图像融合中损失函数【1】--像素级别损失
目录
一、损失函数总结与讨论
二、像素级别损失
1.1 DenseFuse:Afusionapproachtoinfraredandvisible images
摘要翻译
训练部分翻译
第四节 A 翻译
loss代码解析
1.2 LRRNet: A novel represen tation learning guided fusion network for infrared and visible images
摘要翻译
2. 损失函数分析
1.2 ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion
1. 摘要翻译
2. 损失函数分析
3. 代码部分小结
一、损失函数总结与讨论
源自论文Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption
在无监督红外和可见光图像融合领域,损失函数的设计和选择至关重要。这些函数可以一般地从三个主要维度进行理解和分类:像素级别、评估指标和数据特性。(本节不讨论生成模型如生成对抗网络GANs和扩散模型)
- 在像素级别上,L1和均方误差(MSE)损失函数 [19]、[36]、[156] 通过直接像素比较评估图像相似性。
- 结构相似性(SSIM) [19]、[21]、[22]、[94]、[156] 是一个关键的评估指标,它扩展了图像结构和质量的考虑,反映了人的视觉感知。
- 专注于数据特性的损失函数,如图像梯度 [54]、[166],则注重在融合过程中保留详细的纹理。
在此基础上,出现了更复杂的损失函数变体以应对图像融合中的特定挑战。
例如,在像素级别应用视觉显著性图(VSM [79]、[116]、[126])是一种创新,能够产生更细腻的融合效果。
- 在评估指标层面上,使用较少常见的指标如空间频率(SF) [97] 作为损失函数,强调图像的频率特性以及视觉效果,从而实现有效的融合同时保持视觉舒适度。
- 此外,基于复杂图像特征的损失函数,如最大化梯度或边缘提取 [51]、[95]、[100]、[115]、[153] 以及感受性和对比损失 [167],提供了更深入的洞察和解决方案。
损失函数的设计多种多样,除了上述类型之外,还引入了许多特别设计的损失函数。研究者可以根据源图像特性和任务需求来选择、结合和优化这些损失函数,从而推动图像融合领域的进一步发展和创新。
二、像素级别损失
参考文献:
【19】DenseFuse:Afusionapproachtoinfraredandvisible images
【36】H. Li, T. Xu, X.-J. Wu, J. Lu, and J. Kittler, “LRRNet: A novel represen tation learning guided fusion network for infrared and visible images,” IEEETrans.Pattern Anal. Mach.Intell., vol. 45, no. 9, pp. 11040–11052, Sep. 2023.
【156】Z. Huang, J. Liu, X. Fan, R. Liu, W. Zhong, and Z. Luo, “Reconet: Recurrent correction network for fast and efficient multi-modality image fusion,” in Proc. Eur. Conf. Comput. Vis., 2022, pp. 539–555.
1.1 DenseFuse:Afusionapproachtoinfraredandvisible images
https://github.com/hli1221/imagefusion_densefuse
代码:https://github.com/hli1221/imagefusion_densefuse
摘要翻译
在本文中,我们提出了一种新的深度学习架构,用于解决红外和可见光图像融合问题。与传统的卷积网络不同,我们的编码网络结合了卷积层、融合层和密集块,在这些结构中,每一层的输出都连接到每一层。我们尝试通过这种架构在编码过程中从原始图像中获得更有用的特征,并设计了两个融合层(融合策略)来融合这些特征。最后,通过解码器重建融合图像。与现有的融合方法相比,提出的融合方法在客观和主观评估中都达到了最先进的性能。

训练部分翻译
A. 训练
在训练阶段,我们仅考虑编码器和解码器网络(融合层被舍弃),在此过程中我们尝试训练编码器和解码器网络以重构输入图像。在编码器和解码器的权重固定之后,我们使用自适应融合策略来融合由编码器获得的深层特征。我们网络在训练阶段的工作框架如图2所示,我们网络的架构概略见表I。

这种训练策略的明显优势在于,我们可以为特定的融合任务设计合适的融合层。此外,这也为融合层的进一步发展留下了更多的空间。如图2和表I所示,编码网络中的C1是卷积层,包含3×3的滤波器。DC1、DC2和DC3是密集块中的卷积层,每层输出将通过级联操作连接到其他每一层。解码器由C2、C3、C4和C5组成,将用于重建输入图像。为了更精确地重建输入图像,我们需要最小化损失函数L来训练编码器和解码器,公式如下:
这是一个像素损失Lp和结构性相似性(SSIM)损失的加权组合,权重为
。
像素损失 Lp计算为:
其中,O 和 I 分别表示输出图像和输入图像。它是输出图像O 和输入图像 I之间的欧氏距离。结构相似度损失 通过公式 (3) 获取:
其中,SSIM(·) 表示结构相似度操作 [17],它表示两幅图像的结构相似度。由于像素损失和结构相似度损失之间有三个数量级的差异,在训练阶段,将分别设置为 1、10、100 和 1000。训练阶段的目标是训练一个具有更好特征提取和重建能力的自编码网络(编码器、解码器)。由于红外图像和可见光图像的数据不足,我们使用 MS-COCO [18] 的灰度图像来训练我们的模型。在我们的训练阶段,我们使用可见光图像来训练编码器和解码器的权重。我们使用 MS-COCO [18] 的灰度图像作为输入,这些图像包含 80000 张图片,并且所有图像都被调整为 256 × 256,然后转换为灰度图像。学习率为
。批次大小和 epoch 分别设置为 2 和 4。我们的方法使用 NVIDIA GTX 1080Ti GPU 实现,并且使用 Tensorflow 作为网络架构的后端。训练阶段的分析将在第四节 A 中介绍。
第四节 A 翻译
A. 训练阶段分析
在训练阶段,我们使用MS-COCO [18] 作为输入图像。
在这批源图像中,大约使用了79000张图像作为输入图像,在每次迭代中,使用1000张图像来验证重建能力。
如图5所示,在前2000次迭代中,随着SSIM损失权重λ的数值指数增加,我们的网络呈现出快速收敛的趋势。如第三节A部分所述,像素损失和SSIM损失的数量级是不同的。当λ增加时,SSIM损失在训练过程中发挥的作用更加重要。

无效化步骤,我们从MS-COCO中选择1000张图片作为训练网络的输入。我们使用像素损失和SSIM来评估重构能力。从图6中,验证图显示,随着λ的增加,SSIM损失扮演了重要角色。在迭代次数增加到500时,当λ设置为较大值时,像素损失和SSIM都能取得更好的值。然而,当迭代次数超过40000时,无论选择哪种损失权重,我们都能获得最优权重。总体来说,在训练初期,随着λ的增加,我们的网络会更快地收敛。并且,较大的λ会减少训练阶段的时间消耗。
loss代码解析
- 这个项目使用 tensorflow实现的,参考链接中有torch实现代码
1. SSIM 损失函数的实现
import tensorflow as tfimport numpy as npdef _tf_fspecial_gauss(size, sigma):"""Function to mimic the 'fspecial' gaussian MATLAB function"""x_data, y_data = np.mgrid[-size//2 + 1:size//2 + 1, -size//2 + 1:size//2 + 1]x_data = np.expand_dims(x_data, axis=-1)x_data = np.expand_dims(x_data, axis=-1)y_data = np.expand_dims(y_data, axis=-1)y_data = np.expand_dims(y_data, axis=-1)x = tf.constant(x_data, dtype=tf.float32)y = tf.constant(y_data, dtype=tf.float32)g = tf.exp(-((x**2 + y**2)/(2.0*sigma**2)))return g / tf.reduce_sum(g)def SSIM_LOSS(img1, img2, size=11, sigma=1.5):window = _tf_fspecial_gauss(size, sigma) # window shape [size, size]K1 = 0.01K2 = 0.03L = 1 # depth of image (255 in case the image has a differnt scale)C1 = (K1*L)**2C2 = (K2*L)**2mu1 = tf.nn.conv2d(img1, window, strides=[1,1,1,1], padding='VALID')mu2 = tf.nn.conv2d(img2, window, strides=[1,1,1,1],padding='VALID')mu1_sq = mu1*mu1mu2_sq = mu2*mu2mu1_mu2 = mu1*mu2sigma1_sq = tf.nn.conv2d(img1*img1, window, strides=[1,1,1,1],padding='VALID') - mu1_sqsigma2_sq = tf.nn.conv2d(img2*img2, window, strides=[1,1,1,1],padding='VALID') - mu2_sqsigma12 = tf.nn.conv2d(img1*img2, window, strides=[1,1,1,1],padding='VALID') - mu1_mu2value = (2.0*sigma12 + C2)/(sigma1_sq + sigma2_sq + C2)value = tf.reduce_mean(value)return value解析:
- SSIM_LOSS函数:计算两幅图像的 SSIM 值。具体步骤如下:
- 生成高斯窗口。
- 计算图像的均值、方差和协方差。
- 根据 SSIM 公式计算 SSIM 值。

参考:SSIM计算公式-CSDN博客
- Torch 实现代码
def calculate_ssim(img1, img2, border=0):'''calculate SSIMthe same outputs as MATLAB'simg1, img2: [0, 255]'''if not img1.shape == img2.shape:raise ValueError('Input images must have the same dimensions.')h, w = img1.shape[:2]img1 = img1[border:h-border, border:w-border]img2 = img2[border:h-border, border:w-border]if img1.ndim == 2:return ssim(img1, img2)elif img1.ndim == 3:if img1.shape[2] == 3:ssims = []for i in range(3):ssims.append(ssim(img1, img2))return np.array(ssims).mean()elif img1.shape[2] == 1:return ssim(np.squeeze(img1), np.squeeze(img2))else:raise ValueError('Wrong input image dimensions.')def ssim(img1, img2):C1 = (0.01 * 255)**2C2 = (0.03 * 255)**2img1 = img1.astype(np.float64)img2 = img2.astype(np.float64)kernel = cv2.getGaussianKernel(11, 1.5)window = np.outer(kernel, kernel.transpose())mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] # validmu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]mu1_sq = mu1**2mu2_sq = mu2**2mu1_mu2 = mu1 * mu2sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sqsigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sqsigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *(sigma1_sq + sigma2_sq + C2))return ssim_map.mean()2. 像素损失的实现
像素损失是通过计算原始图像和生成图像之间的均方误差(MSE)来实现的。在train_recons.py文件中实现了像素损失的计算。
Step1 构建计算图:
with tf.Graph().as_default(), tf.Session() as sess:original = tf.placeholder(tf.float32, shape=INPUT_SHAPE_OR, name='original')source = originaldfn = DenseFuseNet(model_pre_path)generated_img = dfn.transform_recons(source)Step2 计算像素损失:
pixel_loss = tf.reduce_sum(tf.square(original - generated_img))pixel_loss = pixel_loss/(BATCH_SIZE*HEIGHT*WIDTH)3. 最终损失的实现
最终的损失是 SSIM 损失和像素损失的加权和。在train_recons.py文件中实现了最终损失的计算。
ssim_loss_value = SSIM_LOSS(original, generated_img)ssim_loss = 1 - ssim_loss_valueloss = ssim_weight*ssim_loss + pixel_loss- ssim_loss_value:调用SSIM_LOSS函数计算 SSIM 值。
- ssim_loss = 1 - ssim_loss_value:将 SSIM 值转换为损失值。
- loss = ssim_weight*ssim_loss + pixel_loss:将 SSIM 损失和像素损失加权求和,得到最终的损失。
1.2 LRRNet: A novel represen tation learning guided fusion network for infrared and visible images
https://github.com/hli1221/imagefusion-LRRNet

摘要翻译
基于深度学习的融合方法在图像融合任务中取得了令人瞩目的性能,这主要归因于在网络架构中发挥重要作用的融合过程。然而,通常很难指定一个好的融合架构,因此融合网络的设计仍然是一种“艺术”,而不是科学。为了解决这个问题,我们通过数学形式化了融合任务,并建立了其最优解与可以实现它的网络架构之间的关系。这种方法导致了一种新颖的构建轻量级融合网络的方法。它通过试错策略避免了耗时的手动网络设计。特别是,我们将融合任务采用可学习的表示方法,其中融合网络的构建由生成可学习模型的优化算法引导。低秩表示(LRR)是我们的可学习模型的基础。在解决方案的核心矩阵乘法被转换为卷积操作,而优化过程中的迭代过程被特殊的前馈网络所替代。基于这一新的网络架构,我们构建了一个端到端的轻量级融合网络来融合红外和可见光图像。通过提出一种详细信息到语义信息损失函数来保留图像细节并增强源图像的显著特征,其成功训练得到了促进。我们的实验表明,与现有的最先进的融合方法相比,所提出的融合网络在公共数据集上的融合性能更好。有趣的是,与现有方法相比,我们的网络所需的训练参数更少。
2. 损失函数分析


对应training_fusion_lrr.py代码:
total_loss = loss_pixel_vi + loss_fea_vi + loss_fea_ir + loss_gram_ir1. 像素级损失\(L_{pixel}\)

I_f是最终的融合图像,I_{ir}和I_{vi}表示源图像(红外和可见光)
代码中:
mse_loss = torch.nn.MSELoss()loss_pixel_vi = 10 * mse_loss(out_f, batch_vi)2.特征损失
# --- Feature loss ----vgg_outs = vgg(out_f) #fusedvgg_irs = vgg(batch_ir) #红外vgg_vis = vgg(batch_vi) #可见光# 初始化t_idx = 0loss_fea_vi = 0.loss_fea_ir = 0.loss_gram_ir = 0.weights_fea = [lam2_vi, 0.01, 0.5, 0.1]weights_gram = [0, 0, 0.1, lam3_gram]# 特征损失for fea_out, fea_ir, fea_vi, w_fea, w_gram in zip(vgg_outs, vgg_irs, vgg_vis, weights_fea, weights_gram):#浅层if t_idx == 0:loss_fea_vi = w_fea * mse_loss(fea_out, fea_vi)# 中层if t_idx == 1 or t_idx == 2:# relu2_2, relu3_3, relu4_3loss_fea_ir += w_fea * mse_loss(fea_out, w_ir * fea_ir + w_vi * fea_vi)# 深层if t_idx == 3:gram_out = utils.gram_matrix(fea_out)gram_ir = utils.gram_matrix(fea_ir)loss_gram_ir += w_gram * mse_loss(gram_out, gram_ir)t_idx += 1
- 浅层

- 中层特征损失\(L_{middle}\)

其中,$K$ 表示卷积块的数量,且 $K = 3$,$\beta_k$ 表示每项的权重。$w_{ir}$ 和 $w_{vi}$ 是控制红外图像和可见图像特征之间权衡的平衡参数。具体来说,$w_{vi}$ 应远小于 $w_{ir}$。

- 深层特征损失\(L_{deep}\)

其中,Gram(·) 表示一个Gram矩阵,即一个未经白化操作的协方差矩阵。
1.2 ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion
https://github.com/dlut-dimt/reconet
1. 摘要翻译
近年来,深度网络在红外和可见光图像融合(IVIF)方面取得了巨大的关注。然而,大多数现有方法无法应对源图像中轻微对齐偏差的问题,并且在计算和空间成本上付出高昂代价。本文通过开发一种循环校正网络(ReCoNet)来解决社区中很少触及的这两个关键问题,实现了稳健且高效的图像融合。具体而言,我们设计了一个变形模块来显式补偿几何失真,并设计了一个注意力机制来减轻类似鬼影的伪影。同时,该网络由并行的扩张卷积层组成,并以循环方式运行,显著降低了空间和计算复杂度。ReCoNet能够有效地缓解由轻微对齐偏差引入的结构失真和纹理伪影。在两个公开数据集上的大量实验表明,我们的ReCoNet相对于最先进的IVIF方法具有更高的准确性和有效性。因此,我们在包含对齐偏差的数据集上获得了16%的相对改进的CC值,并提高了86%的效率。
2. 损失函数分析
我们网络的总损失函数由两个损失项组成:融合损失
和配准损失
。融合损失确保网络生成更好的融合结果且包含丰富的信息,而配准损失有助于约束和细化由于对齐不当引起的图像失真。我们训练网络最小化以下损失函数:
L_total = λ * L_fuse + (1−λ) * L_reg
其中 λ 是一个权衡参数。
代码中:
# 最终损失fin_loss = self.rf_weight[0] * reg_loss + self.rf_weight[1] * fus_lossself.log('train/fin', fin_loss)- 融合损失
融合损失由两个损失项组成。结构相似性 LSSIM 用于从光照、对比度和结构信息方面保持图像的过度结构,而 Lpixel 用于平衡两个源图像的像素强度。因此,融合损失 Lfuse 表达为:

其中,\(\gamma\) 是两个损失项的权重。具体来说,我们限制融合结果具有与源图像相同的基本架构,因此结构相似性损失定义为:

代码中:
# ssim损失计算x_w, y_w = batch['ir_w'], batch['vi_w'] # 权重可用于调整红外和可见光的贡献x_ssim = ssim_loss(f, x, window_size=11, reduction='none')y_ssim = ssim_loss(f, y, window_size=11, reduction='none')s_loss = x_ssim * x_w + y_ssim * y_wself.log('fus/ssim', s_loss.mean())同样,融合结果应平衡来自红外和可见光图像的像素强度分布,像素损失可以表示为:

其中·1 表示 \( L_1 \) 范数。
代码中:
# 像素损失x_l1 = l1_loss(f, x, reduction='none')y_l1 = l1_loss(f, y, reduction='none')l_loss = x_l1 * x_w + y_l1 * y_wself.log('fus/l1', l_loss.mean())# 总融合损失
fus_loss = self.f_weight[0] * s_loss + self.f_weight[1] * l_lossfus_loss = fus_loss.mean()self.log('train/fus', fus_loss)其中,
- self.f_weight 对应于论文中的 γ 参数,控制 SSIM 损失和像素损失的平衡
- 使用 Kornia 库的ssim_loss计算结构相似性损失
- 使用 L1 范数计算像素强度损失
- x_w和y_w允许为不同的输入图像分配不同的权重
- 配准损失
此外,配准损失 \( L_{reg} \) 在纠正失真方面发挥关键作用,可以表示为:

其中 \( L_{sim} \) 表示相似性损失,\( L_{smooth} \) 是一个平滑性损失,旨在确保生成平滑变形。\(\eta\) 是在平衡两项之间的一个折中参数。
更精确地,相似性损失 \( L_{sim} \) 计算为:
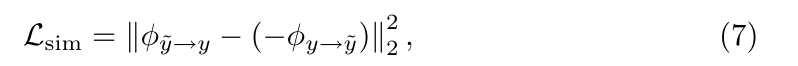
其中表示变形场,
表示生成的随机变形场。由于我们的框架主要关注注册后的融合效果,因此
被粗略用作变形场的标注值,以便我们的配准能够收敛。此过程中引入的这些细微错误将在我们的递归融合机制中消除。
对于二维空间域 \(\Omega\) 中的每个体素 \(p\),平滑损失 \( L_{smooth} \) 可以具体定义为:

其中 \(\nabla\) 表示用相邻体素之间的差异近似空间梯度。
代码:
# 注册损失计算if self.register is not None:# 图像损失:移动后的边缘与原始边缘的MSEimg_loss = mse_loss(y_m_e, y_e)self.log('reg/img', img_loss)# 位置损失:预测的流场与真实流场的MSElocs_gt = batch['locs_gt']locs_loss = mse_loss(locs_pred, locs_gt)self.log('reg/locs', locs_loss)# 平滑损失:计算流场的梯度,确保变形平滑dx = torch.abs(y_m_e[:, :, 1:, :] - y_m_e[:, :, :-1, :])dy = torch.abs(y_m_e[:, :, :, 1:] - y_m_e[:, :, :, :-1])smo_loss = (torch.mean(dx * dx) + torch.mean(dy * dy)) / 2self.log('reg/smooth', smo_loss)# 总注册损失reg_loss = img_loss * self.r_weight[0] + locs_loss * self.r_weight[1] + smo_loss * self.r_weight[2]self.log('train/reg', reg_loss)else:reg_loss = 0其中:
- self.r_weight 对应于论文中的 η 参数,控制相似性损失和光滑损失的平衡
- img_loss 对应于论文中的 L_sim,衡量预测变形与随机变形的相似性
- smo_loss 对应于论文中的 L_smooth,确保变形场的平滑性
- locs_loss 是额外的位置损失项,用于约束预测的流场与真实流场的接近程度
3. 代码部分小结
在reco.py中,训练函数training_step完整实现了上述损失函数的计算过程:
def training_step(self, batch, batch_idx):# 提取输入图像x, y = batch['ir'], batch['vi']# 注册步骤(可选)_, y_e = canny(y) # 计算可见光图像的边缘if self.register is not None:y_t = batch['vi_t'] # 获取变形后的可见光图像y_m, locs_pred, y_m_e = self.r_forward(moving=y_t, fixed=x) # 执行注册else:y_m, locs_pred, y_m_e = y, 0, y_e # 不执行注册时使用原始图像# 融合步骤f = self.f_forward(ir=x, vi=y_m) # 融合注册后的图像# 计算注册损失(如果启用了注册)if self.register is not None:img_loss = mse_loss(y_m_e, y_e) # 图像相似性损失locs_loss = mse_loss(locs_pred, locs_gt) # 位置损失smo_loss = (torch.mean(dx * dx) + torch.mean(dy * dy)) / 2 # 平滑损失reg_loss = img_loss * self.r_weight[0] + locs_loss * self.r_weight[1] + smo_loss * self.r_weight[2]else:reg_loss = 0# 计算融合损失x_w, y_w = batch['ir_w'], batch['vi_w'] # 获取图像权重x_ssim = ssim_loss(f, x, window_size=11, reduction='none') # SSIM损失y_ssim = ssim_loss(f, y, window_size=11, reduction='none')s_loss = x_ssim * x_w + y_ssim * y_wx_l1 = l1_loss(f, x, reduction='none') # 像素损失y_l1 = l1_loss(f, y, reduction='none')l_loss = x_l1 * x_w + y_l1 * y_wfus_loss = self.f_weight[0] * s_loss + self.f_weight[1] * l_lossfus_loss = fus_loss.mean()# 计算总损失fin_loss = self.rf_weight[0] * reg_loss + self.rf_weight[1] * fus_lossreturn fin_loss其中权重定义:
@staticmethoddef add_model_specific_args(parent_parser):parser = parent_parser.add_argument_group('ReCo+')# recoparser.add_argument('--register', type=str, default='x', help='register (m: micro, u: u-net, x: none)')parser.add_argument('--dim', type=int, default=32, help='dimension in backbone (default: 16)')# optimizerparser.add_argument('--lr', type=float, default=1e-3, help='learning rate (default: 1e-3)')# weightsparser.add_argument('--rf_weight', nargs='+', type=float, help='balance in register & fuse')parser.add_argument('--r_weight', nargs='+', type=float, help='balance in register: img, locs, smooth')parser.add_argument('--f_weight', nargs='+', type=float, help='balance in fuse: ssim, l1')return parent_parser| 参数名 | 含义 | 对应论文公式 |
| rf_weight | 平衡注册损失(L_reg)和融合损失(L_fuse)的权重,对应论文中的 λ 和 (1−λ) | L_total = λ*L_fuse + (1−λ)*L_reg |
| r_weight | 注册损失内部的权重,控制 L_sim 和 L_smooth 的平衡,对应论文中的 η 和 (1−η) | L_reg = η*L_sim + (1−η)*L_smooth |
| f_weight | 融合损失内部的权重,控制 L_SSIM 和 L_pixel 的平衡,对应论文中的 γ 和 (1−γ) |
三、总结
对于像素级损失来说,比较重要的一个概念就是范数
1. Frobenius 范数(矩阵范数)
- 定义:对于一个 m \times n 的矩阵\mathbf{A} = [a_{ij}],其 Frobenius 范数定义为:
\|\mathbf{A}\|_F = \sqrt{\sum_{i=1}^m \sum_{j=1}^n |a_{ij}|^2}
等价于将矩阵视为向量后的欧几里得范数,因此也被称为矩阵的欧几里得范数。
- 几何意义:表示矩阵在向量空间中的欧氏距离,不考虑矩阵的结构(如行或列的相关性)。
2. L1 范数(向量 / 矩阵范数)
- 向量 L1 范数:对于向量
,定义为:
衡量向量元素的绝对值之和。
- 矩阵 L1 范数(通常指列和范数):定义为矩阵各列绝对值之和的最大值:
(注:有时也指矩阵所有元素的绝对值之和,需根据上下文判断)。
- 几何意义:向量 L1 范数衡量向量的 “稀疏性”,非零元素越少,范数越小;矩阵 L1 范数衡量列向量的最大强度。
3. 作为损失函数的应用对比
1. Frobenius 范数的应用:
- 场景:图像融合(如 ReCoNet 中的 MSE 损失,本质是 Frobenius 范数的平方)、矩阵分解(如 PCA 的重构误差)、回归问题。
- 例子:
- 特点:追求整体误差最小化,适合需要保留全局信息的任务,但对局部异常值敏感。
例如:
ReCoNet 的注册损失:img_loss = mse_loss(y_m_e, y_e) 本质是 Frobenius 范数的平方(除以批量大小),用于衡量变形后边缘与原始边缘的差异。
LRRNet 的像素损失:
直接使用 Frobenius 范数的平方,约束融合图像与可见光图像的像素级相似性。
- L1 范数的应用:
- 场景:稀疏编码、特征选择(L1 正则化)、异常检测。
- 例子:
- 特点:鼓励预测值与真实值的绝对差最小化,对异常值更鲁棒,适合需要稀疏解的任务(如稀疏表示学习)。
例如:ReCoNet 中融合损失的
,平衡红外与可见光图像的像素强度。