【C++11】右值引用和移动语义
在C++98标准中就已经引入了引用的语法概念,这是一种为已存在的对象创建别名的方式,可以避免指针操作带来的复杂性。而到了C++11标准,为了支持移动语义和完美转发等新特性,新增加了右值引用(Rvalue Reference)这一重要语法特性,使用"&&"符号表示。为了区分这两种引用类型,在C++11之后,我们把传统的引用称为左值引用(Lvalue Reference)。
左值引用和右值引用的本质都是为对象创建别名,但它们在绑定规则上存在重要区别:
- 左值引用通常只能绑定到左值(可以取地址、有持久存储的对象)
- 右值引用专门绑定到右值(临时对象或即将销毁的对象)
例如:
int a = 10; // a是左值
int &lr = a; // 左值引用
int &&rr = 10; // 右值引用绑定到临时对象void process(int &x) { /* 处理左值 */ }
void process(int &&x) { /* 处理右值 */ }
应用场景上:
- 左值引用常用于避免对象拷贝,作为函数参数或返回值
- 右值引用实现了移动语义,显著提升了资源管理效率,比如:
std::vector<std::string> v; v.push_back(std::string("hello")); // 使用移动语义而非拷贝
值得注意的是,C++11还引入了引用折叠规则和通用引用(Universal Reference)的概念,进一步丰富了引用的使用方式。这些特性共同构成了现代C++高效资源管理的基础。
1. 左值和右值详解
左值(lvalue)
左值是一个表示数据的表达式,具有以下显著特征:
- 持久性:通常具有持久状态,存储在内存中
- 可寻址性:可以获取其内存地址(通过
&操作符) - 位置灵活性:可以出现在赋值运算符的左边或右边
常见左值示例:
- 变量名:
int x = 5;中的x - 解引用的指针:
*ptr(假设ptr是有效指针) - 数组元素:
arr[0] - 返回左值引用的函数调用
const修饰的左值特殊情况:
const int y = 10;
// y = 20; // 错误:不能给const左值赋值
int* p = &y; // 正确:可以取const左值的地址
右值(rvalue)
右值是另一个表示数据的表达式,具有以下特征:
- 临时性:通常是临时对象或字面量
- 不可寻址:不能获取其内存地址
- 位置限制:只能出现在赋值运算符的右边
常见右值类型:
- 字面值常量:
42,"hello",3.14 - 表达式结果:
x + y,func()(返回非引用) - 临时对象:
std::string("temp") - 类型转换结果:
static_cast<int>(3.14)
示例:
int a = 10; // 10是右值
int b = a; // a是左值
// 10 = a; // 错误:不能给右值赋值
// &(a + b); // 错误:不能取右值的地址
术语演变与本质区别
术语演变:
- 传统理解:
lvalue=left value,rvalue=right value - 现代C++解释:
lvalue=locator value(可定位的值)rvalue=read value(可读的值)
核心区别:
- 能否取地址是区分左值和右值的关键标准
- 左值有持久内存位置
- 右值通常是短暂存在的临时对象或字面量
补充说明:
- 寄存器变量:CPU寄存器中的值属于右值,因为无法直接获取其内存地址
- 移动语义:C++11引入的右值引用(
&&)允许识别和高效利用右值资源
int main()
{// 左值:可以取地址// 以下的p、b、c、*p、s、s[0]就是常见的左值int* p = new int(0);int b = 1;const int c = b;*p = 10;string s("111111");s[0] = 'x';cout << &c << endl;cout << (void*)&s[0] << endl;// 右值:不能取地址double x = 1.1, y = 2.2;// 以下几个10、x + y、fmin(x, y)、string("11111")都是常见的右值10;x + y;fmin(x, y);string("11111");//cout << &10 << endl;//cout << &(x+y) << endl;//cout << &(fmin(x, y)) << endl;//cout << &string("11111") << endl;return 0;
}运行结果:左值可以取地址

2. 左值引用与右值引用
• 左值引用声明:Type& r1 = x;,右值引用声明:Type&& rr1 = y;。前者为左值创建别名,后者为右值创建别名。
• 引用限制:
- 左值引用不能直接绑定右值,但const左值引用可以绑定右值
- 右值引用不能直接绑定左值,但可以通过
move()绑定左值
• move函数解析:
template <class T> typename remove_reference<T>::type&& move(T&& arg);- 标准库提供的函数模板
- 核心功能是执行强制类型转换
- 涉及引用折叠机制(后续详述)
• 重要特性:
- 所有变量表达式都具有左值属性
- 右值被右值引用绑定后,该引用变量表达式仍为左值
• 实现原理:
- 语法层面:均为别名机制,不分配新空间
- 汇编层面:引用变量实际通过指针实现
- 注意:语法语义与底层实现可能不一致,应分别理解而非强行关联
int main()
{// 左值:可以取地址// 以下的p、b、c、*p、s、s[0]就是常见的左值int* p = new int(0);int b = 1;const int c = b;*p = 10;string s("111111");s[0] = 'x';double x = 1.1, y = 2.2;// 左值引用给左值取别名int& r1 = b;int*& r2 = p;int& r3 = *p;string& r4 = s;char& r5 = s[0];// 右值引用给右值取别名int&& rr1 = 10;double&& rr2 = x + y;double&& rr3 = fmin(x, y);string&& rr4 = string("11111");// 左值引用不能直接引用右值,但是const左值引用可以引用右值const int& rx1 = 10;const double& rx2 = x + y;const double& rx3 = fmin(x, y);const string& rx4 = string("11111");// 右值引用不能直接引用左值,但是右值引用可以引用move(左值)int&& rrx1 = move(b);int*&& rrx2 = move(p);int&& rrx3 = move(*p);string&& rrx4 = move(s);string&& rrx5 = (string&&)s;// b、r1、rr1都是变量表达式,都是左值cout << &b << endl;cout << &r1 << endl;cout << &rr1 << endl;// 这里要注意的是,rr1的属性是左值,所以不能再被右值引用绑定,除非move一下int& r6 = r1;// int&& rrx6 = rr1; //错误int&& rrx6 = move(rr1);return 0;
}运行结果:

3. 引用延长生命周期
在C++中,引用可以用来为临时对象延长生命周期,这主要通过两种方式实现:右值引用(Rvalue Reference)和 const的左值引用(const Lvalue Reference)
两种方式的区别:
- 右值引用允许对临时对象进行修改和资源转移
- const左值引用只能提供只读访问
- 前者常用于实现移动语义和完美转发
- 后者多用于函数参数传递优化
生命周期延长的规则:
- 只有当引用直接绑定到临时对象时才有效
- 临时对象的生命周期将延长到与引用相同
- 对于通过函数返回的临时对象无效
- 链式引用绑定不会延长生命周期
int main()
{string s1 = "Test";//string&& r1 = s1; // 错误:不能绑定到左值const string& r2 = s1 + s1; // OK:绑定到 const 的左值引用延长生存期// r2 += "Test"; // 错误:不能通过绑定到 const 的引用修改std::string&& r3 = s1 + s1; // OK:右值引用延长生存期r3 += "Test"; // OK:能通过绑定到非 const 的引用修改cout << r2 << '\n';cout << r3 << '\n';return 0;
}注意:上面代码中表达式s1 + s1的结果返回的是临时对象,而临时对象具有常性,所以只能被const左值引用或者右值引用
运行结果:

4. 左值与右值的参数匹配
• 在C++98标准中,如果函数参数为const左值引用,则实际参数既可以接受左值也可以接受右值。
• 从C++11开始,当分别重载左值引用、const左值引用和右值引用作为参数的f函数时:
- 左值实参将匹配f(左值引用)
- const左值实参将匹配f(const左值引用)
- 右值实参将匹配f(右值引用)
• 需要注意的是,右值引用变量在作为表达式使用时具有左值属性。这种设计看似反常,但在下面讨论右值引用的使用场景时,我们将理解其实际价值。
void f(int& x)
{std::cout << "左值引用重载 f(" << x << ")\n";
}
void f(const int& x)
{std::cout << "到 const 的左值引用重载 f(" << x << ")\n";
}
void f(int&& x)
{std::cout << "右值引用重载 f(" << x << ")\n";
}
int main()
{int i = 1;const int ci = 2;f(i); // 调用 f(int&)f(ci); // 调用 f(const int&)f(3); // 调用 f(int&&),如果没有 f(int&&) 重载则会调用 f(const int&)f(std::move(i)); // 调用 f(int&&)// 右值引用变量在用于表达式时是左值int&& x = 1;f(x); // 调用 f(int& x)f(std::move(x)); // 调用 f(int&& x)return 0;
}运行结果:

5. 值引用和移动语义的使用场景
5.1 左值引用主要使用场景回顾
左值引用在C++编程中主要有以下几种典型使用场景:
-
函数参数传递
- 避免大型对象拷贝:对于结构体或类等大型对象,通过左值引用传递可显著提升性能
- 示例:void processVector(vector<int>& vec) {...}
-
修改传入参数
- 允许函数修改调用方提供的变量
- 示例:void increment(int& num) { num++; }
-
函数返回值优化
- 返回已有对象的引用,避免不必要的拷贝
- 常见于运算符重载:Matrix& operator+=(const Matrix& other)
-
链式调用支持
- 通过返回引用实现方法链式调用
- 示例:cout.setf(...).width(...).precision(...)
在C++98中,对于需要返回新创建对象的函数(如字符串相加、对象生成等),由于不能返回局部变量的引用(函数结束后对象会被销毁),通常采用以下解决方案:
- 输出型参数:将结果通过引用参数返回
- 示例:void addStrings(string& result, const string& a, const string& b)
- 返回对象副本:牺牲性能避免悬空引用
特别需要注意的限制情况:
- 不能返回局部变量的引用或指针
- 不能返回临时对象的引用
- 返回静态局部变量或全局变量的引用是可行的,但需注意线程安全问题
对于C++11的右值引用,虽然提供了移动语义的优化,但在返回局部对象场景下依然无法解决根本问题,因为:
- 对象生命周期不会因引用类型改变而延长
- 函数返回后局部对象依然会被销毁
- 返回右值引用仍可能导致悬空引用问题
因此,在这些特定场景下,输出型参数仍然是必要的解决方案之一。
5.2 移动构造与移动赋值
• 移动构造函数是一种特殊构造函数,其特性与拷贝构造函数类似。不同之处在于,移动构造函数的第一个参数必须是该类的右值引用类型。若存在其他参数,则必须提供默认值。
• 移动赋值运算符是赋值操作符的重载版本,与拷贝赋值运算符构成重载关系。与后者相比,移动赋值运算符的第一个参数同样要求是类的右值引用。
• 移动语义对需要进行深度拷贝的类(如string/vector)或包含深度拷贝成员变量的类尤为有意义。由于移动构造和移动赋值都接收右值引用参数,其核心机制是通过"窃取"右值对象的资源来实现,而非像拷贝操作那样复制资源,从而显著提升效率。下面的RO::string示例展示了移动构造和移动赋值的具体实现,建议结合使用场景来理解其工作原理。
namespace RO
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}string(const char* str = ""):_size(strlen(str)), _capacity(_size){cout << "string(char* str) —— 构造" << endl;_str = new char[_capacity + 1];strcpy(_str, str);}void swap(string& s){::swap(_str, s._str);::swap(_size, s._size);::swap(_capacity, s._capacity);}string(const string& s):_str(nullptr){cout << "string(const string& s) —— 拷贝构造" << endl;reserve(s._capacity);for (auto ch : s){push_back(ch);}}// 移动构造string(string&& s){cout << "string(string&& s) —— 移动构造" << endl;swap(s);}string& operator=(const string& s){cout << "string& operator=(const string& s) —— 拷贝赋值" <<endl;if (this != &s){_str[0] = '\0';_size = 0;reserve(s._capacity);for (auto ch : s){push_back(ch);}}return *this;}// 移动赋值string& operator=(string&& s){cout << "string& operator=(string&& s) —— 移动赋值" << endl;swap(s);return *this;}~string(){cout << "~string() —— 析构" << endl;delete[] _str;_str = nullptr;}char& operator[](size_t pos){assert(pos < _size);return _str[pos];}void reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];if (_str){strcpy(tmp, _str);delete[] _str;}_str = tmp;_capacity = n;}}void push_back(char ch){if (_size >= _capacity){size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}_str[_size] = ch;++_size;_str[_size] = '\0';}string& operator+=(char ch){push_back(ch);return *this;}const char* c_str() const{return _str;}size_t size() const{return _size;}private:char* _str = nullptr;size_t _size = 0;size_t _capacity = 0;};
}int main()
{RO::string s1("xxxxx");// 拷贝构造RO::string s2 = s1;// 构造+移动构造,优化后直接构造RO::string s3 = RO::string("yyyyy");// 移动构造RO::string s4 = move(s1);cout << "******************************" << endl;return 0;
}运行结果:

注意:移动操作后,被移动的对象应仍处于有效状态(通常为空状态),使其可以安全析构或重新赋值。
5.3 右值引用和移动语义解决传值返回问题
结合上面的string
namespace RO
{string addStrings(string num1, string num2){string str;int end1 = num1.size() - 1, end2 = num2.size() - 1;int next = 0;while (end1 >= 0 || end2 >= 0){int val1 = end1 >= 0 ? num1[end1--] - '0' : 0;int val2 = end2 >= 0 ? num2[end2--] - '0' : 0;int ret = val1 + val2 + next;next = ret / 10;ret = ret % 10;str += ('0' + ret);}if(next == 1)str += '1';reverse(str.begin(), str.end());cout << "******************************" << endl;return str;}
}
// 场景1
int main()
{RO::string ret = RO::addStrings("11111111111111111111", "222222222222222222222222222");cout << ret.c_str() << endl;return 0;
}
// 场景2
int main()
{RO::string ret;ret = RO::addStrings("11111111111111111111", "222222222222222222222222222");cout << ret.c_str() << endl;return 0;
}右值对象构造场景:仅存在拷贝构造函数,未定义移动构造函数的情况分析
• 图1对比了VS2019 Debug模式下编译器对拷贝操作的优化效果:
- 左侧为未优化状态,发生两次拷贝构造
- 右侧为优化后状态,将连续步骤中的拷贝操作合并为单次拷贝构造
• 优化程度差异说明:
- 在VS2019 Release模式及VS2022各模式下,优化效果更为显著
- 原流程(str对象构造→临时对象拷贝→ret对象拷贝)被合并为直接构造
- 理解此优化需结合局部对象生命周期及栈帧机制,详见图3说明
• Linux环境验证方法:
- 将代码复制至test.cpp文件
- 使用编译命令:g++ test.cpp -fno-elide-constructors(关闭构造优化)
- 运行结果将呈现图1左侧未优化的两次拷贝构造情况

图1
linux下运行结果:

右值对象的构造涉及拷贝构造和移动构造两种情况。
• 图2对比了VS2019 debug模式下编译器对拷贝操作的优化效果:左侧未优化时需进行两次移动构造,右侧经过优化后合并为一次移动构造。
• 值得注意的是,在VS2019 release模式以及VS2022的debug/release模式下,优化效果更为显著:str对象的构造、str拷贝构造临时对象以及临时对象拷贝构造ret对象这三个步骤会被合并为直接构造。理解这一优化需要从局部对象生命周期和栈帧的角度进行分析,如图3所示。
• 在Linux环境下,可将代码保存为test.cpp文件,通过g++ test.cpp -fno-elide-constructors命令关闭构造优化,运行结果将如图所示,可观察到未优化的两次移动构造过程。

图2

图3
Linux下运行结果:

当仅有拷贝构造和拷贝赋值函数,而没有移动构造和移动赋值函数时:
-
在VS2019 Debug模式或使用
g++ test.cpp -fno-elide-constructors编译时(关闭优化),编译器会执行一次拷贝构造和一次拷贝赋值操作(如图4左侧所示)。 -
值得注意的是,在以下环境中编译器会进行更深层次的优化:
- VS2019 Release模式
- VS2022的Debug和Release模式
优化后的实现会直接构造返回的临时对象。从实现层面看,str实际上是临时对象的引用(底层通过指针实现)。通过运行结果可以观察到:str的析构发生在赋值操作之后,这验证了str确实是临时对象的别名。

图4

对象右值赋值时涉及拷贝构造、拷贝赋值、移动构造和移动赋值等多种操作。
图5左侧展示了在VS2019 Debug模式以及使用g++ test.cpp -fno-elide-constructors关闭优化的情况下,编译器会执行一次移动构造和一次移动赋值操作。
值得注意的是,在VS2019 Release模式以及VS2022的Debug和Release模式下,编译器会进一步优化代码。此时会直接构造要返回的临时对象,而str实际上是对该临时对象的引用(底层实现通过指针完成)。从运行结果可以看出,str的析构发生在赋值操作之后,这证实了str确实是临时对象的别名。
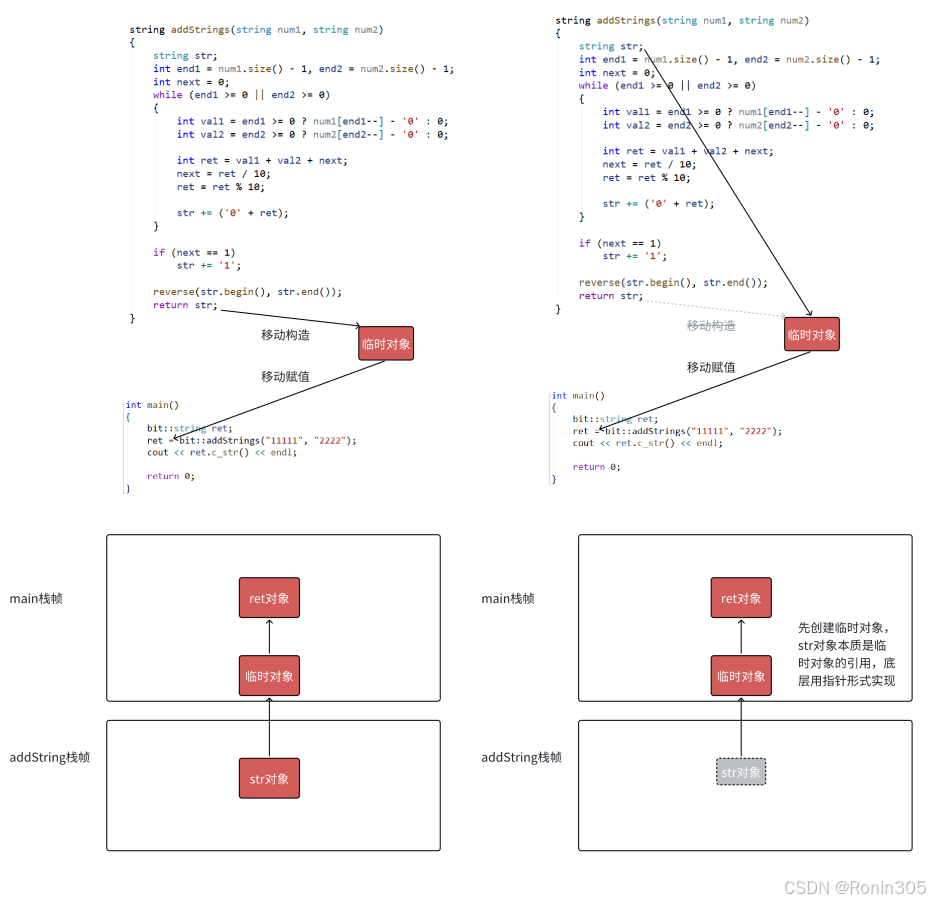
图5

核心区别对比表
| 特性 | 拷贝操作 | 移动操作 |
|---|---|---|
| 资源处理 | 创建资源副本 | 转移资源所有权 |
| 性能开销 | 高(O(n)复制操作) | 低(O(1)指针操作) |
| 源对象状态 | 保持不变 | 置为空/无效状态 |
| 参数类型 | const T& | T&& |
| 异常安全 | 可能抛出异常 | 通常标记为 noexcept(后面会讲) |
| 适用场景 | 需要独立副本 | 临时对象或显式转移 |
| 自动生成 | 默认生成 | 仅当无自定义拷贝/析构时生成 |
5.4 右值引用与移动语义在传参中的性能优化
右值引用和移动语义在函数参数传递中能显著提升性能,主要通过避免不必要的拷贝操作来实现。
一、核心优化原理
1. 传统传参的性能瓶颈
// 传统方式 - 深拷贝问题
void processVector(std::vector<BigObject> data) {// 函数调用时发生完整拷贝// 时间复杂度:O(n)
}std::vector<BigObject> bigData(1000000);
processVector(bigData); // 百万次拷贝构造!2. 移动语义的优化机制
// 移动语义优化版本
void processVector(std::vector<BigObject>&& data) {// 直接接管资源所有权// 时间复杂度:O(1)
}processVector(std::move(bigData)); // 仅指针交换优化本质:
-
将昂贵的深拷贝(O(n))转换为廉价的指针交换(O(1))
-
避免临时对象的构造和析构开销
二、关键优化场景
1. 接收函数返回值
// 传统方式:拷贝构造 + 析构临时对象
std::string createString();
void process(const std::string& str);process(createString()); // 拷贝发生// 优化版本:直接移动
void process(std::string&& str);process(createString()); // 移动构造,零拷贝2. 传递大型对象
class Matrix {double* data;size_t rows, cols;
public:// 移动构造函数Matrix(Matrix&& other) noexcept : data(other.data), rows(other.rows), cols(other.cols){other.data = nullptr;}
};void transform(Matrix&& mat); // 高效接口Matrix largeMat(1000, 1000);
transform(std::move(largeMat)); // 仅复制3个值3. 容器操作优化
// 传统push_back
std::vector<BigType> vec;
BigType obj;
vec.push_back(obj); // 拷贝构造// 移动优化
vec.push_back(std::move(obj)); // 移动构造
vec.emplace_back(args...); // 原位构造,涉及可变参数,后面会讲三、性能优化对比
不同操作的时间复杂度
| 操作类型 | 拷贝语义 | 移动语义 |
|---|---|---|
| std::vector | O(n) | O(1) |
| std::string | O(n) | O(1) |
| 自定义大对象 | O(n) | O(1) |
| 简单类型(int等) | O(1) | O(1) |
实测性能数据(百万元素vector)
| 操作 | 时间(ms) | 加速比 |
|---|---|---|
| 拷贝构造 | 250 | 1x |
| 移动构造 | 0.2 | 1250x |
| emplace_back | 0.15 | 1667x |
移动语义在传参中的核心优势:
-
将O(n)操作降为O(1)
-
消除临时对象构造/析构开销
-
减少动态内存分配次数
-
降低缓存不命中率
-
提升数据局部性
通过合理使用右值引用和移动语义,在资源密集型应用中可实现数量级的性能提升,同时保持代码的安全性和清晰性。
6. 类型分类
• C++11以后,对类型系统进行了更细致的划分,右值被划分为纯右值(pure value,简称prvalue)和将亡值(expiring value,简称xvalue)。这种分类是为了更好地支持移动语义和完美转发。
• 纯右值是指那些:
- 字面值常量:如 42、true、nullptr等
- 不具名的临时对象:如str.substr(1, 2)创建的子字符串
- 传值返回的函数调用:如std::string getString() {return "hello";}返回的临时对象
- 算术表达式的结果:如a+b、a++等表达式的结果
纯右值在C++11中的概念与C++98中的右值概念基本一致,但新增了将亡值的概念。纯右值通常是不可修改的,且没有持久的内存地址。
• 将亡值是指:
- 返回右值引用的函数调用:如std::move(x)的返回值
- 转换为右值引用的转换结果:如static_cast<X&&>(x)的转换结果
- 某些特定表达式的结果:如临时对象的成员访问表达式(a.m,其中a是右值)
将亡值的重要特性是可以被"移动"的资源,代表即将被销毁或重新使用的对象资源。
• 泛左值(generalized value,简称glvalue)是一个更广泛的分类,包含:
- 传统的左值(lvalue):如变量、函数名、左值引用等
- 将亡值(xvalue):如上所述
泛左值的特点是具有身份(identity),即可以确定其存储位置。
• 关于值类别的详细说明,可以参考以下官方文档:Value categories(C++标准文档中的相关说明)
这些文档详细解释了各种值类别的定义、特点和使用场景,特别是对于理解现代C++中的移动语义和完美转发非常重要。

7. 引用折叠
- 在C++中,直接定义引用的引用(如
int& && r = i;)会导致编译错误。不过通过模板或typedef的类型操作可以间接形成引用的引用。 - 针对这种情况,C++11制定了引用折叠规则:
- 右值引用的右值引用会折叠成右值引用
- 其他所有组合都会折叠成左值引用
-
典型的函数模板
f2中,T&& x参数看似是右值引用,但由于引用折叠规则:- 传递左值时实际成为左值引用
- 传递右值时成为右值引用 这种特性也被称为"万能引用"。
-
在
Function(T&& t)模板中:- 当实参为int右值时,T推导为int类型
- 当实参为int左值时,T推导为int&类型 结合引用折叠规则,该模板可以自动适配左值和右值参数,分别实例化出对应的引用版本。
// 由于引用折叠限定,f1实例化以后总是一个左值引用
template<class T>
void f1(T & x)
{}
// 由于引用折叠限定,f2实例化后可以是左值引用,也可以是右值引用
template<class T>
void f2(T&& x)
{}
int main()
{typedef int& lref;typedef int&& rref;int n = 0;lref& r1 = n; // r1 的类型是 int&lref&& r2 = n; // r2 的类型是 int&rref& r3 = n; // r3 的类型是 int&rref&& r4 = 1; // r4 的类型是 int&&// 没有折叠->实例化为void f1(int& x)f1<int>(n);//f1<int>(0); // 报错// 折叠->实例化为void f1(int& x)f1<int&>(n);//f1<int&>(0); // 报错// 折叠->实例化为void f1(int& x)f1<int&&>(n);//f1<int&&>(0); // 报错// 折叠->实例化为void f1(const int& x)f1<const int&>(n);f1<const int&>(0);// 折叠->实例化为void f1(const int& x)f1<const int&&>(n);f1 < const int&& > (0);// 没有折叠->实例化为void f2(int&& x)//f2<int>(n); // 报错f2<int>(0);// 折叠->实例化为void f2(int& x)f2<int&>(n);//f2<int&>(0); // 报错// 折叠->实例化为void f2(int&& x)//f2<int&&>(n); // 报错f2<int&&>(0);return 0;
}8. 完美转发
• 万能引用
在Function(T&& t)函数模板中,传递左值会实例化为左值引用的Function函数,传递右值则会实例化为右值引用的Function函数。
// 万能引用
template<class T>
void Function(T&& t)
{int a = 0;T x = a;//x++;cout << &a << endl;cout << &x << endl << endl;
}
int main()
{// 10是右值,推导出T为int,模板实例化为void Function(int&& t)Function(10); // 右值int a;// a是左值,推导出T为int&,引用折叠,模板实例化为void Function(int& t)Function(a); // 左值// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)Function(std::move(a)); // 右值const int b = 8;// a是左值,推导出T为const int&,引用折叠,模板实例化为void Function(const int&t)// 所以Function内部会编译报错,x不能++Function(b);// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&&t)// 所以Function内部会编译报错,x不能++Function(std::move(b)); // const 右值return 0;
}推导规则:
| 传入参数 | T 推导类型 | t 实际类型 |
|---|---|---|
左值 int x | int& | int& |
右值 10 | int | int&& |
运行结果:

• 根据上文<左值引用与右值引用>中的说明,所有变量表达式都具有左值属性。这意味着即使一个右值被右值引用绑定后,该右值引用变量的表达式属性仍然是左值。因此,Function函数中的t具有左值属性。若直接将t传递给下层函数Fun,都将匹配Fun的左值引用版本。要保留t的原始属性,就需要使用完美转发。
• 完美转发的实现:
template<typename T>
T&& forward(typename std::remove_reference<T>::type& arg) noexcept {return static_cast<T&&>(arg);
}-
核心操作:
static_cast<T&&>实现引用折叠 -
引用折叠规则:
-
& &→& -
& &&→& -
&& &→& -
&& &&→&&
-
• 完美转发forward本质上是一个函数模板,主要通过引用折叠机制实现。例如:
- 当向Function传递右值时,T被推导为int(无引用折叠),forward内部将t强制转换为右值引用返回;
- 当向Function传递左值时,T被推导为int&(发生引用折叠),forward内部将t强制转换为左值引用返回。
// 完美转发
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template<class T>
void Function(T&& t)
{Fun(t);//Fun(forward<T>(t));
}
int main()
{// 10是右值,推导出T为int,模板实例化为void Function(int&& t)Function(10); // 右值int a;// a是左值,推导出T为int&,引用折叠,模板实例化为void Function(int& t)Function(a); // 左值// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)Function(std::move(a)); // 右值const int b = 8;// a是左值,推导出T为const int&,引用折叠,模板实例化为void Function(const int&t)Function(b); // const 左值// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&&t)Function(std::move(b)); // const 右值return 0;
}运行结果:
没有完美转发forward前:

使用完美转发forward后:

完美转发本质总结
| 特性 | 说明 |
|---|---|
| 值类别保持 | 保留参数的左值/右值属性 |
| 常量性保持 | 保留const/volatile限定 |
| 零开销抽象 | 无额外运行时开销 |
| 类型推导依赖 | 依赖模板类型推导规则 |
| 引用折叠核心 | 通过折叠规则实现类型转换 |
| 泛型编程基石 | STL容器和智能指针的实现基础 |
完美转发是现代C++泛型编程的核心技术,它使得:
-
泛型代码能正确处理各种值类别
-
避免不必要的拷贝和移动操作
-
实现高效的类型无关转发
-
构建灵活可扩展的库接口
正确使用完美转发,可以在保持接口简洁性的同时,获得与手写优化代码相同的性能。