自适应哈希索引 和 日志缓冲区
目录
1. 自适应哈希索引在内存中的位置
2. 自适应哈希索引的作用
3. 为什么要创建自适应哈希索引
4. 适应哈希索引的Key -Value如何设置?
5. 日志缓冲区在内存中的位置
6. 日志缓冲区的作用
7. 日志不通过LogBuffer直接写入磁盘不行吗?
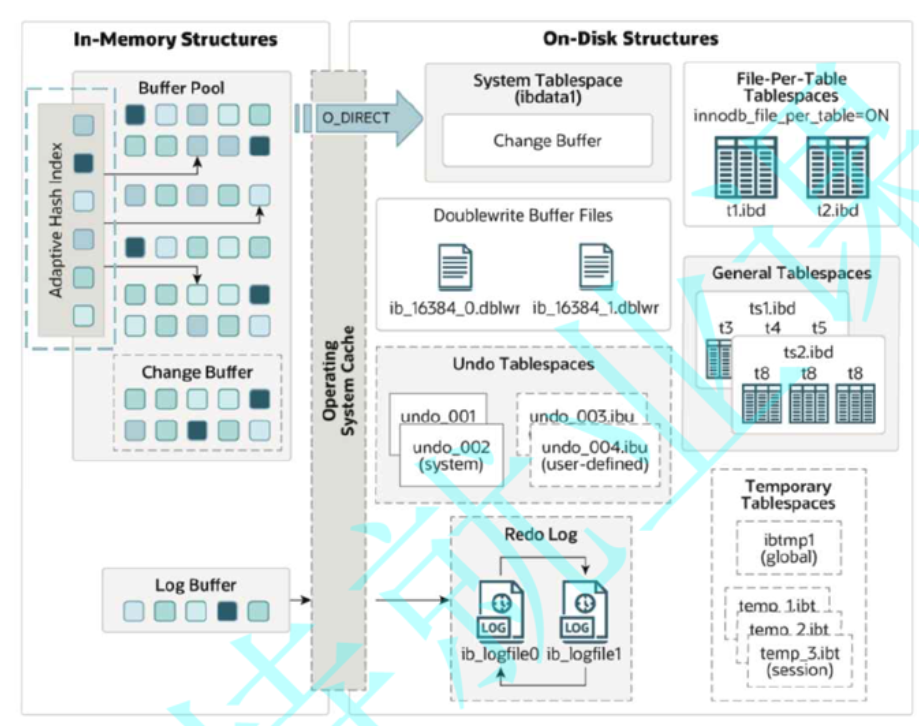
1. 自适应哈希索引在内存中的位置
2. 自适应哈希索引的作用
自适应哈希索引的主要作用就是提升查询效率
自适应哈希索引可以使InnoDB存储引擎在不牺牲事务特性和可靠性以及缓冲池空间足够的前提下提升效率,使用起来更像是一个内存数据库,哈希索引根据经常访问的索引页自动构建;
根据InnoDB内部的监控机制,如果监控到某些查询通过建立哈希索引可以提高性能,则自动对这个页创建哈希索引,这个过程称为自适应,所以叫自适应哈希索引;
如果表完全放在内存中,则哈希索引可以通过直接查找任何元素来加快查询速度
3. 为什么要创建自适应哈希索引
在内存级别进一步提升效率
InnoDB存储引擎的数据存储于B+树中,B+树通常只有3到5层,但从根节点到叶节点的寻路涉及到多层页面内记录的比较,即使所有路径上的页面都在内存中,也非常消耗CPU的资源
InnoDB对寻路的开销进行了优化,比如寻路结束后将cursor缓存起来方便下次查询复用;尽可能的避免单词寻路开销,Adaptive hash index(AHI) 便是为此而设计,可以理解为B+树的索引
本质上是通过缩短寻路路径(Search Path)从而提升MySQL查询性能的一种方式
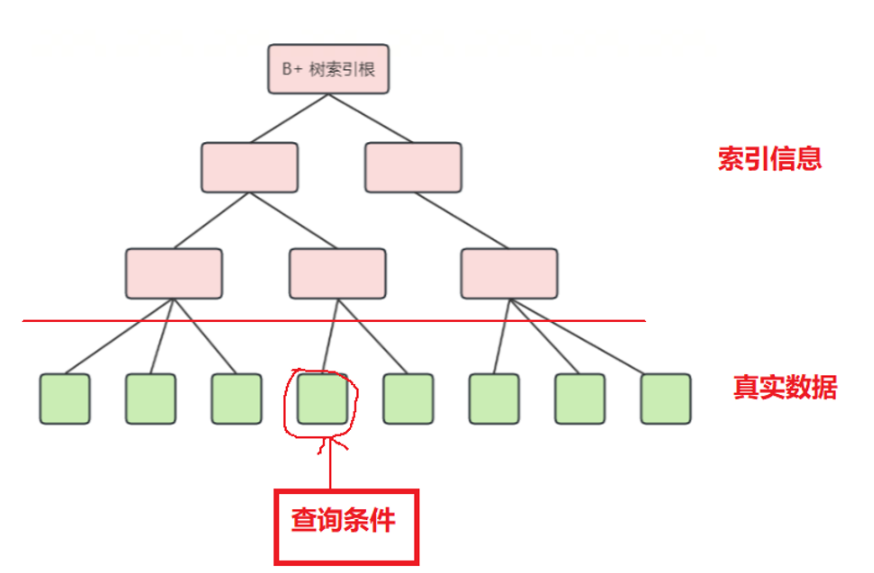
4. 适应哈希索引的Key -Value如何设置?
查询条件为key,B+树页的地址为value的Hash Index
适应哈希索引是InnoDB内部的优化方式,外部不能干预
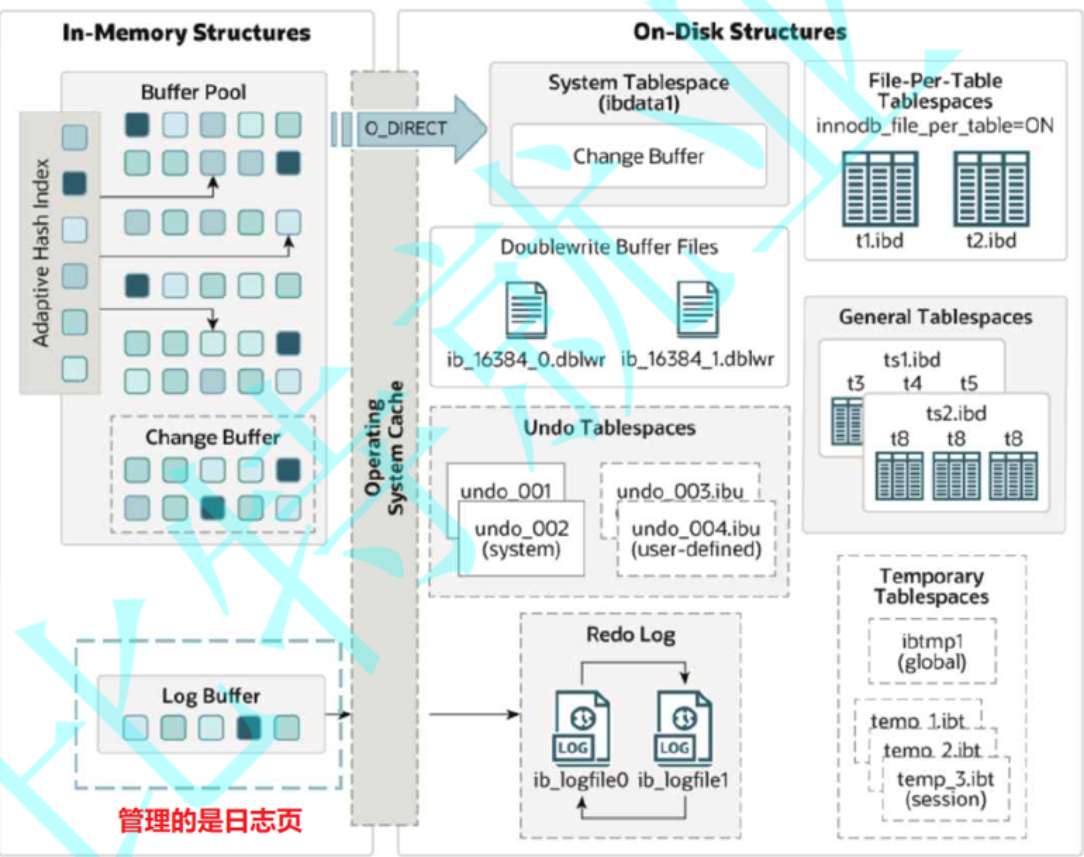
5. 日志缓冲区在内存中的位置
6. 日志缓冲区的作用
日志缓冲区是服务器启动时向操作系统申请的一片连续的内存区域,存储即将要写入磁盘日志文件的数据
在对数据库进行DML操作时,InnoDB会记录对应操作的日志,比如为保证数据完整性实现数据库崩溃恢复的Redo Log,,这些日志会首先写入LogBuffer中,从而解决同步写磁盘导致的性能问题,然后根据不同落盘策略最终写入磁盘
7. 日志不通过LogBuffer直接写入磁盘不行吗?
如果日志不通过LogBuffer直接写入磁盘,那么每次进行DML操作都会进行一次磁盘l/O,这样会严重影响效率,所以把日志统一写入内存中的LogBuffer,根据刷盘策略统一进行落盘操作,可以实现一次磁盘I/O写入多条日志,从而提升效率