Oracle 数据库性能优化之重做日志(redo)
前言
重做日志是数据库重要组成部分之一,在数据库初始化状态下,根据不同的版本redo默认初始值的大小是不一样。如:11G及一下,默认redo大小为50M。12C及以上默认大小是200M。根据不同的业务情况,redo大小将会极大程度上影响到数据库的性能。
简要介绍
1、redo存在四种不同状态,如:current、active、inactive、unused。不同的状态代表着redo文件是否可更改,更改后是否会造成数据丢失。
2、默认情况下,redo必须存在两组及以上的情况下数据库才可以被使用。
问题
1、根据alert日志显示redo落盘情况看,有许多检查点未完成,导致reod数据无法及时落盘到归档日志中,造成数据库产生大量的等待,导致数据库处理效率低下。
=================================================================================================
Checkpoint not complete --- 第一次Current log# 2 seq# 574046 mem# 0: /oracle/oracle11g/oradata/oatwo/redo02.log
Mon Jun 16 13:01:43 2025
Thread 1 advanced to log sequence 574047 (LGWR switch)Current log# 3 seq# 574047 mem# 0: /oracle/oracle11g/oradata/oatwo/redo03.log
Archived Log entry 1081512 added for thread 1 sequence 574046 ID 0x1075ae79 dest 1:
LNS: Standby redo logfile selected for thread 1 sequence 574047 for destination LOG_ARCHIVE_DEST_2
Thread 1 cannot allocate new log, sequence 574048
=================================================================================================
Checkpoint not complete -- 第二次Current log# 3 seq# 574047 mem# 0: /oracle/oracle11g/oradata/oatwo/redo03.log
Thread 1 advanced to log sequence 574048 (LGWR switch)Current log# 1 seq# 574048 mem# 0: /oracle/oracle11g/oradata/oatwo/redo01.log
Archived Log entry 1081514 added for thread 1 sequence 574047 ID 0x1075ae79 dest 1:
Mon Jun 16 13:01:46 2025
LNS: Standby redo logfile selected for thread 1 sequence 574048 for destination LOG_ARCHIVE_DEST_2
Thread 1 cannot allocate new log, sequence 574049
=================================================================================================
Checkpoint not complete -- 第三次Current log# 1 seq# 574048 mem# 0: /oracle/oracle11g/oradata/oatwo/redo01.log
Thread 1 advanced to log sequence 574049 (LGWR switch)Current log# 2 seq# 574049 mem# 0: /oracle/oracle11g/oradata/oatwo/redo02.log
Archived Log entry 1081516 added for thread 1 sequence 574048 ID 0x1075ae79 dest 1:
LNS: Standby redo logfile selected for thread 1 sequence 574049 for destination LOG_ARCHIVE_DEST_2
Mon Jun 16 13:06:02 2025
Thread 1 cannot allocate new log, sequence 574050
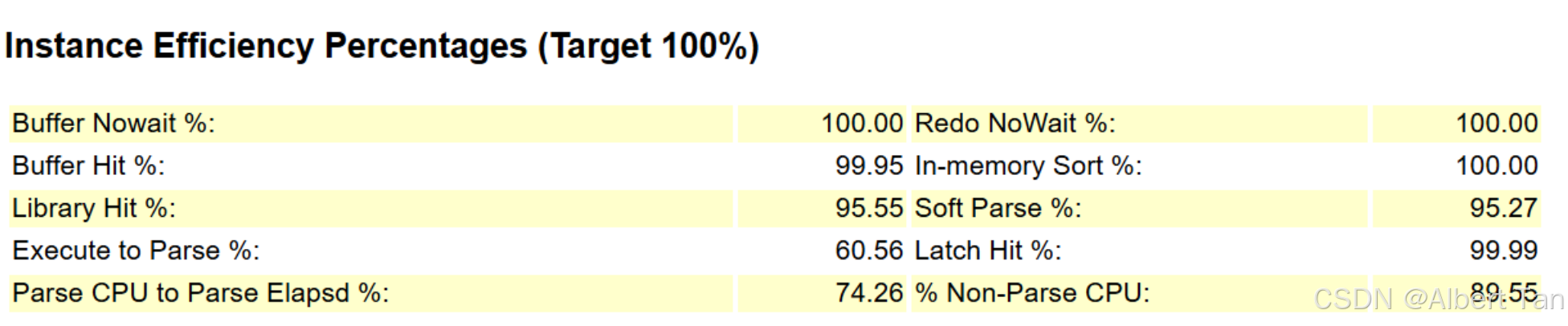
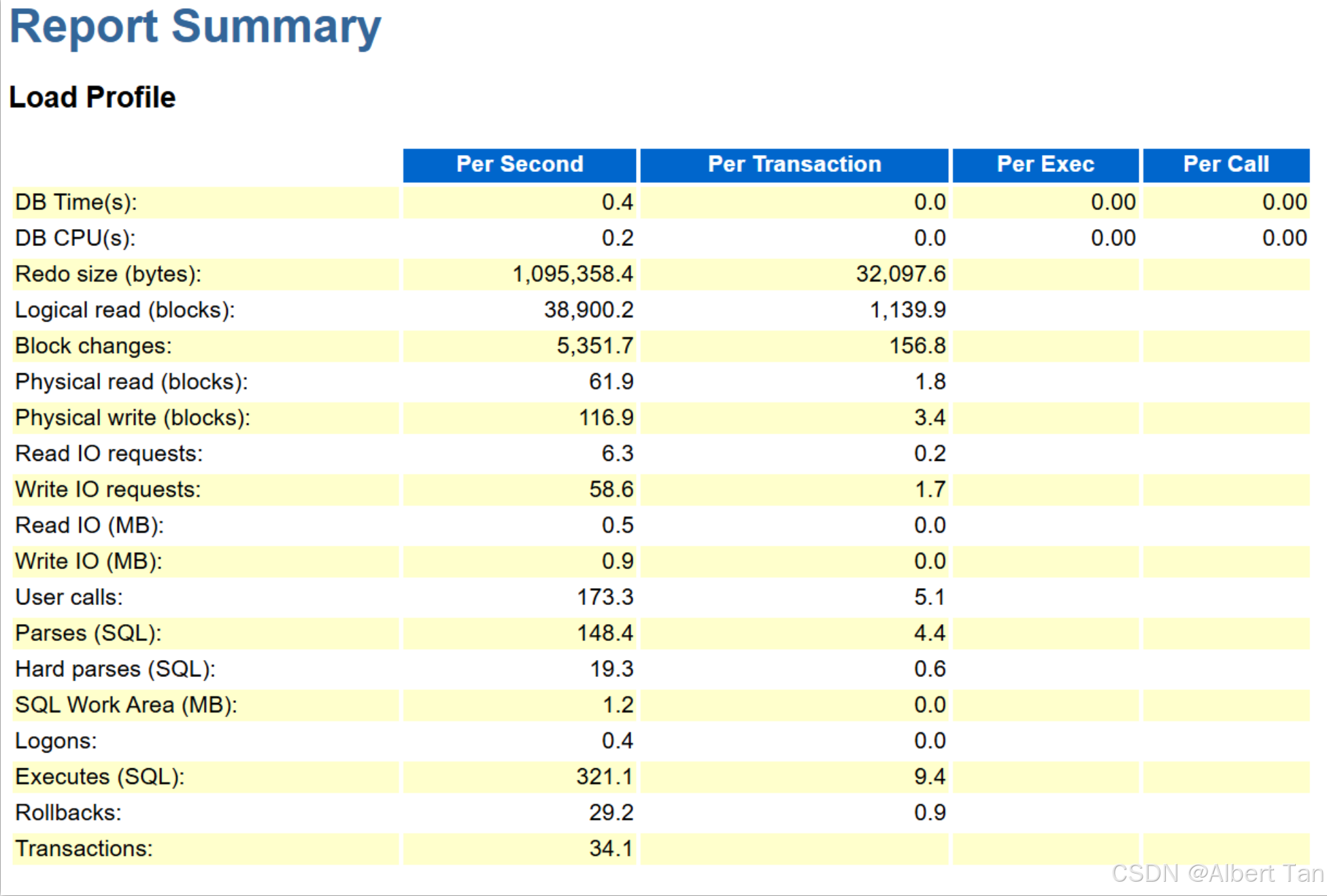
2、从AWR报告中反应出,前十的等待事件中,由于redo日志刷新不及时,占比28%,屈居第二位。第一位DB CPU从目前来看并不是主要事件,因为在load profile中DB Time(s)和DB CPU(s)并没有很高,所以此处排除掉 DB CPU 的负载信息。



解决方案
1、扩大Redo大小,由原50M扩大至300M
优势
1、单位事件内的系统负载同比下降16%
2、前十的等待事件中 log file switch (checkpoint incomplete) 由原27.7%下降到0以下
3、对于SGA和PGA的内存池同比上涨5%