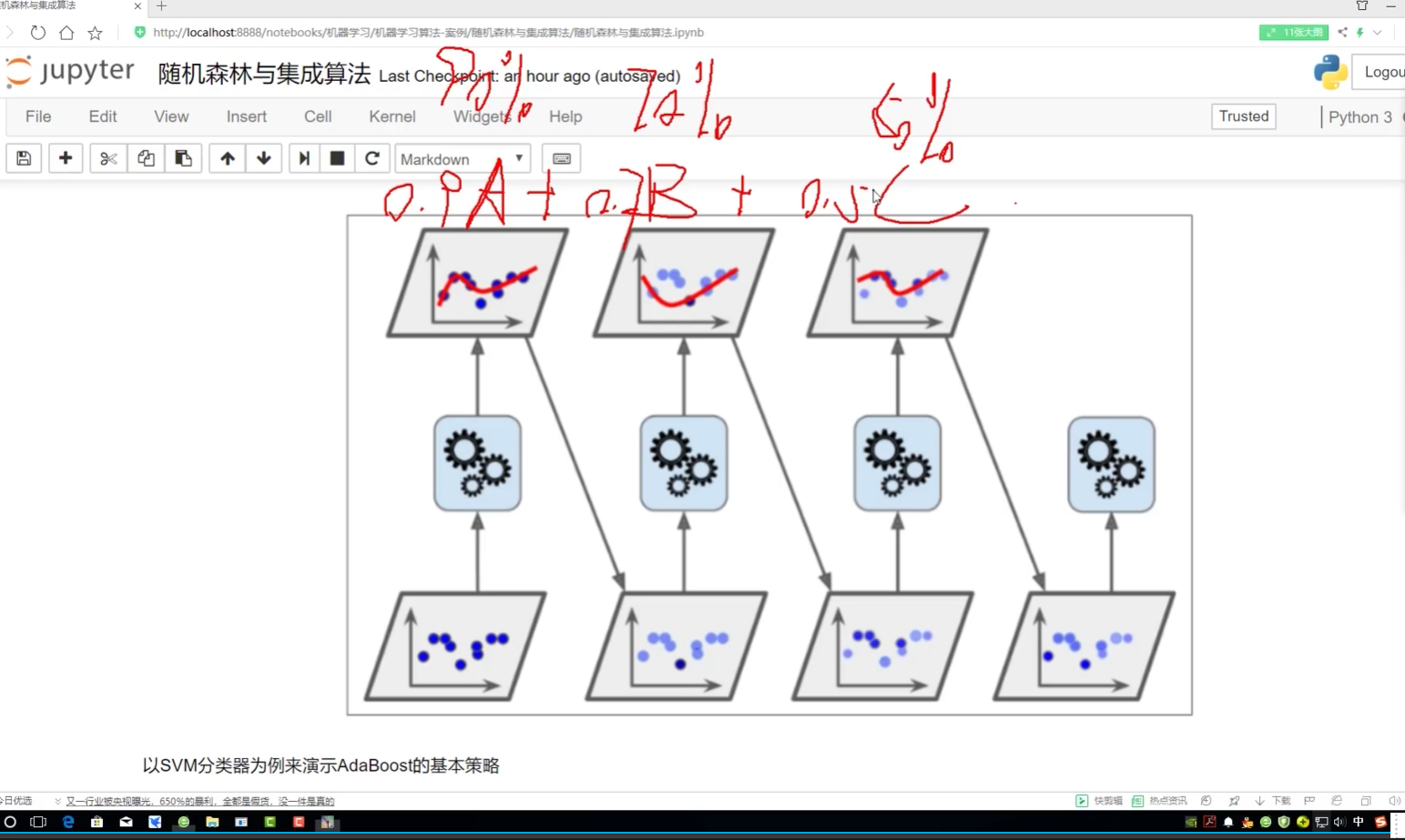
集成算法学习学习
Project Jupyter | Home
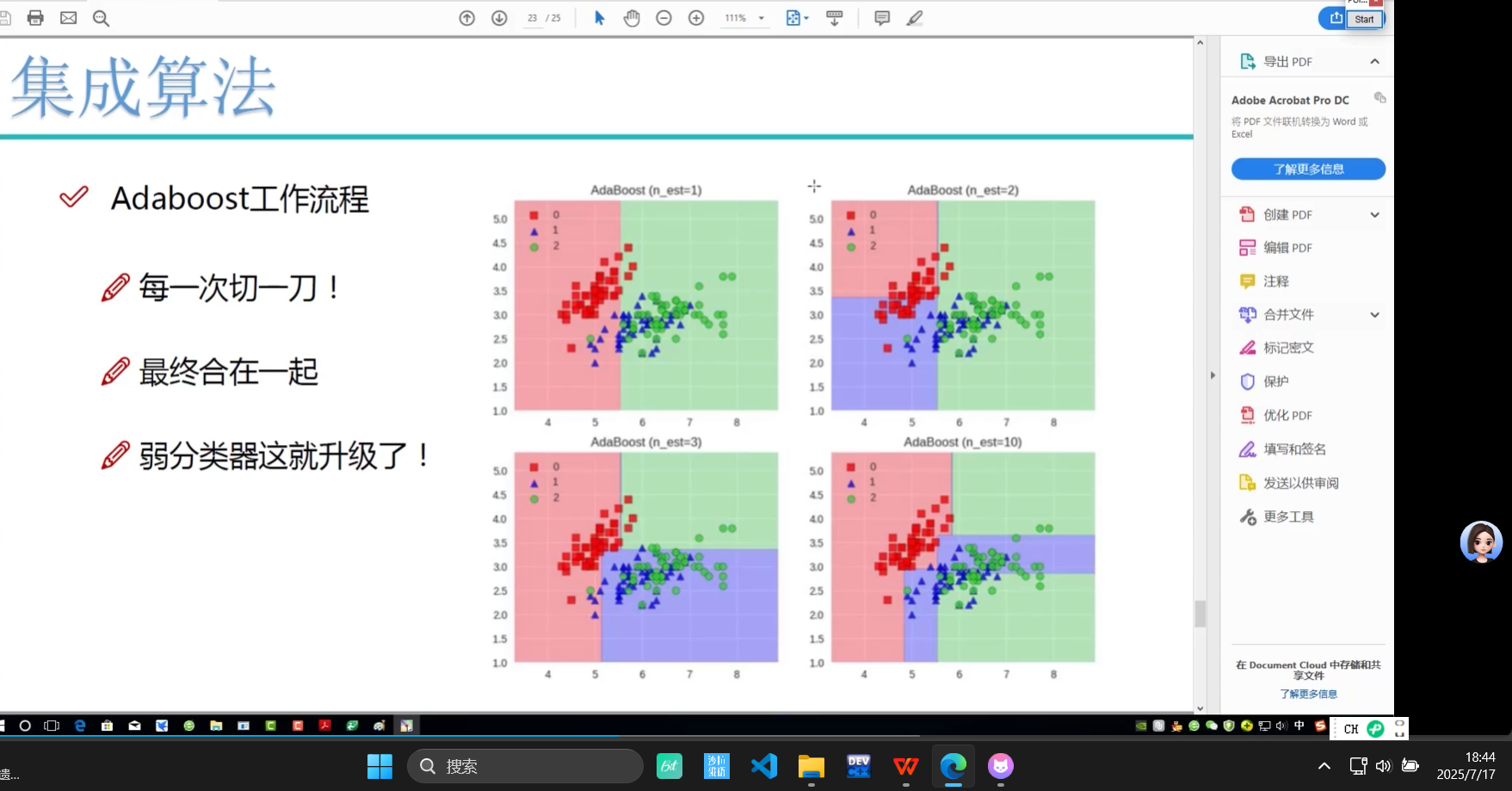
教程8-Adaboost决策边界效果_哔哩哔哩_bilibili
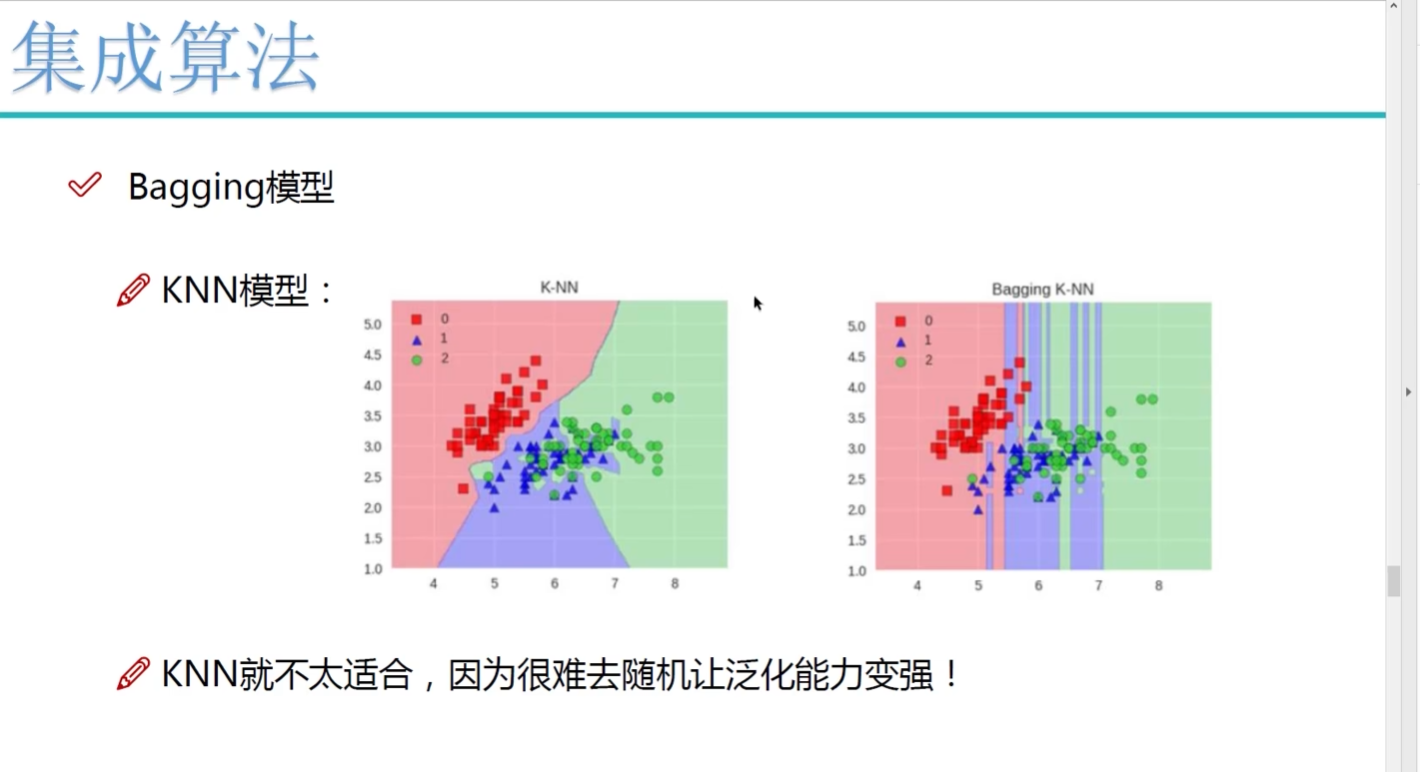
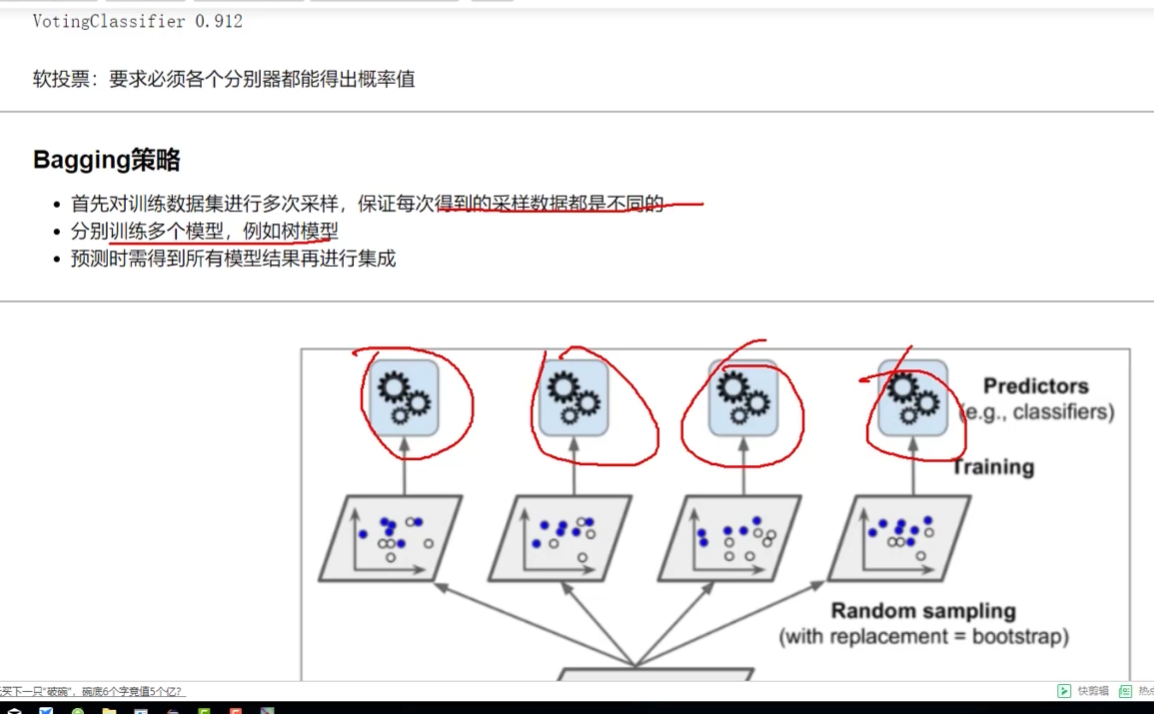
Bagging:取平均
随机森林是典型

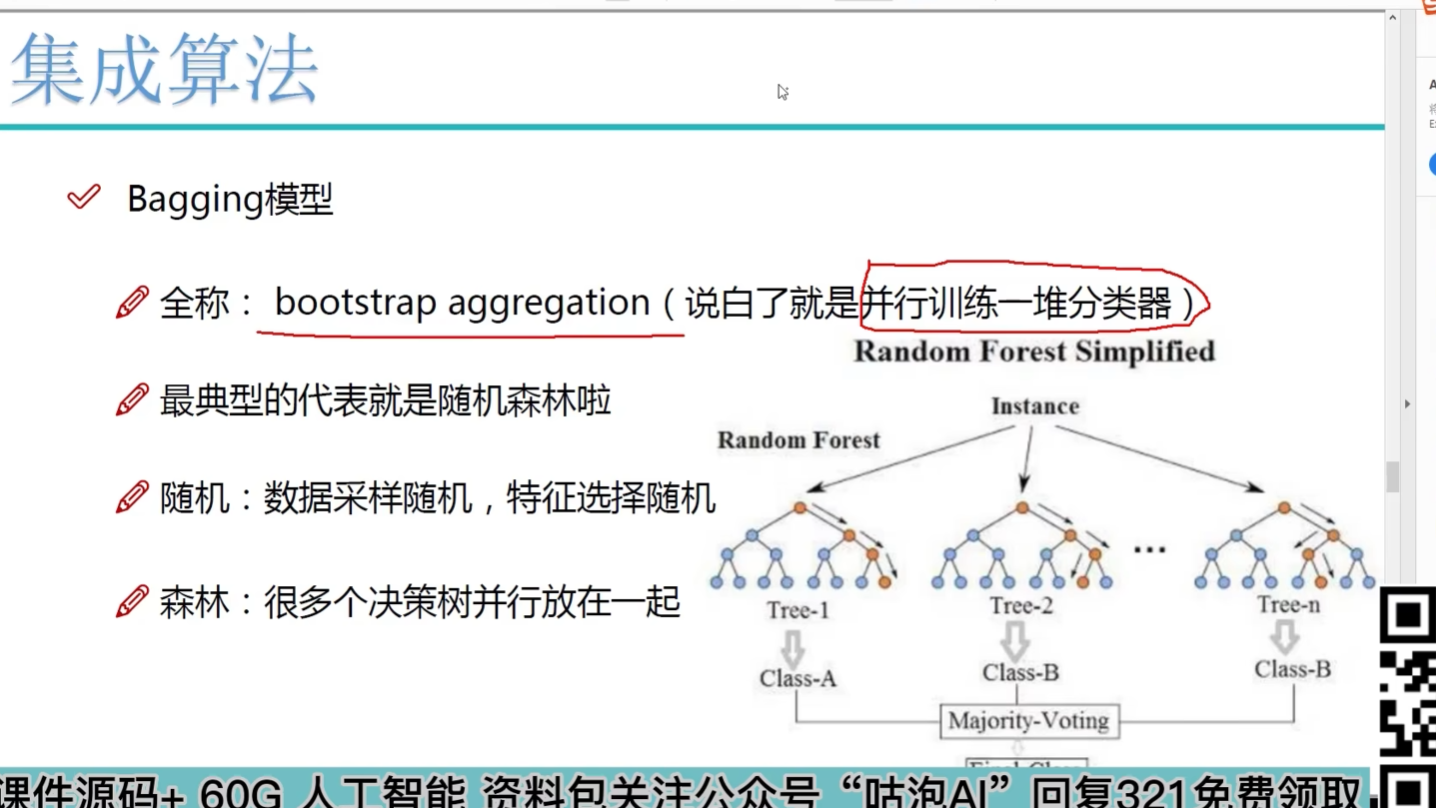
随机:随机样本采样 随机特征采样 自己测试不同比例值
森林:并行训练一对分类器(树) 多个树加在一起去平均
多样性
二重:数据随机采样--

先取100个样本: 80的部分1 80的部分2
再取100个里面的10个:6个分到部分1 6个分到部分2 (不同特征值)
树不一样 根节点有什么特征
全在用树模型:
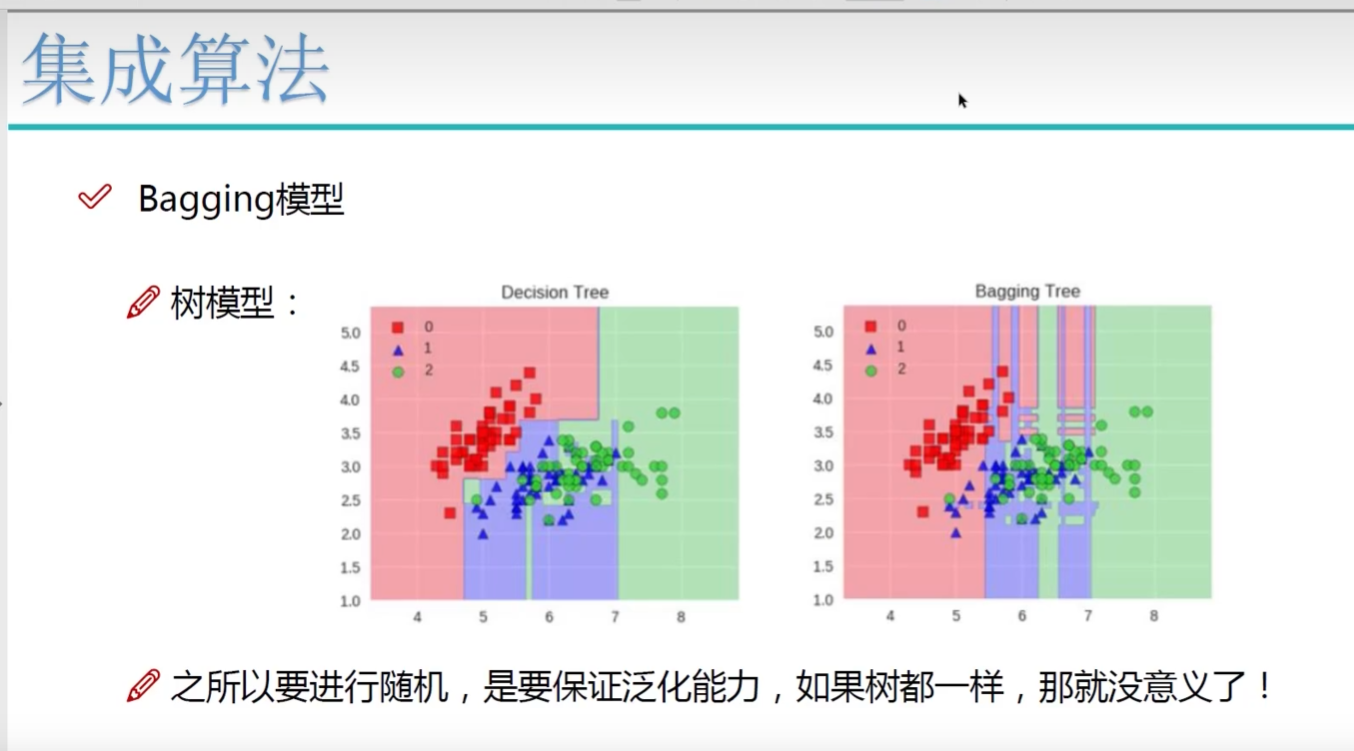
什么特征上做了什么事
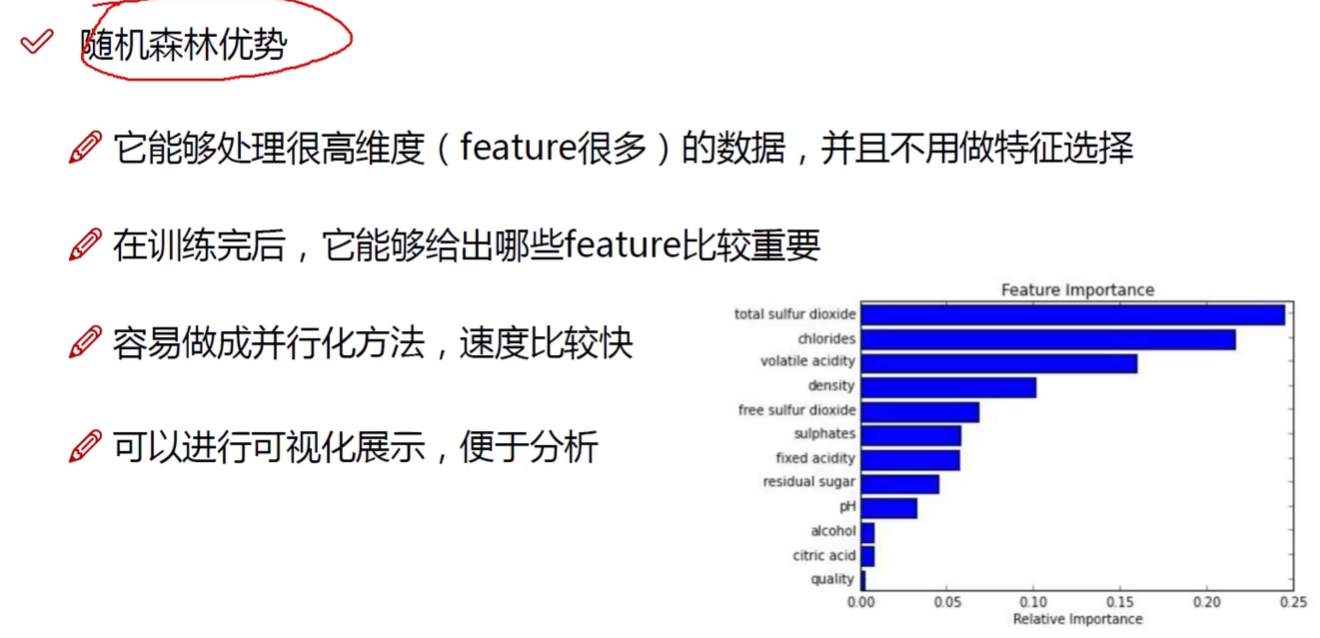
随机森林:可解释性强 自动的特征选择
神经网络:无法解释 输入输出可知 处理未知
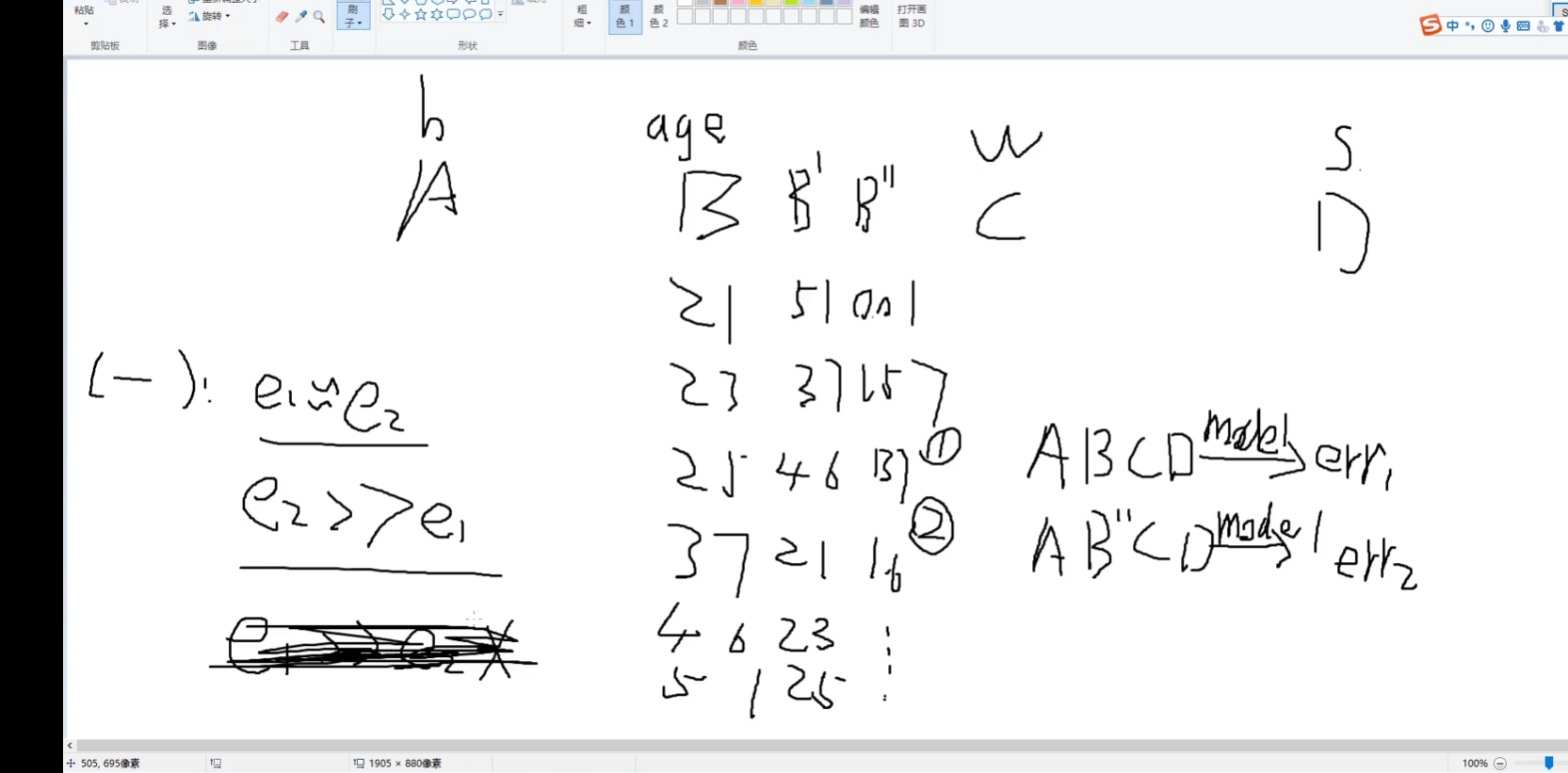
对B进行改变: B丿 B丿丿
A,B,C,D类参数:如身高/体重....
error1 error2
e1≈e2 B没用
e2>>e1 B有用
一些集成算法 除了树模型就不能再去集成了
Boosting:提升
随机森林:总和求均
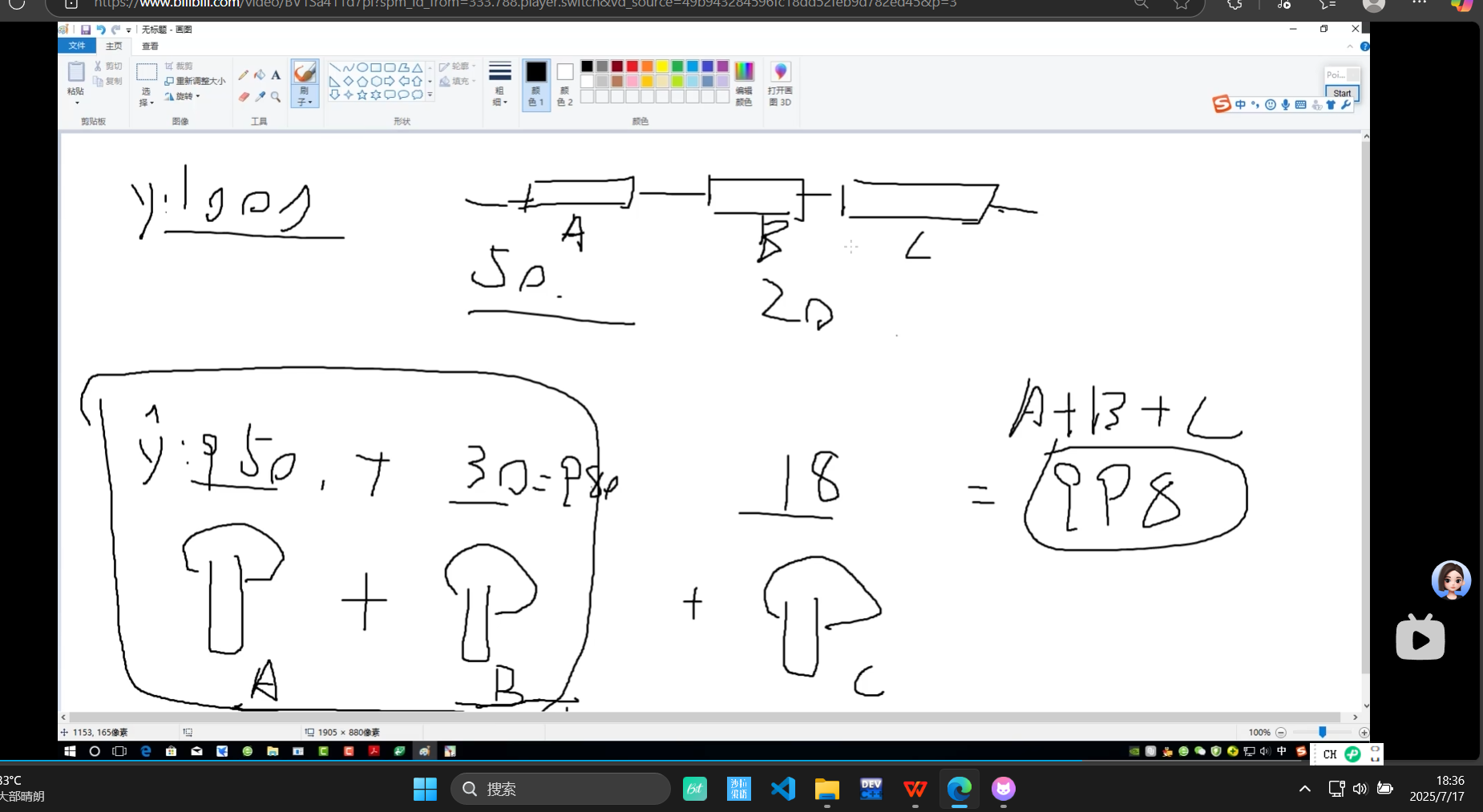
从100-预估950 剩下50中预估30 剩下20中预估18
Adaboost:不断切切 让数据有权重
stacking:堆叠算法
LR:逻辑回归
DT:决策树
RF:random forest随机森林
stacking:堆叠算法 不常用
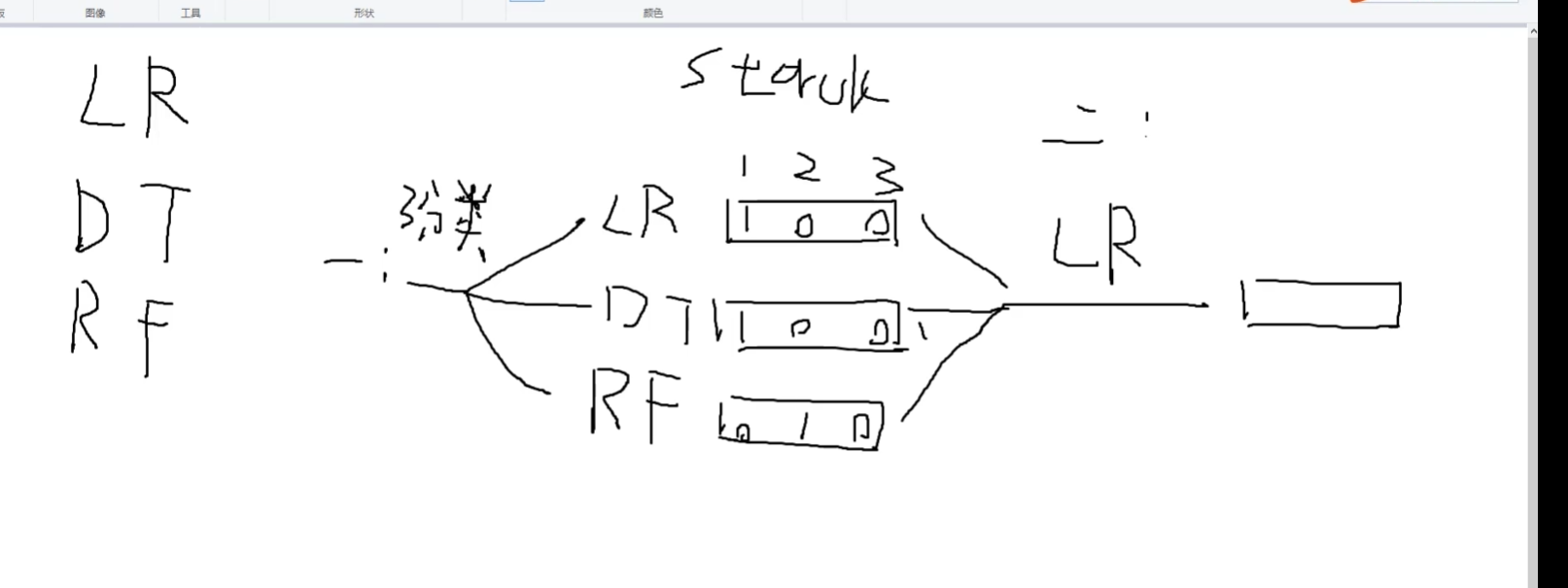
第一步多种 算法LR/DT/RTF得到多种输出
第二步 就选一种算法得到一种输出
集成:3种
1.随机森林式:并行
2.Boosting:提升 一点一点去做 234有关系
3.stacking:
第一步多种 算法LR/DT/RTF得到多种输出
第二步 就选一种算法得到一种输出
集成算法思路:
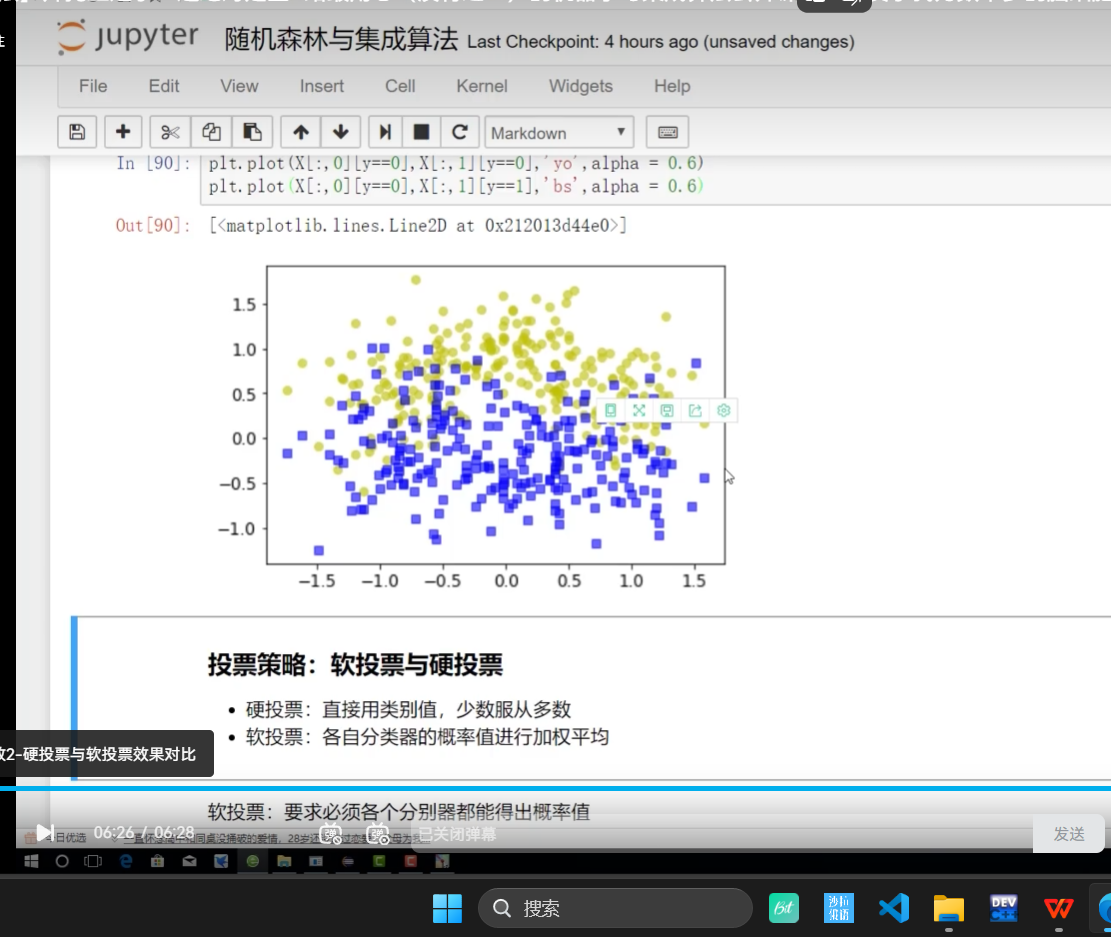
软投票:对概率加权平均
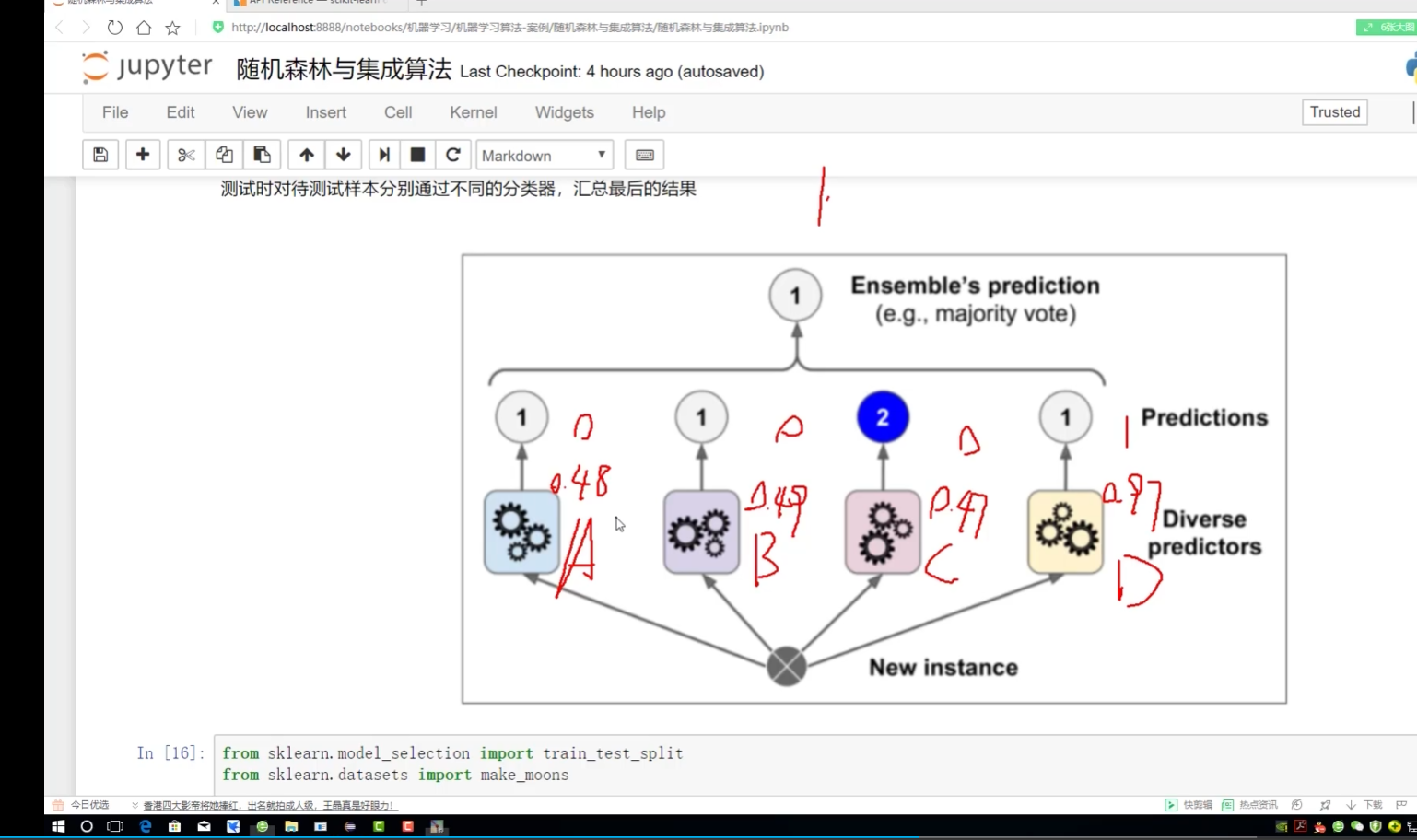
不认为类别:<0.5 认为类别:>0.5
不想上课
ABC:可能点名 D:非常可能会点名 soD 会点名,去上课了
硬投票:只用结果
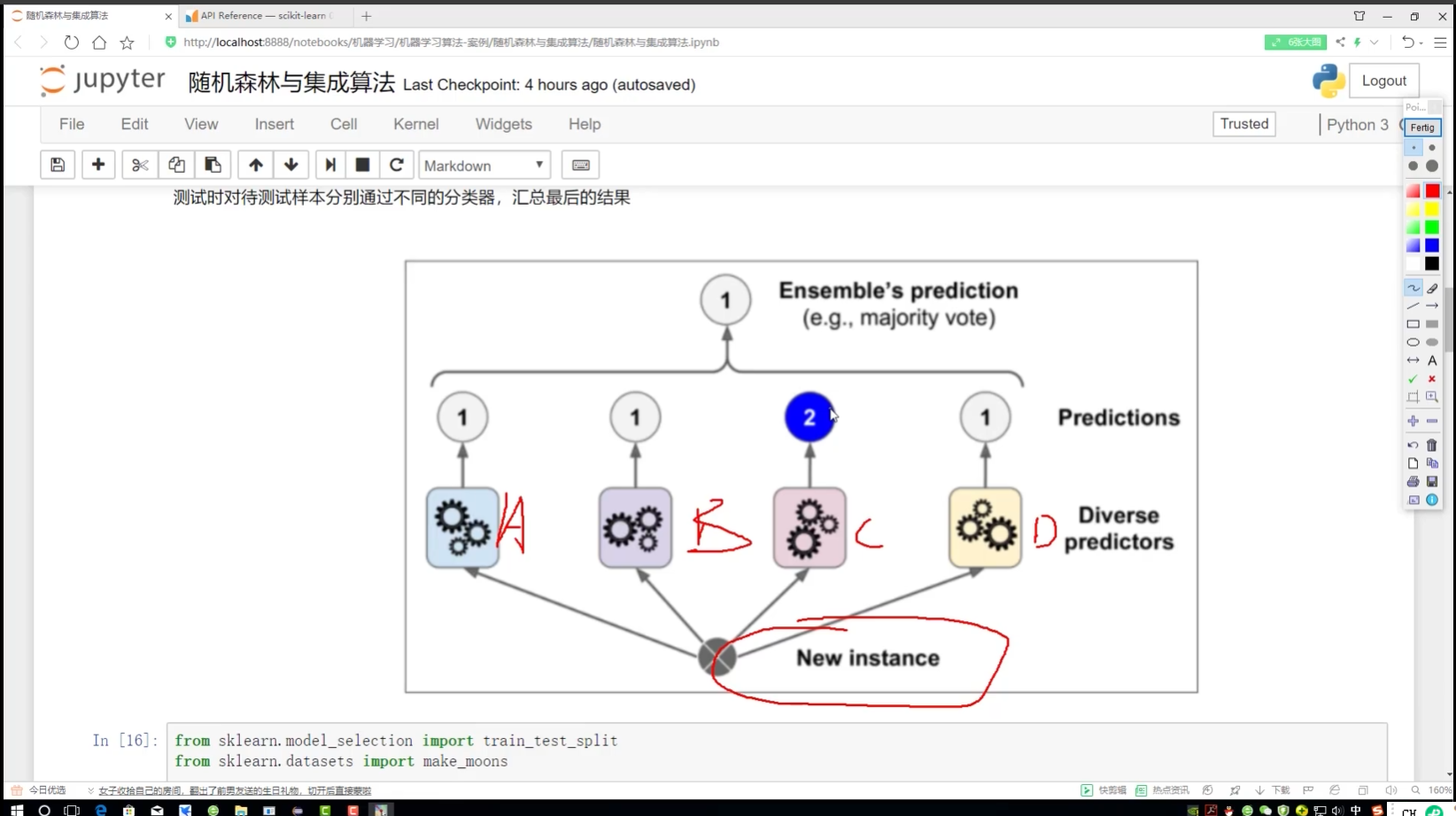
C∈2类 2类太少 soC归入1类
导入数据集selectio split切分
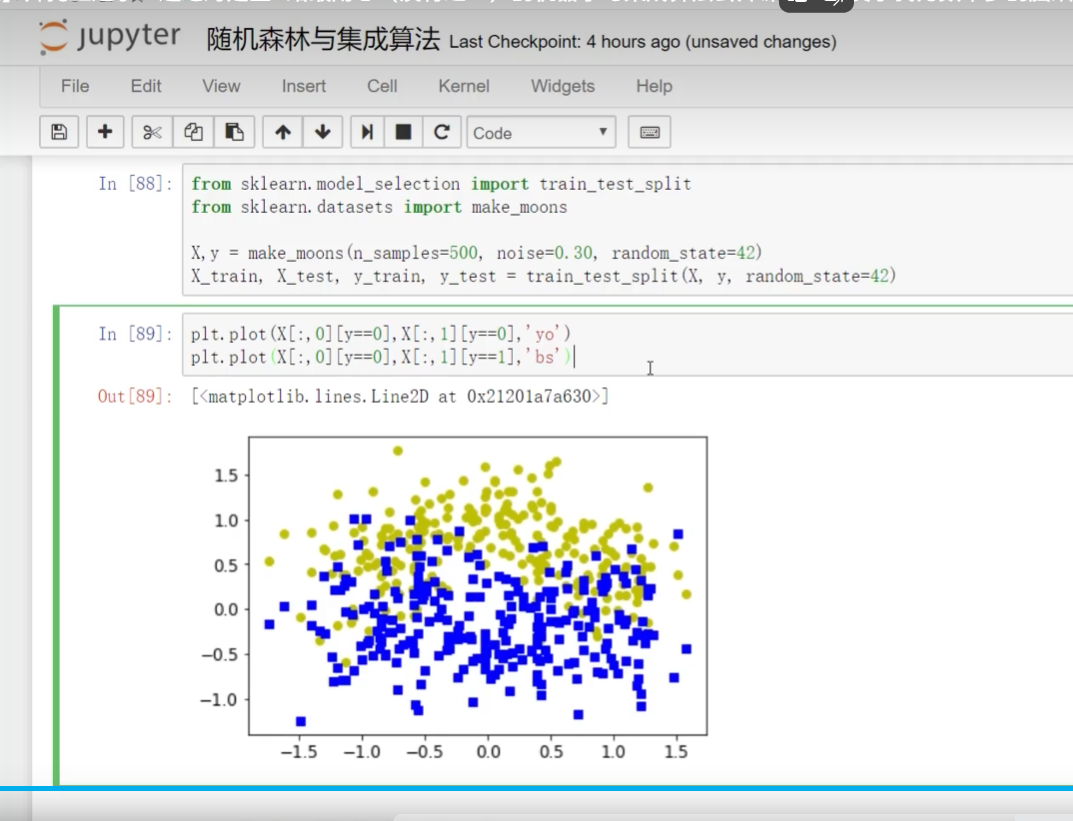
加了一个alpha:突出程度
选算法+选类别值
找分类任务的投票器
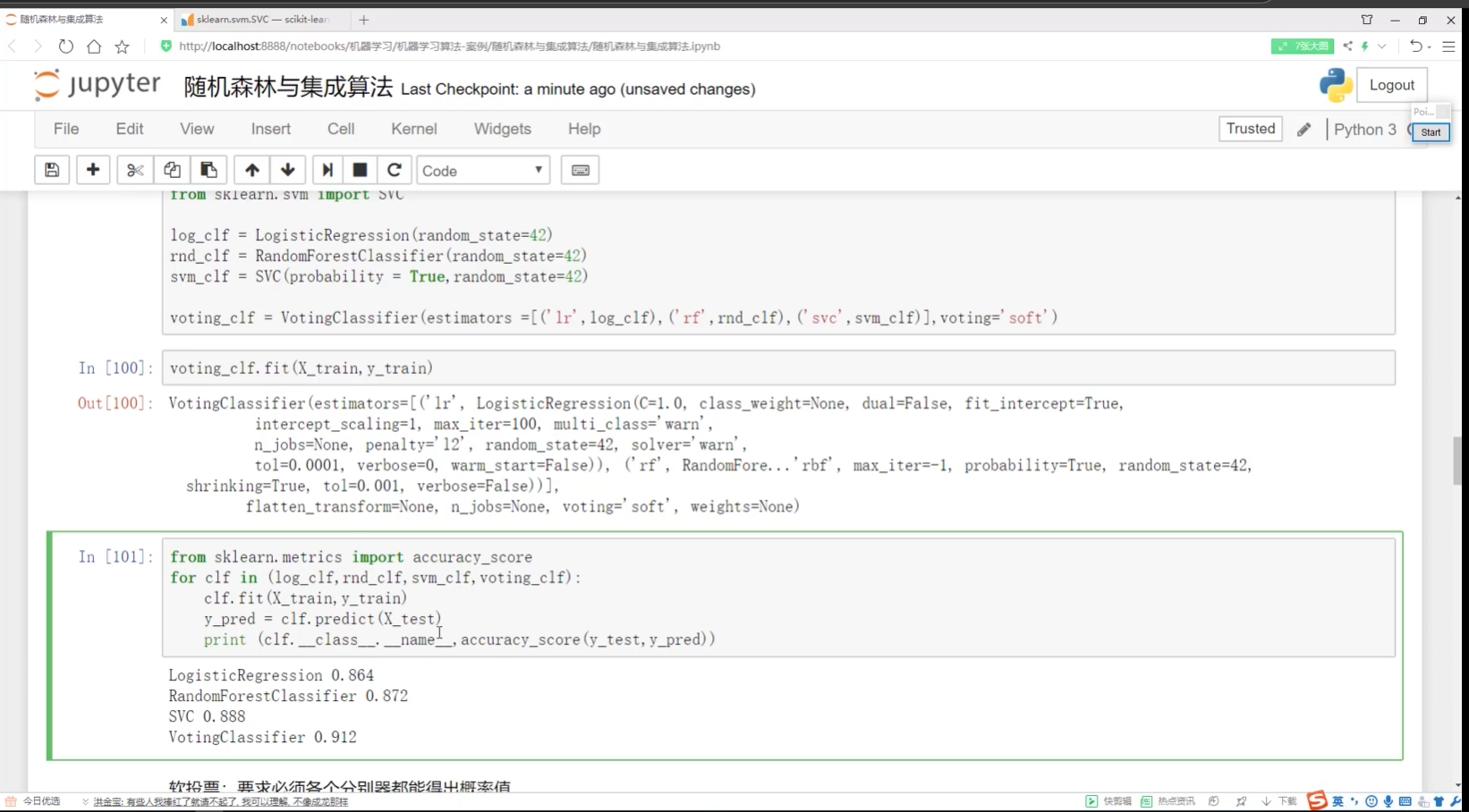
clf分类器
软投票:必须各个分类器都得到概率值
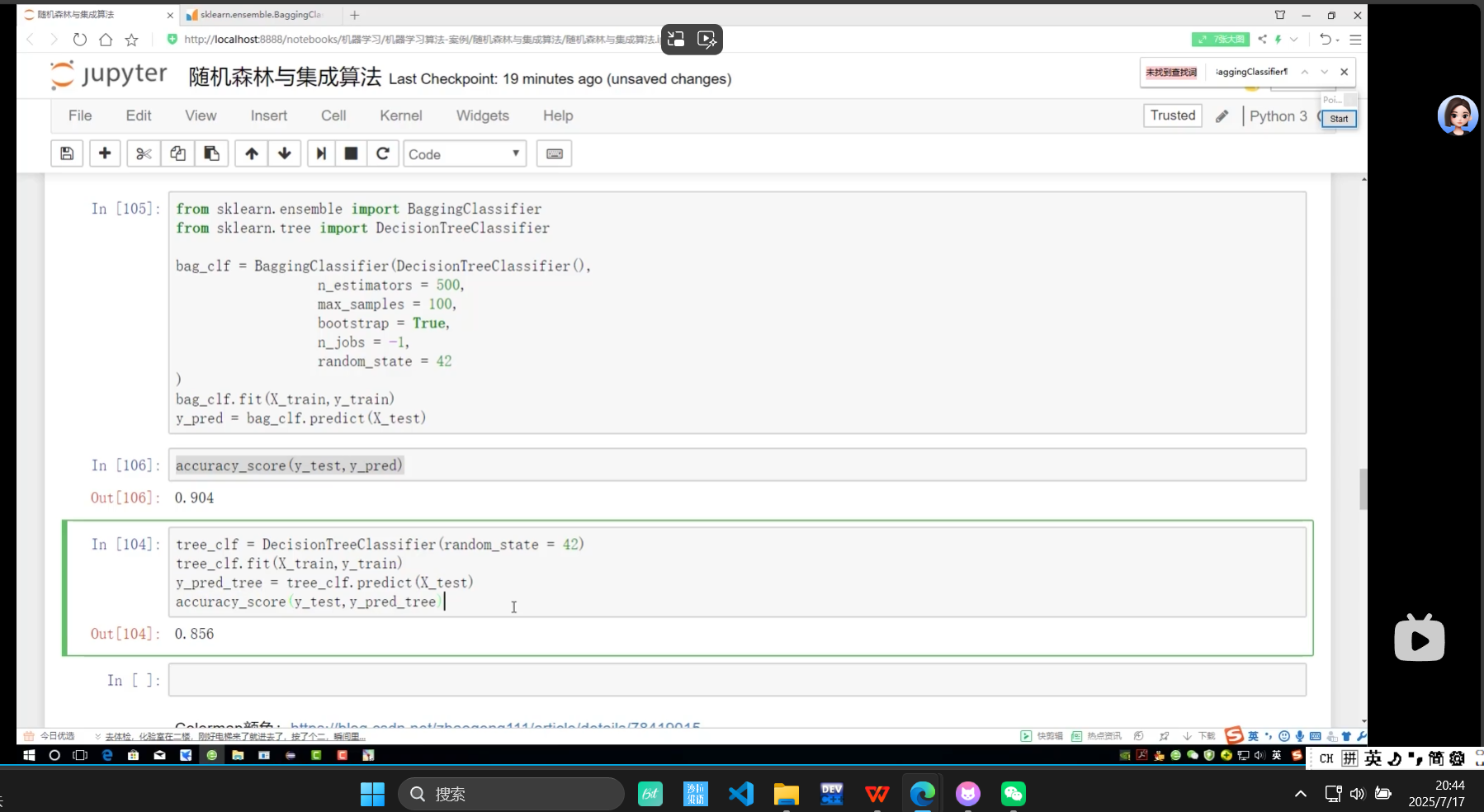
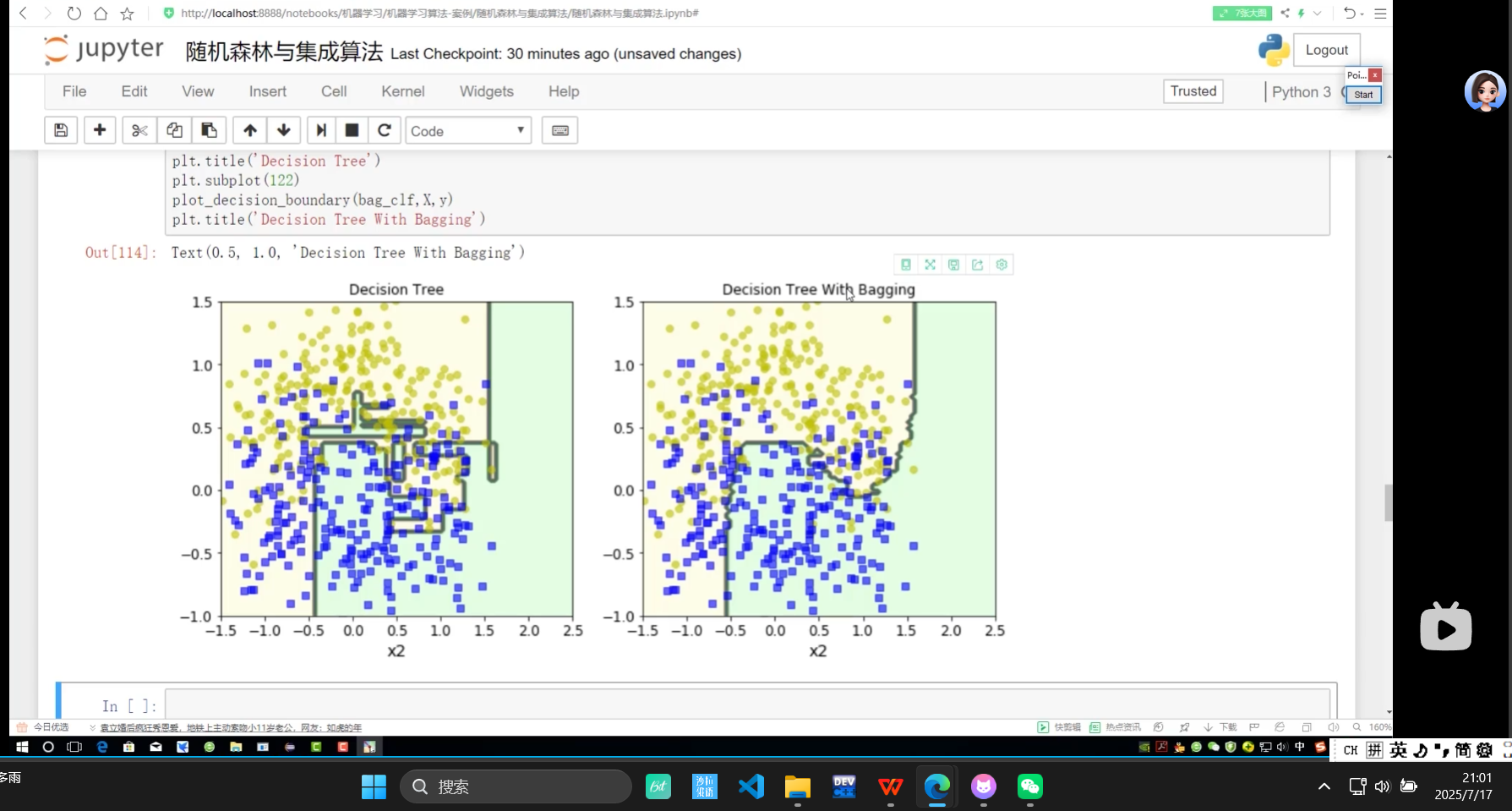
上面有bagging 下面是没有bagging

带bagging的更好些
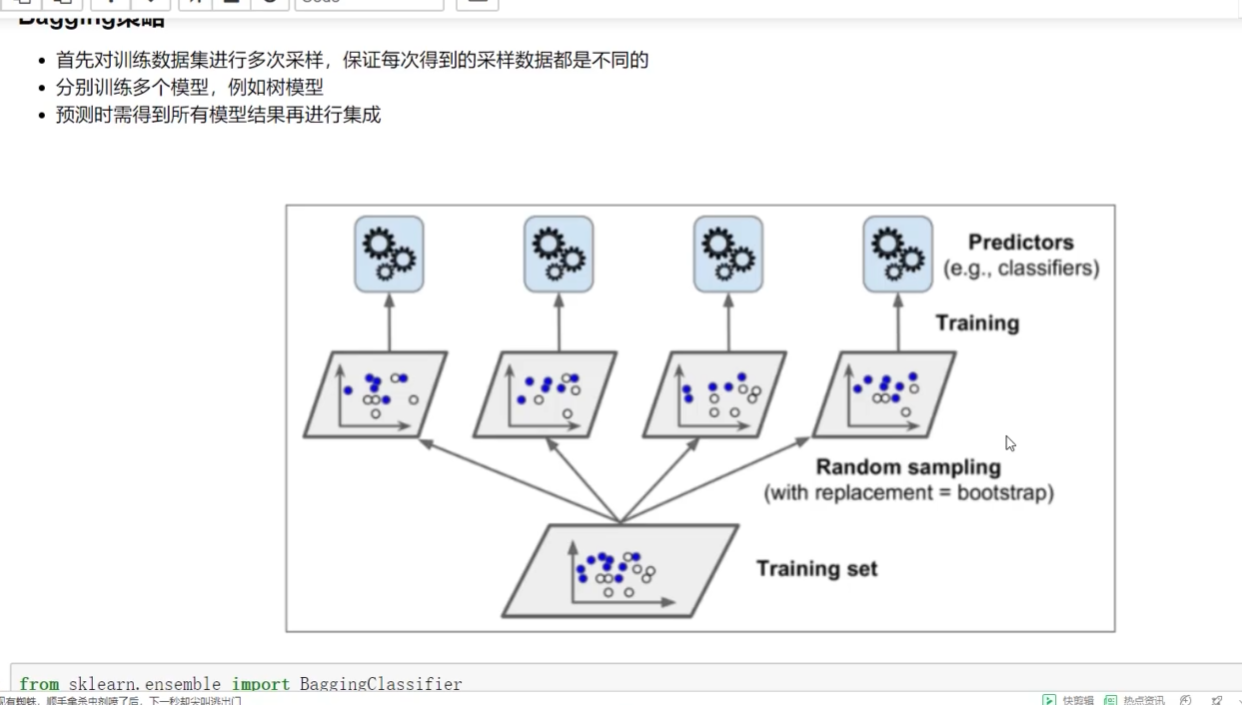
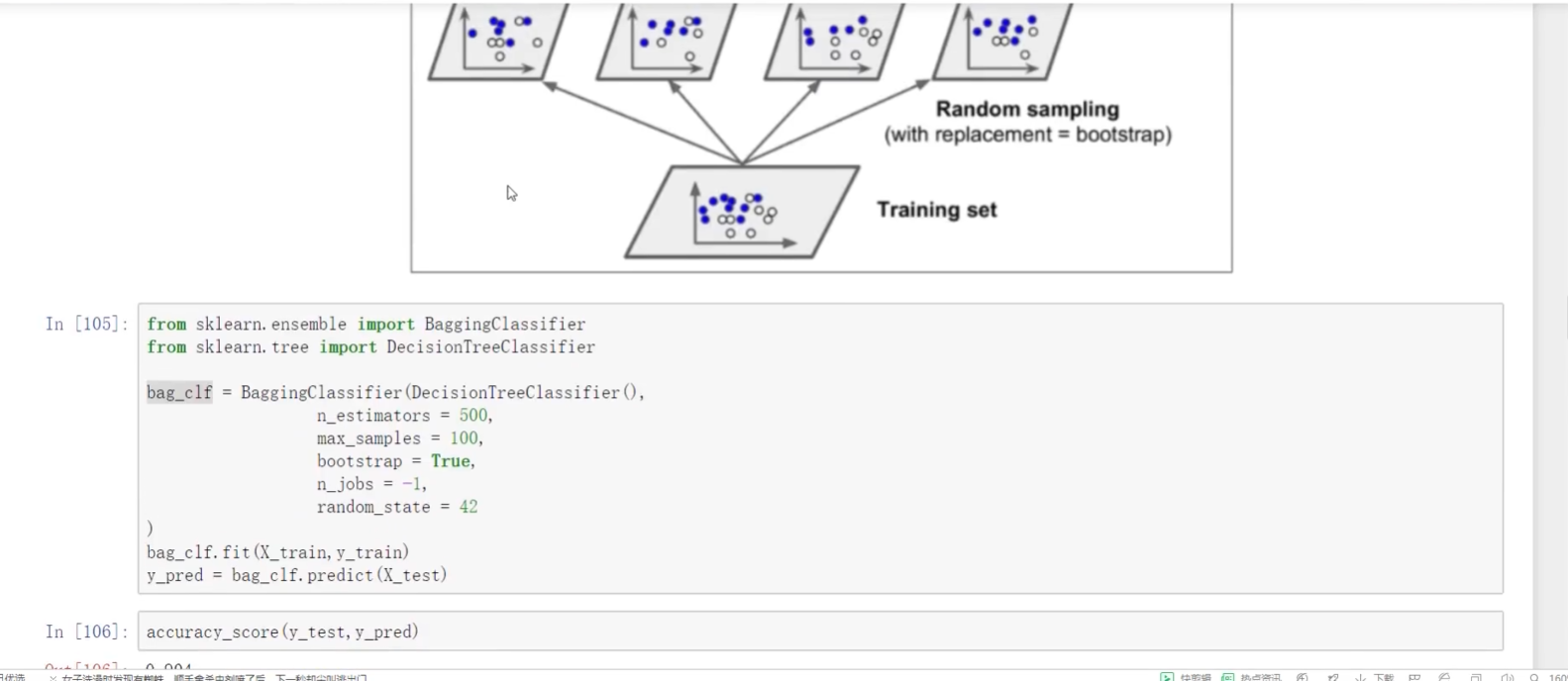
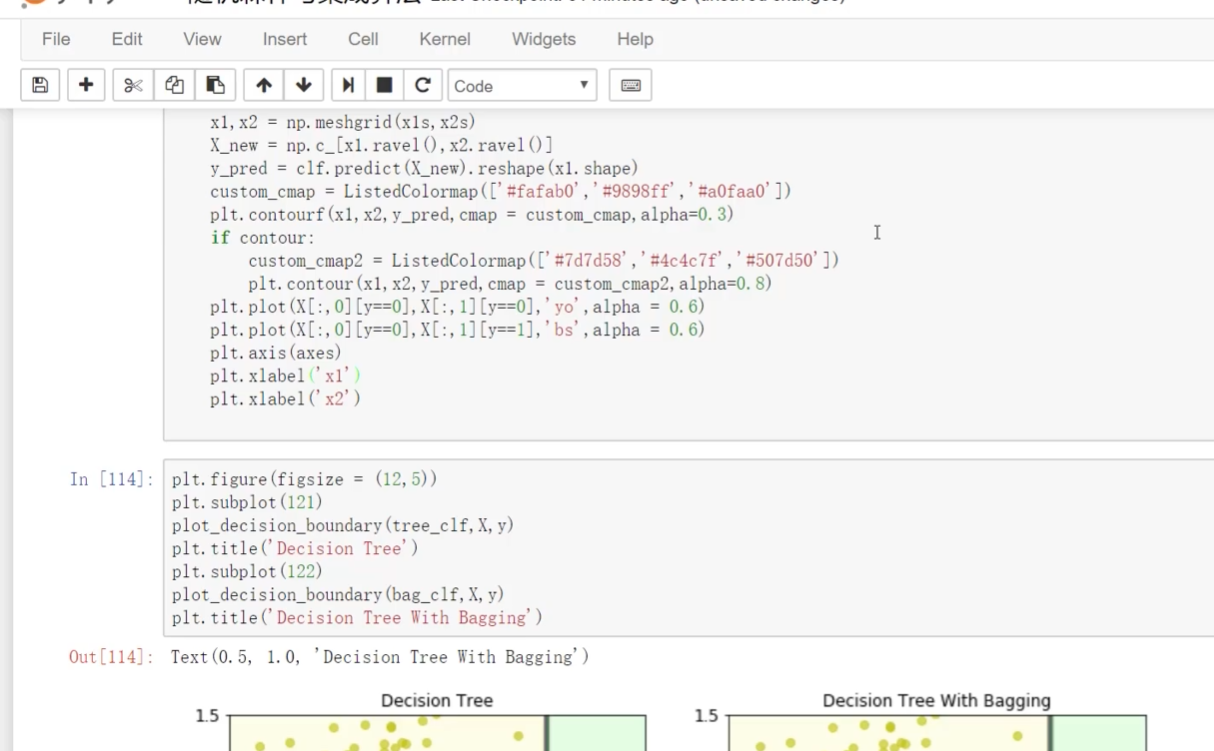
OOB:代办数据
加权平均