RAG入门课程-学习笔记
引用:https://www.bilibili.com/video/BV1hj5DzyE5d/?spm_id_from=333.1387.homepage.video_card.click&vd_source=23c41e5d4f31a4e78f60af9ecdd3fcb7
1.What/Why
1.1 什么是RAG(Retrieval-Augmented Generation)
根据给定的额问题,从知识库中检索出合适的参考内容,让大模型据此回答。
1.2 为什么需要RAG
- 不会私域问题,无法用于企业
- 大模型的数据来自互联网,可用的数据已被消耗殆尽。
1.3 RAG 应用场景
- AI客服
- 政策查询
- AI搜索: 比如Kimi/Deep Seek/Chat GPT 选择
search the web,就是RAG一种。
2.简易RAG流程
2.1 流程图

2.1.1 为什么要切割(chunking)
Q:我们完全可以将所有的资料都传递给大模型,让大模型拿到全量的资料,然后回答,这样回答会更全面,为什么还要切割呢?
1. 上下文窗口限制: Embedding 模型和 LLM 都存在最大 token 限制。太大的文档一次性处理会超出限制。适当长度的 chunk 能保证上下文不超限,且易于处理
2. 调用成本节省:Embedding、检索、LLM 生成等服务都按调用次数或 token 数计费。小块直接带来更少 token ,更便宜 。
3. 提高检索精准度: 将文档切成主题连贯的小块,使检索更精细。小块便于匹配精确答案,大块会混入冗余信息,影响相似度匹配
4. 减少计算资源消耗:处理小块比整篇文档开启 embedding 和检索更快更节省资源 。
5. 保持语义完整性:结构化切割(按句子/段落/语义边界)能避免中断句意,确保 chunk 是完整、有意义的内容单元 。
2.2 准备知识库(索引阶段-Index)
2.2.1 收集知识

PDF 通常以图片形式存放,还涉及到OCR
涉及到视频等,则还要考虑多模态
2.2.2 切分文档
语义连贯性(Semantic Coherence): 将文档切成与主题匹配的“小块”,使每个 chunk 成为一个独立的、语义完整的单元`。避免一个 chunk 涵盖多个话题,否则会干扰向量检索准确性,影响模型生成效果
2.2.2.1 常见切割策略对比
| 策略 | 语义连贯性 | 成本/性能 | 策略说明 |
|---|---|---|---|
| 固定长度切割 Fixed-size | ⭐⭐(可能断句) | ⚡️ 低开销 | 按固定 token/字符划分,简单高效,适合初次快速建库,但容易切断句意 oai_citation:0‡analyticsvidhya.com |
| 语义/边界切割 Boundary-based(按句/段落) | ⭐⭐⭐⭐ 完整语境 | ⚡ 中等 | 按自然语言边界划分,保留语义和上下文,适合语义敏感场景 |
| 递归切割 Recursive | ⭐⭐⭐⭐⭐ 结构优先 | ⚡⚡ 中高 | 多级切割:章节→段落→句子,兼顾结构与长度,适用于复杂文档 |
| 语义切割 Semantic(Embedding 驱动) | ⭐⭐⭐⭐⭐ 高连贯性 | 💲 高 | 用 embedding 计算语义相似度,按意义切分,精度高但计算成本大 |
| 混合策略 Hybrid | ⭐⭐⭐⭐-⭐⭐⭐⭐⭐ 可调 | ⚙️ 平衡 | 结合多种策略(如边界+递归+语义),实现灵活切割,兼顾效率和质量 |
2.2.3 文本向量
- 去重词袋法
- 不去重词袋发
- TF-IDF
- 词嵌入(Word Embedding)
从词袋法到词嵌入,词向量是如何演进的
2.2.3.1 向量存储 — 向量数据库

2.3 检索(Retrieval)
2.3.1 基于文本相似度检索(Vector/Semantic Search)

2.3.2 基于关键字的检索(Keyword Search)

2.3.2 相似度 vs 关键词
🔍 检索方法对比:关键词检索 vs 相似度检索
| 项目 | 关键词检索(Keyword Search) | 相似度检索(Vector/Semantic Search) |
|---|---|---|
| 原理 | 基于词频、倒排索引(TF‑IDF/BM25) | 文本嵌入为向量,根据余弦/欧氏距离计算语义相似度 |
| 匹配方式 | 精确匹配关键词出现频次与文档位置 | 捕捉模糊语义、同义词、多语言等语义关联 |
| 性能 | ⚡️ 非常快,资源占用低,适合海量文本 | 向量计算依赖 ANN 索引,适度延迟,数据量大时需优化 |
| 成本 | 低:算力需求少,部署成熟,解释性强 | 较高:向量存储计算、GPU支持,模型调用成本 |
| 典型应用场景 | - 合同条款检索 - SKU/产品ID 精确查找 - 结构化数据库查询 | - RAG 问答系统 - 客服 Chatbot - 电商推荐 - 图像/音频语义检索 |
2.4 生成阶段(Generation)
2.4.1 提示词模板

2.4.2 模型选择

2.5 小结
3. 优化技巧
3.1 检索优化- small to big
3.1.1 摘要检索
 > 此方法,可以将知识块适当的分割大一些
> 此方法,可以将知识块适当的分割大一些
3.1.2 子问题检索

3.1.3 句子窗口检索

3.2 检索优化 - 多路召回
多路召回就是同时使用多种不同检索器/策略,分别召回一批候选内容,再统一汇总、去重、排序,确保召回的内容全面、语义多元、结构丰富。
常用于问答系统、推荐系统、RAG 知识库中。

- 得分+排名: 文档1胜出
- 平滑指数: 文档2胜出
3.2.1 多路召回常用场景
• 知识库问答(RAG 系统)
• 电商搜索、内容推荐
• 智能客服 Chatbot
• 长文本结构化检索
3.3 检索优化 - Rerank
Rerank 模型是对初始召回的一批候选结果,基于更复杂的深度模型或排序逻辑进行重新打分排序,提升最终 Top-K 结果相关性与质量。
通常配合向量检索 / 多路召回,做最后一轮**“质控”**。

3.4 生成优化
当我们拿到参考文档后,直接拼接到一起,丢给大模型,这样会引申出如下两个问题
- 上下文溢出
- 直接丢弃溢出的部分?
- 直接拼接到一起的文档,知识语意不连贯
3.4.1 refine模式
for-each 知识块 +问题 提问大模型: 利用到了所有的知识块,避免上下文溢出 — 浪费资源

3.4.2 多文档场景的refine

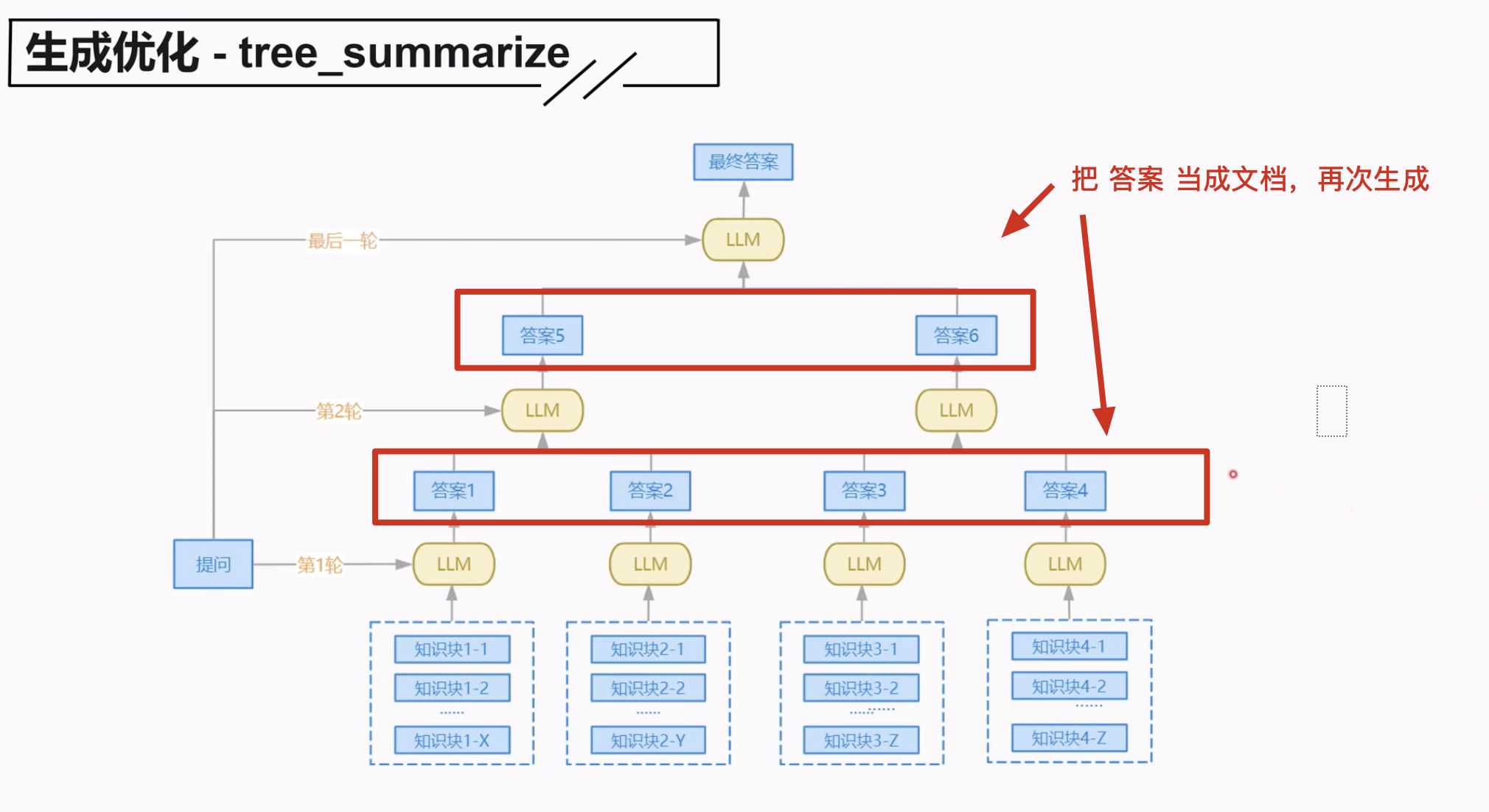
3.4.3 tree_summarize
3.5 改写提问

3.5.1 合理利用元数据

4. 如何评估RAG
4.1 RAG评估指标

4.2 RAG评估方法

4.3 评估工具

5. others
5.1 RAG vs fine-tune
| 对比项 | RAG 检索增强生成 | Fine-tune 模型微调 |
|---|---|---|
| 📖 原理 | 实时检索外部知识库+大模型生成 | 特定领域数据对大模型参数微调 |
| 📦 知识存储 | 外部知识库 + 向量索引 | 模型权重内部 |
| 🔄 知识更新 | 改文档库即可,实时生效 | 需重新训练 |
| 📊 数据量需求 | 少量文档+embedding | 大量标注数据 |
| ⏳ 上线周期 | 快 | 慢 |
| 💰 成本 | 低 | 高 |
| 📈 应用灵活性 | 高,适配多场景 | 低,固定场景 |
| 📌 典型应用 | RAG QA、客服、企业知识库问答、推荐系统 | 指令微调、代码生成、固定场景问答、SFT |
5.2 RAG 三个阶段
