【每日算法】专题十三_队列 + 宽搜(bfs)
1. 算法思路
BFS 算法核心思路
BFS(广度优先搜索)使用 队列(Queue)按层级顺序遍历图或树的节点。以下是 C++ 实现的核心思路和代码模板:
算法框架
#include <queue>
#include <vector>
#include <unordered_set> // 用于图的去重// 树的 BFS 层序遍历
vector<vector<int>> bfs(TreeNode* root) {vector<vector<int>> result;if (!root) return result;queue<TreeNode*> q;q.push(root); // 根节点入队while (!q.empty()) {int level_size = q.size(); // 当前层的节点数vector<int> current_level;// 处理当前层的所有节点for (int i = 0; i < level_size; i++) {TreeNode* node = q.front();q.pop(); // 队首出队current_level.push_back(node->val);// 将子节点入队if (node->left) q.push(node->left);if (node->right) q.push(node->right);}result.push_back(current_level); // 添加当前层到结果}return result;
}关键点
-
队列操作:
push():将节点加入队尾front():获取队首元素pop():移除队首元素empty():判断队列是否为空
-
层级控制:
- 通过
level_size记录当前层的节点数,确保每层节点被单独处理。
- 通过
-
图的 BFS(需去重):
void graphBFS(vector<vector<int>>& graph, int start) {queue<int> q;unordered_set<int> visited;q.push(start);visited.insert(start);while (!q.empty()) {int node = q.front();q.pop();// 处理当前节点cout << node << " ";// 遍历所有邻接节点for (int neighbor : graph[node]) {if (visited.find(neighbor) == visited.end()) {visited.insert(neighbor);q.push(neighbor);}}}
}
应用场景
- 二叉树层序遍历
- 无权图最短路径
int shortestPath(vector<vector<int>>& graph, int start, int target) {queue<pair<int, int>> q; // {节点, 距离}unordered_set<int> visited;q.push({start, 0});visited.insert(start);while (!q.empty()) {auto [node, dist] = q.front();q.pop();if (node == target) return dist;for (int neighbor : graph[node]) {if (!visited.count(neighbor)) {visited.insert(neighbor);q.push({neighbor, dist + 1});}}}return -1; // 无法到达
}- 状态扩展问题(如迷宫)
总结
- 队列选择:C++ 中使用
std::queue或std::deque。 - 去重机制:图的 BFS 必须用
unordered_set避免重复访问。 - 层级处理:通过记录每层节点数实现逐层遍历。
2. 例题
2.1 N 叉数的层序遍历
429. N 叉树的层序遍历 - 力扣(LeetCode)
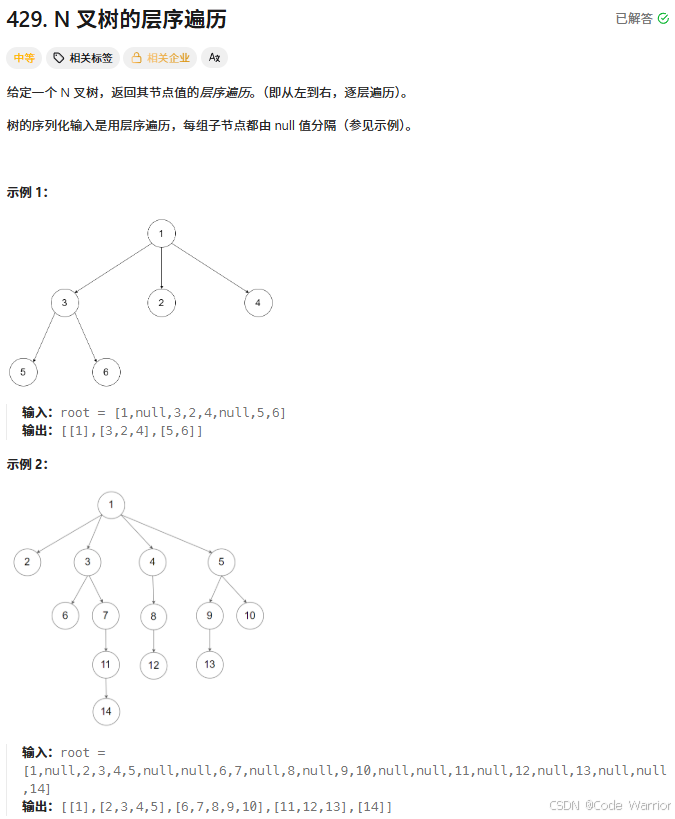
核心思路:队列驱动的层序遍历
这段代码实现了 N 叉树的层序遍历,核心思路是利用队列的 FIFO(先进先出)特性 逐层处理节点。具体步骤如下:
- 初始化队列:将根节点放入队列。
- 循环处理每一层:
- 记录当前层节点数
sz(即队列当前长度)。 - 创建当前层的临时数组
tmp。 - 遍历当前层所有节点:
- 从队列取出节点,将值加入
tmp。 - 将该节点的所有子节点依次入队(确保下一层节点被加入队列尾部)。
- 从队列取出节点,将值加入
- 将当前层结果
tmp加入最终结果ret。
- 记录当前层节点数
- 返回结果:当队列为空时,所有层处理完毕。
关键点
- 层级控制:通过
sz锁定当前层的节点数,确保每次循环处理完一层的所有节点。 - 队列的作用:
- 出队:处理当前层的节点。
- 入队:按顺序存储下一层的节点。
- 适用于 N 叉树:通过
children数组处理任意数量的子节点。
复杂度分析
- 时间复杂度:O (n),每个节点仅入队 / 出队一次。
- 空间复杂度:O (n),最坏情况下队列同时存储一层的所有节点(例如满二叉树的最后一层)。
vector<vector<int>> levelOrder(Node* root) {vector<vector<int>> ret;queue<Node*> q;if(root == nullptr) return ret;q.push(root);while(q.size()){int sz = q.size();vector<int> tmp;for(int i = 0; i < sz; ++i){Node* t = q.front();q.pop();tmp.push_back(t->val);for(Node* child : t->children)q.push(child);}ret.push_back(tmp);}return ret;}2.2 二叉树的锯齿层序遍历
103. 二叉树的锯齿形层序遍历 - 力扣(LeetCode)
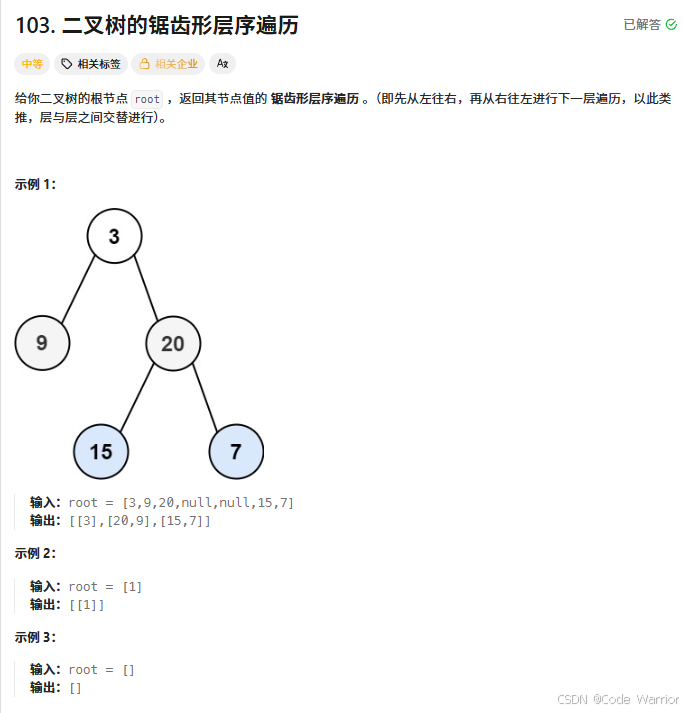
核心思路:基于队列的 zigzag 层序遍历(之字形遍历)
这段代码实现了二叉树的 之字形层序遍历(即相邻层的节点顺序相反:第一层从左到右,第二层从右到左,第三层再从左到右,以此类推),核心思路是利用 队列控制层级 + 双端队列(deque)控制每层顺序。具体步骤如下:
- 初始化队列:将根节点入队,用
flag标记当前层的遍历方向(初始为true,表示从左到右)。 - 循环处理每一层:
- 记录当前层节点数
sz(锁定当前层的节点范围)。 - 创建双端队列
tmp(支持头部和尾部插入,灵活控制顺序)。 - 遍历当前层所有节点:
- 从队列取出节点。
- 根据
flag决定插入方向:flag = true时,从尾部插入(push_back),保持左到右顺序。flag = false时,从头部插入(push_front),实现右到左顺序。
- 将节点的左右子节点依次入队(确保下一层节点按正常顺序存储)。
- 转换并保存当前层结果:将
tmp转为vector<int>后加入最终结果ret。 - 翻转方向标记:
flag = !flag,下一层使用相反顺序。
- 记录当前层节点数
- 返回结果:队列为空时,所有层处理完毕。
关键点
- 队列的作用:控制层级顺序,确保按层依次处理节点(与普通层序遍历一致)。
- 双端队列的作用:通过头部 / 尾部插入,在不改变子节点入队顺序的前提下,灵活反转当前层的输出顺序。
- 方向标记
flag:切换相邻层的遍历方向,实现 “之字形” 效果。
复杂度分析
- 时间复杂度:O (n),每个节点仅入队 / 出队一次,双端队列的插入操作是 O (1)。
- 空间复杂度:O (n),队列和双端队列最多同时存储一层的所有节点。
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {vector<vector<int>> ret;queue<TreeNode*> q;if(root == nullptr) return ret;q.push(root);bool flag = true;while(q.size()){int sz = q.size();deque<int> tmp;for(int i = 0; i < sz; ++i){TreeNode* t = q.front();q.pop();if(flag) // 左向右tmp.push_back(t->val);else // 右向左tmp.push_front(t->val);if(t->left)q.push(t->left);if(t->right)q.push(t->right);}ret.push_back(vector<int>{tmp.begin(), tmp.end()});flag = !flag;} return ret;}2.3 二叉树最大宽度
662. 二叉树最大宽度 - 力扣(LeetCode)
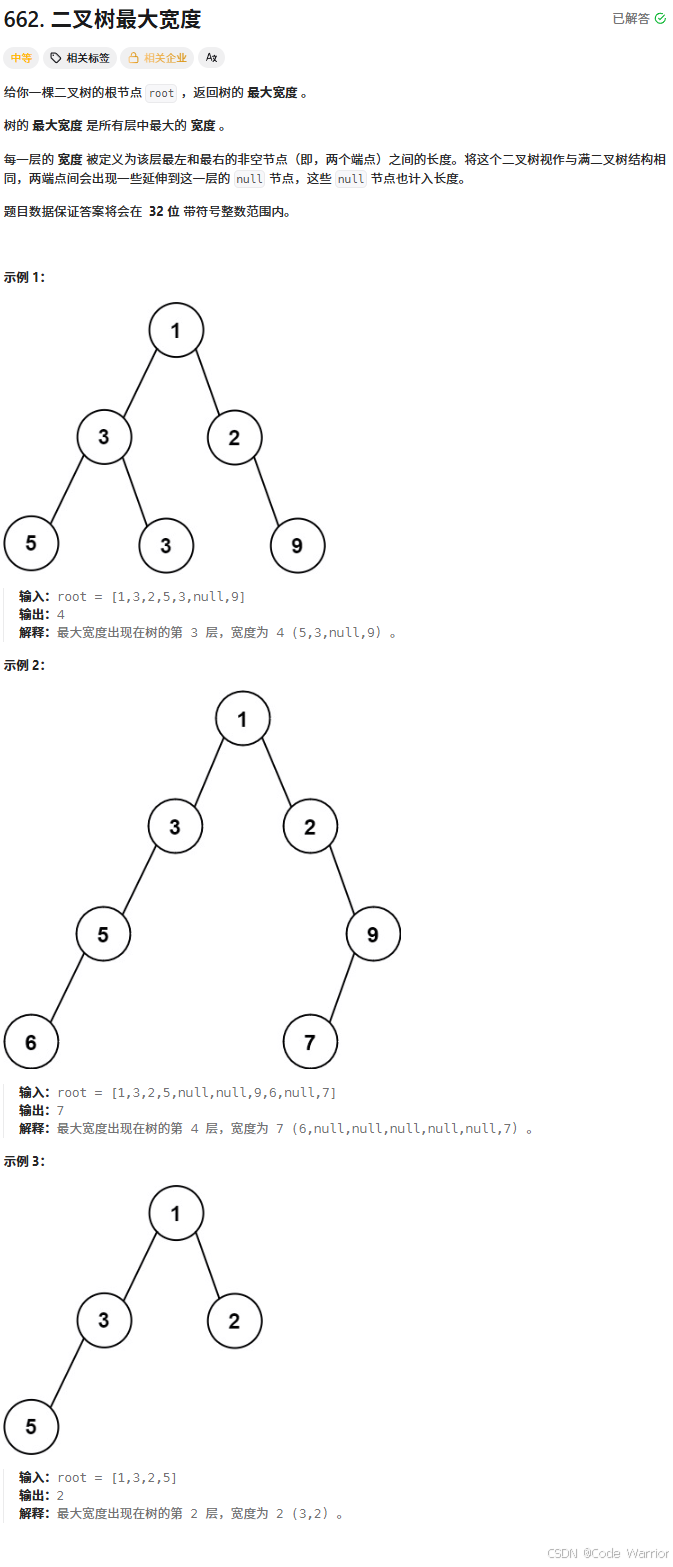
核心思路:二叉树最大宽度计算(层序遍历 + 节点编号)
这段代码实现了计算二叉树的最大宽度(即任意层的最左节点和最右节点之间的跨度,包含空节点),核心思路是通过层序遍历 + 节点编号来确定每层的宽度。具体步骤如下:
-
队列初始化:用
vector<pair<TreeNode*, unsigned int>>存储节点及其编号(根节点编号为0)。编号规则为:若父节点编号为x,则其左子节点编号为2x,右子节点编号为2x+1。 -
循环处理每一层:
- 计算当前层宽度:当前层的宽度为队列中首尾节点的编号之差 + 1(即
x2 - x1 + 1),更新全局最大宽度ret。 - 生成下一层节点:遍历当前层所有节点,将每个节点的子节点(若存在)及其编号加入临时队列
tmp:- 左子节点:编号为
2 * x - 右子节点:编号为
2 * x + 1
- 左子节点:编号为
- 更新队列:用临时队列
tmp替换当前队列q,进入下一层循环。
- 计算当前层宽度:当前层的宽度为队列中首尾节点的编号之差 + 1(即
-
返回结果:遍历完所有层后,
ret即为二叉树的最大宽度。
关键点
- 节点编号:通过编号计算每层宽度,避免直接统计节点数(处理空节点的关键)。
- 层序遍历:确保按层处理节点,计算每层的首尾跨度。
- 容器选择:
- 方法一:用
vector存储每层节点,遍历后整体替换(更高效)。 - 方法二:用
erase删除队首元素(性能较差,因vector的头部删除是 O (n))。
- 方法一:用
- 数据类型:使用
unsigned int避免编号溢出(某些极端二叉树的编号可能非常大)。
复杂度分析
- 时间复杂度:O (n),每个节点仅处理一次。
- 空间复杂度:O (n),队列最多存储一层的所有节点。
int widthOfBinaryTree(TreeNode* root) {int ret = 0;vector<pair<TreeNode*, unsigned int>> q; // 用vector可以进行下标访问,取第一个和最后一个数if(root == nullptr) return ret;q.push_back({root, 0});while(q.size()){// 计算每层的最大宽度auto& [y1, x1] = q[0];auto& [y2, x2] = q.back();ret = max(ret, (int)(x2 - x1 + 1));// 层序遍历// 法一vector<pair<TreeNode*, unsigned int>> tmp;for(auto& [y3, x3] : q){if(y3->left)tmp.push_back({y3->left, 2 * x3});if(y3->right)tmp.push_back({y3->right, 2 * x3 + 1});}// 法二,注意的是频繁的头部删除应该选用deque做容器n(1)//int sz = q.size();// while(sz--)// {// auto [y3, x3] = q[0];// q.erase(q.begin());// if(y3->left)// q.push_back({y3->left, 2 * x3});// if(y3->right)// q.push_back({y3->right, 2 * x3 + 1});// }q = tmp;}return ret;}
2.4 在每个树行中找最大值
515. 在每个树行中找最大值 - 力扣(LeetCode)
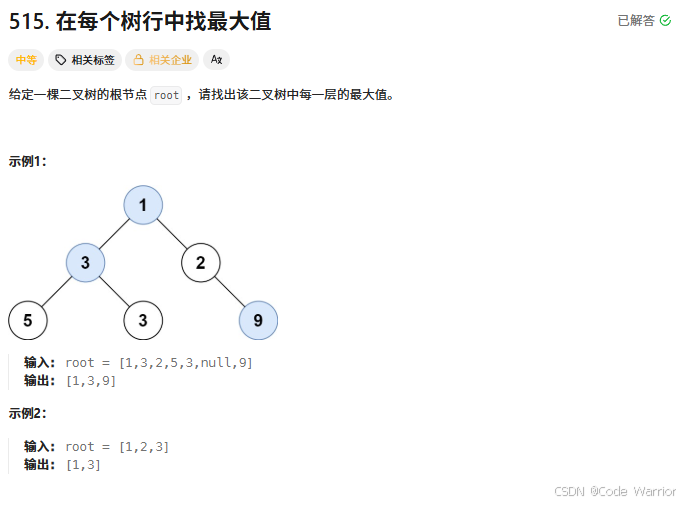
核心思路:二叉树每层最大值(层序遍历 + 分组统计)
这段代码实现了找出二叉树每一层的最大值,核心思路是利用队列进行层序遍历,并在每一层遍历时维护当前层的最大值。具体步骤如下:
-
队列初始化:将根节点加入双端队列
q。 -
循环处理每一层:
- 初始化当前层最大值
ma为INT_MIN。 - 锁定当前层节点数
sz(即队列当前长度)。 - 遍历当前层所有节点:
- 取出队首节点,更新
ma为ma和当前节点值的较大值。 - 将该节点的左右子节点(若存在)加入队列尾部。
- 从队列头部移除当前节点(确保处理完所有当前层节点)。
- 取出队首节点,更新
- 当前层遍历结束后,将
ma加入结果数组ret。
- 初始化当前层最大值
-
返回结果:遍历完所有层后,
ret即为每层的最大值数组。
关键点
- 层级控制:通过
sz锁定当前层的节点数,确保每次循环处理完一层的所有节点。 - 最大值维护:在遍历每层节点时,动态更新当前层的最大值
ma。 - 队列操作:
- 入队:将下一层的节点加入队列尾部。
- 出队:从队列头部取出并移除当前层的节点。
复杂度分析
- 时间复杂度:O (n),每个节点仅入队 / 出队一次。
- 空间复杂度:O (n),最坏情况下队列同时存储一层的所有节点(例如满二叉树的最后一层)。
vector<int> largestValues(TreeNode* root) {vector<int> ret;if(root == nullptr) return ret;deque<TreeNode*> q;q.push_back(root);while(q.size()){int ma = INT_MIN;// deque<TreeNode*> tmp;// for(auto n : q)// {// ma = max(ma, n->val);// if(n->left)// tmp.push_back(n->left);// if(n->right)// tmp.push_back(n->right);// }// q = tmp;int sz = q.size();while(sz--){ma = max(ma, (q.front()->val));// TreeNode* t = q.top();// q.pop();if(q.front()->left)q.push_back(q.front()->left);if(q.front()->right)q.push_back(q.front()->right);q.pop_front();}ret.push_back(ma);}return ret;}