颠覆NLP十年范式!OpenCSG中文数据集助推CMU无分词器模型登顶SOTA
颠覆NLP十年范式!OpenCSG中文数据集助推CMU无分词器模型登顶SOTA
语言模型正迎来划时代的技术跃迁!传统Transformer架构依赖分词器(tokenizer)的范式即将被颠覆,一种全新的端到端建模方式正在崛起。最新研究表明,通过创新的动态分块技术和分层网络架构(H-Net),AI模型首次实现了从原始字节到语义理解的完整闭环,标志着大模型技术正式迈入"后分词时代"。
这项突破性技术展现出三大革命性特征:
-
架构革新:
H-Net通过动态学习数据分块策略,彻底摒弃了传统分词流程,构建了首个真正意义上的端到端语言模型。 -
性能飞跃:
在同等计算资源下,字节级H-Net不仅超越传统分词模型,其多层抽象架构更展现出指数级的数据效率提升。 -
跨域优势:
对中文等非空格语言的处理能力实现质的突破,数据效率最高提升4倍。
特别值得关注的是,这项技术在处理复杂语言场景时展现出惊人潜力:
- 中文理解:原生支持汉字字节流处理,避免传统分词导致的语义割裂。
- 代码生成:直接学习编程语言的底层结构模式。
- 生物序列:对DNA等非自然语言实现高效建模。
这不仅是技术架构的升级,更代表着AI对人类语言的认知方式发生了根本性转变。随着无分词架构的成熟,我们正见证大模型技术从"模拟理解"迈向"本质理解"的关键转折。下一代语言模型的竞赛,已经在新赛道上悄然展开!

OpenCSG中文数据集
在最新一代H-Net无分词器大模型的训练过程中,研究团队采用了OpenCSG最新发布的FineWeb-Edu Chinese V2.1高质量中文教育数据集。这一专为教育领域定制的中文预训练语料库包含188M条经过严格筛选的文本(约420B tokens),通过新一代csg-wukong-enterprise V2评分模型进行质量把控,确保了数据的高质量和教育相关性。
Chinese FineWeb Edu v2
在数据来源方面进行了显著扩展,整合了多个领域的高质量数据集。相较于初代版本,新增了Industry2、CCI3、MiChao、WanJuan1.0、WuDao和ChineseWebText等优质数据源。
这种多元化的数据整合策略使Chinese FineWeb Edu v2具备了更全面的知识覆盖和更强的领域适应性,能够更好地支持教育领域各类NLP任务的训练需求。通过精心设计的融合方案,确保了不同来源数据在风格和质量上的一致性,为构建高性能教育大模型奠定了坚实基础。
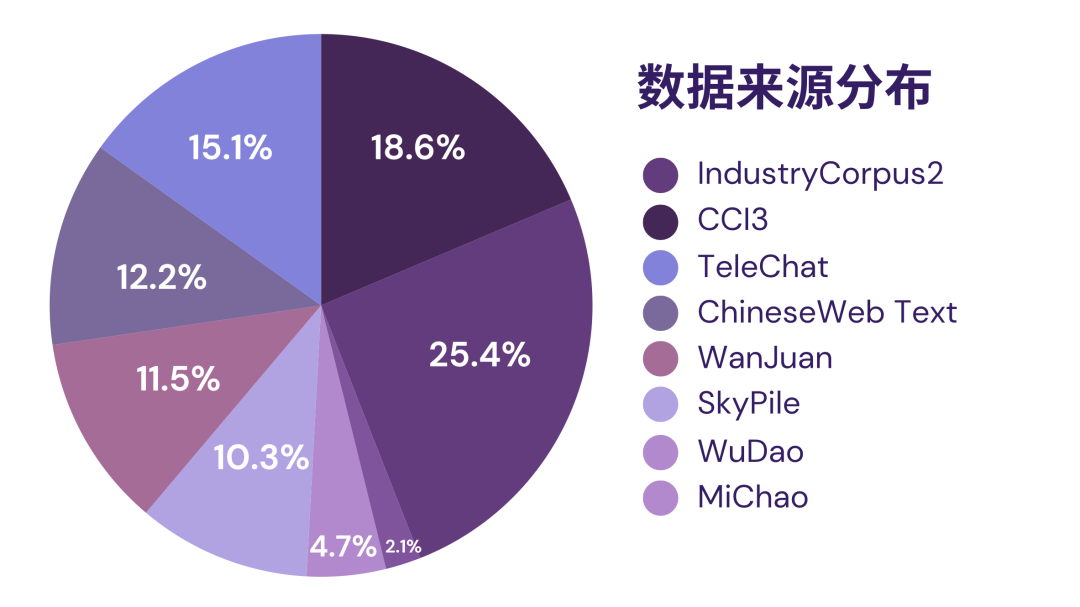
作为教育NLP任务的新标杆,该数据集具有以下显著优势:
-
规模与质量的双重突破
- 数据总量达188M条精选文本(约420B tokens)。
- 采用csg-wukong-enterprise V2评分模型进行严格筛选。
- 包含25%中英对照数据,增强跨语言理解能力。
- 设置3分以上的质量阈值,保证教育内容的专业性。
-
多源数据的深度整合
- 融合Industry2、CCI3等六大优质数据源。
- 涵盖工业、科技、文化等多个专业领域。
- 包含专业文献、技术文档等多样化内容形式。
- 通过创新融合方案确保数据一致性。
-
教育场景的专项优化
- 重构Prompt设计框架以强化教育语义理解。
- 建立多维评估体系(相关性、完整性等指标)。
- 特别适配试题解析、知识点归纳等教育任务。
- 在C-Eval评测中表现优异。
该数据集已在全球范围内确立行业标杆地位,作为下载量TOP3的中文预训练数据集,其影响力体现在多个维度:
在学术领域,获得Stanford、Tsinghua、中国人民大学高瓴人工智能学院、上海人工智能实验室(Shanghai AI Lab)、北京智源研究院(BAAI)等20余家顶尖机构的论文引用和实际应用;在产业界,支撑了Llama3-Chinese、DeepSeek等知名模型的训练,并被面壁智能(ModelBest)、中国移动、中国联通、英伟达(NVIDIA)等领军企业采用。
数据集已形成规模化的生态影响力:
月下载量突破万次,日均处理数千次请求;数据体量达2.42TB,覆盖9.57亿条高质量文本;通过集成13项细分数据集,构建了完整的中文训练套件。其衍生价值尤为突出:已孵化出10余个垂直领域微调模型(涵盖医疗/法律/金融等方向),并催生30多个GitHub开源项目(包括数据清洗工具、评估框架等)。
这一高质量中文训练数据集不仅被收录进权威数据库,更通过其严格的质量标准、专业的教育优化和广泛的应用适配性,持续推动着教育NLP开源生态的发展,为AI技术在教育领域的深度应用提供了坚实基础。随着OpenCSG计划开源评分模型和标注数据,其影响力将进一步扩大,为中文大模型的发展注入新的动力。
大模型分词器的弊端
传统分词方法(如BPE等)存在以下主要不足:
1. 语义理解局限
- 固定词汇表导致语义单元被强制拆分(如将"product"拆分为"pro-“和”-duct")。
- 无法动态适应不同语境下的语义边界。
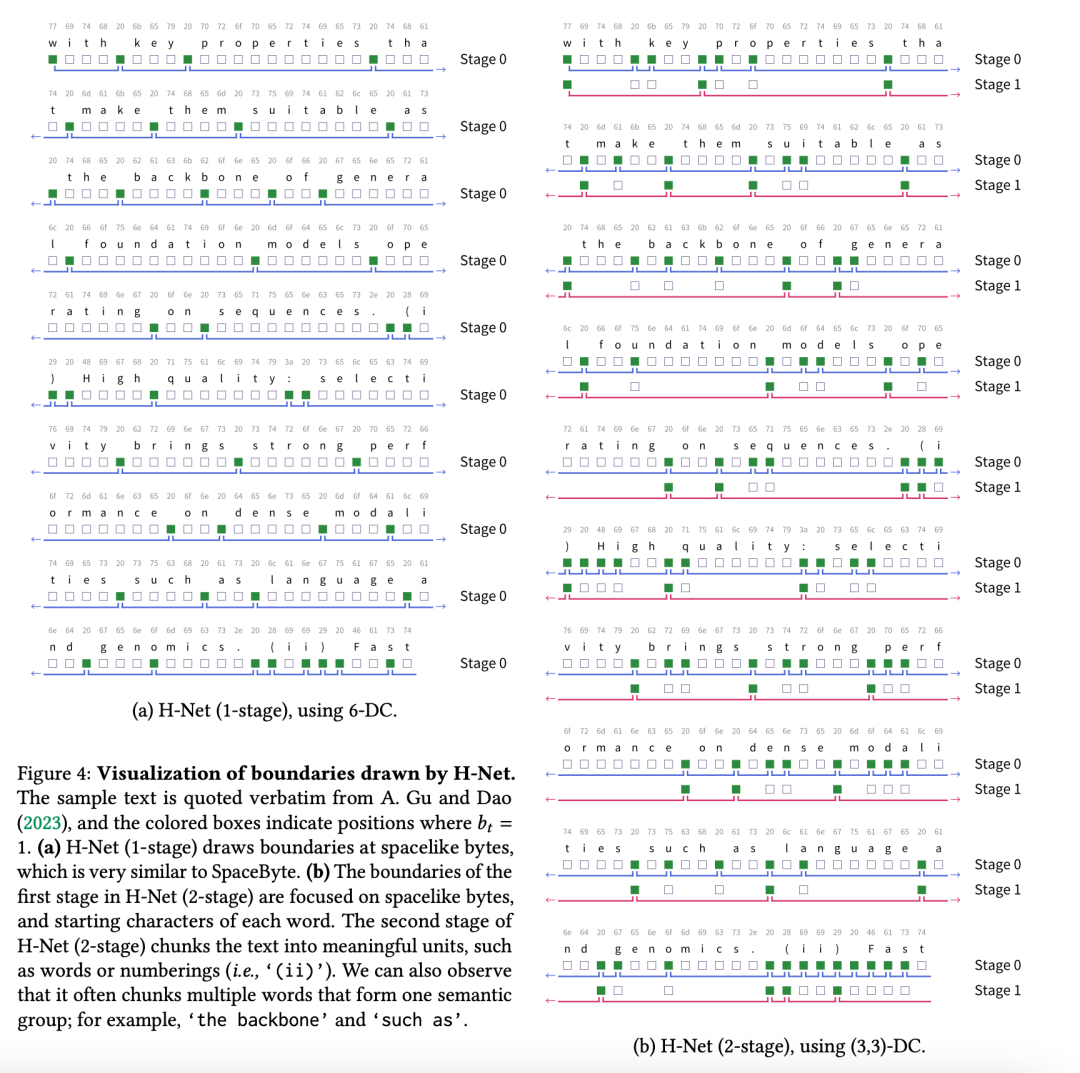
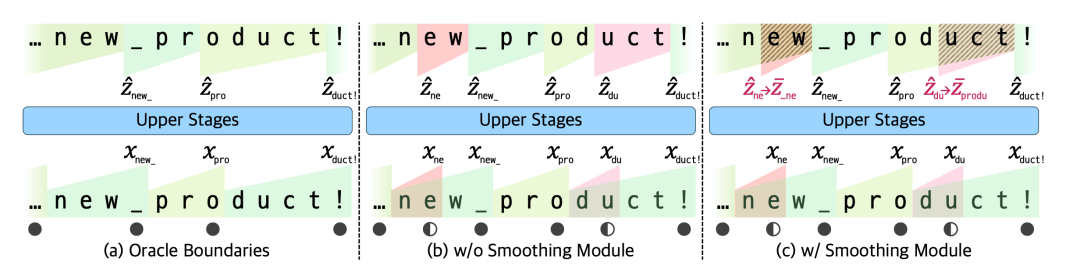
H-Net能动态适应不同语境下的语义边界,完全摒弃预定义词表限制,支持任意长度的语义组合。有效避免传统方法强制拆分语义单元的问题同时能保持词语、短语等语言结构的自然完整性,克服了BPE等传统分词方法的不足,下图为效果示意图:
2. 跨语言适应性差
- 对中文等无空格语言效果不佳。
- 非拉丁语系语言需要特殊处理规则。
- DNA序列等非自然语言场景表现更差。
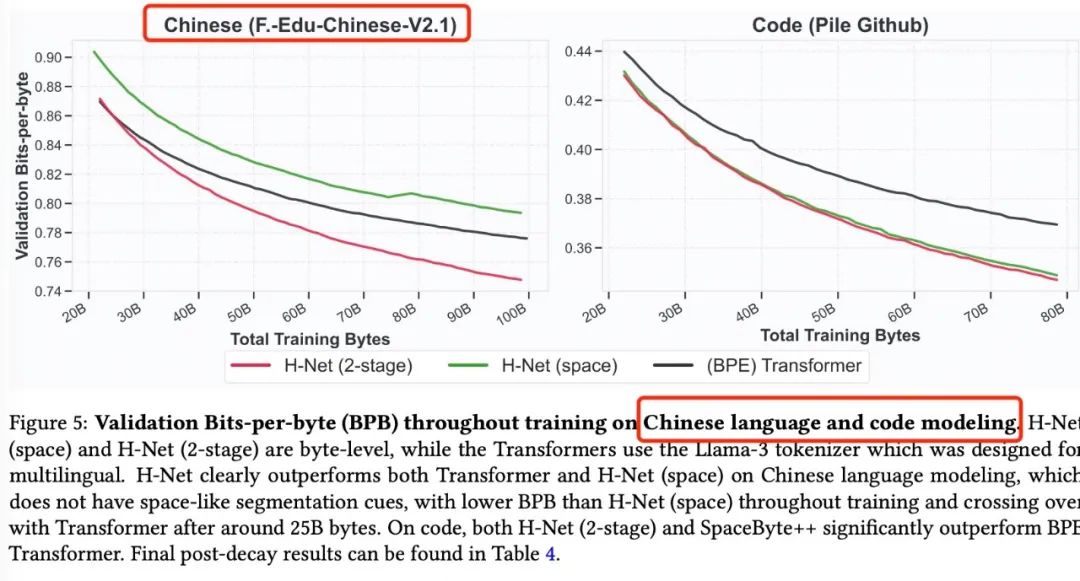
在XWinograd-zh评测中传统分词方法59.9分 vs H-Net 66.3分:

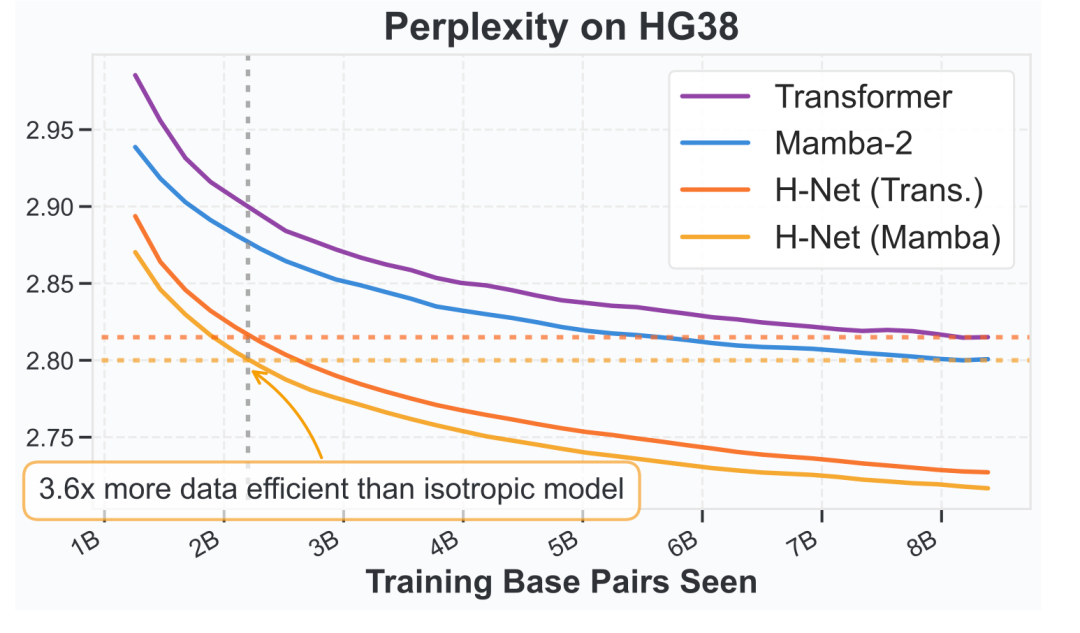
DNA序列数据上效率比H-Net低3.6倍:
3. 鲁棒性缺陷
- 对字符级扰动敏感(如大小写变化、空格删除)。
下图为H-Net(第一阶段)动态绘制的边界位置可视化。给定的文本经过扰动处理,部分空白字符被删除。即使单词边界未被明确空格分隔,H-Net仍能准确检测到词边界,而BPE传统分词方法必须依赖明确边界字符进行有效分词。
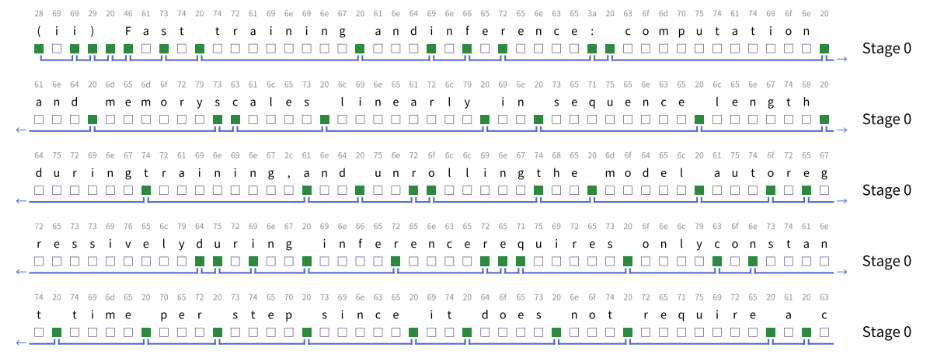
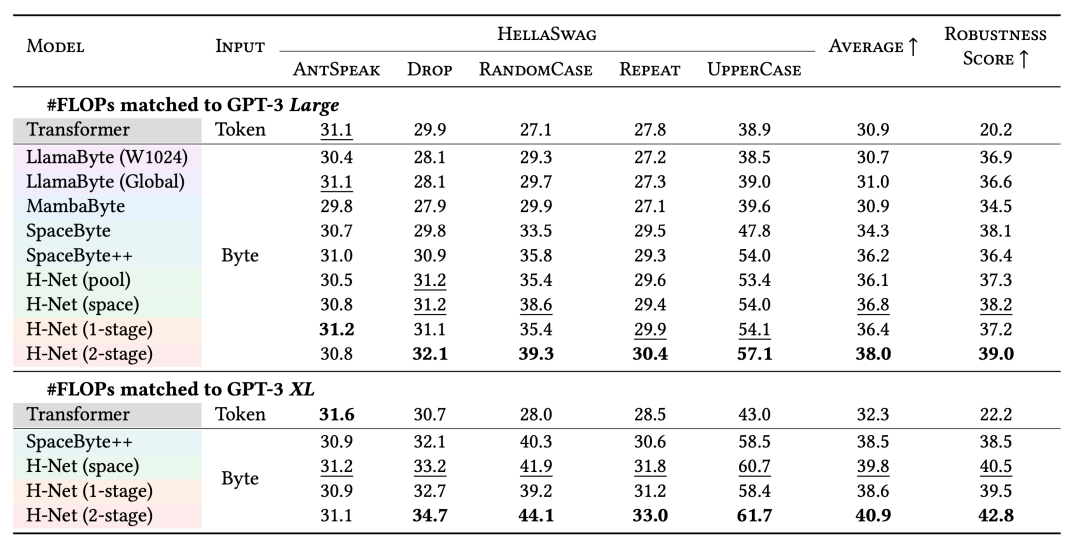
- 在HellaSwag噪声测试中,传统分词模型准确率比字节级模型低15-20%
无分词器模型结构H-Net突破传统大模型架构
动态分块机制(Dynamic Chunking, DC)
DC是H-Net的核心组件,通过可学习的路由模块(Routing Module)和平滑模块(Smoothing Module)实现数据依赖的分块策略。路由模块基于相邻向量的余弦相似度预测边界概率,而平滑模块通过指数移动平均(EMA)将离散分块操作转化为可微分计算,解决了梯度传播难题。两者结合使模型能动态压缩输入序列,同时保留语义关键位置。
H-Net通过动态分块机制实现了语义边界的智能自适应,其核心优势体现在:
-
上下文感知的动态分块
- 采用路由模块实时计算边界概率,根据相邻向量的相似度动态划分语义单元。
- 语义单元长度随内容复杂度灵活变化,避免固定切分。
-
无词汇表约束的架构设计
- 完全摒弃预定义词表限制,支持任意长度的语义组合。
- 通过端到端训练自动学习最优分块策略。
-
语义完整性保护
- 避免传统方法强制拆分语义单元的问题。
- 保持词语、短语等语言结构的自然完整性。
DC完全取代了传统BPE分词器等预处理步骤,使模型能够直接从原始数据(如字节)中学习最优的分块策略。这不仅避免了分词器带来的词汇表偏差和语言限制,还能适应多种模态(如中文、代码、DNA序列)。
分层递归架构(Hierarchical H-Net)
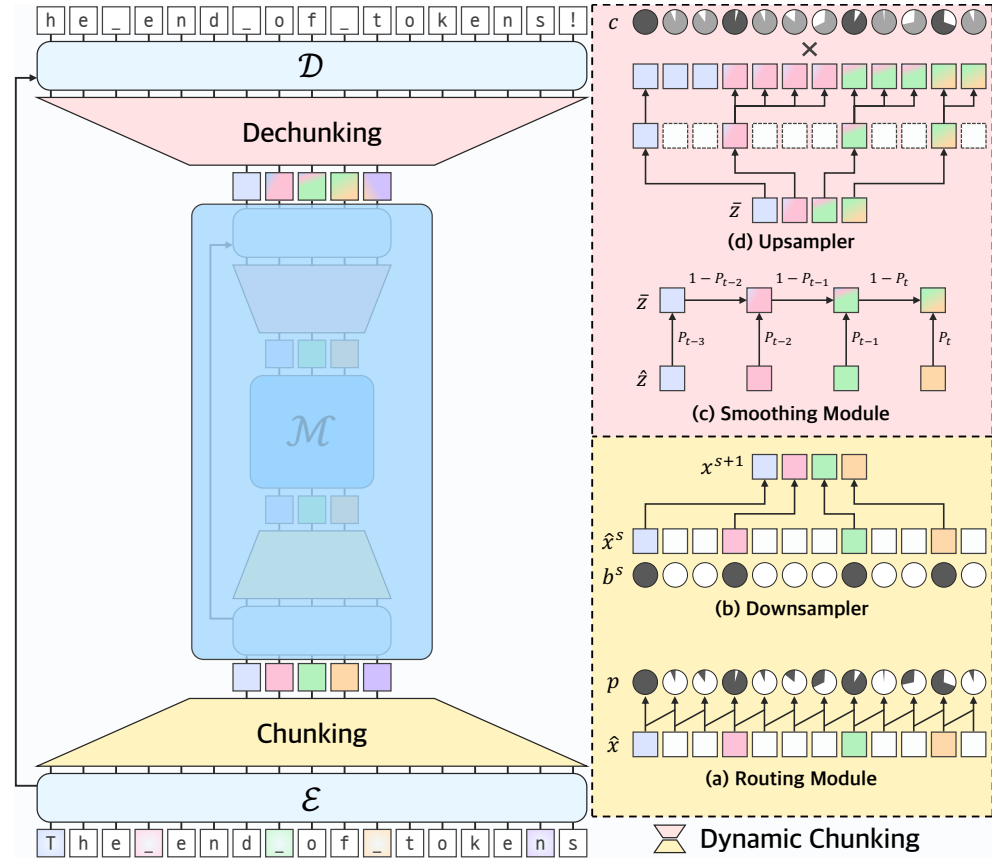
H-Net采用类似U-Net的分层设计,包含编码器(E)、主网络(M)和解码器(D)。其独特之处在于主网络可递归嵌套为另一H-Net,形成多级抽象层次。例如,2阶段H-Net先压缩字节为“词级”块,再进一步压缩为“句级”块,显著提升计算效率和语义建模能力。
信号传播优化技术
论文提出多项稳定训练的改进:
- Norm Balance:
在网络末端添加RMSNorm,平衡残差连接与主路径的梯度贡献。 - 双流分离:
编码器输出分别用于残差连接和主网络输入,通过独立投影保留梯度完整性。 - 比率损失(Ratio Loss):
类似MoE的负载均衡机制,通过调节边界概率均值(G)与实际压缩率(F)的差异,控制目标压缩比(如N=6)。
动态分块机制通过可学习的分块策略、多级抽象和自适应计算分配,不仅解决了传统分词的局限性,还显著提升了模型的效率、性能和泛化能力。
从社区到产业:OpenCSG打造AI模型新基础设施
在这场无分词架构技术革命的背后,国产开源生态的推动力不可忽视。以 OpenCSG 社区为代表的国产 AI 社区,正成为大模型时代关键的基础设施提供者与技术创新策源地。
OpenCSG
(https://opencsg.com)是一个全球领先的开源大模型生态社区,致力于构建开放、协同、可持续的 AI 开发者生态系统。其背后的核心平台 CSGHub提供强大的大模型资产管理能力,为模型训练和部署提供从模型、数据集、代码到 AI 应用的一站式托管、协作与共享服务。
截至目前,OpenCSG 社区已汇聚超过 10 万个高质量开源 AI 模型,覆盖 NLP、CV、语音、多模态等多个核心方向,为研究机构、企业用户和开发者提供了坚实的数据与算力支持。
在本次 H-Net 训练过程中,研究团队正是依托 OpenCSG 最新发布的 Chinese FineWeb Edu V2.1 数据集完成关键预训练阶段,并借助 CSGHub 实现了高效的数据管理与模型迭代。这一协同体系不仅加速了模型开发流程,也凸显了国产开源平台在大模型训练范式变革中的基础设施价值。
OpenCSG正在推动形成具有中国特色的 开源大模型生态闭环,不仅赋能科研机构与企业创新,也让中国 AI 开发者在全球模型生态中拥有更多自主性与话语权。
大语言模型即将迎来无分词时代
大语言模型正迈入无分词时代,这不仅是技术突破,更是语言处理思维的革新。摆脱分词器束缚,模型可端到端学习,从字节到语义,像人类一样自然理解语言。开发更高效,多语言更普惠,专业适配更灵活。
技术上,模型能统一适应不同语言特性;应用上,省去复杂预处理,显著降低多语言开发门槛;认知上,更贴近人类语言习得方式,为语义理解打下基础。
无分词也将打破语言资源不均,小语种和专业领域无需专门分词器,AI能直接从原始文本中学习术语和表达,推动知识平权。
未来,无分词或成大模型新范式,如同CNN之于视觉,让AI更贴近人类语言理解,朝通用人工智能迈进一步。
参考
FineWeb-Edu Chinese V2.1获取途径
- HuggingFace社区开源:
https://huggingface.co/datasets/opencsg/chinese-fineweb-edu-v2 - OpenCSG社区开源:
https://opencsg.com/datasets/OpenCSG/chinese-fineweb-edu-v2
H-Net论文链接
Github链接:https://goombalab.github.io/blog/2025/hnet-past/
arxiv链接:https://arxiv.org/abs/2507.07955v1