python爬虫获取PDF
【前提:菜鸟学习的记录过程,如果有不足之处,还请各位大佬大神们指教(感谢)】
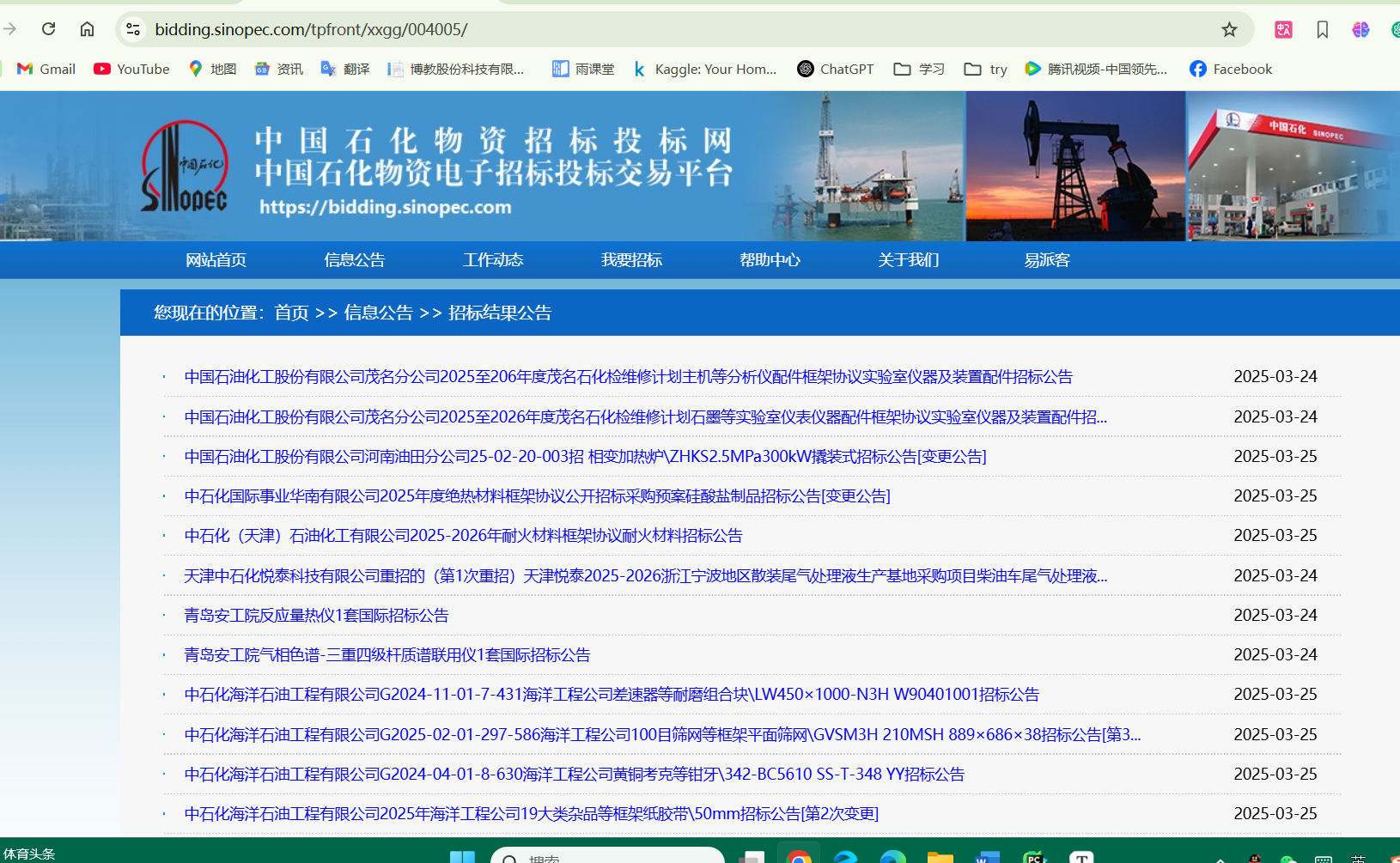
1.方法一:网站找到目标数据【单篇PDF】
https://bidding.sinopec.com/tpfront/xxgg/004005/

按F12,----检查------network----
要看常规的请求方式---get---post
在请求表头,看有没有奇怪的值,可以会加密,
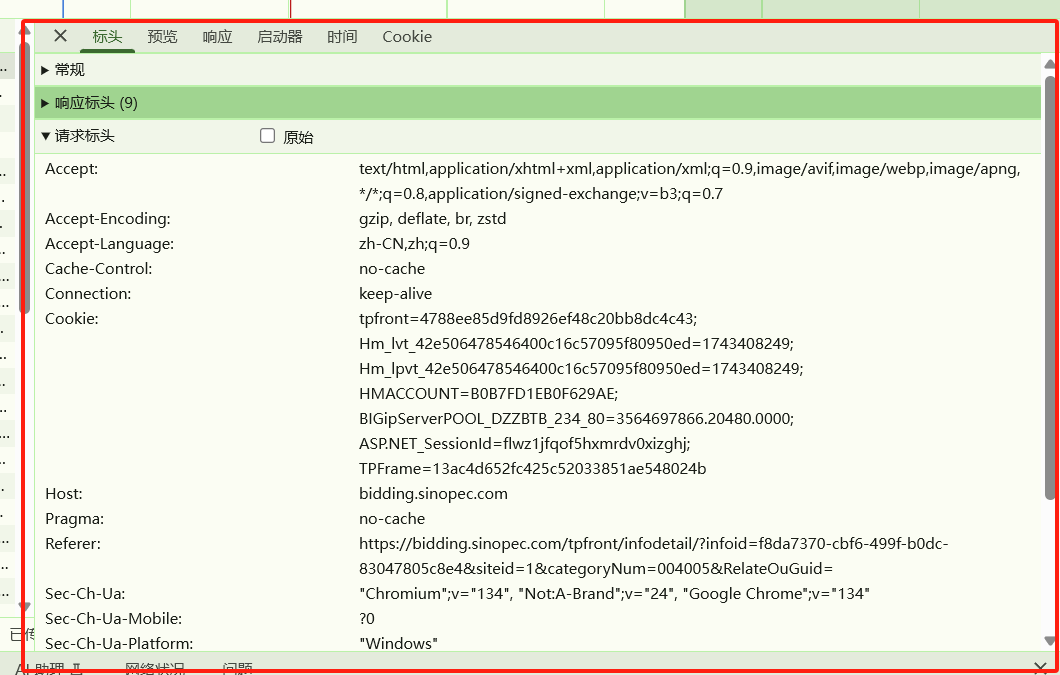
import requests# 一般带上url,user——agent,headers,cookieheaders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36','Cookie':'tpfront=4788ee85d9fd8926ef48c20bb8dc4c43; Hm_lvt_42e506478546400c16c57095f80950ed=1743408249; Hm_lpvt_42e506478546400c16c57095f80950ed=1743408249; HMACCOUNT=B0B7FD1EB0F629AE; BIGipServerPOOL_DZZBTB_234_80=3564697866.20480.0000; ASP.NET_SessionId=flwz1jfqof5hxmrdv0xizghj; TPFrame=13ac4d652fc425c52033851ae548024b'
}
# get里面放url
res=requests.get('https://bidding.sinopec.com/tpframe//AttachStorage202006/202412/J115/f8da7370-cbf6-499f-b0dc-83047805c8e4/%E4%B8%AD%E6%A0%87%E5%85%AC%E5%91%8A.pdf',headers=headers)
print(res)
print(res.text)拿到的数据是乱码,说明是二进制的数据,or 数据被加密了。
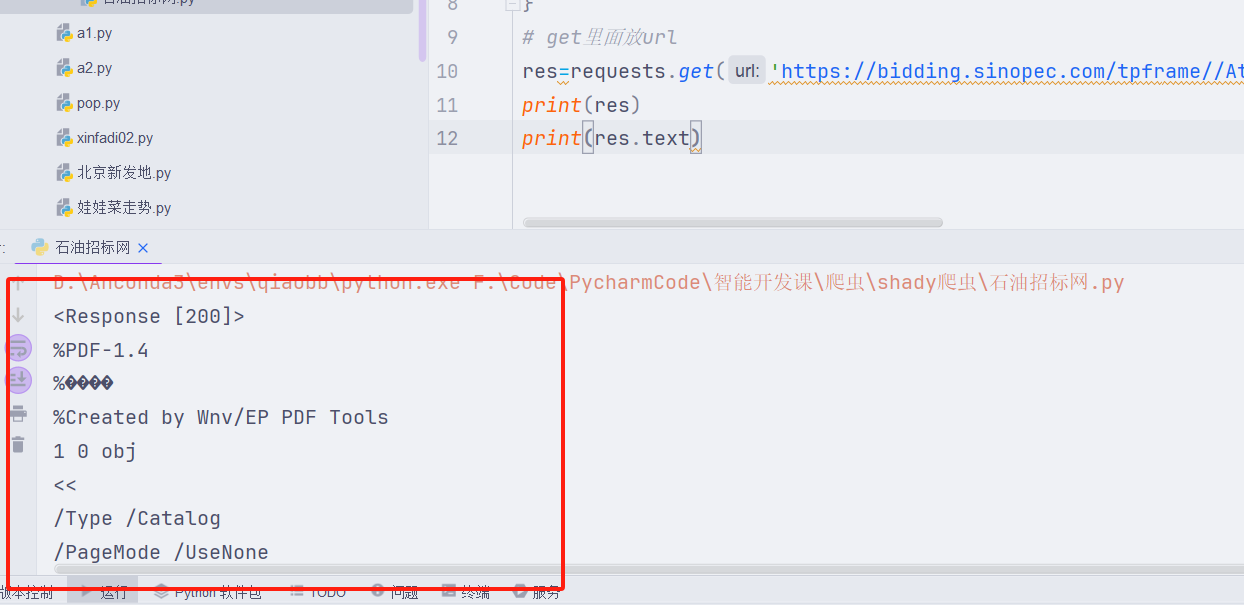
解决:把text换成 content
print(res.content)就会得到一个二进制的数据,把这些数据放进一个二进制的文件保存
with open('石油test.pdf','wb')as f:f.wirte(response.content)
2.方法二下载pdf
F12 找到html的中标公告.pdf
类似url
```
"https://bidding.sinopec.com/tpframe//AttachStorage202006/202412/J115/ca1dce49-f03e-497a-a254-009ff09ee2bd/中标公告.pdf"
```
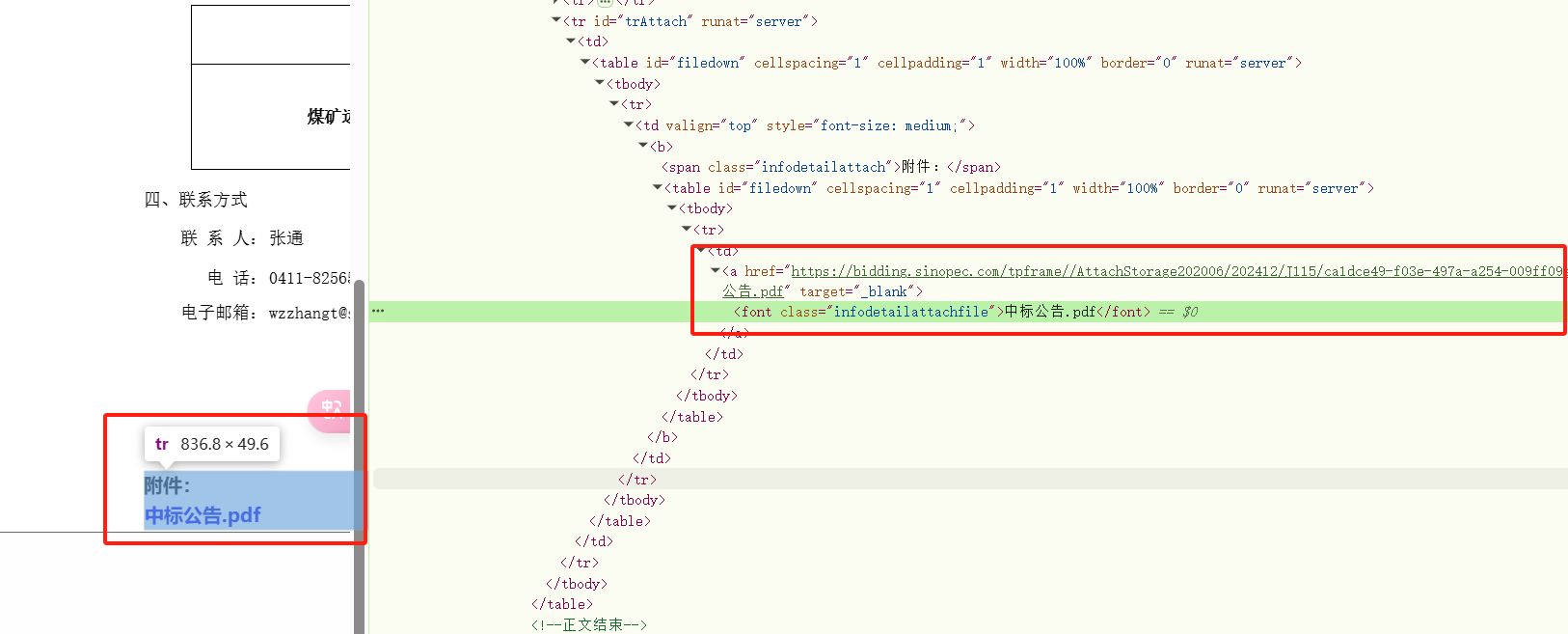
想要获取这个url,就需要先获取html代码。
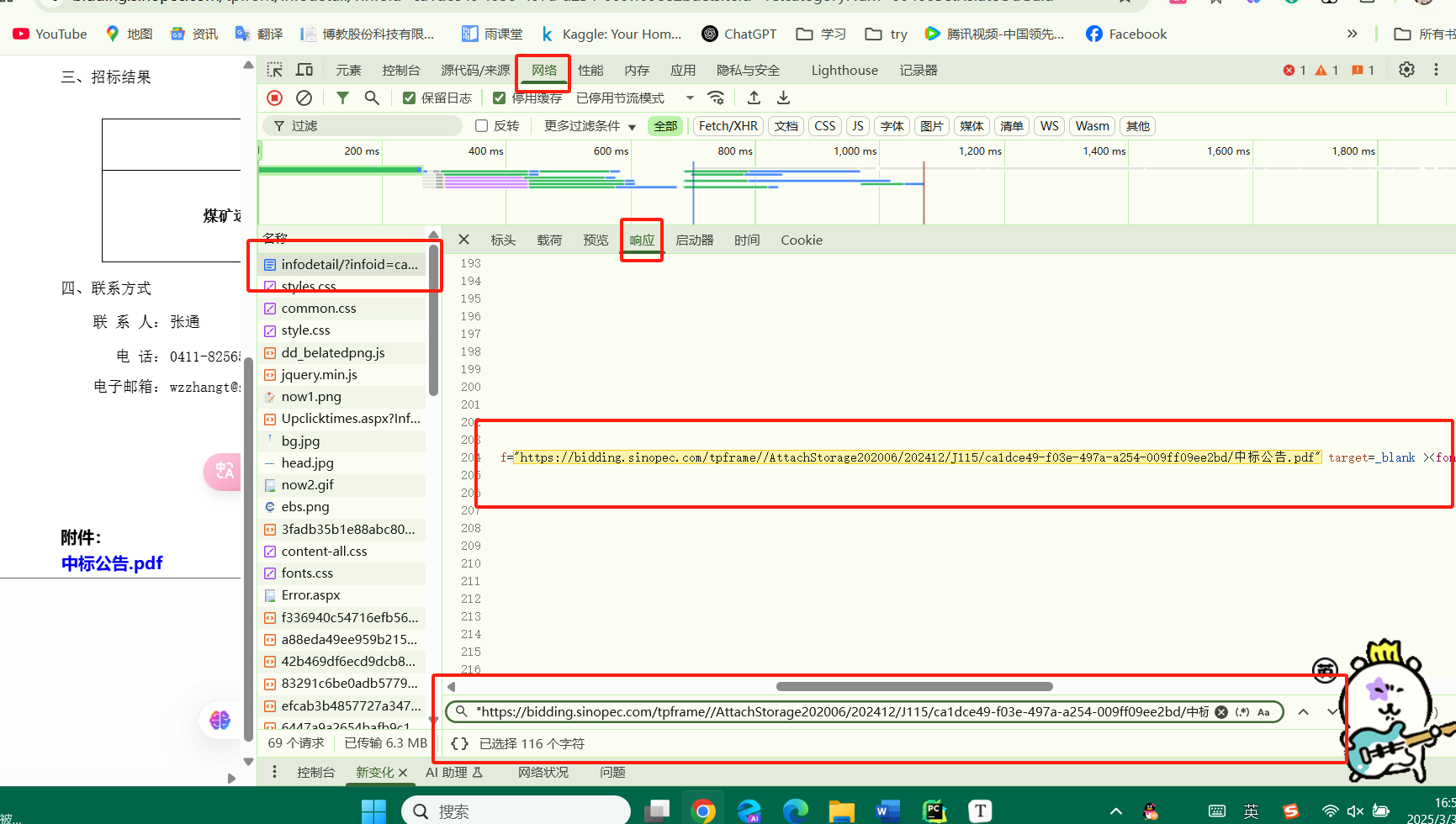
先去分析这个URL在html在哪个部分请求???
我们把想要的url复制,去查找
import requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36','Cookie': 'tpfront=4788ee85d9fd8926ef48c20bb8dc4c43; Hm_lvt_42e506478546400c16c57095f80950ed=1743408249; Hm_lpvt_42e506478546400c16c57095f80950ed=1743408249; HMACCOUNT=B0B7FD1EB0F629AE; BIGipServerPOOL_DZZBTB_234_80=3564697866.20480.0000; ASP.NET_SessionId=flwz1jfqof5hxmrdv0xizghj; TPFrame=13ac4d652fc425c52033851ae548024b'
}response=requests.get('https://bidding.sinopec.com/tpfront/infodetail/?infoid=ca1dce49-f03e-497a-a254-009ff09ee2bd&siteid=1&categoryNum=004005&RelateOuGuid=',headers=headers)
print(response.text)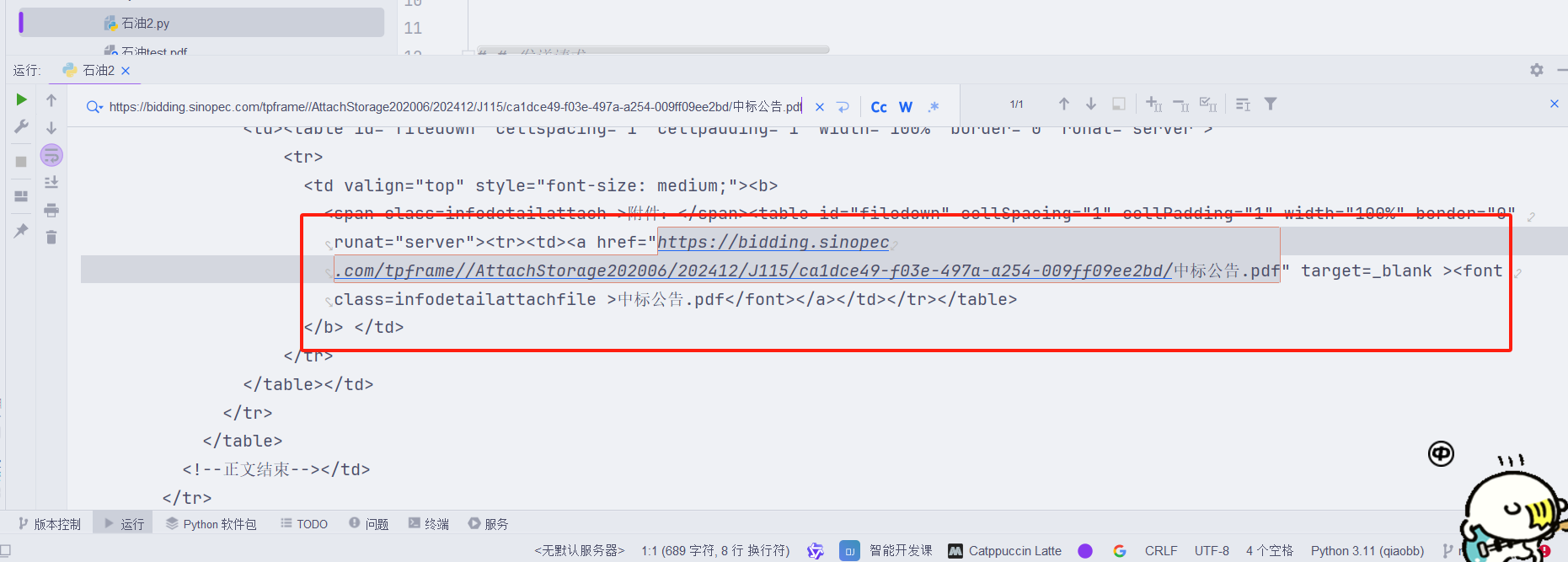
上面,可以把页面的html,下载。
在 HTML 和 CSS 中,ID 选择器使用 # 符号,而 class 选择器使用 .(点)符号。
a[target="_blank"]table#filedown a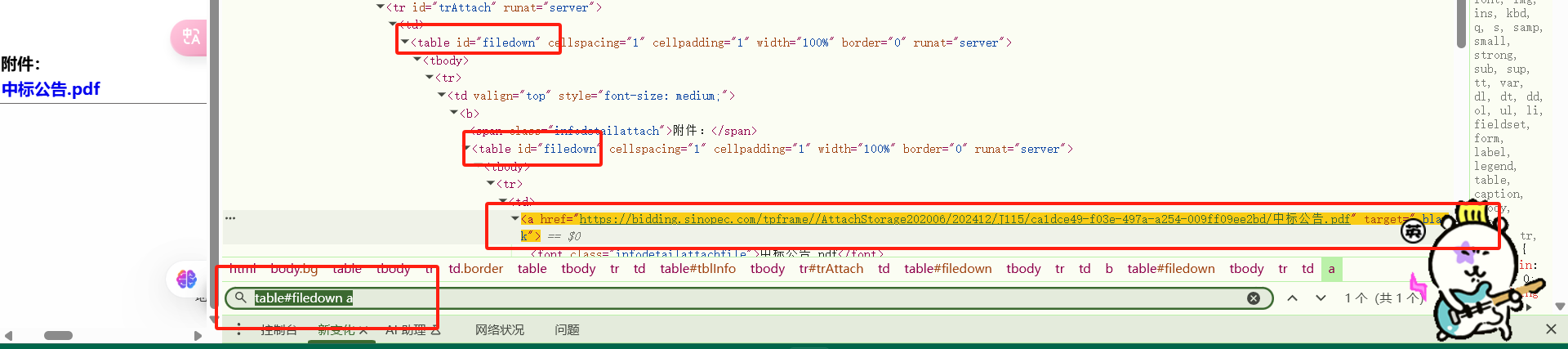
from bs4 import BeautifulSoupsoup=BeautifulSoup(response.text,'lxml')
print(soup.select('table#filedown a')[0])
```python
import requests
from bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36',
}
# 这个url指的是这个网页的
response=requests.get('https://bidding.sinopec.com/tpfront/infodetail/?infoid=ca1dce49-f03e-497a-a254-009ff09ee2bd&siteid=1&categoryNum=004005&RelateOuGuid=',headers=headers)
# print(response.text)soup=BeautifulSoup(response.text,'lxml')
print(soup.select('table#filedown a')[0]['href'])pdf_url=soup.select('table#filedown a')[0]['href']# # 发送请求
res=requests.get(pdf_url,headers=headers)with open('石油2.pdf','wb')as f:f.write(res.content)print("成功啦")```