Clip微调系列:《coOp: learning to prompt for vision-language models》
论文链接:arxiv.org/pdf/2109.01134v1
推荐视频(clip_coop的代码逻辑讲解,代码简单,有助于理解):CLIP和CoOp工作的简单Pytorch复现和理解_哔哩哔哩_bilibili
其他参考链接:CoOp - CLIP 自适应Prompt工程 【一】_coop clip-CSDN博客
动机
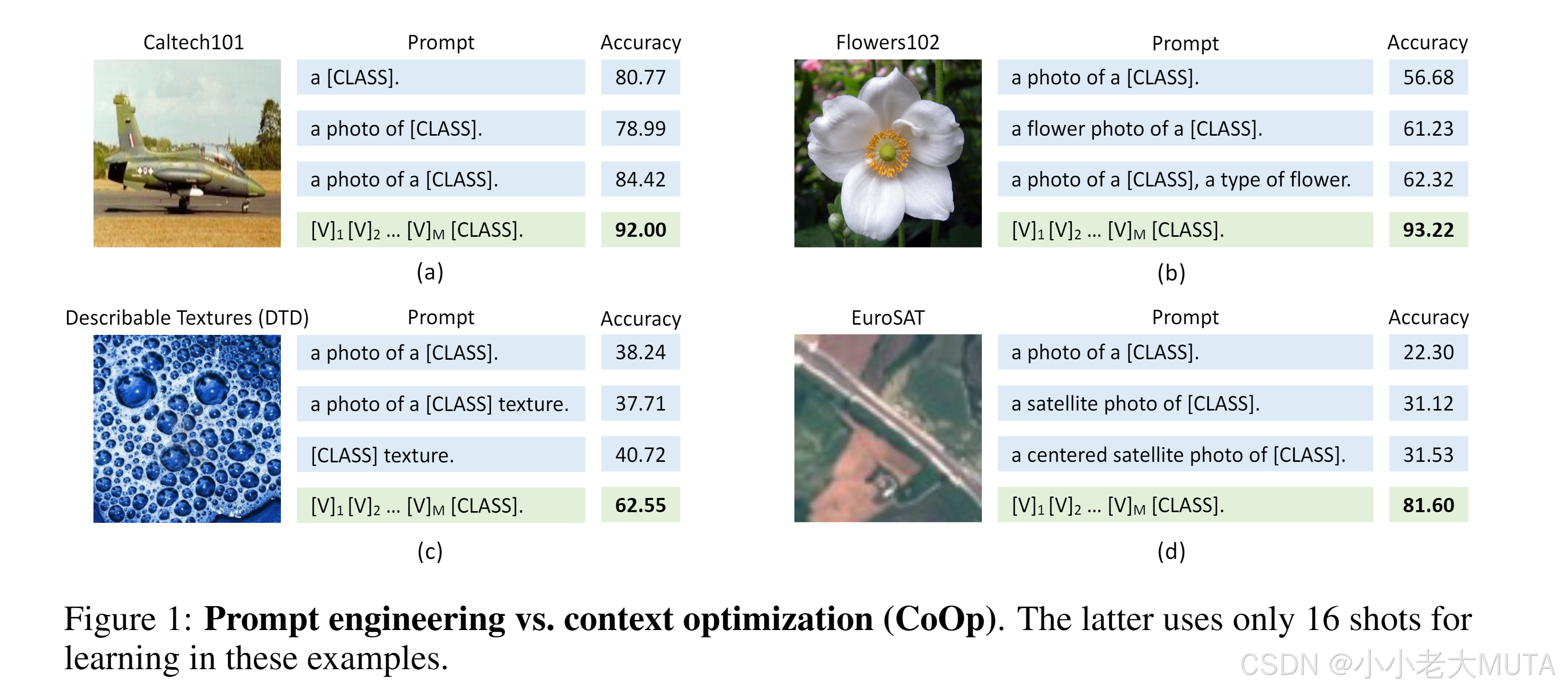
如下图所示,有三种手工设计的prompt提示词:
- a [class]
- a photo of [class]
- a photp of a [class]
用这三种提示词去做zero-shot测试,实验发现尽管这三种提示词在我们人为看来区别不大,但是实际结果却不同------>文本输入(即提示词)对下游数据集性能起关键作用。
因此,作者提出:想让机器自己学习到最合适的prompt提示词来获得更好的结果。
具体方法
如下图所示,原本在CLIP中,文本端的输入就是人为手工设计的prompt + class(A photo if a [class]);
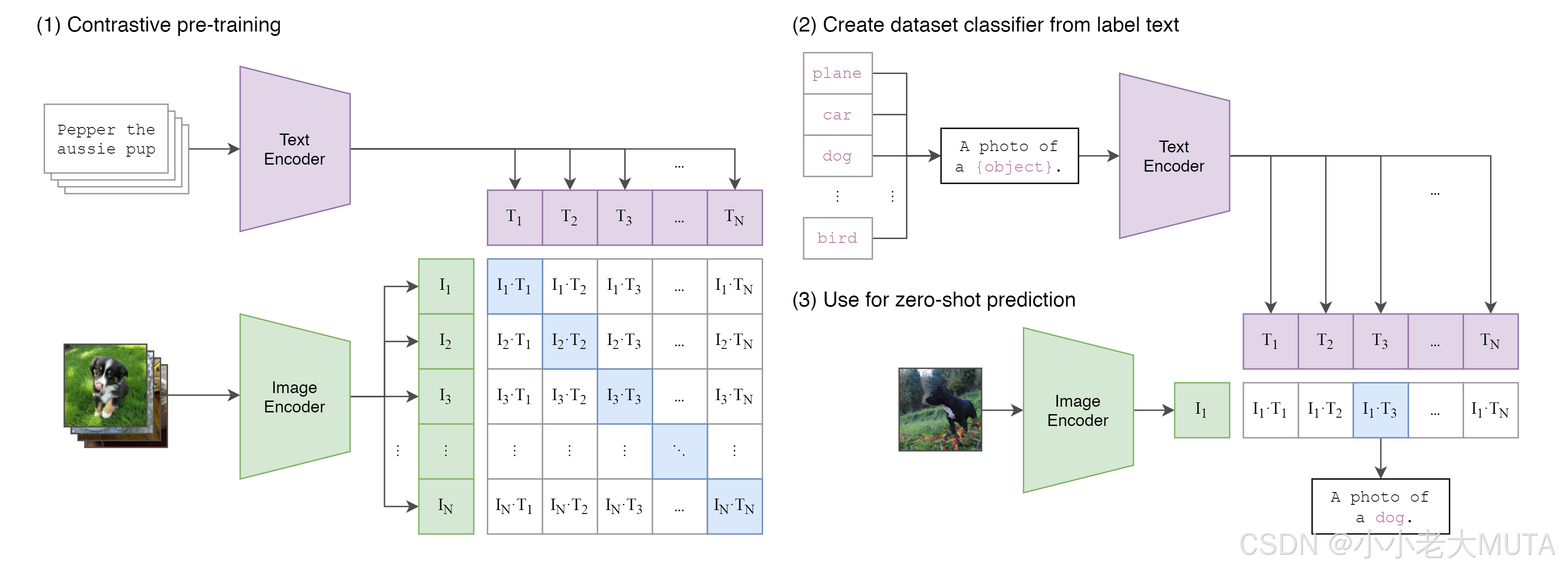
具体而言,就是
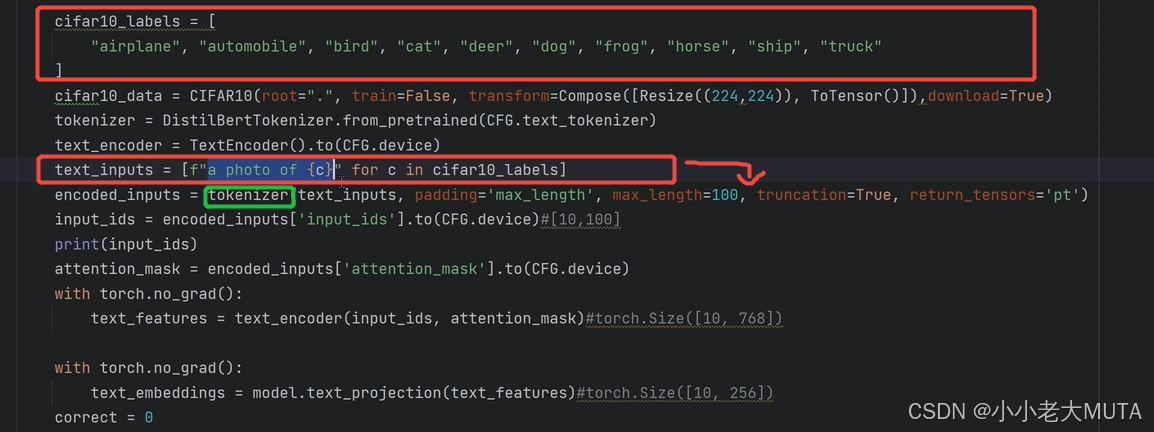
1. 先给定所有的标签labels,然后加上prompt(A photo of) 变成完整的input
2. 再使用tokenizer(bert中先wordpieces)将人能看懂的词语映射成为768维的向量,这里又10个labels,所以是[10,768]维的输入到Text Encoder。
下图是coOp的方法,文本输入端的prompt 变成了 可学习的向量 + class。
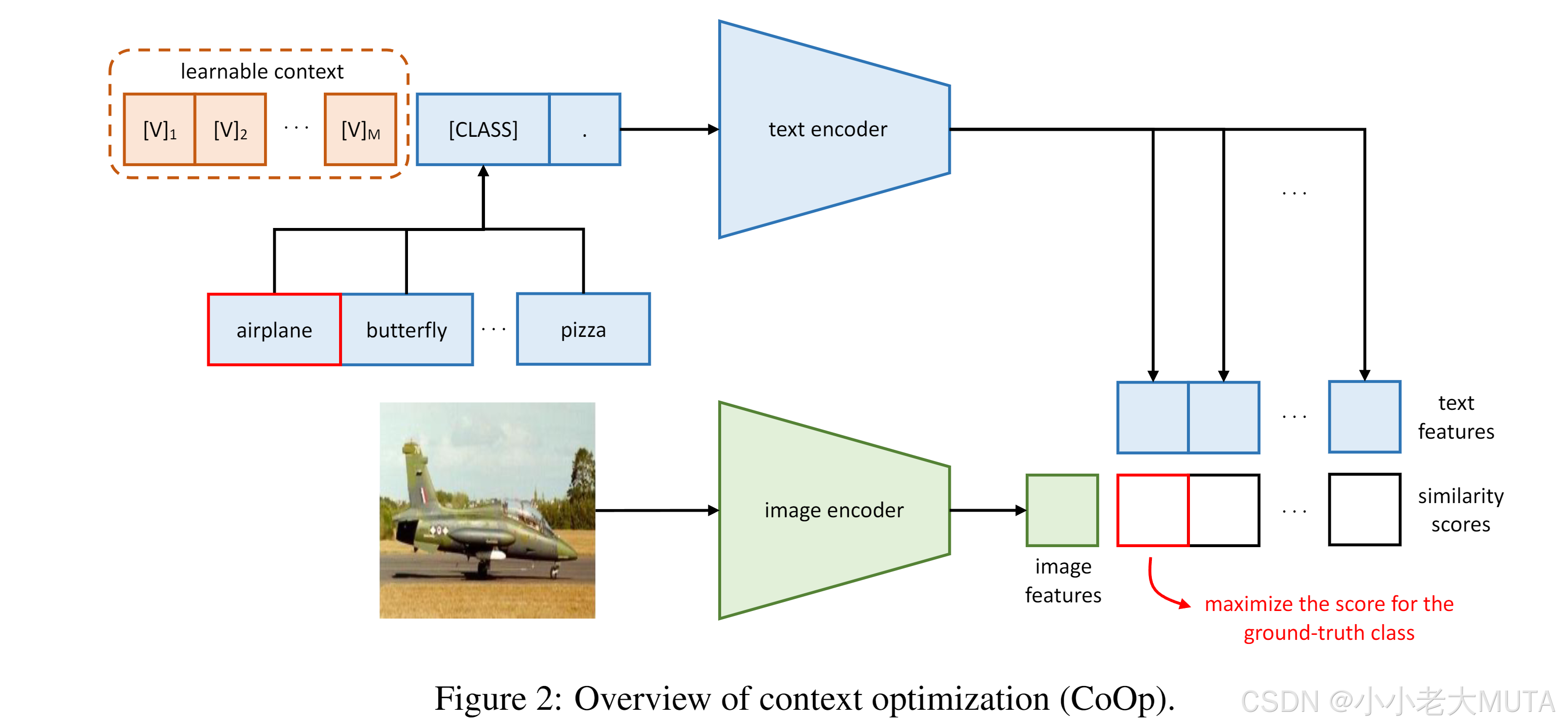
具体而言:
1. 刚开始给的还是 a photo of [class]
2. 将这个a photo of [class] 传给预训练好的模型,加载预训练权重,得到学习好的这个句子对应的向量(10,4,768);
3. clip中原本就直接用这个得到的向量去和图片做交叉熵损失找出相似度最大的类别;
4. coOp得到预训练模型学习好的向量以后,把class类别的向量冻结住;
5. 将得到的4(A photo of [class])的前三个向量当作初始值,然后去学习;
6. 将学习后得到的这三个向量再和[class]拼接回原来的模样,再去 做相似度计算。
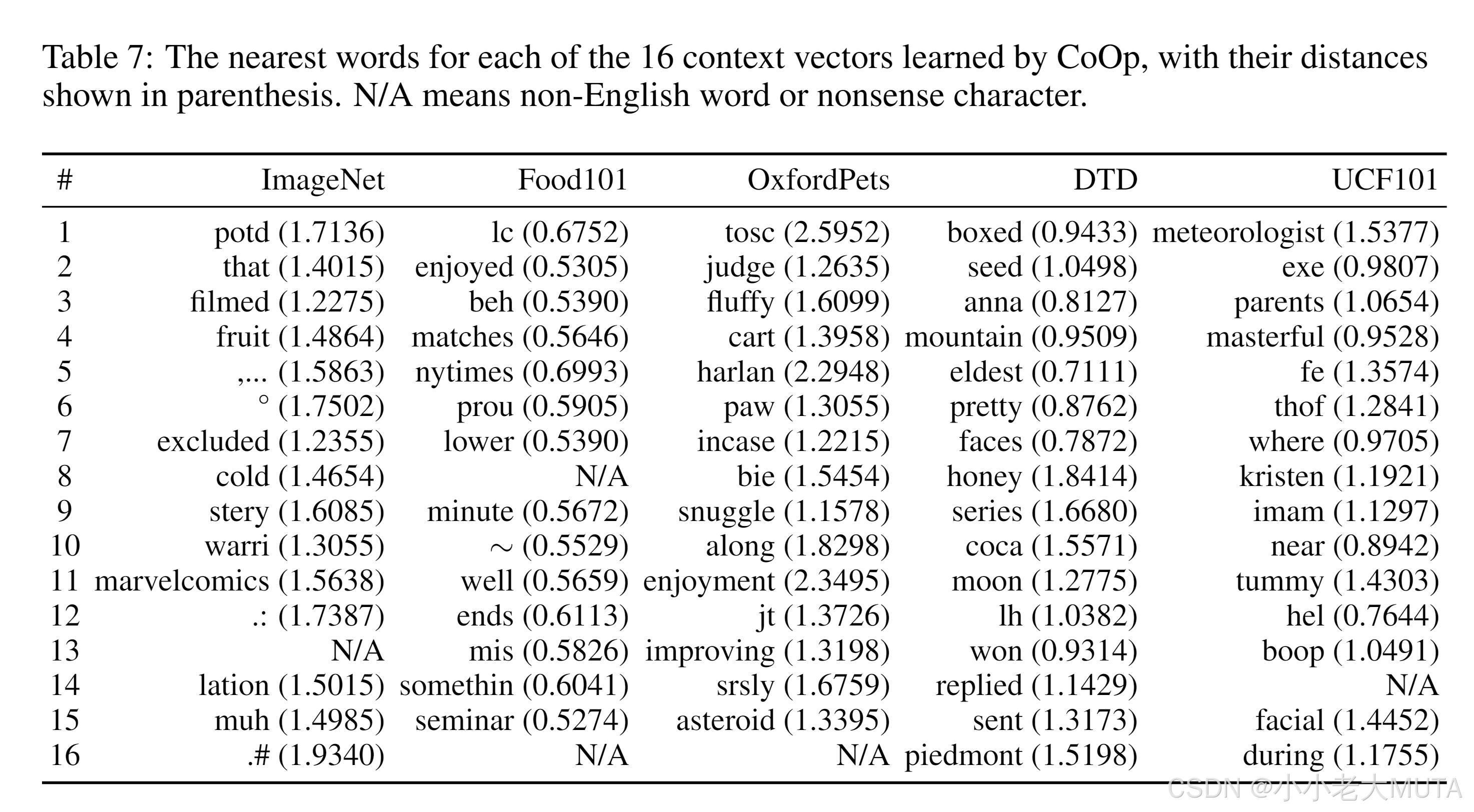
最终得到的前三个向量也就是我们学习得到的prompt,作者将每个词向量与预训练词典进行欧式距离计算。 选择最接近的向量词,作为填充,最终构成一句话,发现其实没有语言逻辑,人是看不懂的。
细节
其实作者考虑了两种可学习prompt:unified context统一可学习 , class-specific context特定类别可学习
我们上面举的例子是 unified context,也就是虽然有十个类别,但是学习到的learnable prompt 都是相同的;
还有一种class-specific context就是不同的类别对应一种learnble prompt。
还考虑了[class]在句子中的不同位置:mid or end.
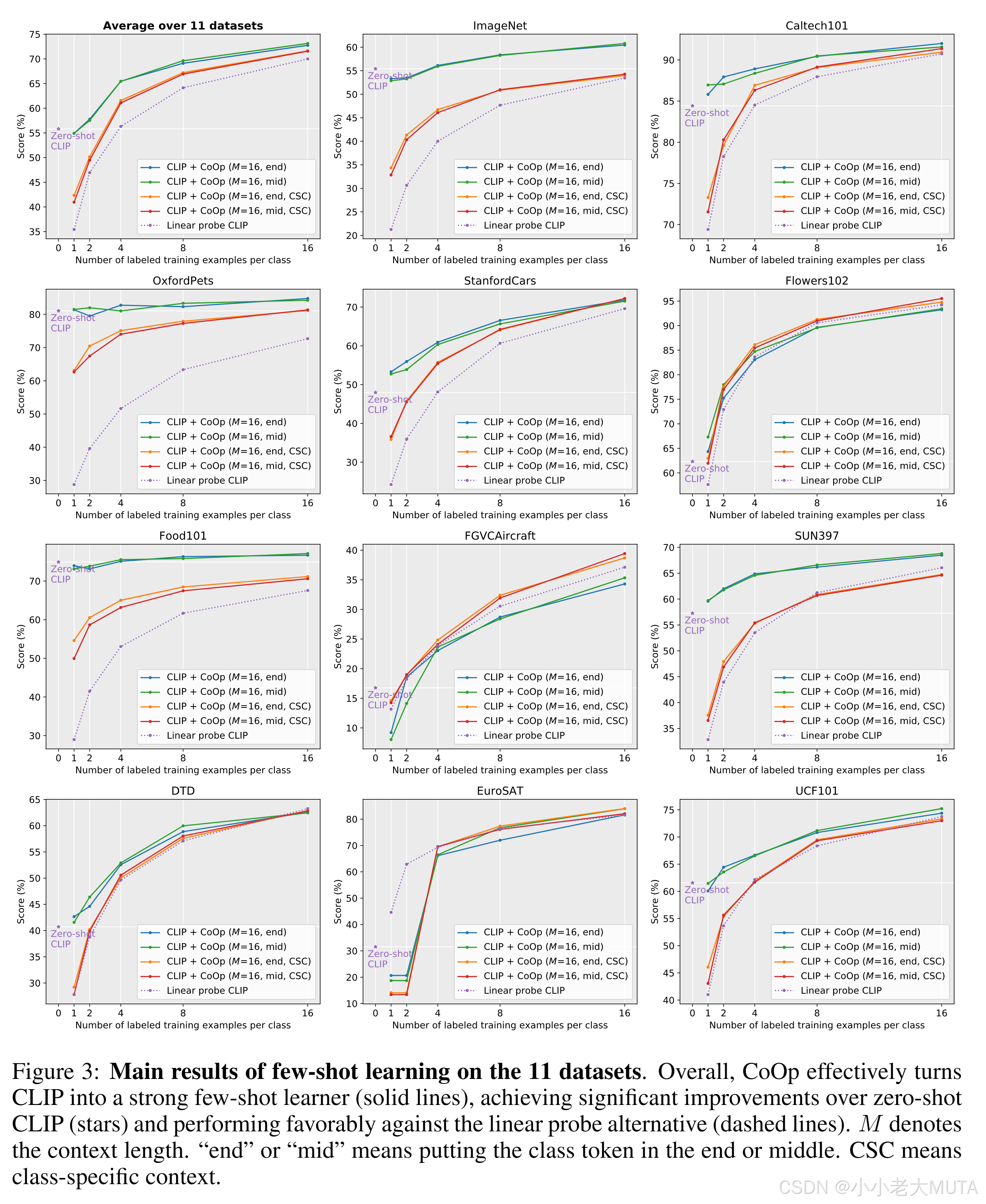
下面是实验结果:
都是少样本训练(0-16个样本量)
- 大部分数据集下, CoOp的效果会明显好于 Linear Probe 形式。且对于 Base model,只有在 8 到 16个 数据集以上的 Few-Shot 才会比 CLIP 的 Zero-Shot 更具优势。
- Prompt词语的 语句序列构成, [CLASS] 在中间 和 在末尾 影响较少,说明 文本Encoder 对于 Prompt词的排序序列 有更强的鲁棒性。
- 统一可学习向量unfiied context 与特定可学习向量class-specific context 相比, 明显发现 unified context 的效果会更好一些。
结果3 是因为:训练的数据参数比 统一可学习向量 多的多,然而在 Few-Shot 数据量明显不够,如果要对class-specific context有更好的效果,就需要更多的参数来去拟合。