RNN循环神经网络
一.RNN简介
1.RNN介绍
循环神经网络(Recurrent Neural Network, RNN)是一种专门处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有“循环”结构,能够处理和记住前面时间步的信息,使其特别适用于时间序列数据或有时序依赖的任务。
我们要明确什么是序列数据,时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
2.RNN的应用
3.自然语言处理
自然语言处理(Nature language Processing, NLP)研究的主要是通过计算机算法来理解自然语言。对于自然语言来说,处理的数据主要就是人类的语言,例如:汉语、英语、法语等,该类型的数据不像我们前面接触过的结构化数据、或者图像数据可以很方便的进行数值化。
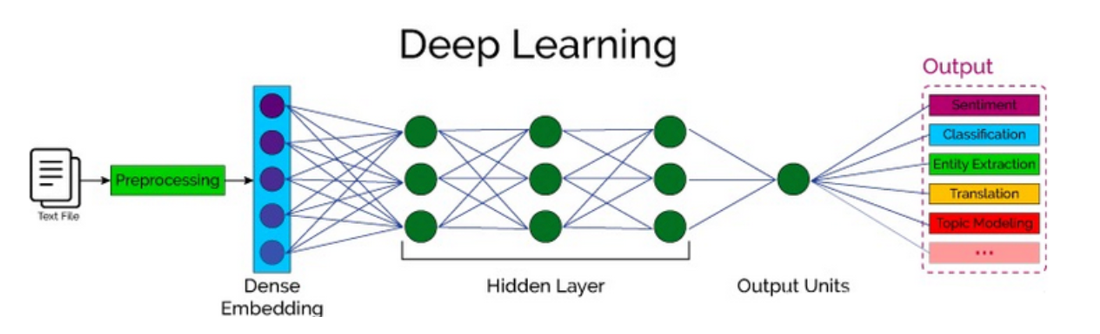
二.词嵌入层
词嵌入层的作用就是将文本转换为向量。
词嵌入层在 RNN 中的作用有输入表示、降低维度和捕捉语义相似性。
词嵌入层首先会根据输入的词的数量构建一个词向量矩阵,例如: 我们有 100 个词,每个词希望转换成 128 维度的向量,那么构建的矩阵形状即为: 100*128,输入的每个词都对应了一个该矩阵中的一个向量。
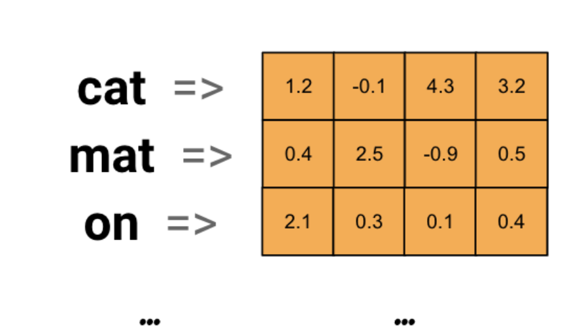
词嵌入流程:

其步骤如下:
三.循环网络层
1.RNN的网络结构
RNN(Recurrent Neural Network)是一种专为处理序列数据设计的神经网络结构,其核心特点是利用循环连接(隐藏层的输出反馈到输入)来捕捉时间或顺序上的动态信息。
例如: "我爱你", 这串文本就是具有序列关系的,"爱" 需要在 "我" 之后,"你" 需要在 "爱" 之后, 如果颠倒了顺序,那么可能就会表达不同的意思。
为了表示出数据的序列关系,需要使用循环神经网络(Recurrent Nearal Networks, RNN) 来对数据进行建模,RNN 是一个作用于处理带有序列特点的样本数据。
一般单层神经网络:

2.RNN模型的作用
RNN的核心作用是建模序列数据的时序依赖关系,适用于需要上下文信息的任务。尽管其基础版本存在局限性,但通过LSTM/GRU等改进和结合注意力机制,RNN家族在序列建模中仍有重要地位。如文本分类, 意图识别, 机器翻译等.
这里举一个例子方便理解:
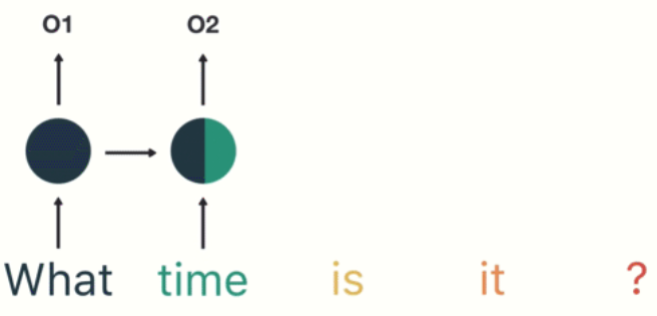
第一步: 用户输入了"What time is it ?", 我们首先需要对它进行基本的分词, 因为RNN是按照顺序工作的, 每次只接收一个单词进行处理.
![]()
第二步: 首先将单词"What"输送给RNN, 它将产生一个输出O1.

第三步: 继续将单词"time"输送给RNN, 但此时RNN不仅仅利用"time"来产生输出O2, 还会使用来自上一层隐层输出O1作为输入信息.
第四步: 重复这样的步骤, 直到处理完所有的单词
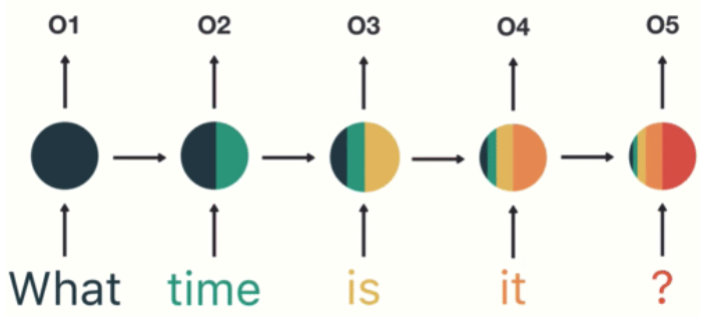
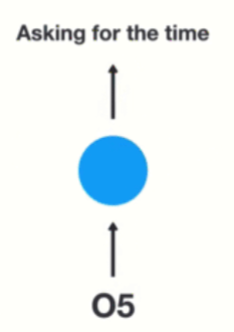
第五步: 最后,将最终的隐层输出O5进行处理来解析用户意图
3.RNN网络原理
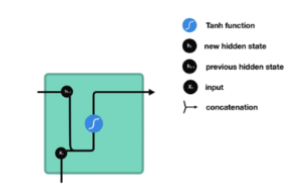
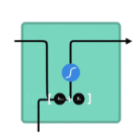
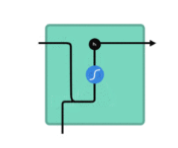
计算当前时刻的输出:网络的输出yt是当前时刻的隐藏状态经过一个线性变换得到的。
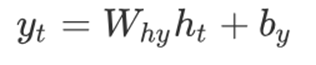
上述公式中:
词汇表映射:
输出yt是一个向量,该向量经过全连接层后输出得到最终预测结果Ypred,Ypred中每个元素代表当前时刻生成词汇表中某个词的得分(或概率,通过激活函数如softmax)。词汇表有多少个词,Ypred就有多少个元素值,最大元素值对应的词就是当前时刻预测生成的词。
4.RNN:API的使用

参数意义是:
将RNN实例化就可以将数据送入进行处理。
输入数据和输出结果
将RNN实例化就可以将数据送入其中进行处理,处理的方式如下所示:

RNN层的代码实现:
import torchx = torch.randn(size=[5,32,128])
print(x)h0 = torch.zeros(size=[1,32,256])
print(h0)rnn = torch.nn.RNN(input_size=128,hidden_size=256,num_layers=1)
print(rnn)y,h1 = rnn(x,h0)
print(h1)
print(y)
接下来介绍一个案例来应用RNN
文本生成任务是一种常见的自然语言处理任务,输入一个开始词能够预测出后面的词序列。本案例将会使用循环神经网络来实现周杰伦歌词生成任务。
整体流程是:
import time
import jieba
import torch.utils.data
import torch# TODO 1.构建词表
def build_vocab():# 分别储存所有杭分此列表和去重后每个分词all_words = []unique_words = []for line in open(r'/data/jaychou_lyrics.txt', mode='r', encoding='utf-8'):words = jieba.lcut(line)all_words.append(words)for word in words:if word not in unique_words:unique_words.append(word)# 去重后单词数量unique_words_cnt = len(unique_words)# 构建小词表: 每个单词对应一个索引unique_words_to_idx = {word: idx for idx, word in enumerate(unique_words)}print(f'词表大小:{unique_words_cnt}')all_words_idx = []for words in all_words:temp = []for word in words:temp.append(unique_words_to_idx[word])temp.append(unique_words_to_idx[' '])all_words_idx.extend(temp)return unique_words, unique_words_cnt, unique_words_to_idx, all_words_idx# TODO 2.构建数据集
class MyDataset(torch.utils.data.Dataset):def __init__(self, all_words_idx, number_chars):self.all_words_idx = all_words_idx# 属性2:每个句子的长度self.number_chars = number_charsself.all_words_idx_cnt = len(self.all_words_idx)self.number = self.all_words_idx_cnt // self.number_charsdef __len__(self):return self.numberdef __getitem__(self, index):start = min(max(0, index), self.all_words_idx_cnt - 1 - self.number_chars)end = start + self.number_charsx = self.all_words_idx[start:end]y = self.all_words_idx[start + 1:end + 1]x = torch.tensor(x)y = torch.tensor(y)return x, y# TODO 3.构建神经网络模型class MyModel(torch.nn.Module):# 重写__init__方法def __init__(self, unique_words_cnt):# 调用父类方法super().__init__()# todo 定义网络结构# 创建一个嵌入层self.embedding = torch.nn.Embedding(num_embeddings=unique_words_cnt, embedding_dim=128)# 创建一个rnn层self.rnn = torch.nn.RNN(input_size=128, hidden_size=256, num_layers=1)# 创建一个全连接层self.out = torch.nn.Linear(in_features=256, out_features=unique_words_cnt)# 重写forward方法def forward(self, x, h):# todo 获取嵌入层输出ebd_x = self.embedding(x)# todo 获取rnn层输出# TODO ebd_x[batch_size, seq_len, input_size]->(seq_len,batch_size, hidden_size)rnn_out, h = self.rnn(ebd_x.transpose(0, 1), h)# todo 全连接层: 只能处理2维张量,此处需要把rnn_out转成2维张量out = self.out(rnn_out.reshape(-1, rnn_out.shape[-1]))# todo 返回结果return out, h# 定义初始化隐藏状态方法def init_hidden(self, batch_size):# 创建初始隐藏状态return torch.zeros(size=[1, batch_size, 256])# TODO 4.模型训练
def train_model(unique_word_to_idx, train_loader, model, epochs, batch_size):# 1.获取数据(本次已经传参)# 2.获取模型(本次已经传参)# 3.创建损失函数对象loss_fn = torch.nn.CrossEntropyLoss()# 4.创建优化器对象optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)# 5.训练模型for epoch in range(epochs):total_loss, sample_cnt, start = 0.0, 0, time.time()for x, y in train_loader:# todo 正(前)向传播:从输入到输出: 预测值和损失值# 先获取隐藏状态h = model.init_hidden(x.size(0))# 然后预测获取预测值和隐藏状态y_pred, h = model(x, h)# 计算损失值loss = loss_fn(y_pred, y.transpose(0, 1).reshape(-1))# 累加损失值和批次数量total_loss += loss.item()sample_cnt += 1# todo 反向传播:从输出到输入: 梯度计算和参数更新optimizer.zero_grad()loss.backward()optimizer.step()# 走到此处,说明一轮结束: 计算每轮损失值epoch_loss = total_loss / sample_cntprint(f"第{epoch + 1}轮,运行时间{time.time() - start:.2f}秒,损失值为:{epoch_loss:.2f}")# 6.保存训练好的模型参数字典torch.save(model.state_dict(), 'model')# TODO 5.模型预测
def eval_model(start_word, length, unique_words_cnt, unique_words, unique_word_to_idx):# 1.获取起始词对应的索引,并封装成列表word_idx = unique_word_to_idx[start_word]words = [word_idx]# 2.创建新模型model = MyModel(unique_words_cnt)model.load_state_dict(torch.load('model'))# 3.模型预测# 提前获取隐藏状态h = model.init_hidden(batch_size=1)for i in range(length):# 模型预测ypred, h = model(torch.tensor([[word_idx]]), h)# 获取预测值索引word_idx = torch.argmax(ypred).item()words.append(word_idx)# print(words)# 4.将索引列表转成词列表words = [unique_words[idx] for idx in words]print(''.join(words))# 程序主入口
if __name__ == '__main__':# TODO 1.构建词表unique_words, unique_words_cnt, unique_word_to_idx, all_words_idx = build_vocab()# TODO 2.构建数据集number_chars = 32dataset = MyDataset(all_words_idx, number_chars)# print(f'数据集大小: {len(dataset)}') # 自动调用__len__方法# print(dataset[0]) # 自动调用了__getitem__方法: (tensor([ 0, 1, 2, 3, 40]), tensor([ 1, 2, 3, 40, 0]))batch_size = 5train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)# TODO 3.构建神经网络模型model = MyModel(unique_words_cnt)print(model)# TODO 4.模型训练epochs = 10# train_model(unique_word_to_idx, train_loader, model, epochs, batch_size)# TODO 5.模型预测# 注意: start_word必须在词表中有,否则报错start_word = '星星'length = 99eval_model(start_word, length, unique_words_cnt, unique_words, unique_word_to_idx)
train后的结果为:
