2-大语言模型—理论基础:详解Transformer架构的实现(2)
目录
1-大语言模型—理论基础:详解Transformer架构的实现(1)-CSDN博客https://blog.csdn.net/wh1236666/article/details/149443139?spm=1001.2014.3001.5502
2.3、残差连接和层归一化
2.3.1、什么是层归一化?
2.3.2、层归一化的核心特点(与其他归一化对比)
2.3.3、特此说明
2.4、编码器和解码器结构
2.4.1、 编码器和解码器到底是什么?
2.4.1.1、编码器:负责 “看懂原文” 的翻译官
2.4.1.2、解码器:负责 “写出译文” 的秘书
2.4.1.3、总结:俩模块的核心作用
2.4.2、编码器(Encoder)
2.4.2.1、 整体结构
2.4.2.2、运算流程
2.4.2.3、核心机制:自注意力(Self-Attention)
2.4.3、解码器(Decoder)
2.4.3.1、 整体结构
2.4.3.2、 运算流程
2.4.3.3、 核心机制:掩码与交叉注意力
2.4.4、编码器与解码器的协作
2.4.5、完整代码
2.5、Transformer整体逻辑
2.5.1、先看 “团队架构”:编码器与解码器的核心组件
2.5.2、编码器:用 “工具包” 把原文 “嚼碎成浓缩信息”
2.5.2.1、 多头自注意力:像 “读句子时同时抓多维度关系”
2.5.2.2、 前馈网络:像 “基于关系提炼深层含义”
3. 残差连接 + 层归一化:像 “保持思路清晰,不混乱”
2.5.3、解码器:用 “工具包” 把 “笔记” 变成 “通顺译文”
2.5.3.1、 掩码多头自注意力:像 “写句子时只看自己已经写的内容”
2.5.3.2、 编码器 - 解码器注意力:像 “写译文时回头看原文笔记”
2.5.3.3、前馈网络 + 残差连接 + 层归一化:和编码器的作用一致
2.5.4、编码器与解码器的 “协作全流程”(以翻译为例)
2.5.5、总结:为什么这套组合能 “超越传统模型”?
2.6、完整代码
2.6.1、Transforemers实现代码
2.6.2、与LSTM对比实现代码
2.7、实验效果
2.7.1、Transforemers实验效果
2.7.2、与LSTM对比实验效果
前文:
1-大语言模型—理论基础:详解Transformer架构的实现(1)-CSDN博客 https://blog.csdn.net/wh1236666/article/details/149443139?spm=1001.2014.3001.5502
https://blog.csdn.net/wh1236666/article/details/149443139?spm=1001.2014.3001.5502
2.3、残差连接和层归一化
2.3.1、什么是层归一化?
层归一化的核心思想是:对单个样本在某一层的所有特征(或隐藏单元)进行归一化,让这些特征的分布保持稳定(均值接近 0,方差接近 1),再通过可学习的参数进行缩放和平移,保留数据的原始特征信息。
具体计算步骤:
假设某一层的输入为向量(d 为特征维度),层归一化的计算过程如下:
- 计算均值:计算该向量所有元素的均值
- 计算方差:计算该向量所有元素的方差
- 归一化:用均值和方差对原始数据进行标准化,消除量纲差异
是一个极小值,避免分母为 0)
- 缩放和平移:通过可学习的参数
(缩放因子)和 \(\beta\)(偏移因子)调整归一化后的数据,保留原始特征的表达能力
2.3.2、层归一化的核心特点(与其他归一化对比)
为了更好理解层归一化,我们可以与常用的批归一化(Batch Normalization,BN) 对比:
| 特性 | 层归一化(LN) | 批归一化(BN) |
|---|---|---|
| 归一化维度 | 单个样本的所有特征(特征维度) | 批次中所有样本的同一特征(批次维度) |
| 依赖 “批次” 吗? | 不依赖,单个样本独立计算 | 依赖,需基于整个批次的样本计算 |
| 适用场景 | 序列模型(RNN、Transformer)、小批量数据 | 卷积神经网络(CNN)、大批量数据 |
层归一化是一种针对 “单个样本特征” 的归一化技术,其核心价值在于:不依赖批次、适配序列模型、稳定训练并加速收敛。
2.3.3、特此说明
Transformer 模型中,层归一化是核心组件之一,它被用于多头注意力层和前馈网络的输入,确保了模型在处理长序列时的稳定性。
具体来说,在 Transformer 中,层归一化的应用场景和作用可以更细致地拆解:
-
多头注意力层的输入与输出:在多头注意力机制计算前,会先对输入的特征向量进行层归一化,确保每个头的注意力计算在稳定的数据分布上进行;而注意力层的输出也会与输入进行残差连接后,再通过层归一化处理,避免特征值因多次叠加而过大或分布失衡,保证后续前馈网络能高效学习。
-
前馈网络的输入:经过注意力层和残差连接、层归一化后的数据,会作为前馈网络的输入。此时的层归一化同样起到 “校准” 作用,让前馈网络(由两个线性层和激活函数组成)在处理特征时,无需适配波动剧烈的数据分布,从而更专注于学习特征间的非线性关系。
这种 “注意力层 + 层归一化 + 残差连接→前馈网络 + 层归一化 + 残差连接” 的模块化设计,是 Transformer 能处理超长序列(如长文本、长视频帧)的重要保障。如果没有层归一化,随着网络深度增加(Transformer 通常有十几到几十层),特征分布会逐渐偏移甚至 “爆炸”,导致模型难以训练或性能骤降。
2.3.4、完整代码
"""
文件名: 2.1 transformer
作者: 墨尘
日期: 2025/7/18
项目名: LLM
备注:
"""import numpy as np
import math
import torch
from sympy.abc import q
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt # 用于可视化注意力权重热图下·
import torch
import torch.nn as nn
import math
import torch.nn.functional as F# -------------------------- 2. 残差连接 + 层规范化(AddNorm) --------------------------
# 作用:Transformer中每个子层(注意力/前馈网络)的标配输出处理,解决深层网络训练难题
# 核心逻辑:通过残差连接保留原始信息,通过层规范化稳定特征分布,使模型可训练数百层
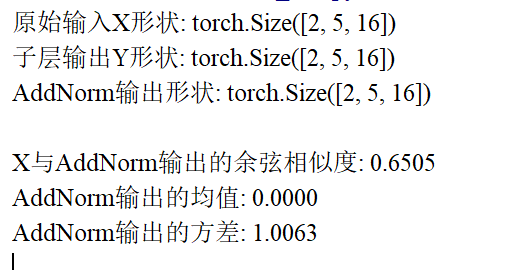
class AddNorm(nn.Module):"""残差连接后进行层规范化(Transformer子层输出的标准处理)"""def __init__(self, normalized_shape, dropout, **kwargs):"""初始化参数参数详解:normalized_shape: 层规范化的维度(通常为输入特征的最后一维,如[seq_len, feature_dim])dropout: Dropout概率(随机丢弃部分特征,防止过拟合)"""super(AddNorm, self).__init__(** kwargs)self.dropout = nn.Dropout(dropout) # Dropout层,仅作用于子层输出(保护原始输入)self.ln = nn.LayerNorm(normalized_shape) # 层规范化层(对每个样本独立归一化,适合序列数据)def forward(self, X, Y):"""前向传播:先残差连接,再层规范化参数:X: 子层的原始输入张量(形状与Y必须一致,否则无法相加)Y: 子层(如注意力机制/前馈网络)的输出张量返回:经过处理的张量(形状与X/Y一致,特征分布更稳定)"""# 步骤解析:# 1. 对Y应用Dropout:随机丢弃部分特征,防止模型过度依赖子层输出# 2. 残差连接(X + dropout(Y)):保留原始输入信息,缓解梯度消失(若Y无效,输出≈X)# 3. 层规范化:对每个样本计算均值和方差,将特征缩放到标准分布,加速训练return self.ln(self.dropout(Y) + X)def main():# 设置参数batch_size = 2 # 批次大小seq_len = 5 # 序列长度feature_dim = 16 # 特征维度(与 normalized_shape 对应)dropout = 0.1 # Dropout概率# 初始化AddNorm层add_norm = AddNorm(normalized_shape=feature_dim, dropout=dropout)# 创建模拟输入:X是子层原始输入,Y是子层输出X = torch.randn(batch_size, seq_len, feature_dim) # 原始输入Y = torch.randn(batch_size, seq_len, feature_dim) # 子层(如注意力/前馈网络)输出# 应用AddNorm处理output = add_norm(X, Y)# 验证形状一致性print(f"原始输入X形状: {X.shape}")print(f"子层输出Y形状: {Y.shape}")print(f"AddNorm输出形状: {output.shape}") # 应与输入形状一致# 验证残差连接效果:输出与输入的差异应受Y影响# 计算X和output的相似度(应低于1.0,说明Y起作用)x_flat = X.flatten()output_flat = output.flatten()similarity = torch.cosine_similarity(x_flat.unsqueeze(0), output_flat.unsqueeze(0)).item()print(f"\nX与AddNorm输出的余弦相似度: {similarity:.4f}") # 应显著小于1.0# 验证层规范化效果:输出特征的均值应接近0,方差接近1mean = output.mean().item()var = output.var().item()print(f"AddNorm输出的均值: {mean:.4f}") # 应接近0print(f"AddNorm输出的方差: {var:.4f}") # 应接近1# 可视化处理前后的特征分布plt.figure(figsize=(10, 4))# 原始输入X的特征分布plt.subplot(1, 2, 1)plt.hist(X.flatten().detach().numpy(), bins=20, alpha=0.7, label='原始输入X')plt.axvline(X.mean().item(), color='r', linestyle='--', label=f'均值: {X.mean().item():.2f}')plt.title('原始输入特征分布')plt.legend()# AddNorm输出的特征分布plt.subplot(1, 2, 2)plt.hist(output.flatten().detach().numpy(), bins=20, alpha=0.7, label='AddNorm输出')plt.axvline(output.mean().item(), color='r', linestyle='--', label=f'均值: {mean:.2f}')plt.title('AddNorm处理后的特征分布')plt.legend()plt.tight_layout()plt.show()if __name__ == "__main__":main()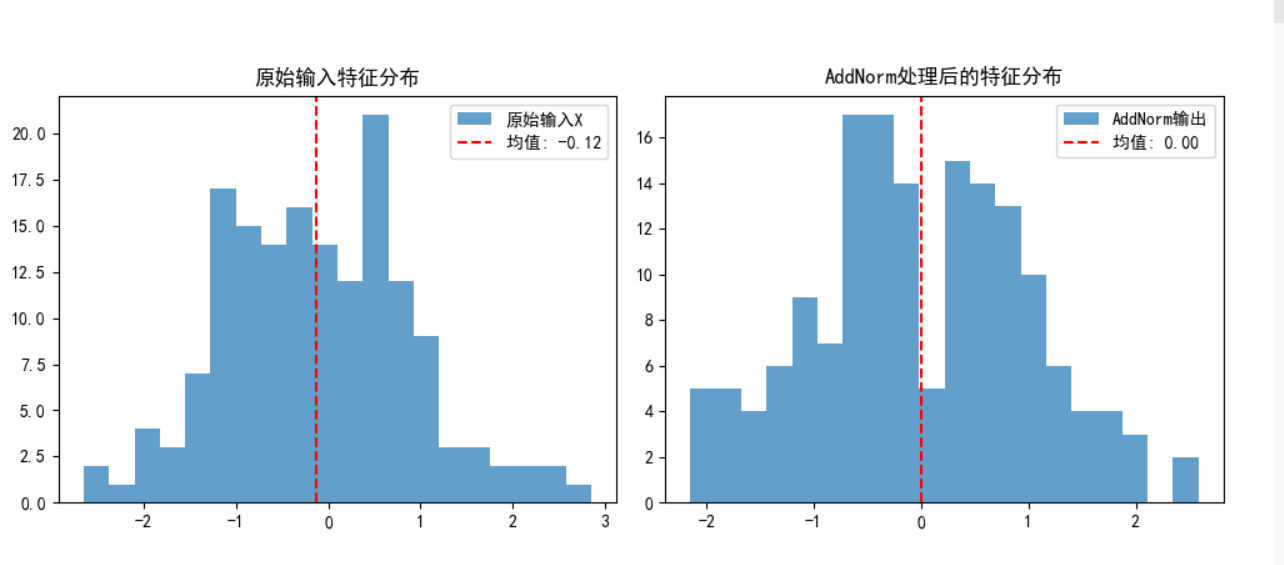
通过直方图直观对比处理前后的特征分布,层规范化后的分布应更集中、波动更小。
2.4、编码器和解码器结构
2.4.1、 编码器和解码器到底是什么?
咱们可以把编码器和解码器想象成两个人合作完成一项 “转换任务”,比如把中文翻译成英文,这样就很好理解了:
2.4.1.1、编码器:负责 “看懂原文” 的翻译官
假设你要把一句中文 “我爱吃苹果” 翻译成英文,编码器就像第一个翻译官,他的工作是彻底理解这句话的意思。
- 他先看到每个字:“我”“爱”“吃”“苹果”。
- 然后他会分析这些字的关系:“我” 是主语,“爱” 是谓语,“吃苹果” 是宾语,整个句子说的是 “主语喜欢做‘吃苹果’这件事”。
- 最后,他把这些信息整理成一份 “笔记”(专业上叫 “上下文向量”),里面不光有每个字的意思,还有它们之间的联系(谁和谁相关,谁修饰谁)。
这份笔记会交给解码器,相当于说:“我已经把原文吃透了,接下来看你的了!”
2.4.1.2、解码器:负责 “写出译文” 的秘书
解码器就像第二个角色,他的工作是根据编码器的 “笔记”,一句一句写出正确的英文。
- 他一开始不知道要写什么,先从一个 “开始信号”(比如
<START>)入手。 - 看到 “开始信号”,再对照编码器的笔记(知道原文是 “我爱吃苹果”),先写出第一个词 “I”。
- 写完 “I” 之后,他会回头看看自己刚写的 “I”,再对照笔记,接着写出 “like”(因为原文是 “爱”)。
- 然后再根据已经写的 “I like” 和笔记,写出 “eating”(对应 “吃”)。
- 最后写出 “apples”(对应 “苹果”),直到写出 “结束信号”(比如
<END>),整个翻译就完成了。
这里有个关键点:解码器写的时候不能 “作弊”,比如写 “I” 的时候,不能提前偷看后面要写的 “like”,只能用自己已经写过的内容,保证句子通顺(这就是 “掩码自注意力” 的作用)。
2.4.1.3、总结:俩模块的核心作用
- 编码器:把输入的序列(句子、语音、图像等)“嚼碎”,提取出所有关键信息和内部关系,变成一份 “浓缩的理解笔记”。
- 解码器:拿着这份 “笔记”,从无到有地生成目标序列,并且保证生成的内容既符合原文意思,又符合目标语言的逻辑(比如语法、顺序)。
就像两个人合作:一个负责 “读懂题意”,一个负责 “写出答案”,缺一不可~
2.4.2、编码器(Encoder)
编码器负责处理输入序列(如源语言句子),将其转换为隐藏表示(特征向量),以便解码器能够理解并生成对应的输出。
2.4.2.1、 整体结构
Transformer 的编码器由 N 个相同的编码层(Encoder Layer) 堆叠而成,每个编码层包含两个子层:
- 多头自注意力层(Multi-Head Self-Attention):捕获输入序列内部的依赖关系(如句子中词语之间的关联)。
- 前馈神经网络(Feed Forward Network):对注意力层的输出进行非线性变换,增强模型表达能力。
每层之后还应用了残差连接(Residual Connection)和层归一化(Layer Normalization),以稳定训练和防止梯度消失。
2.4.2.2、运算流程
以单个编码层为例,其运算步骤如下:
输入:X(上一层的输出,初始为嵌入向量+位置编码)1. 自注意力子层:- 对X进行线性变换,得到查询(Q)、键(K)、值(V)三个矩阵- 计算注意力得分:Attention(Q, K, V) = softmax(Q·Kᵀ/√dₖ)·V- 多头机制:将注意力计算分为多个“头”并行处理,再拼接结果- 残差连接:X₁ = X + MultiHead(Q, K, V)- 层归一化:X₁ = LayerNorm(X₁)2. 前馈网络子层:- 线性变换+ReLU激活:FFN(X₁) = max(0, X₁·W₁ + b₁)·W₂ + b₂- 残差连接:X₂ = X₁ + FFN(X₁)- 层归一化:X₂ = LayerNorm(X₂)输出:X₂(作为下一层的输入)
2.4.2.3、核心机制:自注意力(Self-Attention)
自注意力是编码器的关键创新,允许模型关注输入序列的不同部分来生成当前位置的表示。其核心公式为:
- Q, K, V 分别是查询(Query)、键(Key)、值(Value)矩阵,通过输入 X 线性变换得到。
是缩放因子,防止点积结果过大导致梯度消失。
- 多头注意力将输入分割为多个头,并行计算注意力,捕获不同子空间的信息。
2.4.3、解码器(Decoder)
解码器根据编码器的输出和已生成的部分输出,逐步生成目标序列(如翻译后的句子)。
2.4.3.1、 整体结构
Transformer 的解码器同样由N 个相同的解码层(Decoder Layer)堆叠而成,但每个解码层包含三个子层:
- 掩码多头自注意力层(Masked Multi-Head Self-Attention):与编码器类似,但使用掩码(Mask)防止看到未来位置的信息(确保生成时只依赖已生成的内容)。
- 编码器 - 解码器注意力层(Encoder-Decoder Attention):关注编码器输出的相关部分,建立输入与输出的关联。
- 前馈神经网络(Feed Forward Network):与编码器相同,增强模型表达能力。
每层之后同样应用残差连接和层归一化。
2.4.3.2、 运算流程
以单个解码层为例,其运算步骤如下:
输入:Y(上一层的输出,初始为目标序列的嵌入向量+位置编码)Encoder Output(编码器的最终输出)1. 掩码自注意力子层:- 对Y进行线性变换,得到Q、K、V矩阵- 应用掩码:在注意力得分计算中,将未来位置的得分设为负无穷(softmax后为0)- 计算注意力:Attention(Q, K, V) = softmax(Q·Kᵀ/√dₖ)·V- 残差连接:Y₁ = Y + MaskedMultiHead(Y)- 层归一化:Y₁ = LayerNorm(Y₁)2. 编码器-解码器注意力子层:- 解码器的Q来自Y₁,K和V来自编码器输出- 计算注意力:Attention(Q, K, V) = softmax(Q·Kᵀ/√dₖ)·V- 残差连接:Y₂ = Y₁ + MultiHead(Y₁, Encoder Output, Encoder Output)- 层归一化:Y₂ = LayerNorm(Y₂)3. 前馈网络子层:- 与编码器相同:FFN(Y₂) = max(0, Y₂·W₁ + b₁)·W₂ + b₂- 残差连接:Y₃ = Y₂ + FFN(Y₂)- 层归一化:Y₃ = LayerNorm(Y₃)输出:Y₃(作为下一层的输入)
2.4.3.3、 核心机制:掩码与交叉注意力
- 掩码(Mask):确保解码器在生成第 t 个位置的输出时,只关注 1 到 \(t-1\) 位置的输入,避免信息泄露。
- 编码器 - 解码器注意力:解码器通过查询(Q)关注编码器输出的不同部分,建立源序列与目标序列的对齐关系(如机器翻译中词语的对应关系)。
2.4.4、编码器与解码器的协作
在完整的 Transformer 模型中,编码器和解码器的协作流程如下:
-
编码阶段:
- 输入序列经过词嵌入和位置编码后,进入编码器
- 编码器逐层处理,生成最终的编码表示(上下文向量)
-
解码阶段(自回归生成):
- 解码器从起始标记(如
<START>)开始,每次生成一个词 - 当前已生成的序列作为解码器的输入,结合编码器输出,预测下一个词
- 重复此过程,直到生成结束标记(如
<END>)或达到最大长度
- 解码器从起始标记(如
2.4.5、完整代码
后面一次给出包含实验结果
2.5、Transformer整体逻辑
要理解 Transformer 中编码器与解码器的完整协作逻辑,我们可以用一个具体场景贯穿始终:把中文 “小明在公园给小红送了一本他昨天买的书” 翻译成英文。这个过程中,编码器和解码器就像两个精密配合的 “翻译团队”,各自带着一套 “工具包”(组件),分工协作完成从 “理解原文” 到 “生成译文” 的全流程。
2.5.1、先看 “团队架构”:编码器与解码器的核心组件
不管是编码器还是解码器,都遵循 “多层堆叠” 的设计(原论文中各堆了 6 层),每一层类似一个 “处理单元”。但因为两者任务不同(编码器 “理解输入”,解码器 “生成输出”),“工具包” 略有差异:
| 模块 | 编码器每层包含 | 解码器每层包含 | 核心目标 |
|---|---|---|---|
| 注意力机制 | 多头自注意力(Self-Attention) | 1. 掩码多头自注意力(Masked Self-Attention) 2. 编码器 - 解码器注意力(Encoder-Decoder Attention) | 捕捉 “关系”(输入内部 / 生成序列内部 / 输入与生成的关系) |
| 特征加工 | 前馈网络(Feed-Forward Network) | 前馈网络(Feed-Forward Network) | 深化单个位置的特征(从关系中提炼抽象含义) |
| 稳定机制 | 残差连接(Add)+ 层归一化(LayerNorm) | 残差连接(Add)+ 层归一化(LayerNorm) | 保证多层堆叠时训练稳定,信息传递不 “跑偏” |
2.5.2、编码器:用 “工具包” 把原文 “嚼碎成浓缩信息”
编码器的任务是把输入的中文句子 “嚼碎”,提炼出所有关键信息(谁、做了什么、关系如何),最终输出一个 “浓缩的理解向量”(称为 “编码器输出” 或 “上下文向量”)。它的 “工具包” 是这样工作的:
2.5.2.1、 多头自注意力:像 “读句子时同时抓多维度关系”
面对 “小明在公园给小红送了一本他昨天买的书”,编码器需要同时理清:
- 主体与对象:“小明”→“小红”(动作 “送” 的双方);
- 动作与对象:“送”→“书”(送的是书);
- 指代关系:“他”→“小明”(避免混淆);
- 修饰关系:“他昨天买的”→“书”(书的来源)。
多头自注意力就是干这个的:
- 每个 “头” 是一个独立的 “关系探测器”:有的头专注抓 “谁对谁做了什么”,有的头抓 “指代关系”,有的头抓 “修饰关系”;
- 最后把所有头的结果拼接起来,得到一个 “全方位的关系图谱”—— 每个词的表示都融入了和其他词的关联信息(比如 “书” 的表示里不仅有 “书” 本身,还有 “小明买的”“送给小红” 这些信息)。
2.5.2.2、 前馈网络:像 “基于关系提炼深层含义”
光有表面关系还不够,需要进一步提炼抽象信息。比如:
- 从 “小明送小红书”→ 隐含 “小明和小红可能有关系”;
- 从 “昨天买的书”→ 隐含 “书是新的 / 特意准备的”。
前馈网络就是做这个的:它是一个简单的两层神经网络(线性变换 + ReLU 激活 + 线性变换),对每个词的表示单独 “深加工”—— 基于多头注意力得到的关系,把具体的词转化为更抽象的 “语义特征”(类似人从具体事件中总结潜台词)。
3. 残差连接 + 层归一化:像 “保持思路清晰,不混乱”
编码器是 6 层堆叠的(类似 “一层一层深入理解”),但多层处理容易出两个问题:
- 信息 “越传越歪”:比如第一层的输出突然变大,第二层就很难处理(类似传话游戏传歪了);
- 深层 “学不动”:底层的参数因为梯度太小,学不到有效信息(类似推长链条,前端用力后端没感觉)。
残差连接(把每层的输入直接加到输出上)解决 “学不动” 问题 —— 让信息和梯度能直接 “穿层而过”;
层归一化(把输出标准化,让均值为 0、方差为 1)解决 “传歪” 问题 —— 让每层的输入保持稳定范围,方便下一层处理。
经过 6 层这样的处理,编码器最终输出一个 “上下文向量”(本质是一串向量,每个位置对应输入句的一个词,但都融入了全局信息),相当于给解码器递了一份 “超详细的原文理解笔记”。
2.5.3、解码器:用 “工具包” 把 “笔记” 变成 “通顺译文”
解码器的任务是拿着编码器的 “笔记”,从无到有生成英文译文(“Xiaoming gave Xiaohong a book he bought yesterday in the park”)。它的 “工具包” 更复杂 —— 因为它不仅要理解原文,还要保证生成的英文 “通顺”(符合语法)、“对得上原文”(不跑偏)。
2.5.3.1、 掩码多头自注意力:像 “写句子时只看自己已经写的内容”
解码器生成英文时,是 “逐词推进” 的(先写 “Xiaoming”,再写 “gave”,再写 “Xiaohong”……)。如果写 “gave” 时偷看了后面的 “Xiaohong”,就可能写出不符合语法的句子(比如先写 “gave” 再补主语,这在英文里是错的)。
掩码多头自注意力就是防止 “偷看” 的:
- 它和编码器的 “多头自注意力” 原理类似(抓词之间的关系),但多了一个 “掩码”(类似给未来的词盖了块布)—— 计算当前词和其他词的关系时,只允许关注 “已经写过的词”(比如写 “gave” 时,只能看 “Xiaoming”,不能看 “Xiaohong”“a book” 等还没写的词)。
- 这样生成的序列才能符合语言顺序(比如英文必须 “主语→谓语→宾语”)。
2.5.3.2、 编码器 - 解码器注意力:像 “写译文时回头看原文笔记”
生成英文时,必须保证每个词都和原文对应(比如 “gave” 对应 “送”,“he” 对应 “他”)。
编码器 - 解码器注意力就是干这个的:
- 它让解码器 “盯着编码器的笔记看”—— 计算解码器当前生成的词(比如 “gave”)与编码器输出的每个词(比如 “小明”“送”“小红”)的关联程度;
- 比如生成 “he” 时,会重点关注编码器中 “小明” 的位置(因为 “他” 指代 “小明”);生成 “book” 时,会重点关注 “书” 和 “买” 的位置。
2.5.3.3、前馈网络 + 残差连接 + 层归一化:和编码器的作用一致
- 前馈网络:对解码器生成的每个词(比如 “gave”)做 “深加工”,提炼抽象含义(比如 “gave” 不仅是 “送”,还隐含 “过去式”“主动关系”);
- 残差连接 + 层归一化:保证解码器的 6 层堆叠能稳定训练,生成的序列 “层层优化”(从粗糙到精准)。
2.5.4、编码器与解码器的 “协作全流程”(以翻译为例)
-
编码器处理输入:
中文句子→(嵌入层转成初始向量)→ 经过 6 层编码器(每层:多头自注意力抓关系→前馈网络深加工→残差 + 归一化稳定)→ 输出 “上下文向量”(包含所有词的关系和深层含义)。 -
解码器生成输出:
- 从 “开始信号”(
<START>)出发,生成第一个词(比如 “Xiaoming”); - 生成 “Xiaoming” 后,用掩码自注意力关注 “Xiaoming”(确保只看已生成内容),用编码器 - 解码器注意力关注编码器中 “小明” 的位置(保证对应),再经前馈网络和归一化优化;
- 重复上述步骤:生成 “gave” 时,关注已生成的 “Xiaoming” 和编码器中 “送” 的位置;生成 “Xiaohong” 时,关注 “Xiaoming gave” 和编码器中 “小红” 的位置…… 直到生成 “结束信号”(
<END>)。
- 从 “开始信号”(
-
最终结果:通过编码器的 “透彻理解” 和解码器的 “精准生成”,完成从中文到英文的转换。
2.5.5、总结:为什么这套组合能 “超越传统模型”?
Transformer 的编码器 + 解码器设计,本质是用 “注意力机制” 替代了 RNN 的 “序列依赖”(不用按顺序处理,可并行计算),用 “多层堆叠 + 组件协作” 解决了 CNN 的 “局部视野局限”(能抓长距离关系)。
- 编码器的组件让它能 “吃透输入”(全方位抓关系、挖含义、稳训练);
- 解码器的组件让它能 “精准输出”(不偷看未来、紧盯原文、保通顺);
- 两者协作,就像一个 “超级翻译团队”:一个把原文理解到骨子里,一个把理解转化为完美译文 —— 这也是 Transformer 能在翻译、生成、问答等任务中表现顶尖的核心原因。
2.6、完整代码
2.6.1、Transforemers实现代码
# 导入必要的库
import numpy as np # 用于数值计算和数组操作
import math # 用于数学运算(如平方根、对数)
import torch # PyTorch深度学习框架核心库
from torch import nn # PyTorch神经网络模块
from d2l import torch as d2l # 深度学习工具库(提供基础组件和工具函数)
import matplotlib.pyplot as plt # 用于数据可视化(注意力权重热图等)
import torch.nn.functional as F # PyTorch函数式接口(如softmax、激活函数)class PositionalEncoding(nn.Module):"""位置编码模块:为序列注入位置信息(Transformer无循环结构,需显式编码位置)"""def __init__(self, d_model, max_seq_len=80):"""初始化位置编码矩阵参数:d_model:模型特征维度(与词嵌入维度一致)max_seq_len:最大序列长度(位置编码的最大覆盖范围)"""super().__init__() # 继承nn.Moduleself.d_model = d_model # 保存模型维度# 创建位置编码矩阵:形状为[max_seq_len, d_model],存储每个位置的编码pe = torch.zeros(max_seq_len, d_model)# 生成位置索引(0到max_seq_len-1),并增加维度为[max_seq_len, 1](便于广播计算)position = torch.arange(0, max_seq_len, dtype=torch.float).unsqueeze(1)# 计算频率除数(基于论文公式:div_term = 10000^(2i/d_model) 的倒数,用指数函数避免数值溢出)div_term = torch.exp(torch.arange(0, d_model, 2) # 生成偶数索引序列 [0,2,4,...,d_model-2](对应公式中的2i).float() # 转为浮点数* (-math.log(10000.0) / d_model) # 等价于 1/10000^(2i/d_model))# 为偶数维度(0,2,4...)分配正弦编码,奇数维度(1,3,5...)分配余弦编码pe[:, 0::2] = torch.sin(position * div_term) # 0::2表示从0开始,步长为2的索引(偶数维度)pe[:, 1::2] = torch.cos(position * div_term) # 1::2表示从1开始,步长为2的索引(奇数维度)# 增加批次维度:形状从[max_seq_len, d_model]变为[1, max_seq_len, d_model],适配批量输入pe = pe.unsqueeze(0)# 将位置编码注册为缓冲区(非模型参数,不参与训练,但会随模型保存)self.register_buffer('pe', pe)def forward(self, x):"""将位置编码添加到词嵌入中参数:x:词嵌入张量,形状为[batch_size, seq_len, d_model]返回:注入位置信息的词嵌入,形状与x一致"""# 缩放词嵌入:避免嵌入值与位置编码值量级差异过大(稳定训练)x = x * math.sqrt(self.d_model)# 获取输入序列的实际长度(每个样本的词元数量)seq_len = x.size(1) # x的形状为[batch_size, seq_len, d_model],取第1维为序列长度# 将位置编码中前seq_len个位置的编码添加到词嵌入中(截断或补齐到实际序列长度)x = x + self.pe[:, :seq_len] # self.pe形状为[1, max_seq_len, d_model],取前seq_len个位置return xclass MultiHeadAttention(nn.Module):"""多头注意力机制模块:将注意力拆分为多个并行子空间,捕获多尺度特征"""def __init__(self, heads: int, d_model: int, dropout: float = 0.1):"""初始化多头注意力参数:heads:注意力头的数量(需满足d_model能被heads整除)d_model:模型总维度(输入/输出特征维度)dropout:Dropout概率(防止过拟合)"""super().__init__()self.d_model = d_model # 模型总维度self.h = heads # 注意力头数self.d_k = d_model // heads # 每个注意力头的维度(d_model = heads * d_k)# 线性投影层:将输入特征分别映射到Q(查询)、K(键)、V(值)空间# 作用:区分Q、K、V的语义角色,为注意力计算做准备self.q_linear = nn.Linear(d_model, d_model) # Q的线性变换self.k_linear = nn.Linear(d_model, d_model) # K的线性变换self.v_linear = nn.Linear(d_model, d_model) # V的线性变换# 输出投影层:将多头注意力的结果合并后映射回d_model维度self.out = nn.Linear(d_model, d_model)# Dropout层:随机丢弃部分注意力权重,防止过拟合self.dropout = nn.Dropout(dropout) # 训练时以概率dropout丢弃元素,未丢弃元素缩放1/(1-dropout)# 缩放因子:用于缩放点积注意力的得分(避免得分过大导致softmax梯度消失)self.scale = math.sqrt(self.d_k) # 即1/sqrt(d_k)# 存储注意力权重(用于后续可视化或分析)self.attention_weights = Nonedef create_mask(self, seq_len, valid_lens, device):"""创建注意力掩码(用于屏蔽无效位置,如填充的PAD符号或未来信息)参数:seq_len:序列长度valid_lens:有效长度张量,形状为[batch_size](每个样本的有效长度)或[batch_size, seq_len](每个位置的有效性)device:设备(CPU/GPU)返回:掩码张量,形状为[batch_size, 1, seq_len, seq_len](适配多头注意力的维度)"""if valid_lens is None: # 无掩码时返回Nonereturn Nonebatch_size = valid_lens.size(0) # 批次大小if valid_lens.dim() == 1: # 情况1:每个样本一个有效长度(如[5,4]表示第1个样本有效长度5,第2个4)# 创建形状为[batch_size, seq_len, seq_len]的掩码:每行表示一个查询位置的有效键位置mask = torch.arange(seq_len, device=device).expand(batch_size, seq_len, seq_len)# 将valid_lens扩展为[batch_size, 1, 1],便于广播valid_lens = valid_lens.unsqueeze(1).unsqueeze(2)# 掩码规则:位置索引 < 有效长度的位置为True(保留),否则为False(屏蔽)mask = mask < valid_lenselse: # 情况2:每个位置一个有效性标记(如[batch_size, seq_len]的0/1张量)# 扩展为[batch_size, seq_len, seq_len]:每个查询位置共享相同的键位置有效性mask = valid_lens.unsqueeze(1).expand(batch_size, seq_len, seq_len)# 增加一个维度适配多头注意力(形状变为[batch_size, 1, seq_len, seq_len])return mask.unsqueeze(1)def attention(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor,mask: torch.Tensor = None, dropout: nn.Dropout = None):"""计算单头注意力(点积注意力)参数:q:查询张量,形状[batch_size, heads, seq_len_q, d_k]k:键张量,形状[batch_size, heads, seq_len_k, d_k]v:值张量,形状[batch_size, heads, seq_len_v, d_k](seq_len_k = seq_len_v)mask:掩码张量,形状[batch_size, 1, seq_len_q, seq_len_k]dropout:Dropout层返回:注意力输出(加权聚合后的值),形状[batch_size, heads, seq_len_q, d_k]注意力权重,形状[batch_size, heads, seq_len_q, seq_len_k]"""# 计算注意力得分(Q与K的点积):形状[batch_size, heads, seq_len_q, seq_len_k]# k.transpose(-2, -1):交换k的最后两维,形状变为[batch_size, heads, d_k, seq_len_k]# 点积后除以缩放因子self.scale(即1/sqrt(d_k)),防止得分过大导致softmax梯度消失scores = (torch.matmul(q, k.transpose(-2, -1)) / self.scale)# 应用掩码:将无效位置的得分设为-1e9(softmax后接近0,即不关注)if mask is not None:scores = scores.masked_fill(mask == 0, -1e9) # mask==0的位置被屏蔽# 计算注意力权重:对得分做softmax(按最后一维归一化,每行和为1)attn_weights = F.softmax(scores, dim=-1) # 形状[batch_size, heads, seq_len_q, seq_len_k]# 应用Dropout(训练时随机丢弃部分权重)if dropout is not None:attn_weights = dropout(attn_weights)# 加权聚合值张量v:注意力权重 × v,得到最终注意力输出output = torch.matmul(attn_weights, v) # 形状[batch_size, heads, seq_len_q, d_k]return output, attn_weightsdef forward(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor,mask: torch.Tensor = None):"""多头注意力的前向传播(核心逻辑)参数:q:查询张量,形状[batch_size, seq_len_q, d_model]k:键张量,形状[batch_size, seq_len_k, d_model]v:值张量,形状[batch_size, seq_len_v, d_model](seq_len_k = seq_len_v)mask:掩码张量,可选,形状[batch_size, 1, seq_len]或[batch_size, seq_len, seq_len]返回:多头注意力输出,形状[batch_size, seq_len_q, d_model]注意力权重,形状[batch_size, heads, seq_len_q, seq_len_k]"""batch_size = q.size(0) # 批次大小# 1. 线性投影并重塑为多头结构# 将输入特征通过线性层映射到d_model维度,再拆分为heads个注意力头# 形状变化:[batch_size, seq_len, d_model] → [batch_size, seq_len, heads, d_k]k = self.k_linear(k).view(batch_size, -1, self.h, self.d_k) # k的处理q = self.q_linear(q).view(batch_size, -1, self.h, self.d_k) # q的处理v = self.v_linear(v).view(batch_size, -1, self.h, self.d_k) # v的处理# 2. 调整维度顺序:将heads维度提前,便于并行计算多头注意力# 形状变化:[batch_size, seq_len, heads, d_k] → [batch_size, heads, seq_len, d_k]k = k.transpose(1, 2) # 交换seq_len和heads维度q = q.transpose(1, 2)v = v.transpose(1, 2)# 3. 处理掩码:将输入掩码转换为适配多头注意力的形状[batch_size, 1, seq_len_q, seq_len_k]if mask is not None:# 若掩码维度≤2(如[batch_size, seq_len]),调用create_mask生成标准掩码if mask.dim() <= 2:mask = self.create_mask(q.size(2), mask, q.device) # q.size(2)是seq_len_q# 4. 计算多头注意力:调用attention函数,得到每个头的输出和权重output, attn_weights = self.attention(q, k, v, mask, self.dropout)self.attention_weights = attn_weights # 保存注意力权重# 5. 重塑并合并多头结果# 交换维度:[batch_size, heads, seq_len_q, d_k] → [batch_size, seq_len_q, heads, d_k]output = output.transpose(1, 2).contiguous() # contiguous()确保内存连续,便于后续view操作# 合并多头:将heads和d_k维度合并为d_model(heads×d_k = d_model)# 形状变化:[batch_size, seq_len_q, heads, d_k] → [batch_size, seq_len_q, d_model]output = output.view(batch_size, -1, self.d_model) # -1表示自动计算seq_len_q# 6. 最终线性投影:将合并后的结果映射回d_model维度(进一步调整特征)output = self.out(output)return output, attn_weightsclass PositionWiseFFN(nn.Module):"""基于位置的前馈网络(Transformer子层):对序列中每个位置的特征独立做非线性变换"""def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs, **kwargs):"""初始化前馈网络参数:ffn_num_input:输入特征维度(需与注意力机制输出维度一致,即d_model)ffn_num_hiddens:隐藏层维度(通常大于输入维度,形成"升维-降维"结构)ffn_num_outputs:输出特征维度(需与输入维度一致,才能参与残差连接)"""super(PositionWiseFFN, self).__init__(** kwargs)# 第一层线性变换(升维):将输入从ffn_num_input映射到ffn_num_hiddensself.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)# 非线性激活函数:引入特征间的非线性交互(ReLU是常用选择)self.relu = nn.ReLU()# 第二层线性变换(降维):将隐藏层映射回ffn_num_outputs(即d_model)self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)def forward(self, X):"""前向传播:对每个位置的特征独立应用相同的MLP参数:X:输入张量,形状为[batch_size, seq_len, feature_dim](feature_dim=ffn_num_input)返回:输出张量,形状与X一致([batch_size, seq_len, ffn_num_outputs])"""# 计算流程:输入 → 升维(增强特征交互) → 非线性激活 → 降维(恢复原维度)return self.dense2(self.relu(self.dense1(X)))class AddNorm(nn.Module):"""残差连接 + 层规范化(Transformer子层输出的标准处理):解决深层网络训练难题"""def __init__(self, normalized_shape, dropout, **kwargs):"""初始化参数参数:normalized_shape:层规范化的维度(通常为输入特征的最后一维,如d_model)dropout:Dropout概率(随机丢弃部分特征,防止过拟合)"""super(AddNorm, self).__init__(** kwargs)# Dropout层:仅作用于子层输出(保护原始输入X)self.dropout = nn.Dropout(dropout)# 层规范化层:对每个样本的特征做归一化(均值0,方差1),稳定训练# 与BatchNorm不同,LayerNorm在样本内计算均值方差,更适合序列数据self.ln = nn.LayerNorm(normalized_shape)def forward(self, X, Y):"""前向传播:残差连接 + 层规范化参数:X:子层的原始输入张量(形状与Y必须一致,否则无法相加)Y:子层(如注意力/前馈网络)的输出张量返回:处理后的张量,形状与X/Y一致(特征分布更稳定)"""# 步骤解析:# 1. 对Y应用Dropout:随机丢弃部分特征,防止模型过度依赖子层输出# 2. 残差连接:X + dropout(Y) → 保留原始输入信息,缓解梯度消失(若Y无效,输出≈X)# 3. 层规范化:对每个样本计算均值和方差,将特征缩放到标准分布,加速训练return self.ln(self.dropout(Y) + X)class EncoderBlock(nn.Module):"""Transformer编码器块:编码器的基本单元,堆叠N次形成完整编码器"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, use_bias=False, **kwargs):"""初始化编码器块参数:key_size/query_size/value_size:注意力机制中K/Q/V的特征维度(通常与num_hiddens一致)num_hiddens:隐藏层特征维度(即d_model,与词嵌入维度一致)norm_shape:层规范化的维度(通常为[num_hiddens])ffn_num_input/ffn_num_hiddens:前馈网络的输入/隐藏层维度num_heads:注意力头数dropout:Dropout概率(用于注意力和前馈网络)use_bias:线性层是否使用偏置(控制模型复杂度)"""super(EncoderBlock, self).__init__(** kwargs)# 子层1:多头自注意力机制(Q=K=V=输入X,捕获序列内的依赖关系)self.attention = MultiHeadAttention(heads=num_heads, d_model=num_hiddens, dropout=dropout)# 子层1的输出处理:残差连接 + 层规范化self.addnorm1 = AddNorm(norm_shape, dropout)# 子层2:基于位置的前馈网络(对注意力输出做非线性变换,增强特征表达)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)# 子层2的输出处理:残差连接 + 层规范化self.addnorm2 = AddNorm(norm_shape, dropout)def forward(self, X, valid_lens):"""前向传播:自注意力 → AddNorm → 前馈网络 → AddNorm参数:X:输入序列张量,形状[batch_size, seq_len, num_hiddens]valid_lens:有效长度张量(屏蔽无效位置,如PAD)返回:经过编码器块处理的张量,形状与X一致(已捕获序列内依赖)"""# 步骤1:自注意力 + 残差规范化# 自注意力中,Q=K=V=X,valid_lens控制仅关注有效位置Y = self.addnorm1(X, self.attention(X, X, X, valid_lens)[0]) # [0]取注意力输出(忽略权重)# 步骤2:前馈网络 + 残差规范化# 对自注意力的输出做非线性变换,增强特征表达return self.addnorm2(Y, self.ffn(Y))class TransformerEncoder(d2l.Encoder):"""Transformer编码器:将输入序列编码为包含上下文信息的特征向量"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, use_bias=False, **kwargs):"""初始化编码器参数:vocab_size:词汇表大小(用于词嵌入层)num_layers:编码器块的堆叠数量(层数越多,捕获的上下文越复杂)其他参数:同EncoderBlock"""super(TransformerEncoder, self).__init__(** kwargs)self.num_hiddens = num_hiddens # 隐藏层维度(d_model)# 词嵌入层:将词ID(整数)转换为向量,形状[vocab_size, num_hiddens]self.embedding = nn.Embedding(vocab_size, num_hiddens)# 位置编码层:注入序列顺序信息(使用自定义的PositionalEncoding)self.pos_encoding = PositionalEncoding(d_model=num_hiddens, max_seq_len=100)# 堆叠num_layers个编码器块(用nn.Sequential管理)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module(f"block{i}", # 为每个块命名,便于调试EncoderBlock(key_size=key_size, query_size=query_size, value_size=value_size,num_hiddens=num_hiddens, norm_shape=norm_shape,ffn_num_input=ffn_num_input, ffn_num_hiddens=ffn_num_hiddens,num_heads=num_heads, dropout=dropout, use_bias=use_bias))def forward(self, X, valid_lens, *args):"""前向传播:词嵌入 → 位置编码 → 多层编码器块参数:X:输入词ID序列,形状[batch_size, seq_len]valid_lens:有效长度张量(屏蔽无效位置)返回:编码后的特征向量,形状[batch_size, seq_len, num_hiddens]"""# 1. 词嵌入:将词ID转为向量,并缩放(平衡与位置编码的量级)X = self.embedding(X) * math.sqrt(self.num_hiddens) # 缩放因子为sqrt(d_model)# 2. 注入位置编码:将位置信息添加到词嵌入中(Transformer无循环结构,需显式位置信息)X = self.pos_encoding(X)# 3. 经过所有编码器块:逐层捕获更复杂的上下文依赖self.attention_weights = [None] * len(self.blks) # 存储各层的注意力权重(用于可视化)for i, blk in enumerate(self.blks):X = blk(X, valid_lens) # 每个块处理后更新Xself.attention_weights[i] = blk.attention.attention_weights # 保存第i层的注意力权重return Xclass DecoderBlock(nn.Module):"""Transformer解码器块:解码器的基本单元,堆叠N次形成完整解码器"""def __init__(self, key_size, query_size, value_size, num_hiddens,norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,dropout, i, **kwargs):"""初始化解码器块参数:i:当前块的索引(用于管理历史状态)其他参数:同EncoderBlock(增加了解码器特有的掩蔽自注意力)"""super(DecoderBlock, self).__init__(** kwargs)self.i = i # 块索引(用于跟踪历史状态)# 子层1:掩蔽多头自注意力(Q=K=V=解码器输入,屏蔽未来位置信息)self.attention1 = MultiHeadAttention(heads=num_heads, d_model=num_hiddens, dropout=dropout)self.addnorm1 = AddNorm(norm_shape, dropout) # 残差 + 层规范化# 子层2:编码器-解码器注意力(Q=解码器输出,K=V=编码器输出,结合源序列和目标序列信息)self.attention2 = MultiHeadAttention(heads=num_heads, d_model=num_hiddens, dropout=dropout)self.addnorm2 = AddNorm(norm_shape, dropout) # 残差 + 层规范化# 子层3:前馈网络(增强特征表达)self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)self.addnorm3 = AddNorm(norm_shape, dropout) # 残差 + 层规范化def forward(self, X, state):"""前向传播:掩蔽自注意力 → AddNorm → 编码器-解码器注意力 → AddNorm → 前馈网络 → AddNorm参数:X:解码器输入序列,形状[batch_size, seq_len, num_hiddens]state:状态变量,包含:state[0]:编码器输出(enc_outputs)state[1]:编码器有效长度(enc_valid_lens)state[2]:解码器历史状态(每个块的历史输入,用于推理时累积前文)返回:解码器输出 + 更新后的state(包含历史状态,用于下一时间步解码)"""enc_outputs, enc_valid_lens = state[0], state[1] # 提取编码器输出和有效长度# 管理解码器历史状态(推理时需累积已解码的词,训练时直接用完整序列)if state[2][self.i] is None: # 训练时:历史状态为空,键/值=当前输入Xkey_values = Xelse: # 推理时:将历史序列(已解码的词)与当前输入拼接(确保关注前文)key_values = torch.cat((state[2][self.i], X), axis=1) # 沿序列长度维度拼接state[2][self.i] = key_values # 更新当前块的历史状态# 训练时:生成掩蔽(下三角矩阵),防止关注未来位置(如翻译时第3个词不能看第4个词)if self.training:batch_size, num_steps, _ = X.shape # num_steps是当前输入的序列长度# 生成形状为[batch_size, num_steps]的有效长度(如[1,2,...,num_steps])dec_valid_lens = torch.arange(1, num_steps + 1, device=X.device).repeat(batch_size, 1)else: # 推理时:每次仅解码一个词,无需掩蔽(前文已包含在key_values中)dec_valid_lens = None# 子层1:掩蔽自注意力(确保解码顺序正确,不泄露未来信息)# Q=X,K=V=key_values(训练时为完整序列+掩蔽,推理时为历史+当前)output1, self.attention_weights1 = self.attention1(X, key_values, key_values, dec_valid_lens)Y = self.addnorm1(X, output1) # 残差 + 层规范化# 子层2:编码器-解码器注意力(用编码器输出指导解码,如英文→法文中结合英文信息)# Q=Y(解码器自注意力输出),K=V=enc_outputs(编码器输出)output2, self.attention_weights2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)Z = self.addnorm2(Y, output2) # 残差 + 层规范化# 子层3:前馈网络增强特征表达return self.addnorm3(Z, self.ffn(Z)), stateclass TransformerDecoder(d2l.AttentionDecoder):"""Transformer解码器:将编码器输出转换为目标序列(如翻译任务中的目标语言)"""def __init__(self, vocab_size, key_size, query_size, value_size,num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,num_heads, num_layers, dropout, **kwargs):"""初始化解码器参数:vocab_size:目标语言词汇表大小num_layers:解码器块的堆叠数量其他参数:同TransformerEncoder"""super(TransformerDecoder, self).__init__(** kwargs)self.num_hiddens = num_hiddens # 隐藏层维度(d_model)self.num_layers = num_layers # 解码器块数量# 目标语言词嵌入层:将目标词ID转为向量self.embedding = nn.Embedding(vocab_size, num_hiddens)# 位置编码层:注入目标序列的位置信息self.pos_encoding = PositionalEncoding(d_model=num_hiddens, max_seq_len=100)# 堆叠num_layers个解码器块self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module(f"block{i}",DecoderBlock(key_size=key_size, query_size=query_size, value_size=value_size,num_hiddens=num_hiddens, norm_shape=norm_shape,ffn_num_input=ffn_num_input, ffn_num_hiddens=ffn_num_hiddens,num_heads=num_heads, dropout=dropout, i=i))# 输出层:将解码器特征映射到目标词汇表(vocab_size维度)self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs, enc_valid_lens, *args):"""初始化解码器状态参数:enc_outputs:编码器输出enc_valid_lens:编码器有效长度返回:初始状态,包含:enc_outputs, enc_valid_lens, 空历史状态列表"""# state[2]为每个解码器块的历史状态(初始化为None)return [enc_outputs, enc_valid_lens, [None] * self.num_layers]def forward(self, X, state):"""前向传播:词嵌入 → 位置编码 → 多层解码器块 → 输出层参数:X:目标序列词ID,形状[batch_size, seq_len]state:解码器初始状态(来自init_state)返回:词汇表概率分布(未归一化,形状[batch_size, seq_len, vocab_size]) + 更新后的state"""# 1. 词嵌入 + 位置编码(注入目标序列的位置信息)X = self.embedding(X) * math.sqrt(self.num_hiddens) # 缩放词嵌入X = self.pos_encoding(X) # 添加位置编码# 2. 经过所有解码器块# 存储注意力权重:[0]为自注意力权重,[1]为编码器-解码器注意力权重self._attention_weights = [[None] * len(self.blks) for _ in range(2)]for i, blk in enumerate(self.blks):X, state = blk(X, state) # 每个块处理后更新X和state# 保存当前块的两种注意力权重(用于可视化)self._attention_weights[0][i] = blk.attention_weights1 # 自注意力权重self._attention_weights[1][i] = blk.attention_weights2 # 编码器-解码器注意力权重# 3. 输出层:映射到目标词汇表(未用softmax,训练时结合交叉熵损失)return self.dense(X), state@propertydef attention_weights(self):"""返回注意力权重(用于可视化)"""return self._attention_weightsclass CustomEncoderDecoder(nn.Module):"""自定义编码器-解码器模型:协调编码器和解码器工作,适配训练函数"""def __init__(self, encoder, decoder):super(CustomEncoderDecoder, self).__init__()self.encoder = encoder # 编码器实例self.decoder = decoder # 解码器实例def forward(self, enc_X, dec_X, enc_valid_lens=None):"""前向传播:编码器编码 → 解码器解码参数:enc_X:源序列(如英文句子词ID),形状[batch_size, src_seq_len]dec_X:目标序列(如法语句子词ID,训练时用"强制教学"),形状[batch_size, tgt_seq_len]enc_valid_lens:源序列有效长度返回:解码器输出(词汇表概率分布) + 解码器状态(与训练函数兼容)"""enc_outputs = self.encoder(enc_X, enc_valid_lens) # 编码器编码源序列dec_state = self.decoder.init_state(enc_outputs, enc_valid_lens) # 初始化解码器状态# 解码器解码:输入目标序列和解码器状态,返回输出和状态return self.decoder(dec_X, dec_state)def main():"""主函数:测试Transformer模型的前向传播和关键特性"""# 超参数设置(极简配置,便于测试)vocab_size = 100 # 词汇表大小(模拟小词汇表)d_model = 16 # 模型维度(d_model)num_heads = 2 # 注意力头数num_layers = 2 # 编码器/解码器层数batch_size = 2 # 批次大小seq_len = 5 # 序列长度(每个样本包含5个词元)# 1. 创建编码器和解码器encoder = TransformerEncoder(vocab_size=vocab_size,key_size=d_model,query_size=d_model,value_size=d_model,num_hiddens=d_model,norm_shape=[d_model],ffn_num_input=d_model,ffn_num_hiddens=32, # 前馈网络隐藏层维度num_heads=num_heads,num_layers=num_layers,dropout=0.1)decoder = TransformerDecoder(vocab_size=vocab_size,key_size=d_model,query_size=d_model,value_size=d_model,num_hiddens=d_model,norm_shape=[d_model],ffn_num_input=d_model,ffn_num_hiddens=32,num_heads=num_heads,num_layers=num_layers,dropout=0.1)# 2. 生成模拟输入(随机词ID序列)src_seq = torch.randint(0, vocab_size, (batch_size, seq_len)) # 源序列:[2,5]tgt_seq = torch.randint(0, vocab_size, (batch_size, seq_len)) # 目标序列:[2,5]valid_lens = torch.tensor([seq_len, seq_len - 1]) # 有效长度:第1个样本全有效,第2个样本最后1个无效# 3. 编码器前向传播:测试编码过程enc_output = encoder(src_seq, valid_lens)print(f"源序列形状: {src_seq.shape}") # 期望:[2,5]print(f"编码器输出形状: {enc_output.shape}") # 期望:[2,5,16](batch, seq_len, d_model)# 4. 解码器前向传播:测试解码过程model = CustomEncoderDecoder(encoder, decoder) # 封装编码器-解码器dec_output, _ = model(src_seq, tgt_seq, valid_lens)print(f"目标序列形状: {tgt_seq.shape}") # 期望:[2,5]print(f"解码器输出形状: {dec_output.shape}") # 期望:[2,5,100](batch, seq_len, vocab_size)# 5. 验证编码器注意力权重的有效性enc_attn_weights = encoder.attention_weights[0] # 取第0层的注意力权重print(f"编码器第0层注意力权重形状: {enc_attn_weights.shape}") # 期望:[2,2,5,5](batch, heads, seq_len, seq_len)# 检查注意力权重归一化(每行和应为1.0,因softmax归一化)head0_row0_sum = enc_attn_weights[0, 0, 0].sum().item() # 第0样本、第0头、第0行的权重和print(f"编码器第0层第0个头的权重和: {head0_row0_sum:.4f}") # 期望接近1.0# 6. 可视化解码器自注意力权重(第0层第0个头)dec_self_attn = decoder.attention_weights[0][0] # 解码器第0层自注意力权重print(f"解码器第0层自注意力权重形状: {dec_self_attn.shape}") # 期望:[2,2,5,5]attn_matrix = dec_self_attn[0, 0].detach().numpy() # 取第0样本、第0头的权重矩阵print(f"待可视化的注意力矩阵形状: {attn_matrix.shape}") # 期望:(5,5)# 绘制注意力热图(颜色越深表示关注度越高)plt.figure(figsize=(6, 6))plt.imshow(attn_matrix, cmap='viridis') # 热图可视化plt.colorbar(label='注意力权重')plt.title('解码器第0层自注意力权重')plt.xlabel('键位置(Key Position)')plt.ylabel('查询位置(Query Position)')plt.show()# 7. 验证编码器-解码器注意力的形状(结合源和目标序列)enc_dec_attn = decoder.attention_weights[1][0] # 第0层编码器-解码器注意力print(f"编码器-解码器注意力形状: {enc_dec_attn.shape}") # 期望:[2,2,5,5](batch, heads, tgt_seq_len, src_seq_len)# 程序入口:执行main函数
if __name__ == "__main__":main()2.6.2、与LSTM对比实现代码
"""
文件名: 对比实验
作者: 墨尘
日期: 2025/7/18
项目名: dl_env
备注:
"""
import mathimport torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset, DataLoaderfrom LLM import PositionalEncoding# -------------------------- 数据生成(带长距离依赖的序列) --------------------------
class SequenceDataset(Dataset):"""生成带长距离依赖的序列数据:预测序列的下一个元素,其中偶数位置依赖前2个位置的元素"""def __init__(self, seq_len=10, num_samples=1000):self.seq_len = seq_lenself.num_samples = num_samplesself.data = self._generate_data()def _generate_data(self):"""生成序列:规律为 x[i] = x[i-2] + 噪声(增强长距离依赖)"""data = []for _ in range(self.num_samples):# 随机初始化前2个元素seq = [np.random.randn() for _ in range(2)]# 生成后续元素(依赖前2个位置,制造长距离依赖)for i in range(2, self.seq_len + 1): # +1 是因为需要预测下一个元素seq.append(seq[i - 2] + 0.1 * np.random.randn()) # x[i] = x[i-2] + 噪声data.append(seq)return np.array(data, dtype=np.float32)def __len__(self):return self.num_samplesdef __getitem__(self, idx):seq = self.data[idx]x = seq[:-1] # 输入序列(前seq_len个元素)y = seq[1:] # 目标序列(后seq_len个元素,即下一个元素预测)return torch.tensor(x), torch.tensor(y)# -------------------------- 模型定义 --------------------------
class TransformerModel(nn.Module):"""简化的Transformer模型(用于序列预测)"""def __init__(self, input_dim=1, d_model=32, num_heads=2, num_layers=2, dropout=0.1):super().__init__()self.d_model = d_model# 输入维度映射(将1维序列映射到d_model维)self.input_proj = nn.Linear(input_dim, d_model)self.pos_encoding = PositionalEncoding(d_model, max_seq_len=100)# Transformer编码器层encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=num_heads, dim_feedforward=64, dropout=dropout, batch_first=True)self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)# 输出层(映射回1维)self.output_proj = nn.Linear(d_model, 1)def forward(self, x):# x形状:[batch_size, seq_len, 1]x = self.input_proj(x) # [batch_size, seq_len, d_model]x = self.pos_encoding(x) # 注入位置信息x = self.transformer_encoder(x) # [batch_size, seq_len, d_model]return self.output_proj(x) # [batch_size, seq_len, 1]class LSTMModel(nn.Module):"""对比用的LSTM模型(参数规模与Transformer相近)"""def __init__(self, input_dim=1, hidden_dim=32, num_layers=2, dropout=0.1):super().__init__()self.lstm = nn.LSTM(input_size=input_dim,hidden_size=hidden_dim,num_layers=num_layers,dropout=dropout,batch_first=True)self.output_proj = nn.Linear(hidden_dim, 1) # 输出层def forward(self, x):# x形状:[batch_size, seq_len, 1]lstm_out, _ = self.lstm(x) # [batch_size, seq_len, hidden_dim]return self.output_proj(lstm_out) # [batch_size, seq_len, 1]# -------------------------- 训练与评估函数 --------------------------
def train_model(model, train_loader, epochs=50, lr=0.001):criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=lr)model.train()losses = []for epoch in range(epochs):total_loss = 0.0for x, y in train_loader:# 调整输入形状:[batch_size, seq_len] → [batch_size, seq_len, 1]x = x.unsqueeze(-1)y = y.unsqueeze(-1)optimizer.zero_grad()output = model(x)loss = criterion(output, y)loss.backward()optimizer.step()total_loss += loss.item() * x.size(0)avg_loss = total_loss / len(train_loader.dataset)losses.append(avg_loss)if (epoch + 1) % 10 == 0:print(f"Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.6f}")return lossesdef evaluate_long_sequence(model, seq_len=50):"""评估模型在长序列上的预测能力(测试长距离依赖捕获)"""model.eval()# 生成一个长序列(长度为seq_len)seq = [np.random.randn() for _ in range(2)]for i in range(2, seq_len):seq.append(seq[i - 2] + 0.1 * np.random.randn()) # 遵循x[i] = x[i-2] + 噪声# 用模型预测后续元素x = torch.tensor(seq[:20]).unsqueeze(0).unsqueeze(-1).float() # 取前20个元素作为输入with torch.no_grad():pred = model(x).squeeze().numpy() # 预测接下来的20个元素# 计算与真实值的MSE(关注后10个元素,体现长距离依赖)true = seq[1:21] # 真实的后续元素long_range_mse = np.mean((pred[-10:] - true[-10:]) ** 2) # 仅计算最后10个元素的误差return long_range_mse# -------------------------- 对比实验主函数 --------------------------
def main():# 实验参数seq_len = 20 # 序列长度(包含一定长距离依赖)batch_size = 32epochs = 50hidden_dim = 32 # 确保两个模型的参数规模相近# 1. 生成数据dataset = SequenceDataset(seq_len=seq_len, num_samples=1000)train_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)# 2. 初始化模型transformer = TransformerModel(d_model=hidden_dim)lstm = LSTMModel(hidden_dim=hidden_dim)# 3. 训练模型print("=== 训练Transformer ===")transformer_losses = train_model(transformer, train_loader, epochs=epochs)print("\n=== 训练LSTM ===")lstm_losses = train_model(lstm, train_loader, epochs=epochs)# 4. 评估长序列预测能力(测试长距离依赖)transformer_long_mse = evaluate_long_sequence(transformer, seq_len=50)lstm_long_mse = evaluate_long_sequence(lstm, seq_len=50)print(f"\n长序列预测MSE(越小越好):")print(f"Transformer: {transformer_long_mse:.6f}")print(f"LSTM: {lstm_long_mse:.6f}")# 5. 可视化损失曲线plt.figure(figsize=(10, 5))plt.plot(transformer_losses, label='Transformer')plt.plot(lstm_losses, label='LSTM')plt.xlabel('Epoch')plt.ylabel('MSE Loss')plt.title('训练损失对比')plt.legend()plt.grid(True)plt.show()# 复用之前定义的PositionalEncoding类class PositionalEncoding(nn.Module):def __init__(self, d_model, max_seq_len=80):super().__init__()self.d_model = d_modelpe = torch.zeros(max_seq_len, d_model)position = torch.arange(0, max_seq_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):x = x * math.sqrt(self.d_model)seq_len = x.size(1)x = x + self.pe[:, :seq_len]return xif __name__ == "__main__":main()2.7、实验效果
2.7.1、Transforemers实验效果

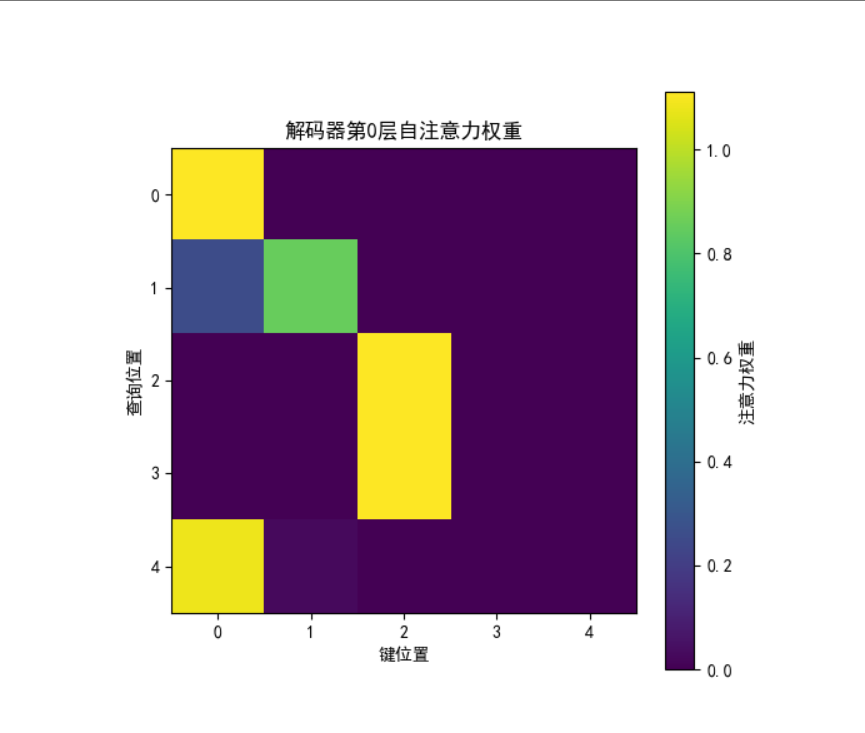
2.7.2、与LSTM对比实验效果