数据库询问RAG框架Vanna的总体架构
数据库询问RAG框架Vanna的总体架构
概述
Vanna是一个数据库询问的RAG框架,可以通过自然语言来和数据库对话。
本质上来说Vanna是以RAG框架的模式来设计的。其中有一个训练的过程,而所谓训练的过程其实就是把相关知识,包括:DDL,table信息,相关文档等信息,添加到向量数据库中。
Vanna可以支持多种源数据库和向量数据库,比如:faiss,chromdb,milvus,pgvector等。可以根据自己的情况来进行选择和配置。
Vanna的总体架构如下图所示:
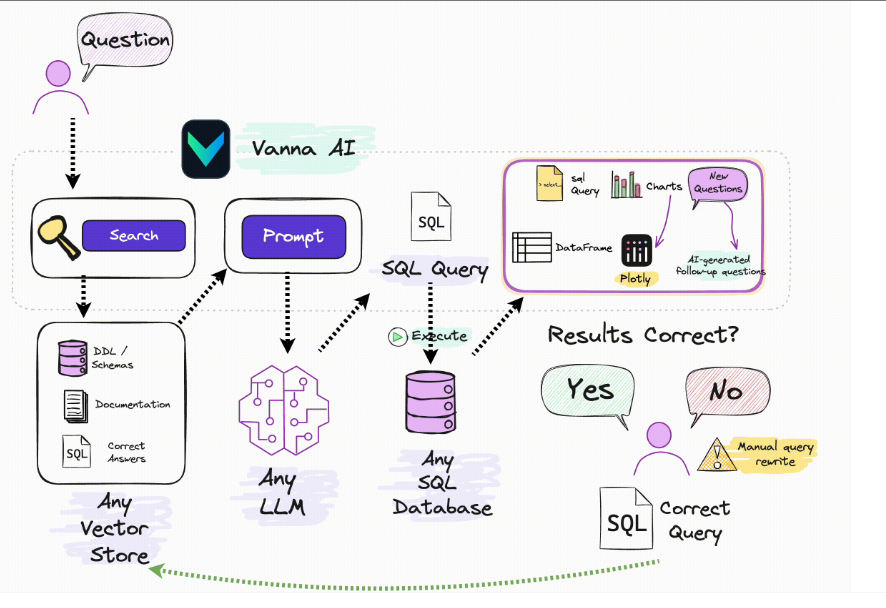
训练过程
在Vanna中,使用的时候有两个过程:
- 训练过程:训练通过调用train()函数来实现训练过程。
- ask过程:实现和数据对话;
训练过程实际上是把相关知识保存到向量数据库中的过程。这里相关的知识,包括:数据表的DDL,数据表的说明文档,数据表的Schema信息等。
把这些知识保存的向量数据库中后,在后续回答用户问题的时候,就可以从向量数据库中查找问题相关的内容。
要注意的是,在处理相关知识时,包括文档和DDL语句等,Vanna并没有对文档内容进行切分,而是把整个文档内容都放入到了向量数据库中。这会导致每次获取到的内容比较冗余,或者导致token的数量会比较多。我个人觉得,这个也是Vanna可以进一步改进的地方。
SQL问答对训练数据
您也可以通过SQL-问答对来训练系统。这是训练系统的最直接方法,并且对系统了解要提出的问题的上下文是最有帮助的。
vn.train(question="What is the average age of our customers?", sql="SELECT AVG(age) FROM customers"
)
SQL-问答对对包含大量嵌入信息,系统可以用来理解问题的上下文。当您的用户倾向于提出具有很多歧义的问题时,尤其如此。
ask过程
询问过程是典型的RAG流程。
(1)先从向量数据库中找到与用户问的问题相关的内容
(2)把与问题相关的内容添加到提示词中
(3)此时提示词就包含了相关内容上下文,然后再把提示词发送给大模型,并获取大模型的返回结果,并对结果内容进行解析。
(4)然后再执行大模型生成的SQL语句,并返回数据
(5)若需要可视化,再对返回的数据进行图表的生成
人工SQL纠正的过程
若是通过页面使用Vanna,则可以人工核验查询结果是否正确,若不正确,可以人工纠正SQL语句,并把正确的SQL语句保存到知识库(向量数据库)中。这个过程其实是一个Human-in-Loop和自我学习的过程,这样可以让AI的结果更加可信,减少由于幻觉而导致的错误结果。
Vanna的特点
- 在复杂数据集上具有高精度。
- Vanna 的能力与你提供的训练数据息息相关
- 更多的训练数据意味着大型复杂数据集的准确性更高
- 安全且私密。
- 数据库内容永远不会发送到 LLM 或向量数据库
- SQL 执行发生在您的本地环境中
- 自我学习
- 如果通过 Jupyter 使用,您可以选择对成功执行的查询进行“自动训练”
- 如果通过其他界面使用,您可以让界面提示用户对结果提供反馈
- 正确的问题和 SQL 对会被保存以供将来参考,使未来的结果更加准确
- 支持任何 SQL 数据库。
- 该包允许您连接到任何可以使用 Python 连接的 SQL 数据库
- 选择您的前端。
- 大多数人都是从 Jupyter Notebook 开始的。
- 通过 Slackbot、Web 应用程序、Streamlit 应用程序或自定义前端向您的最终用户展示。
小结
总的来说Vanna是根据RAG构建了自己的后台架构。通过和向量库的知识库检索相关上下文知识,可以让生成的SQL语句更加准确。Vanna提供了正确知识的反馈机制,这可以说是一种自我学习的过程,这样可以让后续的回答更加准确。另外,在整个过程中加入了人工审核的过程,这在大模型的精准度没有达到一定程度之前,是非常有必要的。Vanna还提供多种使用方式(有前端,或没有前端),这样可以让用户使用起来更加灵活。
另外,在向量生成这一块,还需要进一步优化,才能够让上下文知识更加准确,减少token的小孩,和幻觉的产生。
参考
- https://github.com/vanna-ai/vanna