存队列的评判标准std::unique_ptr<LruCache<Key, size_t>> historyList_; // 访问数据历史记录(value为访问次数)std::unordered_map<Key, Value> historyValueMap_; // 存储未达到k次访问的数据值public:LruKCache(int capacity, int historyCapacity, int k): LruCache<Key, Value>(capacity) // 调用基类构造,historyList_(std::make_unique<LruCache<Key, size_t>>(historyCapacity)), k_(k){}Value get(Key key){// 首先尝试从主缓存获取数据Value value;bool inMainCache = LruCache<Key, Value>::get(key, value);// 获取并更新访问历史计数size_t historyCount = historyList_->get(key);historyCount++;historyList_->put(key, historyCount);// 如果数据在主缓存中,直接返回if (inMainCache){return value;}// 如果数据不在主缓存,但访问次数达到了k次if (historyCount >= k_){// 检查是否有历史值记录auto it = historyValueMap_.find(key);if (it != historyValueMap_.end()){// 有历史值,将其添加到主缓存Value storedValue = it->second;// 从历史记录移除historyList_->remove(key);historyValueMap_.erase(it);// 添加到主缓存LruCache<Key, Value>::put(key, storedValue);return storedValue;}// 没有历史值记录,无法添加到缓存,返回默认值}// 数据不在主缓存且不满足添加条件,返回默认值return value;}void put(const Key &key, const Value &value){// 检查是否已在主缓存Value existingValue;bool inMainCache = LruCache<Key, Value>::get(key, existingValue);if (inMainCache){// 已在主缓存,直接更新LruCache<Key, Value>::put(key, value);return;}// 获取并更新访问历史size_t historyCount = historyList_->get(key);historyCount++;historyList_->put(key, historyCount);// 保存值到历史记录映射,供后续get操作使用historyValueMap_[key] = value;// 检查是否达到k次访问阈值if (historyCount >= k_){// 达到阈值,添加到主缓存historyList_->remove(key);historyValueMap_.erase(key);LruCache<Key, Value>::put(key, value);}}};
但是呢,如果考虑到锁的粒度问题,会发现锁的粒度比较大,而且缓存的压力也比较大。所以我们可以换个思路,利用哈希,将LRU分片
HashLRU
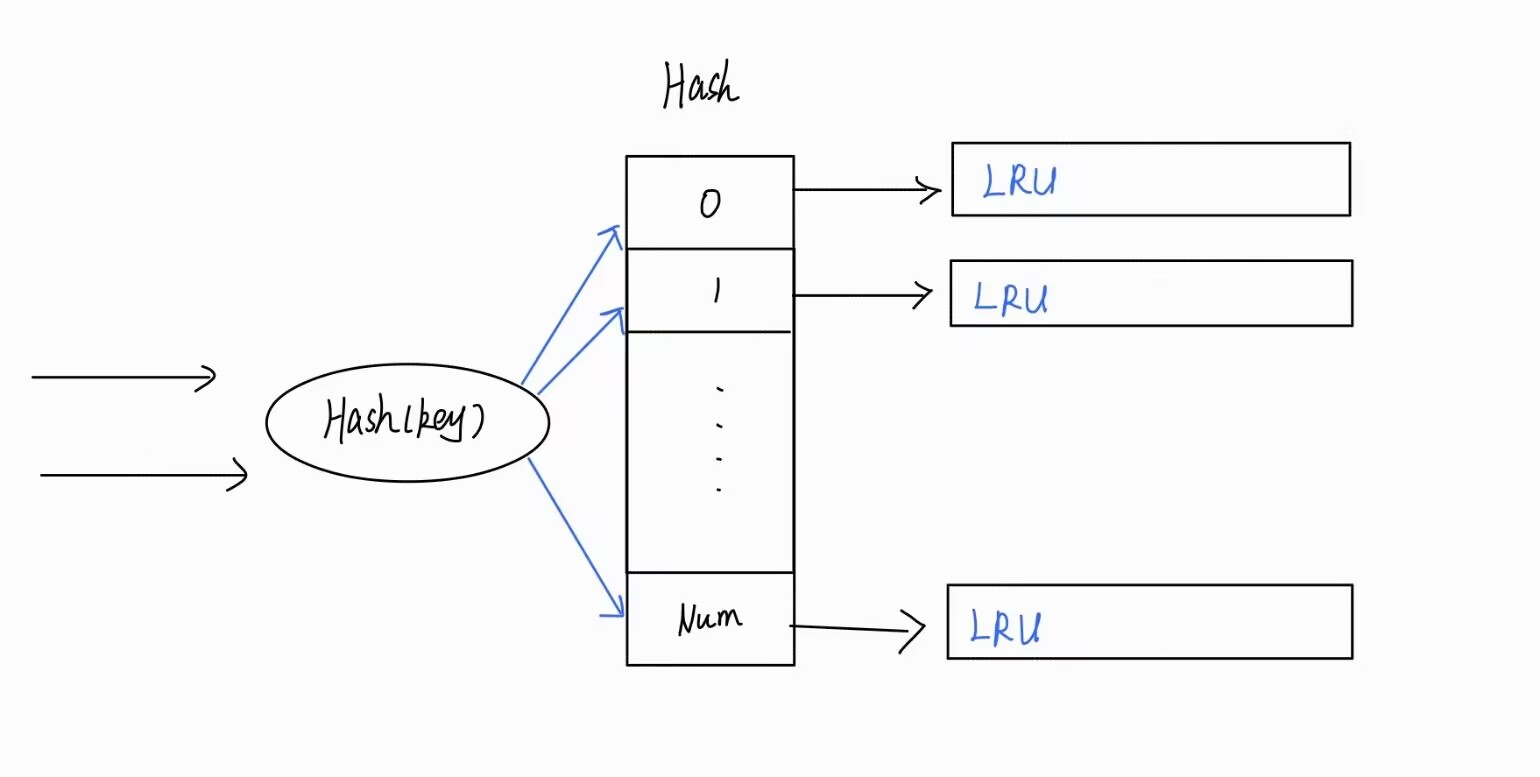
注意:LRU分片之后淘汰的元素就不是全局中访问最近最不经常访问的元素了,淘汰的就是局部最不经常访问的元素,这里是可以接受的,因为可能某个分片LRU(LFU)中存着大量元素,下一个元素还分给这个LRU(LFU)分片的话,就应该将当前的LRU(LFU)中最近最不经常访问的元素剔除而不是全局的最近最不经常访问元素,然后将新元素添加进来。