window显示驱动开发—渲染管道
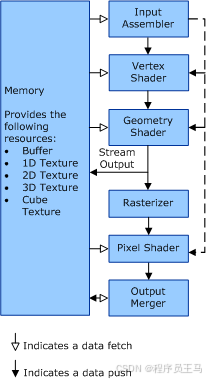
支持 Direct3D 版本 10 的图形硬件可以使用共享可编程着色器核心进行设计。 GPU) (图形处理单元可以编程着色器核心,这些着色器核心可以跨构成呈现管道的功能块进行计划。 这种负载均衡意味着硬件开发人员不需要使用每种着色器类型,而只需要使用执行呈现所需的着色器类型。 然后,此负载均衡可以为处于活动状态的着色器类型释放资源。 下图显示了呈现管道的功能块。 图后面的部分更详细地描述了这些块。
-
输入组装器
输入汇编程序阶段使用固定函数操作读取内存中的顶点。 然后,输入汇编程序形成几何图形基元并创建管道工作项。 自动生成的顶点标识符、实例标识符 (可用于顶点着色器) ,基元标识符 (可用于几何着色器或像素着色器,) 启用特定于标识符的处理。 图中的虚线显示了特定于标识符的处理流程。
-
顶点着色器
顶点着色器阶段采用一个顶点作为输入并输出一个顶点。
-
几何着色器
几何着色器阶段采用一个基元作为输入,并输出零个、一个或多个基元。 在没有几何着色器的情况下,输出基元可以包含比可能更多的数据。 每个操作的输出数据总量 (顶点大小 x 顶点计数) 。
-
流输出
流输出阶段将 (流) 到达几何着色器的输出的基元连接到输出缓冲区。 流输出与几何着色器相关联,两者一起编程。
-
光栅器
光栅器阶段剪辑 (包括自定义剪辑边界) 基元、对基元执行透视划分、实现视口和剪刀选择、执行呈现目标选择和执行基元设置。
-
像素着色器
像素着色器阶段采用一个像素作为输入,并在相同位置或无像素处输出一个像素。 像素着色器无法读取当前呈现目标。
-
输出合并器
输出合并阶段执行固定函数呈现目标混合、深度和模具操作。
1. 共享可编程着色器核心的设计理念
Direct3D 10 引入的统一着色器架构(Unified Shader Architecture)允许 GPU 使用共享的可编程计算单元动态分配资源,而非传统的固定功能着色器单元。这种设计带来以下优势:
- 动态负载均衡:着色器核心(Shader Cores)可灵活分配给 顶点着色器(VS)、几何着色器(GS) 或 像素着色器(PS),避免资源闲置。
- 硬件简化:无需为每种着色器类型单独设计硬件单元,降低芯片复杂度。
- 性能优化:根据渲染负载动态分配资源(例如:当几何处理需求低时,更多核心可分配给像素着色)。
2. Direct3D 10 渲染管线的功能块
下图展示了典型的 Direct3D 10 渲染管线流程,灰色框表示可编程阶段,白色框表示固定功能阶段:
[输入装配器 (IA)] → [顶点着色器 (VS)] → [几何着色器 (GS)] → [流输出 (SO)] ↓
[光栅化器 (Rasterizer)] → [像素着色器 (PS)] → [输出合并器 (OM)](1) 可编程着色器阶段
| 阶段 | 功能 |
|---|---|
| 顶点着色器 (VS) | 处理顶点数据(坐标变换、光照计算等)。 |
| 几何着色器 (GS) | 动态生成/销毁图元(如将点扩展为四边形,新增于 D3D10)。 |
| 像素着色器 (PS) | 计算像素颜色(纹理采样、光照模型等)。 |
(2) 固定功能阶段
| 阶段 | 功能 |
|---|---|
| 输入装配器 (IA) | 组装顶点数据(从缓冲区读取顶点索引)。 |
| 流输出 (SO) | 将几何着色器的输出写入缓冲区(用于GPU粒子系统等)。 |
| 光栅化器 | 将图元转换为像素片段(包括裁剪、视口变换)。 |
| 输出合并器 (OM) | 合并像素着色结果(深度测试、Alpha混合等)。 |
3. 共享着色器核心的工作机制
(1) 动态任务分配
GPU 调度器根据当前帧的渲染需求,将共享着色器核心分配给不同阶段:
- 示例1:若场景需要复杂几何变形(如曲面细分),更多核心分配给 GS。
- 示例2:若场景像素计算密集(如延迟渲染),核心优先分配给 PS。
(2) 硬件实现示例
现代 GPU(如 NVIDIA Fermi 架构或 AMD GCN)的 SIMD 计算单元 可同时处理多种着色器任务:
Shader Core 0: VS → GS → VS → PS
Shader Core 1: PS → PS → VS → GS
(根据每帧需求动态切换)(3) 驱动与运行时协作
驱动:通过 D3D10DDI_DEVICEFUNCS 中的函数表(如 SetShader)配置着色器程序。
硬件:在运行时动态分配计算资源,无需开发者手动干预。
4. 开发者注意事项
(1) 性能优化建议
- 避免着色器核心过载:复杂 GS 可能挤占 VS/PS 资源,需平衡各阶段负载。
- 利用流输出 (SO):将中间几何数据写回缓冲区,减少CPU-GPU通信。
- 着色器一致性:所有可编程阶段使用相同的指令集架构(如HLSL SM4.0)。
(2) 兼容性验证
驱动需通过 OpenAdapter10 和 CreateDevice 报告硬件能力:
D3D10DDI_CAPS caps;
caps.ShaderModel = D3D10DDI_SHADER_MODEL_4_0; // 支持SM4.0
caps.GeometryShaderSupported = TRUE; // 支持GS5. 对比传统架构(Direct3D 9 vs. 10)
| 特性 | Direct3D 9 | Direct3D 10 |
|---|---|---|
| 着色器单元 | 固定功能(VS/PS独立) | 统一着色器核心(动态分配) |
| 几何处理 | 仅顶点着色器 | 新增几何着色器(GS) |
| 资源管理 | 显式管理 | 通过DXGI自动共享 |
| 多线程支持 | 有限 | 完整的多线程渲染管线 |
总结
Direct3D 10 的共享可编程着色器核心设计通过 动态资源分配 和 统一计算架构 显著提升了GPU利用率。开发者需:
- 理解管线阶段:明确VS/GS/PS的职责与交互。
- 优化负载均衡:避免单一阶段成为瓶颈。
- 验证硬件能力:通过DDI接口确认功能支持。