Redis原理之主从复制
上篇文章:
Redis原理之事务![]() https://blog.csdn.net/sniper_fandc/article/details/149141054?fromshare=blogdetail&sharetype=blogdetail&sharerId=149141054&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
https://blog.csdn.net/sniper_fandc/article/details/149141054?fromshare=blogdetail&sharetype=blogdetail&sharerId=149141054&sharerefer=PC&sharesource=sniper_fandc&sharefrom=from_link
目录
1 主从模式
2 创建主从模式
2.1 启动多个Redis
2.2 修改多个从节点配置文件形成主从结构
2.3 临时修改主从结构
3 主从复制的其他配置项
3.1 安全性
3.2 从节点只读
3.3 TCP传输延迟
4 主从复制的拓扑结构
4.1 一主一从
4.2 一主多从
4.3 树形主从
5 主从复制的总体流程
6 主从复制psync命令
6.1 psync命令
6.2 psync命令执行流程
6.3 全量复制
6.4 增量复制
6.5 实时复制
在分布式系统中存在单点问题:即一个物理服务器只部署一个服务器程序,这样存在两个缺点,1是如果该主机挂了,服务器程序也就挂了,可用性差;2是性能/支持的并发量有限。
为了解决单点问题,引入分布式系统,而Redis分布式部署的三种方式:主从模式、主从+哨兵模式、集群模式。这里先讲主从模式:
1 主从模式
一个主节点+多个从节点,主节点的数据和修改操作都会同步给从节点,从节点数据与主节点保持一致,从节点不允许修改数据,只能读数据。
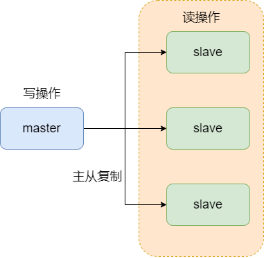
由于所有的节点的数据都时刻保持一致,因此请求哪个节点得到的数据都一样,这也就提高了系统的性能和并发量,同时如果某个从节点挂掉,只需要请求其他节点即可,提高了可用性。
注意:主从模式是针对读操作的并发量和可用性的提高,对于写操作只在主节点进行,如果主节点挂掉,整个集群就无法写操作,因此可用性和并发量(对于写)也没有完全理想。
2 创建主从模式
2.1 启动多个Redis
注意:此处是在一台主机上启动多个Redis服务,因此不是真正的分布式,而是伪分布式。
启动多个Redis需要为每个Redis服务都分配不同的端口号,有两种方式:
1.启动时在redis-server命令后添加--port选项。
2.复制多个配置文件,每个配置文件设置不同的端口号,对应不同的redis服务。
为了便于后续使用,这里采用方式2,slave1端口号6380,slave2端口号6381:


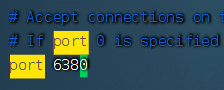
使用vim redis-slave1-config打开配置文件,输入/port可快捷定位到port选项,切换插入模式(快捷键i),修改端口号为6380,同时要修改daemonize选项为yes(后台进程)。这里只演示一个slave的修改方式,其他slave一样。
启动从节点slave1和slave2:

2.2 修改多个从节点配置文件形成主从结构
要想形成主从结构,就需要使用slaveof,有三种使用方式:
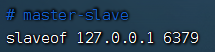
1.想要作为从节点的配置文件添加slaveof {masterHost} {masterPort}。
2.redis-server启动命令加上--slaveof {masterHost} {masterPort}。
3.直接使用redis命令:slaveof {masterHost} {masterPort}。
这里使用方式1,修改配置文件后重启redis服务:
注意:redis的关闭与启动命令通常是搭配使用的。(redis-server 配置文件)与(kill -9 进程id)搭配使用;(service redis-server start)与(service redis-server stop)搭配使用。其中service的方式启动后用kill -9关闭redis,redis会立即重启。
使用netstat -anp | grep redis命令查询连接情况:
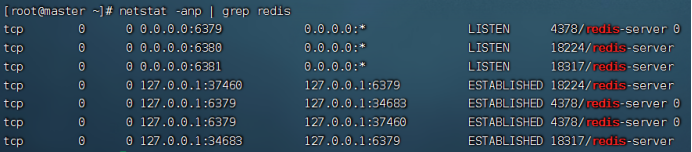
其中下面四个建立的tcp连接实际上就是从节点和主节点网络交互的连接,因为要主从复制就是通过网络的方式进行。其中37460和6379是一对主从节点,34683和6379是另一对主从节点。
在主节点内进行任何写操作,都会同步到从节点:
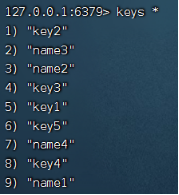
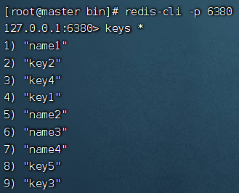
![]()
可以注意到,从节点不能写入。使用info replication命令可以查看主从节点的复制的相关信息:
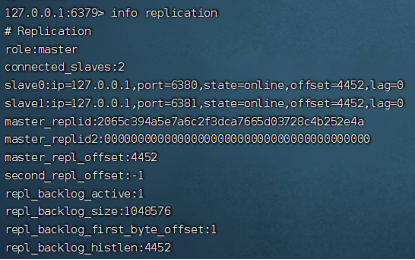
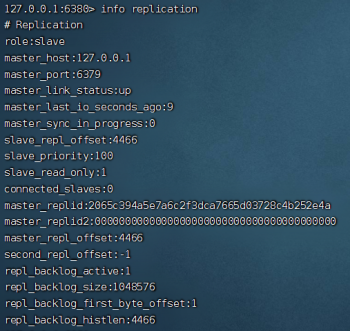
role表示节点的角色,master_replid是主节点的身份码,offset偏移量表示复制的进度(不是瞬间就把所有的信息复制完),priority表示从节点优先级(用于主节点挂了从节点竞争成为主节点的场景),backlog表示积压缓冲区(和主从复制的策略有关),其余信息字面意思就很容易明白。
2.3 临时修改主从结构
使用slaveof no one命令就能断开某个从节点与主节点的连接,使用slaveof {masterHost} {masterPort}命令也能切换连接的主节点,但是这种关系是临时性的,重启从节点后又会恢复原来的主从关系:
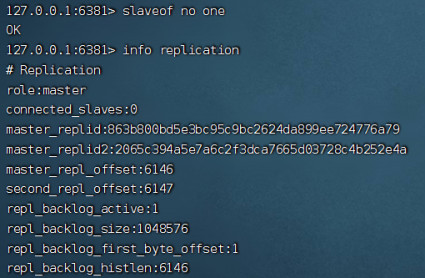
断开连接后,slave独立为master节点,但是之前同步的数据不会删除,之后无法从主节点同步新数据。
3 主从复制的其他配置项
3.1 安全性
对主节点配置密码,可以让所有连接主节点的客户端(包括从节点)都需要密码才能访问。
主节点配置requirepass参数进行密码验证,客户端访问必须使用auth命令校验。
主从复制的建立连接过程,从节点必须配置masterauth和主界面密码一致才能建立连接发起复制流程。
3.2 从节点只读
slave-read-only=yes配置从节点为只读模式(默认模式),不建议取消只读模式,因为从节点的修改主节点无感知。
3.3 TCP传输延迟
由于主从复制采用网络来进行传输,TCP传输就引起主从复制的延迟,repl-disable-tcp-nodelay参数用于控制是否关闭TCP_NODELAY(TCP的nagle算法),默认为no,即开启tcp-nodelay功能。
tcp-nodelay该功能开启时会增加传输延迟(把多个小TCP数据包合并,类似捎带应答的目的),节省网络带宽。
关闭时,会减少传输延迟,增加网络带宽,从而加快主从同步的速度。
4 主从复制的拓扑结构
4.1 一主一从
master节点可以读/写,slave节点只能读。如果master的写请求多,就会造成大量IO压力,因此可以主动关闭AOF(持久化的文件),从节点开启AOF。
注意:这种情况最大的弊端是如果master挂了,不能自动重启恢复数据,因为没有AOF文件,如果自动重启master的数据全部丢失,主从复制后slave的数据也就丢失。此时需要master向slave获取AOF文件用以恢复数据。
4.2 一主多从
适用于读请求多的情况,可以读写分离。master节点进行写,slave节点进行读。但是如果写请求变多,就会导致master节点负载压力大,因为需要同步给多个slave节点。
4.3 树形主从
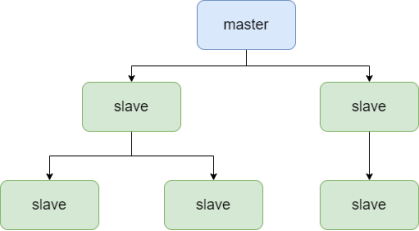
缓解master节点因为挂载多个slave节点从而主从复试负载高的情况。master节点只用同步少数连接的的slave,slave节点再向下依次同步数据。但是,这种结构会导致主从同步的延迟较高,尤其是在叶子的slave节点。
5 主从复制的总体流程
(1)保存主节点信息:保存master的ip和端口号。
(2)主从建立连接:TCP三报文握手,验证连接是否可用(系统层面)。
(3)发送ping命令:验证主从复制是否可用(应用层面)。
(4)权限验证:如果master开启密码才会进行。
(5)同步数据集:全量复制,主从复制开启的一瞬间主节点的所有数据同步到从节点。
(6)命令持续复制:增量复制,后续主节点的修改写入部分持续同步到从节点。
6 主从复制psync命令
主从复制是从节点在建立主从连接后自动执行psync来主动向主节点拉取数据的过程。
6.1 psync命令
语法格式:psync replicationid offset
replicationid(replid):master节点每次启动都会自动生成的用于主从复制的身份id(每次都不同),从节点在建立连接后会获取到master的复制id值。
注意:使用info replication 命令查询节点的信息后,会有两个replicationid(master_replid和master_replid2),其中master_replid是主节点的身份id。而master_replid2只有在网络抖动时会发挥作用:当网络抖动时,slave会向master发送ping心跳包,可能收不到主节点的pong,多次超时重传后就会认为master挂了,此时slave自身就独立为主节点了。因此也就自动生成了replicationid作为master_replid,而slave记录的原来的master的replicationid就会作为master_replid2,用于网络正常后恢复主从结构。
offset:偏移量,主节点和从节点都各自维护offset。主节点每进行一个写操作,offset就会累加命令的字节数。从节点每秒会向主节点上报自己的offset,同时接受到主节点的写命令后也会累加offset。如果偏移量一样,就说明从节点同步进度追上了主节点。
注意:replicationid和offset共同描述了一个“数据集合”,即如果两个节点的replicationid和offset相同,就说明两个节点的数据是一样的。
6.2 psync命令执行流程
| slave | master |
| 向master发送psync replicationid offset | 根据参数和自身情况选择复制的方式: |
| 1.+FULLRESYNC:全量复制 | |
| 2.+CONTINEU:增量复制 | |
| 3.-ERR:主节点版本过低不支持psync |
默认情况下(建立主从连接自动执行),replicationid和offset为?和-1,表示全量复制。关于复制方式的选择:
方式1.+FULLRESYNC:首次建立主从连接,或者主节点不方便进行增量复制。
方式2.+CONTINEU:offset为正整数,或者从节点全量复制后可能发生网络抖动或从节点重启(大部分数据一致,就尝试增量复制能否保持数据一致)。
方式3.-ERR:主节点的Redis版本低,不支持该命令。可以使用sync命令进行主从同步,但是该命令可能阻塞Redis。
6.3 全量复制
| slave | master |
| 1.向master发送psync命令(psync ? 1) | 2.回复+FULLRESYNC响应 |
| 3.接收到master的运行信息后保存 | 4.执行bgsave命令进行RDB文件生成 |
| 6.接收到RDB文件保存在磁盘 | 5.给slave发送RDB文件 |
| 8.把补发的数据追加到RDB文件中 | 7.5-6期间master接收的新的写请求会写入缓冲区中,待6执行完后补发给slave |
| 9.清空自身旧数据 | \ |
| 10.加载RDB文件同步数据 | \ |
| 11.判断是否开启AOF持久化,如果开启AOF,执行bgrewrite命令;如果没有开启,全量复制完成 | \ |
整个全量复制最耗时的部分是4-10,因此如果slave已经有大量数据,应该避免使用全量复制。
注意1:步骤4为什么使用RDB文件?RDB文件已经有了为什么还要重新生成?首先RDB文件是二进制形式,因此体积小,更方便传输。其次,RDB是定期持久化的机制,于是RDB的数据和master的数据存在延迟,全量复制需要同步这一时刻的最新数据,因此就需要重新生成RDB文件。
注意2:步骤11,如果slave开启AOF持久化,在10的过程中会产生AOF日志,存在冗余信息,就需要执行bgrewrite命令来整理AOF日志(让体积更小)。
注意3:从Redis 2.8.18版本开始支持无磁盘复制(diskless)。无磁盘复制master生成的RDB数据不再写入RDB文件(不再写入磁盘),而是直接传输到slave,slave直接把数据加载到Redis中。
6.4 增量复制
| slave | master |
| 1.当slave和master出现网络中断时间超过repl-timeout,master中断复制连接 | |
| 2.中断期间的写请求写入积压缓冲区(repl-backlog-buffer) | |
| 3.网络恢复,slave与master恢复连接 | |
| 4.发送之前保存的replid和offset参数的psync命令 | 5.根据replid和offset判断需要进行增量复制,返回+CONTINEU响应给slave |
| 6.发送slave需要同步的数据 | |
积压缓冲区(repl-backlog-buffer)的实现是环形队列,当队列不满时master的写命令也会写入积压缓冲区中;当队列满时就先把旧的数据出队列再写入新的数据。保证积压缓冲区始终是近期的数据。
步骤5,master首先根据replid判断从节点之前的数据来源是否是master:
如果replid!=master_replid,则进行全量复制;
如果replid==master_replid,则判断offset是否位于积压缓冲区内:
如果offset位于积压缓冲区内,则进行增量复制;
如果offset位于积压缓冲区外(说明除了积压缓冲区,还需要复制不再其中的数据),则进行全量复制。
6.5 实时复制
当主从节点建立连接后,进行全量复制,结束时主节点和从节点在这一时刻是同步的。此后,主从节点建立TCP长连接,主节点把源源不断的写请求同步到从节点,从而保证主从节点的实时一致性(当然还是有网络传输延迟的),这就是实时复制。
实时复制依靠心跳包机制(应用层实现的,而不是TCP自带的)来维护连接的可靠性。master每隔一段时间向slave发送ping命令,slave收到后立即回复pong命令,当master超过repl-timeout时间没有收到pong,就判断slave下线,自主断开连接。
而slave每隔一段时间(比master发送ping的时间间隔短)向master发送replconf ack {offset}命令汇报自身主从复制的进度。
下篇文章: