【AI论文】基于反射生成模型的测试时动态缩放方法
摘要:我们推出首个反射生成模型 MetaStone-S1,其通过自监督过程奖励模型(SPRM)实现了与 OpenAI o3 相当的性能。通过共享主干网络,并分别采用任务特定头部实现下一标记预测与过程评分,SPRM 成功将策略模型与过程奖励模型(PRM)集成于统一接口,且无需额外过程标注,使 PRM 参数减少超 99%,显著提升推理效率。得益于 SPRM 的设计,MetaStone-S1 天然适配测试时动态缩放(TTS),并基于可控思考长度提供三种推理强度模式(低、中、高)。此外,我们通过实证研究揭示了总思考计算量与 TTS 性能之间的缩放规律。实验表明,参数规模仅 320 亿的 MetaStone-S1 即可达到与 OpenAI-o3-mini 系列相当的性能。为推动社区研究,我们已将 MetaStone-S1 开源至:https://github.com/MetaStone-AI/MetaStone-S1。Huggingface链接:Paper page,论文链接:2507.01951
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在自然语言理解和生成领域取得了显著进展,推动了诸如OpenAI的GPT-4、Google的Gemini、Meta的LLaMA系列、阿里巴巴的Qwen和DeepSeek的R1等先进模型的出现。这些模型通过创新的架构和训练技术,能够处理和生成多种格式的内容。特别是OpenAI的o3模型,通过测试时缩放(Test-Time Scaling, TTS)技术,如大规模采样、候选评分和多推理路径搜索,实现了在推理基准测试中的接近人类水平的性能。
然而,现有的TTS方法主要分为内部TTS和外部TTS两类。内部TTS(如DeepSeek R1)通过长链式思考(Long-CoT)生成答案,但可能受到“过度思考”的影响,导致性能下降。外部TTS(如Best-of-N采样、波束搜索和多样验证树搜索)则通过辅助奖励模型(如过程奖励模型,PRM)选择高质量的推理轨迹,但依赖于大规模的过程级标注数据,且训练成本高昂。
研究目的
本研究旨在解决现有TTS方法中的两个主要问题:
- 外部计算开销大:PRM包含与策略模型(LLM)独立的参数,增加了额外的计算负担。
- 标注数据昂贵:PRM的训练需要大规模的过程级标注数据,难以获取。
为此,研究提出了一种新的反射生成形式(Reflective Generative Form),通过共享策略模型和PRM的主干网络,并使用自监督过程奖励模型(SPRM),实现了高效的推理轨迹选择。基于这一形式,研究进一步提出了MetaStone-S1模型,该模型在仅320亿参数规模下,实现了与OpenAI o3-mini系列相当的性能。
二、研究方法
1. 反射生成形式(Reflective Generative Form)
反射生成形式通过共享策略模型和PRM的主干网络,并使用任务特定头部进行推理轨迹预测和评分,实现了参数的高效利用。具体来说:
- 统一接口:策略模型和SPRM共享同一主干网络,SPRM通过轻量级头部对推理轨迹进行评分。
- 自监督训练:SPRM仅使用最终答案标签进行优化,避免了过程级标注的需求。
2. 自监督过程奖励模型(SPRM)
SPRM通过自监督学习,仅使用最终答案的正确性来优化推理轨迹的选择。具体方法包括:
- 步骤分割:使用模型自带的标记器将推理轨迹分割成离散的步骤。
- 轨迹评分预测:基于步骤标记的隐藏表示,使用SPRM头部预测每个步骤的过程分数,并通过几何平均计算整个推理轨迹的最终分数。
3. 优化方法
- 策略模型优化:采用组相对策略优化(GRPO)方法。
- SPRM优化:提出自监督过程奖励损失(SPR Loss),仅基于最终答案的正确性来优化SPRM。
4. 推理方法
在推理阶段,MetaStone-S1通过以下步骤选择高质量的推理轨迹:
- 采样:策略模型生成多个推理轨迹作为候选。
- 评分:SPRM对每个推理轨迹的步骤进行评分,并计算最终分数。
- 选择:选择最终分数最高的推理轨迹,指导策略模型生成答案。
三、研究结果
1. 性能比较
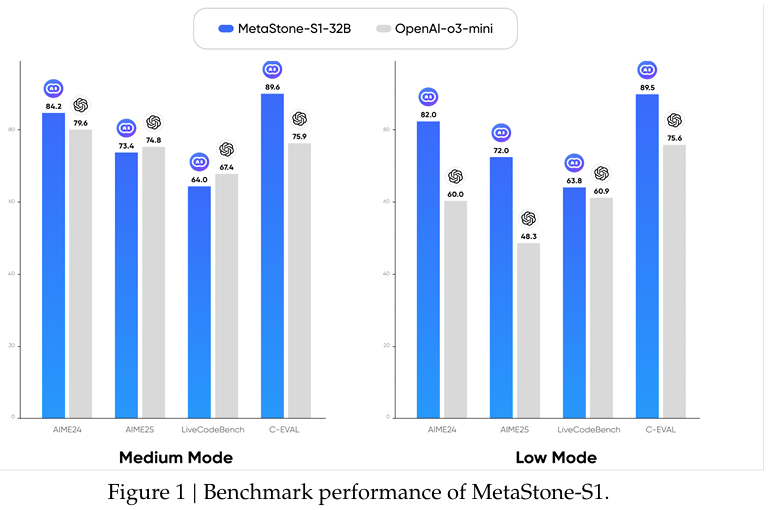
- 数学推理任务:在AIME2024和AIME2025基准测试中,MetaStone-S1-32B模型分别达到了85.2%和73.6%的准确率,优于大多数开源模型,并与OpenAI o3-mini系列相当。
- 编程任务:在LiveCodeBench基准测试中,MetaStone-S1-32B模型达到了64.2%的准确率,优于其他320亿参数规模的模型。
- 中文推理任务:在C-Eval基准测试中,MetaStone-S1-32B模型达到了89.7%的准确率,优于大多数开源模型,并与OpenAI o3-mini系列相当。
2. 缩放规律
研究发现,MetaStone-S1的性能与计算预算(参数规模与推理标记数的乘积)呈对数正相关。当推理长度扩展到基线的32倍以上时,性能提升逐渐减缓。
3. “顿悟时刻”(Aha Moment)
研究观察到,在训练过程中存在一个“顿悟时刻”,此时模型开始能够基于推理内容判断正确性,正确与错误推理轨迹的评分差距逐渐扩大。
4. 消融研究
- SPRM的有效性:仅使用少量额外参数(如500万至5300万)的SPRM,性能优于使用720亿参数的独立PRM。
- 自监督优化的有效性:与使用最终答案正确性作为过程级监督的BCELoss相比,SPRLoss在区分正确与错误推理轨迹方面表现出更强的判别能力。
四、研究局限
1. 额外超参数引入
研究提出的反射生成形式引入了额外的超参数r_min,其最优选择可能因概念而异。虽然设置r_min为全排名的50%在大多数情况下表现良好,但不同概念的最优选择可能有所不同。
2. 训练时间增加
使用SVD初始化权重虽然提高了模型的稳定性和性能,但也增加了时间和计算开销。与标准LoRA初始化相比,SVD初始化需要更多的计算资源。
3. 模型规模限制
虽然MetaStone-S1在320亿参数规模下实现了与OpenAI o3-mini相当的性能,但在更大规模模型上的表现尚未充分验证。
4. 评估基准有限
目前的研究主要在数学推理、编程和中文推理任务上进行了评估,对于其他类型的复杂推理任务(如科学推理、常识推理等)的评估尚不充分。
五、未来研究方向
1. 探索更高效的推理轨迹选择方法
进一步研究如何在不显著增加计算成本的情况下,提高推理轨迹选择的准确性和效率。例如,可以探索基于强化学习的更高效搜索策略,或结合其他类型的奖励模型来优化推理过程。
2. 扩展评估基准
在更多类型的复杂推理任务上评估MetaStone-S1的性能,以验证其泛化能力。这包括科学推理、常识推理、多模态推理等领域。
3. 优化模型架构和训练方法
研究如何进一步优化模型架构和训练方法,以减少训练时间和计算开销。例如,可以探索更高效的权重初始化方法,或结合知识蒸馏等技术来压缩模型规模。
4. 结合其他先进技术
探索将MetaStone-S1与其他先进技术(如注意力机制、图神经网络等)相结合,以提高模型的推理能力和解释性。例如,可以引入图神经网络来更好地处理结构化数据,或结合注意力机制来提高模型对关键信息的关注能力。
5. 实际应用探索
将MetaStone-S1应用于实际场景中,如智能客服、自动驾驶、医疗诊断等领域,以验证其在实际应用中的有效性和可靠性。通过实际应用反馈,进一步优化模型性能和用户体验。