[RAG] 文档格式化 | 知识库摄入 | VectorDB.faiss | BM25索引.pkl
第四章:文档准备与格式化
在上一章中,我们认识了文档解析器——这个智能的数字档案管理员将PDF报告转换为结构化JSON文件。
虽然这是从原始PDF到有序数字数据的重要跨越,但这些JSON文件仍未完全准备好供RAG系统使用。
想象我们的档案管理员交给你一叠分类整齐的书页:
- 某些页面可能
残留扫描产生的污迹或多余符号 - 单个主题的信息可能
分散在不同段落,表格描述可能位于上方段落 - 即使组织有序的
长文档仍难以快速定位关键信息 - 表格数据以
网格形式存在,不利于AI深度理解
文档准备与格式化组件正是为解决这些问题而设计,它如同专业编辑与信息架构师,将原始解析文档转化为优化后的信息块。
核心功能
| 痛点领域 | 问题本质 | 解决方案 |
|---|---|---|
| OCR残留噪声 | 光学字符识别可能引入乱码或不可读符号 | 文本清洗与标准化(如将/one.tnum转为1) |
| 信息离散化 | 相关文本(标题、段落、表格)可能分散存储 | 智能合并逻辑关联的文本块,构建连贯内容单元 |
| 表格认知障碍 | 原始表格数据难以支持复杂推理 | 表格序列化:调用LLM将表格转化为结构化自然语言描述 |
| 文档冗长低效 | 整篇文档或单页内容过长,影响检索效率 | 文档分块:将内容分解为聚焦特定主题的独立信息块 |
OCR识别是一种将图片或纸质文档中的文字自动转换为可编辑、可搜索的电子文本的技术。
OCR残留噪声
指文字识别后留下的非目标内容,如扫描文件的斑点、阴影、污渍等干扰信息,影响文本准确性。
系统调用流程
通过管道协调器执行处理命令:
# 基础配置处理
python main.py process-reports --config base# 启用高级表格序列化功能
python main.py process-reports --config advanced
处理阶段分解
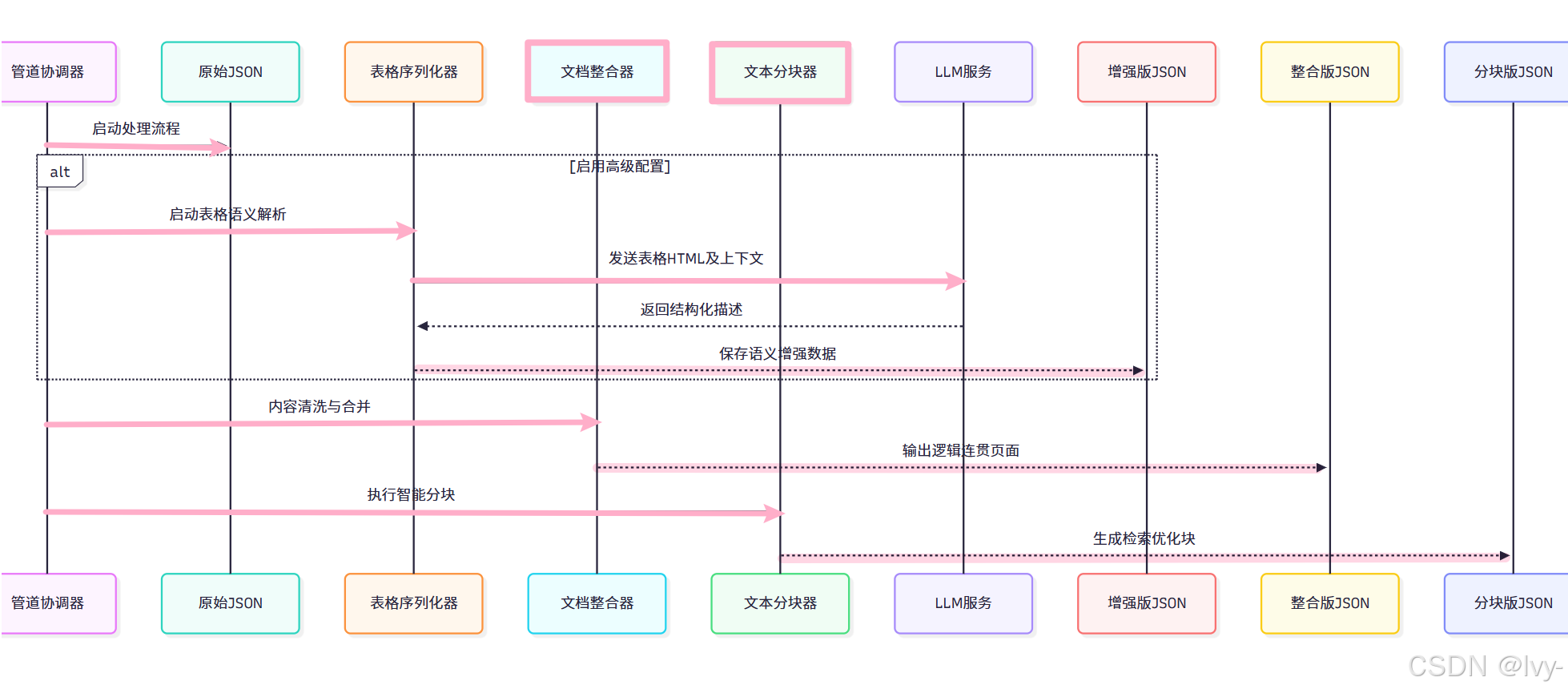
核心模块详解
1. 文档整合器(PageTextPreparation)
位于src/parsed_reports_merging.py,承担内容清洗与逻辑重组重任:
class PageTextPreparation:def _apply_formatting_rules(self, blocks):"""内容重组引擎"""processed_blocks = []for block in blocks:if block["type"] == "section_header":processed_blocks.append(f"\n## {block['text']}\n") # 二级标题elif block["type"] == "table":table_desc = self._get_table_description(block["id"]) # 获取表格描述processed_blocks.append(f"\n{table_desc}\n") # 插入表格语义描述# 其他内容类型处理逻辑...return "".join(processed_blocks)
关键技术:
- 正则表达式清洗OCR残留(如
_clean_text方法) - 智能段落合并策略(检测冒号结尾段落与后续列表的关联性)
- 动态表格描述注入(支持
原生Markdown与LLM增强版本)
正则表达式的实现,前文传送:[dp17_两个数组] 正则表达式匹配 | 最长重复子数组
2. 表格序列化器(TableSerializer)
位于src/tables_serialization.py,实现表格语义升华:
class TableSerializer:class SerializedInformationBlock(BaseModel):subject_core_entity: str = Field(description="核心实体")information_block: str = Field(description="自包含语义块")def _send_serialization_request(self, table_html, context):"""LLM交互核心"""prompt = f"表格上下文:\n{context}\n\n表格内容:\n{table_html}"return self.llm_client.send_message(system_prompt="你是一个表格语义解析专家",user_prompt=prompt,response_model=self.TableBlocksCollection)
核心价值:
- 上下文提取(捕获表格前后3个文本块作为语义背景)
- 结构化输出约束(通过
Pydantic模型确保响应格式) 并行处理优化(采用线程池实现批量表格处理)
前文传送:[Meetily后端框架] AI摘要结构化 | SummaryResponse模型 | Pydantic库 | vs marshmallow库
3. 文本分块器(TextSplitter)
位于src/text_splitter.py,实现信息粒度优化:
class TextSplitter:def _split_report(self, document):"""智能分块引擎"""chunks = []for page in document["pages"]:# 文本分块text_chunks = self.splitter.split_text(page["content"]) chunks.extend([{"type": "text", "content": chunk} for chunk in text_chunks])# 表格分块if page["has_tables"]:table_chunks = self._process_tables(page["tables"])chunks.extend(table_chunks)return chunks
技术特性:
- 递归分块策略(优先在段落/句子边界分割)
动态重叠机制(50个token的上下文重叠窗口)- 多模态分块(区分文本块与表格语义块)
输出成果
整合后文档片段
{"page": 42,"content": "## 2023财务表现\n公司全年营收突破$1.2B,同比增长18%。\n[插入表格: 季度营收分布]","tables": [{"id": "TBL_042","semantic_desc": "季度营收数据显示Q4贡献最大,达$450M占总营收37.5%"}]
}
最终分块结构
{"chunk_id": "CHK_04201","type": "text","content": "2023年Q4营收创新高,单季达到$450M...","metadata": {"source_page": 42,"entities": ["营收","季度"]}
}
总结
文档准备与格式化组件通过三重处理阶段:
- 语义增强:利用LLM升华
表格数据的可解释性 - 逻辑连贯:建立跨段落的内容
关联网络 - 检索优化:生成面向语义搜索的
信息颗粒
这种精细化的处理使得原始文档中的隐性知识得以显性化表达,为后续的知识库构建奠定了高质量的数据基础。
下一章:知识库整合
第五章:知识库摄入
在上一章中,我们看到文档准备与格式化组件如何获取原始PDF内容,进行细致的清理、合并相关信息,最重要的是将其分解为完美大小的文本"块"。
-
可以将这些块想象成独立且组织良好的索引卡,每张卡都包含文档中的特定事实或观点。
-
现在,我们拥有了所有这些出色的索引卡。但如果它们只是堆放在桌面上,又有什么用呢?
-
我们需要一个存储系统,以便
快速准确地找到所需内容,并且是基于我们的*意图*,而不仅仅是精确的关键词进行查找。
这就是知识库摄入组件发挥作用的地方!
知识库摄入解决什么问题?
想象我们有一个巨大的图书馆,刚刚收到数千张这种完美组织的"索引卡"(我们的文档块)。我们不能简单地把它们全部扔进一个盒子里!当需要回答以下问题时:
- “告诉我公司A在2023年的营收情况。”(需要查找特定
关键词和数字) - “根据他们的报告,公司面临哪些挑战?”(需要理解"
挑战"的含义,即使没有明确使用这个词,也要找到类似的观点)
我们需要一个非常智能的"归档系统",既能处理关键词搜索,也能处理基于问题背后含义或观点的搜索。
知识库摄入组件就是我们的高效数字归档系统管理员。
- 它接收这些准备好的文档块,并将其存储在专门的可搜索数据库中。
- 这包括
将文本转换为数值表示(嵌入)用于"基于含义"的数据库,以及构建传统的"基于关键词"的数据库索引。 - 这个过程形成了可快速查询的高效"知识库"。
⭕知识库摄入的核心概念
我们的"数字归档系统"使用两种主要存储类型来实现高效信息检索:
| 存储类型 | 类比 | 功能描述 | 对搜索的帮助 |
|---|---|---|---|
| 向量数据库 | "相似概念"图书管理员 | 将文本存储为称为嵌入的数值表示。可以将其视为文本含义的唯一数字"指纹" | 查找与问题语义相似(意思相近)的文本块,即使使用不同的词汇 |
| BM25索引 | "关键词匹配"图书管理员 | 以优化快速查找特定词汇或短语的方式存储文本,类似于超快速的词典索引 | 查找包含精确关键词或短语的文本块 |
让我们分解这些核心概念:
1. 嵌入:赋予数字意义
可以将嵌入视为将单词、句子甚至整个段落转化为一长串数字的神奇方式。
令人惊讶的是,具有相似含义的单词或短语在数值空间中的位置会非常"接近"。
例如:
- 单词"汽车"可能转化为:
[0.1, 0.5, -0.2, ...] - 同义词"机动车"可能转化为:
[0.11, 0.49, -0.21, ...](非常接近!) - 单词"香蕉"可能转化为:
[-0.8, 0.3, 0.9, ...](完全不同!)
这些数值表示由强大的
AI模型(通常是大型语言模型的一部分)创建。
2. 向量数据库(使用FAISS)
当我们为所有文档块获取这些数字"指纹"(嵌入)后,需要以能快速查找最相似指纹的方式存储它们。
这就是向量数据库的作用。
在本项目中,我们使用名为**FAISS**(Facebook AI相似性搜索)的库来创建这些向量数据库。
- FAISS在查找与查询嵌入最接近的数值邻居方面具有惊人的速度。
- 就像询问我们的"相似概念"图书管理员:“显示所有讨论与’公司发展’类似内容的索引卡,即使它们使用’扩张’或’市场份额增长’等词汇。”
3. BM25索引
虽然向量数据库擅长"含义"搜索
但有时我们只需要快速查找精确关键词。这时**BM25索引**就派上用场。
BM25是经典的文本搜索算法。
-
它通过创建所有块中词汇的索引(类似传统书籍索引)来工作。当搜索"营收2023"时,它会快速查找这些精确词汇,并根据词汇出现频率和稀有程度对相关块进行
排序。 -
就像询问我们的"关键词匹配"图书管理员:“查找所有包含’营收’和’2023’这两个精确词汇的索引卡。”
通过同时拥有这两种索引类型,我们的系统实现了双重优势:高精度的关键词匹配和智能的语义理解。
检索相关,前文传送:
[Es_1] 介绍 | 特点 | 图算法 | Trie | FST
如何使用知识库摄入
如第一章:流水线协调器所述,协调器(Orchestrator)负责总体控制。它会指示知识库摄入组件何时存储准备好的文档块。
在运行parse-pdfs(来自第三章:文档解析器)和process-reports(来自第四章:文档准备与格式化)后,文档块已准备就绪。process-reports命令本身包含知识库摄入的步骤。
运行方式如下:
python main.py process-reports --config base
运行此命令时会发生什么?
当Pipeline(我们的协调器)运行process-reports时,其最终步骤之一是调用create_vector_dbs()方法。该方法触发知识库摄入流程。
以下是协调器调用的简化说明:
# 来源:src/pipeline.py(简化版)
from pathlib import Pathclass Pipeline:# ... 初始化和其他方法...def create_vector_dbs(self):print("正在从分块报告中创建向量数据库和BM25索引...")# 初始化实际执行索引的工具from src.ingestion import VectorDBIngestor, BM25Ingestor # 创建并保存向量数据库vector_ingestor = VectorDBIngestor()vector_ingestor.process_reports(all_reports_dir=self.paths.chunked_reports_path,output_dir=self.paths.vector_db_path)# 创建并保存BM25索引bm25_ingestor = BM25Ingestor()bm25_ingestor.process_reports(all_reports_dir=self.paths.chunked_reports_path,output_dir=self.paths.bm25_db_path)print("知识库摄入完成。数据库已就绪!")def process_parsed_reports(self):"""协调处理已解析PDF数据的步骤。该方法调用与特定模块交互的其他内部方法。"""# ...(调用前一章的merge_reports()、chunk_reports())...print("步骤4:创建向量数据库...")self.create_vector_dbs() # 关键步骤!print("报告处理流程成功完成!")
说明:
process_parsed_reports方法(由python main.py process-reports调用)包含self.create_vector_dbs()步骤。该方法创建VectorDBIngestor和BM25Ingestor(我们专门的"归档系统管理员")实例
并指示它们处理chunked_reports目录中的文档块,同时指定新数据库的保存位置。
输出:
此步骤完成后,终端不会直接显示结果,但查看项目的data/vector_db和data/bm25_db文件夹(由流水线协调器配置),会发现新生成的.faiss(向量数据库)和.pkl(BM25索引)文件,每个文件对应一个处理过的报告。
底层原理:知识库摄入如何工作
知识库摄入流程由src/ingestion.py中的两个主要类处理:BM25Ingestor和VectorDBIngestor。这两个类都由Pipeline(协调器)调用来处理各自的索引类型。
知识库摄入流程(摄入,其实就是加索引,重新编排…)
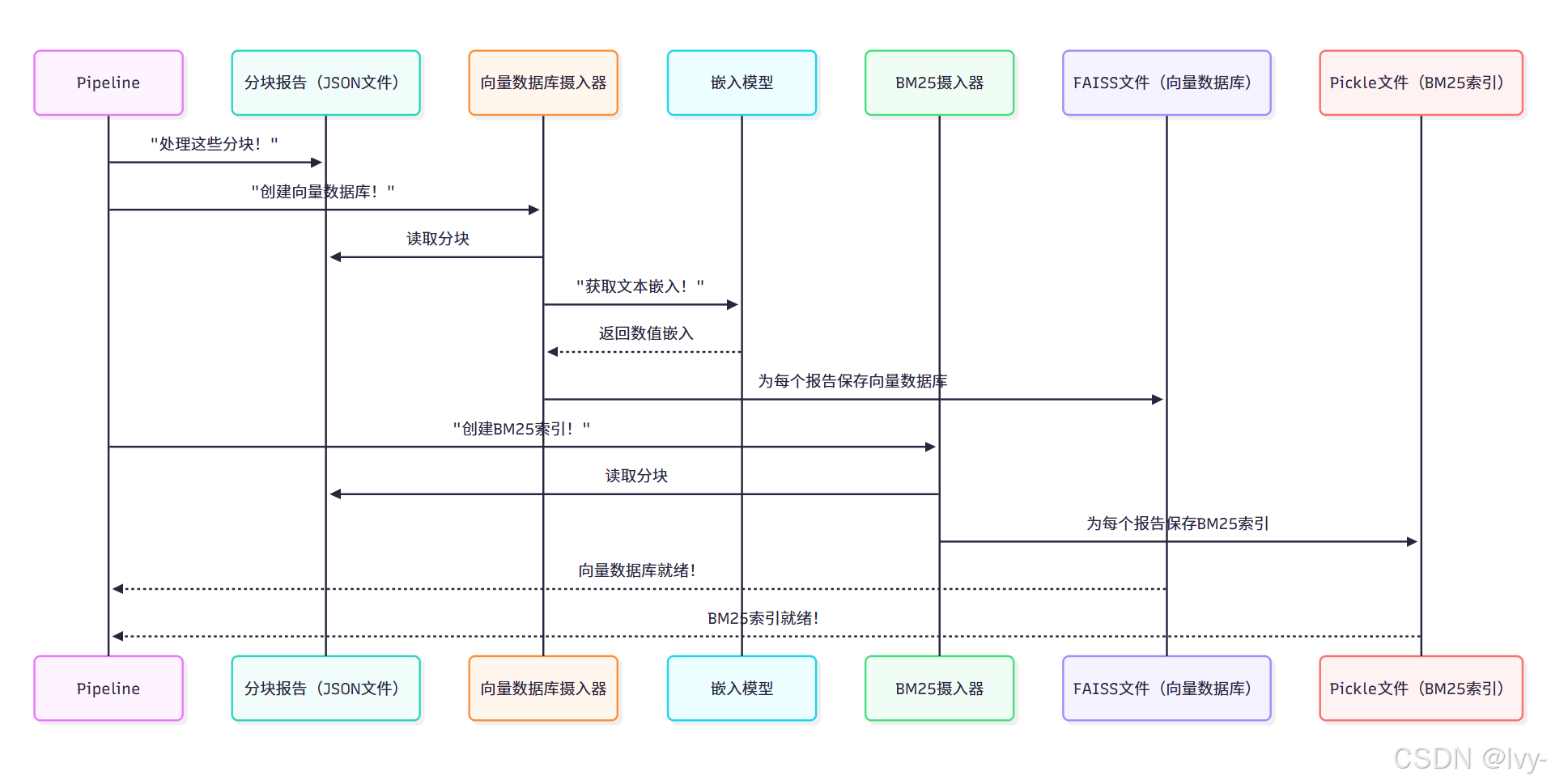
让我们看看src/ingestion.py中的两个主要组件:
1.🎢 BM25Ingestor
该类负责构建传统的基于关键词的BM25索引。
create_bm25_index(self, chunks: List[str]):该方法接收文本块列表。首先对每个块进行"分词"(例如"hello world"变为[“hello”, “world”]),然后使用BM25Okapi库从分词后的块创建BM25索引。process_reports(self, all_reports_dir: Path, output_dir: Path):这是Pipeline调用的主要方法。遍历chunked_reports目录中的所有.json文件,为每个报告:- 加载报告数据
- 提取所有文本块
- 调用
create_bm25_index构建索引 - 使用
pickle库将BM25索引保存为bm25_db目录中的.pkl文件
简化版代码示例:
# 来源:src/ingestion.py(简化版)
import json
import pickle
from pathlib import Path
from rank_bm25 import BM25Okapiclass BM25Ingestor:def create_bm25_index(self, chunks: List[str]) -> BM25Okapi:"""将文本块转换为高效的关键词可搜索索引"""tokenized_chunks = [chunk.split() for chunk in chunks]return BM25Okapi(tokenized_chunks)def process_reports(self, all_reports_dir: Path, output_dir: Path):"""处理所有准备好的报告并为每个保存BM25索引"""output_dir.mkdir(parents=True, exist_ok=True)all_report_paths = list(all_reports_dir.glob("*.json"))for report_path in all_report_paths:with open(report_path, 'r', encoding='utf-8') as f:report_data = json.load(f)text_chunks = [chunk['text'] for chunk in report_data['content']['chunks']]bm25_index = self.create_bm25_index(text_chunks)sha1_name = report_data["metainfo"]["sha1_name"]output_file = output_dir / f"{sha1_name}.pkl"with open(output_file, 'wb') as f:pickle.dump(bm25_index, f)
2. 🎢VectorDBIngestor
该类使用嵌入和FAISS创建语义(基于含义)的向量数据库。
_set_up_llm(self):配置与外部大语言模型(如OpenAI的嵌入模型)的连接,从.env文件安全加载API密钥。_get_embeddings(self, text: Union[str, List[str]], model: str = "text-embedding-3-large"):核心语义理解模块,将文本块发送给LLM获取数值"指纹"。_create_vector_db(self, embeddings: List[float]):使用faiss.IndexFlatIP从嵌入创建FAISS索引。process_reports(self, all_reports_dir: Path, output_dir: Path):遍历所有分块报告,为每个报告:- 加载数据
- 提取文本块
- 获取嵌入
- 创建FAISS索引
- 保存为
.faiss文件
简化版代码示例:
# 来源:src/ingestion.py(简化版)
import os
import json
from pathlib import Path
from dotenv import load_dotenv
from openai import OpenAI
import faiss
import numpy as np
from tenacity import retry, wait_fixed, stop_after_attemptclass VectorDBIngestor:def __init__(self):self.llm = self._set_up_llm()def _set_up_llm(self):load_dotenv()return OpenAI(api_key=os.getenv("OPENAI_API_KEY"))@retry(wait=wait_fixed(20), stop=stop_after_attempt(2))def _get_embeddings(self, text: str, model: str = "text-embedding-3-large") -> List[float]:response = self.llm.embeddings.create(input=text, model=model)return response.data[0].embeddingdef _create_vector_db(self, embeddings: List[float]):embeddings_array = np.array(embeddings, dtype=np.float32)dimension = len(embeddings[0])index = faiss.IndexFlatIP(dimension)index.add(embeddings_array)return indexdef process_reports(self, all_reports_dir: Path, output_dir: Path):all_report_paths = list(all_reports_dir.glob("*.json"))output_dir.mkdir(parents=True, exist_ok=True)for report_path in all_report_paths:with open(report_path, 'r', encoding='utf-8') as file:report_data = json.load(file)text_chunks = [chunk['text'] for chunk in report_data['content']['chunks']]all_embeddings = []for chunk_text in text_chunks:all_embeddings.append(self._get_embeddings(chunk_text))index = self._create_vector_db(all_embeddings)sha1_name = report_data["metainfo"]["sha1_name"]faiss_file_path = output_dir / f"{sha1_name}.faiss"faiss.write_index(index, str(faiss_file_path))
结论
知识库摄入组件将我们精心准备的文档块转化为强大的双用途搜索引擎。
- 通过创建基于含义的向量数据库和基于关键词的BM25索引,我们的系统能够以惊人的速度和准确性查找相关信息,无论是搜索特定词汇还是更广泛的概念。这构成了RAG系统"检索"能力的核心基础。
现在我们的知识库已完全构建并充满可搜索信息,接下来的关键步骤是学习在提问时如何实际找到最相关的信息。
下一章:信息检索器