MySQL索引及其底层原理(上)(10)
文章目录
- 前言
- 一、索引初步认识
- 二、再识磁盘
- 三、MySQL与磁盘交互基本单位
- 四、索引的理解
- 单个Page
- 多个Page
- 单个Page目录
- 多个Page目录
- 总结
前言
注意了,这篇很重要!!
在开始学习之前,我希望你先回顾下以下几篇文章:
MySQL表的约束(5)
DS B/B+/B*树及其应用(21)
Linux基础文件IO(下)(18)
Linux深入理解文件系统(19)
一、索引初步认识
- 索引是提高数据库性能的关键工具。
- 它通过改变数据的组织方式,显著提升查询速度,而无需增加硬件资源或修改应用程序代码。
- 然而,索引的使用也并非没有代价。查询速度的提升是以插入、更新和删除操作的性能下降为代价的,因为这些写操作会增加大量的I/O操作。
- 因此,索引的价值在于提高海量数据的检索速度。
MySQL的CURD操作与内存
- 所有 MySQL 的 CURD 操作都在内存中进行。MySQL 在启动时会预先开辟一大块内存空间,用于缓存数据。
- 这些数据会在适当的时候被刷新到磁盘中进行持久化。
- 因此,MySQL服务器本质上是在内存中运行的,所有的数据库操作都在内存中进行。索引同样也是在内存中的一种特定结构。
- 索引是提高效率的,一般我们知道提高算法效率的因素:1. 组织数据的方式 ,2. 算法本身。
- 索引是更改特定组织数据的方式,把以前数据的组织方式以新的数据结构组织起来。所以索引是内存中一种特定组织的一种数据结构,具体是什么结构后面再说,
索引的类型
常见的索引类型包括:
- 主键索引(Primary Key)
- 唯一索引(Unique)
- 普通索引(Index)
- 全文索引(Fulltext)——主要用于解决中文索引问题
有无索引的比对
我们先创建一个包含800万条记录的表,并观察没有索引时的查询性能。
-- 产生随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begindeclare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';declare return_str varchar(255) default '';declare i int default 0;while i < n doset return_str = concat(return_str, substring(chars_str, floor(1 + rand() * 52), 1));set i = i + 1;end while;return return_str;
end $$
delimiter ;-- 产生随机数字
delimiter $$
create function rand_num()
returns int(5)
begindeclare i int default 0;set i = floor(10 + rand() * 500);return i;
end $$
delimiter ;-- 创建存储过程,向雇员表添加海量数据
delimiter $$
create procedure insert_emp(in start int(10), in max_num int(10))
begindeclare i int default 0;set autocommit = 0;repeatset i = i + 1;insert into EMP (empno, ename, job, mgr, hiredate, sal, comm, deptno)values (start + i, rand_string(6), 'SALESMAN', 0001, curdate(), 2000, 400, rand_num());until i = max_numend repeat;commit;
end $$
delimiter ;-- 执行存储过程,添加8000000条记录
call insert_emp(100001, 8000000);
注意:创建表单前要注意,恢复默认结束符:使用 delimiter ; 将结束符恢复为默认的分号 ;
查询性能测试
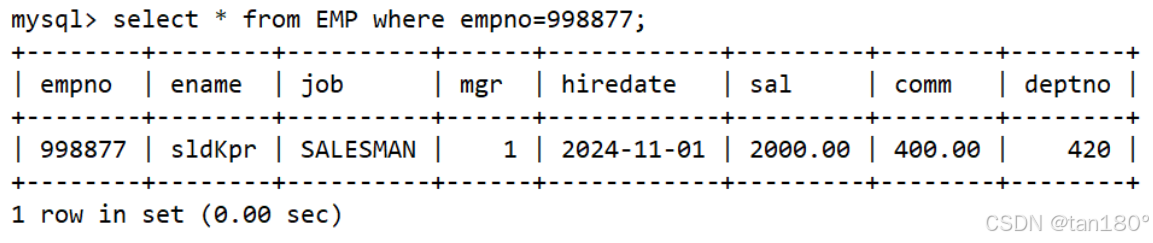
查询员工编号为998877的员工
select * from EMP where empno = 998877;
没有索引时,查询非常慢,在实际项目中,如果放在公网中,同时有1000人并发查询,可能会导致系统崩溃。
但是我们现在一旦加上了索引,查询速度就非常快了
alter table EMP add index(empno);
二、再识磁盘
硬件理解
MySQL 给用户提供存储服务,而存储的都是数据,数据在磁盘这个外设当中。
磁盘是计算机中的一个机械设备,相比于计算机其他电子元件,磁盘效率是比较低的,在加上IO本身的特征,可以知道,如何提升效率,是 MySQL 的一个重要话题。
我们再来看这个盘片的图
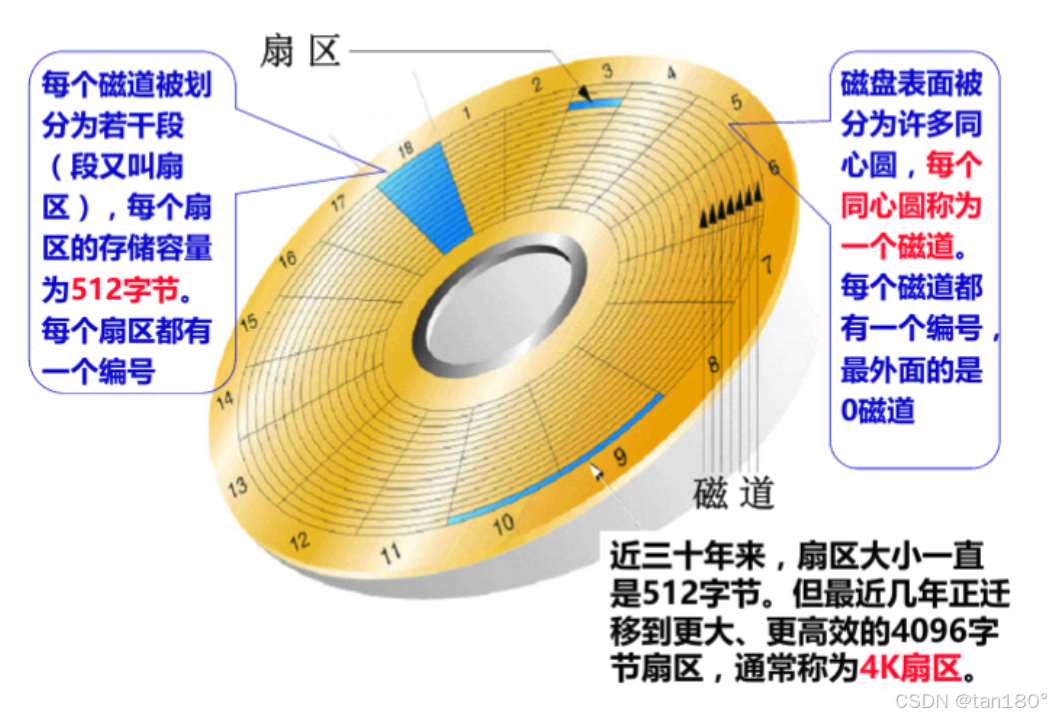
数据库文件,本质其实就是保存在磁盘的盘片当中。也就是上面的一个个小格中,就是我们经常所说的扇区。当然,数据库文件很大,也很多,一定需要占据多个扇区。
其实,我们在使用 Linux ,所看到的大部分目录或者文件,其实就是保存在硬盘当中的。(当然,有一些内存文件系统,如: proc , sys 之类,我们不考虑)
建立数据库其实就是在 linux 下建立一个目录,建立一张表其实就是在 linux 建立一个文件,所以,最基本的,找到一个文件的全部,本质,就是在磁盘找到所有保存文件的扇区。
通过 CHS、LBA(前文已说明),我们现在已经能够在硬件层面定位,任何一个基本数据块了(扇区)。那么在系统软件上,就直接按照扇区进行IO交互吗?
答案是不是
- 如果操作系统直接使用硬件提供的数据大小进行交互,那么系统的 IO 代码,就和硬件强相关,换言之,如果硬件发生变化,系统必须跟着变化
- 从目前来看,单次IO 512字节,还是太小了。IO单位小,意味着读取同样的数据内容,需要进行多次磁盘访问,会带来效率的降低
- 之前学习文件系统,就是在磁盘的基本结构下建立的,文件系统读取基本单位,就不是扇区,而是数据块
故系统读取磁盘,是以块为单位的,基本单位是 4KB 。
三、MySQL与磁盘交互基本单位
软件理解
MySQL是一个应用层软件,依赖操作系统进行 I/O 操作。操作系统和磁盘之间的 I/O 单位是 4KB ,而MySQL为了提高效率,以 16KB 为单位先和 OS 进行 I/O 操作。

MySQL在内存中申请了一个大内存空间(Buffer Pool),用于缓存数据。默认大小为128MB。 Buffer Pool 用于减少磁盘 I/O 次数,提高查询性能。
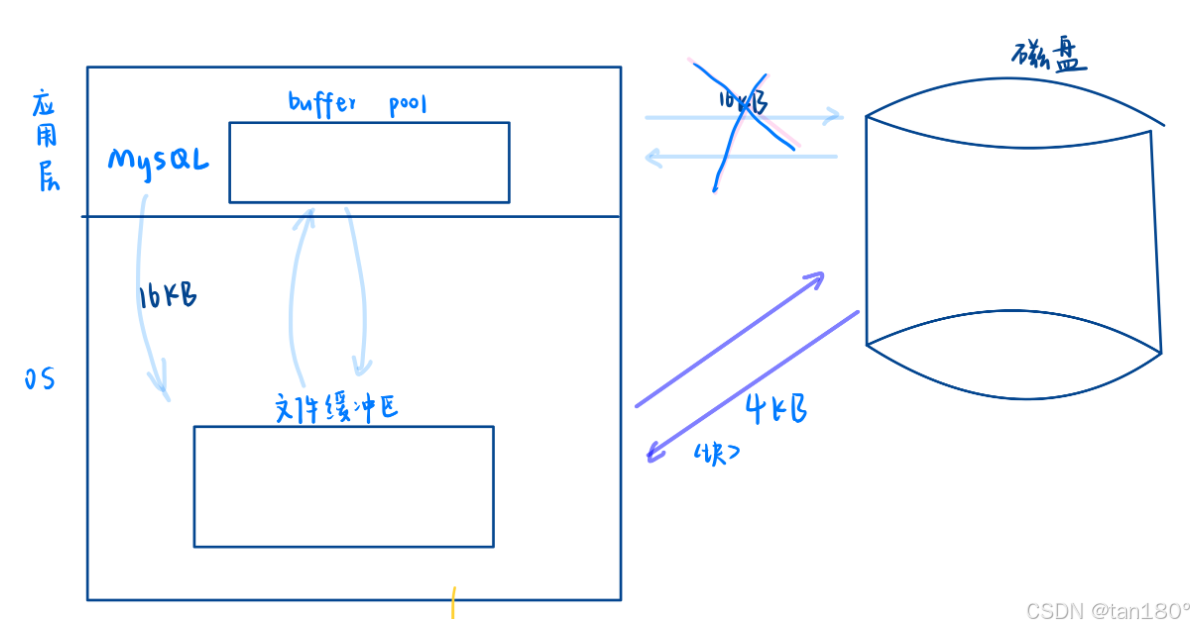
I/O流程
- MySQL向操作系统请求 16KB 数据。
- 操作系统从磁盘读取 4 个 4KB 的数据块,加载到文件缓存区。
- 数据从文件缓存区加载到MySQL的Buffer Pool。
- MySQL在Buffer Pool中对数据进行处理。
- 更新数据时,MySQL将数据写入Buffer Pool,然后通过操作系统刷新到磁盘。

- 16 * 1024 = 16384
- 磁盘这个硬件设备的基本单位是 512 字节,而 MySQL InnoDB 引擎 使用 16KB 进行IO交互。
- 即, MySQL 和磁盘进行数据交互的基本单位是 16KB 。
- 这个 16KB 的基本数据单元,在 MySQL 这里叫做 page(注意和系统的page区分),它们是 1 : 4 的关系
所以说,有三点是我们要牢记于心的
- MySQL以 16KB page为单位进行I/O。
- MySQL有 Buffer Pool ,数据先加载到 Buffer Pool ,再进行处理。
- 减少系统和磁盘 I/O 次数,一次 I/O 的数据量越大,效率越高。
四、索引的理解
建立测试表
create table if not exists user (id int primary key,age int not null,name varchar(16) not null
) engine=InnoDB;
插入多条记录
insert into user (id, age, name) values (3, 25, 'Alice');
insert into user (id, age, name) values (1, 20, 'Bob');
insert into user (id, age, name) values (2, 22, 'Charlie');
查看插入结果

发现数据是有序的,这是因为 MySQL 会默认按照主键进行排序。
这很有意思,明明我们是乱序插入,怎么查询就变得有序起来了?是谁做得,怎么做的?
在这里我们再来重谈 Page
-
磁盘上的文件数据:首先会被读到操作系统的文件缓存区中。
-
MySQL的 Buffer Pool :MySQL在启动时会为自己申请一个 Buffer Pool ,用于缓存数据。MySQL与操作系统之间进行 I/O 交互的基本单位是 16KB ,这是为了提高效率,减少 I/O 成本。
-
Page:MySQL的基本数据单位,大小为 16KB 。
-
Buffer Pool:可以加载多个 Page ,使用双向链表连接。
-
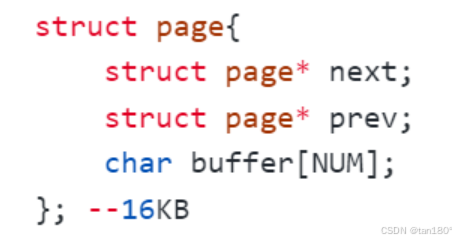
先描述,再组织:不要简单地将Page认为是一个内存块,Page内部也必须写入对应的管理信息。
-
链表管理:所谓在 MySQL 中申请一个 Page ,实际上是 new 一个 Page对象 。然后将所有 Page 用 “链表” 的形式管理起来。我们在 Buffer Pool 内部对 MySQL 中的 Page 进行了建模。
为什么 I/O 交互要用Page?
问题: MySQL和磁盘进行 I/O 交互时,采用 Page 方案的原因是为了提高效率。如果每次只加载需要的数据,例如查找 id=2 的记录,第一次加载 id=1 ,第二次加载 id=2 ,一次一条记录,那么就需要 2 次 I/O 。如果要找 id=5 ,那么就需要5次 I/O 。
批量加载:但如果这5条记录(或更多)都被保存在一个 Page 中(16KB,能保存很多记录),那么第一次 I/O 查找 id=2 时,整个 Page 会被加载到 MySQL 的 Buffer Pool 中,完成一次 I/O 。此后如果查找 id=1,3,4,5 等,完全不需要进行 I/O ,而是在内存中进行。因此,在单Page内大大减少了 I/O 的次数。
因为局部性原理,虽然我们不能严格保证用户下次查找的数据一定在同一个Page内,但有很大概率就真的在同一个 Page 内了,而 IO 效率低下的主要矛盾不是单次 I/O 数据量的大小,而是 I/O 的 次数。
乱序插入,有序查询:我们向一个具有主键的表中,乱序插入数据,发现数据会自动排序。
结论:数据最终以Page为单位进行管理,而Page是先描述后组织的。
有时候一想计算机的世界真是奇妙无比,先贤前辈们竟然能想出那么充满智慧的电子,佩服佩服!
单个Page
Page:一个 Page 可以看作是一个大的结构体,里面可以放很多数据,也有它自己的属性。
数据承载:一个 Page 可以承载一部分数据,而一个文件可能很小也可能很大,因此 MySQL 建立的表可能会是一个或多个 Page 构成。
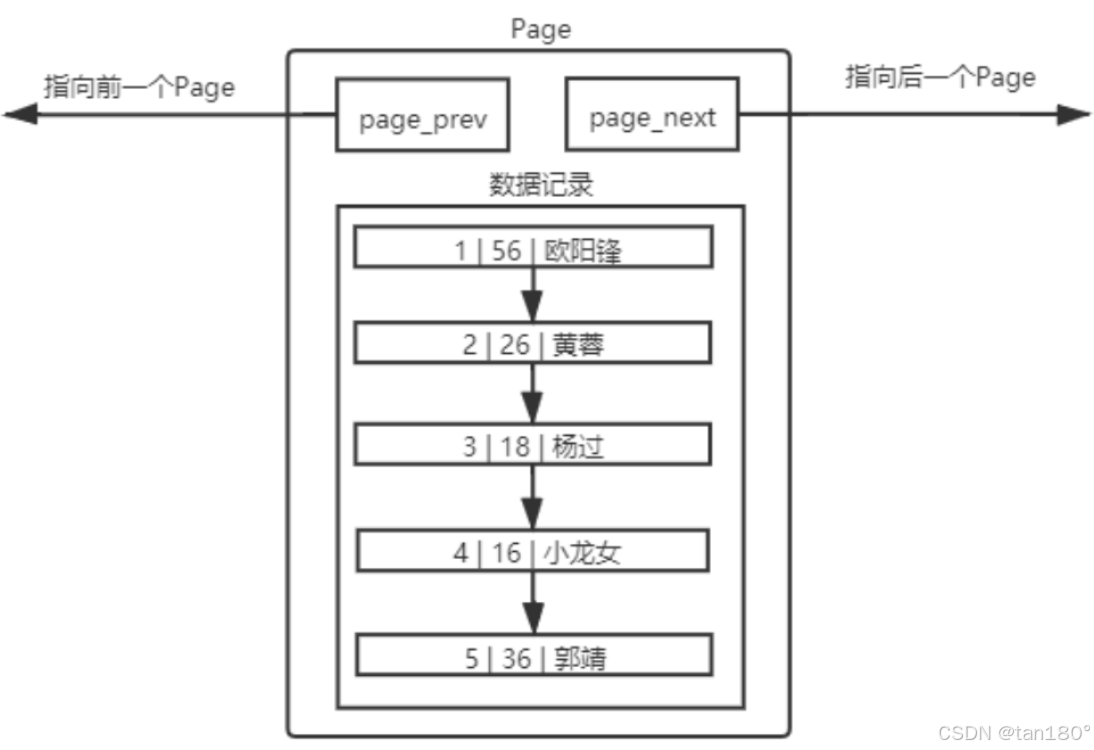
-
大小:在 MySQL 中,每个 Page 的大小都是 16KB 。
-
双向链表:Page 使用 prev 和 next 指针构成双向链表,方便管理和遍历。
-
主键:MySQL 会默认按照主键对数据进行排序。
-
无主键:如果没有主键,默认插入的顺序就是查询时的顺序。
那我们又要思考了,为什么数据库插入的时候要对其进行排序,按正常插入顺序不好吗?
-
目的:插入数据时排序的目的是优化查询的效率。 Page 内部的数据记录实质上是一个链表结构,链表的特点是增删快,查询修改慢。因此,有序的结构在查找时更加高效。
-
优势:有序的数据在查找时从头到尾都是有效查找,没有任何一个查找是浪费的,而且如果运气好,可以提前结束查找过程。
多个Page
单Page的功能:在查询某条数据时,直接将一整页的数据加载到内存中,以减少硬盘 I/O 次数,从而提高性能。
而如果有1千万条数据,需要多个 Page 来保存,多个 Page 彼此使用双链表链接起来,每个Page内部的数据也是基于链表的,这样子说白了在遍历的时候还是线性遍历,较慢
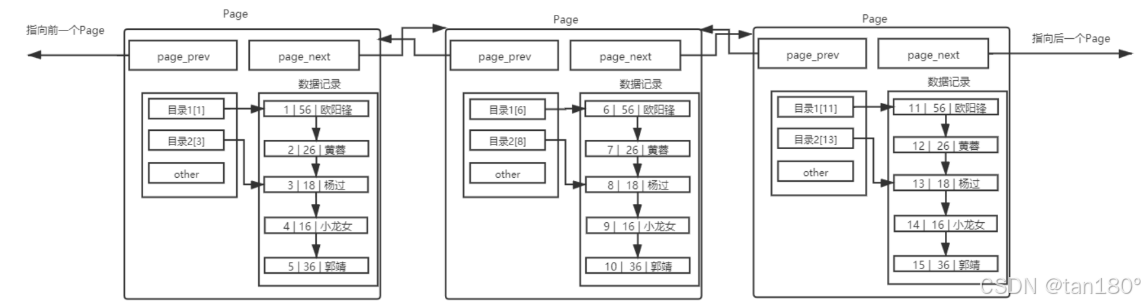
页目录的引入
- 目录的作用:类似于书籍的目录,多花了空间但提高了效率。
- 所以,目录,是一种“空间换时间的做法”
单个Page目录
牺牲 Page 一部分保存数据的空间,把腾出来的空间用来保存目录,这所谓的目录里面只有两个字段
- 第一个是它所指向起始位置的 key 值
- 第二它有一个指针字段指向这条记录的起始位置。
所以未来在查找 key 的时候,不需要在数据记录里面查找了,而是去目录中找
- 先找到目录中对应 key 值的所处的起始位置
- 然后再根据指针找到这条记录
- 然后根据这条记录再向下遍历
- 虽然最后我们依旧需要遍历,但是是一个很小的子序列遍历了,效率也就大大提高了。
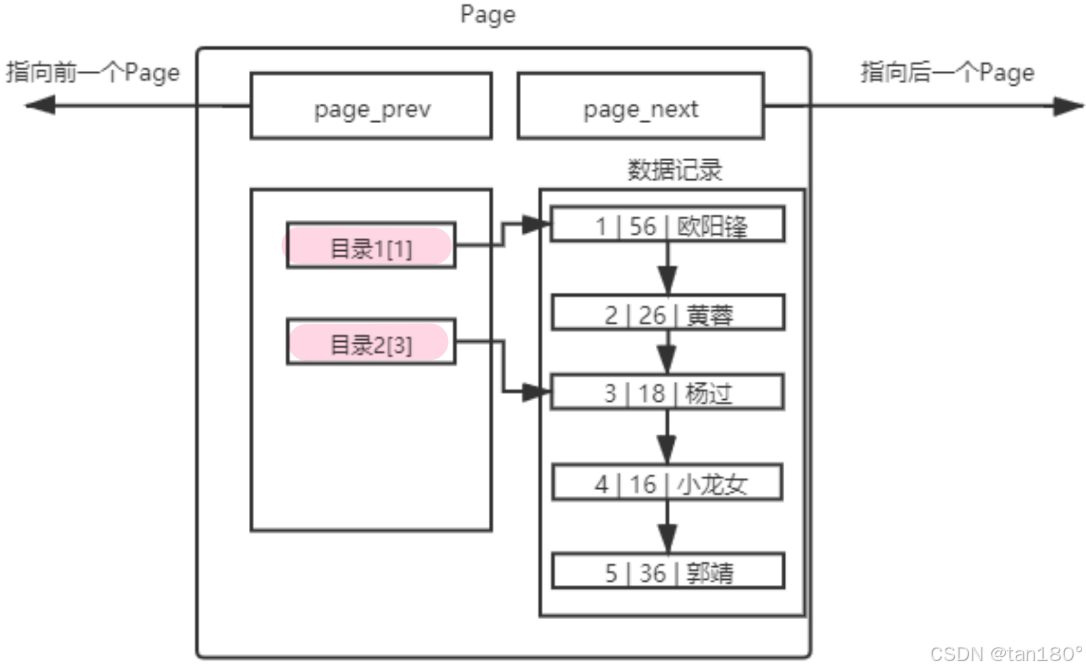
那么当前,在一个Page内部,我们引入了目录。比如,我们要查找 id=4 记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录 2[3] ,直接进行定位新的起始位置,提高了效率,这数据还太小不够明显,如果数据更大就很明白了!
现在我们可以再次正式回答上面的问题了,为何通过键值 MySQL 会自动排序?
答案是可以很方便引入目录。
多个Page目录
Page大小固定: MySQL 中每一页的大小只有 16KB ,单个 Page 大小固定。
数据量增长:随着数据量的不断增大, 16KB 不可能存下所有的数据,因此需要多个 Page 来存储数据
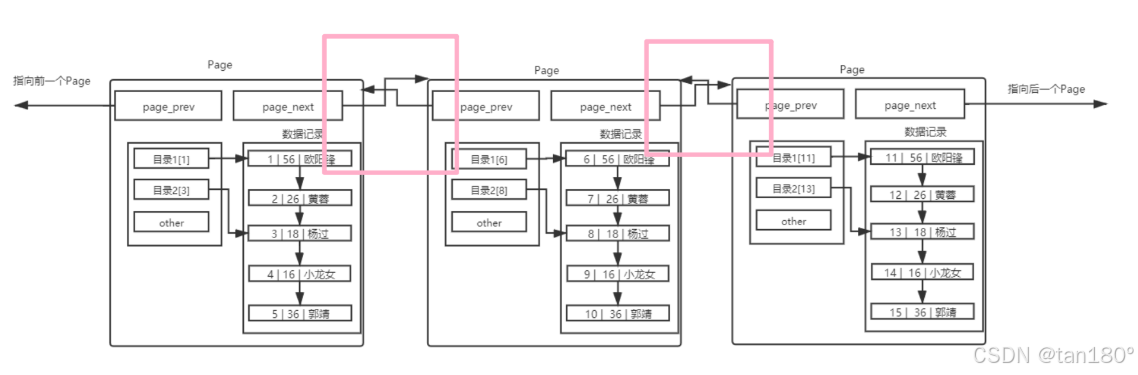
Page 有 动态管理机制 ,在单表数据不断被插入的情况下,MySQL 会在容量不足时,自动开辟新的 Page 来保存新的数据。
组织方式:通过指针的方式,将所有的 Page 组织起来,形成一个链表结构。
但是你会发现,这样又要线性遍历了!于是我们承前面的思想,再加目录!
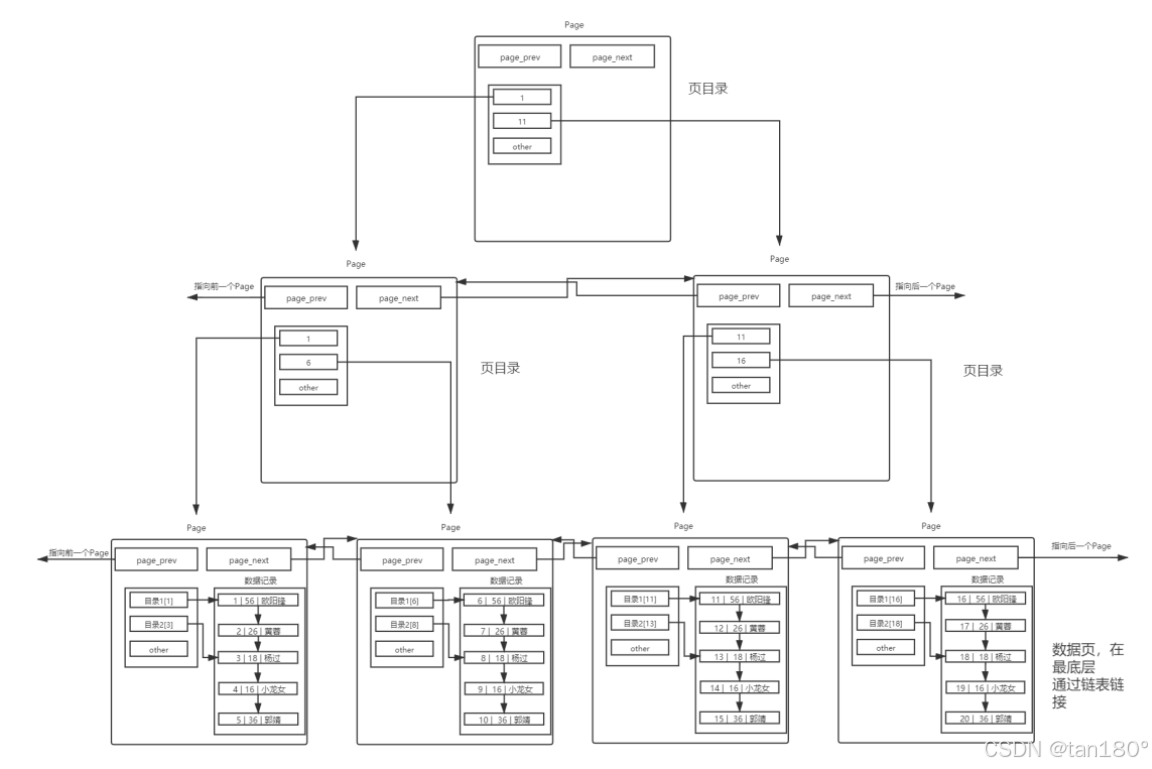
其实这就是传说中的 B+ 树,现在查找的 Page 数一定减少了,也就意味着 I/O 次数减少了,那么效率也就 提高了
总结
有点难,不急,下一篇更难!