LLMs:《WebDancer: Towards Autonomous Information Seeking Agency》翻译与解读
LLMs:《WebDancer: Towards Autonomous Information Seeking Agency》翻译与解读
导读:该论文提出了一个系统的框架,用于从头开始构建端到端的多步信息搜寻Web Agent。通过引入可扩展的QA数据合成方法以及结合SFT和On-Policy强化学习的两阶段训练pipeline,WebDancer Agent在GAIA和WebWalkerQA上取得了强大的性能。这些发现强调了该论文提出的训练策略的重要性,并为社区提供了可操作和系统性的途径,以推进能够处理复杂现实世界信息搜寻任务的日益复杂的Agentic模型的开发。
>> 背景痛点
● 复杂现实世界问题需要深入的信息搜寻和多步推理。
● 现有Agentic系统的信息搜寻能力不足,训练和评估数据集相对简单,无法捕捉真实世界的挑战。
● 构建自主信息搜寻代理面临挑战:
● 获取高质量、细粒度的浏览数据,反映多样化的用户意图和丰富的交互上下文。
● 构建可靠的轨迹,支持长程推理和任务分解。
● 设计可扩展和泛化的训练策略,使Web Agent在分布外的Web环境、复杂的交互模式和长期目标中具备鲁棒的行为。
>> 具体的解决方案:提出了一个构建端到端Agentic信息搜寻代理的统一范式,从数据中心和训练阶段的角度出发。该方法包括四个关键阶段:
● 浏览数据构建(Browsing data construction)。
● 轨迹抽样(Trajectories sampling)。
● 监督式微调(Supervised fine-tuning),用于有效的冷启动。
● 强化学习(Reinforcement learning),用于增强泛化能力。
在ReAct框架的基础上,实例化了一个Web Agent,名为WebDancer。提出了两种数据集合成方法:
● CRAWLQA:通过爬取网页来构建深度查询,从而通过点击动作获取Web信息。
● E2HQA:通过增强由易到难的QA对合成,将简单问题转化为复杂问题,从而激励从弱到强的代理发展。
● 采用两阶段方法,结合拒绝抽样微调(Rejection Sampling Fine-Tuning,RFT)和后续的On-Policy强化学习。
● 在强化学习阶段,采用解耦剪裁和动态抽样策略优化(Decoupled Clip and Dynamic Sampling Policy Optimization,DAPO)算法。
>> 核心思路步骤
* 数据构建 (Step I):
● 基于真实世界的Web环境,构建多样化且具有挑战性的深度信息搜寻QA对。
● 使用CRAWLQA和E2HQA两种方法生成QA对。
* 轨迹抽样 (Step II):
● 使用LLMs和LRMs从QA对中抽样高质量轨迹,以指导代理学习过程。
● 使用ReAct框架,结合Short-CoT和Long-CoT两种方式生成轨迹。
● 通过有效性控制、正确性验证和质量评估三个阶段的漏斗式轨迹过滤框架,筛选高质量轨迹。
* 监督微调 (Step III):
● 执行微调,以使格式化的指令遵循适应Agentic任务和环境。
● 使用监督式微调(SFT)来训练策略模型,以实现冷启动。
● 掩盖来自外部反馈的损失贡献,以避免在学习期间受到干扰。
* 强化学习 (Step IV):
● 应用强化学习,以优化Agent在真实世界Web环境中的决策制定和泛化能力。
● 使用DAPO算法来优化策略模型。
● 设计奖励机制,包括格式得分和答案得分。
>> 优势
● 提出了一个系统的、端到端的pipeline,用于构建长期信息搜寻Web Agent。
● 提出了可扩展的QA数据合成方法。
● 结合了SFT和On-Policy强化学习的两阶段训练pipeline。
● WebDancer在GAIA和WebWalkerQA两个Web信息搜寻基准测试中表现出色。
● 对Agent训练进行了深入分析,提供了有价值的见解和可操作的、系统性的途径,用于开发更强大的Agentic模型。
● DAPO的动态抽样机制可以有效地利用在SFT阶段未充分利用的QA对,从而提高数据效率和策略鲁棒性。
>> 结论和观点
● 没有Agentic能力的框架在GAIA和WebWalkerQA基准测试中表现不佳,突出了主动信息搜寻和Agentic决策制定的必要性。
● 基于Qwen-32B等原生强大推理模型构建的Agentic方法始终优于其非Agentic对应方法,证明了在Agent构建中利用推理专用模型的有效性。
● 在高度可扩展的ReAct框架下,WebDancer在不同的模型规模上都显示出优于Vanilla ReAct基线的显著优势。
● WebDancer在BrowseComp和BrowseComp-zh数据集上表现出持续的强大性能,突出了其在处理困难的推理和信息搜寻任务方面的鲁棒性和有效性。
● 高质量的轨迹数据对于Agent的有效SFT至关重要。
● SFT对于冷启动至关重要,因为Agent任务需要强大的多步多工具指令遵循能力。
● 强化学习能够实现更长的推理过程并支持更复杂的Agentic动作。
● 调整解码温度对最终性能的影响最小,表明解码可变性本身并不能解释Agent的不稳定性。
● 实际环境随时间演变,需要Agent在不断变化的环境和部分可观察性下保持鲁棒性。
● 强推理器模型使用的思维模式知识很难转移到小型指令模型中。
目录
《WebDancer: Towards Autonomous Information Seeking Agency》翻译与解读
Abstract
1、Introduction
Conclusion
《WebDancer: Towards Autonomous Information Seeking Agency》翻译与解读
| 地址 | 地址:[2505.22648] WebDancer: Towards Autonomous Information Seeking Agency |
| 时间 | 2025年5月28日 |
| 作者 | Tongyi Lab , Alibaba Group |
Abstract
| Addressing intricate real-world problems necessitates in-depth information seeking and multi-step reasoning. Recent progress in agentic systems, exemplified by Deep Research, underscores the potential for autonomous multi-step research. In this work, we present a cohesive paradigm for building end-to-end agentic information seeking agents from a data-centric and training-stage perspective. Our approach consists of four key stages: (1) browsing data construction, (2) trajectories sampling, (3) supervised fine-tuning for effective cold start, and (4) reinforcement learning for enhanced generalisation. We instantiate this framework in a web agent based on the ReAct, WebDancer. Empirical evaluations on the challenging information seeking benchmarks, GAIA and WebWalkerQA, demonstrate the strong performance of WebDancer, achieving considerable results and highlighting the efficacy of our training paradigm. Further analysis of agent training provides valuable insights and actionable, systematic pathways for developing more capable agentic models. The codes and demo will be released in this https URL. | 解决复杂的现实世界问题需要深入的信息搜索和多步骤推理。以 Deep Research 为代表的代理系统近期取得的进展表明了自主多步骤研究的潜力。在本研究中,我们从数据为中心和训练阶段的角度出发,提出了一种构建端到端代理信息搜索代理的连贯范式。我们的方法包含四个关键阶段:(1)浏览数据构建,(2)轨迹采样,(3)监督微调以实现有效的冷启动,以及(4)强化学习以增强泛化能力。我们基于 ReAct 实现了一个网络代理 WebDancer 来实例化此框架。在具有挑战性的信息搜索基准 GAIA 和 WebWalkerQA 上进行的实证评估表明,WebDancer 表现强劲,取得了显著成果,并突显了我们训练范式的有效性。对代理训练的进一步分析提供了有价值的见解和可操作的、系统的路径,以开发更强大的代理模型。 |
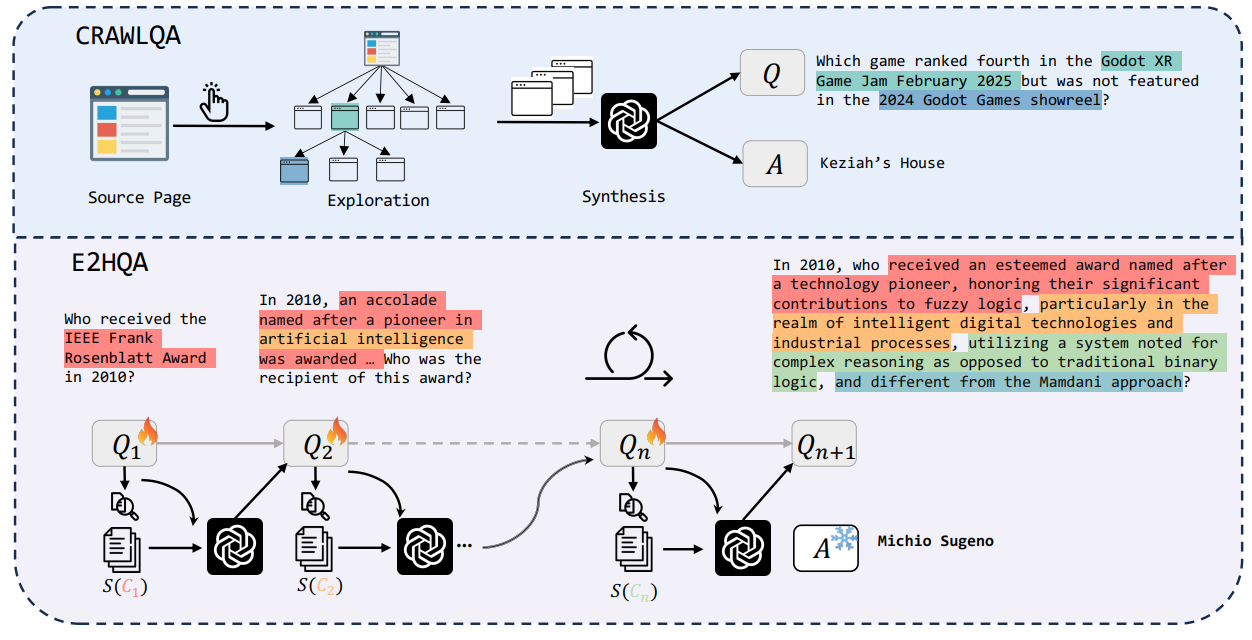
Figure 1: Two web data generation pipelines. ❶ For CRAWLQA, we first collect root url of knowlageable websites. Then we mimic human behavior by systematically clicking and collecting subpages accessible through sublinks on the root/... page. Using predefined rules, we leverage GPT4o to generate synthetic QA pairs based on the gathered information. ❷ For E2HQA, the initial question Q1 is iteratively evolved using the new information Ci retrieved from the entity Ei at iteration i, allowing the task to progressively scale in complexity, from simpler instances to more challenging ones. We use GPT-4o to rewrite the question until the iteration reaches n.图 1:两个网络数据生成流程。❶ 对于 CRAWLQA,我们首先收集知识型网站的根网址。然后通过系统性地点击和收集根页面及其子链接可访问的子页面来模拟人类行为。利用预定义规则,我们借助 GPT4o 根据收集到的信息生成合成的问答对。❷ 对于 E2HQA,初始问题 Q1 在每次迭代 i 时使用从实体 Ei 检索到的新信息 Ci 进行迭代演化,使得任务的复杂度逐步提升,从简单的实例到更具挑战性的实例。我们使用 GPT-4o 重写问题,直到迭代次数达到 n。
1、Introduction
| Web agents are autonomous systems that perceive their real-world web environment, make decisions, and take actions to accomplish specific and human-like tasks. Recent systems, such as ChatGPT Deep Research [1] and Grok DeepSearch [2], have demonstrated strong deep information-seeking capabilities through end-to-end reinforcement learning (RL) training. The community’s previous approaches for information seeking by agentic systems can be categorized into three types: (i) Directly leveraging prompting engineering techniques to guide Large Language Models (LLMs) or Large Reasoning Models (LRMs) [3–5] to execute complex tasks. (ii) Incor-porating search or browser capabilities into the web agents through supervised fine-tuning (SFT) or RL [6, 5, 7–10]. The first training-free methods are unable to effectively leverage the reason-ing capabilities enabled by the reasoning model. Although the latter methods internalize certain information-seeking capabilities through SFT or RL training, both the training and evaluation datasets are relatively simple and do not capture the real-world challenges, for instance, performance on the 2Wiki dataset has already reached over 80%. Moreover, the current SFT or RL training paradigm does not fully and efficiently exploit the potential of information-seeking behavior. Building autonomous information seeking agency involves addressing a set of challenges that span web environment perception and decision-making: (1) acquiring high-quality, fine-grained browsing data that reflects diverse user intents and rich interaction contexts, (2) constructing reliable trajectories that support long-horizon reasoning and task decomposition, and (3) designing scalable and generalizable training strategies capable of endowing the web agent with robust behavior across out-of-distribution web environments, complex interaction patterns, and long-term objectives. | 网络代理是能够感知其真实网络环境、做出决策并采取行动以完成特定且类似人类任务的自主系统。近期的系统,如 ChatGPT Deep Research [1] 和 Grok DeepSearch [2],通过端到端强化学习(RL)训练展示了强大的深度信息搜索能力。 代理系统进行信息搜索的社区先前方法可分为三类:(i)直接利用提示工程技术引导大型语言模型(LLMs)或大型推理模型(LRMs)[3-5]执行复杂任务。(ii)通过监督微调(SFT)或强化学习(RL)将搜索或浏览器功能集成到网络代理中[6, 5, 7-10]。第一种无需训练的方法无法有效利用推理模型所赋予的推理能力。尽管后一种方法通过 SFT 或 RL 训练内化了某些信息搜索能力,但其训练和评估数据集相对简单,并未涵盖现实世界的挑战,例如在 2Wiki 数据集上的性能已超过 80%。此外,当前的 SFT 或 RL 训练范式并未充分且高效地利用信息搜索行为的潜力。构建自主的信息搜索代理涉及解决一系列跨越网络环境感知和决策的挑战:(1)获取高质量、细粒度的浏览数据,这些数据能反映多样化的用户意图和丰富的交互情境;(2)构建可靠的轨迹,以支持长期推理和任务分解;(3)设计可扩展且通用的训练策略,使网络代理能够在分布外的网络环境、复杂的交互模式和长期目标中展现出稳健的行为。 |
| To address these challenges, our objective is to unlock the autonomous multi-turn information-seeking agency, exploring how to build a web agent like Deep Research from scratch. An agent model like Deep Research produces sequences of interleaved reasoning and action steps, where each action invokes a tool to interact with the external environment autonomously. Observations from these interactions guide subsequent reasoning and actions until the task is completed. This process is optimized through end-to-end tool-augmented training. The ReAct framework [11] is the most suitable paradigm, as it tightly couples reasoning with action to facilitate effective learning and generalization in interactive settings. We aim to provide the research community with a systematic guideline for building such agents from a data-centric and training-stage perspective. | 为了解决这些挑战,我们的目标是解锁自主的多轮信息搜索代理能力,探索如何从零开始构建一个像 Deep Research 这样的网络代理。像 Deep Research 这样的代理模型会生成一系列交错的推理和行动步骤序列,其中每个行动都会自主调用一个工具与外部环境进行交互。这些交互的观察结果会引导后续的推理和行动,直至任务完成。这一过程通过端到端工具增强训练得以优化。ReAct 框架[11]是最合适的范式,因为它将推理与行动紧密结合,从而在交互环境中促进有效的学习和泛化。 我们的目标是为研究界提供一个从数据为中心和训练阶段的角度构建此类代理的系统性指南。 |
| From a data-centric perspective, constructing web QA data is crucial to building web agents, re-gardless of whether the training paradigm is SFT or RL. Widely used QA datasets are often shallow, typically consisting of problems that can be solved with a single or a few-turn search. Previous works often filter the difficult QA pairs from open-sourced human-labeled datasets using prompting techniques [7]. Additionally, challenging web-based QA datasets typically only have test or validation sets, and their data size is relatively small. For example, GAIA [12] only has 466, WebWalkerQA [3] contains 680 examples, and BrowseComp [13] has 1,266, making them insufficient for effective training. Therefore, the automatic synthesis of high-quality datasets becomes crucial. [14, 15]. We synthesise the datasets in two ways: 1). By crawling web pages to construct deep queries, referred to as CRAWLQA, enabling the acquisition of web information through click actions. 2). By en-hancing easy-to-hard QA pairs synthesis to incentivize the progression from weak-to-strong agency, transforming simple questions into complex ones, termed E2HQA. From a training-stage perspective, prior work has explored SFT or off-policy RL, but these approaches often face generalization issues, particularly in complex, real-world search environments. Other methods adopt on-policy RL directly [6], but in multi-tool settings, early training steps tend to focus primarily on learning tool usage via instruction following. To enable more efficient and effective training, we adopt a two-stage approach combining rejection sampling fine-tuning (RFT) with subsequent on-policy RL. For the trajectory sampling, we restrict the action space to two commonly effective web information-seeking tools as action: search and click . Building on this setup, we employ rejection sampling to generate trajectories using two prompting strategies: one with a strong instruction LLMs for Short-CoT and another leveraging the LRMs for Long-CoT. These yield high-quality trajectories containing either short or long thought, respectively. In the RL stage, we adopt the Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) algorithm [16], whose dynamic sampling mechanism can effectively exploit QA pairs that remain underutilized during the SFT phase, thereby enhancing data efficiency and policy robustness. | 从以数据为中心的角度来看,构建网络问答数据对于构建网络代理至关重要,无论训练范式是基于监督的微调(SFT)还是基于强化学习(RL)。广泛使用的问答数据集通常比较浅显,通常由可以通过单次或几次搜索解决的问题组成。先前的工作常常使用提示技术从开源的人工标注数据集中过滤掉困难的问答对[7]。此外,具有挑战性的基于网络的问答数据集通常只有测试集或验证集,而且数据规模相对较小。例如,GAIA [12] 只有 466 个样本,WebWalkerQA [3] 包含 680 个示例,BrowseComp [13] 有 1266 个,这使得它们不足以进行有效的训练。因此,高质量数据集的自动合成变得至关重要[14, 15]。我们通过两种方式合成数据集:1)通过抓取网页来构建深度查询,称为 CRAWLQA,这使得能够通过点击操作获取网络信息。2)通过增强从简单到困难的问答对合成,以激励从弱代理到强代理的演进,将简单问题转化为复杂问题,称为 E2HQA。 从训练阶段的角度来看,先前的工作探索了策略微调(SFT)或离策略强化学习(RL),但这些方法往往面临泛化问题,尤其是在复杂的现实世界搜索环境中。其他方法直接采用在策略 RL [6],但在多工具设置中,早期训练步骤往往主要集中在通过遵循指令来学习工具使用。为了实现更高效和有效的训练,我们采用了一个两阶段的方法,将拒绝采样微调(RFT)与后续的在策略 RL 相结合。对于轨迹采样,我们将动作空间限制为两个常用的有效的网络信息搜索工具作为动作:搜索和点击。在此基础上,我们采用拒绝采样,使用两种提示策略生成轨迹:一种是使用强大的指令 LLM 进行短链式思考(Short-CoT),另一种是利用 LRM 进行长链式思考(Long-CoT)。这些分别产生了包含短或长思考的高质量轨迹。在强化学习阶段,我们采用解耦剪辑和动态采样策略优化(DAPO)算法[16],其动态采样机制能够有效利用在 SFT 阶段未充分利用的问答对,从而提高数据效率和策略的稳健性。 |
| Our key contributions can be summarized as follows: we abstract the end-to-end web agents building pipeline into four key stages: Step I: Construct diverse and challenging deep information seeking QA pairs based on the real-world web environment (§2.1); Step II: Sample high-quality trajectories from QA pairs using both LLMs and LRMs to guide the agency learning process (§2.2); Step III: Perform fine-tuning to adapt the format instruction following to agentic tasks and environments (§3.1); Step IV: Apply RL to optimize the agent’s decision-making and generalization capabilities in real-world web environments (§3.2). We offer a systematic, end-to-end pipeline for building long-term information-seeking web agents. Extensive experiments on two web information seeking benchmarks, GAIA and WebWalkerQA, show the effectiveness of our pipeline and WebDancer (§4). We further present a comprehensive analysis covering data efficiency, agentic system evaluation, and agent learning (§5). | 我们的主要贡献可总结如下:我们将端到端的网络代理构建流程抽象为四个关键阶段:步骤一:基于真实世界的网络环境构建多样且具有挑战性的深度信息搜索问答对(§2.1);步骤二:利用大语言模型(LLMs)和语言检索模型(LRMs)从问答对中采样高质量轨迹,以引导代理学习过程(§2.2);步骤三:进行微调以适应格式指令遵循到代理任务和环境(§3.1);步骤四:应用强化学习优化代理在真实网络环境中的决策和泛化能力(§3.2)。我们提供了一个系统性的端到端流程,用于构建长期的信息搜索网络代理。 在两个网络信息搜索基准测试 GAIA 和 WebWalkerQA 上进行的大量实验表明了我们的流程和 WebDancer 的有效性(§4)。我们进一步提供了涵盖数据效率、代理系统评估和代理学习的全面分析(第 5 节)。 |
Conclusion
| In this work, we propose a systematic framework for building end-to-end multi-step information-seeking web agents from scratch. By introducing scalable QA data synthesis methods and a two-stage training pipeline combining SFT and on-policy RL, our WebDancer agent achieves strong performance on GAIA and WebWalkerQA. These findings underscore the significance of our proposed training strategy and provide valuable insights into the critical aspects of agent training. Moving forward, this research offers actionable and systematic pathways for the community to advance the development of increasingly sophisticated agentic models capable of tackling complex real-world information-seeking tasks. | 在本研究中,我们提出了一种从零开始构建端到端多步信息检索网络代理的系统框架。通过引入可扩展的问答数据合成方法以及结合有监督微调(SFT)和策略内强化学习(RL)的两阶段训练流程,我们的 WebDancer 代理在 GAIA 和 WebWalkerQA 上取得了出色的表现。这些发现突显了我们所提出的训练策略的重要性,并为代理训练的关键方面提供了宝贵的见解。展望未来,这项研究为社区提供了切实可行且系统的途径,以推进越来越复杂的代理模型的发展,使其能够应对复杂的现实世界信息检索任务。 |