YOLO融合[CVPR2025]EVSSM中的EDFFN模块

YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程
YOLOv11改进汇总贴:YOLOv11及自研模型更新汇总
《Efficient Visual State Space Model for Image Deblurring》
一、 模块介绍
论文链接:Efficient Visual State Space Model for Image Deblurring
代码链接:https://github.com/kkkls/EVSSM/tree/master
论文速览:
卷积神经网络(CNNs)和视觉变换器(ViTs)在图像恢复方面表现出色。虽然ViTs通过有效捕捉长距离依赖关系和输入特定特征总体上优于CNNs,但它们在图像分辨率增加时计算复杂性呈平方增长。这一限制妨碍了它们在高分辨率图像恢复中的实际应用。在本文中,我们提出了一种简单而有效的视觉状态空间模型(EVSSM)用于图像去模糊,利用状态空间模型(SSMs)在视觉数据中的优势。与现有方法采用几种固定方向扫描进行特征提取显著增加计算成本相反,我们开发了一个高效的视觉扫描块,在每个基于SSM的模块之前应用各种几何变换,捕捉有用的非局部信息并保持高效率。此外,为了更有效地捕捉和表达局部信息,我们提出了一种基于高效判别频域的前馈网络(EDFFN),该网络可以有效估计有用的频率信息以恢复潜在清晰图像。大量实验结果表明,所提出的EVSSM在基准数据集和实际图像上相较于最新方法表现良好。
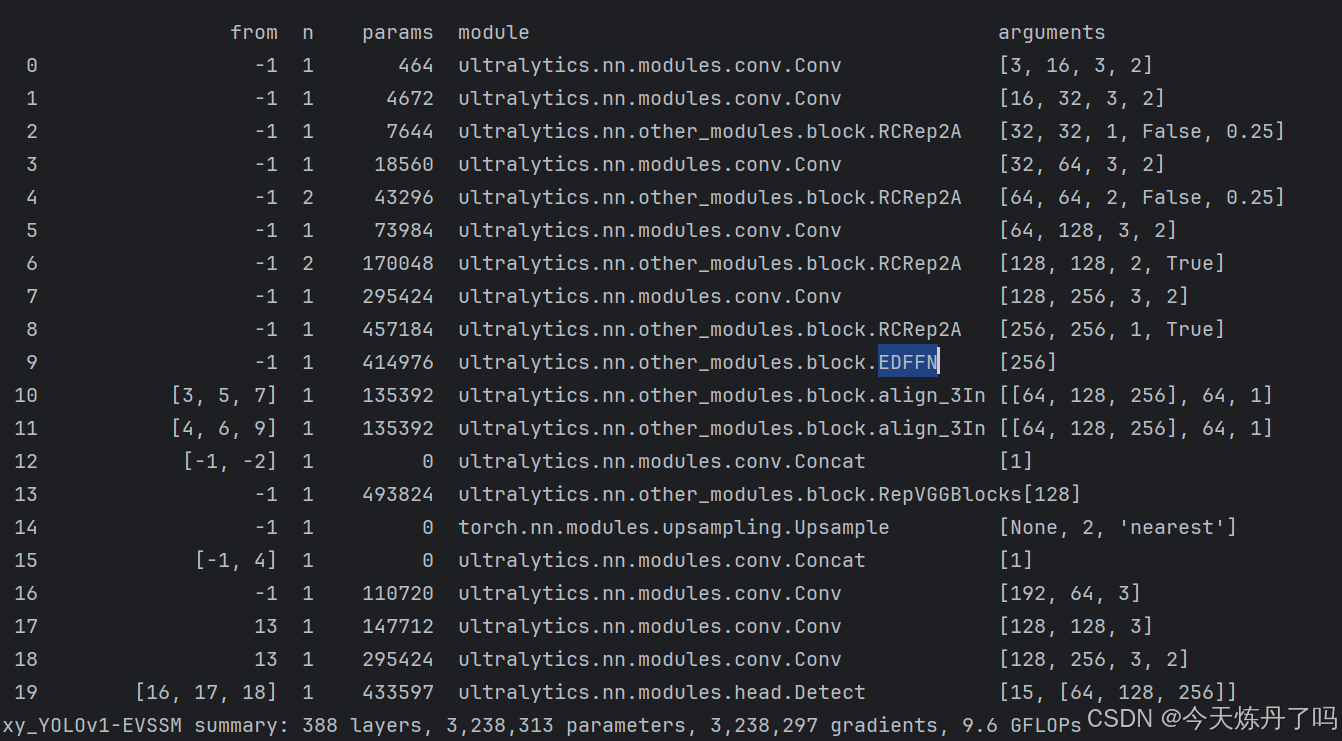
总结:本文更新其中的EDFFN模块。
⭐⭐本文二创模块仅更新于付费群中,往期免费教程可看下方链接⭐⭐
YOLOv11及自研模型更新汇总(含免费教程)文章浏览阅读366次,点赞3次,收藏4次。群文件2024/11/08日更新。,群文件2024/11/08日更新。_yolo11部署自己的数据集https://xy2668825911.blog.csdn.net/article/details/143633356
二、二创融合模块
2.1 相关代码
# https://blog.csdn.net/StopAndGoyyy?spm=1011.2124.3001.5343
# https://github.com/kkkls/EVSSM/tree/master
class EDFFN(nn.Module):def __init__(self, dim, ffn_expansion_factor=2, bias=True):super(EDFFN, self).__init__()hidden_features = int(dim * ffn_expansion_factor)self.patch_size = 8self.dim = dimself.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,groups=hidden_features * 2, bias=bias)self.fft = nn.Parameter(torch.ones((dim, 1, 1, self.patch_size, self.patch_size // 2 + 1)))self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)def forward(self, x):x = self.project_in(x)x1, x2 = self.dwconv(x).chunk(2, dim=1)x = F.gelu(x1) * x2x = self.project_out(x)b, c, h, w = x.shapeh_n = (8 - h % 8) % 8w_n = (8 - w % 8) % 8x = torch.nn.functional.pad(x, (0, w_n, 0, h_n), mode='reflect')x_patch = rearrange(x, 'b c (h patch1) (w patch2) -> b c h w patch1 patch2', patch1=self.patch_size,patch2=self.patch_size)x_patch_fft = torch.fft.rfft2(x_patch.float())x_patch_fft = x_patch_fft * self.fftx_patch = torch.fft.irfft2(x_patch_fft, s=(self.patch_size, self.patch_size))x = rearrange(x_patch, 'b c h w patch1 patch2 -> b c (h patch1) (w patch2)', patch1=self.patch_size,patch2=self.patch_size)return x
2.2更改yaml文件 (以自研模型为例)
yam文件解读:YOLO系列 “.yaml“文件解读_yolo yaml文件-CSDN博客
打开更改ultralytics/cfg/models/11路径下的YOLOv11.yaml文件,替换原有模块。

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# ⭐⭐Powered by https://blog.csdn.net/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 377 layers, 2,249,525 parameters, 2,249,509 gradients, 8.7 GFLOPs/258 layers, 2,219,405 parameters, 0 gradients, 8.5 GFLOPss: [0.50, 0.50, 1024] # summary: 377 layers, 8,082,389 parameters, 8,082,373 gradients, 29.8 GFLOPs/258 layers, 7,972,885 parameters, 0 gradients, 29.2 GFLOPsm: [0.50, 1.00, 512] # summary: 377 layers, 20,370,221 parameters, 20,370,205 gradients, 103.0 GFLOPs/258 layers, 20,153,773 parameters, 0 gradients, 101.2 GFLOPsl: [1.00, 1.00, 512] # summary: 521 layers, 23,648,717 parameters, 23,648,701 gradients, 124.5 GFLOPs/330 layers, 23,226,989 parameters, 0 gradients, 121.2 GFLOPsx: [1.00, 1.50, 512] # summary: 521 layers, 53,125,237 parameters, 53,125,221 gradients, 278.9 GFLOPs/330 layers, 52,191,589 parameters, 0 gradients, 272.1 GFLOPs# n: [0.33, 0.25, 1024]
# s: [0.50, 0.50, 1024]
# m: [0.67, 0.75, 768]
# l: [1.00, 1.00, 512]
# x: [1.00, 1.25, 512]
# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, RCRep2A, [128, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 4, RCRep2A, [256, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 4, RCRep2A, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, RCRep2A, [1024, True]]- [-1, 1, EDFFN, []] # 9# YOLO11n head
head:- [[3, 5, 7], 1, align_3In, [256, 1]] # 10- [[4, 6, 9], 1, align_3In, [256, 1]] # 11- [[-1, -2], 1, Concat, [1]] #12 cat- [-1, 1, RepVGGBlocks, []] #13- [-1, 1, nn.Upsample, [None, 2, "nearest"]] #14- [[-1, 4], 1, Concat, [1]] #15 cat- [-1, 1, Conv, [256, 3]] # 16- [13, 1, Conv, [512, 3]] #17- [13, 1, Conv, [1024, 3, 2]] #18- [[16, 17, 18], 1, Detect, [nc]] # Detect(P3, P4, P5)# ⭐⭐Powered by https://blog.csdn.net/StopAndGoyyy, 技术指导QQ:2668825911⭐⭐
2.3 修改train.py文件
创建Train脚本用于训练。
from ultralytics.models import YOLO
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'if __name__ == '__main__':model = YOLO(model='ultralytics/cfg/models/xy_YOLO/xy_yolov1.yaml')# model = YOLO(model='ultralytics/cfg/models/11/yolo11l.yaml')model.train(data='./datasets/data.yaml', epochs=1, batch=1, device='0', imgsz=320, workers=1, cache=False,amp=True, mosaic=False, project='run/train', name='exp',)
在train.py脚本中填入修改好的yaml路径,运行即可训练,数据集创建教程见下方链接。
YOLOv11入门到入土使用教程(含结构图)_yolov11使用教程-CSDN博客