【跟我学YOLO】(2)YOLO12 环境配置与基本应用
欢迎关注『跟我学 YOLO』系列
【跟我学YOLO】(1)YOLO12:以注意力为中心的物体检测
【跟我学YOLO】(2)YOLO12 环境配置与基本应用
【跟我学YOLO】(3)YOLO12 用于诊断视网膜病变
【跟我学YOLO】(2)YOLO12 环境配置与基本应用
- 1. YOLO12 简介
- 2. YOLO12 项目和模型下载
- 2.1 下载 YOLO12 项目
- 2.2 下载 YOLO12 模型
- 3. 虚拟环境的创建与配置
- 3.1 创建虚拟环境
- 3.2 安装项目依赖
- 4. YOLO12 安装与测试
- 4.1 安装 YOLO12
- 4.2 YOLO12 安装测试
- 4.3 配置 Pycharm 编辑器
- 5. YOLO12 模型推理
- 5.1 CLI 方式运行
- 5.2 Python 程序运行
- 5.3 分割任务和分类任务
- 6. 参数说明
- 7. YOLOv12 的模型架构
- 7.1 YOLOv12 模型架构图
- 7.2 YOLOv12 模型配置文件
- 7.3 YOLOv12 模型架构详解
- 7.4 YOLO12 核心模块 A2C2f 的结构功能
本节介绍 YOLO12 的下载、配置和推理。
1. YOLO12 简介
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,最初于 2015 年推出。
YOLOv12 提出了一种以注意力为中心的网络架构,利用区域注意力降低计算复杂度,并通过**残差高效层聚合网络(R-ELAN)**增强特征聚合能力。通过优化注意力机制的关键组件,以更好地适配YOLO的实时性需求,同时保持高速性能。通过有效结合区域注意力、R-ELAN和架构优化,YOLOv12在准确率和效率上均实现了显著提升,达到了SOTA性能,推动了注意力机制在实时目标检测中的集成。
YOLO12 支持一系列核心计算机视觉任务:物体检测、实例分割、图像分类、姿态估计和定向物体检测 (OBB)。与 YOLO10、YOLO11 相比,YOLO12 效率更高,部署灵活。
2. YOLO12 项目和模型下载
YOLOv12 下载:GitHub - YOLO12
Ultralytics 官方文档: YOLO12 使用指南(中文版)
2.1 下载 YOLO12 项目
YOLO12 开源网址:GitHub - YOLO12
- 方法一:克隆 repo。
>>> git clone https://github.com/sunsmarterjie/yolov12
- 方法二:直接从 GitHub 网页下载压缩文件。
没有安装 git 的同学,可以在 GitHub 网站的 YOLO12 项目页面,点击绿色的 “<>Code”,选择 “Download ZIP”,可以下载 YOLO12 项目的压缩包。
2.2 下载 YOLO12 模型
使用 YOLO12 进行推理,首先要下载 YOLO12 预训练模型。使用 YOLO12 训练自己的模型,也常用 YOLO12 预训练模型作为初始模型。
YOLO12 支持多种计算机视觉任务,提供了检测(Detection)、分类(Classification)、分割(Segmentation)、姿态估计(Pose)、定向边界框检测(OBB)、跟踪(Track)等任务的预训练模型。
YOLO11 有多个不同规模的模型,从小到大依次是:YOLO12n、YOLO12s、YOLO12m、YOLO12l、YOLO12x。这些模型与各种操作模式兼容,包括推理、验证、训练和导出,便于在部署和开发的不同阶段使用。
在 下载 YOLO12 项目 中的 Readme.md 文件中可以找到以下内容(包括模型下载地址): YOLO12n , YOLO12s, YOLO12m, YOLO12l , YOLO12x。
以检测任务为例,如下图所示,点击所需的模型即可下载相应的预训练模型。
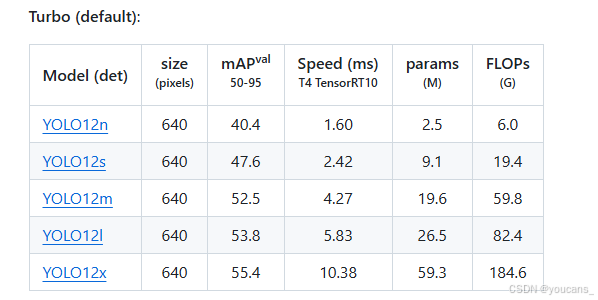
以分类任务为例,如下图所示,点击所需的模型即可下载相应的预训练模型。
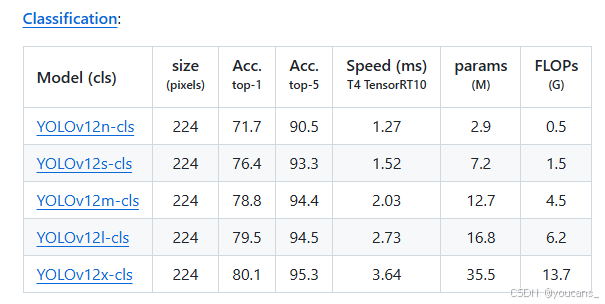
说明:YOLO12在运行时如果在本地没有检测到预训练模型,,将会自动从网络下载并保存,但下载速度可能很慢甚至连接失败(视网络条件和限制),因此推荐先将 YOLO12 预训练模型下载到本地。
本文选择检测任务模型 YOLO12n,参数约 2.5M。下载完成后,将模型文件保存在 YOLO12 项目的根目录路径下,即 “.\YOLO12\yolov12n.pt”。
3. 虚拟环境的创建与配置
说明:本文所有内容都是基于 python 环境实现的,因此先要确保已经安装了 python 开发环境。推荐使用 python3.8 或以上版本,并安装 PyTorch1.8 或以上版本。
3.1 创建虚拟环境
虚拟环境可以将YOLO12 训练所需的依赖包和其他项目的依赖包隔离开来,避免版本冲突,更加便于管理。
推荐使用 miniconda 搭建Python环境,其安装和使用可以参见:【youcans的深度学习 01】安装环境详解之 miniconda。
创建名称为 YOLO12 的 Python 环境,注意推荐Python 版本为3.11。激活 YOLO12 环境。
conda env list
conda create -n YOLO12 python=3.11
conda activate YOLO12
3.2 安装项目依赖
在所选择的 Python 环境下,安装 YOLO12 项目所需的依赖(安装项目所需的库)。
1、项目依赖
项目中的 requirements.txt 文件已经详细列出了所需的库及版本。
考虑国内安装环境问题,对 torch,torchvision 和 flash_attn 先注释掉。
#torch==2.2.2
#torchvision==0.17.2
#flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
timm==1.0.14
albumentations==2.0.4
onnx==1.14.0
onnxruntime==1.15.1
pycocotools==2.0.7
PyYAML==6.0.1
scipy==1.13.0
onnxslim==0.1.31
onnxruntime-gpu==1.18.0
gradio==4.44.1
opencv-python==4.9.0.80
psutil==5.9.8
py-cpuinfo==9.0.0
huggingface-hub==0.23.2
safetensors==0.4.3
numpy==1.26.4
supervision==0.22.0
切换到 YOLO12 项目根目录(本例为“C:\Python\Projects\YOLOv12”),激活 YOLO12 环境,从 requirements.txt 文件批量安装项目的所有依赖包(不包括注释的内容)。
cd C:\Python\Projects\yolov12 # YOLOv12 项目根目录
conda activate YOLO12
pip install -r requirements.txt
注意:
-
由于安装 YOLO12 项目所需的第三方库内容很多,如果下载太慢,可以指定下载源,也可以从已有的虚拟环境中复制 Lib\site-package 中的内容,但要检查版本能否满足本项目中的 requirements.txt 的要求。
-
对于未安装的库或版本不满足要求的库,可以手动安装,例如:
pip install numpy==1.26.4
- requirements.txt 中没有 thop,但运行 YOLO12 时可能需要,因此可以手动安装:
pip install thop
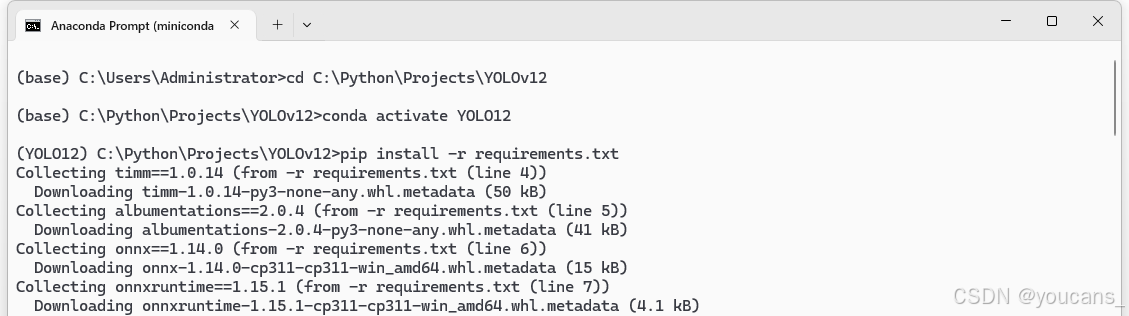
耐心等待安装完成…
2、下载 FlashAttention
项目 requirements.txt 文件列出的 “flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl” 是针对 Linux 系统的,对于 Windows 系统不能下载和使用。
对于 Windows 系统,推荐从 Github 下载 FlashAttention:
FlashAttention Windows:https://github.com/bdashore3/flash-attention/releases
我选择了 v2.7.0.post2 版本:
flash_attn-2.7.0.post2+cu124torch2.3.1cxx11abiFALSE-cp311-cp311-win_amd64.whl
下载完成之后需要本地安装。将下载的 FlashAttention 的 .whl 文件,复制到 yolov12 项目的根目录下,pip 安装如下。
cd C:\Python\Projects\yolov12 # YOLOv12 项目根目录
conda activate YOLO12
pip install flash_attn-2.7.0.post2+cu124torch2.3.1cxx11abiFALSE-cp311-cp311-win_amd64.whl
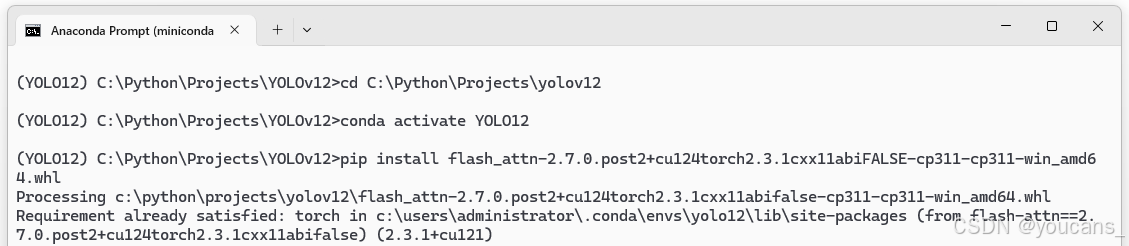

3、安装 CUDA 和 PyTorch
FlashAttention 的 flash_attn-2.7.0.post2+cu124torch2.3.1cxx11abiFALSE-cp311-cp311-win_amd64.whl 文件名的含义为:适配的 CUDA 版本为 12.4,PyTorch 版本为 2.3.1,Python 版本为 3.11,操作系统为 Windows 64bit。
安装指定版本的 CUDA 和 PyTorch 如下。
pip install torch2.3.1 torchvision0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121
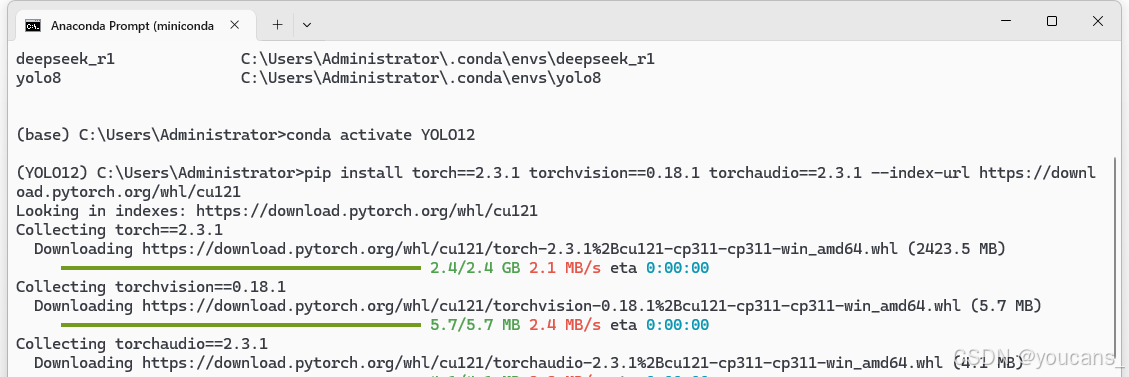
4. YOLO12 安装与测试
4.1 安装 YOLO12
- 在线安装(不推荐)
YOLO12 提供了命令行执行方式,但是需要按照要求来进行安装:
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
这种方式安装方便,但对网络有一定要求,而且不方便对源码的修改(修改后容易出错),因此并不推荐。
- 离线安装(推荐)
将 2.1 节所下载的项目文件复制到 Python 项目文件夹,如 “C:\Python\Projects\Yolov12”。如果下载的是压缩文件,解压到 Python 项目文件夹。
打开 miniconda Prompt,激活创建的 Python 环境 Yolo12,切换到本项目文件夹,pip 安装 Yolo12。
“pip install -e .” 用于以"可编辑模式"(editable mode)安装当前目录的 Python 包。注意安装命令中的 “-e” 和 “.” 之间有一个空格。
conda activate Yolo12
cd C:\Python\Projects\YOLOv12
pip install -e .
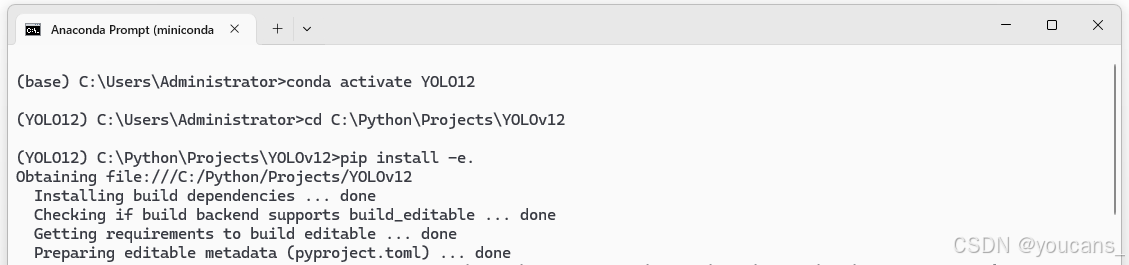

4.2 YOLO12 安装测试
安装完成后,在 miniconda Prompt 直接输入 “yolo help”,系统给出 Yolo 的帮助信息如下图所示,说明安装成功。
yolo help
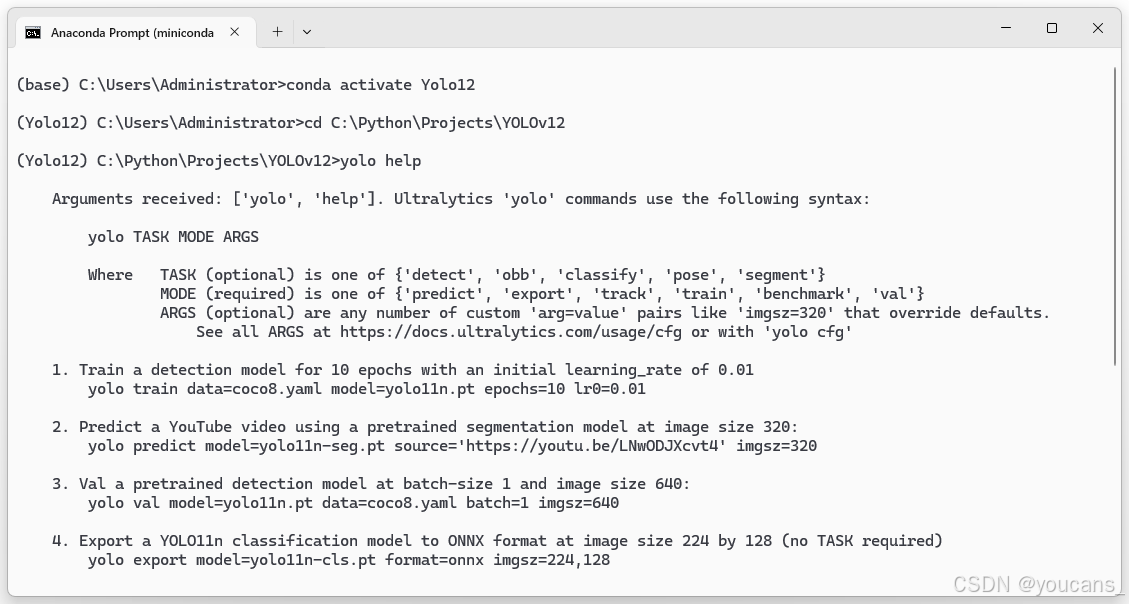
4.3 配置 Pycharm 编辑器
1、打开 PyCharm,打开 YOLOv12 项目。
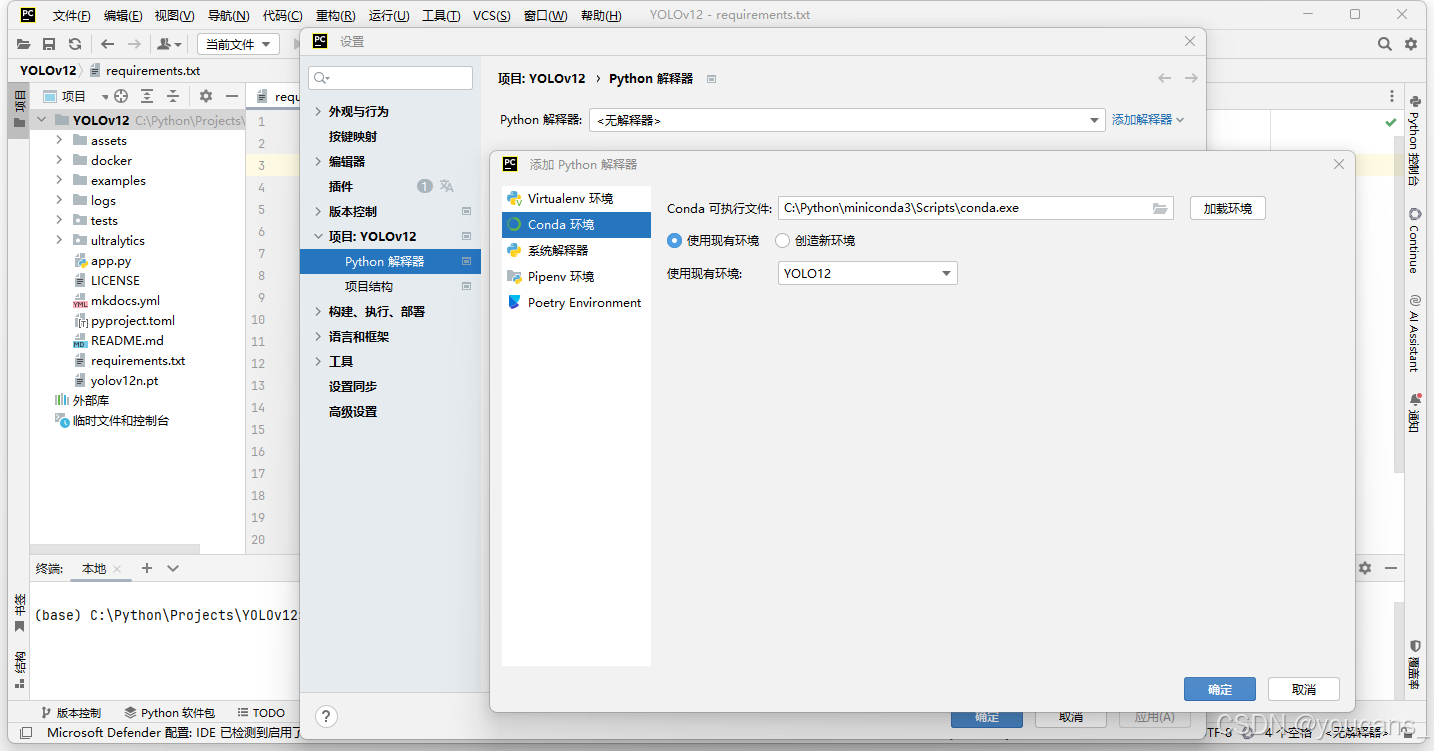
2、在 PyCharm 菜单选择:“文件-设置-项目-Python 解释器(python interpreter)” ,点击右侧窗口中的“添加解释器”,选择“添加本地解释器”,弹出“添加解释器” 窗口。
3、在“添加解释器” 窗口中,选择左侧“conda环境”,选中右侧“使用现有环境”,从“使用现有环境”下拉框中选择 YOLO12 环境,如下图所示。
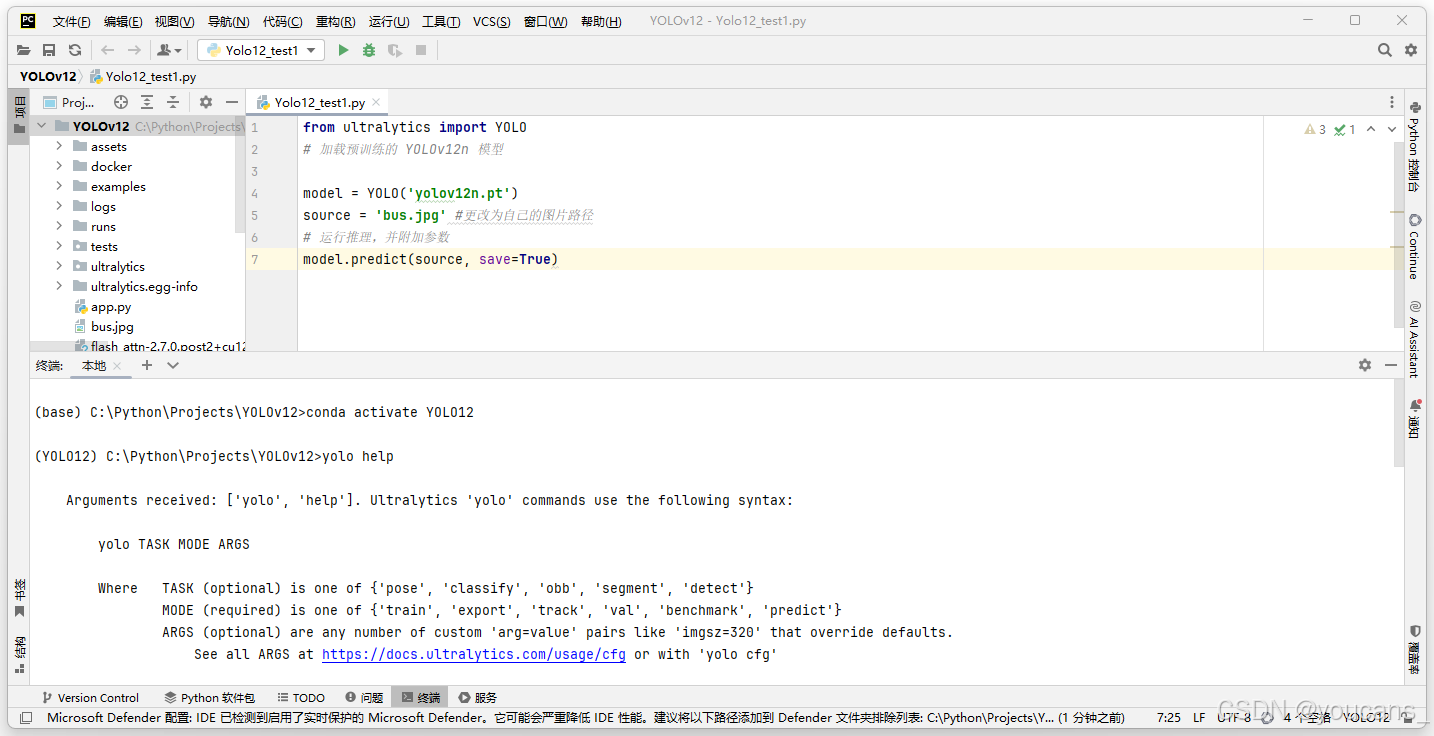
4、配置完成后,在 PyCharm 的命令行窗口,激活 YOLO11 虚拟环境,输入 “yolo help” 。如下图所示,系统给出 YOLO11 的帮助提示信息,说明配置成功。
5. YOLO12 模型推理
5.1 CLI 方式运行
YOLO12 支持使用命令行接口(command line interface, CLI)对模型进行训练、验证或运行推断。
YOLO12 命令行接口(CLI)方便在各种任务和版本上训练、验证或推断模型,不需要定制或代码,可以使用 yolo 命令从终端运行所有任务。
语法:
yolo task=detect mode=train model=YOLO11n.yaml args...classify predict YOLO11n-cls.yaml args...segment val YOLO11n-seg.yaml args...export YOLO11n.pt format=onnx args...
使用 miniconda Prompt 命令行,或在 PyCharm 的命令行窗口,都可以以CLI 方式运行 “yolo predict” 命令进行物体检测任务,具体操作步骤如下:
-
使用 miniconda Prompt 命令行,激活 YOLO12 虚拟环境,输入如下命令对指定图片进行检测。
-
在 PyCharm 的命令行窗口,激活 YOLO12 虚拟环境,输入如下命令对指定图片进行检测。
conda activate YOLO12
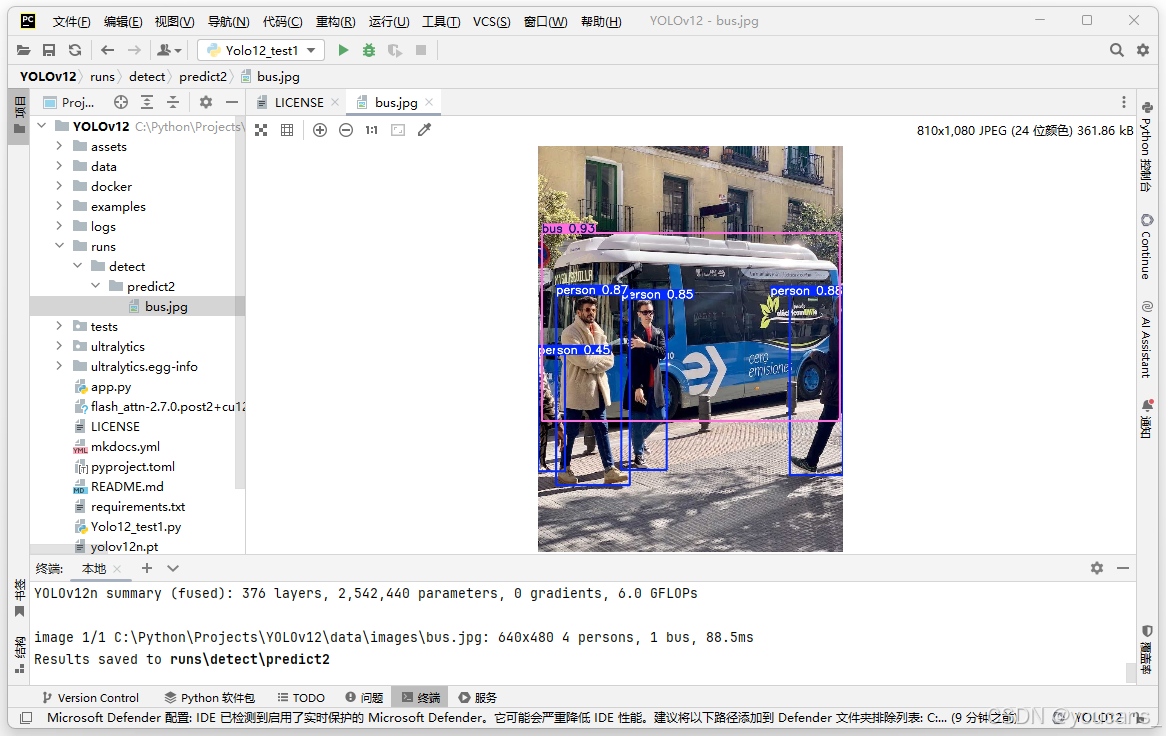
yolo predict model=“./yolov12n.pt” source=“./data/images/bus.jpg”
注意:
(1)必须先激活 YOLO12 虚拟环境。
(2)当前路径必须是 YOLO12 项目所在的目录,例如 “C:\Python\Projects\YOLOv12”。
(3)预训练模型 yolo12n.pt 必须保存在模型配置参数 “model” 指定的路径。例如,如果模型保存在 “.\model\yolov12n.pt”,则将模型配置参数修改为 “model=.\model\yolov12n.pt”。
(4)待检测的图片必须保存在 “source” 指定的路径,可以是图像路径、视频文件、目录、URL 或用于摄像头设备 ID。例如,可以指定网络地址,读取待检测图片。
yolo predict model=“.\yolov12n.pt” source=“https://ultralytics.com/images/bus.jpg”
(5)检测结果默认保存在 “.\runs\detect\predict” 目录下,也可以在命令中使用 “project” 参数,指定保存预测结果的项目目录名称。
(6)完整的写法是:
yolo task=detect mode=predict model=“.\yolov12n.pt” source=“./data/images/bus.jpg”
在命令行窗口显示的运行结果如下。
(base) C:\Python\Projects\YOLOv12>conda activate YOLO12 (YOLO12) C:\Python\Projects\YOLOv12>yolo predict model="./yolov12n.pt" source="./data/images/bus.jpg"
Ultralytics 8.3.63 🚀 Python-3.11.13 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce RTX 3060, 12288MiB)
YOLOv12n summary (fused): 376 layers, 2,542,440 parameters, 0 gradients, 6.0 GFLOPsimage 1/1 C:\Python\Projects\YOLOv12\data\images\bus.jpg: 640x480 4 persons, 1 bus, 88.5ms
Speed: 2.0ms preprocess, 88.5ms inference, 57.2ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs\detect\predict
检测结果保存在 Yolov12项目的子目录路径 “.\runs\detect\predict” 下,如下图所示。
5.2 Python 程序运行
YOLO12 也提供了 Python 接口的调用方式。它提供了加载和运行模型以及处理模型输出的函数。该界面设计易于使用,以便用户可以在他们的项目中快速实现目标检测。
使用预训练模型 yolov12n.pt 进行推理的 Python 程序如下。
from ultralytics import YOLO# 加载预训练的YOLO12模型
model = YOLO("./yolov12n.pt",task = "detect")# 使用模型对图像执行对象检测
result = model(source="./ultralytics/assets/zidane.jpg", save=True)
运行程序,就实现对指定图像文件的检测,并将检测结果保存到文件夹 “./runs/detect/predict2”。
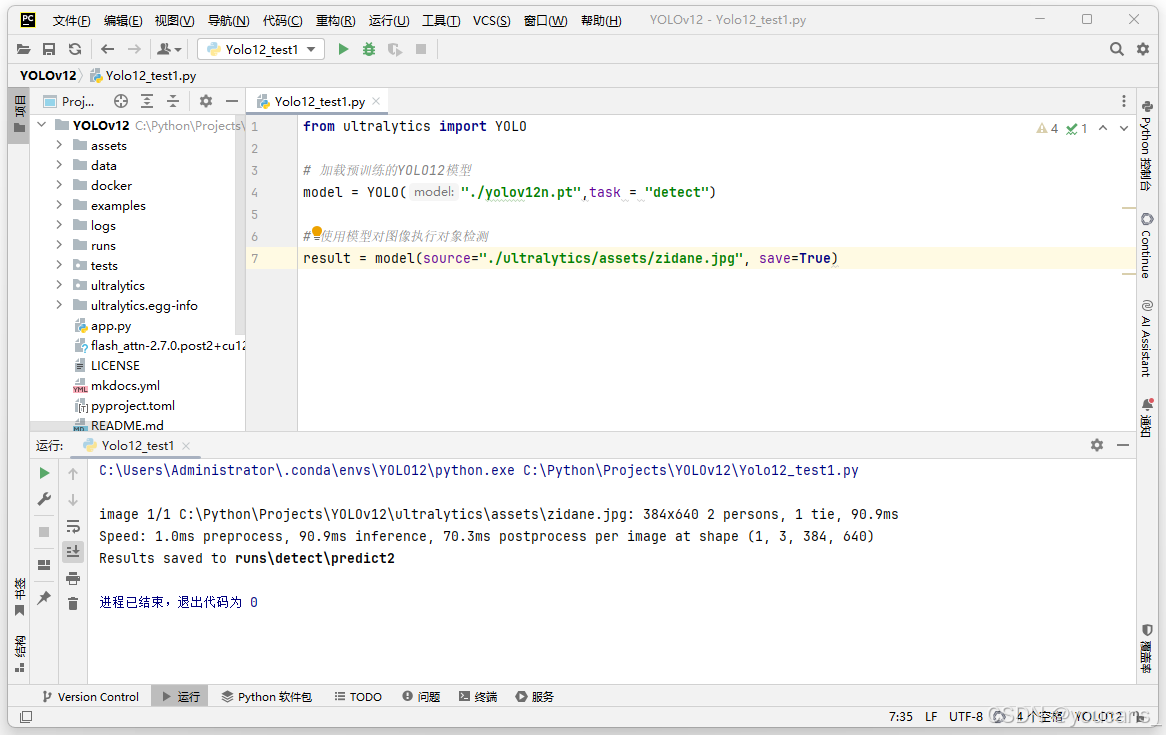
Python 程序运行结果与 CLI 方式是相同的,但可以执行更复杂的任务。
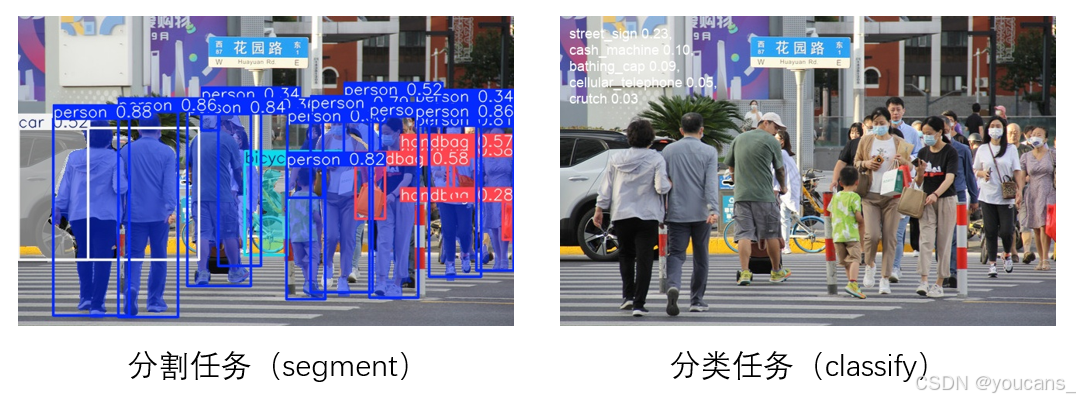
5.3 分割任务和分类任务
YOLO12 默认执行检测任务,也可以提供指定参数 TASK 实现分割、分类、姿势、定位任务。注意需要下载或使用对应任务的预训练模型,例如:分割任务模型 YOLO12n-seg.pt,分类任务模型 YOLO12n-cls.pt。
yolo TASK MODE ARGSWhere TASK (optional) is one of ('detect', 'segment', 'classify', 'pose', 'obb')MODE (required) is one of ('train', 'val', 'predict', 'export', 'track', 'benchmark')ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.See all ARGS at https://docs.ultralytics.com/usage/cfg or with 'yolo cfg'
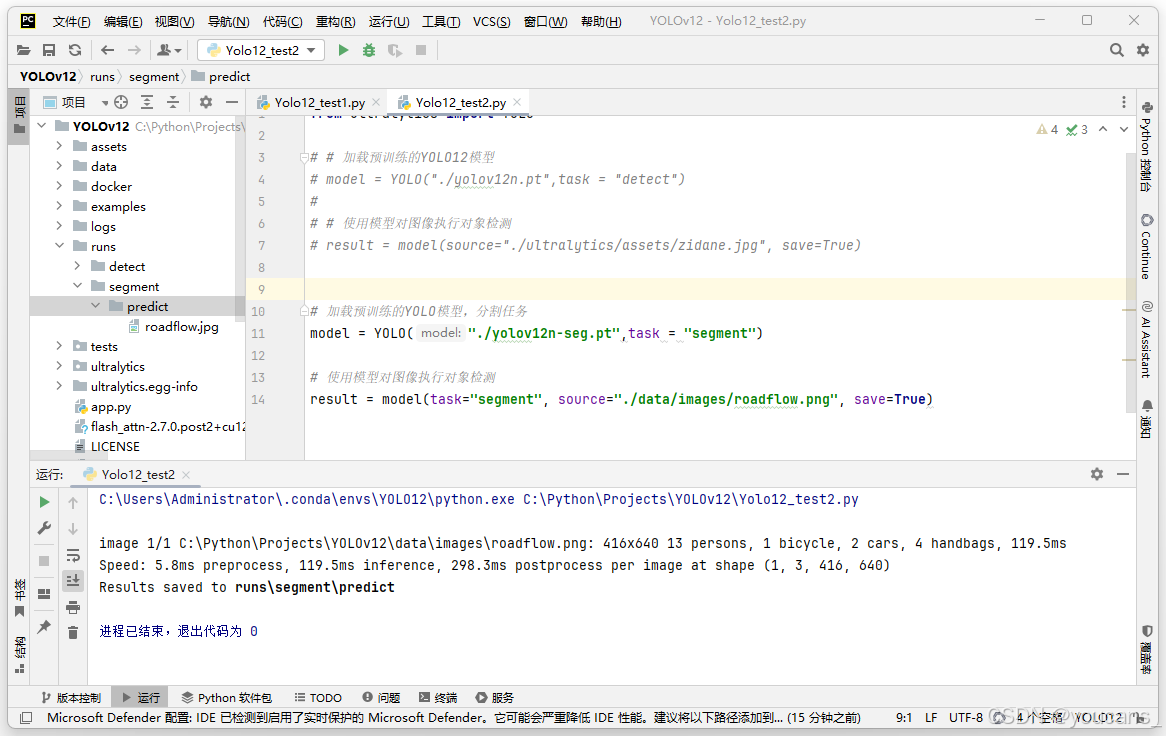
- 分割任务(segment)
注意要下载分割任务 预训练模型 yolov12n-seg.pt。
from ultralytics import YOLO# 加载预训练的YOLO模型,分割任务
model = YOLO("./yolov12n-seg.pt",task = "segment")# 使用模型对图像执行对象检测
result = model(task="segment", source="./data/images/roadflow.jpg", save=True)
程序运行结果如下图所示,检测结果保存到文件夹 “./runs/segment/predict”。
- 分类任务(“classify”)
from ultralytics import YOLO# 加载预训练的YOLO模型,分类任务
model = YOLO("./YOLO12n-cls.pt",task = "classify")# 使用模型对图像执行对象检测
result = model(task="classify", source="./ultralytics/assets/Mask01.jpg", save=True)
运行程序,检测结果保存到文件夹 “./runs\classify\predict”。
分割任务和分类任务的运行结果如下。
6. 参数说明
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| model | str | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
| data | str | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练和 验证数据类名和类数。 |
| epochs | int | 100 | 训练历元总数。每个历元代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
| time | float | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
| batch | int 或 float | 16 | 批量大小有三种模式: 设置为整数(如 batch=16)、自动模式,内存利用率为 60%GPU (batch=-1),或指定利用率的自动模式 (batch=0.70). |
| imgsz | int 或 list | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
| save | bool | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
| cache | bool | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O,提高训练速度,但代价是增加内存使用量。 |
| device | int 或 str 或 list | None | 指定用于训练的计算设备:单个GPU (device=0)、多个 GPU (device=[0,1])、CPU (device=cpu)、MPS for Apple silicon (device=mps),或自动选择最空闲的GPU (device=-1)或多个闲置 GPU (device=[-1,-1]) |
| workers | int | 8 | 加载数据的工作线程数(每 RANK 如果多GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多GPU 设置。 |
| project | str | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
| optimizer | str | ‘auto’ | 为培训选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
| classes | list[int] | None | 指定要训练的类 ID 列表。有助于在训练过程中筛选出特定的类并将其作为训练重点。 |
| freeze | int 或 list | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
| lr0 | float | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3).调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
| lrf | float | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
| momentum | float | 0.937 | 用于 SGD 的动量因子,或用于Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
| weight_decay | float | 0.0005 | L2正则化项,对大权重进行惩罚,以防止过度拟合。 |
| warmup_epochs | float | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
7. YOLOv12 的模型架构
7.1 YOLOv12 模型架构图

7.2 YOLOv12 模型配置文件
# YOLOv12 🚀, AGPL-3.0 license
# YOLOv12 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# CFG file for YOLOv12-turbo# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov12n.yaml' will call yolov12.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 497 layers, 2,553,904 parameters, 2,553,888 gradients, 6.2 GFLOPss: [0.50, 0.50, 1024] # summary: 497 layers, 9,127,424 parameters, 9,127,408 gradients, 19.7 GFLOPsm: [0.50, 1.00, 512] # summary: 533 layers, 19,670,784 parameters, 19,670,768 gradients, 60.4 GFLOPsl: [1.00, 1.00, 512] # summary: 895 layers, 26,506,496 parameters, 26,506,480 gradients, 83.3 GFLOPsx: [1.00, 1.50, 512] # summary: 895 layers, 59,414,176 parameters, 59,414,160 gradients, 185.9 GFLOPs# YOLO12-turbo backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2, 1, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2, 1, 4]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 4, A2C2f, [512, True, 4]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 4, A2C2f, [1024, True, 1]] # 8# YOLO12-turbo head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, A2C2f, [512, False, -1]] # 11- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, A2C2f, [256, False, -1]] # 14- [-1, 1, Conv, [256, 3, 2]]- [[-1, 11], 1, Concat, [1]] # cat head P4- [-1, 2, A2C2f, [512, False, -1]] # 17- [-1, 1, Conv, [512, 3, 2]]- [[-1, 8], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)7.3 YOLOv12 模型架构详解
YOLOv12 模型结构包括:Backbone(主干网络)和 Head(头部网络)。Backbone 用作特征提取器,通过一系列卷积层处理输入图像,以生成不同尺度的分层特征图,捕获目标检测所需的基本空间和上下文信息。Head 负责多尺度特征融合,通过结合上采样、级联和卷积操作增强了特征表示,确保对小型、中型和大型目标的鲁棒检测。
1. Backbone(主干网络)
YOLOv12 主干网络的核心是 残差高效层聚合网络(R-ELAN),这是对传统 ELAN 结构的改进,引入了块级残差连接和特征聚合优化,将更深的卷积层与精心设置的残差连接融合在一起。具体地,YOLOv12 的 Backbone 由 Conv(卷积层)、C3k2 和 A2C2f 模块组成。
YOLOv12 的主干网络通过一系列卷积层处理输入图像,逐步降低其空间维度,同时增加特征图的深度。该过程首先由一个初始卷积层开始,用于提取低级特征;然后是其他卷积层,用于执行下采样以捕获层次化信息。第一阶段采用步长为 2 的 3×3 卷积来生成初始特征图。接下来是另一个卷积层,进一步降低空间分辨率,同时增加特征深度。当图像在主干网络中移动时,它会使用 C3k2 和 A2C2F 等专用模块进行多尺度特征学习。C3k2 模块在保持计算效率的同时增强了特征表示,而 A2C2F 模块则改进了特征融合,从而更好地理解空间和上下文。主干网络持续此过程,直到生成三个关键特征图:P3、P4 和 P5,每个图代表不同的特征提取尺度。
2. Head(头部网络)
YOLOv12 的头部网络负责合并多尺度特征并生成最终的目标检测预测。
具体地,通过 Concat(拼接层)、Upsample(上采样层)和 A2C2f 模块,对 Backbone 提取的特征进行特征融合和调整,通过上采样和拼接操作,整合不同层次的特征信息,增强特征的表达。
首先使用最近邻插值方法对最高分辨率特征图 (P5) 进行上采样。然后,将其与相应的低分辨率特征图 (P4) 连接起来,以创建精细的特征表示。融合后的特征将使用 A2C2F 模块进一步处理,以增强其表达能力。对下一个尺度重复类似的过程,即对精细的特征图进行上采样,并将其与低尺度特征 (P3) 连接起来。这种分层融合确保低级和高级特征都能参与最终检测,从而提升模型在不同尺度下检测目标的能力。特征融合后,网络将进行最终处理,为检测做好准备。经过优化的特征再次进行下采样,并在不同层级上进行合并,以增强目标表征。C3k2 模块应用于最大规模(P5/32-large),以确保在降低计算成本的同时保留高分辨率特征。
YOLOv12 的检测头由多个 Detect(检测层)组成,将分类和回归任务分离,以减少特征冲突。特征融合后的特征图被传递到最终检测层,该层对不同的目标类别进行分类和定位预测。
7.4 YOLO12 核心模块 A2C2f 的结构功能
A2C2f(Adaptive channel-wise and spatial attention with context fusion) 是 YOLO12 模型的关键结构,其结构如下。
A2C2f
├── cv1
│ ├── Conv2d(256, 128)
│ ├── BatchNorm2d(128)
│ └── SiLU()
├── cv2
│ ├── Conv2d(256, 256)
│ ├── BatchNorm2d(256)
│ └── SiLU()
└── m (ModuleList)└── Sequential├── ABlock│ ├── AAttn│ │ ├── qkv(Conv2d(128, 384))│ │ ├── proj(Conv2d(128, 128))│ │ └── pe(Conv2d(128, 128))│ └── MLP│ ├── Conv2d(128, 256)│ └── Conv2d(256, 128)└── ABlock├── AAttn│ ├── qkv(Conv2d(128, 384))│ ├── proj(Conv2d(128, 128))│ └── pe(Conv2d(128, 128))└── MLP├── Conv2d(128, 256)└── Conv2d(256, 128)
- cv1 和 cv2:
卷积层(Conv),分别将输入通道数从 256 转换到 128 (cv1) 和保持在 256 (cv2)。
每个 Conv 都由一个 Conv2d 层、一个 BatchNorm2d 层以及一个激活函数(SiLU 或 Identity)组成。 - m (ModuleList):
包含了一个或多个 Sequential 模块,每个模块中有一个或多个 ABlock。 - ABlock:
每个 ABlock 包含一个注意力机制模块 AAttn 和一个多层感知机(MLP)模块。- AAttn (Attention Block):
qkv: 一个卷积层,用于生成查询(query)、键(key)和值(value)向量。输出通道数为输入的三倍(在这个例子中,输入是 128,输出是 384)。
proj: 另一个卷积层,用于将注意力结果投影回原始维度。
pe: 位置编码(Position Encoding),通过一个深度可分离卷积(groups=128)实现,其核大小为 7x7,并带有适当的填充以确保输入和输出尺寸相同。 - MLP (多层感知机):
MLP 由两层卷积层构成,其中第一层扩展了特征维度(例如从 128 到 256),而第二层则将其压缩回到原来的维度(如从 256 回到 128)。每层之间使用 SiLU 作为激活函数,除了最后一层使用 Identity(即没有激活函数)。
- AAttn (Attention Block):
【本节完】
版权声明:
欢迎关注『youcans动手学模型』系列
转发请注明原文链接:
【跟我学YOLO】(2)YOLO12 环境配置与基本应用
Copyright 2025 youcans
Crated:2025-07
如果您在研究中使用了 YOLO12,请引用水牛城大学和中国科学院大学的原作:
@article{tian2025yolov12,title={YOLOv12: Attention-Centric Real-Time Object Detectors},author={Tian, Yunjie and Ye, Qixiang and Doermann, David},journal={arXiv preprint arXiv:2502.12524},year={2025}
}@software{yolo12,author = {Tian, Yunjie and Ye, Qixiang and Doermann, David},title = {YOLOv12: Attention-Centric Real-Time Object Detectors},year = {2025},url = {https://github.com/sunsmarterjie/yolov12},license = {AGPL-3.0}
}