微服务常用的基础知识
1.微服务介绍
1.1 产生背景
随着互联网的发展,网站应用的规模不断扩大,传统单体架构逐渐难以应对大型网站高并发、高扩展性等需求,于是分布式系统架构应运而生。Spring Cloud 就是在这种背景下诞生的,它利用 Spring Boot 的开发便利性,简化了分布式系统的开发。
1.2 主要功能
1.服务发现与注册 :在分布式系统中,各个微服务需要相互调用,服务发现与注册功能可以动态地发现和注册服务的地址,使得服务之间能够方便地进行通信。例如,Eureka 是 Spring Cloud 中常用的服务发现与注册组件,它提供了一个服务注册中心,各个微服务启动时会向注册中心注册自己的信息,当其他服务需要调用它时,通过查询注册中心就可以获取到其地址进行通信。
2.配置中心:集中管理应用程序的配置信息,方便统一修改和管理配置。Config 是 Spring Cloud 的配置中心组件,它支持配置信息存储在多种后端,如本地文件系统、数据库、Git 仓库等。当配置信息发生变化时,可以及时通知各个微服务进行更新。
3.熔断器:在分布式系统中,某些服务可能会因为各种原因出现故障或响应缓慢,熔断器可以快速熔断故障服务的调用,避免故障蔓延,提高系统的稳定性和可用性。Hystrix 是 Spring Cloud 常用的熔断器组件,它能够实时监控服务调用的健康状况,当故障率达到一定程度时,自动熔断后续的调用请求,并可以设置熔断后的降级策略。
4.API 网关:作为系统的统一入口,对外提供 API 接口的路由转发、负载均衡、鉴权认证等功能。Zuul 是 Spring Cloud 的 API 网关组件,它可以对进入系统的请求进行过滤、路由和转发,根据不同的条件将请求分发到不同的后端微服务,并且可以实现一些安全控制和流量控制等功能。
1.3 架构优势
1.微服务架构支持:Spring Cloud 完全契合微服务架构理念,能够帮助开发者快速构建松耦合、易扩展的微服务应用,使得各个服务可以独立开发、部署和扩展。
2.开发便捷性:基于 Spring Boot 的自动配置特性,Spring Cloud 大大简化了分布式系统开发的复杂性,开发者可以使用简单的注解和配置快速搭建和集成各个功能组件。
3.良好的扩展性:Spring Cloud 的各个组件相互独立又可以协同工作,开发者可以根据项目需求灵活选择和组合不同的组件,方便地对系统进行扩展和升级。
2.常用中间件
2.1 Nacos
2.1.1 Nacos功能
1.服务发现与服务健康检查
2.动态配置管理
3.动态DNS服务
4.服务与元数据管理
2.1.2 Nacos注册中心原理

Nacos注册中心分为server与client,server采用Java编写,为client提供注册发现服务与配置服务。而client可以用多语言实现,client与微服务嵌套在一起,nacos提供sdk和openApi,如果没有sdk也可以根据openApi手动写服务注册与发现和配置拉取的逻辑
Nacos注册概括来说有6个步骤:
1、服务容器负责启动,加载,运行服务提供者。
2、服务提供者在启动时,向注册中心注册自己提供的服务。
3、服务消费者在启动时,向注册中心订阅自己所需的服务。
4、注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5、服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
6、服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Nacos 服务注册与订阅的完整流程
Nacos 客户端进行服务注册有两个部分组成,一个是将服务信息注册到服务端,另一个是像服务端发送心跳包,这两个操作都是通过 NamingProxy 和服务端进行数据交互的。
Nacos 客户端进行服务订阅时也有两部分组成,一个是不断从服务端查询可用服务实例的定时任务,另一个是不断从已变服务队列中取出服务并通知 EventListener 持有者的定时任务。
2.1.3 Nacos配置中心原理

Nacos的注册发现是一种三层模型: 即 服务--集群--实例
Nacos服务领域模型主要分为命名空间、集群、服务。在服务级别,保存了健康检查开关、元数据、路由机制、保护阈值等设置,而集群保存了健康检查模式、元数据、同步机制等数据,实例保存了该实例的ip、端口、权重、健康检查状态、下线状态、元数据、响应时间。
在Nacos中管理微服务的配置文件,需要在Nacos控制台创建配置项,指定命名空间和分组,定义配置内容,并通过Nacos客户端在微服务中动态获取和监听配置更新。
2.1.4 注册中心基本使用
1、添加依赖
<!-- springcloud alibaba nacos discovery -->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency><!-- springcloud loadbalancer -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-loadbalancer</artifactId>
</dependency><!-- SpringBoot Web -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>2.添加Nacos配置
# Spring
spring: application:# 应用名称name: ruoyi-xxxx cloud:nacos:discovery:# 服务注册地址server-addr: 127.0.0.1:88483、在Application启动类加入注解@SpringBootApplication。
@SpringBootApplication
public class RuoYiXxxxApplication
{public static void main(String[] args){SpringApplication.run(RuoYiXxxxApplication.class, args);System.out.println("(♥◠‿◠)ノ゙ Xxxx启动成功 ლ(´ڡ`ლ)゙ \n" +" .-------. ____ __ \n" +" | _ _ \\ \\ \\ / / \n" +" | ( ' ) | \\ _. / ' \n" +" |(_ o _) / _( )_ .' \n" +" | (_,_).' __ ___(_ o _)' \n" +" | |\\ \\ | || |(_,_)' \n" +" | | \\ `' /| `-' / \n" +" | | \\ / \\ / \n" +" ''-' `'-' `-..-' ");}
}4.启动服务,查看Nacos控制台的服务列表

2.1.5 配置中心基本使用
1.添加依赖
<!-- springcloud alibaba nacos config -->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency><!-- SpringBoot Web -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>2、在bootstrap.yml添加Nacos配置
# Spring
spring: application:# 应用名称name: ruoyi-xxxxprofiles:# 环境配置active: devcloud:nacos:config:# 配置中心地址server-addr: 127.0.0.1:8848# 配置文件格式file-extension: yml# 共享配置shared-configs:- application-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}3、在Application启动类加入注解@SpringBootApplication。
@SpringBootApplication
public class RuoYiXxxxApplication
{public static void main(String[] args){SpringApplication.run(RuoYiXxxxApplication.class, args);System.out.println("(♥◠‿◠)ノ゙ Xxxx启动成功 ლ(´ڡ`ლ)゙ \n" +" .-------. ____ __ \n" +" | _ _ \\ \\ \\ / / \n" +" | ( ' ) | \\ _. / ' \n" +" |(_ o _) / _( )_ .' \n" +" | (_,_).' __ ___(_ o _)' \n" +" | |\\ \\ | || |(_,_)' \n" +" | | \\ `' /| `-' / \n" +" | | \\ / \\ / \n" +" ''-' `'-' `-..-' ");}
}2.2 Sentinel
2.2.1 基本介绍
Sentinel是阿里巴巴开源的一款面向分布式服务架构的流量控制、熔断降级组件。它以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度帮助用户保障微服务的稳定性。
2.2.2 Sentinel的使用
Sentinel 的使用可以分为两个部分:
- 控制台(Dashboard):控制台主要负责管理推送规则、监控、集群限流分配管理、机器发现等。
- 核心库(Java 客户端):不依赖任何框架/库,能够运行于 Java 7 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
1.添加依赖
<!-- springcloud alibaba sentinel -->
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency><!-- SpringBoot Web -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId>
</dependency>2.添加sentinel配置
spring: application:# 应用名称name: ruoyi-xxxx cloud:sentinel:# 取消控制台懒加载eager: truetransport:# 控制台地址dashboard: 127.0.0.1:87183.下载sentinel客户端jar包
4.在jar目录下输入终端命令
java -jar sentinel-dashboard-1.8.6.jar --server.port=8081
or
java -Dserver.port=8081 -Dcsp.sentinel.dashboard.server=localhost:8081 -Dproject.name=sentinel-dashboard -Dcsp.sentinel.api.port=8082 -jar "C:\project\xinlingzhitong2javacloud\sentinel-dashboard-1.8.6.jar"
or
java -Dserver.port=38718 -Dcsp.sentinel.dashboard.server=localhost:38718 -Dproject.name=sentinel-dashboard -Dfile.encoding=utf-8 -Xms256m -Xmx512m -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -jar sentinel-dashboard-1.8.6.jar5.访问:http://localhost:8081/#/dashboard
2.3 Seata
2.3.1 Seata简介
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
2.3.2 Seata基本架构
- TC (Transaction Coordinator) - 事务协调者;维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器;定义全局事务的范围:开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器;管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。

2.3.3 分布式事务解决方案
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入。
- TCC模式:最终一致的分阶段事务模式,有业务侵入。
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式。
- SAGA模式:长事务模式,有业务侵入。
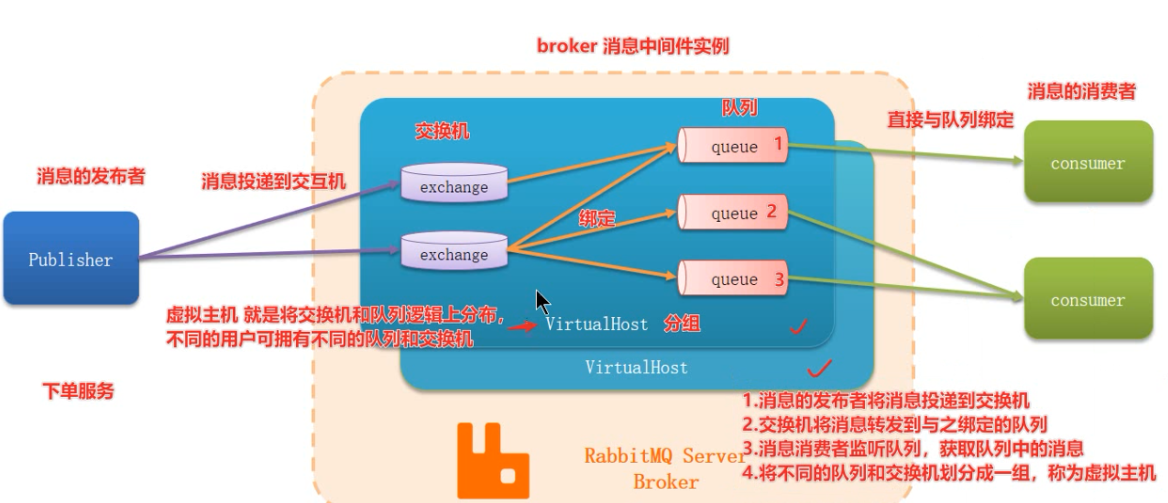
2.4 RabbitMQ
2.4.1 RabbitMQ的基本概念
RabbitMQ中的一些角色:
publisher:生产者(发布者)
consumer:消费者
exchange:交换机,负责消息路由
queue:队列,存储消息
virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
channel:表示通道,操作MQ的工具。是消息发布者和交换机之间的连接通道,也是消息消费者连接队列的通道
将以上的RabbitMQ基本结构归纳为以下四点:
1.消息的发布者(publisher)将消息投递到交换机(exchange)
2.交换机(exchange)将消息转发到与之绑定的队列(queue)
3.消息消费者(consumer)监听队列(queue),获取队列(queue)中的消息
4.将不同的队列(queue)和交换机(exchange)划分成一组,称为虚拟主机(virtualHost)
2.4.2 官方示例
1.基本消息队列

P(producer/ publisher):生产者,一个发送消息的用户应用程序。我们自己书写代码发送。
C(consumer):消费者,消费和接收有类似的意思,消费者是一个主要用来等待接收消息的用户应用程序。我们自己书写代码接收。
队列(红色区域):存在于rabbitmq内部。许多生产者可以发送消息到一个队列,许多消费者可以尝试从一个队列接收数据。
2.工作消息队列

工作消息队列是基本消息队列的增强版,具有多个消费者消费队列的消息。假设消息队列中积压了多个消息,那么此时可以使用多个消费者来消费队列中的消息。效率要比基本消息队列模型高。
3.发布订阅

将消息交给所有绑定到交换机的队列,生产者发送的消息,只能发送到交换机,交换机来决定要发给哪个队列,生产者无法决定。交换机把消息发送给绑定过的所有队列.队列的消费者都能拿到消息。实现一条消息被多个消费者消费.
4.路由

1.在广播模式中,生产者发布消息,所有消费者都可以获取所有消息。
2.在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。在Direct模型下,队列与交换机的绑定,不能是任意绑定了,而是要指定一个RoutingKey(路由key).消息的发送方在向Exchange发送消息时,也必须指定消息的routing key。
3.P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
4.X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
5.主题

1.Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符!
2.Routingkey 一般都是有一个或多个单词组成,多个单词之间以”.”分割,例如: item.insert
3.通配符规则:
#:匹配一个或多个词
*:匹配恰好1个词
2.5 SpringCloud Gateway
2.5.1 基本介绍
服务网关
API Gateway(APIGW / API 网关),顾名思义,是系统对外的唯一入口。API网关封装了系统内部架构,为每个客户端提供定制的API。 近几年来移动应用与企业间互联需求的兴起。从以前单一的Web应用,扩展到多种使用场景,且每种使用场景对后台服务的要求都不尽相同。 这不仅增加了后台服务的响应量,还增加了后台服务的复杂性。随着微服务架构概念的提出,API网关成为了微服务架构的一个标配组件。
why use?
微服务的应用可能部署在不同机房,不同地区,不同域名下。此时客户端(浏览器/手机/软件工具)想 要请求对应的服务,都需要知道机器的具体 IP 或者域名 URL,当微服务实例众多时,这是非常难以记忆的,对 于客户端来说也太复杂难以维护。此时就有了网关,客户端相关的请求直接发送到网关,由网关根据请求标识 解析判断出具体的微服务地址,再把请求转发到微服务实例。这其中的记忆功能就全部交由网关来操作了。
核心概念
路由(Route):路由是网关最基础的部分,路由信息由 ID、目标 URI、一组断言和一组过滤器组成。如果断言 路由为真,则说明请求的 URI 和配置匹配。
断言(Predicate):Java8 中的断言函数。Spring Cloud Gateway 中的断言函数输入类型是 Spring 5.0 框架中 的 ServerWebExchange。Spring Cloud Gateway 中的断言函数允许开发者去定义匹配来自于 Http Request 中的任 何信息,比如请求头和参数等。
过滤器(Filter):一个标准的 Spring Web Filter。Spring Cloud Gateway 中的 Filter 分为两种类型,分别是 Gateway Filter 和 Global Filter。过滤器将会对请求和响应进行处理。
2.5.2 使用网关
1.添加依赖
<!-- spring cloud gateway 依赖 -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>2.resources/application.yml配置文件
server:port: 8080spring: application:name: ruoyi-gatewaycloud:gateway:routes:# 系统模块- id: ruoyi-systemuri: http://localhost:9201/predicates:- Path=/system/**filters:- StripPrefix=13.网关启动类
@SpringBootApplication
public class RuoYiGatewayApplication
{public static void main(String[] args){SpringApplication.run(RuoYiGatewayApplication.class, args);System.out.println("(♥◠‿◠)ノ゙ 若依网关启动成功 ლ(´ڡ`ლ)゙ \n" +" .-------. ____ __ \n" +" | _ _ \\ \\ \\ / / \n" +" | ( ' ) | \\ _. / ' \n" +" |(_ o _) / _( )_ .' \n" +" | (_,_).' __ ___(_ o _)' \n" +" | |\\ \\ | || |(_,_)' \n" +" | | \\ `' /| `-' / \n" +" | | \\ / \\ / \n" +" ''-' `'-' `-..-' ");}
}2.6 MongoDB
2.6.1 简单介绍
MongoDB是一个基于分布式文件存储的数据库
由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。
Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引
2.6.2 使用场景
传统的关系型数据库(如MySQL),在数据操作的三高需求以及应对Web2.0的网站需求面前,显得力不从心,而 MongoDB可应对“三高“需求。
High performance:对数据库高并发读写的需求
Huge Storage:对海量数据的高效率存储和访问的需求
High Scalability && High Availability:对数据库的高可扩展性和高可用性的需求
具体应用场景:
社交场景,使用 MongoDB存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。
游戏场景,使用 MongoDB存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、高效率存储和访问。
物流场景,使用 MongoDB存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来
物联网场景,使用 MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
视频直播,使用 MongoDB存储用户信息、点赞互动信息等。
这些应用场景中,数据操作方面的共同特点是:
(1)数据量大
(2)写入操作频繁(读写都很频繁)
(3)价值较低的数据,对事务性要求不高
对于这样的数据,我们更适合使用 MongoDB来实现数据的存储。
2.6.3 数据类型
MongoDB的最小存储单位就是文档document对象。文档document对象对应于关系型数据库的行。数据在MongoDB中以BSON(Binary-JSON)文档的格式存储在磁盘上。
BSON(Binary Serialized Document Format)是一种类json的一种二进制形式的存储格式,简称 Binary JSON;BSON和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和Bin Data类型。
BSON采用了类似于C语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量性、可遍历性、高效性的三个特点,可以有效描述非结构化数据和结构化数据。这种格式的优点是灵活性高,但它的缺点是空间利用率不是很理想。
BSON中,除了基本JSON类型: string,integer,boolean,double,null,array和object,mongo还使用了特殊的数据类型。这些类型包括 date, object id, binary data, regular expression和code。每一个驱动都以特定语言的方式实现了这些类型,查看你的驱动的文档来获取详细信息。

2.6.4 基本常用命令
增:插入文档
db.集合名.insert(json数据)
集合存在则直接插入数据,不存在则隐式创建集合并插入数据
json数据格式要求key得加"",但这里为了方便查看,对象的key统一不加"";查看集合数据时系统会自动给key加""
mongodb会自动给每条数据创建全球唯一的_id键(我们也可以自定义_id的值,只要给插入的json数据增加_id键即可覆盖,但是不推荐这样做)插入测试

删:删除数据
db.集合名.remove(条件 [,是否删除一条])# 是否删除一条
- false删除多条,即全部删除(默认)
- true删除一条
改:修改数据
db.集合名.update(条件, 新数据 [,是否新增, 是否修改多条])
# 新数据
- 默认是对原数据进行替换
- 若要进行修改,格式为 {修改器:{key:value}}# 是否新增
- 条件匹配不到数据时是否插入: true插入,false不插入(默认)# 是否修改多条
- 条件匹配成功的数据是否都修改: true都修改,false只修改一条(默认)
查:查询数据
db.集合名.find(条件 [,查询的列])
db.集合名.find(条件 [,查询的列]).pretty() #格式化查看# 条件
- 查询所有数据 {}或不写
- 查询指定要求数据 {key:value}或{key:{运算符:value}}# 查询的列(可选参数)
- 不写则查询全部列
- {key:1} 只显示key列
- {key:0} 除了key列都显示
- 注意:_id列都会存在
2.7 RBAC模型
2.7.1 RABC
RBAC(Role-Based Access Control)是一种通过角色(Role)关联用户(User)和权限(Permission)的访问控制模型,核心思想是:用户→角色→权限。
用户(User):系统的实际使用者,拥有唯一标识。
角色(Role):一组权限的集合,代表用户在系统中的职责(如管理员、普通用户)。
权限(Permission):对系统资源的操作许可(如 “用户查看”、“订单删除”)。
关联关系:
用户与角色:多对多(一个用户可拥有多个角色,一个角色可分配给多个用户)。
角色与权限:多对多(一个角色可包含多个权限,一个权限可被多个角色拥有)。
优点:
简化权限管理:通过角色统一管理权限,避免直接对用户逐个授权。
灵活性:新增角色或修改角色权限时,无需逐个调整用户,只需关联角色即可。
职责分离:符合现实中组织架构的职责划分(如财务角色、研发角色)。
2.7.2 RBAC - 1
RBAC - 1 在基本 RBAC 模型的基础上引入了角色层次结构的概念。即一个角色可以继承另一个角色的权限,形成类似于树状或有向无环图(DAG)的结构。例如,“高级管理员” 角色可能继承 “普通管理员” 角色的所有权限,并且还拥有额外的权限。这种层次结构使得权限管理更加灵活和高效,能够更好地反映现实组织中的职责和权力关系。
优势
- 当一个新角色需要继承已有角色的大部分权限时,只需将其置于角色层次结构中合适的位置,而无需重新分配所有权限。
- 角色层次结构可以确保权限的分配遵循一定的规则和逻辑,减少了权限分配的混乱和错误。
- 能够准确地反映组织中不同职位之间的上下级关系和权限继承关系。
2.7.3 RBAC - 2(约束型 RBAC)
RBAC - 2 在基本 RBAC 模型基础上,添加了各种约束条件,以增强系统的安全性和合规性。这些约束可以限制用户、角色和权限之间的关系,防止不合理的权限分配和使用。
常见约束类型:
互斥角色约束:某些角色不能同时被一个用户拥有。例如,在财务系统中,“审计员” 和 “财务管理员” 角色是互斥的,因为一个人不能同时既负责审计又负责财务管理,以防止利益冲突和欺诈行为。
基数约束:对用户可拥有的角色数量、角色可分配的用户数量或权限可分配的角色数量进行限制。例如,规定每个项目只能有一个 “项目经理” 角色。
先决条件约束:一个角色必须在用户拥有另一个角色之后才能被分配。比如,用户必须先拥有 “普通员工” 角色,才能被分配 “部门主管” 角色。
优势
增强安全性:约束条件可以有效防止用户滥用权限,减少内部人员违规操作的风险。
满足合规要求:许多行业有严格的法规和合规要求,RBAC - 2 的约束机制有助于系统满足这些要求,如金融行业的监管要求。
提高系统可靠性:通过约束条件,可以避免不合理的权限分配导致的系统故障和数据不一致问题。
2.8 Elasticsearch
2.8.1 简介
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。

2.8.2 安装
1.下载注意选择的版本需要和你的jdk版本适配
Past Releases of Elastic Stack Software | Elastic
2.修改配置(config下的elasticsearch.yml)
cluster.name: xuecheng #配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name: xc_node_1 #节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
network.host: 0.0.0.0 #绑定ip地址 ,这个位置改为127.0.0.1,否则报错
http.port: 19200 #暴露的http端口
transport.tcp.port: 19300 #内部端口
node.master: true #主节点
node.data: true #数据节点
discovery.zen.ping.unicast.hosts: ["0.0.0.0:19300", "0.0.0.0:19301", "0.0.0.0:19302"] #设置集群中master节点的初始列表
discovery.zen.minimum_master_nodes: 1 #主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
bootstrap.memory_lock: false #内存的锁定只给es用
node.max_local_storage_nodes: 1 #单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1
path.data: C:\elasticsearch-6.2.1\data #索引目录
path.logs: C:\elasticsearch-6.2.1\logs #日志
http.cors.enabled: true # 跨域设置
http.cors.allow-origin: “*” #设置跨域2.8.3 使用
1.进入Elasticsearch的bin目录
cd C:\elasticsearch-6.2.1\bin2.运行elasticsearch-service.bat文件来启动服务
elasticsearch-service.bat install3.启动服务
elasticsearch.bat4.启动成功,访问http://localhost:19200/(19200为配置的端口号)

2.9 Logstash
2.9.1 简介
作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
2.10 Kibana
2.10.1 简介
Kibana 是为 Elasticsearch设计的开源分析和可视化平台。你可以使用 Kibana 来搜索,查看存储在 Elasticsearch 索引中的数据并与之交互。你可以很容易实现高级的数据分析和可视化,以图表的形式展现出来。
2.10.2 安装
1.下载安装
到网站https://www.elastic.co/cn/downloads/kibana下载 可以直接通过修改版本号来下载 https://artifacts.elastic.co/downloads/kibana/kibana-7.17.25-windows-x86_64.zip 版本号和es的一样就行了
2.修改配置文件

2.10.3 使用
启动访问:http://localhost:5601/app/kibana/

ELK架构

2.11 FeignClient
2.11.1 介绍
FeignClient是Spring Cloud的一个声明式HTTP客户端工具,简化了微服务之间的HTTP调用,通过注解和接口定义能够自动且快速发送HTTP请求。
在接触FeignClient之前,对HTTP请求更多的是在前端代码,而FeignClient是后端用来请求HTTP服务(也就是后端某个工程需要请求某个服务),它与前端请求并没有明显的差距,都包括请求url,请求方式,请求参数等,只是书写方式有区别。
2.11.2 使用
FeignClient 的使用步骤
1.引入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2.启用 FeignClient
@SpringBootApplication
@EnableFeignClients
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}
}3.定义 FeignClient 接口
@FeignClient(contextId = "remoteRecruitService", value = ServiceNameConstants.RECRUIT_SERVICE, fallbackFactory = RemoteRecruitFallbackFactory.class)
public interface RemoteRecruitService {@PostMapping("/jobInfo/getJobHotCityList")AjaxResult getJobHotCityList(@RequestBody RecruitCityVo cityVo,@RequestHeader(SecurityConstants.FROM_SOURCE) String source);
}4.调用 FeignClient
@PostMapping("/hotCityList")
public AjaxResult hotCityList(@RequestBody RecruitCityVo cityVo) {cityVo.setBeHot(1); // 热门城市return remoteRecruitService.getJobHotCityList(cityVo, SecurityConstants.INNER);
}2.11.3 服务降级
@Component
public class RemoteRecruitFallbackFactory implements FallbackFactory<RemoteRecruitService>
{private static final Logger log = LoggerFactory.getLogger(RemoteRecruitFallbackFactory.class);@Overridepublic RemoteRecruitService create(Throwable throwable){log.error("招募服务调用失败:{}", throwable.getMessage());return new RemoteRecruitService(){@Overridepublic AjaxResult cancelCollect(RecruitSwCollect recruitSwCollect, String inner) {return AjaxResult.error("recruit服务cancelCollect接口API调用失败:" + throwable.getMessage());}};}
}