在Jetson部署AI语音家居助手(二):语音激活+语音转文字
前言
在jetson上搭建一个AI语音家居助手,主要需要四个部分的工作:
- 1️⃣获取麦克风输入,语音激活功能+语音转文字功能
- 2️⃣部署大语言模型理解转换后的文字输入 (本地推理或云推理)
- 3️⃣提取大模型推理文字结果后,执行文字转语音功能,播放推理结果
- 4️⃣根据推理结果,选择动作执行(控制家居设备)
本文主要完成1️⃣的搭建,2️⃣的搭建可以笔者之前的文章:
https://blog.csdn.net/Vingnir/article/details/149119735?spm=1001.2014.3001.5502
该部分功能的参考源码放在github仓库:
硬件构成
该部分主要有三个硬件构成;
Jetson主控- Orin NX 16g super,其他Orin系列产品也可。
麦克风- 四通道,单通道和双通道也可以,用于获取用户语音输入。
扬声器-USB接口或者其他接口都行,可以播放声音就行。
本人使用硬件如下:
主控:https://www.seeedstudio.com/reComputer-Super-J4012-p-6443.html

麦克风:https://www.seeedstudio.com/ReSpeaker-4-Mic-Array-for-Raspberry-Pi.htm
准备工作一
安装依赖:
sudo apt install nlohmann-json3-dev libcurl4-openssl-dev
sudo apt install mpg123
准备麦克风获取与语音激活程序:
git clone https://github.com/jjjadand/record-activate.git
然后根据你使用的硬件,以及使用情况修改程序中的参数。
根据你的麦克风参数修改respeaker.cpp的参数:
#define SAMPLE_RATE 44100 //44100hz or 16000hz
#define BIT_PER_SAMPLE 16
#define CHANNELS 2
#define FORMAT SND_PCM_FORMAT_S16_LE
#define RECORD_MS 20000 //最大录音时长
#define SLIENCE_MS 4000 //讲话结束静音时长判断阈值
#define ENERGY_VOICE 2000 //voice enegry threshold about active input
#define DEVICE_NAME "plughw:2,0" // 改为你的麦克风 device,hw:2,0兼容性不好,建议不要用
-
其中,
SAMPLE_RATE是麦克风的采样率,可以自行查看,大多麦克风都支持16000hz的采样率,或者支持多个采样率。 -
CHANNELS是录音的通道数量,一般和麦克风硬件有关,麦克风上有四个接收器则最大设置为4,两个接收器器则最大设置为2。一般有四个接收器的麦克风可以把采样率参数调高,把通道数设置为2。 -
FORMAT是每个采集的音频样本的编码格式,16表示16bit长度,常见还有32bit和8bit的长度,LE表示小端字节编排形式。 -
BIT_PER_SAMPLE是指每个采集的样本长度,要和FORMAT对应,SND_PCM_FORMAT_S16_LE则对应16 -
SLIENCE_MS参数如果设置得小,程序则认为较短时间的停顿就结束录音,设置得比较大,则停顿时间较长时才结束录音。 -
RECORD_MS用来限制最大录音的时间长度。 -
ENERGY_VOICE是一个激活阈值,当声音的能量低于阈值的时候,程序不会主动录音,当检测到某一帧的声音能量大于阈值后,程序才会开始录音。笔者程序中的计算方式为取某一帧的均值用于比较判断。 -
DEVICE_NAME为麦克风映射的设备名,可以用下面的指令查看:
arecord -l打印如下信息为例:
card 2: Array [reSpeaker XVF3800 4-Mic Array], device 0: USB Audio [USB Audio]Subdevices: 0/1Subdevice #0: subdevice #0表示映射为设备名plughw:2,0或hw:2,0
除此之外,voice_gate.hpp和respeaker.cpp的一个数据类型FORMAT参数进行修改:
typedef int16_t bit_per; //int16,对应SND_PCM_FORMAT_S16_LE
我们还需要在wav2text.cpp中设置扬声器的设备名:
const std::string device = "plughw:0,3"; // 对应 card 0, device 3
扬声器的映射设备名类似地也可以用下面指令查看:
aplay -l
笔者的扬声器接入到hdmi显示屏上,类似的输出如下:
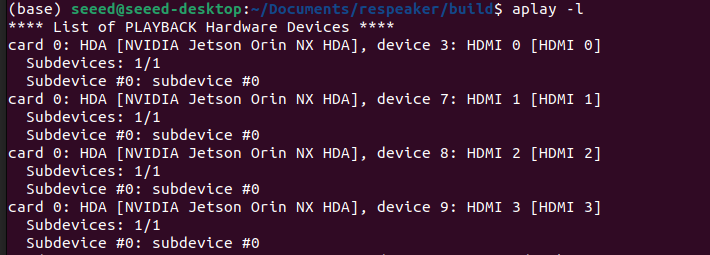
hdmi相关的有四个扬声器设备名映射,笔者都试了一下,最终确定有效映射为card 0, device 3
设置好这些基本参数后,我们再wav2text.cpp设置需要语音激活的关键词:
std::vector<std::string> keywords = {"hello", "Hello", "super", "Super"};
语音激活的关键词可以是一个或者多个。
完成设置后,进行编译:
cd build
cmake ..
make
编译完成后获取如下两个程序:

其中,wav2text程序需要依赖whisper语音转文字模型,whisper的部署和启用在下面的小节。
准备工作二,whisper部署
语音转文字的功能我们借助开源项目whisper完成。完成whisper的部署后,就可以实现语音激活,并且可以为大语言模型提供语音转文字的输入。
git clone项目, 并获取针对英语的语音转文字模型,笔者这里选用的是base大小规格的模型:
git clone https://github.com/ggml-org/whisper.cpp.git
cd whisper.cpp
sh ./models/download-ggml-model.sh base.en
更多其他规格和语音种类的模型可以查看:https://github.com/ggml-org/whisper.cpp/blob/master/models/README.md
编译项目并测试是否可用:
cmake -B build
cmake --build build -j --config Release# transcribe an audio file
./build/bin/whisper-cli -f samples/jfk.wav
编译完成后,在whisper项目文件夹下的build/bin路径对应的执行文件:
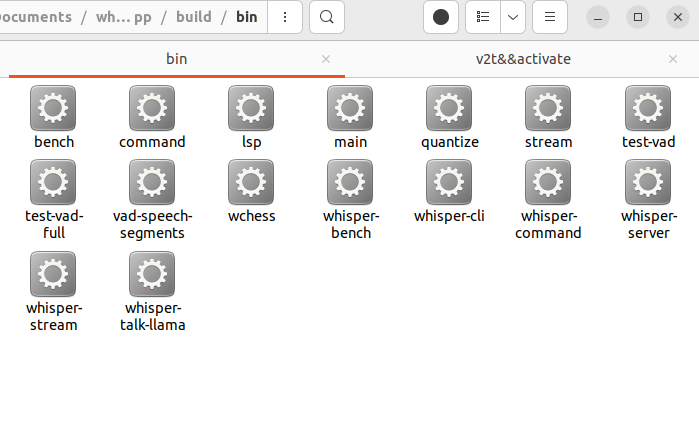
对模型进行量化,以提高推理速度:
./build/bin/quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
量化完成后的模型在whisper项目下的models文件夹:
完成语音激活+语音转文字
连接好硬件,基于准备工作一和准备工作二的程序,我们就可以完成语音转文字和语音激活的功能。
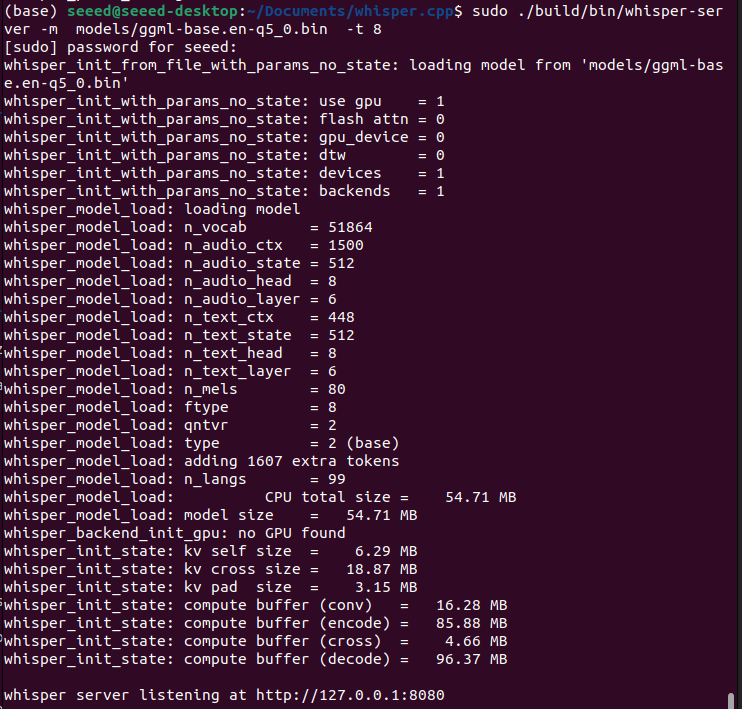
首先启动whisper的推理服务端,在whisper的项目路径下:
sudo ./build/bin/whisper-server -m models/ggml-base.en-q5_0.bin -t 8
不加入其他参数的情况下,默认请求推理地址和端口为“127.0.0.1:8080/inference”
-t 8表示启用八个线程。
启动语音转文字的本地服务后,运行(准备工作一)种编译好的wav2text程序:
pasuspender -- sudo ./wav2text
然后运行record_lite:
pasuspender -- sudo ./record_lite
运行的时候增加pasuspender选项是因为需要挂起PulseAudio,以便我们的程序后端可以直接访问ALSA设备,而不会被PulseAudio占用,避免音频设备冲突问题。
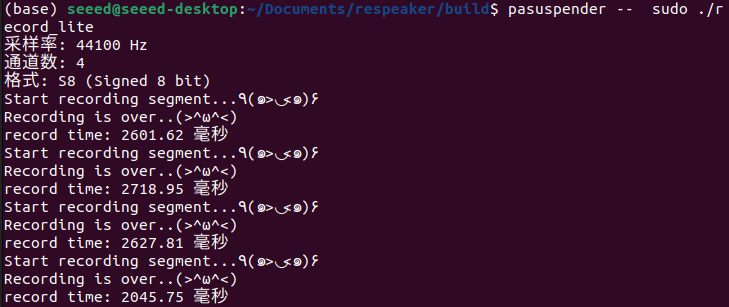
运行结果如下:
record_lite进程检测到声音能量大于阈值后开始录音,没有输入超过mute的时间阈值后结束录音:
wav2text完成语音转文字的请求,输出语音转文字结果,并进行语音激活检测,激活默认播放activate.mp3,可以替换为你想触发激活响应语音:
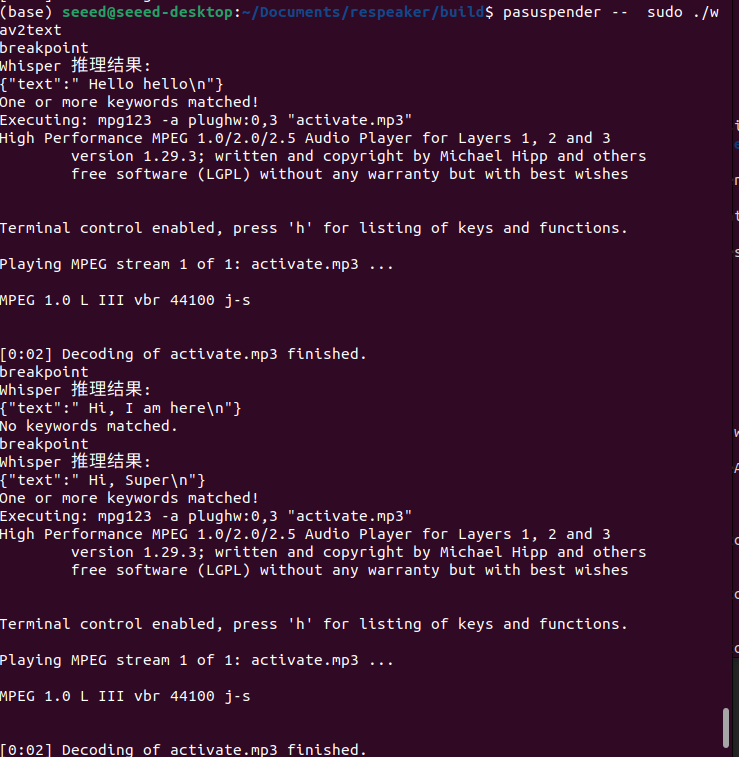
whisper-server完成语音转文字的推理请求,并把推理结果发送给wav2text:
总结
至此,我们完成了AI语音家居助手搭建的第二个模块,结合本地部署的大语言模型或云端的大语言模型,就实现一个雏形,剩下的工作就是action部分,并把大模型的输出整理后转为语音输出增加互动性。
附录
这里把主要的源码贴一下,如果访问不了github可以直接从这里复制:
------------respeaker.cpp------------⬇
#include <alsa/asoundlib.h>
#include <iostream>
#include <fstream>
#include <string>
#include <chrono>
#include <thread>#define SAMPLE_RATE 44100
#define BIT_PER_SAMPLE 16
#define CHANNELS 2
#define FORMAT SND_PCM_FORMAT_S16_LE
#define RECORD_MS 10000 //最大录音时长
#define SLIENCE_MS 2000 //讲话结束静音时长判断阈值
#define DEVICE_NAME "plughw:2,0" // 改为你的麦克风 device,hw:2,0兼容性不好,建议不要用typedef int16_t bit_per;#include "voice_gate.hpp"std::ofstream wavFile;
size_t totalBytes = 0;unsigned int sample_rate = SAMPLE_RATE;
int dir;
snd_pcm_format_t format;
unsigned int channels = 4;void write_wav_header(std::ofstream &file, int sample_rate, int num_channels, int bits_per_sample) {char header[44] = {0};int16_t audio_format = 1; // PCMint32_t byte_rate = sample_rate * num_channels * bits_per_sample / 8;int16_t block_align = num_channels * bits_per_sample / 8;// RIFF chunkmemcpy(header, "RIFF", 4);*(int32_t*)(header + 4) = 0; // Placeholder for file sizememcpy(header + 8, "WAVE", 4);// fmt subchunkmemcpy(header + 12, "fmt ", 4);*(int32_t*)(header + 16) = 16; // Subchunk1Size for PCM*(int16_t*)(header + 20) = audio_format;*(int16_t*)(header + 22) = num_channels;*(int32_t*)(header + 24) = sample_rate;*(int32_t*)(header + 28) = byte_rate;*(int16_t*)(header + 32) = block_align;*(int16_t*)(header + 34) = bits_per_sample;// data subchunkmemcpy(header + 36, "data", 4);*(int32_t*)(header + 40) = 0; // Placeholder for data sizefile.write(header, 44);
}void finalize_wav(std::ofstream &file, size_t dataBytes) {file.seekp(4, std::ios::beg);int32_t fileSize = 36 + dataBytes;file.write(reinterpret_cast<char*>(&fileSize), 4);file.seekp(40, std::ios::beg);file.write(reinterpret_cast<char*>(&dataBytes), 4);
}int main() {snd_pcm_t *pcm_handle;snd_pcm_hw_params_t *params;int dir;int rc = -1;rc = snd_pcm_open(&pcm_handle, DEVICE_NAME, SND_PCM_STREAM_CAPTURE, 0);if (rc < 0) {std::cerr << "Unable to open PCM device: " << snd_strerror(rc) << std::endl;return 1;}// 分配参数结构snd_pcm_hw_params_malloc(¶ms);snd_pcm_hw_params_any(pcm_handle, params);// 获取采样率snd_pcm_hw_params_get_rate(params, &sample_rate, &dir);std::cout << "采样率: " << sample_rate << " Hz" << std::endl;// 获取通道数snd_pcm_hw_params_get_channels(params, &channels);std::cout << "通道数: " << channels << std::endl;// 获取音频格式snd_pcm_hw_params_get_format(params, &format);std::cout << "格式: " << snd_pcm_format_name(format)<< " (" << snd_pcm_format_description(format) << ")" << std::endl;//config the PCM_handlesnd_pcm_hw_params_set_access(pcm_handle, params, SND_PCM_ACCESS_RW_INTERLEAVED);snd_pcm_hw_params_set_format(pcm_handle, params, FORMAT);snd_pcm_hw_params_set_channels(pcm_handle, params, CHANNELS);snd_pcm_hw_params_set_rate(pcm_handle, params, sample_rate, 0);snd_pcm_hw_params(pcm_handle, params);snd_pcm_hw_params_free(params);snd_pcm_prepare(pcm_handle);int buffer_frames = 1024 * 2; // bit_per* buffer = new bit_per[buffer_frames](); //强制零初始化int buffer_l_frames = 1024 ; // bit_per* buffer_l = new bit_per[buffer_l_frames * CHANNELS](); //强制零初始化//int16_t* buffer = (int16_t*) aligned_alloc(16, buffer_frames * sizeof(int16_t));//memset(buffer, 0, buffer_frames * sizeof(int16_t));std::string filename = "respeaker_output.wav";//实例化输入声响阈值VoiceGate gate(/*energyThresh*/ 500, //单帧能量阈值/*silenceMs */ RECORD_MS,/*sampleRate */ SAMPLE_RATE,/*frameSamples*/ buffer_l_frames * CHANNELS);size_t total_samples = SAMPLE_RATE * RECORD_MS/1000;size_t recorded_samples = 0;while(true){rc = snd_pcm_readi(pcm_handle, buffer_l, buffer_l_frames);if (rc < 0) continue;if (rc > buffer_l_frames) {std::cerr << "rc = " << rc << " exceeds buffer_frames = " << buffer_frames << std::endl;continue;}if(rc >0 ){//printf("Read %d frames from PCM device.\n", rc);gate.update(buffer_l, rc * CHANNELS);}bool enable = false;if(gate.startSegment()) {std::cout << "Start recording segment...٩(๑>◡<๑)۶" << std::endl; if (wavFile.is_open()) wavFile.close();wavFile.open(filename, std::ios::binary);write_wav_header(wavFile, SAMPLE_RATE, CHANNELS, BIT_PER_SAMPLE); // 32-bit PCMwavFile.write(reinterpret_cast<char*>(buffer_l), rc * CHANNELS * sizeof(bit_per));recorded_samples += rc;totalBytes += rc * sizeof(bit_per);while((recorded_samples < total_samples)&&(gate.stopSegment() == false)){//printf("breakpoint\n" );if(enable == true){rc = snd_pcm_readi(pcm_handle, buffer_l, buffer_l_frames);}enable = true;gate.update(buffer_l, rc * CHANNELS);if (rc == -EPIPE) {std::cerr << "Overrun occurred" << std::endl;snd_pcm_prepare(pcm_handle);continue;} else if (rc < 0) {std::cerr << "Error reading: " << snd_strerror(rc) << std::endl;break;}//wavFile.write((char *)buffer_l, rc * CHANNELS * sizeof(bit_per));wavFile.write(reinterpret_cast<char*>(buffer_l), rc * CHANNELS * sizeof(bit_per));recorded_samples += rc;totalBytes += rc * CHANNELS * sizeof(bit_per);}std::cout << "Recording is over..(>^ω^<)" << std::endl;recorded_samples = 0;finalize_wav(wavFile, totalBytes);wavFile.close();//free(buffer);totalBytes = 0;}}snd_pcm_drain(pcm_handle);snd_pcm_close(pcm_handle);delete[] buffer;delete[] buffer_l;std::cout << "Saved to " << filename << std::endl;return 0;
}------------voice_gate.hpp------------⬇
#ifndef VOICE_GATE_HPP
#define VOICE_GATE_HPP#include <stdio.h>
#include <cstdint>
#include <cmath>typedef int16_t bit_per; // feed one frame class VoiceGate {
public:VoiceGate(double energyThresh, // e.g. 800int silenceMs, // e.g. 1000 int sampleRate, // e.g. 16000int frameSamples) // e.g. : THRESH(energyThresh),SILENCE_LIMIT_FRAMES((silenceMs * sampleRate) / (1000 * frameSamples)),samplesPerFrame(frameSamples) {}void update(const bit_per* data, int len) {double e = rmsEnergy(data, len);double log_sound = e;//printf("this frame e is %lf\n",log_sound);if (state == Standby) {if (e > THRESH) { // speech startsstate = Recording;silenceCtr = 0;started = true;stopped = false;}} else { // Recordingif (e > THRESH) {re_mute = true;silenceCtr = 0; // still speech} else {if(re_mute = true){start_time = std::chrono::high_resolution_clock::now();re_mute = false;}++silenceCtr;if((silenceCtr > SILENCE_LIMIT_FRAMES)){state = Standby; // speech endedstarted =false;stopped = true;auto over_time = std::chrono::high_resolution_clock::now();std::chrono::duration<double, std::milli> duration_ms = over_time - start_time;//std::cout << "mute time: " << duration_ms.count() << " 毫秒" << std::endl;}}}}bool isRecording() const { return state == Recording; }bool startSegment() { bool f = started; started = false; return f; }bool stopSegment() { bool f = stopped; return f; }private:enum { Standby, Recording } state = Standby;const float THRESH;const int SILENCE_LIMIT_FRAMES;const int samplesPerFrame;int silenceCtr = 0;bool started = false;bool stopped = false;bool re_mute = true;std::chrono::time_point<std::chrono::_V2::system_clock, std::chrono::_V2::system_clock::duration> start_time;double rmsEnergy(const bit_per* buf, int len) const {double sum = 0.0f;bit_per tmp_data = 0;len > (samplesPerFrame)? len = (samplesPerFrame) : len = len; for (int i = 0; i < len; ++i){if (buf[i] < -2147483648 || buf[i] > 2147483647) {fprintf(stderr, "Error: Sample value out of range: %d\n", buf[i]);return 0.0; // Return 0 if sample is out of range}tmp_data = abs(buf[i]); // Ensure the value is non-negativesum += tmp_data;//printf("buf[%d] is %d\n", i, buf[i]);}double ave = sum / len;return ave;}
};
#endif ------------shared_state.h------------⬇
// shared_state.h
#ifndef SHARED_STATE_H
#define SHARED_STATE_Henum class VoiceState {RECORDED,RECORDING,DECODE,PLAYING,RESTART,INIT
};#endif------------wav2text.cpp------------⬇
#include <iostream>
#include <fstream>
#include <unistd.h>
#include <string>
#include <fcntl.h>
#include <sys/stat.h> // for mkfifo
#include <sys/types.h> // for mode_t
#include <string>
#include <chrono>
#include <thread>
#include <curl/curl.h>
#include <nlohmann/json.hpp>#include "shared_state.h"
using json = nlohmann::json;// 用于保存返回数据
static size_t WriteCallback(void *contents, size_t size, size_t nmemb, void *userp) {((std::string*)userp)->append((char*)contents, size * nmemb);return size * nmemb;
}std::string transcribe_audio(const std::string& filepath) {CURL *curl;CURLcode res;std::string readBuffer;curl_mime *form = nullptr;curl_mimepart *field = nullptr;curl_global_init(CURL_GLOBAL_ALL);curl = curl_easy_init();if(curl) {form = curl_mime_init(curl);// 添加 WAV 文件field = curl_mime_addpart(form);curl_mime_name(field, "file");curl_mime_filedata(field, filepath.c_str());// 设置 response_format = jsonfield = curl_mime_addpart(form);curl_mime_name(field, "response_format");curl_mime_data(field, "json", CURL_ZERO_TERMINATED);curl_easy_setopt(curl, CURLOPT_URL, "http://127.0.0.1:8080/inference");curl_easy_setopt(curl, CURLOPT_MIMEPOST, form);// 设置回调函数保存返回内容curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);curl_easy_setopt(curl, CURLOPT_WRITEDATA, &readBuffer);// 执行请求res = curl_easy_perform(curl);// 检查错误if(res != CURLE_OK)std::cerr << "curl_easy_perform() failed: " << curl_easy_strerror(res) << std::endl;curl_mime_free(form);curl_easy_cleanup(curl);}curl_global_cleanup();return readBuffer;
}bool contains_keywords(const std::string& text, const std::vector<std::string>& keywords) {for (const auto& keyword : keywords) {if (text.find(keyword) != std::string::npos) {return true; // Keyword found}}return false; // No keyword found
}int main() {mkfifo("/tmp/state_pipe2", 0666); // 创建命名管道int pipe_fd = open("/tmp/state_pipe", O_RDONLY | O_NONBLOCK);int pipe_ba = open("/tmp/state_pipe2", O_WRONLY | O_NONBLOCK );VoiceState state = VoiceState::INIT;VoiceState state_ba = VoiceState::INIT;while(1){read(pipe_fd, &state, sizeof(state));if(state == VoiceState::RECORDED){printf("breakpoint\n");state_ba = VoiceState::DECODE;write(pipe_ba, &state_ba, sizeof(state_ba));std::string result_json = transcribe_audio("respeaker_output.wav");std::cout << "Whisper 推理结果:\n" << result_json << std::endl;// Parse JSONnlohmann::json j = nlohmann::json::parse(result_json);std::string text = j["text"];// Define multiple keywordsstd::vector<std::string> keywords = {"hello", "Hello", "super", "Super"};//delete respeaker_output.wav// Check if any of the keywords are found in the textif (contains_keywords(text, keywords)) {std::cout << "One or more keywords matched!" << std::endl;const std::string device = "plughw:0,3"; // 对应 card 0, device 3const std::string file = "activate.mp3";std::string cmd = "mpg123 -a " + device + " \"" + file + "\"";std::cout << "Executing: " << cmd << std::endl;int ret = system(cmd.c_str());if (ret != 0) {std::cerr << "mpg123 playback failed!" << std::endl;}state_ba = VoiceState::RESTART;write(pipe_ba, &state_ba, sizeof(state_ba));} else {std::cout << "No keywords matched." << std::endl;state_ba = VoiceState::RESTART;write(pipe_ba, &state_ba, sizeof(state_ba));}}}close(pipe_fd);close(pipe_ba);return 0;
}