聚类的可视化选择:PCA / t-SNE丨TomatoSCI分析日记
聚类完之后怎么可视化?这个问题很容易被忽略,我也是最近才发现这个问题拿出来跟大家讨论。聚类和可视化是两个独立步骤:聚类负责给样本分组,而可视化负责以合适方式呈现结果。以经典的 K-means 聚类为例,它本身在高维空间中运行,而我们大多数可视化只能展示二维或三维图像,因此必须先进行降维。
降维方法主要分为两类:线性降维(如 PCA) 和 非线性降维(如 t-SNE)。所以常见的可视化组合可以分为两种:
·K-means + PCA → 更易解释
·K-means + t-SNE → 更易观察
下面用同一份数据进行不同的分析。
01 K-means + PCA:可解释性强的组合
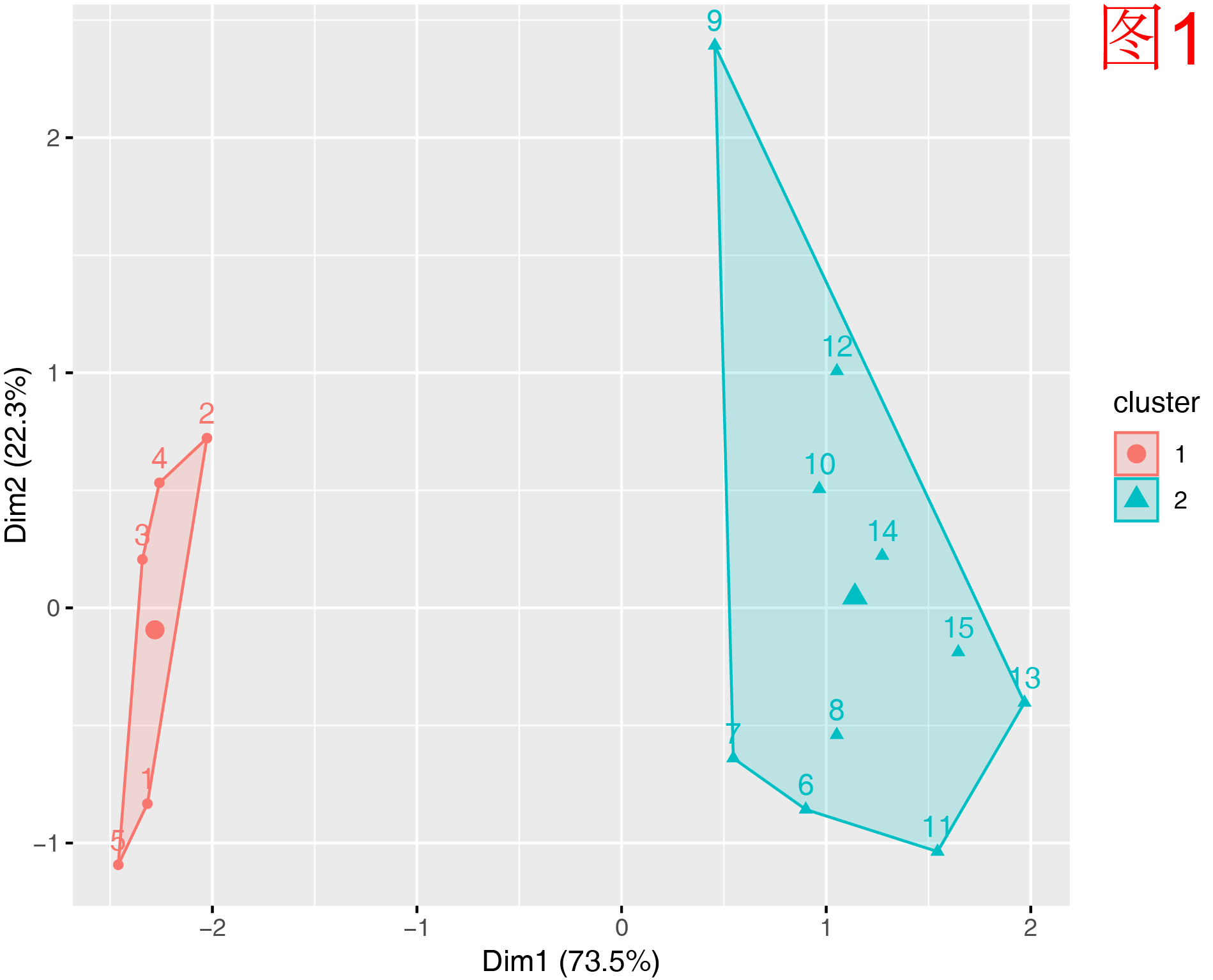
见图1。PCA(主成分分析)是一种线性降维方法,它通过提取数据中方差最大的方向,保留原始数据的全局结构。图中两条轴分别代表前两个主成分,并附带方差解释比例,可以明确知道我们保留了多少信息。
PCA 的优势在于降维后的结果依然保留了数据结构,可继续用于分析。比如:通过主成分载荷,可以识别出哪些变量在不同聚类中起了主要作用,便于解释各簇的特征。
02 K-means + t-SNE:可视化表现更佳的组合
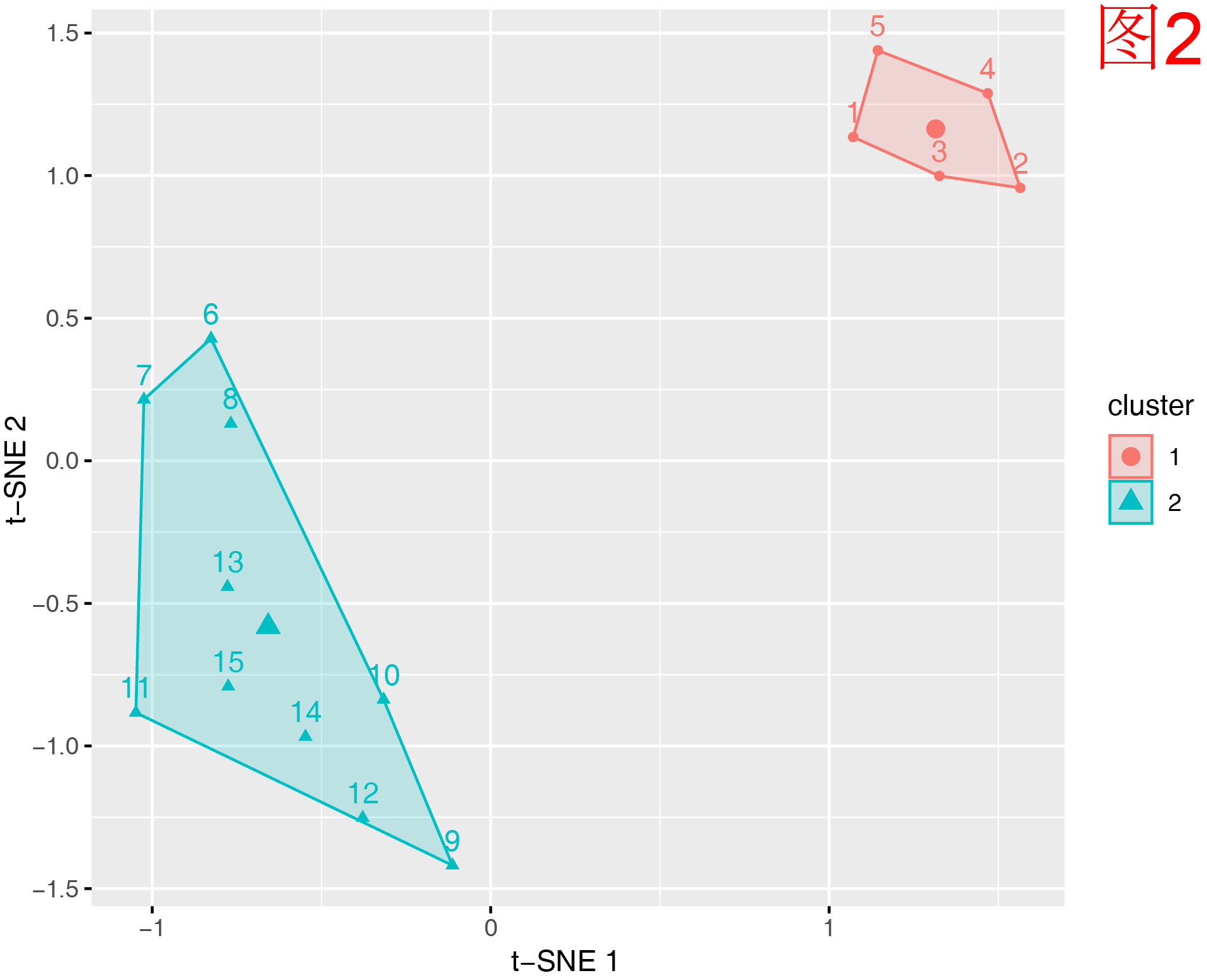
见图2。t-SNE 是一种 非线性降维方法,它擅长保留数据点之间的局部相似性,使原本在高维空间中接近的点在低维空间中仍然靠近,从而呈现出更加清晰的聚类结构。
与 PCA 不同,t-SNE 投影的坐标轴没有实际意义,也无法告诉我们保留了多少原始信息。它不能用于后续分析和建模,因为降维过程扭曲了数据的距离关系。但它的图像表现通常更好,特别是在高维图像特征、文本嵌入、单细胞数据等领域,能够明显展示类群边界。
03 如何选择可视化方式?
如果你觉得上述原理还是不好区分,记住以下三点也能帮你快速决策:
1. 如果你还想进一步解释变量含义或分析主轴结构,优先选 PCA;
2. 如果你只是想让分群效果清晰可见、图好看,选 t-SNE;
3. 拿不准可以两种都做一遍,选效果更清晰的。
有的小伙伴可能会问,又线性又非线性的,前面K-means结果的作用是什么?
聚类结果是基于高维空间做出的,是一个“先做好的分组标签”;而降维后的可视化,仅是为了把这些标签更直观地展示出来,所以:聚类是核心结论;降维是辅助表现形式。你可以把聚类结果看作一位模特,PCA 是正面写实肖像,t-SNE 是创意光影写真,你可以根据展示目的选择不同“摄影风格”来讲述这个数据故事。
K-means聚类和t-SNE可视化已经上线TomatoSCI科研数据分析平台,欢迎大家来访!数据分析无需登录,专业在线客服答疑,还可在线传输文件,五折优惠码“tomatosci”开放使用中。PCA、RDA、PCoA、Lasso回归等方法等你就位。
