注意力机制从理论到实践:注意力提示、汇聚与评分函数
目录
注意力机制:是什么?有啥用?
一、注意力机制是什么?
二、注意力机制有啥用?
三、注意力机制的核心逻辑(“关注什么→怎么关联→如何融合”)
1. 明确 “关注目标”(Query 的定义)
2. 计算 “关联强度”(注意力权重的量化)
3. 归一化 “重要性”(注意力权重的归一化)
4. 聚焦融合关键信息(注意力汇聚)
详细介绍三个技术点
一、注意力提示(Attention Cues)
理论
实践
1.完整代码
2.实践结果
二、注意力汇聚(Attention Aggregation)
理论
1、核心步骤:
2、示例:
进一步解释
3、分类详解
一、平均汇聚(Average Pooling)
二、非参数注意力汇聚(Non-parametric Attention Pooling)
三、带参数注意力汇聚(Parametric Attention Pooling)
实践
1、完整代码
2、实践结果
1、平均汇聚
2、非参数注意力汇聚
3、带参数注意力汇聚
三、 注意力评分函数(Attention Scoring Function)
理论
1、缩放点积(Scaled Dot-Product)
2、加性评分(Additive Score)
3、核心对比与总结
实践
1、完整代码
2、实验结果
注意力机制:是什么?有啥用?
一、注意力机制是什么?
注意力机制(Attention Mechanism)是一种模拟人类注意力分配方式的计算框架,核心思想是:在处理信息时,有选择地聚焦于关键信息,忽略次要信息,从而高效利用计算资源并提升任务性能。
它的本质是一种 “权重分配机制”:对于输入的一系列信息(如文本中的词语、图像中的像素、序列中的元素),通过计算每个信息的 “重要性权重”,让模型在输出时更关注权重高的关键信息,权重低的信息则被弱化。
二、注意力机制有啥用?
注意力机制的核心价值在于解决 “信息过载” 和 “长距离依赖” 问题,具体作用体现在以下几个方面:
-
聚焦关键信息,提升效率
现实场景中,输入数据往往包含大量冗余信息(例如,一句话中可能只有几个关键词决定语义,一张图片中只有部分区域是核心目标)。注意力机制通过分配权重,让模型优先处理关键信息,减少对无关信息的计算,提升处理效率。示例:在机器翻译 “我爱自然语言处理” 时,模型会更关注 “爱”“自然语言处理” 等核心词,而非虚词 “我”。
-
捕捉长距离依赖关系
在序列数据(如文本、时间序列)中,远距离元素可能存在重要关联(例如,句子中 “他” 可能指代前文的 “小明”)。传统模型(如 RNN)处理长序列时容易丢失远距离信息,而注意力机制通过直接计算任意两个元素的关联权重,能精准捕捉这种长距离依赖。示例:在文本理解中,注意力机制可让模型明确 “他” 与 “小明” 的指代关系,即使两者相隔多个句子。
-
增强模型可解释性
注意力机制的权重分布可直观展示模型关注的信息,帮助人类理解模型决策逻辑。例如:- 机器翻译中,通过注意力权重可看到输出词对应输入的哪个词;
- 图像分类中,权重热力图可显示模型关注的图像区域(如识别 “猫” 时,权重集中在猫的头部和身体)。
-
适应多模态任务
在图文匹配、视频字幕等多模态任务中,注意力机制能动态关联不同模态的信息(如文本中的 “红色” 与图像中的红色区域),实现跨模态的信息融合。 -
成为 Transformer 等模型的核心组件
注意力机制是 Transformer 架构的核心(如 BERT、GPT 等大语言模型均基于 Transformer),其并行计算能力克服了 RNN 的序列依赖限制,使得模型能高效处理超长序列,推动了自然语言处理等领域的突破性进展。
三、注意力机制的核心逻辑(“关注什么→怎么关联→如何融合”)
1. 明确 “关注目标”(Query 的定义)
核心技术:自顶向下 / 自底向上的注意力提示(Cues)
- 自顶向下提示:由任务目标定义 “关注方向”(如翻译时,解码器当前状态作为 Query,代表 “需要翻译的词”)。
- 自底向上提示:由输入数据的显著性特征驱动(如文本中高频词、图像中高对比度区域)。
- 作用:确定 “Query”(当前任务的关注点),回答 “模型应该关注什么”。
2. 计算 “关联强度”(注意力权重的量化)
核心技术:注意力评分函数(Scoring Function)
- 功能:计算 Query 与输入中每个信息单元(Key)的相似度,量化 “关联强度”。
- 常见实现:
- 缩放点积(Scaled Dot-Product):
(Transformer 核心,高效并行)。
- 加性评分(Additive Score):
(Bahdanau 注意力采用,适合维度不匹配场景)。
- 余弦相似度:衡量向量方向的一致性(适合语义匹配)。
- 缩放点积(Scaled Dot-Product):
- 作用:将 “关联强度” 转化为原始分数,为后续权重归一化做准备。
3. 归一化 “重要性”(注意力权重的归一化)
核心技术:Softmax 归一化
- 功能:将原始评分转化为总和为 1 的注意力权重(\(\alpha_i\)),确保权重可直接用于加权融合。
- 公式:
。
- 作用:让权重满足 “重要性占比” 的物理意义(权重越高,对应信息越重要)。
4. 聚焦融合关键信息(注意力汇聚)
核心技术:加权求和(Weighted Aggregation)
- 功能:将输入信息(Value)按注意力权重加权求和,得到 “聚焦于 Query 的融合结果”。
- 公式:
,
为与
对应的信息内容)。
- 作用:输出由关键信息主导的结果,实现 “关注重要信息、忽略次要信息”。
详细介绍三个技术点
一、注意力提示(Attention Cues)
理论
注意力提示是引导模型 “关注什么” 的信号,本质是驱动注意力分配的线索。人类注意力的分配受两种提示影响,机器学习中也借鉴了这一机制:
-
非自主性提示(自下而上的线索) 由输入数据本身的显著特征触发,无需外部目标引导。例如:
- 图像中颜色鲜艳的物体(如红色苹果在绿色树叶中);
- 文本中高频出现的关键词(如新闻中的 “地震”)。 模型通过感知输入的 “显著性” 自动聚焦于这些特征。
-
自主性提示(自上而下的线索) 由任务目标或外部指令驱动,引导模型主动关注特定信息。例如:
- 机器翻译中,翻译 “猫坐在垫子上” 时,“猫” 作为主语需重点关注;
- 目标检测中,任务要求 “找到图像中的汽车”,模型会主动搜索汽车的特征(轮子、车窗等)。
作用:注意力提示决定了模型 “应该关注输入的哪些部分”,是注意力机制的 “导向标”。
实践
1.完整代码
"""
文件名: 10.1 注意力机制
作者: 墨尘
日期: 2025/7/16
项目名: dl_env
备注: 注意力权重可视化工具 - 使用热图展示注意力分布
"""
# 导入必要的库
import matplotlib.pyplot as plt # 用于绘图
import torch # PyTorch深度学习框架
from d2l import torch as d2l # 动手学深度学习(Dive into Deep Learning)的辅助库#@save
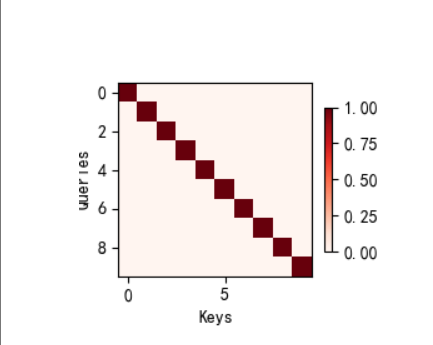
def show_heatmaps(matrices, xlabel, ylabel, titles=None, figsize=(2.5, 2.5),cmap='Reds'):"""显示矩阵热图 - 用于可视化注意力权重参数:matrices: 待可视化的矩阵张量,形状为(行数, 列数, 高度, 宽度)xlabel: x轴标签ylabel: y轴标签titles: 每个子图的标题列表(可选)figsize: 每个子图的大小,元组(宽, 高)cmap: 颜色映射,默认使用红色系('Reds')"""d2l.use_svg_display() # 使用SVG格式显示图形,提高清晰度# 获取矩阵的行数和列数,用于创建子图网格num_rows, num_cols = matrices.shape[0], matrices.shape[1]# 创建子图网格,设置共享坐标轴以保证对齐fig, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize,sharex=True, sharey=True, squeeze=False)# 遍历每个矩阵并绘制热图for i, (row_axes, row_matrices) in enumerate(zip(axes, matrices)):for j, (ax, matrix) in enumerate(zip(row_axes, row_matrices)):# 使用imshow绘制热图,将PyTorch张量转为NumPy数组并分离计算图pcm = ax.imshow(matrix.detach().numpy(), cmap=cmap)# 只在最后一行设置x轴标签,避免重复if i == num_rows - 1:ax.set_xlabel(xlabel)# 只在第一列设置y轴标签,避免重复if j == 0:ax.set_ylabel(ylabel)# 如果提供了标题,则设置子图标题if titles:ax.set_title(titles[j])# 添加统一的颜色条,缩放到0.6倍以适应布局fig.colorbar(pcm, ax=axes, shrink=0.6);if __name__ == '__main__':# 创建一个10×10的单位矩阵作为注意力权重示例# 单位矩阵表示每个查询只关注对应的键(对角线元素为1,其余为0)attention_weights = torch.eye(10).reshape((1, 1, 10, 10))# 调用函数可视化注意力权重,x轴为"Keys",y轴为"Queries"show_heatmaps(attention_weights, xlabel='Keys', ylabel='Queries')# 显示图形(在某些环境中可能不需要此行)plt.show()2.实践结果
二、注意力汇聚(Attention Aggregation)
理论
注意力汇聚是根据注意力权重对输入信息进行聚合的过程。其核心逻辑是:对输入中 “更重要” 的部分赋予更高权重,再通过加权求和整合信息。
1、核心步骤:
-
确定 “查询(Query)”“键(Key)”“值(Value)”:
- query:当前任务的 “关注点”(如翻译时的解码器当前状态);
- key:输入中可供匹配的 “特征标识”(如编码器的所有隐藏状态);
- value:与 key 对应的 “具体信息内容”(如编码器隐藏状态对应的语义)。
-
计算注意力权重:通过 “注意力评分函数”计算 query 与每个 key 的相似度,得到权重(权重之和为 1,满足归一化)。
-
加权聚合:将 value 按权重求和,得到 “聚焦于 query 的聚合结果”(即注意力输出)。
2、示例:
假设输入序列为 “[猫,在,垫子,上]”,当前 query 是 “猫”,key 是每个词的特征,value 是每个词的语义向量。若 “猫” 与 “垫子” 的相似度高(权重 0.6),与 “在” 的相似度低(权重 0.1),则聚合结果更偏向 “猫” 和 “垫子” 的语义。
进一步解释
1. Key(每个词的特征):用于计算相似度的 “标识性特征”
“特征” 在这里指的是每个词的低层次、结构化的表示,用于快速判断词与词之间的关联(即作为计算注意力权重的 “依据”)。
具体含义:特征是词的 “标识属性”,可能包含词性、词形、基础语法功能等结构化信息。例如:
- “猫” 的特征:[名词,动物,单数,主语]
- “垫子” 的特征:[名词,物品,单数,宾语]
- “在” 的特征:[介词,表位置,连接作用]
- “上” 的特征:[方位词,表位置,补充作用]
作用:特征(Key)的核心是 “可比较性”—— 通过这些结构化特征,模型能快速计算 “猫” 与其他词的相似度(例如 “猫” 和 “垫子” 都是名词,且在句中构成 “动作对象” 关系,因此特征相似度高,对应注意力权重 0.6;“猫” 和 “在” 词性差异大,特征相似度低,权重 0.1)。
2. Value(每个词的语义向量):用于聚合的 “深层语义表示”
“语义向量” 是每个词的高层次、抽象的语义表示,包含词的含义、上下文关联等深层信息,是最终参与 “注意力汇聚” 的核心内容。
具体含义:语义向量是通过嵌入层(如 Word2Vec、BERT 嵌入)或编码器生成的稠密向量,编码了词的内涵和语境意义。例如:
- “猫” 的语义向量:包含 “猫 = 小型哺乳动物 + 宠物 + 会跑跳” 等语义信息。
- “垫子” 的语义向量:包含 “垫子 = 柔软物品 + 用于坐卧 + 放置于地面” 等语义信息。
- “在” 和 “上” 的语义向量:包含 “表示位置关系” 的语义,但具体内涵较弱(因此权重低)。
作用:语义向量(Value)是注意力机制最终 “聚焦” 的内容。当计算出 “猫” 对 “垫子” 的权重为 0.6、对自身权重假设为 0.3(剩余 0.1 给 “在” 和 “上”)时,聚合结果为: 聚合向量 = 0.3×猫的语义向量 + 0.6×垫子的语义向量 + 0.1×其他词的语义向量 这个向量会更偏向 “猫” 和 “垫子” 的核心语义,从而准确表达 “猫与垫子的关联”(如 “猫在垫子上” 的核心语义)。
总结
- Key(特征):是词的 “标识性属性”,用于计算注意力权重(解决 “谁和谁相似”);
- Value(语义向量):是词的 “深层语义内容”,用于最终的加权聚合(解决 “相似的词贡献什么语义”)。
公式抽象:设注意力权重为(对应第i个 value),则聚合结果为:
![]()
注意力汇聚的核心是通过权重分配实现 “重要信息强化,次要信息弱化”。
3、分类详解
一、平均汇聚(Average Pooling)
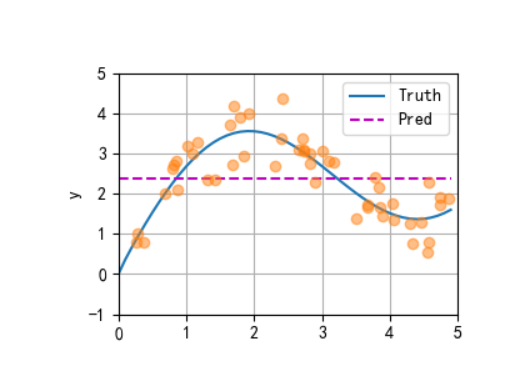
平均汇聚是最基础的 “汇聚”(Pooling)操作,核心是对输入的多个元素取算术平均值,将 “多元素” 压缩为 “单元素”,实现信息的聚合。
核心思想
忽略输入元素的 “重要性差异”,认为所有元素同等重要,通过平均操作保留整体趋势,过滤局部噪声。
公式与示例
设输入序列为
(每个
可以是标量或向量),平均汇聚的结果为:
- 示例:对序列 “[猫,在,垫子,上]” 的词向量(假设每个词向量为
)进行平均汇聚,结果为:
,即 4 个词向量的平均。
特点与应用
- 优点:简单、无参数(无需训练)、计算高效,适合快速聚合信息。
- 缺点:平等对待所有元素,会丢失重要元素的权重(例如 “猫” 可能比 “在” 更重要,但平均后被稀释)。
- 应用:早期神经网络的特征聚合(如 CNN 的池化层、简单序列模型的句子表示)。
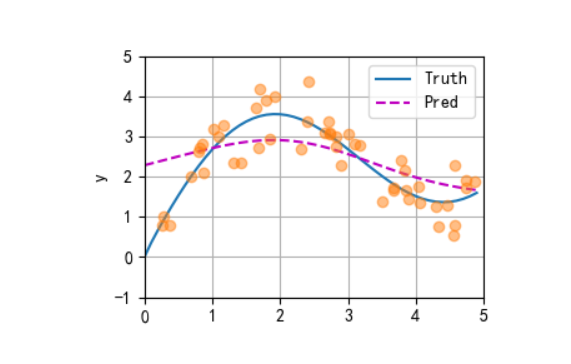
二、非参数注意力汇聚(Non-parametric Attention Pooling)
非参数注意力汇聚是注意力机制的基础形式,核心是通过计算 “查询(query)与键(key)的相似度” 动态分配权重,再加权聚合值(value),且无需要学习的参数。
核心思想
- 重要性不是固定的(区别于平均汇聚),而是由 query 与每个 key 的 “相关性” 决定:相关性越高,对应 value 的权重越大。
- 无参数:相似度计算方式固定(如高斯核、余弦相似度),不涉及可学习参数。
公式与步骤
设 query 为 q,键值对为
,非参数注意力汇聚的步骤为:
计算相似度:用固定函数(如高斯核)计算 q 与每个
。 常用高斯核(Gaussian kernel):
(
是超参数,手动设定而非学习)
权重归一化:用 softmax 将相似度转换为和为 1 的权重
加权聚合:用权重加权求和 value,得到汇聚结果:
示例
以序列 “[猫,在,垫子,上]” 为例,设:
- query q 是 “猫” 的特征向量;
- 键
分别是 “猫”“在”“垫子”“上” 的特征向量;
- 值
若计算得相似度:
,则:
- 权重
,
- 同理得
,
,
,
- 汇聚结果
,更偏向 “猫” 和 “垫子” 的语义。
特点与应用
- 优点:动态分配权重,比平均汇聚更灵活,能捕捉 query 与 key 的相关性。
- 缺点:相似度函数固定(如高斯核的 \(\sigma\) 需手动调),无法适应任务自动优化。
- 应用:早期注意力模型(如 Bahdanau 注意力的简化版)、无监督学习中的特征聚合。
三、带参数注意力汇聚(Parametric Attention Pooling)
带参数注意力汇聚在非参数版本的基础上引入可学习参数,让模型通过训练自动优化 “相似度计算方式”,更适应任务需求。
核心思想
- 相似度计算不再固定,而是由可学习参数(如权重矩阵、偏置)定义,模型通过训练学习 “如何衡量相关性”。
- 权重
不仅依赖 query 和 key,还依赖参数,能更精准地捕捉任务相关的重要性。
典型形式与公式
常用的带参数注意力包括加性注意力(Additive Attention) 和缩放点积注意力(Scaled Dot-Product Attention),以加性注意力为例:
相似度计算:用小型神经网络(含参数)计算相似度:
是权重矩阵,
是权重向量,b 是偏置,均为可学习参数)
权重归一化:同非参数版本,用 softmax 得
加权聚合:同前,
。
与非参数的关键区别
- 非参数:相似度函数固定(如高斯核),无参数,灵活性低。
- 带参数:相似度函数由参数定义,可学习,能适应不同任务(如机器翻译中 “猫” 与 “垫子” 的相关性可能比 “在” 更高,参数会学习强化这一点)。
实践
1、完整代码
"""
文件名: 10.2
作者: 墨尘
日期: 2025/7/16
项目名: dl_env
备注: 注意力汇聚的核回归示例 - 对比平均汇聚、非参数注意力汇聚、带参数注意力汇聚的效果
"""
# 导入必要库
import torch # PyTorch深度学习框架,用于张量计算和模型构建
from torch import nn # PyTorch的神经网络模块,含激活函数、损失函数等
from d2l import torch as d2l # 动手学深度学习的辅助库,含绘图和数据处理工具
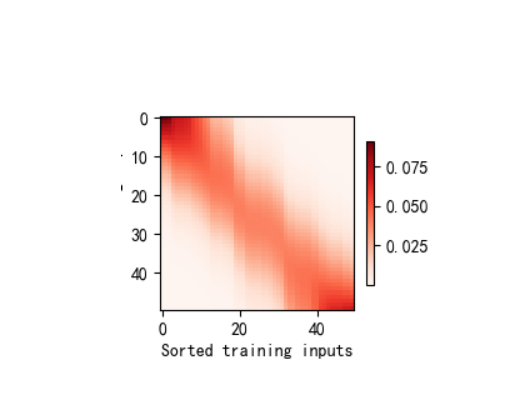
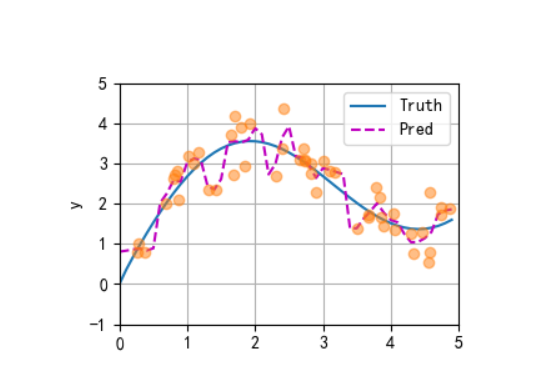
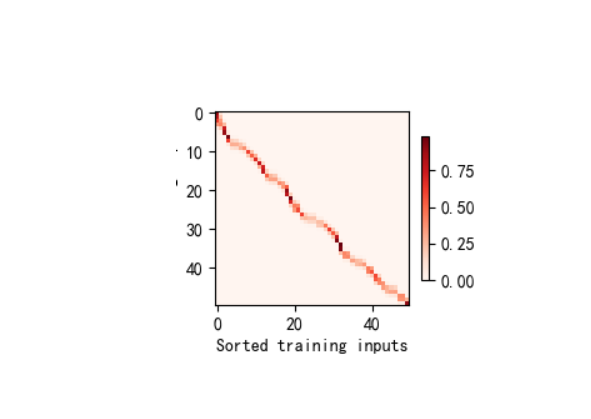
import matplotlib.pyplot as plt # 用于图形显示def plot_kernel_reg(y_hat):"""可视化核回归的预测结果与真实值对比参数:y_hat: 模型的预测值张量,形状为(测试样本数,)"""# 绘制真实值(Truth)和预测值(Pred)曲线d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],xlim=[0, 5], ylim=[-1, 5]) # x轴范围0-5,y轴范围-1-5# 绘制训练样本点(散点图),alpha=0.5设置透明度d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);class NWKernelRegression(nn.Module):"""带参数的注意力汇聚模型(核回归) - Nadaraya-Watson核回归的参数化版本引入可学习参数w,用于调整注意力权重的缩放程度"""def __init__(self, **kwargs):super().__init__(** kwargs) # 继承nn.Module的初始化方法# 定义可学习参数w,初始值随机,需要计算梯度(requires_grad=True)self.w = nn.Parameter(torch.rand((1,), requires_grad=True))def forward(self, queries, keys, values):"""前向传播:计算带参数的注意力汇聚结果参数:queries: 查询张量,形状为(查询样本数,)keys: 键张量,形状为(查询样本数, 键值对数量)values: 值张量,形状为(查询样本数, 键值对数量)返回:注意力汇聚的预测结果,形状为(查询样本数,)"""# 将查询重复为与键同形状:(查询数, 键值对数量),每一行都是相同的查询queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))# 计算注意力权重:基于查询与键的距离,用softmax归一化# 公式:权重 = softmax( -((查询-键)*w)^2 / 2 ),w为可学习参数,控制距离的缩放self.attention_weights = nn.functional.softmax(-((queries - keys) * self.w) **2 / 2, dim=1) # dim=1表示按行归一化# 批量矩阵乘法:注意力权重(查询数,1,键值对数) × 值(查询数,键值对数,1) → 预测结果return torch.bmm(self.attention_weights.unsqueeze(1), # 增加维度以满足bmm要求values.unsqueeze(-1)).reshape(-1) # 压缩维度为(查询数,)if __name__ == '__main__':# -------------------------- 1. 生成训练数据和测试数据 --------------------------n_train = 50 # 训练样本数量# 生成训练输入x_train:0-5之间的随机数,排序后便于后续可视化x_train, _ = torch.sort(torch.rand(n_train) * 5)# 定义真实函数f(x) = 2*sin(x) + x^0.8(非线性函数,适合核回归测试)def f(x):return 2 * torch.sin(x) + x** 0.8# 生成训练输出y_train:真实值+噪声(模拟真实数据中的观测误差)y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 噪声均值0,标准差0.5# 生成测试输入x_test:0-5之间间隔0.1的均匀采样(共50个点)x_test = torch.arange(0, 5, 0.1)y_truth = f(x_test) # 测试数据的真实输出(无噪声)n_test = len(x_test) # 测试样本数量(50)print(f"测试样本数量: {n_test}") # 输出:50# -------------------------- 2. 平均汇聚(基准模型) --------------------------# 平均汇聚:所有测试样本的预测值都等于训练数据的平均值(忽略输入特征,最简单的汇聚方式)y_hat = torch.repeat_interleave(y_train.mean(), n_test) # 重复平均值n_test次# 可视化平均汇聚的预测结果与真实值对比plot_kernel_reg(y_hat)plt.show() # 显示图形:平均汇聚效果差,无法捕捉非线性趋势# -------------------------- 3. 非参数注意力汇聚 --------------------------# 构造查询矩阵X_repeat:形状(n_test, n_train),每行都是相同的测试输入(查询)X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))# 计算注意力权重:基于查询与键(训练输入x_train)的欧式距离,用高斯核度量相似度# 公式:权重 = softmax( -(查询-键)^2 / 2 ),无参数,完全由数据驱动attention_weights = nn.functional.softmax(-(X_repeat - x_train) **2 / 2, dim=1)# 非参数注意力汇聚:预测值 = 注意力权重 × 训练输出(矩阵乘法实现加权求和)y_hat = torch.matmul(attention_weights, y_train)# 可视化非参数注意力汇聚的结果plot_kernel_reg(y_hat)plt.show() # 显示图形:预测更贴近真实值,能捕捉局部趋势# 可视化非参数注意力权重的热图# 热图形状:(1,1,n_test,n_train),行=测试样本,列=训练样本,颜色越深权重越大d2l.show_heatmaps(attention_weights.unsqueeze(0).unsqueeze(0),xlabel='Sorted training inputs(键)',ylabel='Sorted testing inputs(查询)')plt.show() # 显示热图:测试样本与接近的训练样本权重更高(局部注意力)# -------------------------- 4. 带参数注意力汇聚(模型训练与测试) --------------------------# 演示批量矩阵乘法(bmm)的维度要求:用于批量处理多个样本的矩阵乘法X = torch.ones((2, 1, 4)) # 批量=2,每个矩阵1×4Y = torch.ones((2, 4, 6)) # 批量=2,每个矩阵4×6print(torch.bmm(X, Y).shape) # 输出:torch.Size([2, 1, 6]),符合矩阵乘法规则# 演示注意力权重与值的批量乘法:权重(2,1,10) × 值(2,10,1) → 结果(2,1,1)weights = torch.ones((2, 10)) * 0.1 # 均匀权重,每行和为1values = torch.arange(20.0).reshape((2, 10)) # 示例值:0-19print(torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))) # 输出每行平均值# 构造训练用的键值对(排除自身样本,避免过拟合)# X_tile:形状(n_train, n_train),每行都是相同的训练输入(作为查询)X_tile = x_train.repeat((n_train, 1))# Y_tile:形状(n_train, n_train),每行都是相同的训练输出(作为值)Y_tile = y_train.repeat((n_train, 1))# 键:排除对角线元素(自身样本),形状(n_train, n_train-1)keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))# 值:对应排除自身样本的训练输出,形状(n_train, n_train-1)values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))# 初始化带参数的注意力模型、损失函数和优化器net = NWKernelRegression() # 带可学习参数w的模型loss = nn.MSELoss(reduction='none') # 均方误差损失,保留每个样本的损失trainer = torch.optim.SGD(net.parameters(), lr=0.5) # 随机梯度下降优化器,学习率0.5animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5]) # 可视化训练损失# 训练模型(5个epoch)for epoch in range(5):trainer.zero_grad() # 清除梯度# 前向传播:用训练数据的查询、键、值计算预测l = loss(net(x_train, keys, values), y_train)l.sum().backward() # 损失求和并反向传播trainer.step() # 更新参数wprint(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}') # 输出当前损失animator.add(epoch + 1, float(l.sum())) # 记录损失用于绘图plt.show() # 显示训练损失曲线:损失逐渐下降,参数w收敛# 用训练好的模型预测测试数据# 构造测试用的键和值:键=训练输入x_train(形状(n_test, n_train)),值=训练输出y_trainkeys = x_train.repeat((n_test, 1))values = y_train.repeat((n_test, 1))# 带参数注意力汇聚的预测结果(detach()脱离计算图,仅用于可视化)y_hat = net(x_test, keys, values).unsqueeze(1).detach()# 可视化带参数注意力汇聚的预测结果plot_kernel_reg(y_hat)plt.show() # 显示图形:预测精度进一步提升,更贴近真实值# 可视化带参数模型的注意力权重热图d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),xlabel='Sorted training inputs(键)',ylabel='Sorted testing inputs(查询)')plt.show() # 显示热图:权重更集中,参数w优化了距离的缩放,增强了局部关联性2、实践结果
1、平均汇聚
2、非参数注意力汇聚
注意力权重
3、带参数注意力汇聚
注意力权重
三、 注意力评分函数(Attention Scoring Function)
理论
注意力评分函数是计算 query 与 key 相似度的工具,其输出经归一化(如 Softmax)后即为注意力权重。常见的评分函数有两类:
1、缩放点积(Scaled Dot-Product)
- 原理:直接计算 query 与 key 的内积,再除以向量维度的平方根(避免维度过高导致内积值过大,影响 Softmax 稳定性)。
- 注意:缩放点积注意力是 Transformer 模型采用的核心注意力机制,通过向量内积计算相似度,并引入缩放因子解决维度灾难问题。
- 公式:
其中d是 query/key 的维度,
是向量内积(衡量相似度)。
- 优点:计算效率极高(仅需矩阵乘法和 softmax,适合 GPU 并行);无额外参数(仅依赖内积)。
- 缺点:当查询和键的维度 d 差异较大时,内积可能无法有效衡量相似度。
- 适用场景:高维向量、大规模批量数据(如 Transformer、BERT、GPT 等大语言模型)。
2、加性评分(Additive Score)
- 原理:通过线性变换将 query 和 key 映射到同一空间,再用 tanh 激活后与权重向量相乘,输出标量评分。
- 注意:加性注意力通过多层感知机(MLP) 计算查询与键的相似度,适用于查询和键维度不同的场景,由 Bahdanau 在机器翻译模型中首次提出。
- 公式:
其中
是可学习的权重矩阵,v是可学习的向量。
- 特点:适用于 query 与 key 维度不同的场景,计算复杂度高于点积,但灵活性更强。
评分函数的选择需根据任务场景(如维度是否一致、效率要求)决定,其核心是量化 query 与 key 的关联程度。
3、核心对比与总结
| 维度 | 缩放点积注意力 | 加性注意力 |
|---|---|---|
| 评分函数 | 内积 + 缩放( | MLP( |
| 参数数量 | 0(无额外参数) | |
| 计算复杂度 | ||
| 适用维度 | 要求 | 支持 |
| 典型应用 | Transformer、大语言模型(GPT/BERT) | Bahdanau 机器翻译、跨模态注意力 |
| 核心优势 | 效率极高,适合大规模数据 | 灵活性高,适合复杂相似度建模 |
实践
1、完整代码
"""
文件名: 10.3
作者: 墨尘
日期: 2025/7/16
项目名: dl_env
备注: 实现加性注意力(Additive Attention)和缩放点积注意力(Scaled Dot-Product Attention),包含掩码softmax功能,用于处理序列长度不一致的场景
"""
import math # 用于数学运算(如缩放点积中的平方根)
import torch # PyTorch框架,用于张量计算和模型构建
from torch import nn # 神经网络模块,含线性层、Dropout等组件
from d2l import torch as d2l # 动手学深度学习辅助库,含绘图和序列处理工具
import matplotlib.pyplot as plt # 用于图形显示#@save # 标记为可保存的函数,便于后续调用
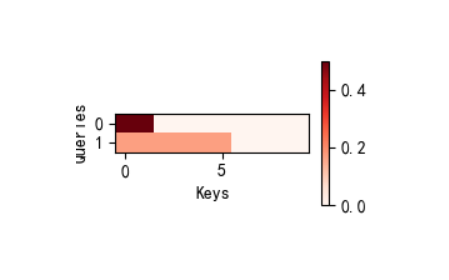
def masked_softmax(X, valid_lens):"""带掩码的softmax函数:对序列中超出有效长度的部分进行掩码(权重置为0)参数:X: 输入张量,形状通常为(batch_size, num_queries, num_keys),表示查询与键的相似度分数矩阵valid_lens: 有效长度张量,形状为(batch_size,)或(batch_size, num_queries)表示每个查询/样本的有效键值对数量(超出部分需掩码)返回:掩码后的softmax结果,形状与X一致,无效位置的权重被置为0"""if valid_lens is None:# 若没有有效长度限制,直接对最后一维做softmaxreturn nn.functional.softmax(X, dim=-1)else:shape = X.shape # 获取输入形状,用于后续恢复维度# 处理有效长度维度:若为1D(每个样本一个有效长度),则重复为与查询数匹配的2Dif valid_lens.dim() == 1:# 例如:valid_lens = [2,6],重复后变为[2,2,...,6,6,...](每个查询对应相同的样本有效长度)valid_lens = torch.repeat_interleave(valid_lens, shape[1])else:# 若为2D(每个查询有独立有效长度),则展平为1D便于处理valid_lens = valid_lens.reshape(-1)# 1. 将X展平为(batch_size * num_queries, num_keys),便于统一处理掩码# 2. 使用d2l.sequence_mask对超出有效长度的位置填充-1e6(softmax后接近0)X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6)# 恢复原形状并对最后一维做softmax,确保无效位置权重为0return nn.functional.softmax(X.reshape(shape), dim=-1)#@save
class AdditiveAttention(nn.Module):"""加性注意力模型(Bahdanau注意力):通过MLP计算查询与键的相似度"""def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):"""初始化加性注意力参数参数:key_size: 键的特征维度query_size: 查询的特征维度num_hiddens: 隐藏层维度(MLP的中间维度)dropout: Dropout概率,用于防止过拟合**kwargs: 其他可选参数"""super(AdditiveAttention, self).__init__(** kwargs)# 键的线性投影层:将键从key_size映射到num_hiddens,无偏置self.W_k = nn.Linear(key_size, num_hiddens, bias=False)# 查询的线性投影层:将查询从query_size映射到num_hiddens,无偏置self.W_q = nn.Linear(query_size, num_hiddens, bias=False)# 输出层:将隐藏层特征映射到标量(相似度分数),无偏置self.w_v = nn.Linear(num_hiddens, 1, bias=False)# Dropout层:训练时随机丢弃部分注意力权重,降低过拟合风险self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):"""前向传播:计算加性注意力的输出参数:queries: 查询张量,形状为(batch_size, num_queries, query_size)keys: 键张量,形状为(batch_size, num_kv_pairs, key_size)(num_kv_pairs为键值对数量)values: 值张量,形状为(batch_size, num_kv_pairs, value_size)valid_lens: 有效长度张量,形状为(batch_size,)或(batch_size, num_queries)返回:注意力加权后的输出,形状为(batch_size, num_queries, value_size)"""# 1. 线性投影:将查询和键映射到隐藏空间queries, keys = self.W_q(queries), self.W_k(keys) # 形状分别为:(batch_size, num_queries, num_hiddens)、(batch_size, num_kv_pairs, num_hiddens)# 2. 扩展维度并广播相加:模拟加性注意力的特征融合# queries.unsqueeze(2):在第2维增加维度 → (batch_size, num_queries, 1, num_hiddens)# keys.unsqueeze(1):在第1维增加维度 → (batch_size, 1, num_kv_pairs, num_hiddens)# 广播机制:相加后形状为(batch_size, num_queries, num_kv_pairs, num_hiddens)features = queries.unsqueeze(2) + keys.unsqueeze(1)features = torch.tanh(features) # 激活函数,增强非线性表达能力# 3. 计算相似度分数:将隐藏特征映射为标量分数# self.w_v(features):形状为(batch_size, num_queries, num_kv_pairs, 1)# squeeze(-1):移除最后一维 → (batch_size, num_queries, num_kv_pairs)scores = self.w_v(features).squeeze(-1)# 4. 计算带掩码的注意力权重:超出有效长度的位置权重为0self.attention_weights = masked_softmax(scores, valid_lens)# 5. 加权聚合值:注意力权重 × 值,应用Dropout防止过拟合# 批量矩阵乘法:(batch_size, num_queries, num_kv_pairs) × (batch_size, num_kv_pairs, value_size)# → 输出形状:(batch_size, num_queries, value_size)return torch.bmm(self.dropout(self.attention_weights), values)#@save
class DotProductAttention(nn.Module):"""缩放点积注意力:通过向量内积计算相似度,引入缩放因子缓解维度问题"""def __init__(self, dropout, **kwargs):"""初始化缩放点积注意力参数:dropout: Dropout概率,用于防止过拟合**kwargs: 其他可选参数"""super(DotProductAttention, self).__init__(** kwargs)self.dropout = nn.Dropout(dropout) # Dropout层def forward(self, queries, keys, values, valid_lens=None):"""前向传播:计算缩放点积注意力的输出参数:queries: 查询张量,形状为(batch_size, num_queries, d)(d为特征维度,需与键相同)keys: 键张量,形状为(batch_size, num_kv_pairs, d)values: 值张量,形状为(batch_size, num_kv_pairs, value_size)valid_lens: 有效长度张量,形状为(batch_size,)或(batch_size, num_queries)(可选)返回:注意力加权后的输出,形状为(batch_size, num_queries, value_size)"""d = queries.shape[-1] # 获取特征维度d,用于缩放因子计算# 1. 计算相似度分数:查询 × 键的转置,除以√d(缩放因子)# keys.transpose(1,2):交换键的后两维 → (batch_size, d, num_kv_pairs)# 批量矩阵乘法:(batch_size, num_queries, d) × (batch_size, d, num_kv_pairs) → (batch_size, num_queries, num_kv_pairs)# 缩放:除以√d,避免高维时内积值过大导致softmax梯度消失scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)# 2. 计算带掩码的注意力权重self.attention_weights = masked_softmax(scores, valid_lens)# 3. 加权聚合值:应用Dropout后与值做批量矩阵乘法return torch.bmm(self.dropout(self.attention_weights), values)if __name__ == '__main__':# -------------------------- 1. 测试掩码softmax函数 --------------------------# 测试1:valid_lens为1D张量(每个样本一个有效长度)# 输入X形状:(2,2,4) → 2个样本,每个样本2个查询,4个键# valid_lens = [2,3] → 第1个样本有效键长度为2,第2个为3print("掩码softmax测试1(1D valid_lens):")print(masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3])))# 输出解读:每行(查询)中,超出有效长度的位置softmax结果接近0# 测试2:valid_lens为2D张量(每个查询独立有效长度)# valid_lens = [[1,3], [2,4]] → 第1个样本第1个查询有效长度1,第2个查询3;第2个样本类似print("\n掩码softmax测试2(2D valid_lens):")print(masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]])))# 输出解读:每个查询的有效长度独立,超出部分权重为0# -------------------------- 2. 测试加性注意力 --------------------------# 构造输入数据# queries:2个样本,每个样本1个查询,维度20 → (2,1,20)# keys:2个样本,每个样本10个键,维度2 → (2,10,2)queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))# values:2个样本,每个样本10个值,维度4(值=0~39,重复2次)→ (2,10,4)values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)valid_lens = torch.tensor([2, 6]) # 有效长度:第1个样本只关注前2个键,第2个关注前6个# 初始化加性注意力模型attention = AdditiveAttention(key_size=2, # 键的维度query_size=20, # 查询的维度num_hiddens=8, # 隐藏层维度dropout=0.1 # Dropout概率)attention.eval() # 切换到评估模式(不启用Dropout)# 前向传播计算注意力输出output = attention(queries, keys, values, valid_lens)print("\n加性注意力输出形状:", output.shape) # 应为(2,1,4)# 可视化注意力权重热图:形状(1,1,2,10) → 2个样本,每个样本1个查询,10个键d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')# 热图解读:颜色越深表示权重越大,第1个样本仅前2个键有权重,第2个样本前6个键有权重plt.show()# -------------------------- 3. 测试缩放点积注意力 --------------------------# 构造查询:2个样本,每个样本1个查询,维度2(与键维度一致)→ (2,1,2)queries = torch.normal(0, 1, (2, 1, 2))# 初始化缩放点积注意力模型attention = DotProductAttention(dropout=0.5)attention.eval() # 评估模式# 前向传播计算输出output = attention(queries, keys, values, valid_lens)print("\n缩放点积注意力输出形状:", output.shape) # 应为(2,1,4)# 可视化注意力权重热图d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),xlabel='Keys', ylabel='Queries')# 热图解读:与加性注意力类似,有效长度内的键有权重,但具体分布因评分函数不同而有差异plt.show()2、实验结果