小白学Python,网络爬虫篇(1)——requests库
目录
一、网络爬虫的介绍
1.网络爬虫库
2.robots.txt 规则
二、requests 库和网页源代码
1.requests 库的安装
2.网页源代码
三、获取网页资源
1.get () 函数
(1)get() 搜索信息
(2)get() 添加信息
2.返回 Response 对象
(1)Response 的属性
(2)设置编码
(3)返回网页内容
一、网络爬虫的介绍
1.网络爬虫库
网络爬虫通俗来讲就是使用代码将 HTML 网页的内容下载到本地的过程。爬取网页主要是为了获取网页中的关键信息,例如网页中的数据、图片、视频等。Python 语言中提供了多个具有爬虫功能的库,下面将具体介绍。
urllib 库:是 Python 自带的标准库,无须下载、安装即可直接使用。urllib 库中包含大量的爬虫功能,但其代码编写略微复杂。
requests 库:是 Python 的第三方库,需要下载、安装之后才能使用。由于 requests 库是在 urllib 库的基础上建立的,它包含 urllib 库的功能,这使得 requests 库中的函数和方法的使用更加友好,因此 requests 库使用起来更加简洁、方便。
scrapy 库:是 Python 的第三方库,需要下载、安装之后才能使用。scrapy 库是一个适用于专业应用程序开发的网络爬虫库。scrapy 库集合了爬虫的框架,通过框架可创建一个专业爬虫系统。
selenium 库:是 Python 的第三方库,需要下载、安装后才能使用。selenium 库可用于驱动计算机中的浏览器执行相关命令,而无须用户手动操作。常用于自动驱动浏览器实现办公自动化和 Web 应用程序测试。
本章主要介绍 requests 库和 selenium 库。
2.robots.txt 规则
在正式学习网络爬虫之前,需要掌握爬取规则,不是网站中的所有信息都允许被爬取,也不是所有的网站都允许被爬取。在大部分网站的根目录中存在一个 robots.txt 文件,该文件用于声明此网站中禁止访问的 url 和可以访问的 url。用户只需在网站域名后面加上 /robots.txt 即可读取此文件的内容。
例如要获取豆瓣官网中的 robots.txt 文件,打开浏览器输入豆瓣官网域名并在域名后加上 /robots.txt,按 Enter 键即可,如图所示。豆瓣官网的主域名下存在大量的子域名,例如某个电影的影评 url 是在主域名的基础上增加子目录,其形式与磁盘中的目录路径相同。
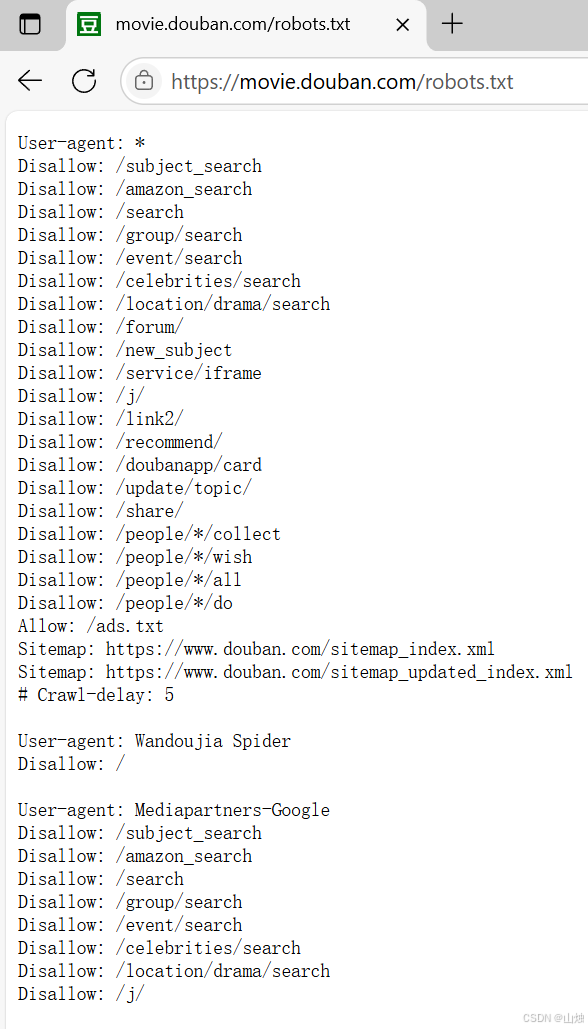
robots.txt 规则用于表明当前网站中的哪些内容是可以访问的,哪些内容是禁止访问的。接下来具体介绍 robots.txt 文件的内容。
User-agent:表示访问网站的搜索引擎,如图中一共存在 3 个 User-agent 内容,第 1 个 User-agent 的值为 *,表示所有类型的搜索引擎都需要遵守第 2~21 行的规则。第 2 个 User-agent 的值为 Wandoujia Spider,表示 Wandoujia Spider 搜索引擎需要遵守的规则。第 3 个 User-agent 的值为 Mediapartners-Google,表示Mediapartners-Google 搜索引擎需要遵守的规则。
Disallow:表明该搜索引擎不允许访问的 url。例如图中的 /subject_search,表明豆瓣官网根目录下的 /subject_search 是不允许被访问的,读者可以尝试使用浏览器访问此 url 并观察结果。当 Disallow 的值为 / 时,表明不允许此搜索引擎访问网站的任何内容。例如图所示的 Wandoujia Spider 搜索引擎就不能访问豆瓣官网中的任何信息。
Allow:表明允许该搜索引擎访问的 url。例如图中的 /ads.txt 是允许被任何搜索引擎访问的。
Sitemap:网站地图,用于提供网站中所有可以被爬取的 url,方便搜索引擎能够快速爬取到对应网页。
#:表明注释,与 Python 中的注释概念相同。Crawl - delay:5 用于提醒用户在使用爬虫工具时,每次访问之间需要延迟 5 秒钟,这是为了避免因用户频繁访问而导致服务器拥挤,使得用户无法正常使用浏览器。每个网站在同一时间内有访问上限,超过上限将导致新用户无法访问,例如在 “双十一” 期间会有大量用户访问同一个购物网站,这时候如果使用爬虫工具频繁访问该网站,且爬虫工具是由代码实现的,访问速度将会非常快,就可能导致网站拥堵,使用户无法正常进入网站,还可能造成商家的经济损失。
因此读者在使用爬虫工具访问某网站时,需要先阅读网站的 robots.txt 规则并严格遵守此规则。但有些网站并没有设定 robots.txt 规则,例如访问人民邮电出版社官网的 robots.txt 规则的结果如图所示。当网站中没有 robots.txt 规则时,一般默认允许用户使用爬虫工具访问,但仍然要遵守《中华人民共和国网络安全法》等。
二、requests 库和网页源代码
1.requests 库的安装
在命令提示符窗口或终端中执行以下命令:
pip install requests2.网页源代码
用户在使用浏览器访问网页时,往往会忽视网页的源代码,而获取网页中的信息需要从网页的源代码出发。
例如使用Edge浏览器打开人民邮电出版社官网中的期刊页。在网页空白处单击鼠标右键,选择快捷菜单中的 “查看页面源代码” 即可打开当前网页的源代码信息页面,如图所示。
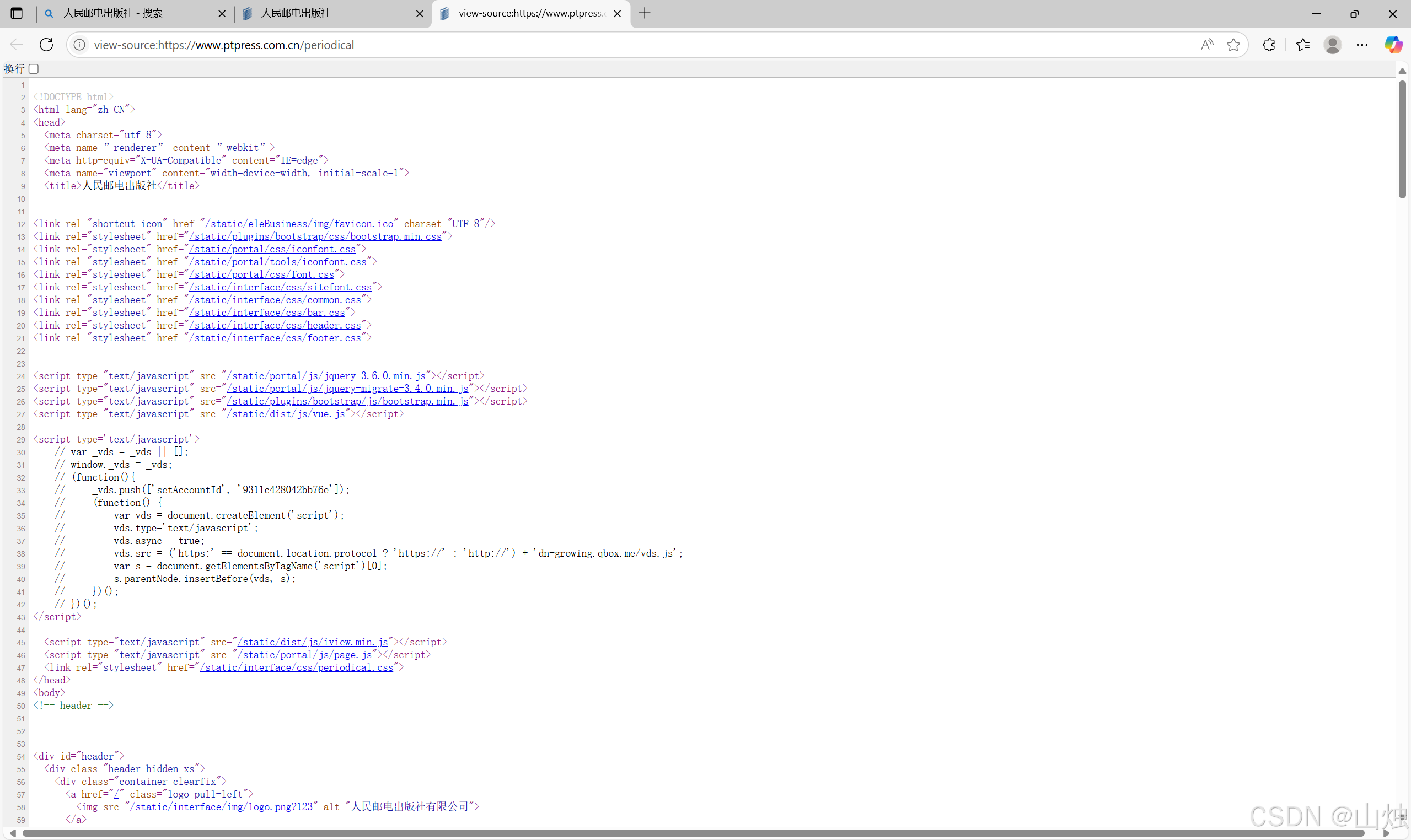
网页中的源代码形式与 HTML 代码形式基本相同,读者可尝试阅读网页中的源代码。通过源代码可以轻松地获取网页中的文字、图片、视频等信息,还可以获取图片或视频文件的 url 并将文件下载到本地。
而一个网页除了 HTML 代码还包含 JavaScript 脚本语言代码,JavaScript 脚本语言代码使得浏览器可以解析和渲染网页源代码,使得用户可以浏览到图形化界面,而不是阅读纯文本代码。网页中有大量数据是包含在 JavaScript 脚本语言代码中的,而通过查看源代码的方式是无法获取这些数据的。例如图中的图片信息在网页源代码中是无法找到的,但可以通过检查(在网页空白处单击鼠标右键,选择快捷菜单中的 “检查” 选项)窗口查看渲染后的网页内容,找到对应图片的 url,如图所示。
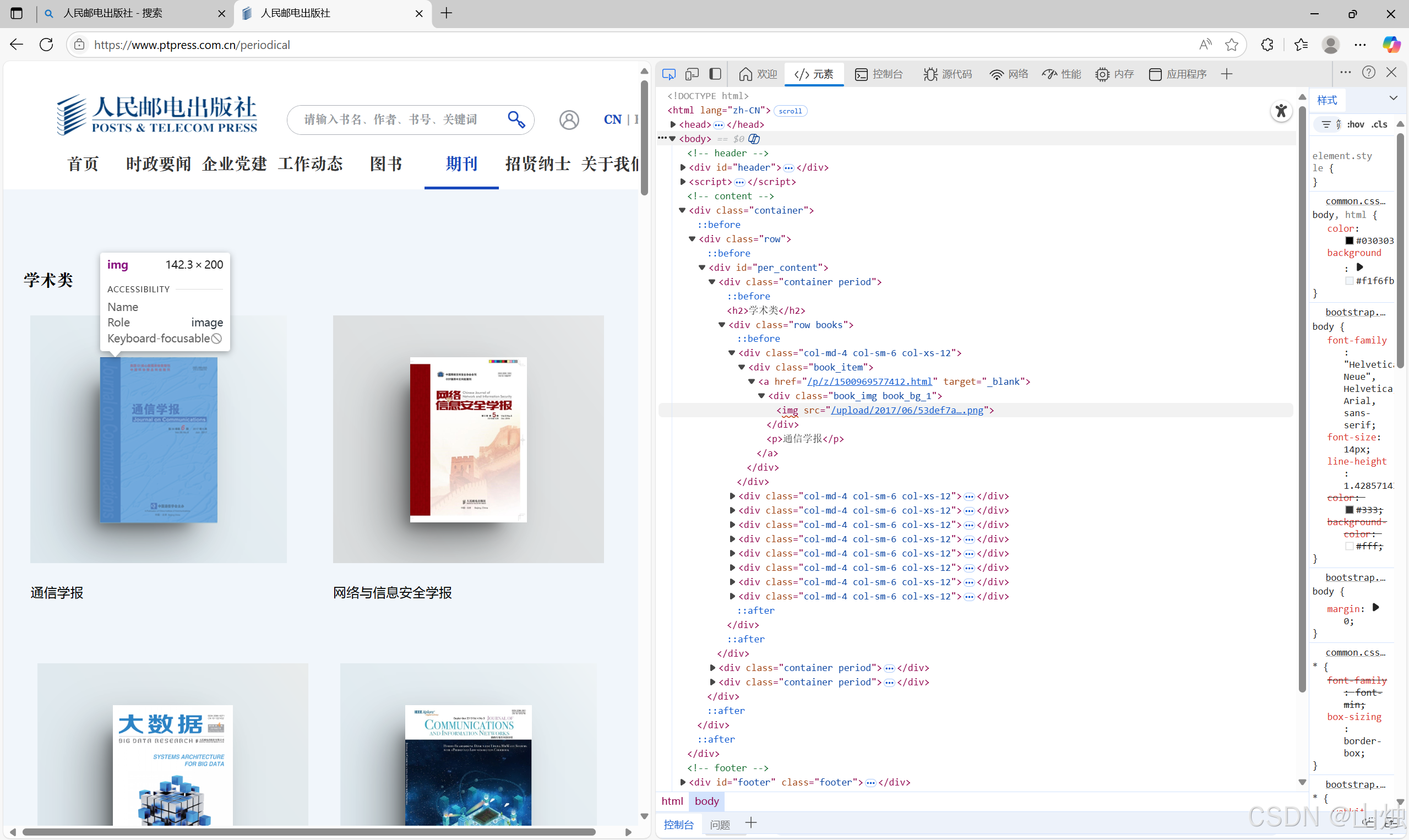
获取人民邮电出版社官网中期刊页的《通信学报》封面图片 url 的步骤如下。
步骤 1,单击检查窗口中的元素选择按钮,如图 15 - 6 所示的标注框所在位置内的图标。
步骤 2,单击网页中的图片位置,检查窗口将会自动跳转到该图片对应的源代码位置。
步骤 3,浅蓝色部分的<img src="/upload/2017/06/53def7a9b43044a1b1afd1991d82a323.png">为图片的源代码内容,其中upload/2017/06/53def7a9b43044a1b1afd1991d82a323.png为图片在网站服务器中的目录地址,完整的 url 只需要在前面加入网站主域名即可。
虽然网站中的内容是动态更新的,但只需按照上面介绍的方法执行即可获取大部分网站中的信息,包括文字、图片、音乐、视频等。
三、获取网页资源
requests 库具有获取网页内容和向网页中提交信息的功能。
1.get () 函数
在 requests 库中获取 HTML 网页内容的方法是使用 get() 函数。其使用形式如下:
get(url, params=None, **kwargs)
- 参数 url:表示需要获取的 HTML 网址(也称为 url)。
- 参数 params:表示可选参数,以字典的形式发送信息,当需要向网页中提交查询信息时使用。
- 参数**kwargs:表示请求采用的可选参数。
- 返回值:返回一个由类 Response 创建的对象。类 Response 位于 requests 库的 models.py 文件中。
示例代码:
import requests
r = requests.get('https://www.ptpress.com.cn/')
print(r.text)
第 1 行代码导入了 requests 库。
第 2 行使用 requests 库中的 get() 函数获取人民邮电出版社的官方网址,并返回一个 Response 对象给变量r。
第 3 行代码使用print()语句输出变量r的text方法,Response 对象中的text方法用于获取相应的文本内容,即网页的源代码。
运行结果:
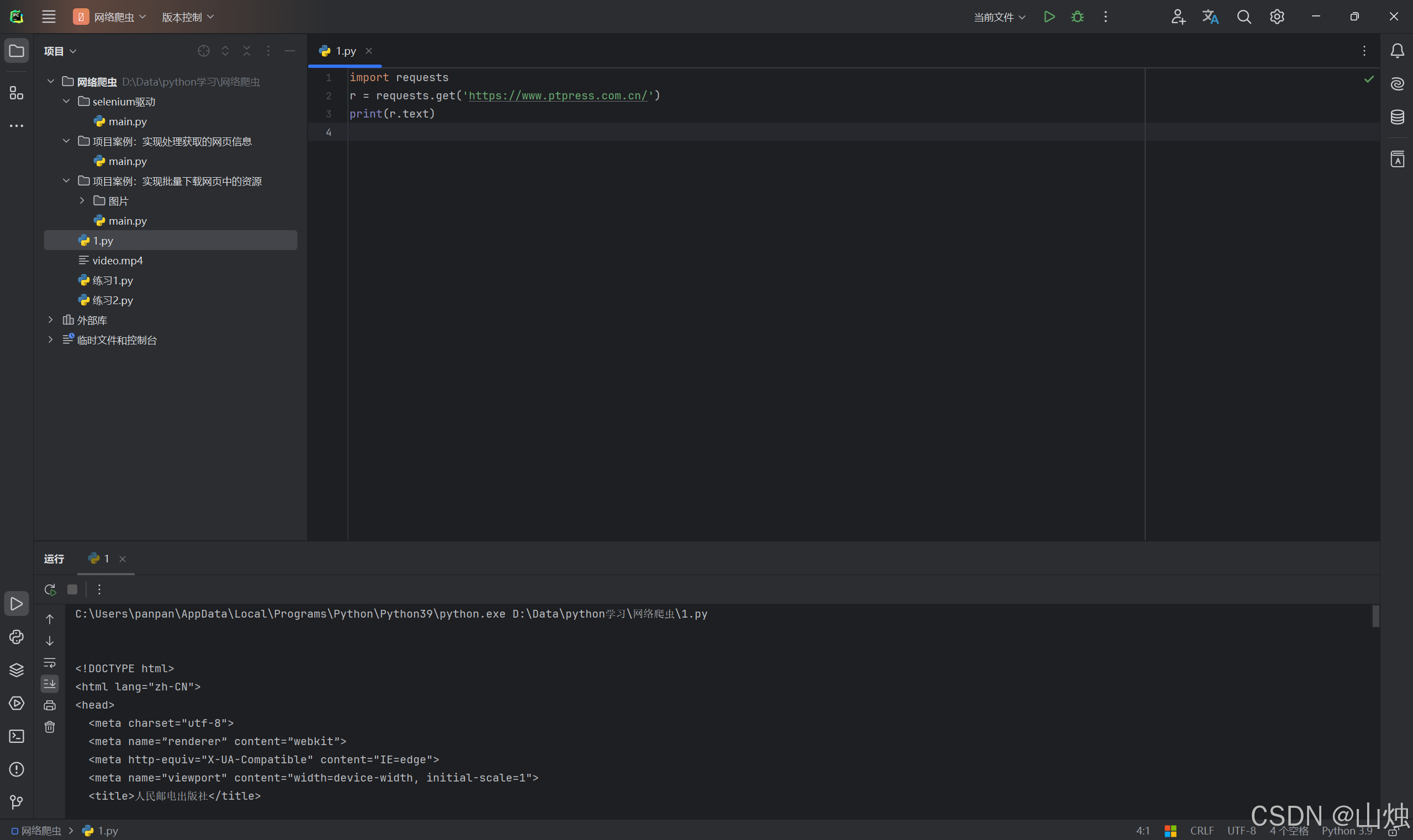
执行代码后的输出结果如图所示。对比使用代码输出的信息和使用浏览器访问的网页源代码,它们的内容是相同的。
(1)get() 搜索信息
当在网页中搜索是人民邮电出版社中的某些指定信息时,可以在图所示的搜索框中输入搜索信息,例如输入关键词"excel",搜索结果如图所示。


从搜索结果网页中可以看到当前页面的网址为https://www.ptpress.com.cn/search?keyword=excel,其中https://www.ptpress.com.cn/为官网主页,search 表示搜索,keyword 表示搜索的关键词(这里值为 excel,表示需要搜索的关键词为 “excel” ),“?” 用于分隔 search 和 keyword。
在其他网页中搜索也有与以上类似的效果,search 或 keyword 可能会用其他字符表示,但基本形式是相同的。读者可在其他网页中进行尝试,例如使用百度的网址 + s?wd=excel 可以搜索到关键词为 “excel” 的内容,其中 s 为 search 的缩写,wd 为 word 的缩写。
在 requests 库中可以充分利用以上方法实现获取网页中的资源。
示例代码:
import requests
r = requests.get('https://www.ptpress.com.cn/search?keyword=word')
print(r.text)
第 2 行代码用于实现在人民邮电出版社官网中搜索关键词为 “word” 的信息。
(2)get() 添加信息
get() 函数中第 2 个参数 params 会以字典的形式在 url 后自动添加信息,需要提前将 params 定义为字典。
示例代码:
import requests
info = {'keyword':'Excel' }
r = requests.get('https://www.ptpress.com.cn/search',params=info)
print(r.url)
print(r.text)
运行结果:
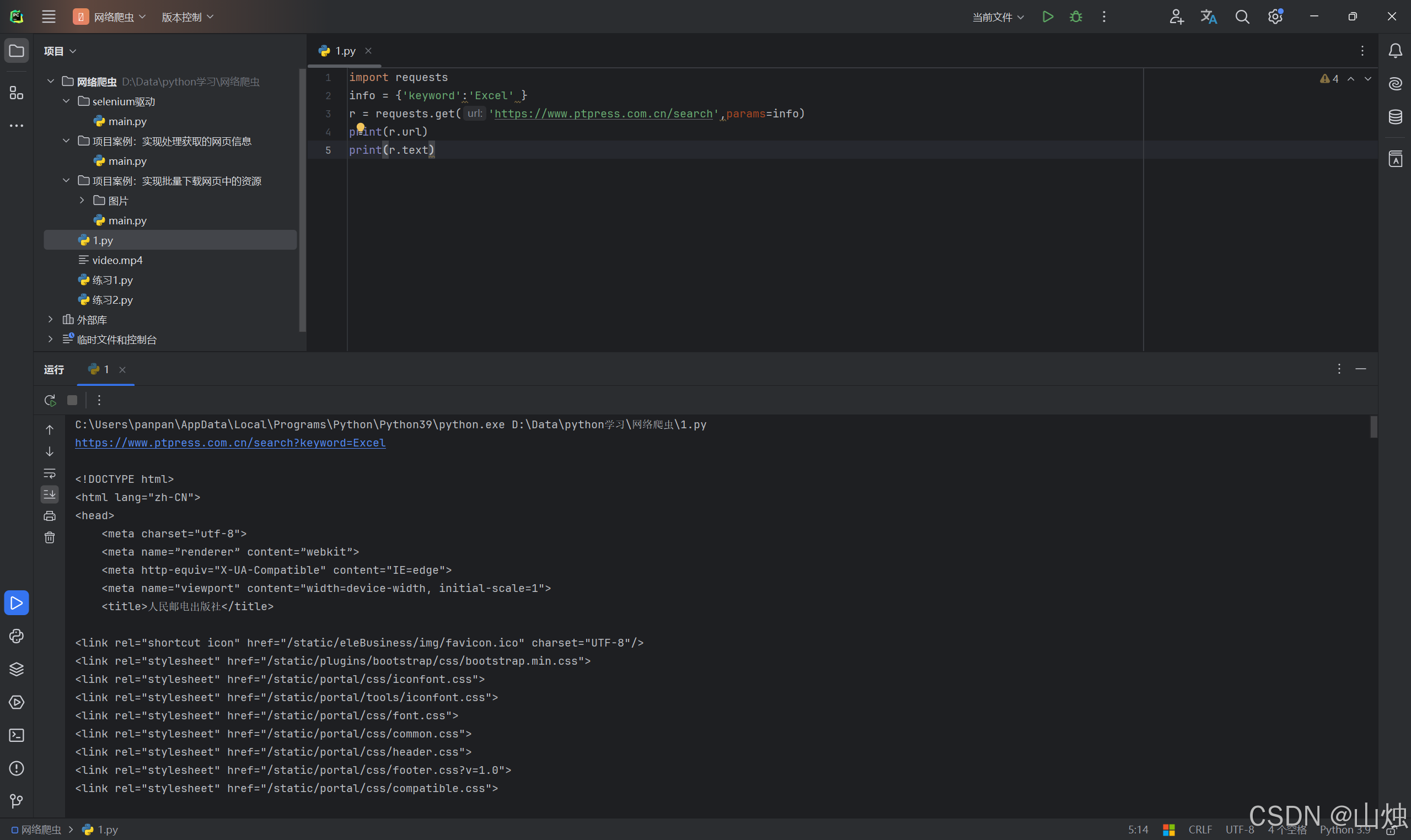
第 2 行代码建立字典 info,包含一个键值对。
第 3 行代码使用 get() 函数获取网页,由于 get() 中包含参数 params,因此系统会自动在 url 后添加字典信息,形式为https://www.ptpress.com.cn/search?keyword=excel,该使用形式便于灵活设定需要搜索的信息,即可以添加或删除字典信息。
第 4 行代码输出返回的 Response 对象中的 url,即获取网页的 url。
2.返回 Response 对象
通过 get () 函数获取 HTML 网页内容后,由于网页的多样性,通常还需要对网页返回的 Response 对象进行设置。本小节将主要讲解类 Response 中的方法。
(1)Response 的属性
Response 包含的属性有 status_code、headers、url、encoding、cookies 等。
status_code(状态码):当获取一个 HTML 网页时,网页所在的服务器会返回一个状态码,表明本次获取网页的状态。例如访问人民邮电出版社官网,当使用 get() 函数发出请求时,人民邮电出版社官网的服务器接收到请求信息后,会先判断请求信息是否合理,如果请求合理则返回状态码 200 和网页信息;如果请求不合理则返回一个异常状态码。
常见的 HTTP(Hypertext Transfer Protocol,超文本传送协议)状态码有 200(请求成功)、301(网页内容被永久转移到其他 url)、404(请求的网页不存在)、500(内部服务器错误)等,更多状态码可以使用搜索引擎查询。
因此在使用 get() 函数请求访问网页时,为了确保获取正确的网页信息,需要判断服务器返回的状态码是否为 200。Response 对象中的 status_code 为服务器返回的状态码。
示例代码:
import requests
r = requests.get('https://www.ptpress.com.cn')
print(r.status_code)
if r.status_code == 200:print(r.text)
else:print('本次访问失败')
第 3 行代码输出 Response 对象返回的状态码。第 4 行代码用于判断状态码是否为 200,如果为 200,则输出获取的网页内容,否则表明访问存在异常。
headers(响应头):服务器返回的附加信息,主要包括服务器传递的数据类型、使用的压缩方法、语言、服务器的信息、响应该请求的时间等。
url:响应的最终 url 位置。
encoding:访问 r.text 时使用的编码。
cookies:服务器返回的文件。这是服务器为辨别用户身份,对用户操作进行会话跟踪而存储在用户本地终端上的数据。
(2)设置编码
当访问一个网页时,如果获取的内容是乱码。这是由网页读取编码错误导致的,可以通过设置requests.get(url)返回的 Response 对象的encoding='utf - 8'来修改 “Response 对象.text” 文本内容的编码方式。同时 Response 对象中提供了apparent_encoding()方法来自动识别网页的编码方式,不过由于此方法是由机器自动识别,因此可能会存在识别错误的情况(大部分情况下是可用的)。
如果要设置自动识别网页的编码方式,可以使用以下形式:
Response对象.encoding = Response对象.apparent_encoding
示例代码:
import requests
r = requests.get('此处填入‘百度官网地址’.com')
r.encoding = r.apparent_encoding
print(r.text)
第 3 行代码设置自动识别网页的编码方式,执行代码后的输出结果中将包含可识别的文字,而不再是乱码。当设置自动识别编码方式后依然出现内容乱码时,读者需要自行设置encoding编码方式。
(3)返回网页内容
Response 对象中返回网页内容有两种方法,分别是 text() 方法和 content() 方法,其中 text() 方法在前面的内容中有介绍,它是以字符串的形式返回网页内容。而 content() 方法是以二进制的形式返回网页内容,常用于直接保存网页中的媒体文件。
示例代码(下载人民邮电出版社官网中的图片):
import requests
r = requests.get('https://cdn.ptpress.cn/uploadimg/Material/978-7-115-41359-8/72jpg/41359.jpg')
f2 = open('b.jpg','wb')
f2.write(r.content)
f2.close()
第 2 行代码使用 get() 方法访问了图片 url。
第 3 行代码使用 open() 函数创建了一个b.jpg文件,并且设置以二进制写入的模式。
第 4 行代码将获取的 url 内容以二进制形式写入文件。
执行代码后将在相应文件夹中存储一张图片,如图所示。
运行结果:
