Kafka 控制器(Controller)详解:架构、原理与实战
目录
- Kafka 控制器(Controller)详解:架构、原理与实战
- 一、控制器的核心职责
- 1. 元数据管理
- 2. 分区状态机
- 3. 故障恢复
- 4. 集群操作协调
- 二、传统 ZooKeeper 模式下的控制器
- 1. 控制器选举机制
- 2. 控制器与 ZooKeeper 的交互
- 3. 潜在问题
- 三、KRaft 模式下的控制器
- 1. 架构革新
- 2. 控制器节点配置
- 3. Raft 协议实现
- 4. 优势
Kafka 控制器(Controller)详解:架构、原理与实战
Kafka 控制器是集群的核心组件,负责管理元数据、协调分区状态和故障恢复。本文将深入解析控制器的工作原理、配置要点及运维实践,帮助你全面掌握这一关键组件。
一、控制器的核心职责
1. 元数据管理
- 集群拓扑维护:跟踪所有 broker 的加入与离开,维护 broker 列表。
- Topic 与分区管理:管理 Topic 的创建、删除、分区扩缩容,记录分区副本分配方案。
- 状态同步:将元数据变更同步到所有 broker,确保集群视图一致。
2. 分区状态机
- Leader 选举:当分区 Leader 故障时,控制器负责选举新的 Leader。
- 副本状态转换:管理副本的状态(如 Online、Offline、New 等),确保数据一致性。
3. 故障恢复
- Broker 崩溃检测:通过 ZooKeeper(传统模式)或控制器心跳(KRaft 模式)检测 broker 故障。
- 分区重分配:当 broker 故障时,重新分配受影响的分区副本,保证高可用。
4. 集群操作协调
- 配置变更:处理动态配置变更(如调整 Topic 参数)。
- 集群扩容/缩容:协调 broker 加入或离开时的分区迁移。
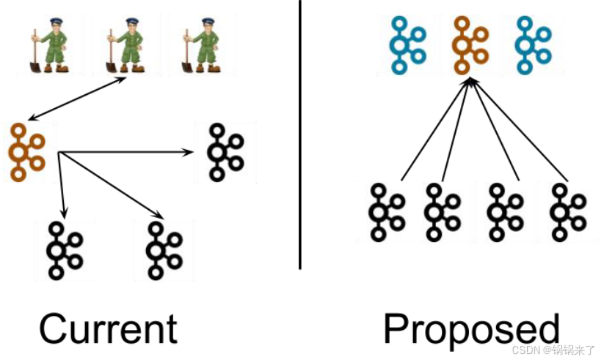
左图为 Kafka 架构,元数据在 zookeeper 中,运行时动态选举 controller,由 controller 进行 Kafka 集群管理。
右图为 kraft 模式架构(实验性),不再依赖 zookeeper 集群,而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
二、传统 ZooKeeper 模式下的控制器
1. 控制器选举机制
- 首次启动:第一个成功在 ZooKeeper 上创建
/controller临时节点的 broker 成为控制器。 - 故障转移:当控制器所在 broker 崩溃时,
/controller节点消失,其他 broker 监听此节点变化,通过竞争创建新节点成为新控制器。
2. 控制器与 ZooKeeper 的交互
- 注册监听:控制器监听 ZooKeeper 中的关键路径(如
/brokers/ids、/brokers/topics)。 - 元数据存储:控制器从 ZooKeeper 读取元数据,并同步到其他 broker。
- 会话管理:控制器通过 ZooKeeper 会话保持活跃状态,会话超时(默认 6 秒)则触发重新选举。
3. 潜在问题
- 脑裂风险:网络分区可能导致多个 broker 同时认为自己是控制器。
- 性能瓶颈:ZooKeeper 不适合高频写入,大规模集群中元数据变更可能成为瓶颈。
- 运维复杂度:需额外维护 ZooKeeper 集群,增加故障点。
三、KRaft 模式下的控制器
1. 架构革新
- 移除 ZooKeeper 依赖:控制器通过内置的 Raft 协议自主管理元数据,无需外部协调服务。
- 多节点控制器集群:支持 3-5 个控制器节点组成集群,通过 Raft 达成共识,提升可用性。
2. 控制器节点配置
关键参数:
# server.properties
process.roles=controller # 或同时作为 broker: broker,controller
controller.quorum.voters=1@controller1:9093,2@controller2:9093,3@controller3:9093
controller.listener.names=CONTROLLER
inter.broker.listener.name=PLAINTEXT
3. Raft 协议实现
- Leader 选举:控制器集群通过 Raft 协议选举 Leader,负责处理元数据变更。
- 日志复制:元数据变更记录为 Raft 日志,复制到多数节点后才被提交。
- 故障恢复:当 Leader 故障时,剩余节点重新选举 Leader,继续服务。
4. 优势
- 简化架构:减少外部依赖,降低运维复杂度。
- 高性能:Raft 协议比 ZooKeeper 更适合高频元数据变更。
- 更强一致性:Raft 提供线性一致性保证,避免脑裂问题。